
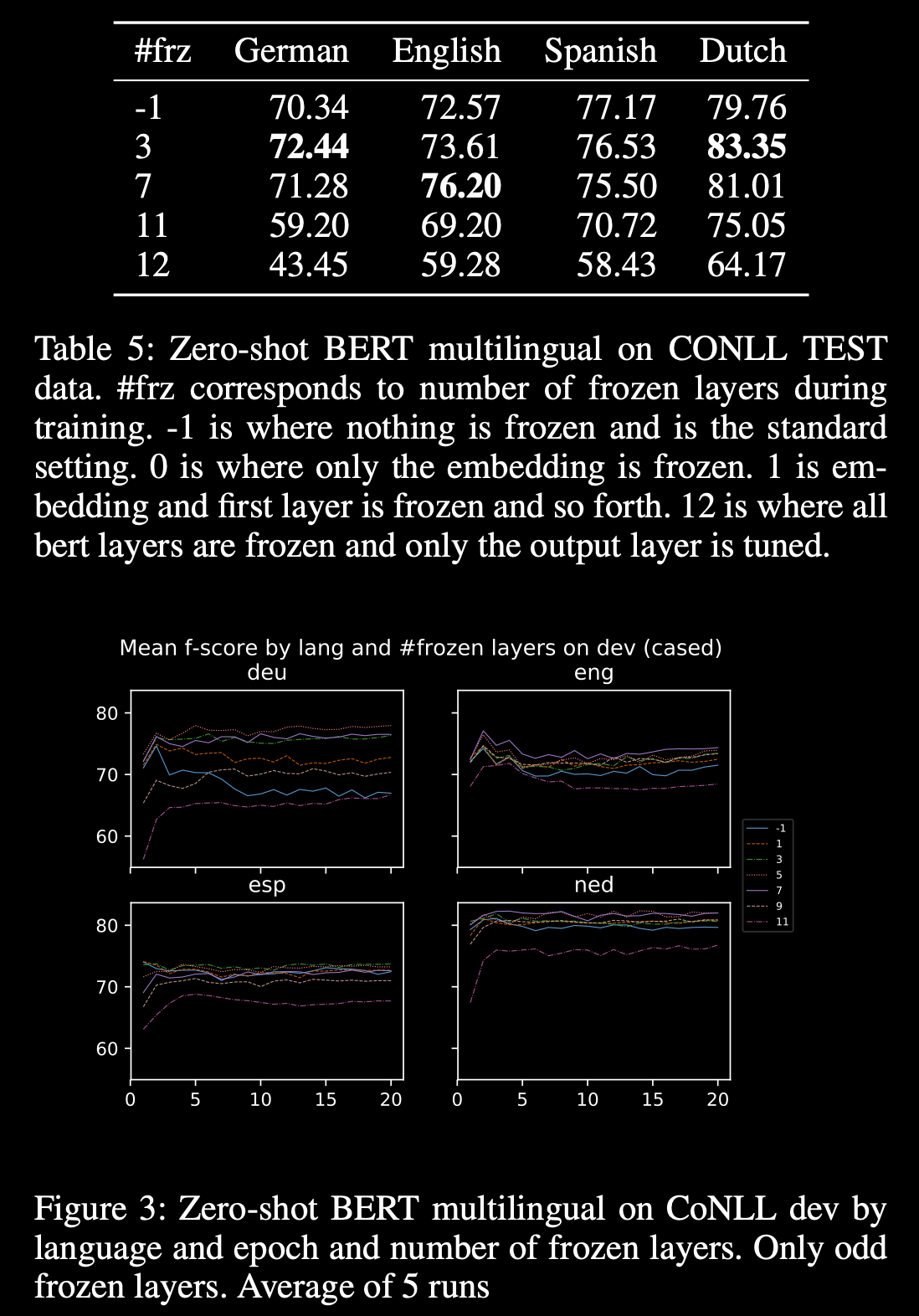
Towards Lingua Franca Named Entity Recognition with BERT
The authors present a simple and effective recipe for building #multilingual #NER systems with #BERT.
By utilizing a multilingual BERT framework, they were able to not only train a system that can perform inference on English, German, Spanish, and Dutch languages, but it performs better than the same model trained only on one language at a time, and also is able to perform 0-shot inference.
The resulting model yields #SotA results on CoNLL Spanish and Dutch, and on OntoNotes Chinese and Arabic datasets.
Also, the English trained model yields SotA results for 0-shot languages for Spanish, Dutch, and German NER, improving it by a range of 2.4F to 17.8F.
Furthermore, the runtime signature (memory/CPU/GPU) of the model is the same as the models built on single languages, significantly simplifying its life- cycle maintenance.
paper: https://arxiv.org/abs/1912.01389
The authors present a simple and effective recipe for building #multilingual #NER systems with #BERT.
By utilizing a multilingual BERT framework, they were able to not only train a system that can perform inference on English, German, Spanish, and Dutch languages, but it performs better than the same model trained only on one language at a time, and also is able to perform 0-shot inference.
The resulting model yields #SotA results on CoNLL Spanish and Dutch, and on OntoNotes Chinese and Arabic datasets.
Also, the English trained model yields SotA results for 0-shot languages for Spanish, Dutch, and German NER, improving it by a range of 2.4F to 17.8F.
Furthermore, the runtime signature (memory/CPU/GPU) of the model is the same as the models built on single languages, significantly simplifying its life- cycle maintenance.
paper: https://arxiv.org/abs/1912.01389
{kind=link}
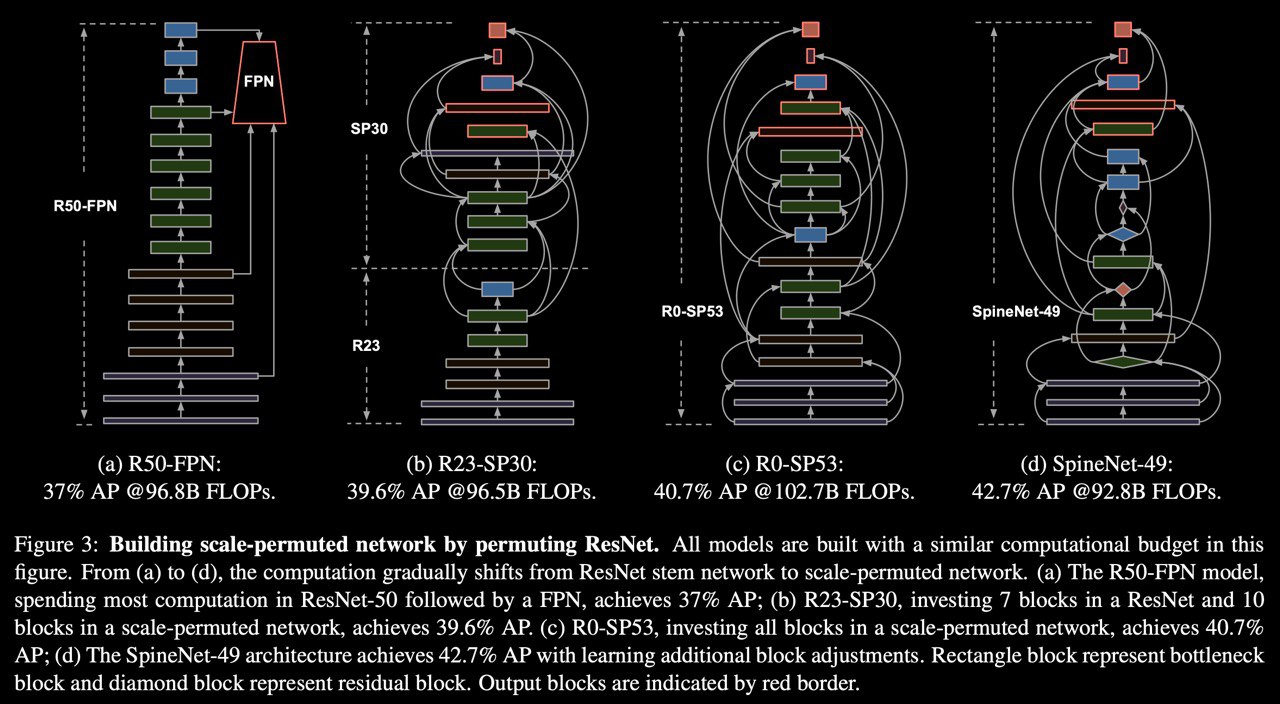
SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization
Abstract: CNN typically encodes an input image into a series of intermediate features with decreasing resolutions. While this structure is suited to classification tasks, it does not perform well for tasks requiring simultaneous recognition and localization (e.g., object detection). The encoder-decoder architectures are proposed to resolve this by applying a decoder network onto a backbone model designed for classification tasks. In this paper, we argue that encoder-decoder architecture is ineffective in generating strong multi-scale features because of the scale-decreased backbone. We propose SpineNet, a backbone with scale-permuted intermediate features and cross-scale connections that are learned on an object detection task by Neural Architecture Search. SpineNet achieves the SOTA performance of a one-stage object detector on COCO with 60% less computation and outperforms ResNet-FPN counterparts by 6% AP. SpineNet architecture can transfer to classification tasks, achieving 6% top-1 accuracy improvement on a challenging iNaturalist fine-grained dataset.
