
Episodic Memory in Lifelong Language Learning
tl;dr – the model needs to learn from a stream of text examples without any dataset identifier.
The authors propose an episodic memory model that performs sparse experience replay and local adaptation to mitigate catastrophic forgetting in this setup. Experiments on text classification and question answering demonstrate the complementary benefits of sparse experience replay & local adaptation to allow the model to continuously learn from new datasets.
Also, they show that the space complexity of the episodic memory module can be reduced significantly (∼50-90%) by randomly choosing which examples to store in memory with a minimal decrease in performance. They consider an episodic memory component as a crucial building block of general linguistic intelligence and see the model as the first step in that direction.
paper: https://arxiv.org/abs/1906.01076
#nlp #bert #NeurIPSConf19
tl;dr – the model needs to learn from a stream of text examples without any dataset identifier.
The authors propose an episodic memory model that performs sparse experience replay and local adaptation to mitigate catastrophic forgetting in this setup. Experiments on text classification and question answering demonstrate the complementary benefits of sparse experience replay & local adaptation to allow the model to continuously learn from new datasets.
Also, they show that the space complexity of the episodic memory module can be reduced significantly (∼50-90%) by randomly choosing which examples to store in memory with a minimal decrease in performance. They consider an episodic memory component as a crucial building block of general linguistic intelligence and see the model as the first step in that direction.
paper: https://arxiv.org/abs/1906.01076
#nlp #bert #NeurIPSConf19
{kind=link}
Cross-Lingual Ability of Multilingual BERT: An Empirical Study to #ICLR2020
In this work, the authors provide a comprehensive study of the contribution of different components in multilingual #BERT (M-BERT) to its cross-lingual ability.
They study the impact of linguistic properties of the languages, the architecture of the model, and the learning objectives. The experimental study is done in the context of three typologically different languages – #Spanish, #Hindi, & #Russian – & using two conceptually different #NLP tasks, textual entailment & #NER.
Also, they construct a new corpus – Fake-English (#enfake), by shifting the Unicode of each character in English Wikipedia text by a large constant so that there is strictly no character overlap with any other Wikipedia text.
And, in this work, they consider Fake-English as a different language.
Among their key conclusions are the fact that the lexical overlap between languages plays a negligible role in the cross-lingual success, while the depth of the network is an integral part of it.
paper: https://arxiv.org/abs/1912.07840
In this work, the authors provide a comprehensive study of the contribution of different components in multilingual #BERT (M-BERT) to its cross-lingual ability.
They study the impact of linguistic properties of the languages, the architecture of the model, and the learning objectives. The experimental study is done in the context of three typologically different languages – #Spanish, #Hindi, & #Russian – & using two conceptually different #NLP tasks, textual entailment & #NER.
Also, they construct a new corpus – Fake-English (#enfake), by shifting the Unicode of each character in English Wikipedia text by a large constant so that there is strictly no character overlap with any other Wikipedia text.
And, in this work, they consider Fake-English as a different language.
Among their key conclusions are the fact that the lexical overlap between languages plays a negligible role in the cross-lingual success, while the depth of the network is an integral part of it.
paper: https://arxiv.org/abs/1912.07840
{kind=link}
Revealing the Dark Secrets of BERT
tl;dr:
* BERT is heavily over parametrized
* BERT does not need to be all that smart
* BERT’s success is due to ~black magic~ something other than self-attention
This work focuses on the complementary question: what happens in the fine-tuned #BERT? In particular, how much of the linguistically interpretable self-attention patterns that are presumed to be its strength are actually used to solve downstream tasks?
Using a subset of #GLUE tasks and a set of handcrafted features-of-interest, they propose the methodology and carry out a qualitative and quantitative analysis of the information encoded by the individual BERT’s heads.
Also, they show that manually disabling attention in certain heads leads to performance improvement over the regular fine-tuned BERT models.
paper: https://www.aclweb.org/anthology/D19-1445.pdf
blog post: https://text-machine-lab.github.io/blog/2020/bert-secrets/
tl;dr:
* BERT is heavily over parametrized
* BERT does not need to be all that smart
* BERT’s success is due to ~black magic~ something other than self-attention
This work focuses on the complementary question: what happens in the fine-tuned #BERT? In particular, how much of the linguistically interpretable self-attention patterns that are presumed to be its strength are actually used to solve downstream tasks?
