Приветственный пост
Рады приветствовать всех на нашем канале!
Вы устали от скучного, монотонного, обезличенного контента по плюсам?
Тогда мы идем к вам!
Здесь не будет бесполезных 30 IQ постов, сгенеренных ChatGPT, накрученных подписчиков и активности.
Канал ведут два сеньора, Денис и Владимир, которые искренне хотят делится своими знаниями по С++ и создать самое уютное коммьюнити позитивных прогеров в телеге!
(ну вы поняли, да? с++, плюс плюс, плюс типа
позитивный?.. ай ладно)
Жмакай и попадешь в наш чат. Там обсуждения не привязаны к постам, можете общаться на любые темы.
Материалы для новичка
ГАЙДЫ:
Мини-гайд по собеседованиям
Гайд по тестовым заданиям
Гайд по категория выражения и мув-семантике
Гайд по inline
Дальше пойдет список хэштегов, которыми вы можете пользоваться для более удобной навигации по каналу и для быстрого поиска группы постов по интересующей теме:
#algorithms
#datastructures
#cppcore
#stl
#goodoldc
#cpp11
#cpp14
#cpp17
#cpp20
#commercial
#net
#database
#hardcore
#memory
#goodpractice
#howitworks
#NONSTANDARD
#interview
#digest
#OS
#tools
#optimization
#performance
#fun
#compiler
#design
#exception
#guide
#задачки
#base
#quiz
#concurrency
#ЧЗХ
#ревью
Рады приветствовать всех на нашем канале!
Вы устали от скучного, монотонного, обезличенного контента по плюсам?
Тогда мы идем к вам!
Здесь не будет бесполезных 30 IQ постов, сгенеренных ChatGPT, накрученных подписчиков и активности.
Канал ведут два сеньора, Денис и Владимир, которые искренне хотят делится своими знаниями по С++ и создать самое уютное коммьюнити позитивных прогеров в телеге!
(ну вы поняли, да? с++, плюс плюс, плюс типа
позитивный?.. ай ладно)
Жмакай и попадешь в наш чат. Там обсуждения не привязаны к постам, можете общаться на любые темы.
Материалы для новичка
ГАЙДЫ:
Мини-гайд по собеседованиям
Гайд по тестовым заданиям
Гайд по категория выражения и мув-семантике
Гайд по inline
Дальше пойдет список хэштегов, которыми вы можете пользоваться для более удобной навигации по каналу и для быстрого поиска группы постов по интересующей теме:
#algorithms
#datastructures
#cppcore
#stl
#goodoldc
#cpp11
#cpp14
#cpp17
#cpp20
#commercial
#net
#database
#hardcore
#memory
#goodpractice
#howitworks
#NONSTANDARD
#interview
#digest
#OS
#tools
#optimization
#performance
#fun
#compiler
#design
#exception
#guide
#задачки
#base
#quiz
#concurrency
#ЧЗХ
#ревью
Telegram
Грокаем C++ Chat
You’ve been invited to join this group on Telegram.
🔥37❤19👍15🤔2🐳1
Указатель на void
Тот случай, когда тема сишная, но знать это надо и это довольно часто встречается в плюсовых проектах.
Естественно, это все про сишные интерфейсы и C-style функции. Мы все с этим сталкивается, ничего не поделать.
Нетипизированный указатель - очень крутая штука в контексте Си. Он предоставляет возможность до определенной степени использовать обобщенное программирование. Самый очевидный пример - malloc. Он выделяет память заданного размера и выдает указатель на начало этого куска. Функция не знает, как будет использоваться память и под какие структуры. Поэтому перекладывает на программиста ответственность за то, как дальше память будет использована. А программист должен скастовать void* к типизированному указателю, чтобы получить доступ к структуре. Но зачем?
Дело в том, что любой указатель - просто 8-мибайтное число, указывающее на какую-то точку в памяти. Но объекты и структуры - это не точки. Это отрезки. От и до. Поэтому компиллятору надо знать размер области памяти, чтобы достать оттуда информацию. Отсюда и правило, что разыменовывать void* нельзя. Отсюда и второе правило, что адресная арифметика неприменима к void*. Поэтому нужны типизированные указатели. Любой определенный тип имеет вполне конкретный размер, известный компилятору. И когда мы храним указатель на этот тип, мы говорим условному gcc "тут лежит объект и, чтобы откопать его, копай на 4 байта вправо от указателя".
В этом и прикол указателя на воид - если у функции есть такой параметр, мы можем передать туда все что угодно. Отсюда мы имеем 2 основных сценария использования таких указателей.
Первый - дженерик функции, работающие с любым типом. Главное знать размер этого типа. Типичные примеры: стандартный memcpy или какой-нибудь кастомный bytesToHexString
Второй - передача параметров callback функциям, когда типы параметров неизвестны вызывающему коду. Для примера, посмотрите функцию qsort. Она принимает компаратор с двумя параметрами - void*. Это необходимо, так как сама qsort не знает, с какими данными она работает и передает их в callback как есть, в виде void*.
Stay cool.
#cppcore #goodoldc #memory
Тот случай, когда тема сишная, но знать это надо и это довольно часто встречается в плюсовых проектах.
Естественно, это все про сишные интерфейсы и C-style функции. Мы все с этим сталкивается, ничего не поделать.