So, by Google's beloved method of creating a new SOTA, there is a new one! They just permute ResNet layers by NAS with adding resample cross-scale connections for correct connection scales output between layers. It seems that no need FPN cause the whole backbone is FPN. They train from scratch on RetinaNet just replace ResNet backbone with SpineNet and get SOTA. On two-stage detectors, there is the same result by replacing the backbone with SpineNet. If you want just classify something with that backbone it is performed very well too. So new architecture for any application!
Good job.
paper: https://arxiv.org/abs/1912.05027
code: Very wanted, but not release yet
#CV #ObjectDetection #GoogleResearch #NAS #SOTA
Abstract: CNN typically encodes an input image into a series of intermediate features with decreasing resolutions. While this structure is suited to classification tasks, it does not perform well for tasks requiring simultaneous recognition and localization (e.g., object detection). The encoder-decoder architectures are proposed to resolve this by applying a decoder network onto a backbone model designed for classification tasks. In this paper, we argue that encoder-decoder architecture is ineffective in generating strong multi-scale features because of the scale-decreased backbone. We propose SpineNet, a backbone with scale-permuted intermediate features and cross-scale connections that are learned on an object detection task by Neural Architecture Search. SpineNet achieves the SOTA performance of a one-stage object detector on COCO with 60% less computation and outperforms ResNet-FPN counterparts by 6% AP. SpineNet architecture can transfer to classification tasks, achieving 6% top-1 accuracy improvement on a challenging iNaturalist fine-grained dataset.
So, by Google's beloved method of creating a new SOTA, there is a new one! They just permute ResNet layers by NAS with adding resample cross-scale connections for correct connection scales output between layers. It seems that no need FPN cause the whole backbone is FPN. They train from scratch on RetinaNet just replace ResNet backbone with SpineNet and get SOTA. On two-stage detectors, there is the same result by replacing the backbone with SpineNet. If you want just classify something with that backbone it is performed very well too. So new architecture for any application!
Good job.
paper: https://arxiv.org/abs/1912.05027
code: Very wanted, but not release yet
#CV #ObjectDetection #GoogleResearch #NAS #SOTA
{kind=link}
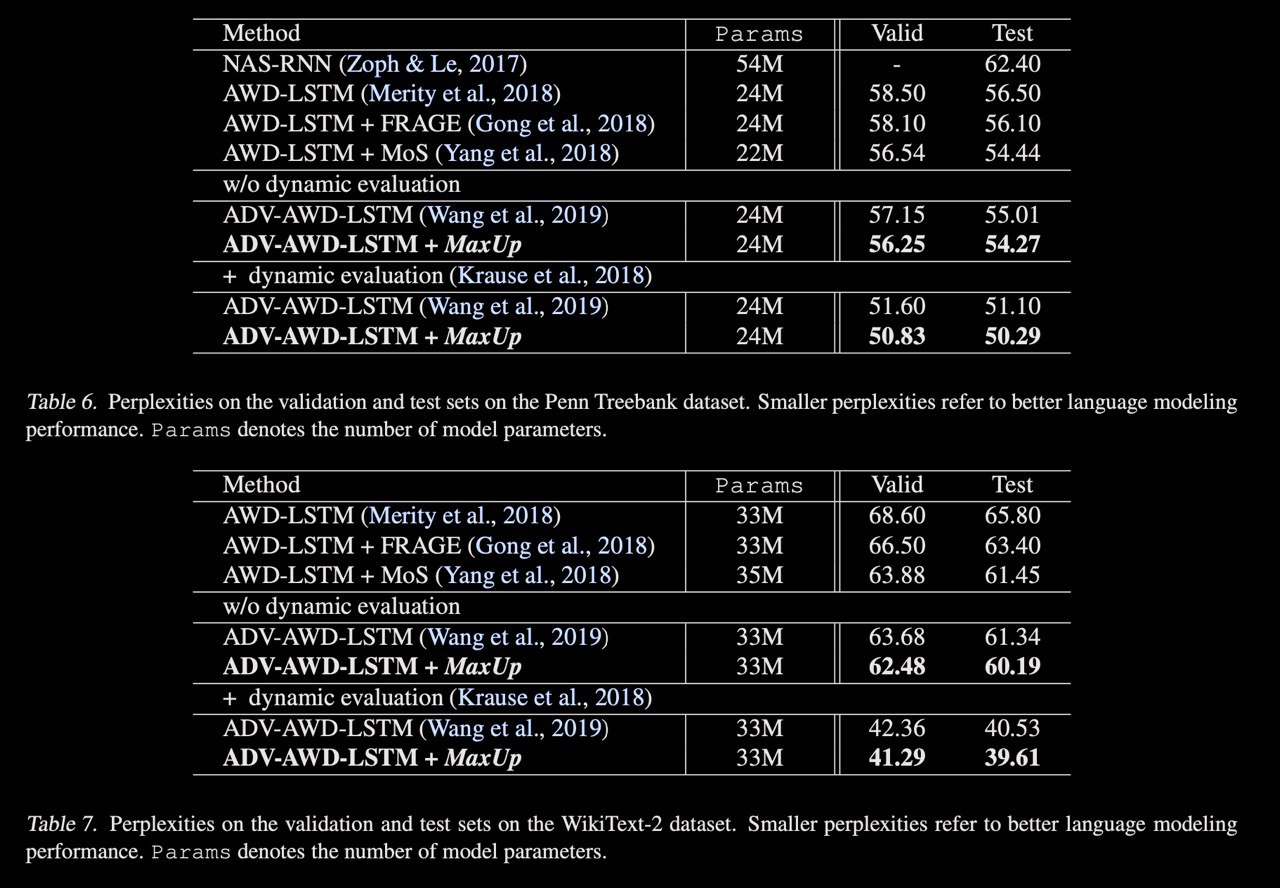
MaxUp: A Simple Way to Improve Generalization of Neural Network Training
A new approach to augmentation both images and text. The idea is to generate a set of augmented data with some random perturbations or transforms and minimize the maximum, or worst case loss over the augmented data. By doing so, the authors implicitly introduce a smoothness or robustness regularization against the random perturbations, and hence improve the generation performance. Testing MaxUp on a range of tasks, including image classification, language modeling, and adversarial certification, it is consistently outperforming the existing best baseline methods, without introducing substantial computational overhead.
Each sample in the batch is augmented
There is some proof of the theorem that MaxUp is gradient-norm regularization if minimizing loss through all batch. Also, It can be viewed as an adversarial variant of data augmentation, in that it minimizes the worse case loss on the perturbed data, instead of an average loss like typical data augmentation methods.
MaxUp easy to mix with other
paper: https://arxiv.org/abs/2002.09024
#augmentations #SOTA #ml
A new approach to augmentation both images and text. The idea is to generate a set of augmented data with some random perturbations or transforms and minimize the maximum, or worst case loss over the augmented data. By doing so, the authors implicitly introduce a smoothness or robustness regularization against the random perturbations, and hence improve the generation performance. Testing MaxUp on a range of tasks, including image classification, language modeling, and adversarial certification, it is consistently outperforming the existing best baseline methods, without introducing substantial computational overhead.
Each sample in the batch is augmented
m times and then found aug with maximum loss and does backprop only through that. i.e. minimizing max loss.There is some proof of the theorem that MaxUp is gradient-norm regularization if minimizing loss through all batch. Also, It can be viewed as an adversarial variant of data augmentation, in that it minimizes the worse case loss on the perturbed data, instead of an average loss like typical data augmentation methods.
