
VirTex: Learning Visual Representations from Textual Annotations
The authors offer an alternative approach to pre-training backbones for CV tasks – using semantically dense captions to learn visual representations.
Recent methods have explored unsupervised pretraining to scale to vast quantities of unlabeled images. In contrast, the authors aim to learn high-quality visual representations from fewer images. They revisit supervised pretraining and seek data-efficient alternatives to classification-based pretraining.
VirTex (CNN + Transformer) is pre-trained on COCO captions. On downstream tasks it can reach performance similar to pre-training on ImageNet, but with 10x less images!
Paper: https://arxiv.org/abs/2006.06666
Code: https://github.com/kdexd/virtex
Site: https://kdexd.github.io/virtex/
#imagecaptioning #cv #visual #annotation #transformer #pretraining #transferlearning #deeplearning #paper
The authors offer an alternative approach to pre-training backbones for CV tasks – using semantically dense captions to learn visual representations.
Recent methods have explored unsupervised pretraining to scale to vast quantities of unlabeled images. In contrast, the authors aim to learn high-quality visual representations from fewer images. They revisit supervised pretraining and seek data-efficient alternatives to classification-based pretraining.
VirTex (CNN + Transformer) is pre-trained on COCO captions. On downstream tasks it can reach performance similar to pre-training on ImageNet, but with 10x less images!
Paper: https://arxiv.org/abs/2006.06666
Code: https://github.com/kdexd/virtex
Site: https://kdexd.github.io/virtex/
#imagecaptioning #cv #visual #annotation #transformer #pretraining #transferlearning #deeplearning #paper
{kind=link}
ReXNet: Diminishing Representational Bottleneck on Convolutional Neural Network
The authors propose a set of design principles that improves model performance significantly based on the analysis of representation bottlenecks.
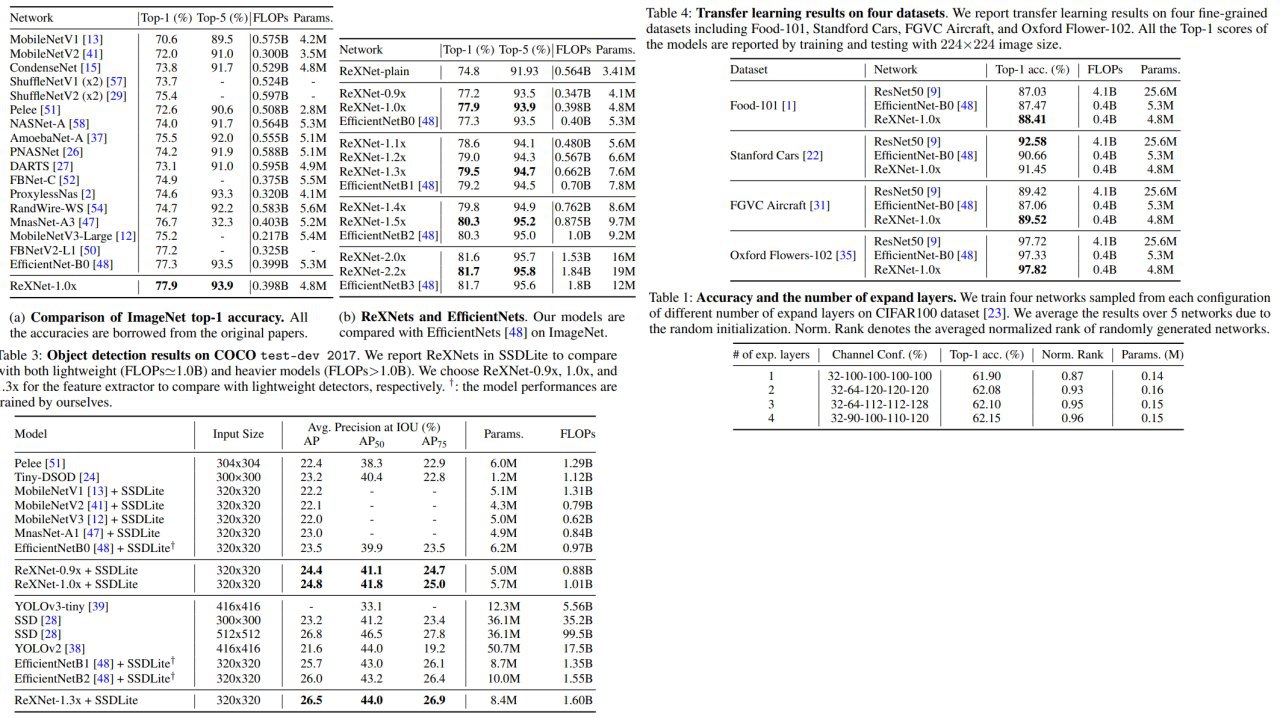
Authors think that commonly used architectures have a representation bottleneck and try to fix it by expanding channel size, using more expand layers, and better activation functions. This also improves the performance of models on ImageNet and good results on transfer learning on classification and object detection.