Нетипизированный указатель - очень крутая штука в контексте Си. Он предоставляет возможность до определенной степени использовать обобщенное программирование. Самый очевидный пример - malloc. Он выделяет память заданного размера и выдает указатель на начало этого куска. Функция не знает, как будет использоваться память и под какие структуры. Поэтому перекладывает на программиста ответственность за то, как дальше память будет использована. А программист должен скастовать void* к типизированному указателю, чтобы получить доступ к структуре. Но зачем?
Дело в том, что любой указатель - просто 8-мибайтное число, указывающее на какую-то точку в памяти. Но объекты и структуры - это не точки. Это отрезки. От и до. Поэтому компиллятору надо знать размер области памяти, чтобы достать оттуда информацию. Отсюда и правило, что разыменовывать void* нельзя. Отсюда и второе правило, что адресная арифметика неприменима к void*. Поэтому нужны типизированные указатели. Любой определенный тип имеет вполне конкретный размер, известный компилятору. И когда мы храним указатель на этот тип, мы говорим условному gcc "тут лежит объект и, чтобы откопать его, копай на 4 байта вправо от указателя".
В этом и прикол указателя на воид - если у функции есть такой параметр, мы можем передать туда все что угодно. Отсюда мы имеем 2 основных сценария использования таких указателей.
Первый - дженерик функции, работающие с любым типом. Главное знать размер этого типа. Типичные примеры: стандартный memcpy или какой-нибудь кастомный bytesToHexString
Второй - передача параметров callback функциям, когда типы параметров неизвестны вызывающему коду. Для примера, посмотрите функцию qsort. Она принимает компаратор с двумя параметрами - void*. Это необходимо, так как сама qsort не знает, с какими данными она работает и передает их в callback как есть, в виде void*.
Stay cool.
#cppcore #goodoldc #memory
{kind=link}
❤17👍6🔥5
Копаемся в маллоке
Короче. Попробуем новый формат на канале - статьи. Вот пожалуйста ссылочка https://telegra.ph/Nahodim-razmer-bloka-malloc-11-30. Это продолжение песни, начатой здесь. Инфы там многовато, поэтому пришлось в немного более длинном формате ее упаковать.
Было прикольно немного поисследовать вопрос, лично я кайфанул во время писания статьи.
Пишите свои мысли по поводу вопроса. Буду рад пообсуждать в комментах.
You are the best.
#fun #howitworks #memory #goodoldc #hardcore
Короче. Попробуем новый формат на канале - статьи. Вот пожалуйста ссылочка https://telegra.ph/Nahodim-razmer-bloka-malloc-11-30. Это продолжение песни, начатой здесь. Инфы там многовато, поэтому пришлось в немного более длинном формате ее упаковать.
Было прикольно немного поисследовать вопрос, лично я кайфанул во время писания статьи.
Пишите свои мысли по поводу вопроса. Буду рад пообсуждать в комментах.
You are the best.
#fun #howitworks #memory #goodoldc #hardcore
Telegraph
Находим размер блока malloc
Недавно рассказывал в общих чертах про то, как malloc на самом деле аллоцирует память. Попробуем теперь самостоятельно найти нужную циферку. Почти очевидно, что размер должен храниться с отрицательным смещением от указателя на начало блока. Размер ведь динамический…
❤11👍5🔥3
Variable length array
У большинства разработчиков есть стереотип, что С++ - это надмножество Си. Плюсовики же знают, что это не так, но зачастую на вопрос о различиях ничего ответить не могут. Так и что же есть такого в Си, чего нет в С++? Сделаю оговорку, что сейчас речь пойдет только о стандартах языков. Так как любой кастомный крестовый компилятор может поддерживать те или иные фичи языка Си. Это называется расширения компилятора. Мы всё-таки говорим о стандарте.
Сегодня мы рассмотрим только один из примеров. Механизм называется VLA или Variable Length Array. Или массивы переменной длины. В сущности он позволяет создавать массивы, размер которых не известен на момент компиляции, а память под них выделяется в автоматической области, то есть на стеке. Синтаксис ничем не отличается от статических массивов.
int n = 10;
int array[n];
Во всех учебниках по С++ написано, что создание динамических массивов на стеке запрещено и код выше запрещен стандартом (у значение переменной n нет квалификатора const). Однако в Си это часть стандарта, начиная с С99.
Фича довольно полезная в контексте простоты написания кода, не нужно городить дополнительных конструкций с выделением динамической памяти. Да и само выделение на стеке быстрее и операции с его памятью тоже происходят ощутимо быстрее. Однако всегда есть опасность выделить слишком много памяти и словить переполнение. Из-за этого о фиче мнение неоднозначно. В самом сишном стандарте то ограничивают ее, то вновь вводят поддержку в С23. А в один момент времени она даже была в драфте плюсового стандарта 14 года. Но на момент релиза ее убрали оттуда. Из-за этого кстати в некоторых компиляторах, например гцц, есть поддержка VLA. И код выше там скомпиляруется. Как-то я и сам неосознанно ею пользовался для написания небольшой библиотечки. А потом мне на ревью сказали, что вместо динамических массивов на стеке в плюсах принято пользоваться вектором. Так бы и не узнал, что использую запрещенку.