MaxUp easy to mix with other
augs without the overhead. Only m times to forward pass on the sample but one time to backprop. paper: https://arxiv.org/abs/2002.09024
#augmentations #SOTA #ml
{kind=link}
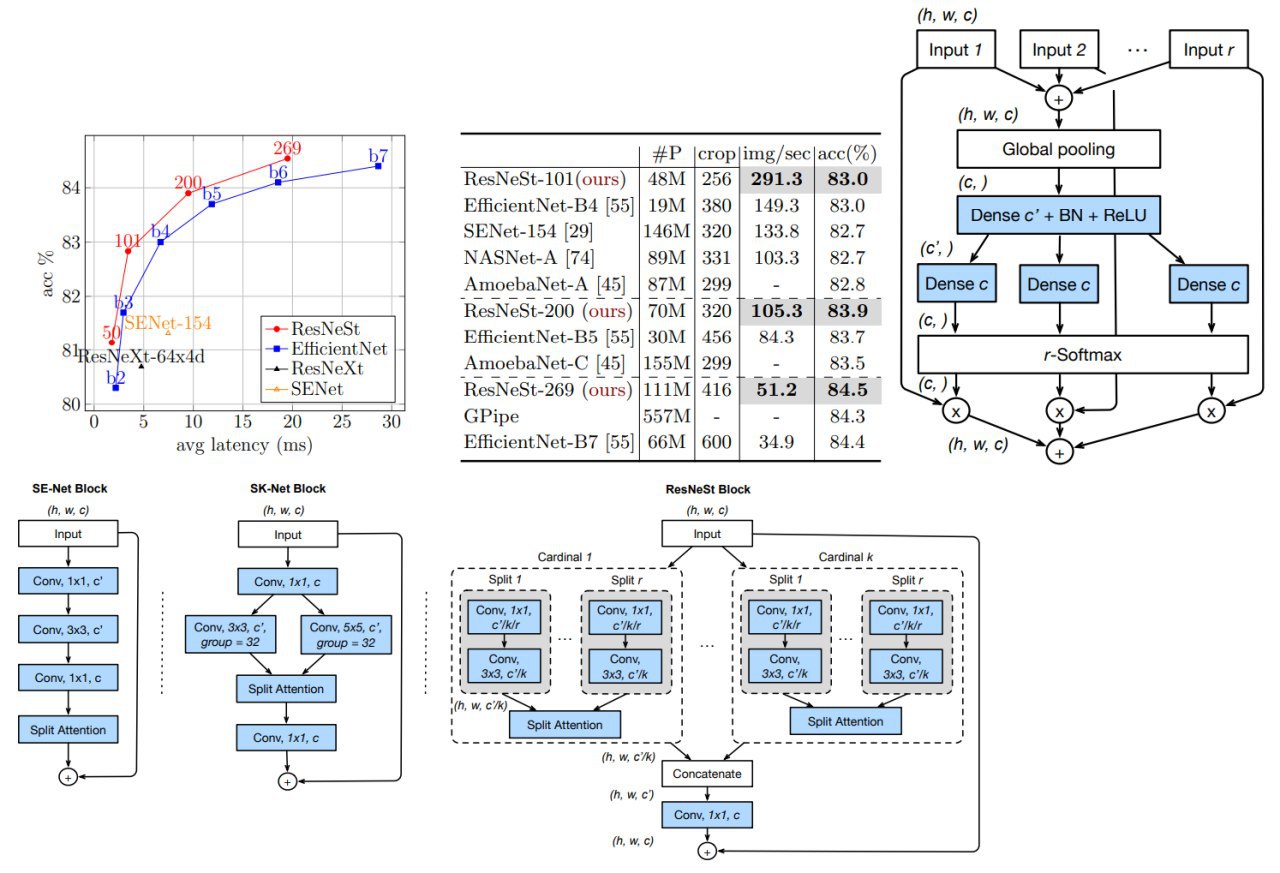
ResNeSt: Split-Attention Networks
A novel variation of ResNet architecture that outperforms other networks with similar model complexities.
Usually, downstream applications use the ResNet or one of its variants as the backbone CNN. Its simple and modular design can be easily adapted to various tasks. However, since ResNet models are originally designed for image classification, they may not be suitable for various downstream applications because of the limited receptive-field size and lack of cross-channel interaction.
Main contributions of the paper:
- Split-Attention block. Each block divides the feature-map into several groups (along the channel dimension) and finer-grained subgroups or splits, where the feature representation of each group is determined via a weighted combination of the representations of its splits. By stacking several Split-Attention blocks, they get a ResNet-like network called ResNeSt (
- a lot of large scale benchmarks on image classification and transfer learning.
Models utilizing a ResNeSt backbone are able to achieve SOTA performance on several tasks, namely: image classification, object detection, instance segmentation, and semantic segmentation.
ResNeSt-50 achieves 81.13% top-1 accuracy on ImageNet using a single crop-size of 224 × 224, outperforming previous best ResNet variant by more than 1% accuracy
Paper: https://arxiv.org/abs/2004.08955
Github: https://github.com/zhanghang1989/ResNeSt
#computervision #deeplearning #resnet #image #backbone #downstream #sota
A novel variation of ResNet architecture that outperforms other networks with similar model complexities.
Usually, downstream applications use the ResNet or one of its variants as the backbone CNN. Its simple and modular design can be easily adapted to various tasks. However, since ResNet models are originally designed for image classification, they may not be suitable for various downstream applications because of the limited receptive-field size and lack of cross-channel interaction.
Main contributions of the paper:
- Split-Attention block. Each block divides the feature-map into several groups (along the channel dimension) and finer-grained subgroups or splits, where the feature representation of each group is determined via a weighted combination of the representations of its splits. By stacking several Split-Attention blocks, they get a ResNet-like network called ResNeSt (
S stands for “split”). This architecture requires no more computation than existing ResNet-variants, and is easy to be adopted as a backbone for other vision tasks- a lot of large scale benchmarks on image classification and transfer learning.
Models utilizing a ResNeSt backbone are able to achieve SOTA performance on several tasks, namely: image classification, object detection, instance segmentation, and semantic segmentation.
ResNeSt-50 achieves 81.13% top-1 accuracy on ImageNet using a single crop-size of 224 × 224, outperforming previous best ResNet variant by more than 1% accuracy
Paper: https://arxiv.org/abs/2004.08955
Github: https://github.com/zhanghang1989/ResNeSt
#computervision #deeplearning #resnet #image #backbone #downstream #sota
{kind=link}
A new SOTA on voice separation model that distinguishes multiple speakers simultaneously
Pandemic given a sufficient rise to new technologies covering voice communication. Noise cancelling is required more than ever and now #Facebook introduced a new method for separating as many as five voices speaking simultaneously into a single microphone. It pushes state of the art on multiple benchmarks, including ones with challenging noise and reverberations.
Blogpost: https://ai.facebook.com/blog/a-new-state-of-the-art-voice-separation-model-that-distinguishes-multiple-speakers-simultaneously
Paper: https://arxiv.org/pdf/2003.01531.pdf
#SOTA #FacebookAI #voicerecognition #soundlearning #DL
Pandemic given a sufficient rise to new technologies covering voice communication. Noise cancelling is required more than ever and now #Facebook introduced a new method for separating as many as five voices speaking simultaneously into a single microphone. It pushes state of the art on multiple benchmarks, including ones with challenging noise and reverberations.
Blogpost: https://ai.facebook.com/blog/a-new-state-of-the-art-voice-separation-model-that-distinguishes-multiple-speakers-simultaneously
Paper: https://arxiv.org/pdf/2003.01531.pdf
#SOTA #FacebookAI #voicerecognition #soundlearning #DL
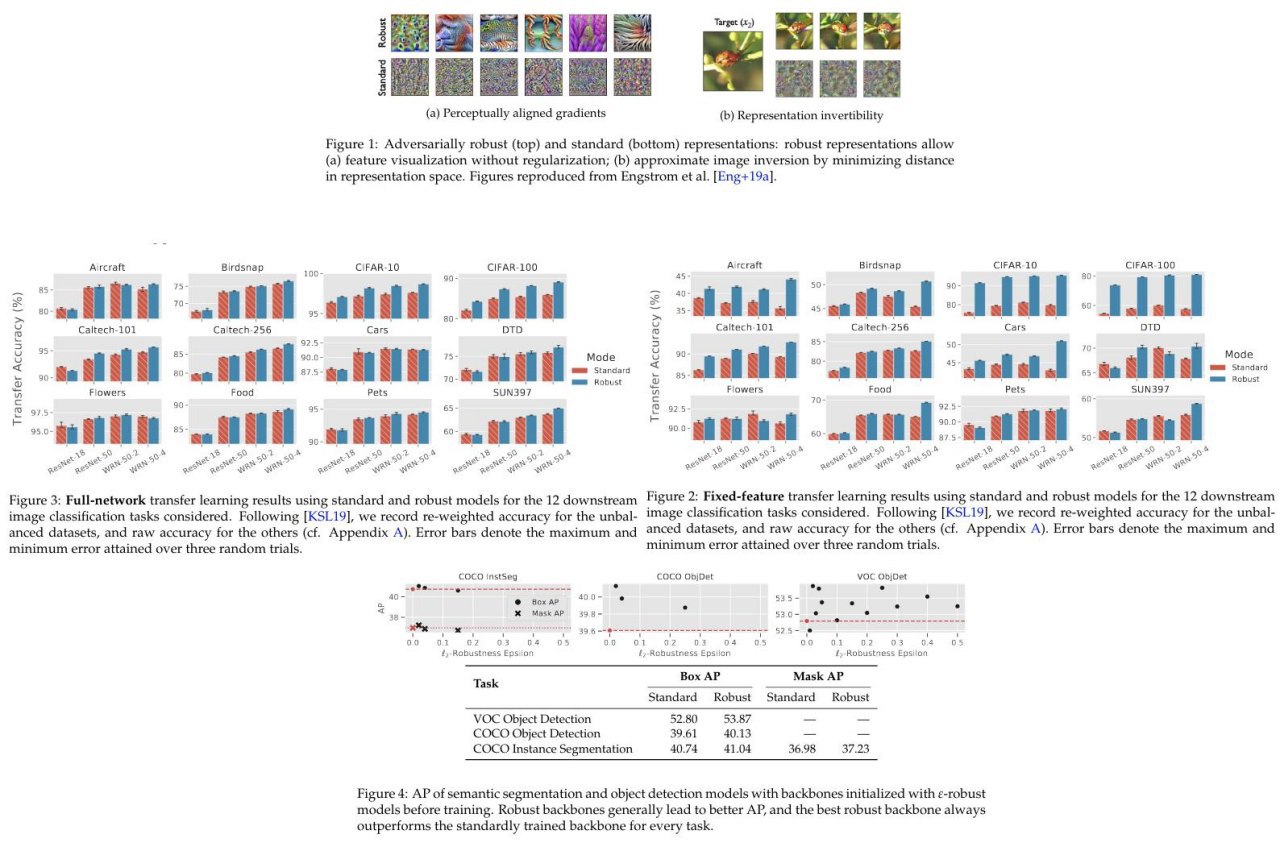
Do Adversarially Robust ImageNet Models Transfer Better?
