
ImageNet/ResNet-50 Training speed dramatically (6.6 min -> 224 sec) reduced
ResNet-50 on ImageNet now (allegedly) down to 224sec (3.7min) using 2176 V100s. Increasing batch size schedule, LARS, 5 epoch LR warmup, synch BN without mov avg. (mixed) fp16 training. "2D-Torus" all-reduce on NCCL2, with NVLink2 & 2 IB EDR interconnect.
1.28M images over 90 epochs with 68K batches, so the entire optimization is ~1700 updates to converge.
ArXiV: https://arxiv.org/abs/1811.05233
#ImageNet #ResNet
ResNet-50 on ImageNet now (allegedly) down to 224sec (3.7min) using 2176 V100s. Increasing batch size schedule, LARS, 5 epoch LR warmup, synch BN without mov avg. (mixed) fp16 training. "2D-Torus" all-reduce on NCCL2, with NVLink2 & 2 IB EDR interconnect.
1.28M images over 90 epochs with 68K batches, so the entire optimization is ~1700 updates to converge.
ArXiV: https://arxiv.org/abs/1811.05233
#ImageNet #ResNet
And the same for #ResNet, #RNN and feed-forward #nn without residual connections.
Gradient Descent Finds Global Minima of Deep Neural Networks
ArXiV: https://arxiv.org/pdf/1811.03804.pdf
On the Convergence Rate of Training Recurrent Neural Networks
ArXiV: https://arxiv.org/pdf/1810.12065.pdf
A Convergence Theory for Deep Learning via Over-Parameterization
ArXiV: https://arxiv.org/pdf/1811.03962.pdf
#dl
Gradient Descent Finds Global Minima of Deep Neural Networks
ArXiV: https://arxiv.org/pdf/1811.03804.pdf
On the Convergence Rate of Training Recurrent Neural Networks
ArXiV: https://arxiv.org/pdf/1810.12065.pdf
A Convergence Theory for Deep Learning via Over-Parameterization
ArXiV: https://arxiv.org/pdf/1811.03962.pdf
#dl
Implementing a ResNet model from scratch.
Well-written and explained note on how to build and train a ResNet model from ground zero.
Link: https://towardsdatascience.com/implementing-a-resnet-model-from-scratch-971be7193718
#ResNet #DL #CV #nn #tutorial
Well-written and explained note on how to build and train a ResNet model from ground zero.
Link: https://towardsdatascience.com/implementing-a-resnet-model-from-scratch-971be7193718
#ResNet #DL #CV #nn #tutorial
Medium
Implementing a ResNet model from scratch.
A basic description of how ResNet works and a hands-on approach to understanding the state-of-the-art network.
Neural Networks seem to follow a puzzlingly simple strategy to classify images
Interesting article on how actually #NN see images and what helps to distinct different classes.
Link: https://medium.com/bethgelab/neural-networks-seem-to-follow-a-puzzlingly-simple-strategy-to-classify-images-f4229317261f
#BagNet #ResNet #Dl #CV
Interesting article on how actually #NN see images and what helps to distinct different classes.
Link: https://medium.com/bethgelab/neural-networks-seem-to-follow-a-puzzlingly-simple-strategy-to-classify-images-f4229317261f
#BagNet #ResNet #Dl #CV
{kind=link}
The new ResNet PoseNet model is much more accurate than the MobileNet one (the trade off being size & speed). The model is quantized & 25MB.
Pose estimation model, capable of running on devices
This model is really great for art installations or running on desktops.
Demo (requires camera, will work on desktop): https://storage.googleapis.com/tfjs-models/demos/posenet/camera.html?linkId=69346544
Github: https://github.com/tensorflow/tfjs-models/tree/master/posenet
#tensorflow #tensorflowjs #js #pose #poseestimation #posenet #ResNet #device #ondevice
Pose estimation model, capable of running on devices
This model is really great for art installations or running on desktops.
Demo (requires camera, will work on desktop): https://storage.googleapis.com/tfjs-models/demos/posenet/camera.html?linkId=69346544
Github: https://github.com/tensorflow/tfjs-models/tree/master/posenet
#tensorflow #tensorflowjs #js #pose #poseestimation #posenet #ResNet #device #ondevice
📹What's Hidden in a Randomly Weighted Neural Network?
Amazingly this paper finds a subnetwork with random weights in a Wide ResNet-50 that outperforms optimized weights in a ResNet-34 for ImageNet!
On the last ICLR article by Lottery Ticket Hypothesis — the authors showed that it is possible to take a trained big net, and throw out at 95% of the scales so that the rest can be learned on the same quality, starting with the same initialization.