Но то, что в gcc есть поддержка vla, не значит, что она реализована так, как это предполагается по сишному стандарту. vla - лишь одна из граней variable length types. И в контексте этого понятия поведение кода, написанном на чистом С и на плюсах под гцц, будет разным. Не будем углубляться в детали. Просто надо понимать, что в данном случае лучше не использовать это расширение gcc, да и в принципе стараться придерживаться стандарта.
Stay cool.
#goodoldc
У большинства разработчиков есть стереотип, что С++ - это надмножество Си. Плюсовики же знают, что это не так, но зачастую на вопрос о различиях ничего ответить не могут. Так и что же есть такого в Си, чего нет в С++? Сделаю оговорку, что сейчас речь пойдет только о стандартах языков. Так как любой кастомный крестовый компилятор может поддерживать те или иные фичи языка Си. Это называется расширения компилятора. Мы всё-таки говорим о стандарте.
Сегодня мы рассмотрим только один из примеров. Механизм называется VLA или Variable Length Array. Или массивы переменной длины. В сущности он позволяет создавать массивы, размер которых не известен на момент компиляции, а память под них выделяется в автоматической области, то есть на стеке. Синтаксис ничем не отличается от статических массивов.
int n = 10;
int array[n];
Во всех учебниках по С++ написано, что создание динамических массивов на стеке запрещено и код выше запрещен стандартом (у значение переменной n нет квалификатора const). Однако в Си это часть стандарта, начиная с С99.
Фича довольно полезная в контексте простоты написания кода, не нужно городить дополнительных конструкций с выделением динамической памяти. Да и само выделение на стеке быстрее и операции с его памятью тоже происходят ощутимо быстрее. Однако всегда есть опасность выделить слишком много памяти и словить переполнение. Из-за этого о фиче мнение неоднозначно. В самом сишном стандарте то ограничивают ее, то вновь вводят поддержку в С23. А в один момент времени она даже была в драфте плюсового стандарта 14 года. Но на момент релиза ее убрали оттуда. Из-за этого кстати в некоторых компиляторах, например гцц, есть поддержка VLA. И код выше там скомпиляруется. Как-то я и сам неосознанно ею пользовался для написания небольшой библиотечки. А потом мне на ревью сказали, что вместо динамических массивов на стеке в плюсах принято пользоваться вектором. Так бы и не узнал, что использую запрещенку.
Но то, что в gcc есть поддержка vla, не значит, что она реализована так, как это предполагается по сишному стандарту. vla - лишь одна из граней variable length types. И в контексте этого понятия поведение кода, написанном на чистом С и на плюсах под гцц, будет разным. Не будем углубляться в детали. Просто надо понимать, что в данном случае лучше не использовать это расширение gcc, да и в принципе стараться придерживаться стандарта.
Stay cool.
#goodoldc
{kind=link}
👍15🏆2❤🔥1
Как использовать RAII с сишным API
Все мы с вами используем сишный API. Базы данных, работа с сетью, криптография. Перечислять области можно долго. И все мы с вами немного недолюбливаем такой способ взаимодействия с сущностями. Оно и понятно. Не зря умные дяди придумывали объектно-ориентированное программирование и не зря мы, не такие умные дяди, стараемся этой методологии следовать. А тут нужны какие-то сырые указатели, байтовые буфферы и прочие вульгарности. Это не только неудобно, но может приводить к трудноотловимым ошибкам, недостаточной гарантии безопасности. Старшие ребята, естественно, знают, как правильно использовать плюсовые объекты в таких случаях, а вот молодняк может не знать этого или не осознавать подходов, которые они использовали. Поэтому поделюсь своей интерпретацией адекватного подхода, который поможет грамотно использовать RAII с сишным апи.
На помощь нам неожиданно приходят std::array и std::vector. Это простые RAII обертки над статическими и динамическими массивами, которые предлагают следующие фичи:
1️⃣ Автоматическое управление памятью. std::array в конструкторе аллоцирует память на стеке, std::vector - на куче. Их деструктор вызывается при выходе из скоупа.
2️⃣ Детерминированная инициализация. Инициализация этих контейнеров происходи в конструкторе, что предотвращает обращение к неинициализированной памяти.
3️⃣ Безопасный и удобный доступ к элементам с помощью методов .at(), .back(), .front() и итераторов.
4️⃣ Легкий доступ к буферу через метод .data().
Как их использовать для взаимодействия с С API? Гениально и просто.
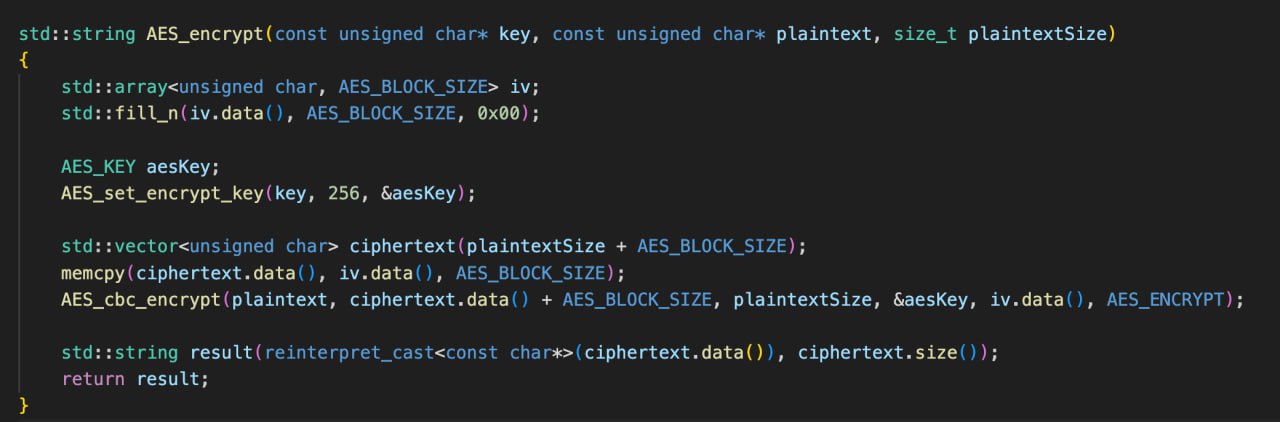
👉🏿 Объявить нужный массив. Если размер структуры известен на момент компиляции - std::array, если нет - std::vector. Инициализировать его в конструкторе нужными значениями: дефолтовыми - в конструкторе, кастомными - через memcpy(array_ptr, struct_ptr, struct_size).
