
👩🎓Online lectures on Special Topics in AI: Deep Learning
Fresh free and open playlist on special topics in #DL from University of Wisconsin-Madison. Topics covering reliable deep learning, generalization, learning with less supervision, lifelong learning, deep generative models and more.
Overview Lecture: https://www.youtube.com/watch?v=6LSErxKe634&list=PLKvO2FVLnI9SYLe1umkXsOfIWmEez04Ii
YouTube Playlist: https://www.youtube.com/playlist?list=PLKvO2FVLnI9SYLe1umkXsOfIWmEez04Ii
Syllabus: http://pages.cs.wisc.edu/~sharonli/courses/cs839_fall2020/schedule.html
#wheretostart #lectures #YouTube
Fresh free and open playlist on special topics in #DL from University of Wisconsin-Madison. Topics covering reliable deep learning, generalization, learning with less supervision, lifelong learning, deep generative models and more.
Overview Lecture: https://www.youtube.com/watch?v=6LSErxKe634&list=PLKvO2FVLnI9SYLe1umkXsOfIWmEez04Ii
YouTube Playlist: https://www.youtube.com/playlist?list=PLKvO2FVLnI9SYLe1umkXsOfIWmEez04Ii
Syllabus: http://pages.cs.wisc.edu/~sharonli/courses/cs839_fall2020/schedule.html
#wheretostart #lectures #YouTube
YouTube
CS839 Special Topics in Deep Learning: Course Overview (Lecture 1)
MPG: A Multi-ingredient Pizza Image Generator with Conditional StyleGANs
Work on conditional image generation
ArXiV: https://arxiv.org/abs/2012.02821
#GAN #DL #food2vec
Work on conditional image generation
ArXiV: https://arxiv.org/abs/2012.02821
#GAN #DL #food2vec
{kind=link}
Data Science by ODS.ai 🦜
Tool for restoration of pixelated images Tool uses De Bruijn sequence to restore the original information Github: https://github.com/beurtschipper/Depix #pixelization #github
Bayesian Image Reconstruction using Deep Generative Models
Really impressive results reported, but there is no code yet.
ArXiV: https://arxiv.org/abs/2012.04567
#DL #BayesianLearning #Reconstruction
Really impressive results reported, but there is no code yet.
ArXiV: https://arxiv.org/abs/2012.04567
#DL #BayesianLearning #Reconstruction
🔥New breakthrough on text2image generation by #OpenAI
DALL·E: Creating Images from Text
This architecture is capable of understanding style descriptions as well as complex relationship between objects in context.
That opens whole new perspective for digital agencies, potentially threatening stock photo sites and new opportunies for regulations and lawers to work on.
Interesting times!
Website: https://openai.com/blog/dall-e/
#GAN #GPT3 #openai #dalle #DL
DALL·E: Creating Images from Text
This architecture is capable of understanding style descriptions as well as complex relationship between objects in context.
That opens whole new perspective for digital agencies, potentially threatening stock photo sites and new opportunies for regulations and lawers to work on.
Interesting times!
