
Towards Lingua Franca Named Entity Recognition with BERT
The authors present a simple and effective recipe for building #multilingual #NER systems with #BERT.
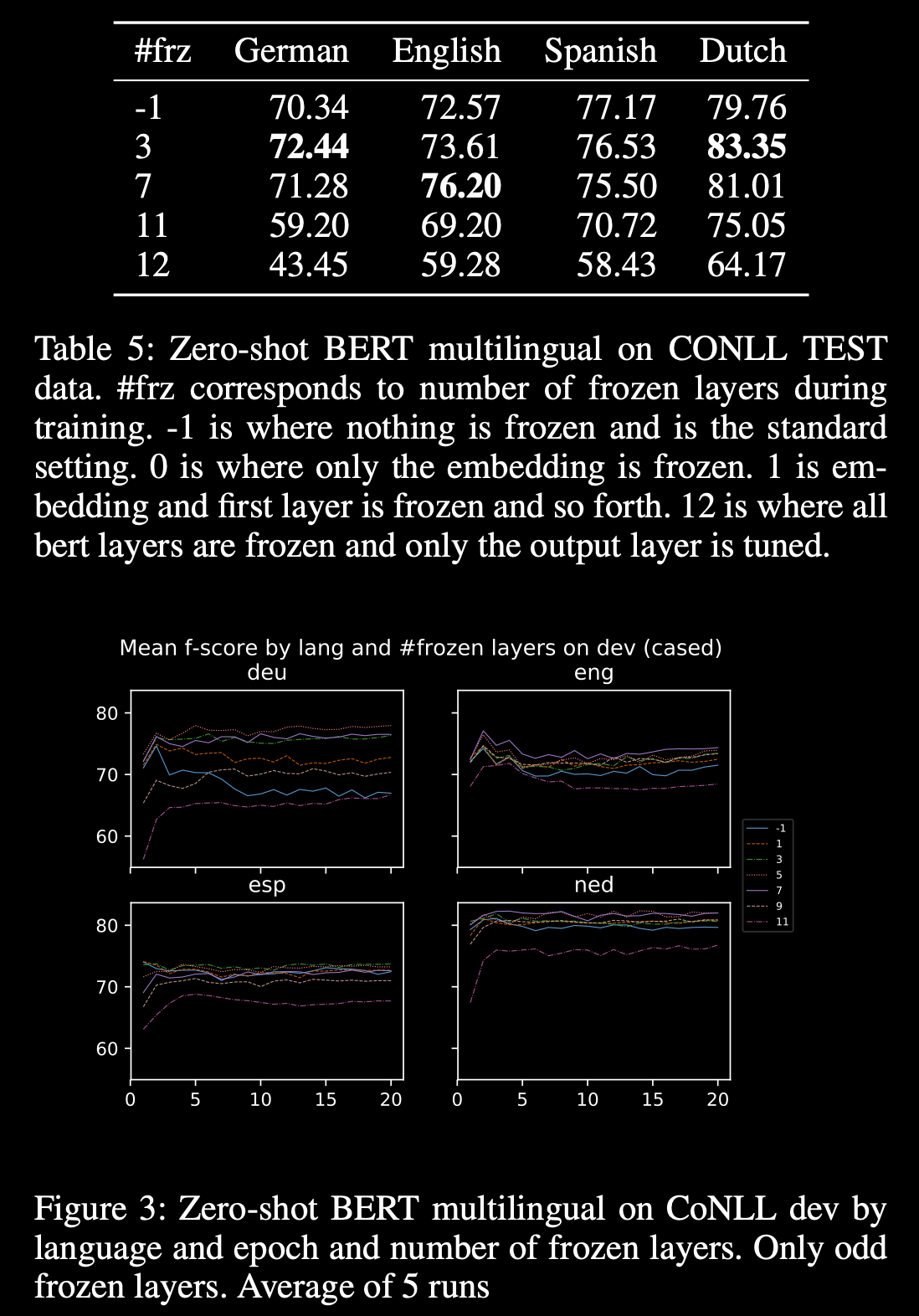
By utilizing a multilingual BERT framework, they were able to not only train a system that can perform inference on English, German, Spanish, and Dutch languages, but it performs better than the same model trained only on one language at a time, and also is able to perform 0-shot inference.
The resulting model yields #SotA results on CoNLL Spanish and Dutch, and on OntoNotes Chinese and Arabic datasets.
Also, the English trained model yields SotA results for 0-shot languages for Spanish, Dutch, and German NER, improving it by a range of 2.4F to 17.8F.
Furthermore, the runtime signature (memory/CPU/GPU) of the model is the same as the models built on single languages, significantly simplifying its life- cycle maintenance.
paper: https://arxiv.org/abs/1912.01389
The authors present a simple and effective recipe for building #multilingual #NER systems with #BERT.