👉🏿 Передать в Сишный апи. Например так:
AES_cbc_encrypt(plaintext_array.data, ciphertext_array.size(), plaintext_array.size() ...);
👉🏿 Наслаждаться жизнью, ибо больше вам не нужно ни о чем беспокоиться.
Если уж вы передаете в С API более сложные структуры, чем массивы, то вам могут понадобиться методы сериализации и десериализации.
Используя возможности RAII массивов вы можете упростить и оптимизировать свой код, гарантировать правильное управление памятью и безопасную передачу данных в С API.
Делитесь своим опытом взаимодействия с API C и используйте modern C++ для более надежного и эффективного кода.
Stay cool.
#goodoldc #design #cppcore #STL
Все мы с вами используем сишный API. Базы данных, работа с сетью, криптография. Перечислять области можно долго. И все мы с вами немного недолюбливаем такой способ взаимодействия с сущностями. Оно и понятно. Не зря умные дяди придумывали объектно-ориентированное программирование и не зря мы, не такие умные дяди, стараемся этой методологии следовать. А тут нужны какие-то сырые указатели, байтовые буфферы и прочие вульгарности. Это не только неудобно, но может приводить к трудноотловимым ошибкам, недостаточной гарантии безопасности. Старшие ребята, естественно, знают, как правильно использовать плюсовые объекты в таких случаях, а вот молодняк может не знать этого или не осознавать подходов, которые они использовали. Поэтому поделюсь своей интерпретацией адекватного подхода, который поможет грамотно использовать RAII с сишным апи.
На помощь нам неожиданно приходят std::array и std::vector. Это простые RAII обертки над статическими и динамическими массивами, которые предлагают следующие фичи:
1️⃣ Автоматическое управление памятью. std::array в конструкторе аллоцирует память на стеке, std::vector - на куче. Их деструктор вызывается при выходе из скоупа.
2️⃣ Детерминированная инициализация. Инициализация этих контейнеров происходи в конструкторе, что предотвращает обращение к неинициализированной памяти.
3️⃣ Безопасный и удобный доступ к элементам с помощью методов .at(), .back(), .front() и итераторов.
4️⃣ Легкий доступ к буферу через метод .data().
Как их использовать для взаимодействия с С API? Гениально и просто.
👉🏿 Объявить нужный массив. Если размер структуры известен на момент компиляции - std::array, если нет - std::vector. Инициализировать его в конструкторе нужными значениями: дефолтовыми - в конструкторе, кастомными - через memcpy(array_ptr, struct_ptr, struct_size).
👉🏿 Передать в Сишный апи. Например так:
AES_cbc_encrypt(plaintext_array.data, ciphertext_array.size(), plaintext_array.size() ...);
👉🏿 Наслаждаться жизнью, ибо больше вам не нужно ни о чем беспокоиться.
Если уж вы передаете в С API более сложные структуры, чем массивы, то вам могут понадобиться методы сериализации и десериализации.
Используя возможности RAII массивов вы можете упростить и оптимизировать свой код, гарантировать правильное управление памятью и безопасную передачу данных в С API.
Делитесь своим опытом взаимодействия с API C и используйте modern C++ для более надежного и эффективного кода.
Stay cool.
#goodoldc #design #cppcore #STL
{kind=link}
❤3👍3🔥2
Квантовая суперпозиция bool переменных
Наверно у многих в головах давно лежит прямая и четкая ассоциация, что тип данных bool всегда принимает значение true или false. Спешу развеять ваши убеждения!
На первый взгляд кажется, что такая ветка условия никогда не может быть выполнена:
Но, неожиданно и к сожалению, у менять есть вот такой пример: https://compiler-explorer.com/z/jf7zE64eq
С точки зрения ожидаемой модели языка C++ это невозможно, т.к. модель не предполагает какого-либо еще состояния логической переменной. Однако, если знать, что находится под капотом булей, то все становится вполне очевидным.
Небольшой экскурс в историю. Раньше в языке C такого типа как bool не существовало в принципе. Вместо него использовались целочисленные переменные, такие как int. Неявное приведение происходит по правилу:
Но как мы знаем, С++ во многом совместимым с С. Следовательно, он перенимает некоторые особенности своего прародителя, поэтому логическая переменная может скрывать под собой абсолютно любое целочисленное значение! И напротив, логические константы true и false однозначно определены, как 1 и 0 соответственно.