Authors hope that their design ideas could be used by NAS to create even better models.
Paper: https://arxiv.org/abs/2007.00992
Code: https://github.com/clovaai/rexnet
#deeplearning #pretraining #transferlearning #computervision #pytorch
The authors propose a set of design principles that improves model performance significantly based on the analysis of representation bottlenecks.
Authors think that commonly used architectures have a representation bottleneck and try to fix it by expanding channel size, using more expand layers, and better activation functions. This also improves the performance of models on ImageNet and good results on transfer learning on classification and object detection.
Authors hope that their design ideas could be used by NAS to create even better models.
Paper: https://arxiv.org/abs/2007.00992
Code: https://github.com/clovaai/rexnet
#deeplearning #pretraining #transferlearning #computervision #pytorch
{kind=link}
LightningDOT: Pre-training Visual-Semantic Embeddings for Real-Time Image-Text Retrieval
Pre-training transformers simultaneously on text and images proved to work quite well for model performance on multiple tasks, but such models usually have a low inference speed due to cross-modal attention. As a result, in practice, these models can hardly be used when low latency is required.
The authors of the paper offer a solution to this problem:
- pre-training on three new learning objectives
- extracting feature indexes offline
- using dot-product matching
- further re-ranking with a separate model
LightningDOT outperforms the previous state-of-the-art while significantly speeding up inference time by 600-2000× on Flickr30K and COCO image-text retrieval benchmarks.
Paper: https://arxiv.org/abs/2103.08784
Code and checkpoints will be available here:
https://github.com/intersun/LightningDOT
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-lightningdot
#pretraining #realtime #ranking #deeplearning
Pre-training transformers simultaneously on text and images proved to work quite well for model performance on multiple tasks, but such models usually have a low inference speed due to cross-modal attention. As a result, in practice, these models can hardly be used when low latency is required.