By utilizing a multilingual BERT framework, they were able to not only train a system that can perform inference on English, German, Spanish, and Dutch languages, but it performs better than the same model trained only on one language at a time, and also is able to perform 0-shot inference.
The resulting model yields #SotA results on CoNLL Spanish and Dutch, and on OntoNotes Chinese and Arabic datasets.
Also, the English trained model yields SotA results for 0-shot languages for Spanish, Dutch, and German NER, improving it by a range of 2.4F to 17.8F.
Furthermore, the runtime signature (memory/CPU/GPU) of the model is the same as the models built on single languages, significantly simplifying its life- cycle maintenance.
paper: https://arxiv.org/abs/1912.01389
{kind=link}
Cross-Lingual Ability of Multilingual BERT: An Empirical Study to #ICLR2020
In this work, the authors provide a comprehensive study of the contribution of different components in multilingual #BERT (M-BERT) to its cross-lingual ability.
They study the impact of linguistic properties of the languages, the architecture of the model, and the learning objectives. The experimental study is done in the context of three typologically different languages – #Spanish, #Hindi, & #Russian – & using two conceptually different #NLP tasks, textual entailment & #NER.
Also, they construct a new corpus – Fake-English (#enfake), by shifting the Unicode of each character in English Wikipedia text by a large constant so that there is strictly no character overlap with any other Wikipedia text.
And, in this work, they consider Fake-English as a different language.
Among their key conclusions are the fact that the lexical overlap between languages plays a negligible role in the cross-lingual success, while the depth of the network is an integral part of it.
paper: https://arxiv.org/abs/1912.07840
In this work, the authors provide a comprehensive study of the contribution of different components in multilingual #BERT (M-BERT) to its cross-lingual ability.
They study the impact of linguistic properties of the languages, the architecture of the model, and the learning objectives. The experimental study is done in the context of three typologically different languages – #Spanish, #Hindi, & #Russian – & using two conceptually different #NLP tasks, textual entailment & #NER.
Also, they construct a new corpus – Fake-English (#enfake), by shifting the Unicode of each character in English Wikipedia text by a large constant so that there is strictly no character overlap with any other Wikipedia text.
And, in this work, they consider Fake-English as a different language.
Among their key conclusions are the fact that the lexical overlap between languages plays a negligible role in the cross-lingual success, while the depth of the network is an integral part of it.
paper: https://arxiv.org/abs/1912.07840
{kind=link}
A new approach for NER on partially labeled datasets.
One of the common problems with NER modeling is the lack of datasets covering all required slot types. Often there are several datasets that have labels for different entities.
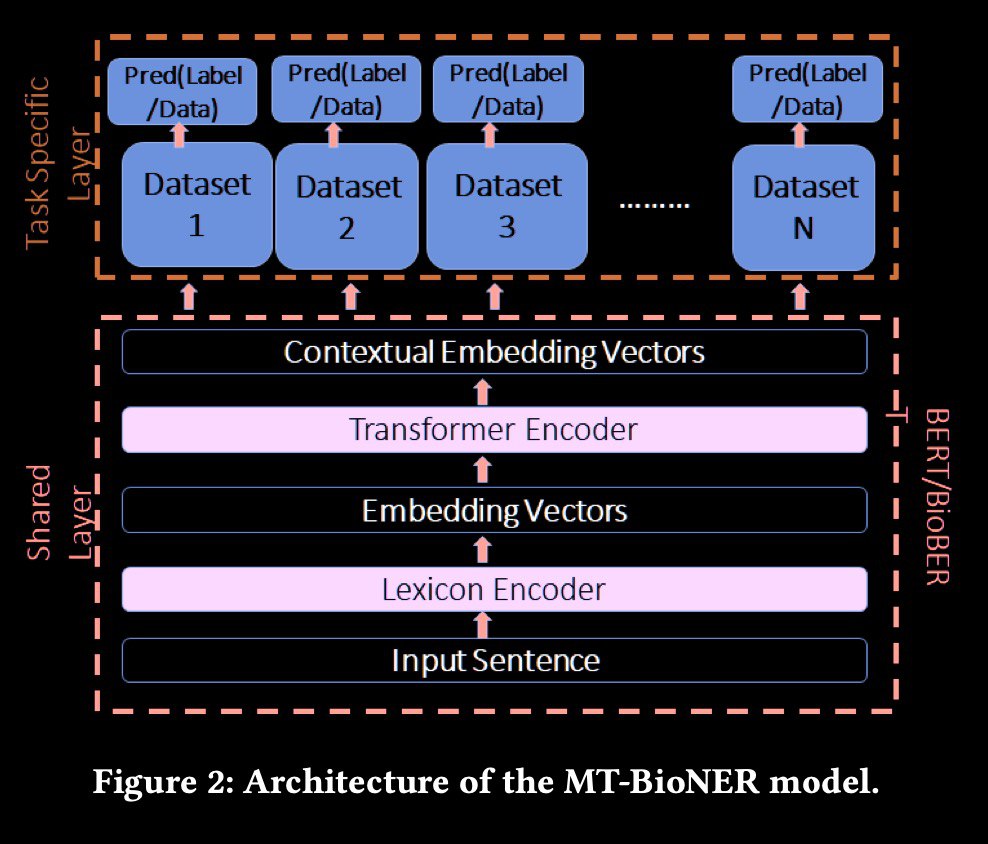
The key idea of the paper is using multi-task transformer-based architecture on multiple datasets.