Website: https://openai.com/blog/dall-e/
#GAN #GPT3 #openai #dalle #DL
{kind=link}
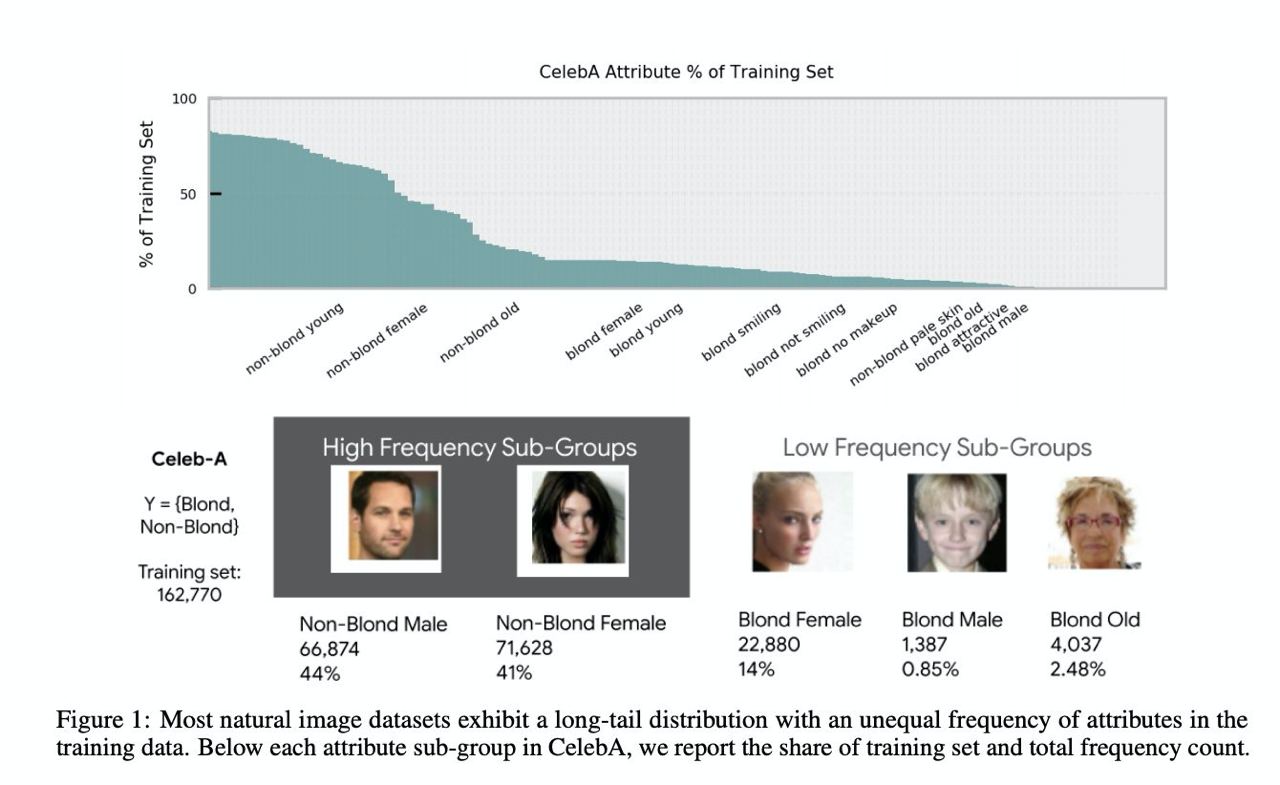
Characterising Bias in Compressed Models
Popular compression techniques turned out to amplify bias in deep neural networks.
ArXiV: https://arxiv.org/abs/2010.03058
#NN #DL #bias
Popular compression techniques turned out to amplify bias in deep neural networks.
ArXiV: https://arxiv.org/abs/2010.03058
#NN #DL #bias
{kind=link}
Towards Causal Representation Learning
Work on how neural networks derive casual variables from low-level observations.
Link: https://arxiv.org/abs/2102.11107
#casuallearning #bengio #nn #DL
Work on how neural networks derive casual variables from low-level observations.
Link: https://arxiv.org/abs/2102.11107
#casuallearning #bengio #nn #DL
SEER: The start of a more powerful, flexible, and accessible era for computer vision
#SEER stands for SElf-supERvised architecture which follows the vision of Yan LeCunn that real breakthrough in quality of models is possible only with #selfsupervised learning.
And here it is — model which was trained using some enormous amount of data achieves 84.2 percent top-1 accuracy on ImageNet.
Paramus: 1.3B
Dataset: 1B random images
Hardware: 512 GPUs (unspecified)
Blogpost: https://ai.facebook.com/blog/seer-the-start-of-a-more-powerful-flexible-and-accessible-era-for-computer-vision
ArXiV: https://arxiv.org/pdf/2103.01988.pdf
#facebook #fair #cv #dl
#SEER stands for SElf-supERvised architecture which follows the vision of Yan LeCunn that real breakthrough in quality of models is possible only with #selfsupervised learning.