In the follow-up Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask found out that, it is possible to leave the weight with the initialization and learn only the mask, throwing unnecessary connections from the network - so it was possible to get under 40% of the quality on the Cifar, teaching not the weight of the model, but only its structure. Similar observations were made for simple RL tasks, see Weight-Agnostic Neural Network.
However, it was not clear how much structure-only training works on normal datasets and large nets, or without the right weights.
In the article the authors for the first time start struture-only on Imagenet. For this purpose:
- It takes a bold grid aka DenseNet, weights are initialized from the "binaryized" kaiming normal (either +std, or -std instead of normal).
- For each weight, an additional scalar - score s, showing how important it is for a good prediction. On the inference we take the top-k% weights and zero out the rest.
- With fixed weights, we train the scores. The main trick is that although in the forward pass we, like in the inference, take only top-k weights, in the backward pass the gradient flows through all the scores. It is ambiguous LRD where all weights are used in the forward, and in the backward - only a small subset.
Thus we can to prune a random WideResnet50 and get 73.3% accuracy on imagenet and there will be less active weights than in Resnet34. Magic.
ArXiV: https://arxiv.org/pdf/1911.13299.pdf
YouTube explanation: https://www.youtube.com/watch?v=C6Tj8anJO-Q
via @JanRocketMan
#ImageNet #ResNet
Amazingly this paper finds a subnetwork with random weights in a Wide ResNet-50 that outperforms optimized weights in a ResNet-34 for ImageNet!
On the last ICLR article by Lottery Ticket Hypothesis — the authors showed that it is possible to take a trained big net, and throw out at 95% of the scales so that the rest can be learned on the same quality, starting with the same initialization.
In the follow-up Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask found out that, it is possible to leave the weight with the initialization and learn only the mask, throwing unnecessary connections from the network - so it was possible to get under 40% of the quality on the Cifar, teaching not the weight of the model, but only its structure. Similar observations were made for simple RL tasks, see Weight-Agnostic Neural Network.
However, it was not clear how much structure-only training works on normal datasets and large nets, or without the right weights.
In the article the authors for the first time start struture-only on Imagenet. For this purpose:
- It takes a bold grid aka DenseNet, weights are initialized from the "binaryized" kaiming normal (either +std, or -std instead of normal).