The authors of the paper offer a solution to this problem:
- pre-training on three new learning objectives
- extracting feature indexes offline
- using dot-product matching
- further re-ranking with a separate model
LightningDOT outperforms the previous state-of-the-art while significantly speeding up inference time by 600-2000× on Flickr30K and COCO image-text retrieval benchmarks.
Paper: https://arxiv.org/abs/2103.08784
Code and checkpoints will be available here:
https://github.com/intersun/LightningDOT
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-lightningdot
#pretraining #realtime #ranking #deeplearning
{kind=link}
Are Pre-trained Convolutions Better than Pre-trained Transformers?
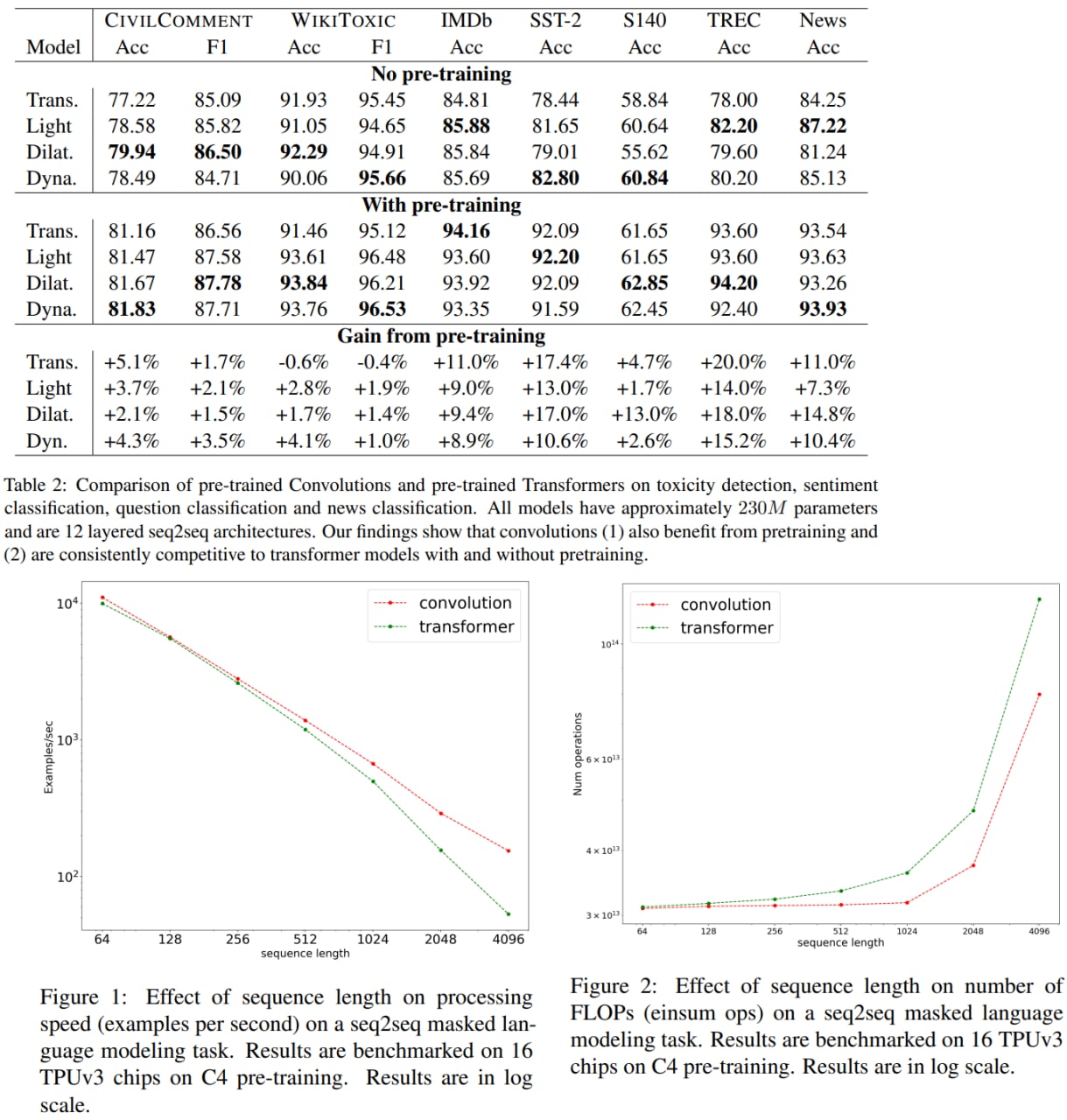
In this paper, the authors from Google Research wanted to investigate whether CNN architectures can be competitive compared to transformers on NLP problems. It turns out that pre-trained CNN models outperform pre-trained Transformers on some tasks; they also train faster and scale better to longer sequences.
Overall, the findings outlined in this paper suggest that conflating pre-training and architectural advances is misguided and that both advances should be considered independently. The authors believe their research paves the way for a healthy amount of optimism in alternative architectures.
Paper: https://arxiv.org/abs/2105.03322
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-cnnbettertransformers
#nlp #deeplearning #cnn #transformer #pretraining
In this paper, the authors from Google Research wanted to investigate whether CNN architectures can be competitive compared to transformers on NLP problems. It turns out that pre-trained CNN models outperform pre-trained Transformers on some tasks; they also train faster and scale better to longer sequences.
Overall, the findings outlined in this paper suggest that conflating pre-training and architectural advances is misguided and that both advances should be considered independently. The authors believe their research paves the way for a healthy amount of optimism in alternative architectures.
Paper: https://arxiv.org/abs/2105.03322