And here it is — model which was trained using some enormous amount of data achieves 84.2 percent top-1 accuracy on ImageNet.
Paramus: 1.3B
Dataset: 1B random images
Hardware: 512 GPUs (unspecified)
Blogpost: https://ai.facebook.com/blog/seer-the-start-of-a-more-powerful-flexible-and-accessible-era-for-computer-vision
ArXiV: https://arxiv.org/pdf/2103.01988.pdf
#facebook #fair #cv #dl
Meta
SEER: The start of a more powerful, flexible, and accessible era for computer vision
The future of AI is in creating systems that can learn directly from whatever information they’re given — whether it’s text, images, or another type of data — without relying on carefully curated and labeled data sets to teach them how to recognize objects…
🏥Self-supervised Learning for Medical images
Due to standard imaging procedures, medical images (X-ray, CT scans, etc) are usually well aligned.
This paper gives an opportunity to utilize such an alignment to automatically connect similar pairs of images for training.
GitHub: https://github.com/fhaghighi/TransVW
ArXiV: https://arxiv.org/abs/2102.10680
#biolearning #medical #dl #pytorch #keras
Due to standard imaging procedures, medical images (X-ray, CT scans, etc) are usually well aligned.
This paper gives an opportunity to utilize such an alignment to automatically connect similar pairs of images for training.
GitHub: https://github.com/fhaghighi/TransVW
ArXiV: https://arxiv.org/abs/2102.10680
#biolearning #medical #dl #pytorch #keras
GitHub
GitHub - fhaghighi/TransVW: Official Keras & PyTorch Implementation and Pre-trained Models for TransVW
Official Keras & PyTorch Implementation and Pre-trained Models for TransVW - fhaghighi/TransVW
GAN Prior Embedded Network for Blind Face Restoration in the Wild
New proposed method allowed authors to improve the quality of old photoes
ArXiV: https://arxiv.org/abs/2105.06070
Github: https://github.com/yangxy/GPEN
#GAN #GPEN #blind_face_restoration #CV #DL
New proposed method allowed authors to improve the quality of old photoes
ArXiV: https://arxiv.org/abs/2105.06070
Github: https://github.com/yangxy/GPEN
#GAN #GPEN #blind_face_restoration #CV #DL
Color2Style: Real-Time Exemplar-Based Image Colorization with Self-Reference Learning and Deep Feature Modulation
ArXiV: https://arxiv.org/pdf/2106.08017.pdf
#colorization #dl
ArXiV: https://arxiv.org/pdf/2106.08017.pdf
#colorization #dl
Mava: a scalable, research framework for multi-agent reinforcement learning
The framework integrates with popular MARL environments such as PettingZoo, SMAC, RoboCup, OpenSpiel, Flatland , as well as a few custom environments.
Mava includes distributed implementations of multi-agent versions of ddpg, d4pg, dqn, ppo, as well as DIAL, VDN and QMIX.
ArXiV: https://arxiv.org/pdf/2107.01460.pdf
GitHub: https://github.com/instadeepai/Mava
#MARL #RL #dl
The framework integrates with popular MARL environments such as PettingZoo, SMAC, RoboCup, OpenSpiel, Flatland , as well as a few custom environments.
Mava includes distributed implementations of multi-agent versions of ddpg, d4pg, dqn, ppo, as well as DIAL, VDN and QMIX.
ArXiV: https://arxiv.org/pdf/2107.01460.pdf
GitHub: https://github.com/instadeepai/Mava
#MARL #RL #dl
GitHub
GitHub - instadeepai/Mava: 🦁 A research-friendly codebase for fast experimentation of multi-agent reinforcement learning in JAX
🦁 A research-friendly codebase for fast experimentation of multi-agent reinforcement learning in JAX - instadeepai/Mava
🎓Online Berkeley Deep Learning Lectures 2021
University of Berkeley released its fresh course lectures online for everyone to watch. Welcome Berkeley CS182/282 Deep Learnings - 2021!