Using a subset of #GLUE tasks and a set of handcrafted features-of-interest, they propose the methodology and carry out a qualitative and quantitative analysis of the information encoded by the individual BERT’s heads.
Also, they show that manually disabling attention in certain heads leads to performance improvement over the regular fine-tuned BERT models.
paper: https://www.aclweb.org/anthology/D19-1445.pdf
blog post: https://text-machine-lab.github.io/blog/2020/bert-secrets/
{kind=link}
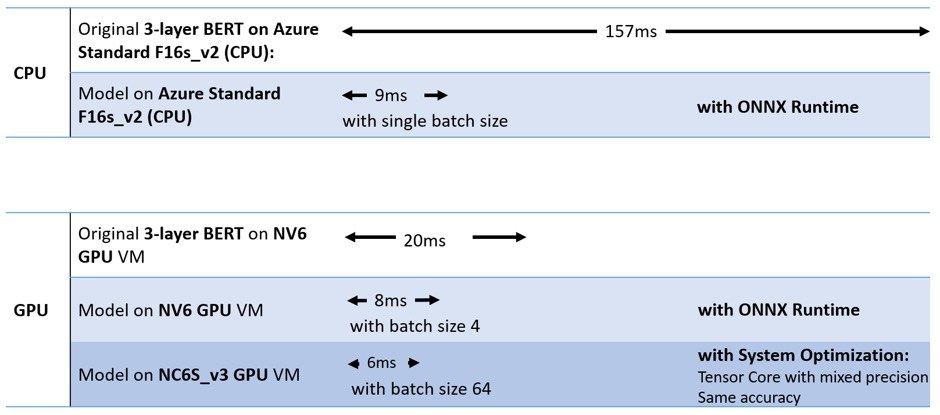
Microsoft open sources breakthrough optimizations for transformer inference on GPU and CPU
How?
#Transformer models like #BERT consist of a graph of many operators. Graph optimization, ranging from small graph simplifications and node eliminations to more complex node fusions and layout optimizations, is an essential technique built into #ONNX Runtime.
Since the BERT model is mainly composed of stacked transformer cells, we optimize each cell by fusing key sub-graphs of multiple elementary operators into single kernels for both CPU and GPU, including Self-Attention, LayerNormalization, and Gelu layers. This significantly reduces memory copy between numerous elementary computations.
Additionally, in the CPU implementation of Self-Attention, the columns of matrix Q, K, and V are partitioned based on the number of self-attention heads. With this optimization, we can significantly increase the parallelization and fully leverage available CPU cores. Moreover, the transpose op following the full connection of Q, K, and V can be computed within GEMM, which further reduces the computation cost.
blog post: https://cloudblogs.microsoft.com/opensource/2020/01/21/microsoft-onnx-open-source-optimizations-transformer-inference-gpu-cpu/
How?
#Transformer models like #BERT consist of a graph of many operators. Graph optimization, ranging from small graph simplifications and node eliminations to more complex node fusions and layout optimizations, is an essential technique built into #ONNX Runtime.
Since the BERT model is mainly composed of stacked transformer cells, we optimize each cell by fusing key sub-graphs of multiple elementary operators into single kernels for both CPU and GPU, including Self-Attention, LayerNormalization, and Gelu layers. This significantly reduces memory copy between numerous elementary computations.
Additionally, in the CPU implementation of Self-Attention, the columns of matrix Q, K, and V are partitioned based on the number of self-attention heads. With this optimization, we can significantly increase the parallelization and fully leverage available CPU cores. Moreover, the transpose op following the full connection of Q, K, and V can be computed within GEMM, which further reduces the computation cost.
blog post: https://cloudblogs.microsoft.com/opensource/2020/01/21/microsoft-onnx-open-source-optimizations-transformer-inference-gpu-cpu/
{kind=link}
A new approach for NER on partially labeled datasets.
One of the common problems with NER modeling is the lack of datasets covering all required slot types. Often there are several datasets that have labels for different entities.