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-cnnbettertransformers
#nlp #deeplearning #cnn #transformer #pretraining
{kind=link}
Long Text Generation by Modeling Sentence-Level and Discourse-Level Coherence
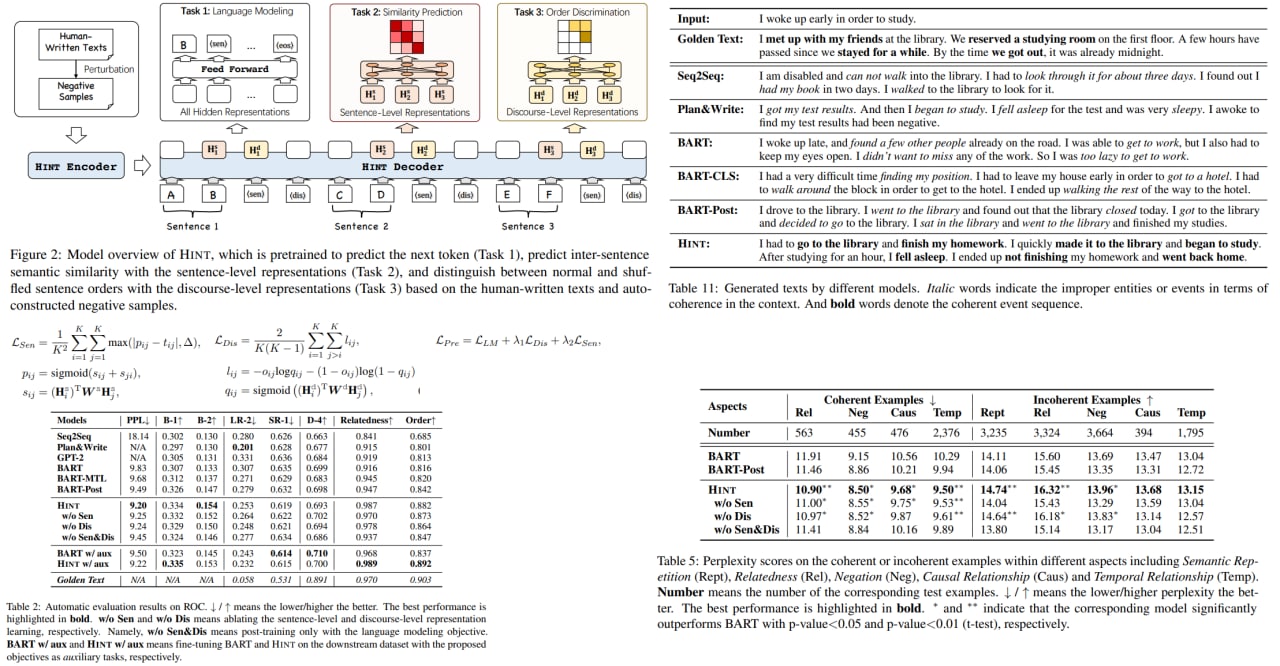
Modern NLP models still struggle with generating long and coherent texts, especially for open-ended dialogues such as story generation. The authors of the paper suggest a new model architecture HINT (a generation model equipped with HIgh-level representations for loNg Text generation) with two pre-training objectives to improve the language generation models: predicting inter-sentence semantic similarity and distinguishing between normal and shuffled sentence orders. Experiments and ablation studies show that these improvements result in more coherent texts than state-of-the-art baselines.
Paper: https://arxiv.org/abs/2105.08963
Code: https://github.com/thu-coai/HINT
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-hint
#deeplearning #nlp #nlg #pretraining
Modern NLP models still struggle with generating long and coherent texts, especially for open-ended dialogues such as story generation. The authors of the paper suggest a new model architecture HINT (a generation model equipped with HIgh-level representations for loNg Text generation) with two pre-training objectives to improve the language generation models: predicting inter-sentence semantic similarity and distinguishing between normal and shuffled sentence orders. Experiments and ablation studies show that these improvements result in more coherent texts than state-of-the-art baselines.
Paper: https://arxiv.org/abs/2105.08963
Code: https://github.com/thu-coai/HINT
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-hint
#deeplearning #nlp #nlg #pretraining
{kind=link}
ByT5: Towards a token-free future with pre-trained byte-to-byte models
Pre-trained language models usually operate on the sequences of tokens, which are based on words or subword units.
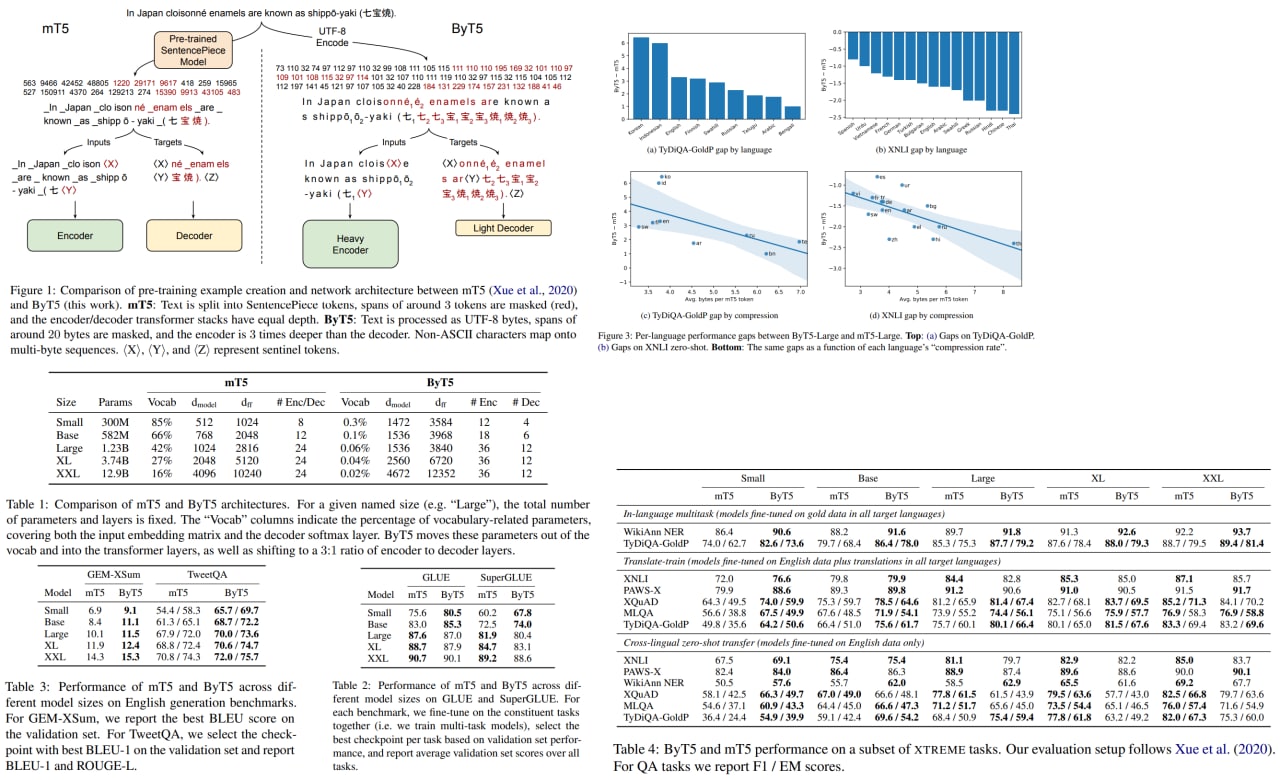
Token-free models operate directly on the raw text (characters or bytes) instead. They can work with any language, are more robust to the noise, and don’t require preprocessing.