YouTube: https://www.youtube.com/playlist?list=PLuv1FSpHurUevSXe_k0S7Onh6ruL-_NNh
#MOOC #wheretostart #Berkeley #dl
University of Berkeley released its fresh course lectures online for everyone to watch. Welcome Berkeley CS182/282 Deep Learnings - 2021!
YouTube: https://www.youtube.com/playlist?list=PLuv1FSpHurUevSXe_k0S7Onh6ruL-_NNh
#MOOC #wheretostart #Berkeley #dl
Program Synthesis with Large Language Models
Paper compares models used for program synthesis in general purpose programming languages against two new benchmarks, MBPP (The Mostly Basic Programming Problems) and MathQA-Python, in both the few-shot and fine-tuning regimes.
MBPP contains 974 programming tasks, designed to be solvable by entry-level programmers. MathQA benchmark, contains 23914 problems that evaluate the ability of the models to synthesize code from more complex text.
Largest fine-tuned model achieves 83.8 percent accuracy on the latter benchmark.
Why this is interesting: better models for code / problem understanding means improved search for the coding tasks and the improvement of the coding-assistant projects like #TabNine or #Copilot
ArXiV: https://arxiv.org/abs/2108.07732
#DL #NLU #codewritingcode #benchmark
Paper compares models used for program synthesis in general purpose programming languages against two new benchmarks, MBPP (The Mostly Basic Programming Problems) and MathQA-Python, in both the few-shot and fine-tuning regimes.
MBPP contains 974 programming tasks, designed to be solvable by entry-level programmers. MathQA benchmark, contains 23914 problems that evaluate the ability of the models to synthesize code from more complex text.
Largest fine-tuned model achieves 83.8 percent accuracy on the latter benchmark.
Why this is interesting: better models for code / problem understanding means improved search for the coding tasks and the improvement of the coding-assistant projects like #TabNine or #Copilot
ArXiV: https://arxiv.org/abs/2108.07732
#DL #NLU #codewritingcode #benchmark
{kind=link}
🔥Alias-Free Generative Adversarial Networks (StyleGAN3) release
King is dead! Long live the King! #StyleGAN2 was #SOTA and default standard for generating images. #Nvidia released update version, which will lead to more realistic images generated by the community.
Article: https://nvlabs.github.io/stylegan3/
GitHub: https://github.com/NVlabs/stylegan3
Colab: https://colab.research.google.com/drive/1BXNHZBai-pXtP-ncliouXo_kUiG1Pq7M
#GAN #dl
King is dead! Long live the King! #StyleGAN2 was #SOTA and default standard for generating images. #Nvidia released update version, which will lead to more realistic images generated by the community.
Article: https://nvlabs.github.io/stylegan3/
GitHub: https://github.com/NVlabs/stylegan3
Colab: https://colab.research.google.com/drive/1BXNHZBai-pXtP-ncliouXo_kUiG1Pq7M
#GAN #dl
🦜 Hi!
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
GitHub
ultimate_posts/where_to_start at master · open-data-science/ultimate_posts
Ultimate posts for opendatascience telegram channel - open-data-science/ultimate_posts
Imagen — new neural network for picture generation from Google
TLDR: Competitor of DALLE was released.
Imagen — text-to-image diffusion model with an unprecedented degree of photorealism and a deep level of language understanding. Imagen builds on the power of large transformer language models in understanding text and hinges on the strength of diffusion models in high-fidelity image generation. #Google key discovery is that generic large language models (e.g. T5), pretrained on text-only corpora, are surprisingly effective at encoding text for image synthesis: increasing the size of the language model in Imagen boosts both sample fidelity and image-text alignment much more than increasing the size of the image diffusion model.
Website: https://imagen.research.google
#GAN #CV #DL #Dalle
TLDR: Competitor of DALLE was released.
Imagen — text-to-image diffusion model with an unprecedented degree of photorealism and a deep level of language understanding. Imagen builds on the power of large transformer language models in understanding text and hinges on the strength of diffusion models in high-fidelity image generation. #Google key discovery is that generic large language models (e.g. T5), pretrained on text-only corpora, are surprisingly effective at encoding text for image synthesis: increasing the size of the language model in Imagen boosts both sample fidelity and image-text alignment much more than increasing the size of the image diffusion model.