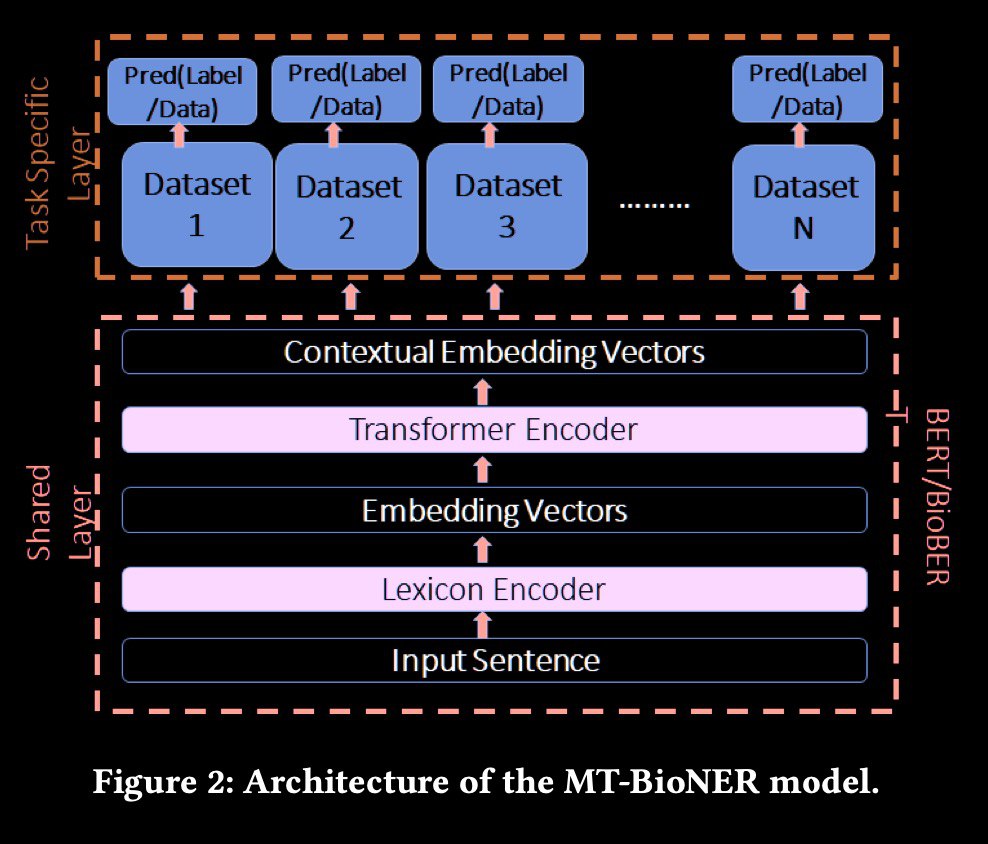
The key idea of the paper is using multi-task transformer-based architecture on multiple datasets.
The model architecture looks like this:
- lexicon encoder layer (input is tokens with words, position and segment embeddings);
- transformer encoder, which generates the shared contextual embedding vectors;
- separate heads for each dataset.
During the training phase, it is necessary to not only train the task-dependent layers but also to fine-tune the shared language model.
Experiments were conducted on four datasets using a single Tesla K80. A single multi-task model (iterating over datasets) shows SOTA results and trains faster than separate models for each task.
Paper: https://arxiv.org/abs/2001.08904
#nlp #bert #ner #biomedical
MT-BioNER: Multi-task Learning for Biomedical Named EntityRecognition using Deep Bidirectional TransformersA new approach for NER on partially labeled datasets.
One of the common problems with NER modeling is the lack of datasets covering all required slot types. Often there are several datasets that have labels for different entities.
The key idea of the paper is using multi-task transformer-based architecture on multiple datasets.
The model architecture looks like this:
- lexicon encoder layer (input is tokens with words, position and segment embeddings);
- transformer encoder, which generates the shared contextual embedding vectors;
- separate heads for each dataset.
During the training phase, it is necessary to not only train the task-dependent layers but also to fine-tune the shared language model.