The authors use a modified mT5 architecture and show that their approach is competitive with token-level models.
Paper: https://arxiv.org/abs/2105.13626
Code: https://github.com/google-research/byt5
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-byt5
#nlp #deeplearning #transformer #pretraining
Pre-trained language models usually operate on the sequences of tokens, which are based on words or subword units.
Token-free models operate directly on the raw text (characters or bytes) instead. They can work with any language, are more robust to the noise, and don’t require preprocessing.
The authors use a modified mT5 architecture and show that their approach is competitive with token-level models.
Paper: https://arxiv.org/abs/2105.13626
Code: https://github.com/google-research/byt5
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-byt5
#nlp #deeplearning #transformer #pretraining
{kind=link}
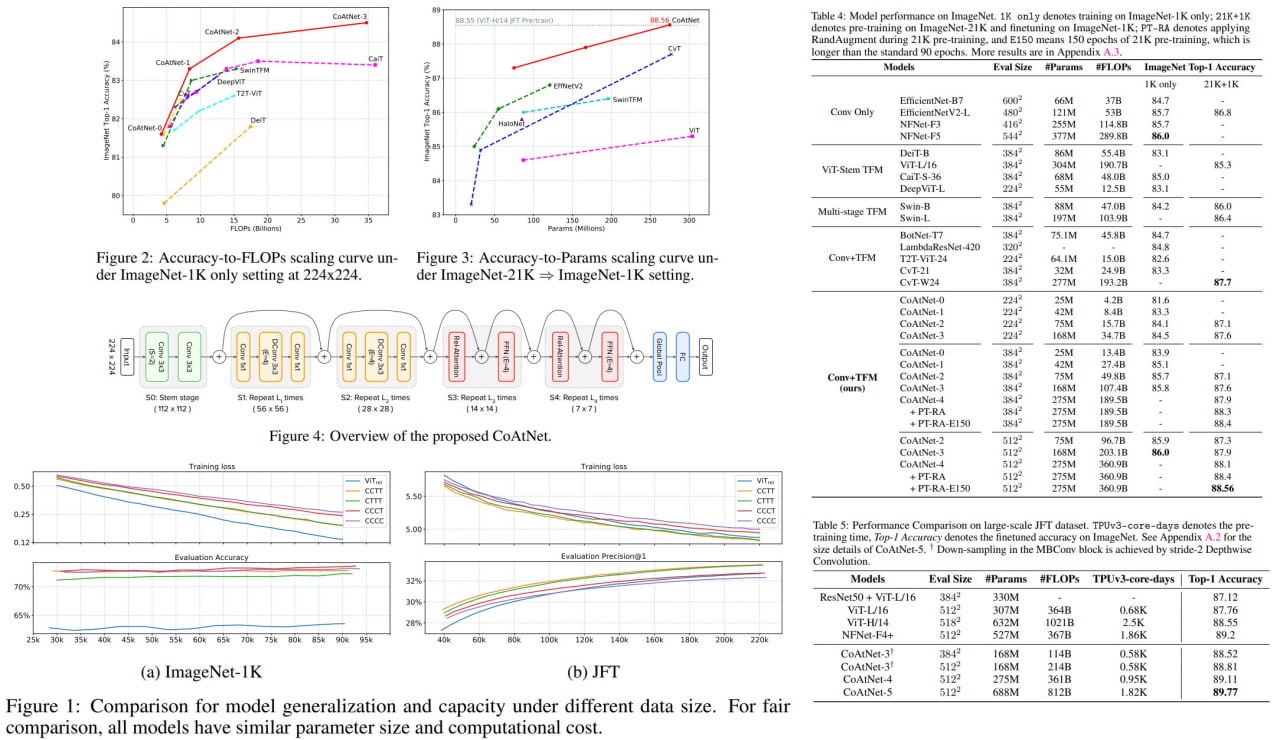
CoAtNet: Marrying Convolution and Attention for All Data Sizes
This is a paper on combining CNN and attention for Computer Vision tasks by Google Research.
