
Great collections of Data Science learning materials
The list includes free books and online courses on range of DS-related disciplines:
Machine learning (#ML)
Deep Learning (#DL)
Reinforcement learning (#RL)
#NLP
Tutorials on #Keras, #Tensorflow, #Torch, #PyTorch, #Theano
Notable researchers, papers and even #datasets. It is a great place to start reviewing your knowledge or learning something new.
Link: https://hackmd.io/@chanderA/aiguide
#wheretostart #entrylevel #novice #studycontent #studymaterials #books #MOOC #meta
The list includes free books and online courses on range of DS-related disciplines:
Machine learning (#ML)
Deep Learning (#DL)
Reinforcement learning (#RL)
#NLP
Tutorials on #Keras, #Tensorflow, #Torch, #PyTorch, #Theano
Notable researchers, papers and even #datasets. It is a great place to start reviewing your knowledge or learning something new.
Link: https://hackmd.io/@chanderA/aiguide
#wheretostart #entrylevel #novice #studycontent #studymaterials #books #MOOC #meta
Taskmaster-2 dataset by Google Research
The Taskmaster-2 dataset consists of 17 289 dialogs in seven domains:
– restaurants (3276)
– food ordering (1050)
– movies (3047)
– hotels (2355)
– flights (2481)
– music (1602)
– sports (3478)
All dialogs were collected using the same Wizard of Oz system used in Taskmaster-1 where crowdsourced workers playing the "user" interacted with human operators playing the "digital assistant" using a web-based interface
Github page: https://github.com/google-research-datasets/Taskmaster/tree/master/TM-2-2020
Web page: https://research.google/tools/datasets/taskmaster-2/
#nlp #datasets #dialogs
The Taskmaster-2 dataset consists of 17 289 dialogs in seven domains:
– restaurants (3276)
– food ordering (1050)
– movies (3047)
– hotels (2355)
– flights (2481)
– music (1602)
– sports (3478)
All dialogs were collected using the same Wizard of Oz system used in Taskmaster-1 where crowdsourced workers playing the "user" interacted with human operators playing the "digital assistant" using a web-based interface
Github page: https://github.com/google-research-datasets/Taskmaster/tree/master/TM-2-2020
Web page: https://research.google/tools/datasets/taskmaster-2/
#nlp #datasets #dialogs
GitHub
Taskmaster/TM-2-2020 at master · google-research-datasets/Taskmaster
Please see the readme file as well as our 2019 EMNLP paper linked here --> - google-research-datasets/Taskmaster
Most of the Scots NLP models used Wikipedia for training are wrong
One person who had done 200,000 edits and written 20,000 articles of Scots Wikipedia was not using Scots language but rather faking it. Since Wikipedia texts are often used as a dataset for #NLU / #NLP / #NMT neural nets training, those models using it as an input had a flaw.
Reddit thread: https://www.reddit.com/r/Scotland/comments/ig9jia/ive_discovered_that_almost_every_single_article/