The model architecture looks like this:
- lexicon encoder layer (input is tokens with words, position and segment embeddings);
- transformer encoder, which generates the shared contextual embedding vectors;
- separate heads for each dataset.
During the training phase, it is necessary to not only train the task-dependent layers but also to fine-tune the shared language model.
Experiments were conducted on four datasets using a single Tesla K80. A single multi-task model (iterating over datasets) shows SOTA results and trains faster than separate models for each task.
Paper: https://arxiv.org/abs/2001.08904
#nlp #bert #ner #biomedical
MT-BioNER: Multi-task Learning for Biomedical Named EntityRecognition using Deep Bidirectional TransformersA new approach for NER on partially labeled datasets.
One of the common problems with NER modeling is the lack of datasets covering all required slot types. Often there are several datasets that have labels for different entities.
The key idea of the paper is using multi-task transformer-based architecture on multiple datasets.
The model architecture looks like this:
- lexicon encoder layer (input is tokens with words, position and segment embeddings);
- transformer encoder, which generates the shared contextual embedding vectors;
- separate heads for each dataset.
During the training phase, it is necessary to not only train the task-dependent layers but also to fine-tune the shared language model.
Experiments were conducted on four datasets using a single Tesla K80. A single multi-task model (iterating over datasets) shows SOTA results and trains faster than separate models for each task.
Paper: https://arxiv.org/abs/2001.08904
#nlp #bert #ner #biomedical
{kind=link}
TENER: Adapting Transformer Encoder for Named Entity Recognition
The authors suggest several modifications to Transformer architecture for NER tasks.
Recently Transformer architectures were adopted in many NLP tasks and showed great results. Nevertheless, the performance of the vanilla Transformer in NER is not as good as it is in other NLP tasks.
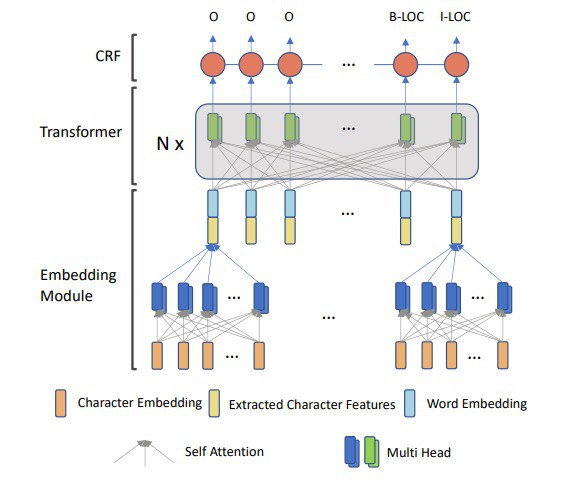
To improve the performance of this approach for NER tasks the following improvements were implemented:
– revised relative positional encoding to use both the direction and distance information;
– un-scaled attention, as few contextual words are enough to judge its label
– using both word-embeddings and character-embeddings.
The experiments show that this approach can reach SOTA results (without considering the pre-trained language models). The adapted Transformer is also suitable for being used as the English character encoder.
Paper: https://arxiv.org/abs/1911.04474
Code: https://github.com/fastnlp/TENER
#deeplearning #nlp #transformer #attention #encoder #ner
The authors suggest several modifications to Transformer architecture for NER tasks.
Recently Transformer architectures were adopted in many NLP tasks and showed great results. Nevertheless, the performance of the vanilla Transformer in NER is not as good as it is in other NLP tasks.
To improve the performance of this approach for NER tasks the following improvements were implemented:
– revised relative positional encoding to use both the direction and distance information;
– un-scaled attention, as few contextual words are enough to judge its label
– using both word-embeddings and character-embeddings.