The authors unify depthwise convolutions and self-attention via relative attention and vertically stack attention and convolutional layers in a specific way.
Resulting CoAtNets have good generalization, capacity and efficiency.
CoAtNet achieves 86.0% ImageNet top-1 accuracy without extra data and 89.77% with extra JFT data, outperforming the prior state of the art of both convolutional networks and Transformers. Notably, when pre-trained with 13M images from ImageNet-21K, CoAtNet achieves 88.56% top-1 accuracy, matching ViT-huge pre-trained with 300M images from JFT while using 23x less data.
Paper: https://arxiv.org/abs/2106.04803
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-coatnet
#cv #deeplearning #transformer #pretraining
This is a paper on combining CNN and attention for Computer Vision tasks by Google Research.
The authors unify depthwise convolutions and self-attention via relative attention and vertically stack attention and convolutional layers in a specific way.
Resulting CoAtNets have good generalization, capacity and efficiency.
CoAtNet achieves 86.0% ImageNet top-1 accuracy without extra data and 89.77% with extra JFT data, outperforming the prior state of the art of both convolutional networks and Transformers. Notably, when pre-trained with 13M images from ImageNet-21K, CoAtNet achieves 88.56% top-1 accuracy, matching ViT-huge pre-trained with 300M images from JFT while using 23x less data.
Paper: https://arxiv.org/abs/2106.04803
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-coatnet
#cv #deeplearning #transformer #pretraining
{kind=link}
NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion
In this paper, Microsoft Research Asia and Peking University researchers share a unified multimodal (texts, images, videos, sketches) pre-trained model called NÜWA that can generate new or manipulate existing visual data for various visual synthesis tasks. Furthermore, they have designed a 3D transformer encoder-decoder framework with a 3D Nearby Attention (3DNA) mechanism to consider the nature of the visual data and reduce the computational complexity.
NÜWA achieves state-of-the-art results on text-to-image generation, text-to-video generation, video prediction, and several other tasks and demonstrates good results on zero-shot text-guided image and video manipulation tasks.
Paper: https://arxiv.org/abs/2111.12417
Code: https://github.com/microsoft/NUWA
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-nuwa
#deeplearning #cv #transformer #pretraining
In this paper, Microsoft Research Asia and Peking University researchers share a unified multimodal (texts, images, videos, sketches) pre-trained model called NÜWA that can generate new or manipulate existing visual data for various visual synthesis tasks. Furthermore, they have designed a 3D transformer encoder-decoder framework with a 3D Nearby Attention (3DNA) mechanism to consider the nature of the visual data and reduce the computational complexity.