Website: https://imagen.research.google
#GAN #CV #DL #Dalle
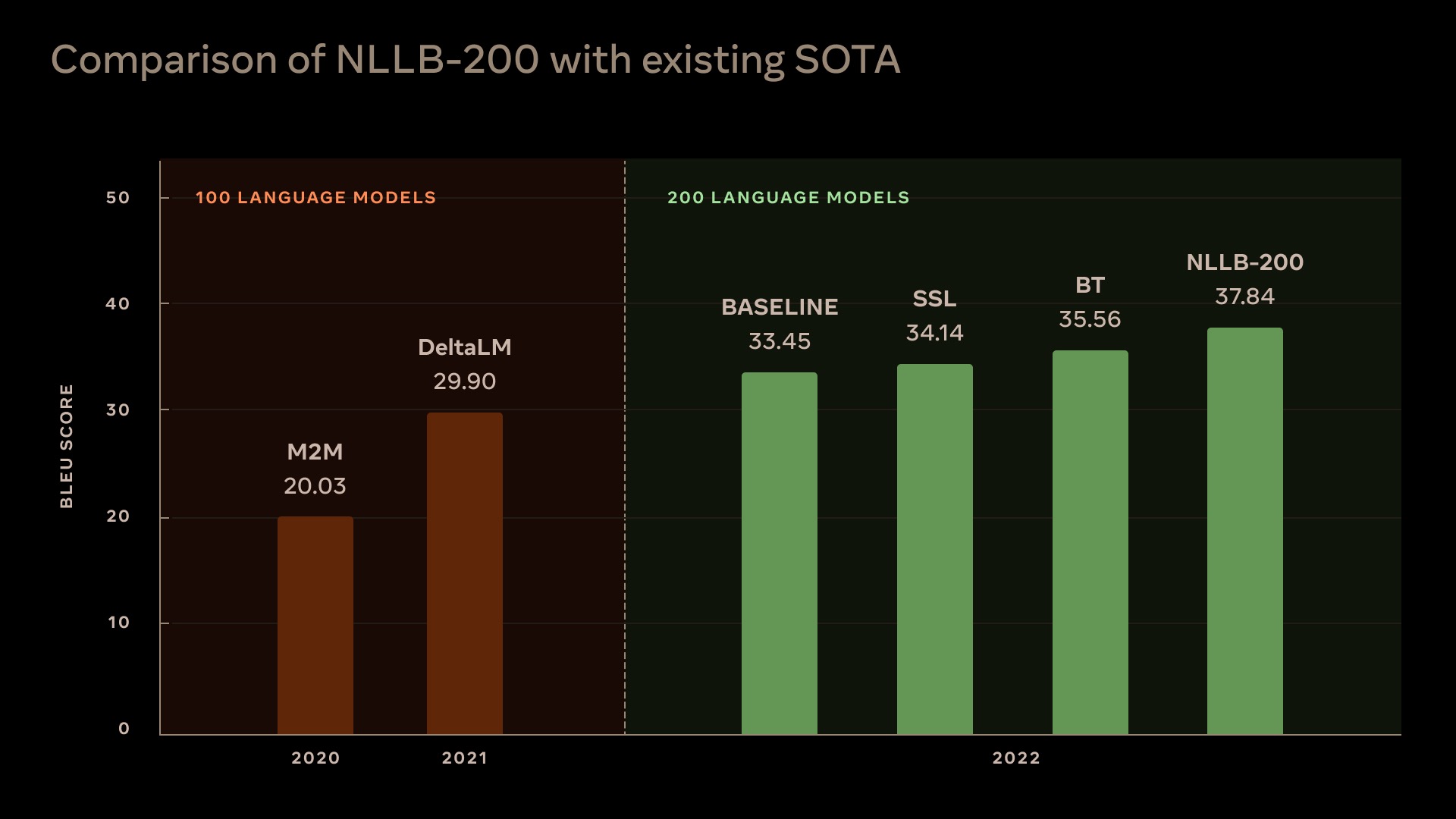
No Language Left Behind
Scaling Human-Centered Machine Translation
No Language Left Behind (NLLB) is a first-of-its-kind, AI breakthrough project that open-sources models capable of delivering high-quality translations directly between any pair of 200+ languages — including low-resource languages like Asturian, Luganda, Urdu and more. It aims to help people communicate with anyone, anywhere, regardless of their language preferences.