Experiments were conducted on four datasets using a single Tesla K80. A single multi-task model (iterating over datasets) shows SOTA results and trains faster than separate models for each task.
Paper: https://arxiv.org/abs/2001.08904
#nlp #bert #ner #biomedical
{kind=link}
BERT-of-Theseus: Compressing BERT by Progressive Module Replacing
tl;dr
with a huggingface – compatible weights
take original BERT, replace some of his layers with new (smaller) ones randomly during the distillation. the probability of replacing the module will increase over time, resulting in a small model at the end.
them approach leverages only one loss function and one hyper-parameter, liberating human effort from hyper-parameter tuning.
also, they outperform existing knowledge distillation approaches on GLUE benchmark, showing a new perspective of model compression
paper: https://arxiv.org/abs/2002.02925
github: https://github.com/JetRunner/BERT-of-Theseus
#nlp #compressing #knowledge #distillation #bert
tl;dr
[ONE loss] + [ONE hyperparameter] + [NO external data] = GREAT PERFORMANCEwith a huggingface – compatible weights
take original BERT, replace some of his layers with new (smaller) ones randomly during the distillation. the probability of replacing the module will increase over time, resulting in a small model at the end.
them approach leverages only one loss function and one hyper-parameter, liberating human effort from hyper-parameter tuning.
also, they outperform existing knowledge distillation approaches on GLUE benchmark, showing a new perspective of model compression
paper: https://arxiv.org/abs/2002.02925
github: https://github.com/JetRunner/BERT-of-Theseus
#nlp #compressing #knowledge #distillation #bert
{kind=link}
Optimus: Organizing Sentences via Pre-trained Modeling of a Latent Space
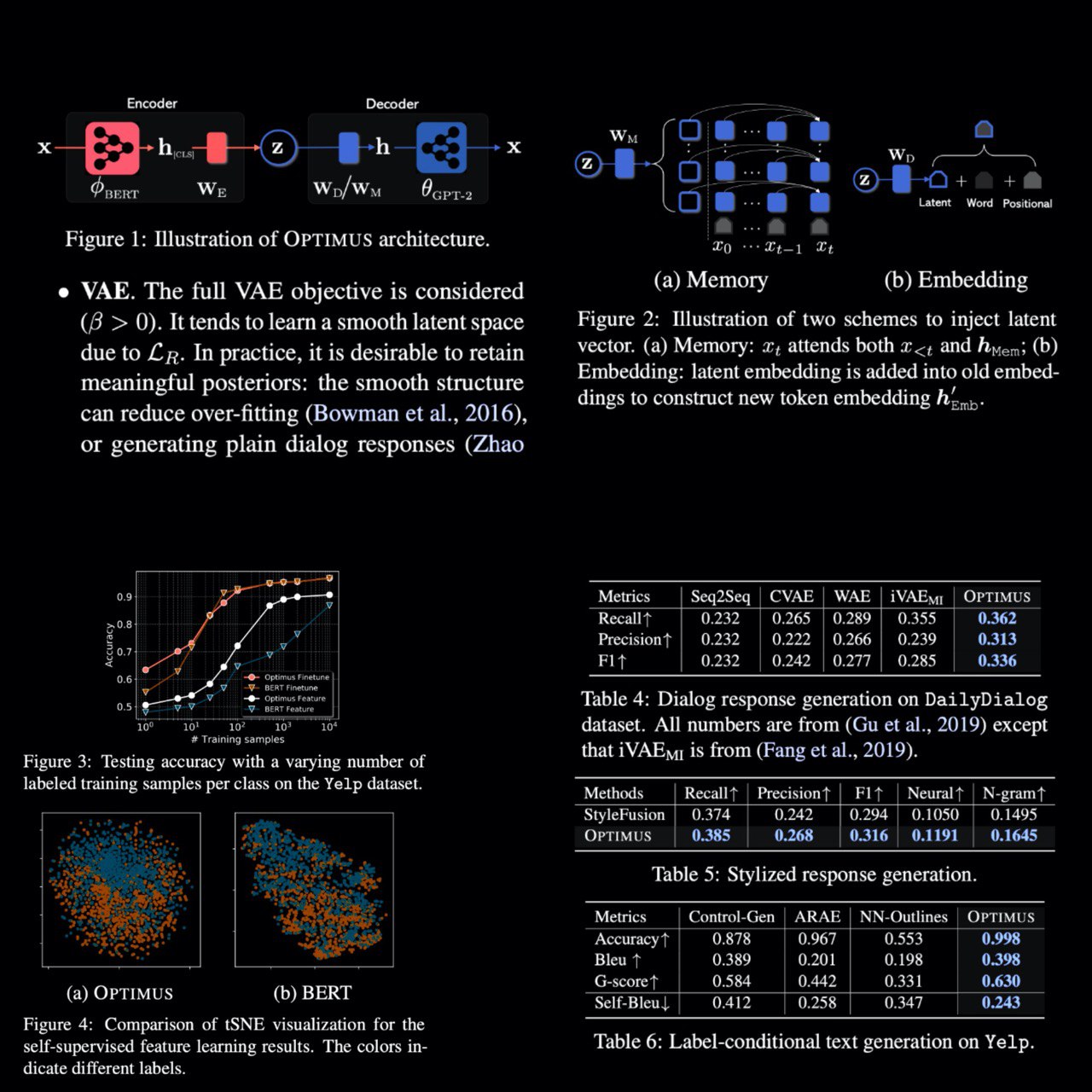
The authors propose the first large-scale language VAE model – Optimus.
This new model uses BERT weights in the encoder and GPT-2 weights in the decoder. Thanks to this Optimus supports NLU and text generation tasks. Learned language representation is more universal, which means that it is easier to fine-tune this model to a new domain/task. Also, Optimus can control high-level semantics in text generation (tense, topic, sentiment).