NÜWA achieves state-of-the-art results on text-to-image generation, text-to-video generation, video prediction, and several other tasks and demonstrates good results on zero-shot text-guided image and video manipulation tasks.
Paper: https://arxiv.org/abs/2111.12417
Code: https://github.com/microsoft/NUWA
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-nuwa
#deeplearning #cv #transformer #pretraining
{kind=link}
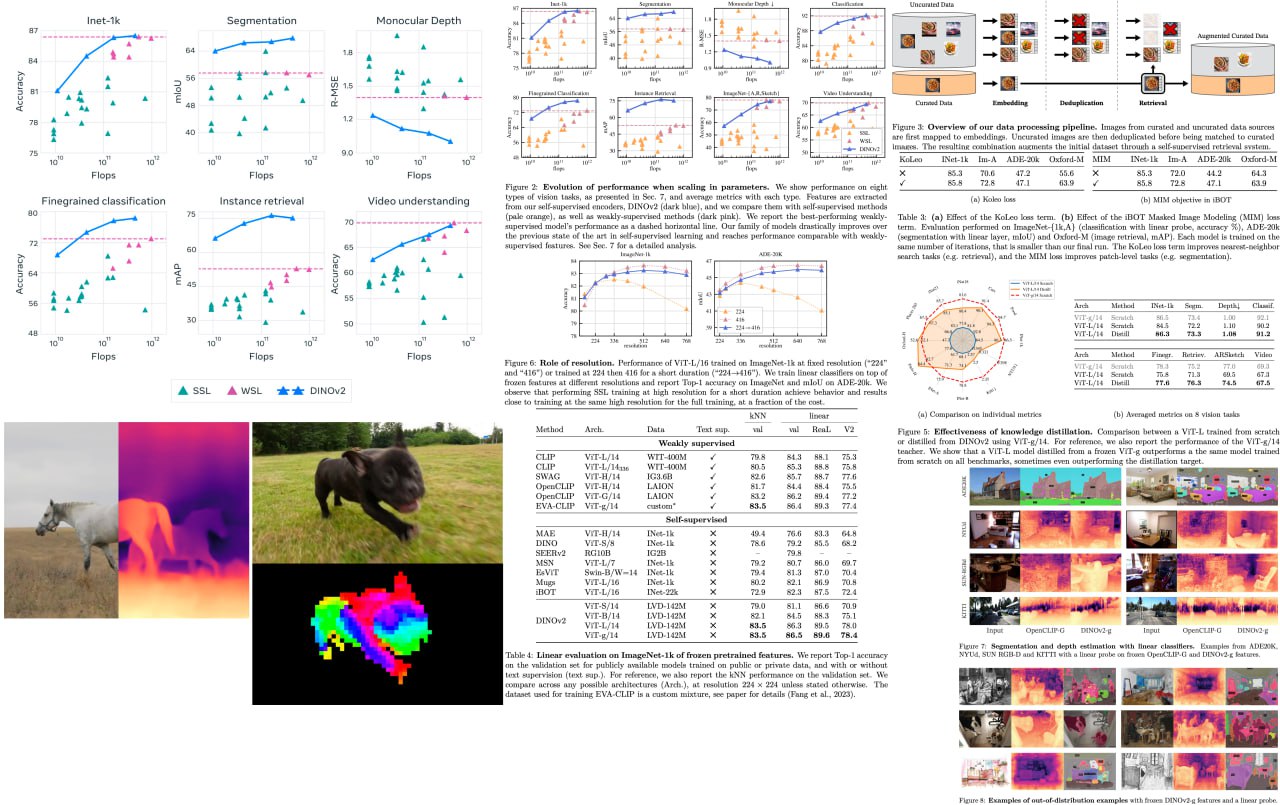
DINOv2: Learning Robust Visual Features without Supervision
Get ready for a game-changer in computer vision! Building on the groundbreaking achievements in natural language processing, foundation models are revolutionizing the way we use images in various systems. By generating all-purpose visual features that excel across diverse image distributions and tasks without finetuning, these models are set to redefine the field.
The researchers behind this work have combined cutting-edge techniques to scale pretraining in terms of data and model size, turbocharging the training process like never before. They've devised an ingenious automatic pipeline to create a rich, diverse, and curated image dataset, setting a new standard in the self-supervised literature. To top it off, they've trained a colossal ViT model with a staggering 1 billion parameters and distilled it into a series of smaller, ultra-efficient models. These models outshine the best available all-purpose features, OpenCLIP, on most benchmarks at both image and pixel levels.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dinov2
Project link: https://dinov2.metademolab.com/
#deeplearning #cv #pytorch #imagesegmentation #sota #pretraining
Get ready for a game-changer in computer vision! Building on the groundbreaking achievements in natural language processing, foundation models are revolutionizing the way we use images in various systems. By generating all-purpose visual features that excel across diverse image distributions and tasks without finetuning, these models are set to redefine the field.
The researchers behind this work have combined cutting-edge techniques to scale pretraining in terms of data and model size, turbocharging the training process like never before. They've devised an ingenious automatic pipeline to create a rich, diverse, and curated image dataset, setting a new standard in the self-supervised literature. To top it off, they've trained a colossal ViT model with a staggering 1 billion parameters and distilled it into a series of smaller, ultra-efficient models. These models outshine the best available all-purpose features, OpenCLIP, on most benchmarks at both image and pixel levels.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dinov2