Получается, что на самом деле мы работаем с этим:
Конечно, в С++ этого получается почти всегда избежать, т.к. есть заранее определенные константы и неявные преобразования к типу bool. Но все же иногда бывают случаи, когда этого недостаточно. Например, когда переменная осталась неинициализированной.
Чисто теоретически можно создать другие, очень специфичные условия. Приведу другой пример, но напоминаю -- это UB: https://compiler-explorer.com/z/fn6YPvnzP
Да, просто под капотом сравнивается
У вас могут появиться вопросы, зачем нам может понадобиться такое знание? Это ведь, фактически, UB, которое надо постараться воспроизвести!
Приведу практический пример из моей опыта. Я написал этот код несколько лет назад. Мне хотелось избежать лишних условных ветвлений в коде и написать что-то типа такого:
А-ля, если логическая переменная
Пока что этот код не выстрелил :) Но я вижу его проблему... Так что перепроверяйте некоторые очевидные убеждения и пишите безопасный код!
#hardcore #cppcore #goodoldc
Наверно у многих в головах давно лежит прямая и четкая ассоциация, что тип данных bool всегда принимает значение true или false. Спешу развеять ваши убеждения!
На первый взгляд кажется, что такая ветка условия никогда не может быть выполнена:
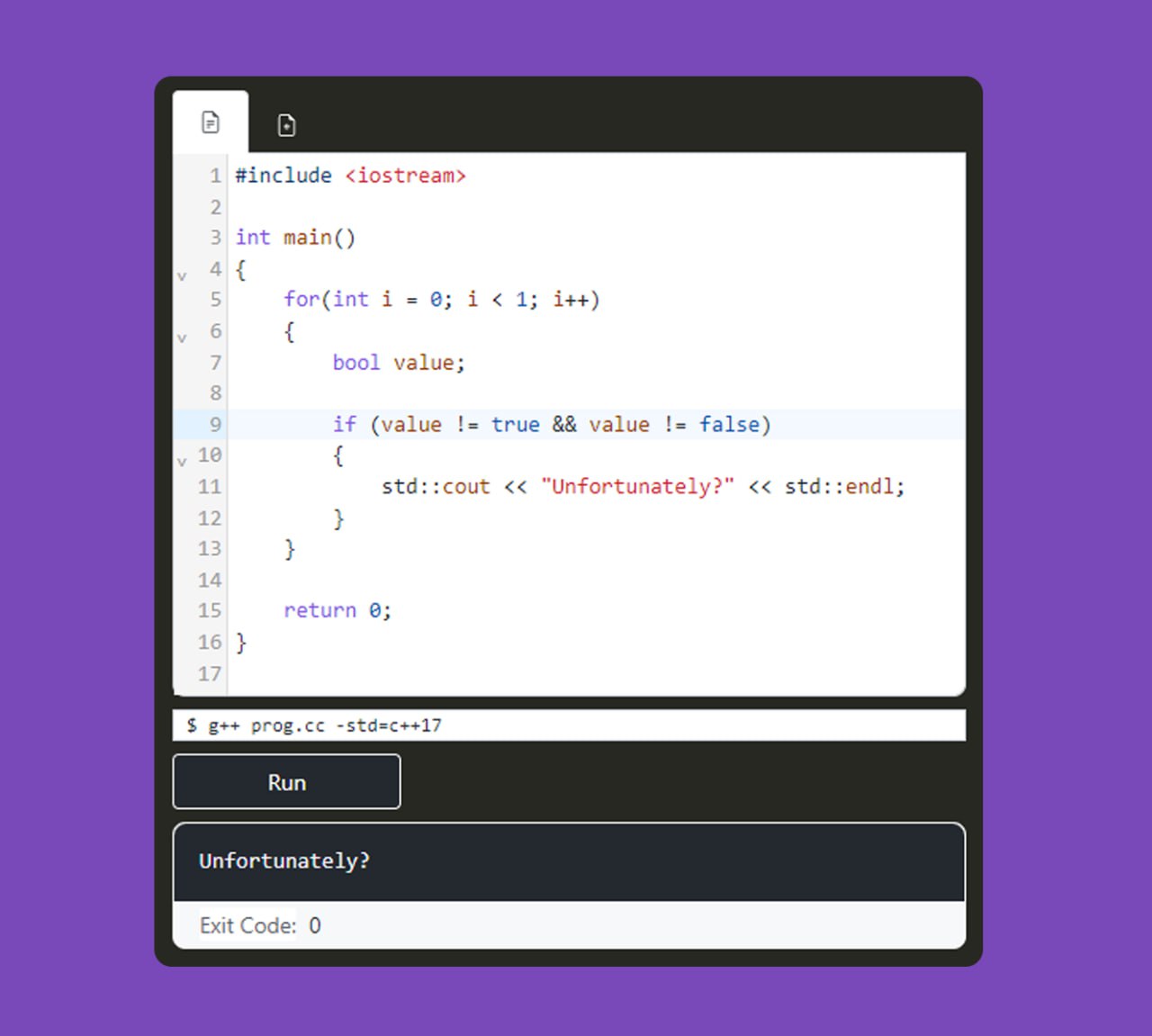
bool condition;
if (condition != true && condition != false)
{
// Недостижимый код?