#datasets #translation #scots #wikipedia
One person who had done 200,000 edits and written 20,000 articles of Scots Wikipedia was not using Scots language but rather faking it. Since Wikipedia texts are often used as a dataset for #NLU / #NLP / #NMT neural nets training, those models using it as an input had a flaw.
Reddit thread: https://www.reddit.com/r/Scotland/comments/ig9jia/ive_discovered_that_almost_every_single_article/
#datasets #translation #scots #wikipedia
Reddit
From the Scotland community on Reddit: I’ve discovered that almost every single article on the Scots version of Wikipedia is written…
Explore this post and more from the Scotland community
No Language Left Behind
Scaling Human-Centered Machine Translation
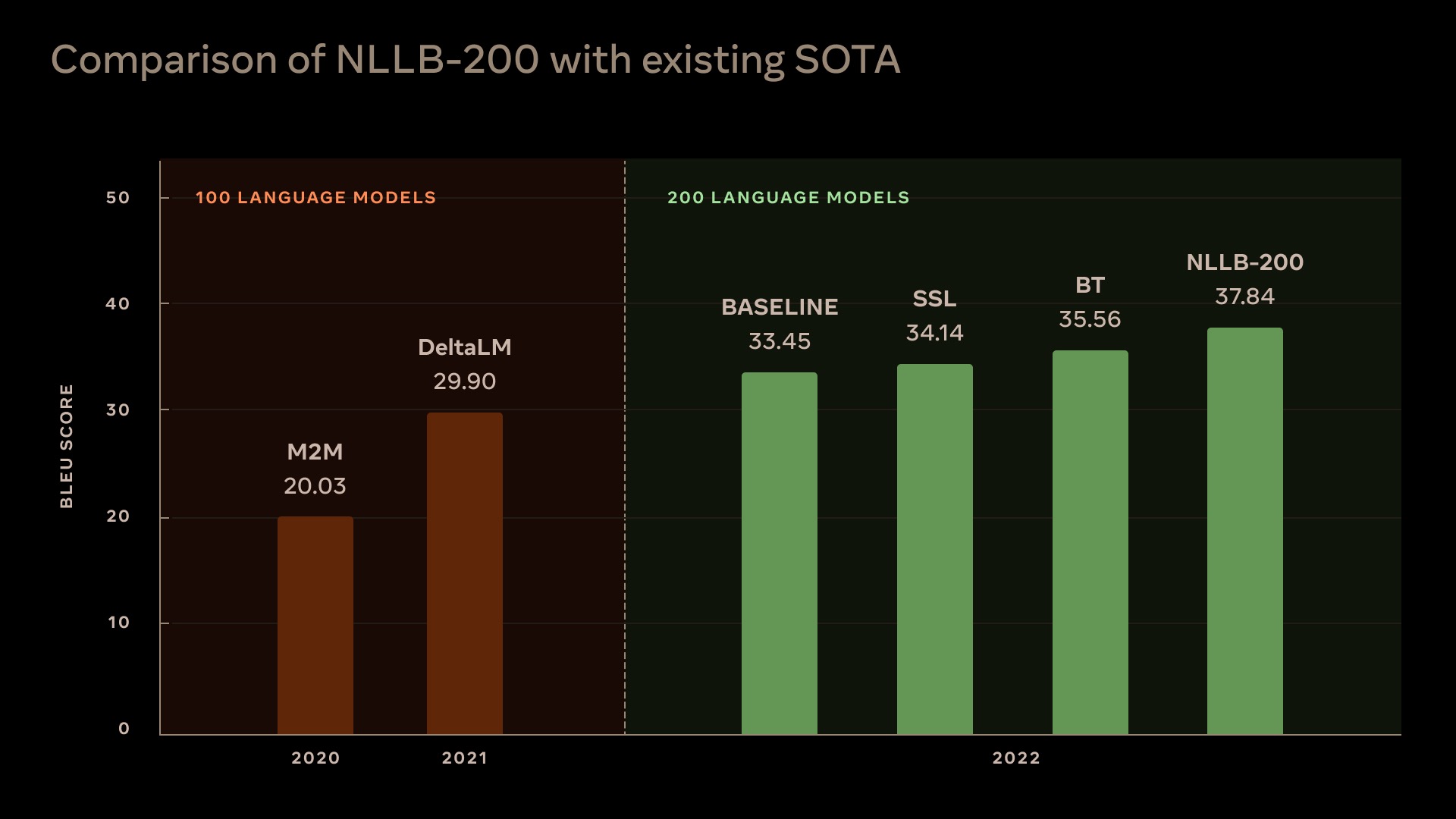
No Language Left Behind (NLLB) is a first-of-its-kind, AI breakthrough project that open-sources models capable of delivering high-quality translations directly between any pair of 200+ languages — including low-resource languages like Asturian, Luganda, Urdu and more. It aims to help people communicate with anyone, anywhere, regardless of their language preferences.
To enable the community to leverage and build on top of NLLB, the lab open source all they evaluation benchmarks (FLORES-200, NLLB-MD, Toxicity-200), LID models and training code, LASER3 encoders, data mining code, MMT training and inference code and our final NLLB-200 models and their smaller distilled versions, for easier use and adoption by the research community.
Paper: https://research.facebook.com/publications/no-language-left-behind/
Blog: https://ai.facebook.com/blog/nllb-200-high-quality-machine-translation/
GitHub: https://github.com/facebookresearch/fairseq/tree/26d62ae8fbf3deccf01a138d704be1e5c346ca9a
#nlp #translations #dl #datasets
Scaling Human-Centered Machine Translation
No Language Left Behind (NLLB) is a first-of-its-kind, AI breakthrough project that open-sources models capable of delivering high-quality translations directly between any pair of 200+ languages — including low-resource languages like Asturian, Luganda, Urdu and more. It aims to help people communicate with anyone, anywhere, regardless of their language preferences.
To enable the community to leverage and build on top of NLLB, the lab open source all they evaluation benchmarks (FLORES-200, NLLB-MD, Toxicity-200), LID models and training code, LASER3 encoders, data mining code, MMT training and inference code and our final NLLB-200 models and their smaller distilled versions, for easier use and adoption by the research community.
Paper: https://research.facebook.com/publications/no-language-left-behind/
Blog: https://ai.facebook.com/blog/nllb-200-high-quality-machine-translation/
GitHub: https://github.com/facebookresearch/fairseq/tree/26d62ae8fbf3deccf01a138d704be1e5c346ca9a
#nlp #translations #dl #datasets
{kind=link}