Project link: https://dinov2.metademolab.com/
#deeplearning #cv #pytorch #imagesegmentation #sota #pretraining
{kind=link}
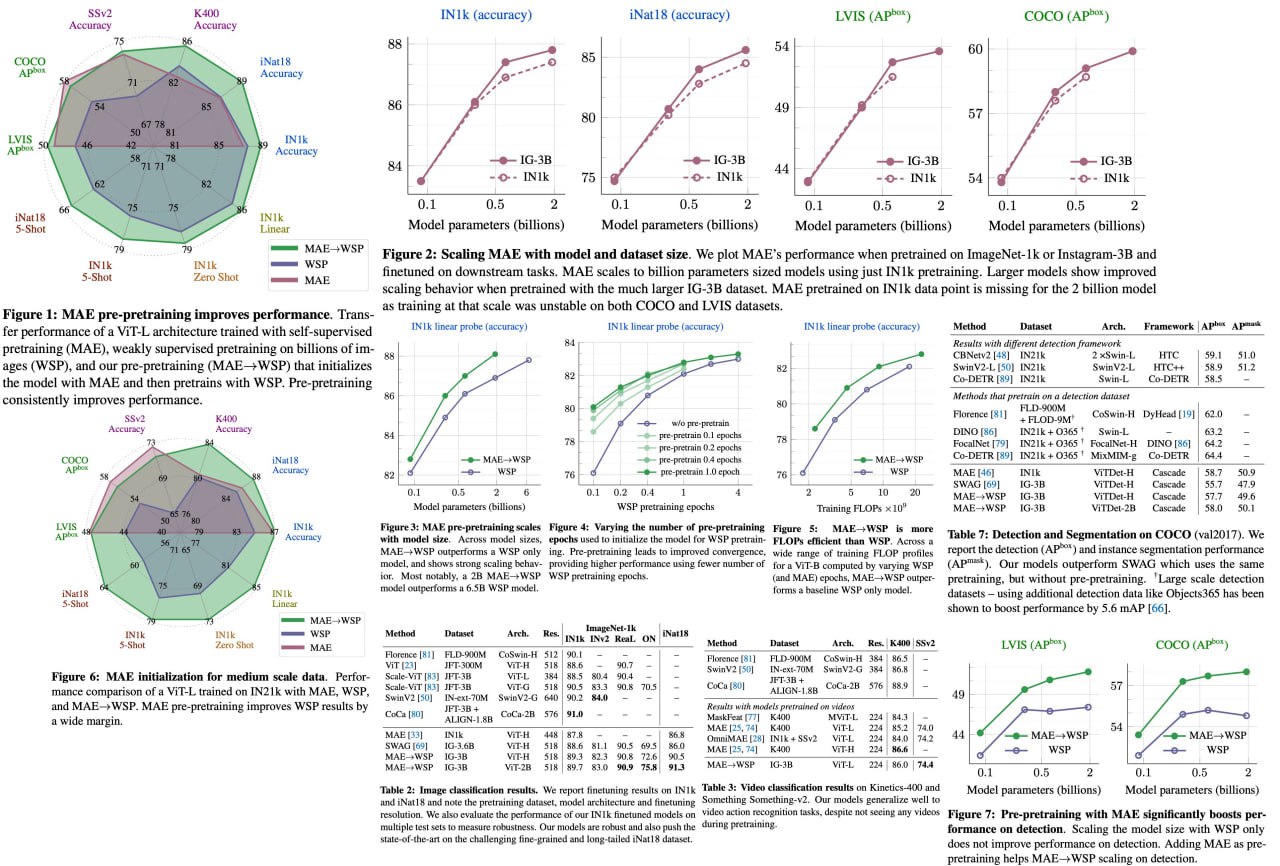
The effectiveness of MAE pre-pretraining for billion-scale pretraining
Revolutionizing the current pretrain-then-finetune paradigm of computer vision, this research has introduced an innovative pre-pretraining stage. Utilizing the Masked Autoencoder (MAE) technique for model initialization, this pre-pretraining strategy scales with the size of both the model and the data. This makes it an ideal tool for training next-generation foundation models, even on the grandest scales.
The robustness of our pre-pretraining technique is demonstrated by consistent improvement in model convergence and downstream transfer performance across diverse model scales and dataset sizes. The authors measured the effectiveness of pre-pretraining on a wide array of visual recognition tasks, and the results have been promising. The ielargest model achieved unprecedented results on iNaturalist-18 (91.3%), 1-shot ImageNet-1k (62.1%), and zero-shot transfer on Food-101 (96.0%), underlining the tremendous potential of proper model initialization, even when handling web-scale pretraining with billions of images.
Paper link: https://arxiv.org/abs/2303.13496
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-mae-pretrain
#deeplearning #cv #pretraining #selfsupervisedlearning
Revolutionizing the current pretrain-then-finetune paradigm of computer vision, this research has introduced an innovative pre-pretraining stage. Utilizing the Masked Autoencoder (MAE) technique for model initialization, this pre-pretraining strategy scales with the size of both the model and the data. This makes it an ideal tool for training next-generation foundation models, even on the grandest scales.
The robustness of our pre-pretraining technique is demonstrated by consistent improvement in model convergence and downstream transfer performance across diverse model scales and dataset sizes. The authors measured the effectiveness of pre-pretraining on a wide array of visual recognition tasks, and the results have been promising. The ielargest model achieved unprecedented results on iNaturalist-18 (91.3%), 1-shot ImageNet-1k (62.1%), and zero-shot transfer on Food-101 (96.0%), underlining the tremendous potential of proper model initialization, even when handling web-scale pretraining with billions of images.
Paper link: https://arxiv.org/abs/2303.13496
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-mae-pretrain
#deeplearning #cv #pretraining #selfsupervisedlearning
{kind=link}