}
Но, неожиданно и к сожалению, у менять есть вот такой пример: https://compiler-explorer.com/z/jf7zE64eq
С точки зрения ожидаемой модели языка C++ это невозможно, т.к. модель не предполагает какого-либо еще состояния логической переменной. Однако, если знать, что находится под капотом булей, то все становится вполне очевидным.
Небольшой экскурс в историю. Раньше в языке C такого типа как bool не существовало в принципе. Вместо него использовались целочисленные переменные, такие как int. Неявное приведение происходит по правилу:
0 -> false, иначе true. Приведу пример:if ( 0) // false
if ( 1) // true
if ( 2) // true
if (-1) // true
Но как мы знаем, С++ во многом совместимым с С. Следовательно, он перенимает некоторые особенности своего прародителя, поэтому логическая переменная может скрывать под собой абсолютно любое целочисленное значение! И напротив, логические константы true и false однозначно определены, как 1 и 0 соответственно.
Получается, что на самом деле мы работаем с этим:
int condition; // Неинициализированное значение
if (condition != 1 && condition != 0)
{
// Вполне себе достимый код
}
Конечно, в С++ этого получается почти всегда избежать, т.к. есть заранее определенные константы и неявные преобразования к типу bool. Но все же иногда бывают случаи, когда этого недостаточно. Например, когда переменная осталась неинициализированной.
Чисто теоретически можно создать другие, очень специфичные условия. Приведу другой пример, но напоминаю -- это UB: https://compiler-explorer.com/z/fn6YPvnzP
Да, просто под капотом сравнивается
10 != 1 - и никакой магии. Но увидеть это порой столь же неожиданно.У вас могут появиться вопросы, зачем нам может понадобиться такое знание? Это ведь, фактически, UB, которое надо постараться воспроизвести!
Приведу практический пример из моей опыта. Я написал этот код несколько лет назад. Мне хотелось избежать лишних условных ветвлений в коде и написать что-то типа такого:
bool condition = ???;
int position = index + static_cast<int>(condition);
А-ля, если логическая переменная
condition == true (типа оно равно 1), значит index + 1, иначе index + 0. Так вот на самом деле нельзя с уверенностью сказать, какое целочисленное значение лежит под булем.Пока что этот код не выстрелил :) Но я вижу его проблему... Так что перепроверяйте некоторые очевидные убеждения и пишите безопасный код!
#hardcore #cppcore #goodoldc
{kind=link}
👍11🔥5❤3
Сравниваем циклы
Пришла в голову такая незамысловатая идея сравнить время работы разных видов циклов, в которых будут выполняться простая операция - инкремент элемента массива. Операция простая и сравнимая по затратам с затратами на само итерирование. Поэтому разница в затратах на итерирование должна сыграть весомую роль в различиях итоговых значений. Если конечно, такие различия будут.
Берем довольно солидный массивчик на 1кк элементов и в циклах будем просто инкрементировать его элементы. Если вам 1кк кажется небольшим числом и результаты будут неточными, вы правы. Результаты в любом случае будут неточные, потому что моя тачка не заточена под перформанс тестирование. Однако флуктуации можно убрать: надо запустить изменение времени много-много раз и затем усреднить результаты. При достаточном количестве запусков, результатам можно будет верить. Я выбрал его равным 100 000. Просто имперически. Не хотел ждать больше 10 мин выполнения кода)
Дальше дело техники. Шаблонная функция для измерения времени, по циклу на сбор статистики и вывод результатов.
Шо по цифрам. В целом, все довольно ожидаемо. С++-like циклы прикурили у старых-добрых Си-style циклов. За комфорт, лаконичность и объектно-ориентированность приходится платить самым дорогим, что у программиста есть - процессорными клоками. Однако не совсем ожидаемо, что разница будет ~50%. Эт довольно много, поэтому все мы на заметочку себе взяли.
Не зря в критичных узких местах все до сих пор используют сишечку. С++ хорош при описании сущностей, способе работы с ними и удобстве работы с ними. Но С - гарант качественного перформанса.
Ну и соболезнования для for_each. Им как бы и так никто не пользуется, еще и здесь унизили.
Тема сравнения производительности кажется мне интересной и в будущем думаю, что затестим еще много чего.
Measure your performance. Stay cool.
#performance #fun #goodoldc
Пришла в голову такая незамысловатая идея сравнить время работы разных видов циклов, в которых будут выполняться простая операция - инкремент элемента массива. Операция простая и сравнимая по затратам с затратами на само итерирование. Поэтому разница в затратах на итерирование должна сыграть весомую роль в различиях итоговых значений. Если конечно, такие различия будут.
Берем довольно солидный массивчик на 1кк элементов и в циклах будем просто инкрементировать его элементы. Если вам 1кк кажется небольшим числом и результаты будут неточными, вы правы. Результаты в любом случае будут неточные, потому что моя тачка не заточена под перформанс тестирование. Однако флуктуации можно убрать: надо запустить изменение времени много-много раз и затем усреднить результаты. При достаточном количестве запусков, результатам можно будет верить. Я выбрал его равным 100 000. Просто имперически. Не хотел ждать больше 10 мин выполнения кода)
Дальше дело техники. Шаблонная функция для измерения времени, по циклу на сбор статистики и вывод результатов.