- For each weight, an additional scalar - score s, showing how important it is for a good prediction. On the inference we take the top-k% weights and zero out the rest.
- With fixed weights, we train the scores. The main trick is that although in the forward pass we, like in the inference, take only top-k weights, in the backward pass the gradient flows through all the scores. It is ambiguous LRD where all weights are used in the forward, and in the backward - only a small subset.
Thus we can to prune a random WideResnet50 and get 73.3% accuracy on imagenet and there will be less active weights than in Resnet34. Magic.
ArXiV: https://arxiv.org/pdf/1911.13299.pdf
YouTube explanation: https://www.youtube.com/watch?v=C6Tj8anJO-Q
via @JanRocketMan
#ImageNet #ResNet
arXiv.org
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
Neural network pruning techniques can reduce the parameter counts of trained networks by over 90%, decreasing storage requirements and improving computational performance of inference without...
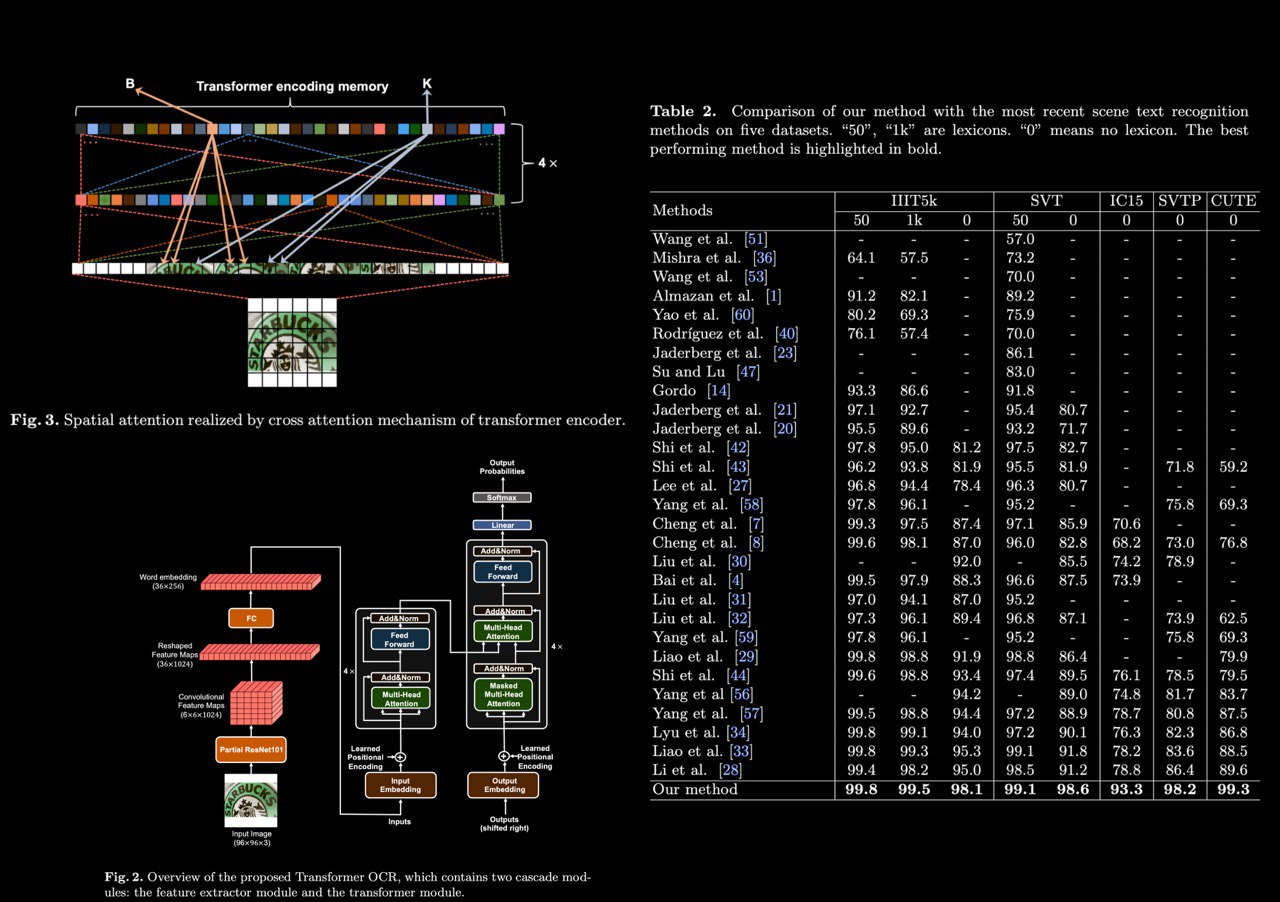
Scene Text Recognition via Transformer
The authors propose a simple but extremely effective scene text recognition method based on the transformer. The proposed method uses convolutional feature maps as word embedding input into the transformer. In such a way, their method is able to make full use of the powerful attention mechanism of the transformer.
Extensive experimental results show that the proposed method significantly outperforms SOTA methods by a very large margin on both regular and irregular text datasets. In particular, the proposed method performs the best on two regular text benchmarks. On irregular text benchmarks, the proposed method shows its powerful ability to recognize irregular texts. Surprisingly, the proposed method outperforms the second best by very large margins, 14.5%, 11.8%, and 9.7%, on the IC15, SVTP, and CUTE, respectively.
paper: https://arxiv.org/abs/2003.08077
github: https://github.com/fengxinjie/Transformer-OCR
#ocr #scene #text #recognition #cv #nlp #resNet #Transformer
The authors propose a simple but extremely effective scene text recognition method based on the transformer. The proposed method uses convolutional feature maps as word embedding input into the transformer. In such a way, their method is able to make full use of the powerful attention mechanism of the transformer.
Extensive experimental results show that the proposed method significantly outperforms SOTA methods by a very large margin on both regular and irregular text datasets. In particular, the proposed method performs the best on two regular text benchmarks. On irregular text benchmarks, the proposed method shows its powerful ability to recognize irregular texts. Surprisingly, the proposed method outperforms the second best by very large margins, 14.5%, 11.8%, and 9.7%, on the IC15, SVTP, and CUTE, respectively.