There are several novel contributions, which are made thanks to this work:
– latent vector injection: two schemes are suggested to inject conditioning vectors into GPT-2 without retraining it;
– the idea to combine BERT and GPT-2 could inspire people to integrate existing language models into larger and ever more complex models;
– pre-training on a big corpora is an effective approach to reduce KL vanishing;
– VAE is a good approach to balance the compactness and usability of learned representations;
– pre-training latent space improves performance on several language tasks;
Experimental results on a wide range of tasks and datasets have demonstrated the strong performance of OPTIMUS, including new state-of-the-art for language VAEs.
Paper: https://arxiv.org/abs/2004.04092v1
Github: https://github.com/ChunyuanLI/Optimus
#deeplearning #nlp #nlu #transformer #vae #bert #gpt2
The authors propose the first large-scale language VAE model – Optimus.
This new model uses BERT weights in the encoder and GPT-2 weights in the decoder. Thanks to this Optimus supports NLU and text generation tasks. Learned language representation is more universal, which means that it is easier to fine-tune this model to a new domain/task. Also, Optimus can control high-level semantics in text generation (tense, topic, sentiment).
There are several novel contributions, which are made thanks to this work:
– latent vector injection: two schemes are suggested to inject conditioning vectors into GPT-2 without retraining it;
– the idea to combine BERT and GPT-2 could inspire people to integrate existing language models into larger and ever more complex models;
– pre-training on a big corpora is an effective approach to reduce KL vanishing;
– VAE is a good approach to balance the compactness and usability of learned representations;
– pre-training latent space improves performance on several language tasks;
Experimental results on a wide range of tasks and datasets have demonstrated the strong performance of OPTIMUS, including new state-of-the-art for language VAEs.