TLDR - Yes.
Authors decide to check will adversarial trained network performed better on transfer learning tasks despite on worst accuracy on the trained dataset (ImageNet of course). And it is true.
They tested this idea on a frozen pre-trained feature extractor and trained only linear classifier that outperformed classic counterpart. And they tested on a full unfrozen fine-tuned network, that outperformed too on transfer learning tasks.
On pre-train task they use the adversarial robustness prior, that refers to a model’s invariance to small (often imperceptible) perturbations of its inputs.
They show also that such an approach gives better future representation properties of the networks.
They did many experiments (14 pages of graphics) and an ablation study.
paper: https://arxiv.org/abs/2007.08489
code: https://github.com/Microsoft/robust-models-transfer
#transfer_learning #SOTA #adversarial
TLDR - Yes.
Authors decide to check will adversarial trained network performed better on transfer learning tasks despite on worst accuracy on the trained dataset (ImageNet of course). And it is true.
They tested this idea on a frozen pre-trained feature extractor and trained only linear classifier that outperformed classic counterpart. And they tested on a full unfrozen fine-tuned network, that outperformed too on transfer learning tasks.
On pre-train task they use the adversarial robustness prior, that refers to a model’s invariance to small (often imperceptible) perturbations of its inputs.
They show also that such an approach gives better future representation properties of the networks.
They did many experiments (14 pages of graphics) and an ablation study.
paper: https://arxiv.org/abs/2007.08489
code: https://github.com/Microsoft/robust-models-transfer
#transfer_learning #SOTA #adversarial
{kind=link}
QVMix and QVMix-Max: Extending the Deep Quality-Value Family of Algorithms to Cooperative Multi-Agent Reinforcement Learning
Paper extends the Deep Quality-Value (DQV) family of al-
gorithms to multi-agent reinforcement learning and outperforms #SOTA
ArXiV: https://arxiv.org/abs/2012.12062
#DQV #RL #Starcraft
Paper extends the Deep Quality-Value (DQV) family of al-
gorithms to multi-agent reinforcement learning and outperforms #SOTA
ArXiV: https://arxiv.org/abs/2012.12062
#DQV #RL #Starcraft
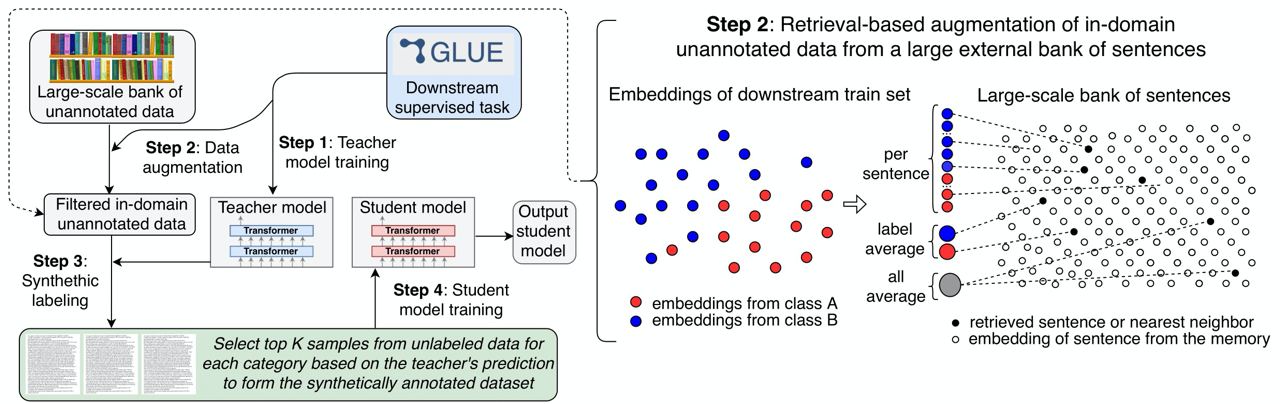
Self-training improves pretraining for natural language understanding
Authors suggested another way to leverage unlabeled data through semi-supervised learning. They use #SOTA sentence embeddings to structure the information of a very large bank of sentences.
Code: https://github.com/facebookresearch/SentAugment
Link: https://arxiv.org/abs/2010.02194
Authors suggested another way to leverage unlabeled data through semi-supervised learning. They use #SOTA sentence embeddings to structure the information of a very large bank of sentences.
Code: https://github.com/facebookresearch/SentAugment
Link: https://arxiv.org/abs/2010.02194
{kind=link}
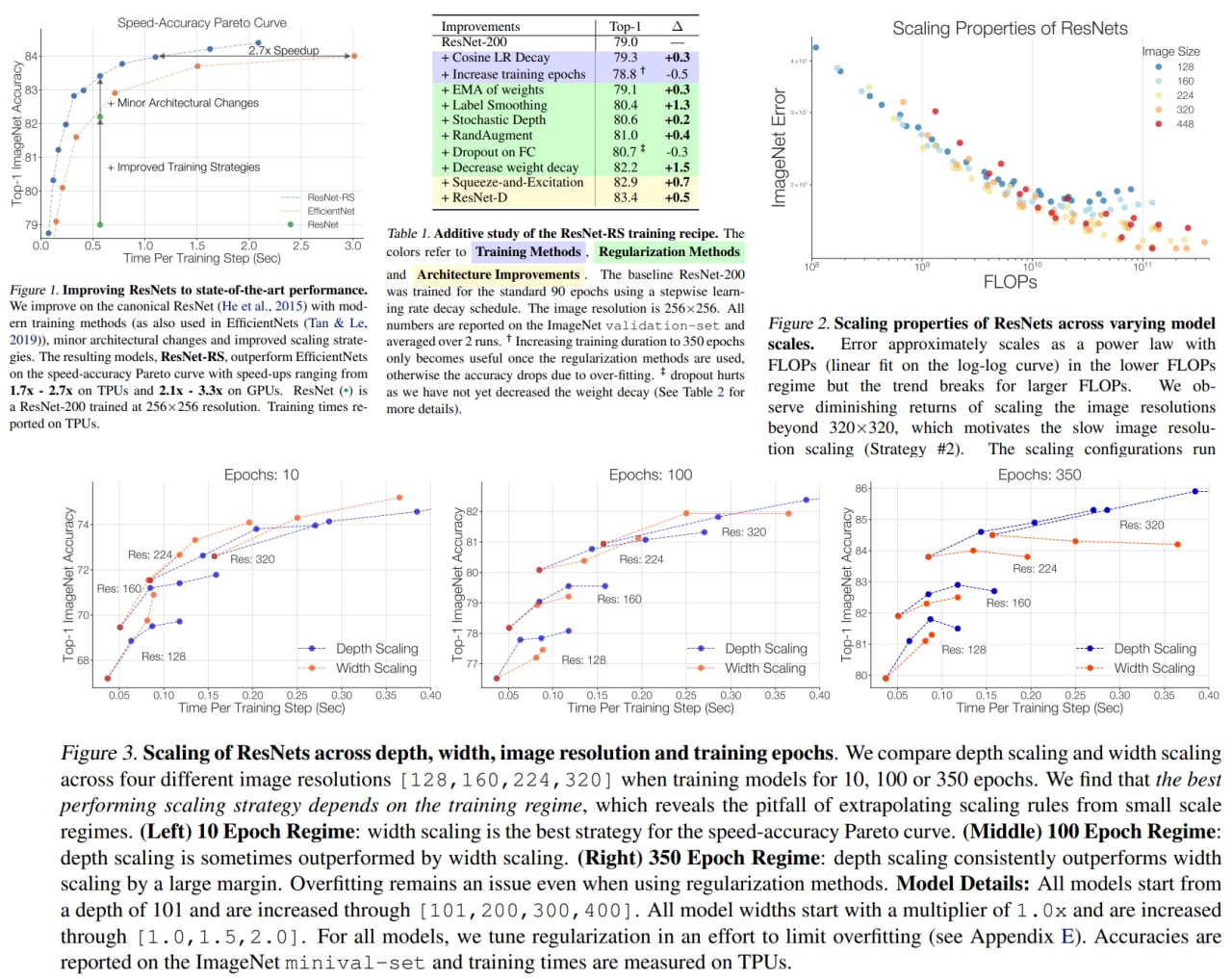
Revisiting ResNets: Improved Training and Scaling Strategies
The authors of the paper (from Google Brain and UC Berkeley) have decided to analyze the effects of the model architecture, training, and scaling strategies separately and concluded that these strategies might have a higher impact on the score than the architecture.