Шо по цифрам. В целом, все довольно ожидаемо. С++-like циклы прикурили у старых-добрых Си-style циклов. За комфорт, лаконичность и объектно-ориентированность приходится платить самым дорогим, что у программиста есть - процессорными клоками. Однако не совсем ожидаемо, что разница будет ~50%. Эт довольно много, поэтому все мы на заметочку себе взяли.
Не зря в критичных узких местах все до сих пор используют сишечку. С++ хорош при описании сущностей, способе работы с ними и удобстве работы с ними. Но С - гарант качественного перформанса.
Ну и соболезнования для for_each. Им как бы и так никто не пользуется, еще и здесь унизили.
Тема сравнения производительности кажется мне интересной и в будущем думаю, что затестим еще много чего.
Measure your performance. Stay cool.
#performance #fun #goodoldc
{kind=link}
👍15🔥7🤔3🤡3❤1
Оптимизации компилятора
Задача компилятора - перевести код на понятном человеку языке программирования в непонятный человеку машинный код. Соответственно, чем больше мы делаем наш язык и программу проще для понимания: вводим удобные языковые конструкции, строим сложные архитектурные абстракции - тем больше работы нужно сделать компилятору, чтобы преобразовать наш код в машинный. Когда-нибудь это дойдет до такого, что мы пишем тех задания на русском языке и на его основе код будет писаться за нас. Но это уже лирика. То, как удобно человеку - не обязательно самый эффективный вариант. С очень большой вероятностью это будет самый медленный вариант.
Компьютер - очень сложная штука. Людей, которые реально понимают, что происходит внутри него, и, исходя из этого, знают, как писать эффективные программы - ну если не по пальцам пересчитать, то их числа явно недостаточно, чтобы закрыть мировой спрос на программистов. Умные дяди думали-думали над этой проблемой и придумали одно решение. "А напишем-ка мы программу, которая будет знать, что происходит внутри машины, позволит людям писать удобный код и, на основе своих знаний, поможет им этот код ускорить!" Это и есть компилятор. Отсюда еще одной задачей компилятора является изменение наивного пользовательского кода так, чтобы его функционал не изменился, а время работы скоратилось. Причем делать такие изменения только по запросу программиста. Так появились оптимизации компилятора и соотвествующие опции, включающие их.
Вчерашний пост очень хорошо демонстрирует описанные выше концепции. Было 4 вида циклов и сравнивались затраты на их итерирование. Те результаты, которые получились там, отражают именно что различия в том, как эти циклы реализованы. То есть компилятор тупо брал и переводил их машинные инструкции без каких либо дополнительных манипуляций со своей стороны. И результаты получились соответствующими: чем проще и понятнее было писать цикл, тем больше времени требовалось на его отработку. Это напрямую подтверждает мысль о том, что за все удобные плюсовые примочки мы платим цену временем работы этих примочек.
Но я не дал компилятору проявить себя во всей красе. Умные люди в комментариях сразу указали на эту проблему. Код компилировался без оптимизаций. И тот пост был подводкой к теме оптимизаций компилятора и как они могут аффектить наш код. Просто так рассказать про это было бы не очень интересно. А так чуть ли не скандал разразился и вы сильнее вовлеклись в тему😆. А я не устаю убеждаться, что в нашем коммьюнити много крутых и внимательных специалистов с критическим мышлением)
И хоть многое уже было проспойлерено, но не все, поэтому начнем раскрывать эту тему с наглядной демонстрации возможностей gcc по изменению выхлопа от вчерашнего кода.
Существует дохренальен флагов оптимизации, но сегодня мы обратим внимание на группу флагов с префиксом -О. -О0, -О1, -О2, -О3. Это такие удобные верхнеуровневые рычажки, дергая которые вы включаете целый набор оптимизаций. Пока не будем углубляться из чего он состоит. Важно знать, что -О0 - дефолтный флаг(нет оптимизаций), и что чем больше чиселка при букве О, тем больше компилятор изменяет ваш код, чтобы он работал быстрее. Не факт, что у него получится что-то ускорить, но в среднем выигрыш будет. Какого характера может быть выигрыш?
Продолжение в комментах
#optimization #compiler #goodoldc #performance
Задача компилятора - перевести код на понятном человеку языке программирования в непонятный человеку машинный код. Соответственно, чем больше мы делаем наш язык и программу проще для понимания: вводим удобные языковые конструкции, строим сложные архитектурные абстракции - тем больше работы нужно сделать компилятору, чтобы преобразовать наш код в машинный. Когда-нибудь это дойдет до такого, что мы пишем тех задания на русском языке и на его основе код будет писаться за нас. Но это уже лирика. То, как удобно человеку - не обязательно самый эффективный вариант. С очень большой вероятностью это будет самый медленный вариант.
Компьютер - очень сложная штука. Людей, которые реально понимают, что происходит внутри него, и, исходя из этого, знают, как писать эффективные программы - ну если не по пальцам пересчитать, то их числа явно недостаточно, чтобы закрыть мировой спрос на программистов. Умные дяди думали-думали над этой проблемой и придумали одно решение. "А напишем-ка мы программу, которая будет знать, что происходит внутри машины, позволит людям писать удобный код и, на основе своих знаний, поможет им этот код ускорить!" Это и есть компилятор. Отсюда еще одной задачей компилятора является изменение наивного пользовательского кода так, чтобы его функционал не изменился, а время работы скоратилось. Причем делать такие изменения только по запросу программиста. Так появились оптимизации компилятора и соотвествующие опции, включающие их.