To enable the community to leverage and build on top of NLLB, the lab open source all they evaluation benchmarks (FLORES-200, NLLB-MD, Toxicity-200), LID models and training code, LASER3 encoders, data mining code, MMT training and inference code and our final NLLB-200 models and their smaller distilled versions, for easier use and adoption by the research community.
Paper: https://research.facebook.com/publications/no-language-left-behind/
Blog: https://ai.facebook.com/blog/nllb-200-high-quality-machine-translation/
GitHub: https://github.com/facebookresearch/fairseq/tree/26d62ae8fbf3deccf01a138d704be1e5c346ca9a
#nlp #translations #dl #datasets
Scaling Human-Centered Machine Translation
No Language Left Behind (NLLB) is a first-of-its-kind, AI breakthrough project that open-sources models capable of delivering high-quality translations directly between any pair of 200+ languages — including low-resource languages like Asturian, Luganda, Urdu and more. It aims to help people communicate with anyone, anywhere, regardless of their language preferences.
To enable the community to leverage and build on top of NLLB, the lab open source all they evaluation benchmarks (FLORES-200, NLLB-MD, Toxicity-200), LID models and training code, LASER3 encoders, data mining code, MMT training and inference code and our final NLLB-200 models and their smaller distilled versions, for easier use and adoption by the research community.
Paper: https://research.facebook.com/publications/no-language-left-behind/
Blog: https://ai.facebook.com/blog/nllb-200-high-quality-machine-translation/
GitHub: https://github.com/facebookresearch/fairseq/tree/26d62ae8fbf3deccf01a138d704be1e5c346ca9a
#nlp #translations #dl #datasets
{kind=link}
🔥Seeing Beyond the Brain: Conditional Diffusion Model with Sparse Masked Modeling for Vision Decoding
TLDR: Scientists kinda learned how to read thoughts. Paper on the reconstruction of the visual stimuli based on fMRI readings.
Website: https://mind-vis.github.io
Github: https://github.com/zjc062/mind-vis
#fMRI #visualstimulireconstruction #mindreading #dl
TLDR: Scientists kinda learned how to read thoughts. Paper on the reconstruction of the visual stimuli based on fMRI readings.
Website: https://mind-vis.github.io
Github: https://github.com/zjc062/mind-vis
#fMRI #visualstimulireconstruction #mindreading #dl
Data Science by ODS.ai 🦜
LLM models are in their childhood years Source.
Objective-Driven AI: Towards AI systems that can learn, remember, reason, and plan
A presentation by Yann Lecun on the #SOTA in #DL
YouTube: https://www.youtube.com/watch?v=MiqLoAZFRSE
Slides: Google Doc
Paper: Open Review
P.S. Stole the post from @chillhousetech
A presentation by Yann Lecun on the #SOTA in #DL
YouTube: https://www.youtube.com/watch?v=MiqLoAZFRSE
Slides: Google Doc
Paper: Open Review
P.S. Stole the post from @chillhousetech
YouTube
Yann Lecun | Objective-Driven AI: Towards AI systems that can learn, remember, reason, and plan
Ding Shum Lecture 3/28/2024
Speaker: Yann Lecun, New York University & META
Title: Objective-Driven AI: Towards AI systems that can learn, remember, reason, and plan
Abstract: How could machines learn as efficiently as humans and animals?
How could machines…
Speaker: Yann Lecun, New York University & META
Title: Objective-Driven AI: Towards AI systems that can learn, remember, reason, and plan
Abstract: How could machines learn as efficiently as humans and animals?
How could machines…