The experiments show that this approach can reach SOTA results (without considering the pre-trained language models). The adapted Transformer is also suitable for being used as the English character encoder.
Paper: https://arxiv.org/abs/1911.04474
Code: https://github.com/fastnlp/TENER
#deeplearning #nlp #transformer #attention #encoder #ner
{kind=link}
End-to-end Named Entity Recognition and Relation Extraction using Pre-trained Language Models
Authors propose an end-to-end model for jointly extracting entities and
their relations.
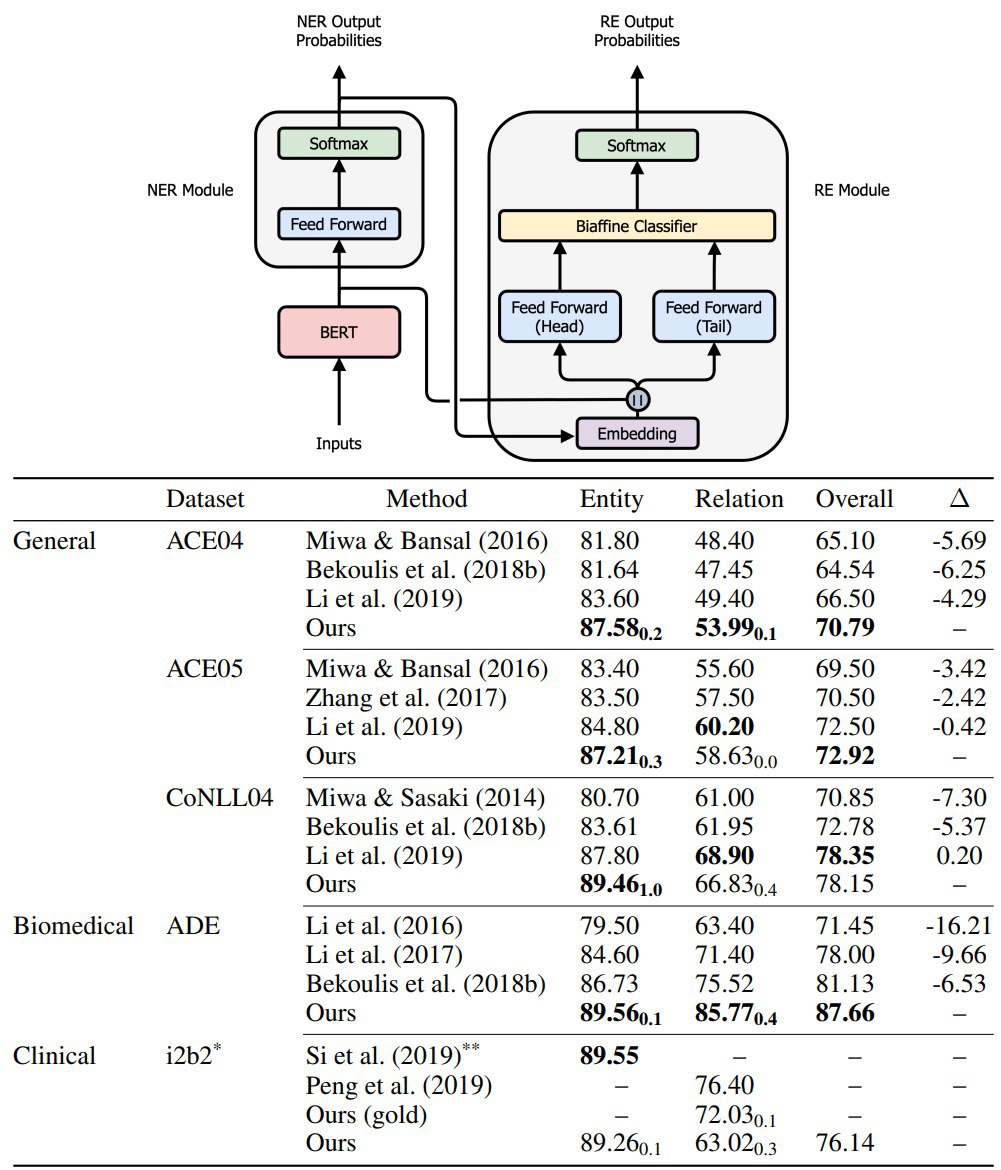
There were multiple approaches to solve this task, but they either showed a low predictive power or used some external tools. The authors suggest using BERT as a pre-trained model and a single architecture with modules for NER and ER.