They offer two new strategies:
- scale model depth if overfitting is possible, scale model width otherwise
- increase image resolution slower than recommended in previous papers
Based on these ideas, the new architecture ResNet-RS was developed. It is 2.1x–3.3x faster than EfficientNets on GPU while reaching similar accuracy on ImageNet.
In semi-supervised learning, ResNet-RS achieves 86.2% top-1 ImageNet accuracy while being 4.7x faster than EfficientNet-NoisyStudent.
Transfer learning on downstream tasks also has improved performance.
The authors suggest using these ResNet-RS as a baseline for further research.
Paper: https://arxiv.org/abs/2103.07579
Code and checkpoints are available in TensorFlow:
https://github.com/tensorflow/models/tree/master/official/vision/beta
https://github.com/tensorflow/tpu/tree/master/models/official/resnet/resnet_rs
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-resnetsr
#deeplearning #computervision #sota
The authors of the paper (from Google Brain and UC Berkeley) have decided to analyze the effects of the model architecture, training, and scaling strategies separately and concluded that these strategies might have a higher impact on the score than the architecture.
They offer two new strategies:
- scale model depth if overfitting is possible, scale model width otherwise
- increase image resolution slower than recommended in previous papers
Based on these ideas, the new architecture ResNet-RS was developed. It is 2.1x–3.3x faster than EfficientNets on GPU while reaching similar accuracy on ImageNet.
In semi-supervised learning, ResNet-RS achieves 86.2% top-1 ImageNet accuracy while being 4.7x faster than EfficientNet-NoisyStudent.
Transfer learning on downstream tasks also has improved performance.
The authors suggest using these ResNet-RS as a baseline for further research.
Paper: https://arxiv.org/abs/2103.07579
Code and checkpoints are available in TensorFlow:
https://github.com/tensorflow/models/tree/master/official/vision/beta
https://github.com/tensorflow/tpu/tree/master/models/official/resnet/resnet_rs
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-resnetsr
#deeplearning #computervision #sota
{kind=link}
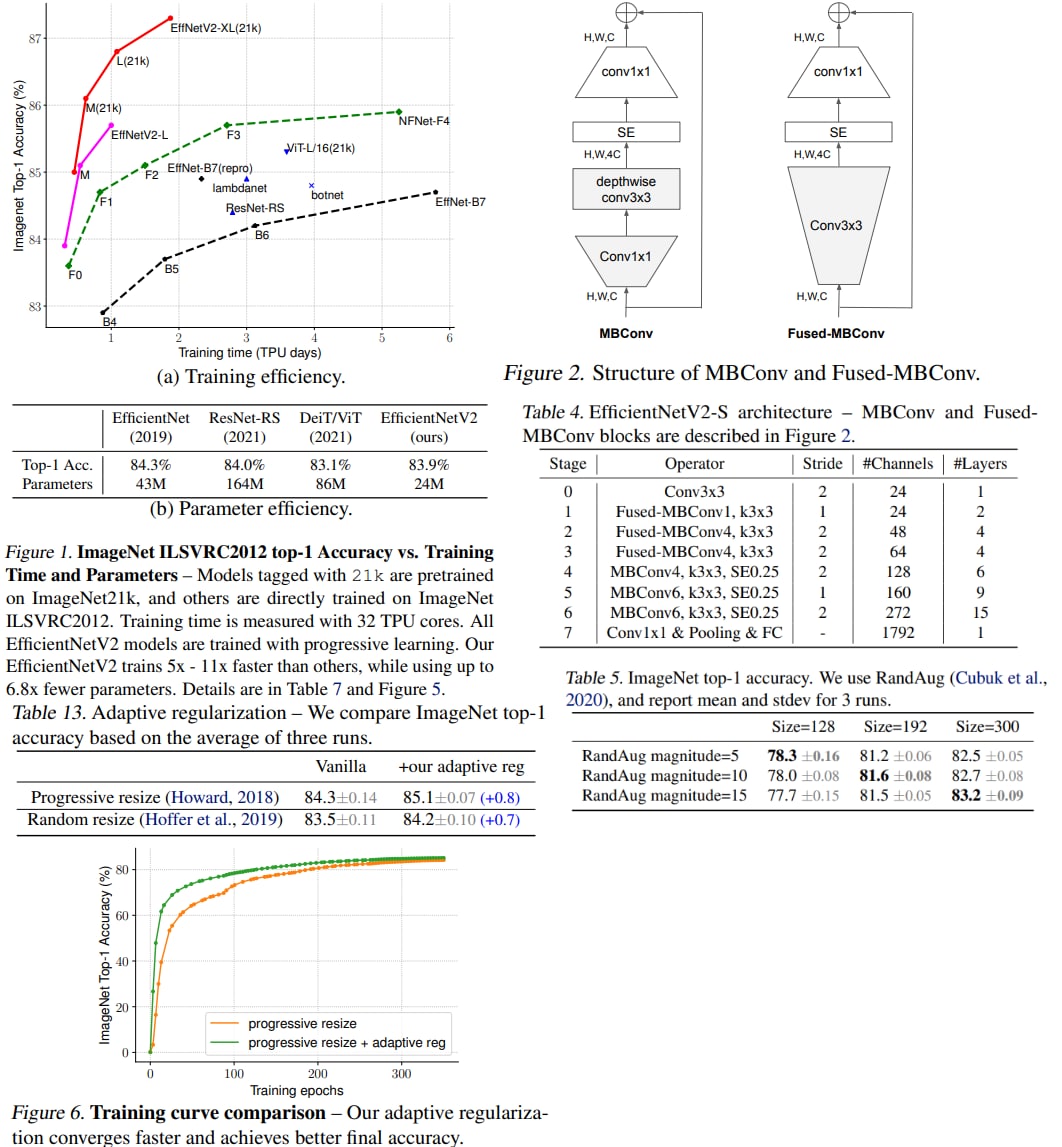
EfficientNetV2: Smaller Models and Faster Training
A new paper from Google Brain with a new SOTA architecture called EfficientNetV2. The authors develop a new family of CNN models that are optimized both for accuracy and training speed. The main improvements are:
- an improved training-aware neural architecture search with new building blocks and ideas to jointly optimize training speed and parameter efficiency;
- a new approach to progressive learning that adjusts regularization along with the image size;
As a result, the new approach can reach SOTA results while training faster (up to 11x) and smaller (up to 6.8x).
Paper: https://arxiv.org/abs/2104.00298
Code will be available here:
https://github.com/google/automl/tree/master/efficientnetv2
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-effnetv2
#cv #sota #nas #deeplearning
A new paper from Google Brain with a new SOTA architecture called EfficientNetV2. The authors develop a new family of CNN models that are optimized both for accuracy and training speed. The main improvements are:
- an improved training-aware neural architecture search with new building blocks and ideas to jointly optimize training speed and parameter efficiency;
- a new approach to progressive learning that adjusts regularization along with the image size;
As a result, the new approach can reach SOTA results while training faster (up to 11x) and smaller (up to 6.8x).
Paper: https://arxiv.org/abs/2104.00298
Code will be available here:
https://github.com/google/automl/tree/master/efficientnetv2
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-effnetv2
#cv #sota #nas #deeplearning
{kind=link}
Summarizing Books with Human Feedback
#OpenAI fine-tuned #GPT3 to summarize books well enough to be human-readable. Main approach: recursively split text into parts and then meta-summarize summaries.
This is really important because once there will be a great summarization #SOTA we won't need editors to write posts for you. And researchers ultimatively will have some asisstance interpreting models' results.
BlogPost: https://openai.com/blog/summarizing-books/
ArXiV: https://arxiv.org/abs/2109.10862
#summarization #NLU #NLP
#OpenAI fine-tuned #GPT3 to summarize books well enough to be human-readable. Main approach: recursively split text into parts and then meta-summarize summaries.
This is really important because once there will be a great summarization #SOTA we won't need editors to write posts for you. And researchers ultimatively will have some asisstance interpreting models' results.