Paper: https://arxiv.org/abs/2004.04092v1
Github: https://github.com/ChunyuanLI/Optimus
#deeplearning #nlp #nlu #transformer #vae #bert #gpt2
{kind=link}
Transformer Reasoning Network for Image-Text Matching and Retrieval
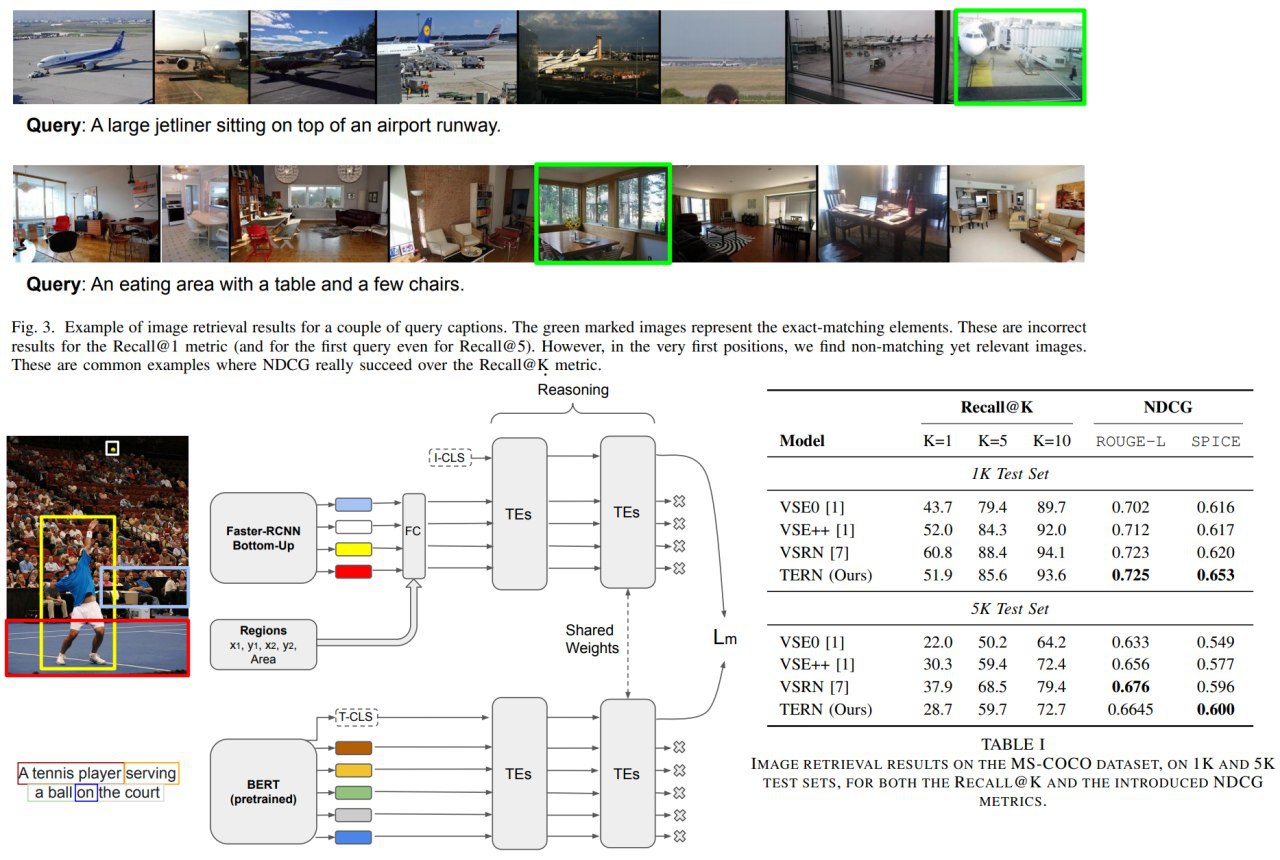
A new approach for image-text matching using Faster-RCNN Bottom-Up and BERT.
Usually, downstream applications use the ResNet or one of its variants as the backbone CNN. Its simple and modular design can be easily adapted to various tasks. However, since ResNet models are originally designed for image classification, they may not be suitable for various downstream applications because of the limited receptive-field size and lack of cross-channel interaction.
Authors suggest an architecture, where images and texts are processed at first, and then their representations are combined.
Main contributions of the paper:
- TERN Architecture
- NDCG metric in addition to Recall@K
- show SOTA result on the benchmark
Paper: https://arxiv.org/abs/2004.09144
Code: https://github.com/mesnico/TERN
#computervision #deeplearning #bert #imagetextmatching
A new approach for image-text matching using Faster-RCNN Bottom-Up and BERT.
Usually, downstream applications use the ResNet or one of its variants as the backbone CNN. Its simple and modular design can be easily adapted to various tasks. However, since ResNet models are originally designed for image classification, they may not be suitable for various downstream applications because of the limited receptive-field size and lack of cross-channel interaction.