This paper makes the following innovations:
– end-to-end approach, relying on no handcrafted features or external NLP tools
– fast training thanks to using pre-trained models
– match or exceed state-of-the-art results for joint NER and RE on 5 datasets across 3 domains
Paper: https://arxiv.org/abs/1912.13415
Code: https://github.com/bowang-lab/joint-ner-and-re
Unofficial code: https://github.com/BaderLab/saber/blob/development/saber/models/bert_for_ner_and_re.py
#deeplearning #nlp #transformer #NER #ER
Authors propose an end-to-end model for jointly extracting entities and
their relations.
There were multiple approaches to solve this task, but they either showed a low predictive power or used some external tools. The authors suggest using BERT as a pre-trained model and a single architecture with modules for NER and ER.
This paper makes the following innovations:
– end-to-end approach, relying on no handcrafted features or external NLP tools
– fast training thanks to using pre-trained models
– match or exceed state-of-the-art results for joint NER and RE on 5 datasets across 3 domains
Paper: https://arxiv.org/abs/1912.13415
Code: https://github.com/bowang-lab/joint-ner-and-re
Unofficial code: https://github.com/BaderLab/saber/blob/development/saber/models/bert_for_ner_and_re.py
#deeplearning #nlp #transformer #NER #ER
{kind=link}
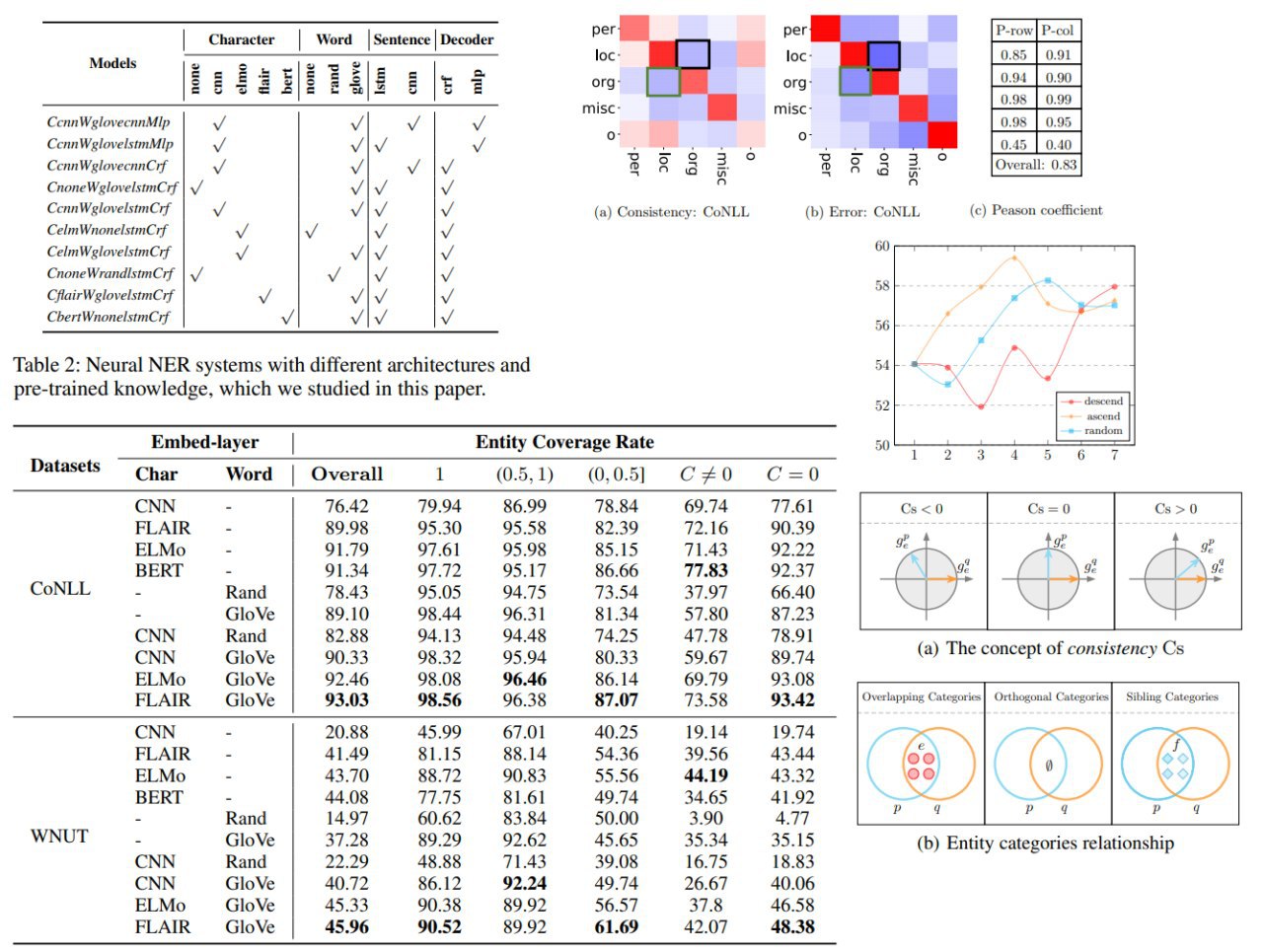
Rethinking Generalization of Neural Models: A Named Entity Recognition Case Study
Authors use the NER task to analyze the generalization behavior of existing models from different perspectives. Experiments with in-depth analyses diagnose the bottleneck of existing neural NER models in terms of breakdown performance analysis, annotation errors, dataset bias, and category relationships, which suggest directions for improvement.