BlogPost: https://openai.com/blog/summarizing-books/
ArXiV: https://arxiv.org/abs/2109.10862
#summarization #NLU #NLP
{kind=link}
🔥Alias-Free Generative Adversarial Networks (StyleGAN3) release
King is dead! Long live the King! #StyleGAN2 was #SOTA and default standard for generating images. #Nvidia released update version, which will lead to more realistic images generated by the community.
Article: https://nvlabs.github.io/stylegan3/
GitHub: https://github.com/NVlabs/stylegan3
Colab: https://colab.research.google.com/drive/1BXNHZBai-pXtP-ncliouXo_kUiG1Pq7M
#GAN #dl
King is dead! Long live the King! #StyleGAN2 was #SOTA and default standard for generating images. #Nvidia released update version, which will lead to more realistic images generated by the community.
Article: https://nvlabs.github.io/stylegan3/
GitHub: https://github.com/NVlabs/stylegan3
Colab: https://colab.research.google.com/drive/1BXNHZBai-pXtP-ncliouXo_kUiG1Pq7M
#GAN #dl
🦜 Hi!
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
GitHub
ultimate_posts/where_to_start at master · open-data-science/ultimate_posts
Ultimate posts for opendatascience telegram channel - open-data-science/ultimate_posts
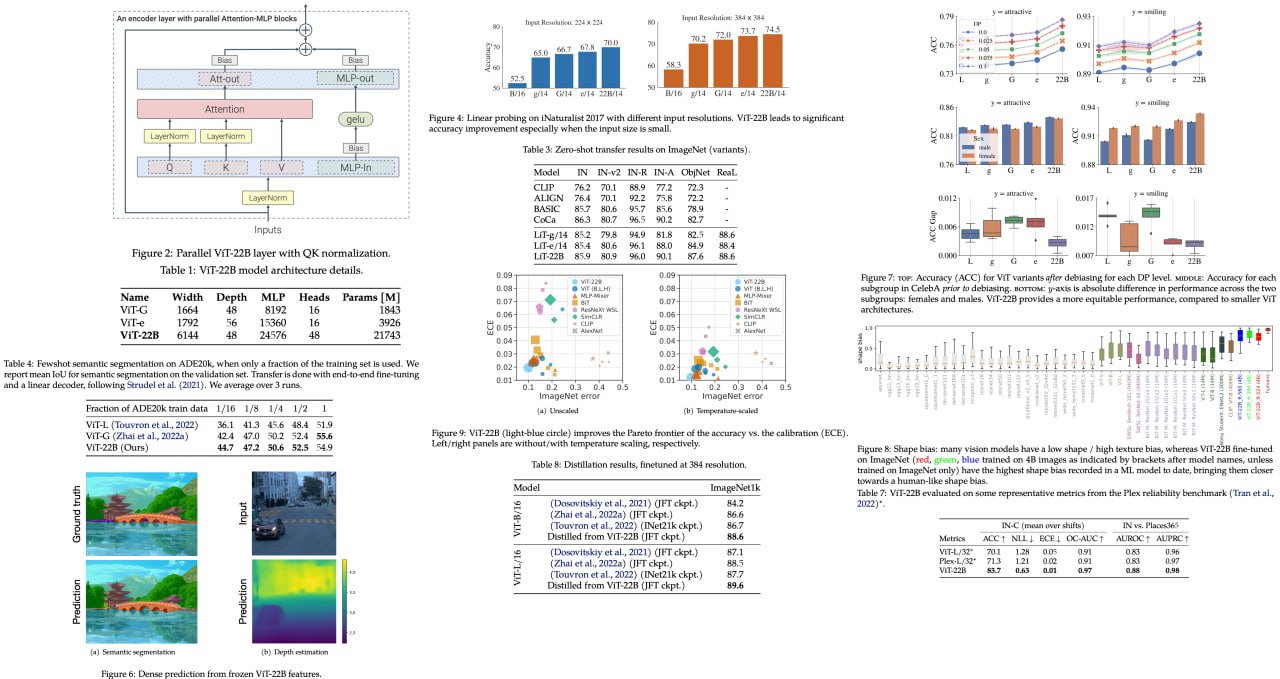
Scaling Vision Transformers to 22 Billion Parameters
Google Research authors present a recipe for training a highly efficient and stable Vision Transformer (ViT-22B) with 22B parameters, the largest dense ViT model to date. Experiments reveal that as the model's scale increases, its performance on downstream tasks improves. Additionally, ViT-22B shows an improved tradeoff between fairness and performance, state-of-the-art alignment with human visual perception in terms of shape/texture bias, and improved robustness. The authors suggest that ViT-22B demonstrates the potential for achieving “LLM-like” scaling in vision models and takes important steps toward that goal.
Paper: https://arxiv.org/abs/2302.05442
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-vit-22
#deeplearning #cv #transformer #sota
Google Research authors present a recipe for training a highly efficient and stable Vision Transformer (ViT-22B) with 22B parameters, the largest dense ViT model to date. Experiments reveal that as the model's scale increases, its performance on downstream tasks improves. Additionally, ViT-22B shows an improved tradeoff between fairness and performance, state-of-the-art alignment with human visual perception in terms of shape/texture bias, and improved robustness. The authors suggest that ViT-22B demonstrates the potential for achieving “LLM-like” scaling in vision models and takes important steps toward that goal.
Paper: https://arxiv.org/abs/2302.05442
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-vit-22
#deeplearning #cv #transformer #sota
{kind=link}
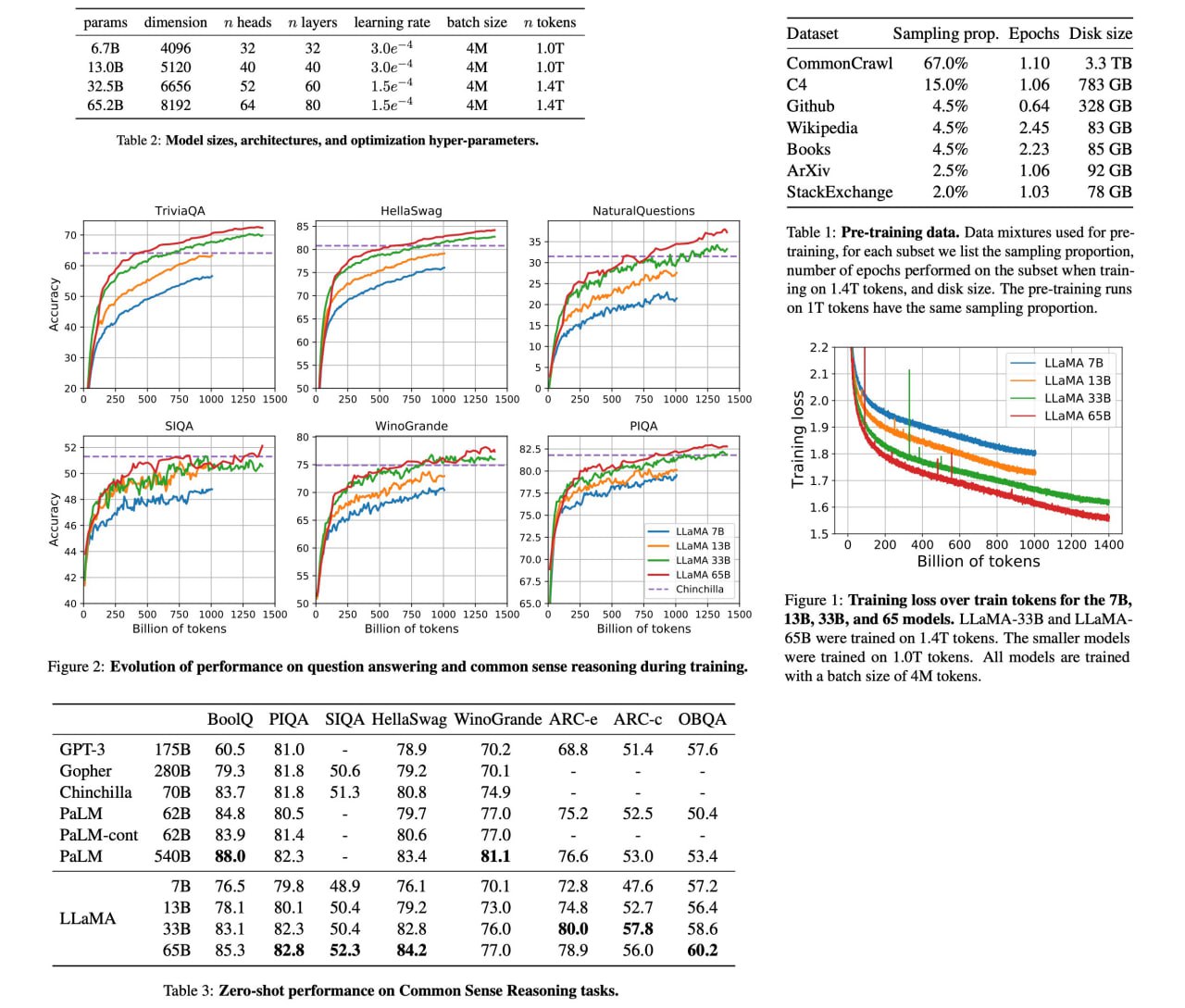
LLaMA: Open and Efficient Foundation Language Models
LLaMA is a set of large language models, ranging from 7B to 65B parameters, that have been trained on publicly available datasets containing trillions of tokens. The LLaMA-13B model performs better than GPT-3 (175B) on most benchmarks, and the LLaMA-65B model is competitive with other state-of-the-art models, such as Chinchilla70B and PaLM-540B. This suggests that it is possible to achieve excellent performance in language modeling without relying on proprietary or inaccessible datasets.