paper: https://arxiv.org/abs/2003.08077
github: https://github.com/fengxinjie/Transformer-OCR
#ocr #scene #text #recognition #cv #nlp #resNet #Transformer
{kind=link}
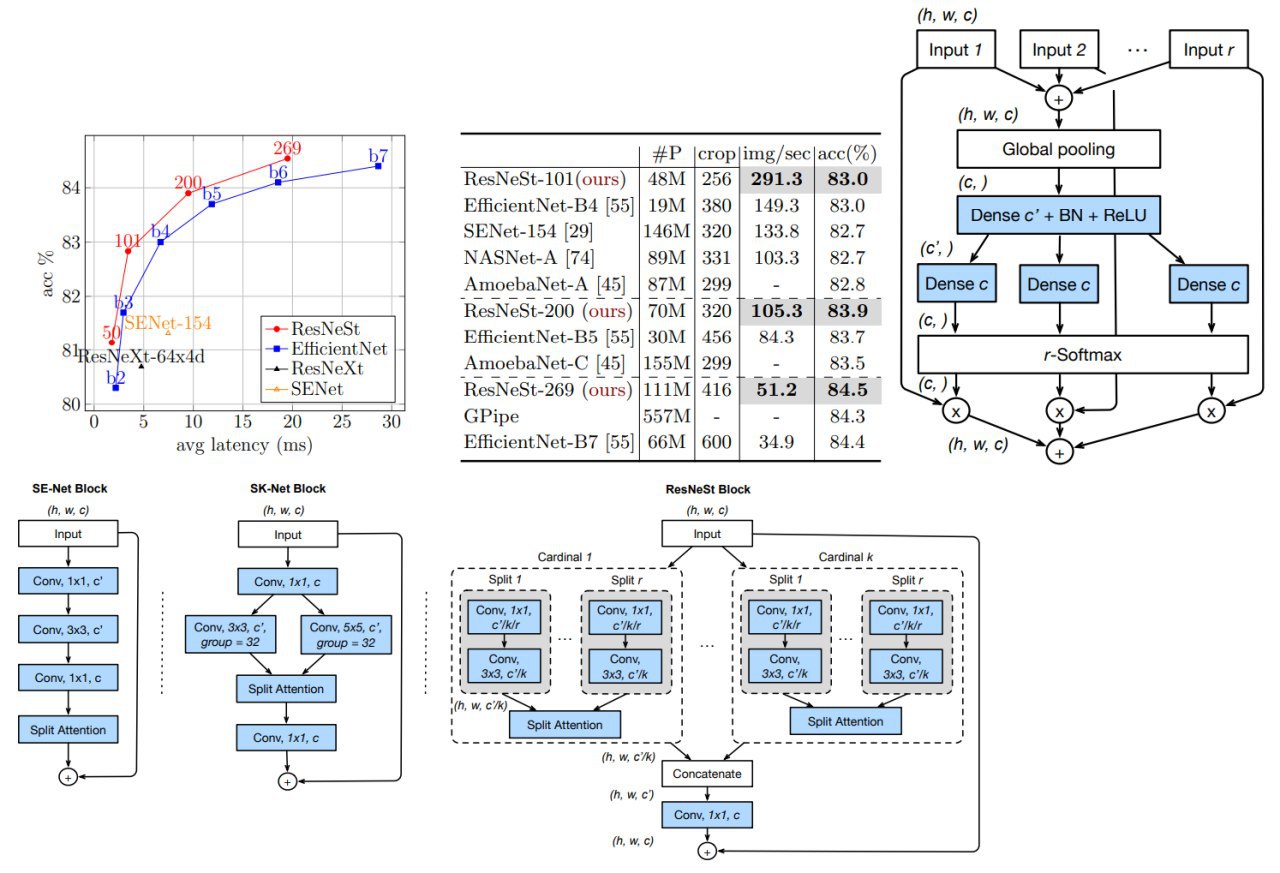
ResNeSt: Split-Attention Networks
A novel variation of ResNet architecture that outperforms other networks with similar model complexities.
Usually, downstream applications use the ResNet or one of its variants as the backbone CNN. Its simple and modular design can be easily adapted to various tasks. However, since ResNet models are originally designed for image classification, they may not be suitable for various downstream applications because of the limited receptive-field size and lack of cross-channel interaction.
Main contributions of the paper:
- Split-Attention block. Each block divides the feature-map into several groups (along the channel dimension) and finer-grained subgroups or splits, where the feature representation of each group is determined via a weighted combination of the representations of its splits. By stacking several Split-Attention blocks, they get a ResNet-like network called ResNeSt (
- a lot of large scale benchmarks on image classification and transfer learning.
Models utilizing a ResNeSt backbone are able to achieve SOTA performance on several tasks, namely: image classification, object detection, instance segmentation, and semantic segmentation.
ResNeSt-50 achieves 81.13% top-1 accuracy on ImageNet using a single crop-size of 224 × 224, outperforming previous best ResNet variant by more than 1% accuracy
Paper: https://arxiv.org/abs/2004.08955
Github: https://github.com/zhanghang1989/ResNeSt
#computervision #deeplearning #resnet #image #backbone #downstream #sota
A novel variation of ResNet architecture that outperforms other networks with similar model complexities.
Usually, downstream applications use the ResNet or one of its variants as the backbone CNN. Its simple and modular design can be easily adapted to various tasks. However, since ResNet models are originally designed for image classification, they may not be suitable for various downstream applications because of the limited receptive-field size and lack of cross-channel interaction.