Authors suggest an architecture, where images and texts are processed at first, and then their representations are combined.
Main contributions of the paper:
- TERN Architecture
- NDCG metric in addition to Recall@K
- show SOTA result on the benchmark
Paper: https://arxiv.org/abs/2004.09144
Code: https://github.com/mesnico/TERN
#computervision #deeplearning #bert #imagetextmatching
{kind=link}
SpERT: Span-based Joint Entity and Relation Extraction with Transformer Pre-training
Authors introduce SpERT, an attention model for span-based joint entity and relation extraction.
This work investigates the use of Transformer networks for relation extraction: given a pre-defined set of target relations and a sentence such as “Leonardo DiCaprio starred in Christopher Nolan’s thriller Inception”, the goal is to extract triplets such as (“Leonardo DiCaprio”, Plays-In, “Inception”) or (“Inception”, Director, “Christopher Nolan”).
The main contributions of the paper are:
– a novel approach towards span-based joint entity and relation extraction
– ablation study showing that negative samples from the same sentence yield efficient training, a localized context representation is beneficial, finetuning a pre-trained model yields a strong performance increase over training from scratch.
This approach improves the SOTA score on CoNLL04 dataset by 2.6% (micro) F1.
Paper: https://arxiv.org/abs/1909.07755
Code: https://github.com/markus-eberts/spert
#nlp #deeplearning #transformer #bert #ner #relationextraction
Authors introduce SpERT, an attention model for span-based joint entity and relation extraction.
This work investigates the use of Transformer networks for relation extraction: given a pre-defined set of target relations and a sentence such as “Leonardo DiCaprio starred in Christopher Nolan’s thriller Inception”, the goal is to extract triplets such as (“Leonardo DiCaprio”, Plays-In, “Inception”) or (“Inception”, Director, “Christopher Nolan”).
The main contributions of the paper are:
– a novel approach towards span-based joint entity and relation extraction
– ablation study showing that negative samples from the same sentence yield efficient training, a localized context representation is beneficial, finetuning a pre-trained model yields a strong performance increase over training from scratch.
This approach improves the SOTA score on CoNLL04 dataset by 2.6% (micro) F1.
Paper: https://arxiv.org/abs/1909.07755
Code: https://github.com/markus-eberts/spert
#nlp #deeplearning #transformer #bert #ner #relationextraction
{kind=link}
🦜 Hi!
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
GitHub
ultimate_posts/where_to_start at master · open-data-science/ultimate_posts
Ultimate posts for opendatascience telegram channel - open-data-science/ultimate_posts
Scaling Transformer to 1M tokens and beyond with RMT
Imagine extending the context length of BERT, one of the most effective Transformer-based models in natural language processing, to an unprecedented two million tokens! This technical report unveils the Recurrent Memory Transformer (RMT) architecture, which achieves this incredible feat while maintaining high memory retrieval accuracy.
The RMT approach enables storage and processing of both local and global information, allowing information flow between segments of the input sequence through recurrence. The experiments showcase the effectiveness of this groundbreaking method, with immense potential to enhance long-term dependency handling in natural language understanding and generation tasks, as well as enable large-scale context processing for memory-intensive applications.
Paper link: https://arxiv.org/abs/2304.11062
Code link: https://github.com/booydar/t5-experiments/tree/scaling-report
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-rmt-1m
#deeplearning #nlp #bert #memory
Imagine extending the context length of BERT, one of the most effective Transformer-based models in natural language processing, to an unprecedented two million tokens! This technical report unveils the Recurrent Memory Transformer (RMT) architecture, which achieves this incredible feat while maintaining high memory retrieval accuracy.
The RMT approach enables storage and processing of both local and global information, allowing information flow between segments of the input sequence through recurrence. The experiments showcase the effectiveness of this groundbreaking method, with immense potential to enhance long-term dependency handling in natural language understanding and generation tasks, as well as enable large-scale context processing for memory-intensive applications.
Paper link: https://arxiv.org/abs/2304.11062
Code link: https://github.com/booydar/t5-experiments/tree/scaling-report
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-rmt-1m
#deeplearning #nlp #bert #memory
{kind=link}