Paper: https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
Code: https://github.com/facebookresearch/llama
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-llama
#deeplearning #nlp #transformer #sota #languagemodel
LLaMA is a set of large language models, ranging from 7B to 65B parameters, that have been trained on publicly available datasets containing trillions of tokens. The LLaMA-13B model performs better than GPT-3 (175B) on most benchmarks, and the LLaMA-65B model is competitive with other state-of-the-art models, such as Chinchilla70B and PaLM-540B. This suggests that it is possible to achieve excellent performance in language modeling without relying on proprietary or inaccessible datasets.
Paper: https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
Code: https://github.com/facebookresearch/llama
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-llama
#deeplearning #nlp #transformer #sota #languagemodel
{kind=link}
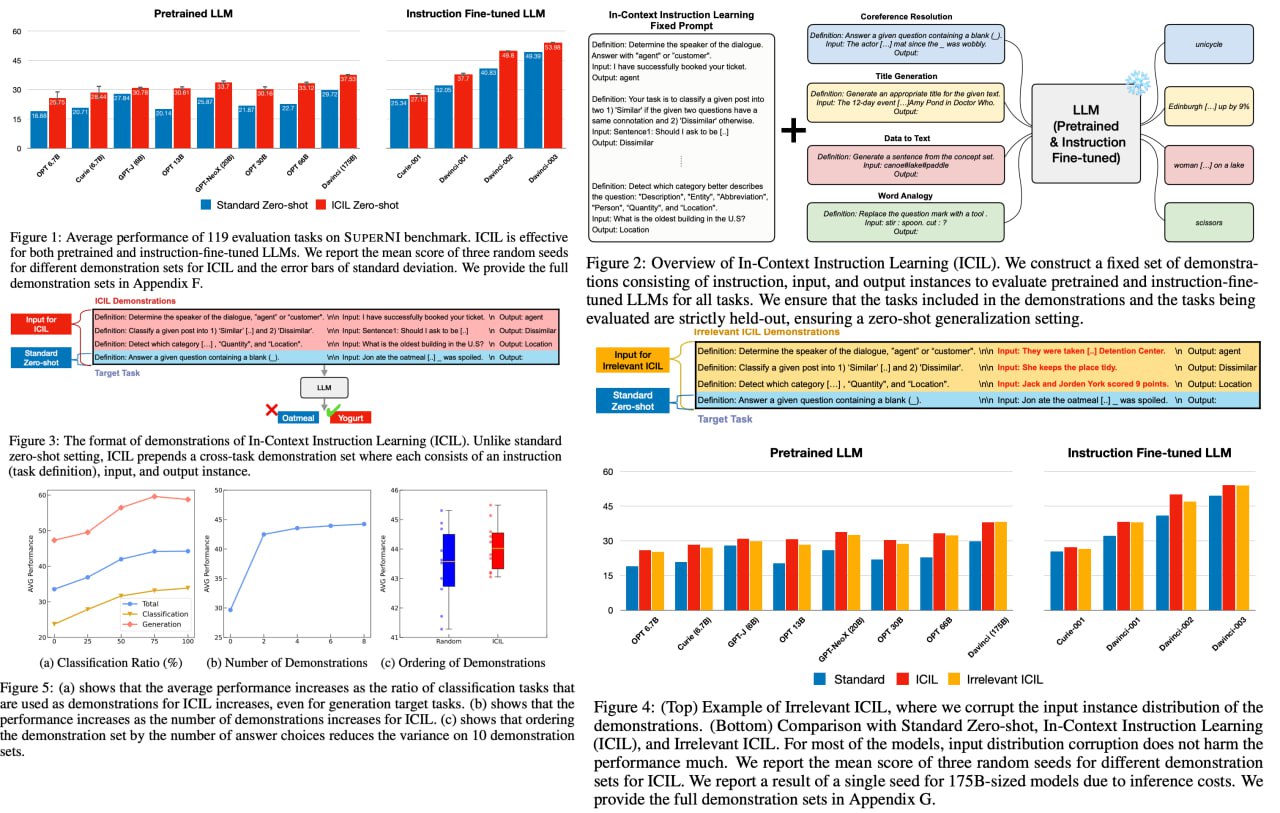
In-Context Instruction Learning
The authors introduce a novel approach called In-Context Instruction Learning (ICIL), which greatly enhances zero-shot task generalization performance for both pretrained and instruction-fine-tuned models. ICIL employs a single fixed prompt to evaluate all tasks, which is a concatenation of cross-task demonstrations. The authors demonstrate that even the most powerful instruction-fine-tuned baseline (text-davinci-003) benefits from ICIL by 9.3%, indicating that the effect of ICIL is complementary to instruction-based fine-tuning.
Paper: https://arxiv.org/abs/2302.14691
Code: https://github.com/seonghyeonye/ICIL
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-icil
#deeplearning #nlp #transformer #sota #languagemodel
The authors introduce a novel approach called In-Context Instruction Learning (ICIL), which greatly enhances zero-shot task generalization performance for both pretrained and instruction-fine-tuned models. ICIL employs a single fixed prompt to evaluate all tasks, which is a concatenation of cross-task demonstrations. The authors demonstrate that even the most powerful instruction-fine-tuned baseline (text-davinci-003) benefits from ICIL by 9.3%, indicating that the effect of ICIL is complementary to instruction-based fine-tuning.
Paper: https://arxiv.org/abs/2302.14691
Code: https://github.com/seonghyeonye/ICIL
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-icil
#deeplearning #nlp #transformer #sota #languagemodel
{kind=link}
PaLM-E: An Embodied Multimodal Language Model
In this paper, the authors introduce the concept of "embodied language models," which integrate real-world sensory information with language processing. This integration enables the models to perform tasks related to robotics and perception seamlessly.
To achieve this, the models are trained end-to-end using a large language model and multiple sensory inputs, including visual and textual information. These models can tackle complex tasks such as sequential robotic manipulation planning, visual question answering, and captioning. The results of evaluations demonstrate the effectiveness of this approach, including positive transfer across different domains.
The flagship model, PaLM-E-562B, is the crown jewel of this research. It excels in robotics tasks and delivers state-of-the-art performance on OK-VQA. Despite its specialization in robotics, this model maintains its generalist language capabilities.
Paper: https://arxiv.org/abs/2303.03378
Project link: https://palm-e.github.io/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-palme
#deeplearning #nlp #transformer #sota #languagemodel #robotics
In this paper, the authors introduce the concept of "embodied language models," which integrate real-world sensory information with language processing. This integration enables the models to perform tasks related to robotics and perception seamlessly.
To achieve this, the models are trained end-to-end using a large language model and multiple sensory inputs, including visual and textual information. These models can tackle complex tasks such as sequential robotic manipulation planning, visual question answering, and captioning. The results of evaluations demonstrate the effectiveness of this approach, including positive transfer across different domains.
The flagship model, PaLM-E-562B, is the crown jewel of this research. It excels in robotics tasks and delivers state-of-the-art performance on OK-VQA. Despite its specialization in robotics, this model maintains its generalist language capabilities.
Paper: https://arxiv.org/abs/2303.03378
Project link: https://palm-e.github.io/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-palme
#deeplearning #nlp #transformer #sota #languagemodel #robotics
{kind=link}
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
ChatGPT is a language interface with distinctive conversational competency and reasoning capabilities across many domains. However, it is currently unable to process or generate images from the visual world. To address this limitation, the authors propose a system called Visual ChatGPT that incorporates different Visual Foundation Models to enable users to interact with ChatGPT using both language and images. The system is capable of handling complex visual questions or instructions that require multiple AI models and steps. Additionally, it allows for feedback and corrections.
Rather than creating a new multimodal ChatGPT from scratch, the authors propose building Visual ChatGPT by incorporating various (22) Visual Foundation Models (VFMs) directly into ChatGPT. To facilitate the integration of these VFMs, the authors introduce a Prompt Manager that supports several functions. These include specifying the input-output formats of each VFM, converting visual information to language format, and managing the histories, priorities, and conflicts of different VFMs. With the Prompt Manager's help, ChatGPT can use these VFMs iteratively and receive their feedback until it satisfies the users' requirements or reaches the end condition.