Main contributions of the paper:
- Split-Attention block. Each block divides the feature-map into several groups (along the channel dimension) and finer-grained subgroups or splits, where the feature representation of each group is determined via a weighted combination of the representations of its splits. By stacking several Split-Attention blocks, they get a ResNet-like network called ResNeSt (
S stands for “split”). This architecture requires no more computation than existing ResNet-variants, and is easy to be adopted as a backbone for other vision tasks- a lot of large scale benchmarks on image classification and transfer learning.
Models utilizing a ResNeSt backbone are able to achieve SOTA performance on several tasks, namely: image classification, object detection, instance segmentation, and semantic segmentation.
ResNeSt-50 achieves 81.13% top-1 accuracy on ImageNet using a single crop-size of 224 × 224, outperforming previous best ResNet variant by more than 1% accuracy
Paper: https://arxiv.org/abs/2004.08955
Github: https://github.com/zhanghang1989/ResNeSt
#computervision #deeplearning #resnet #image #backbone #downstream #sota
{kind=link}
Castle in the Sky
Dynamic Sky Replacement and Harmonization in Videos
Fascinating and ready to be applied for work. (With colab notebook)
The authors proposed a method to replace the sky in the video that works well in high resolution. The results are very impressive. The method runs in real-time and produces video almost without glitches and artifacts. Also, can generate for example lightning and glow on target video.
The pipeline is quite complicated and contains several tasks:
– A sky matting network to segmentation sky on video frames
– A motion estimator for sky objects
– A skybox for blending where sky and other environments on video are relighting and recoloring.
Authors say their work, in a nutshell, proposes a new framework for sky augmentation in outdoor videos. The solution is purely vision-based and it can be applied to both online and offline scenarios.
But let's take a closer look.
A sky matting module is a ResNet-like encoder and several layers upsampling decoder to solve sky pixel-wise segmentation tasks followed by a refinement stage with guided image filtering.
A motion estimator directly estimates the motion of the objects in the sky. The motion patterns are modeled by an affine matrix and optical flow.
The sky image blending module is a decoder that models a linear combination of target sky matte and aligned sky template.
Overall, the network architecture is ResNet-50 as encoder and decoder with coordConv upsampling layers with skip connections and implemented in Pytorch,
The result is presented in a very cool video https://youtu.be/zal9Ues0aOQ
site: https://jiupinjia.github.io/skyar/
paper: https://arxiv.org/abs/2010.11800
github: https://github.com/jiupinjia/SkyAR
#sky #CV #video #cool #resnet
Dynamic Sky Replacement and Harmonization in Videos
Fascinating and ready to be applied for work. (With colab notebook)
The authors proposed a method to replace the sky in the video that works well in high resolution. The results are very impressive. The method runs in real-time and produces video almost without glitches and artifacts. Also, can generate for example lightning and glow on target video.
The pipeline is quite complicated and contains several tasks:
– A sky matting network to segmentation sky on video frames
– A motion estimator for sky objects
– A skybox for blending where sky and other environments on video are relighting and recoloring.
Authors say their work, in a nutshell, proposes a new framework for sky augmentation in outdoor videos. The solution is purely vision-based and it can be applied to both online and offline scenarios.
But let's take a closer look.
A sky matting module is a ResNet-like encoder and several layers upsampling decoder to solve sky pixel-wise segmentation tasks followed by a refinement stage with guided image filtering.
A motion estimator directly estimates the motion of the objects in the sky. The motion patterns are modeled by an affine matrix and optical flow.
The sky image blending module is a decoder that models a linear combination of target sky matte and aligned sky template.
Overall, the network architecture is ResNet-50 as encoder and decoder with coordConv upsampling layers with skip connections and implemented in Pytorch,
The result is presented in a very cool video https://youtu.be/zal9Ues0aOQ
site: https://jiupinjia.github.io/skyar/
paper: https://arxiv.org/abs/2010.11800
github: https://github.com/jiupinjia/SkyAR
#sky #CV #video #cool #resnet
YouTube
Dynamic Sky Replacement and Harmonization in Videos
Preprint: Castle in the Sky: Zhengxia Zou, Dynamic Sky Replacement and Harmonization in Videos, 2020.
Project page: https://jiupinjia.github.io/skyar/
Project page: https://jiupinjia.github.io/skyar/
🦜 Hi!
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
GitHub
ultimate_posts/where_to_start at master · open-data-science/ultimate_posts
Ultimate posts for opendatascience telegram channel - open-data-science/ultimate_posts