The authors also release two datasets for future research: ReCoNLL and PLONER.
The main findings of the paper:
– the performance of existing models (including the state-of-the-art model) heavily influenced by the degree to which test entities have been seen in the training set with the same label
– the proposed measure enables to detect human annotation errors.
Once these errors are fixed, previous models can achieve new state-of-the-art results
– authors introduce two measures to characterize the data bias and the cross-dataset generalization experiment shows that the performance of NER systems is influenced not only by whether the test entity has been seen in the training set but also by whether the context of the test entity has been observed
– providing more training samples is not a guarantee of better results. A targeted increase in training samples will make it more profitable
– the relationship between entity categories influences the difficulty of model learning, which leads to some hard test samples that are difficult to solve using common learning methods
Paper: https://arxiv.org/abs/2001.03844
Github: https://github.com/pfliu-nlp/Named-Entity-Recognition-NER-Papers
Website: http://pfliu.com/InterpretNER/
#nlp #generalization #NER #annotations #dataset
Authors use the NER task to analyze the generalization behavior of existing models from different perspectives. Experiments with in-depth analyses diagnose the bottleneck of existing neural NER models in terms of breakdown performance analysis, annotation errors, dataset bias, and category relationships, which suggest directions for improvement.
The authors also release two datasets for future research: ReCoNLL and PLONER.
The main findings of the paper:
– the performance of existing models (including the state-of-the-art model) heavily influenced by the degree to which test entities have been seen in the training set with the same label
– the proposed measure enables to detect human annotation errors.
Once these errors are fixed, previous models can achieve new state-of-the-art results
– authors introduce two measures to characterize the data bias and the cross-dataset generalization experiment shows that the performance of NER systems is influenced not only by whether the test entity has been seen in the training set but also by whether the context of the test entity has been observed
– providing more training samples is not a guarantee of better results. A targeted increase in training samples will make it more profitable
– the relationship between entity categories influences the difficulty of model learning, which leads to some hard test samples that are difficult to solve using common learning methods
Paper: https://arxiv.org/abs/2001.03844
Github: https://github.com/pfliu-nlp/Named-Entity-Recognition-NER-Papers
Website: http://pfliu.com/InterpretNER/
#nlp #generalization #NER #annotations #dataset
{kind=link}
SpERT: Span-based Joint Entity and Relation Extraction with Transformer Pre-training
Authors introduce SpERT, an attention model for span-based joint entity and relation extraction.
This work investigates the use of Transformer networks for relation extraction: given a pre-defined set of target relations and a sentence such as “Leonardo DiCaprio starred in Christopher Nolan’s thriller Inception”, the goal is to extract triplets such as (“Leonardo DiCaprio”, Plays-In, “Inception”) or (“Inception”, Director, “Christopher Nolan”).
The main contributions of the paper are:
– a novel approach towards span-based joint entity and relation extraction
– ablation study showing that negative samples from the same sentence yield efficient training, a localized context representation is beneficial, finetuning a pre-trained model yields a strong performance increase over training from scratch.
This approach improves the SOTA score on CoNLL04 dataset by 2.6% (micro) F1.
Paper: https://arxiv.org/abs/1909.07755
Code: https://github.com/markus-eberts/spert
#nlp #deeplearning #transformer #bert #ner #relationextraction
Authors introduce SpERT, an attention model for span-based joint entity and relation extraction.
This work investigates the use of Transformer networks for relation extraction: given a pre-defined set of target relations and a sentence such as “Leonardo DiCaprio starred in Christopher Nolan’s thriller Inception”, the goal is to extract triplets such as (“Leonardo DiCaprio”, Plays-In, “Inception”) or (“Inception”, Director, “Christopher Nolan”).
The main contributions of the paper are:
– a novel approach towards span-based joint entity and relation extraction
– ablation study showing that negative samples from the same sentence yield efficient training, a localized context representation is beneficial, finetuning a pre-trained model yields a strong performance increase over training from scratch.
This approach improves the SOTA score on CoNLL04 dataset by 2.6% (micro) F1.