Paper: https://arxiv.org/abs/2303.04671
Code link: https://github.com/microsoft/visual-chatgpt
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-palme
#deeplearning #nlp #transformer #sota #languagemodel #visual
ChatGPT is a language interface with distinctive conversational competency and reasoning capabilities across many domains. However, it is currently unable to process or generate images from the visual world. To address this limitation, the authors propose a system called Visual ChatGPT that incorporates different Visual Foundation Models to enable users to interact with ChatGPT using both language and images. The system is capable of handling complex visual questions or instructions that require multiple AI models and steps. Additionally, it allows for feedback and corrections.
Rather than creating a new multimodal ChatGPT from scratch, the authors propose building Visual ChatGPT by incorporating various (22) Visual Foundation Models (VFMs) directly into ChatGPT. To facilitate the integration of these VFMs, the authors introduce a Prompt Manager that supports several functions. These include specifying the input-output formats of each VFM, converting visual information to language format, and managing the histories, priorities, and conflicts of different VFMs. With the Prompt Manager's help, ChatGPT can use these VFMs iteratively and receive their feedback until it satisfies the users' requirements or reaches the end condition.
Paper: https://arxiv.org/abs/2303.04671
Code link: https://github.com/microsoft/visual-chatgpt
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-palme
#deeplearning #nlp #transformer #sota #languagemodel #visual
{kind=link}
BloombergGPT: A Large Language Model for Finance
The realm of financial technology involves a wide range of NLP applications, such as sentiment analysis, named entity recognition, and question answering. Although Large Language Models (LLMs) have demonstrated effectiveness in various tasks, no LLM specialized for the financial domain has been reported so far. This work introduces BloombergGPT, a 50-billion-parameter language model trained on an extensive range of financial data. The researchers have created a massive 363-billion-token dataset using Bloomberg's data sources, supplemented with 345 billion tokens from general-purpose datasets, potentially creating the largest domain-specific dataset to date.
BloombergGPT has been validated on standard LLM benchmarks, open financial benchmarks, and a suite of internal benchmarks that accurately reflect its intended usage. The mixed dataset training results in a model that significantly outperforms existing models on financial tasks without sacrificing performance on general LLM benchmarks. The paper also discusses modeling choices, training processes, and evaluation methodology. As a next step, the researchers plan to release training logs (Chronicles) detailing their experience in training BloombergGPT.
Paper: https://arxiv.org/abs/2303.17564
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-bloomberggpt
#deeplearning #nlp #transformer #sota #languagemodel #finance
The realm of financial technology involves a wide range of NLP applications, such as sentiment analysis, named entity recognition, and question answering. Although Large Language Models (LLMs) have demonstrated effectiveness in various tasks, no LLM specialized for the financial domain has been reported so far. This work introduces BloombergGPT, a 50-billion-parameter language model trained on an extensive range of financial data. The researchers have created a massive 363-billion-token dataset using Bloomberg's data sources, supplemented with 345 billion tokens from general-purpose datasets, potentially creating the largest domain-specific dataset to date.
BloombergGPT has been validated on standard LLM benchmarks, open financial benchmarks, and a suite of internal benchmarks that accurately reflect its intended usage. The mixed dataset training results in a model that significantly outperforms existing models on financial tasks without sacrificing performance on general LLM benchmarks. The paper also discusses modeling choices, training processes, and evaluation methodology. As a next step, the researchers plan to release training logs (Chronicles) detailing their experience in training BloombergGPT.
Paper: https://arxiv.org/abs/2303.17564
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-bloomberggpt
#deeplearning #nlp #transformer #sota #languagemodel #finance
{kind=link}
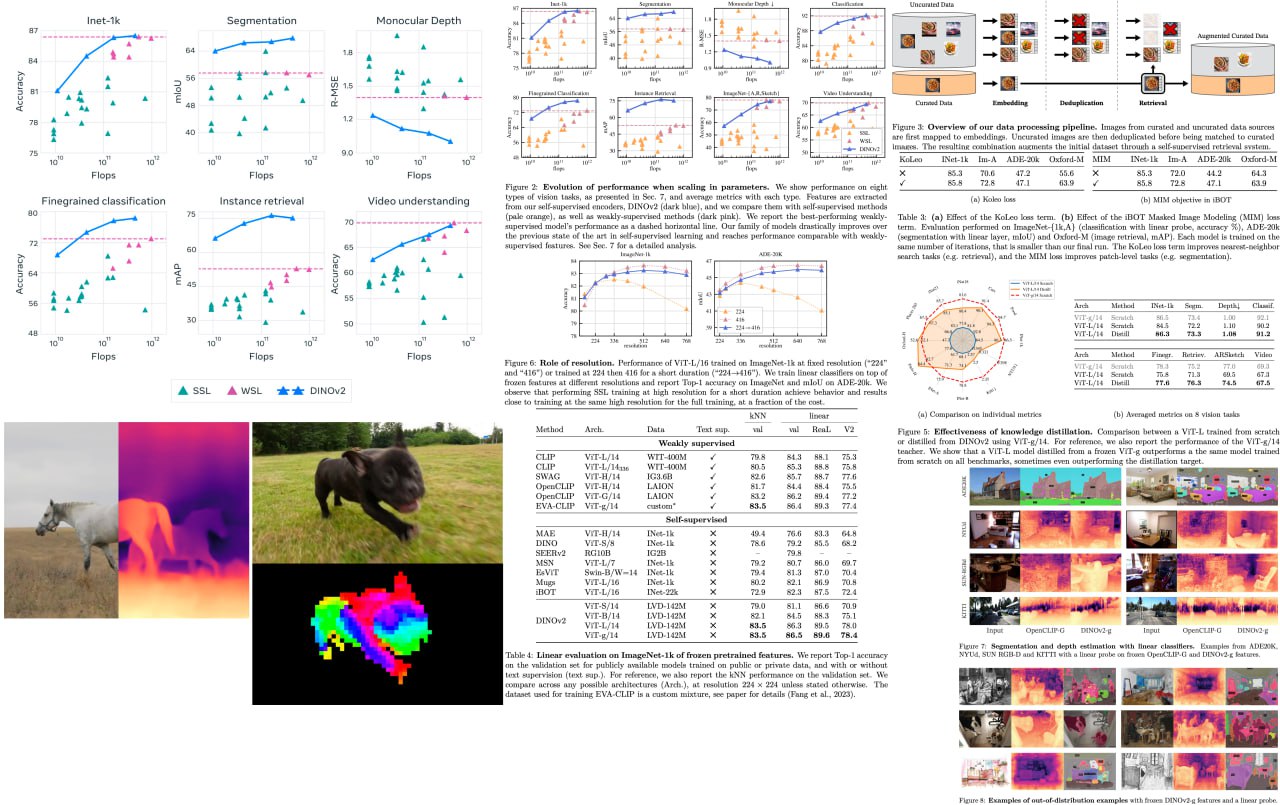
DINOv2: Learning Robust Visual Features without Supervision
Get ready for a game-changer in computer vision! Building on the groundbreaking achievements in natural language processing, foundation models are revolutionizing the way we use images in various systems. By generating all-purpose visual features that excel across diverse image distributions and tasks without finetuning, these models are set to redefine the field.
The researchers behind this work have combined cutting-edge techniques to scale pretraining in terms of data and model size, turbocharging the training process like never before. They've devised an ingenious automatic pipeline to create a rich, diverse, and curated image dataset, setting a new standard in the self-supervised literature. To top it off, they've trained a colossal ViT model with a staggering 1 billion parameters and distilled it into a series of smaller, ultra-efficient models. These models outshine the best available all-purpose features, OpenCLIP, on most benchmarks at both image and pixel levels.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dinov2
Project link: https://dinov2.metademolab.com/
#deeplearning #cv #pytorch #imagesegmentation #sota #pretraining
Get ready for a game-changer in computer vision! Building on the groundbreaking achievements in natural language processing, foundation models are revolutionizing the way we use images in various systems. By generating all-purpose visual features that excel across diverse image distributions and tasks without finetuning, these models are set to redefine the field.
The researchers behind this work have combined cutting-edge techniques to scale pretraining in terms of data and model size, turbocharging the training process like never before. They've devised an ingenious automatic pipeline to create a rich, diverse, and curated image dataset, setting a new standard in the self-supervised literature. To top it off, they've trained a colossal ViT model with a staggering 1 billion parameters and distilled it into a series of smaller, ultra-efficient models. These models outshine the best available all-purpose features, OpenCLIP, on most benchmarks at both image and pixel levels.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dinov2
Project link: https://dinov2.metademolab.com/
#deeplearning #cv #pytorch #imagesegmentation #sota #pretraining
{kind=link}