Paper: https://arxiv.org/abs/1909.07755
Code: https://github.com/markus-eberts/spert
#nlp #deeplearning #transformer #bert #ner #relationextraction
{kind=link}
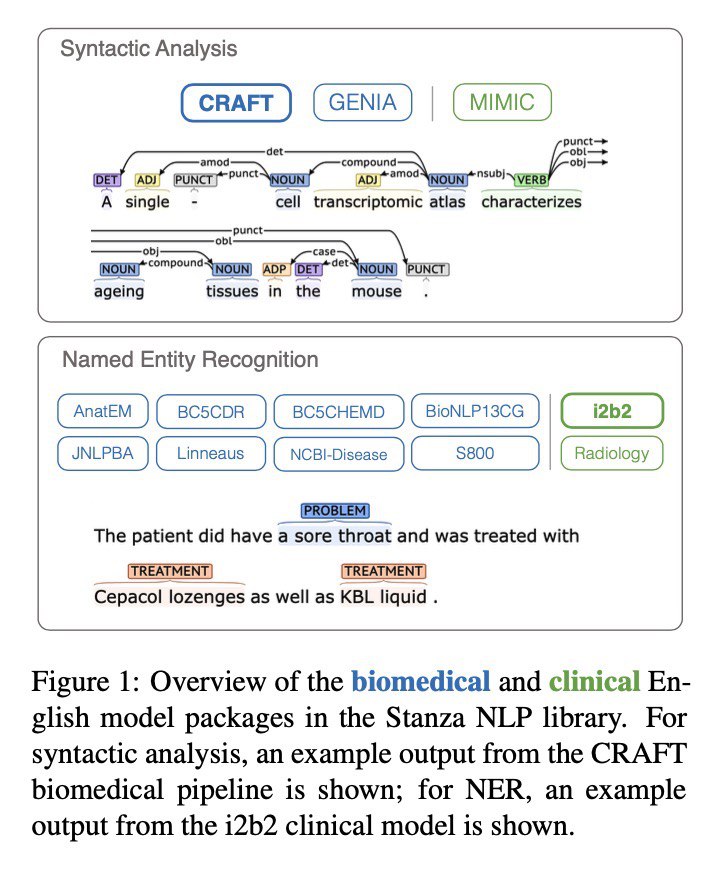
Stanford updated tool Stanza with #NER for biomedical and clinical terms
Stanza extended with first domain-specific models for biomedical and clinical medical English. They range from approaching to significantly improving state of the art results on syntactic and NER tasks.
That means that now neural networks are capable of understanding difficult texts with lots of specific terms. That means better search, improved knowledge extraction and approach for performing META analysis, or even research with medical ArXiV publications.
Demo: http://stanza.run/bio
ArXiV: https://arxiv.org/abs/2007.14640
#NLProc #NLU #Stanford #biolearning #medicallearning
Stanza extended with first domain-specific models for biomedical and clinical medical English. They range from approaching to significantly improving state of the art results on syntactic and NER tasks.
That means that now neural networks are capable of understanding difficult texts with lots of specific terms. That means better search, improved knowledge extraction and approach for performing META analysis, or even research with medical ArXiV publications.
Demo: http://stanza.run/bio
ArXiV: https://arxiv.org/abs/2007.14640
#NLProc #NLU #Stanford #biolearning #medicallearning
{kind=link}
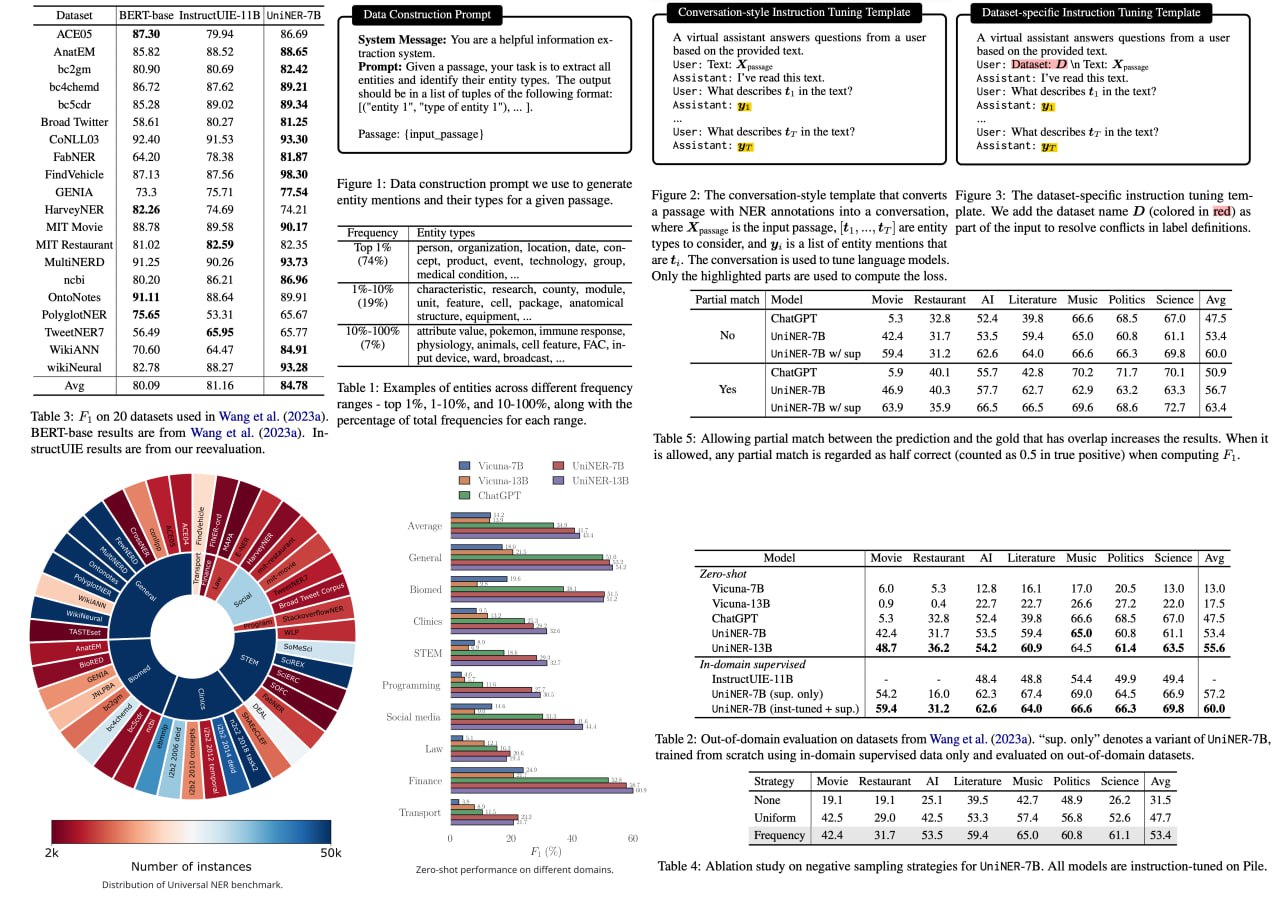
UniversalNER: Targeted Distillation from Large Language Models for Open Named Entity Recognition
The landscape of large language models (LLMs) has just been enhanced with the introduction of UniversalNER, a groundbreaking innovation using targeted distillation with mission-focused instruction tuning. The researchers managed to distill ChatGPT into more cost-efficient UniversalNER models without losing the quality of named entity recognition (NER). The study showcases how UniversalNER excels across an impressive array of 43 datasets in 9 diverse domains, outperforming other models like Alpaca and Vicuna by over 30 absolute F1 points on average.
What sets UniversalNER apart is its ability to acquire the capabilities of ChatGPT while having only a fraction of the parameters. It not only recognizes arbitrary entity types but even surpasses ChatGPT's NER accuracy by 7-9 absolute F1 points. Most remarkably, without any direct supervision, it manages to outclass even state-of-the-art multi-task systems like InstructUIE. This achievement is poised to be a game-changer in the field of NLP, offering a potent combination of efficiency and accuracy.
Paper link: https://arxiv.org/abs/2308.03279
Project link: https://universal-ner.github.io/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-universalner
#deeplearning #nlp #llm #ner
The landscape of large language models (LLMs) has just been enhanced with the introduction of UniversalNER, a groundbreaking innovation using targeted distillation with mission-focused instruction tuning. The researchers managed to distill ChatGPT into more cost-efficient UniversalNER models without losing the quality of named entity recognition (NER). The study showcases how UniversalNER excels across an impressive array of 43 datasets in 9 diverse domains, outperforming other models like Alpaca and Vicuna by over 30 absolute F1 points on average.
What sets UniversalNER apart is its ability to acquire the capabilities of ChatGPT while having only a fraction of the parameters. It not only recognizes arbitrary entity types but even surpasses ChatGPT's NER accuracy by 7-9 absolute F1 points. Most remarkably, without any direct supervision, it manages to outclass even state-of-the-art multi-task systems like InstructUIE. This achievement is poised to be a game-changer in the field of NLP, offering a potent combination of efficiency and accuracy.
Paper link: https://arxiv.org/abs/2308.03279
Project link: https://universal-ner.github.io/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-universalner
#deeplearning #nlp #llm #ner
{kind=link}