Вчерашний пост очень хорошо демонстрирует описанные выше концепции. Было 4 вида циклов и сравнивались затраты на их итерирование. Те результаты, которые получились там, отражают именно что различия в том, как эти циклы реализованы. То есть компилятор тупо брал и переводил их машинные инструкции без каких либо дополнительных манипуляций со своей стороны. И результаты получились соответствующими: чем проще и понятнее было писать цикл, тем больше времени требовалось на его отработку. Это напрямую подтверждает мысль о том, что за все удобные плюсовые примочки мы платим цену временем работы этих примочек.
Но я не дал компилятору проявить себя во всей красе. Умные люди в комментариях сразу указали на эту проблему. Код компилировался без оптимизаций. И тот пост был подводкой к теме оптимизаций компилятора и как они могут аффектить наш код. Просто так рассказать про это было бы не очень интересно. А так чуть ли не скандал разразился и вы сильнее вовлеклись в тему😆. А я не устаю убеждаться, что в нашем коммьюнити много крутых и внимательных специалистов с критическим мышлением)
И хоть многое уже было проспойлерено, но не все, поэтому начнем раскрывать эту тему с наглядной демонстрации возможностей gcc по изменению выхлопа от вчерашнего кода.
Существует дохренальен флагов оптимизации, но сегодня мы обратим внимание на группу флагов с префиксом -О. -О0, -О1, -О2, -О3. Это такие удобные верхнеуровневые рычажки, дергая которые вы включаете целый набор оптимизаций. Пока не будем углубляться из чего он состоит. Важно знать, что -О0 - дефолтный флаг(нет оптимизаций), и что чем больше чиселка при букве О, тем больше компилятор изменяет ваш код, чтобы он работал быстрее. Не факт, что у него получится что-то ускорить, но в среднем выигрыш будет. Какого характера может быть выигрыш?
Продолжение в комментах
#optimization #compiler #goodoldc #performance
👍14🔥9❤5😁1
std::signbit
В прошлом посте мы уже упоминали std::signbit. Сегодня мы посмотрим на эту сущность по-подробнее.
По сути, это самый говорящий и плюсовый чтоли способ узнать знаковый бит числа, который появился в нашем арсенале с приходом С++11. Причем не только целого, но и числа с плавающей точкой. Хотя на самом деле даже наоборот.
вот такие перегрузки мы имеем для floating-point чисел. А вот такую:
для целых. Последняя перегрузка является дополнительной. Это значит, что в имплементации стандартной библиотеки она не обязана выглядеть прям в точности так. Единственное требование - перегрузки должны быть достаточными, чтобы определить попадание интегрального типа в функцию.
В чем особенность целочисленной перегрузки. В том, что число, которое туда попадает трактуется, как double. Поэтому выражение std::signbit(num) эквивалентно std::signbit(static_cast<double>(num)).
Также эта функция детектирует наличие знакового бита у нулей, бесконечностей и NaN'ов. Да, да. У нуля есть знак. Так что 0.0 и -0.0 - не одно и то же. И если вы внимательные, то заметили даже у NaN есть знак. И std::signbit - один из двух возможных кроссфплатформенных способов узнать знак NaN. Этот факт еще больше мотивирует использовать эту функцию(в ситуациях, где это свойство решает).
Начиная с 23 стандарта функция становится constexpr, что не может не радовать любителей compile-time вычислений.
Для языка С тоже кстати есть похожая сущность. Только там это макрос
И для него гарантируется такое поведение: для положительных чисел возвращаем ноль, а для отрицательных - ненулевое целое число.
Мне кажется, что в повседневной разработке(там где не нужно выжимать все возможные такты и кода) плюсовое решение будет более предпочтительным, по сравнению с аналогами. Говорящее название и поддержка стандрата - наши главные друзья.
Look for signs in life. Stay cool.
#cpp23 #cpp11 #goodoldc
В прошлом посте мы уже упоминали std::signbit. Сегодня мы посмотрим на эту сущность по-подробнее.
По сути, это самый говорящий и плюсовый чтоли способ узнать знаковый бит числа, который появился в нашем арсенале с приходом С++11. Причем не только целого, но и числа с плавающей точкой. Хотя на самом деле даже наоборот.
bool signbit( float num );
bool signbit( double num );
bool signbit( long double num );
вот такие перегрузки мы имеем для floating-point чисел. А вот такую:
template< class Integer >
bool signbit( Integer num );
для целых. Последняя перегрузка является дополнительной. Это значит, что в имплементации стандартной библиотеки она не обязана выглядеть прям в точности так. Единственное требование - перегрузки должны быть достаточными, чтобы определить попадание интегрального типа в функцию.
В чем особенность целочисленной перегрузки. В том, что число, которое туда попадает трактуется, как double. Поэтому выражение std::signbit(num) эквивалентно std::signbit(static_cast<double>(num)).
Также эта функция детектирует наличие знакового бита у нулей, бесконечностей и NaN'ов. Да, да. У нуля есть знак. Так что 0.0 и -0.0 - не одно и то же. И если вы внимательные, то заметили даже у NaN есть знак. И std::signbit - один из двух возможных кроссфплатформенных способов узнать знак NaN. Этот факт еще больше мотивирует использовать эту функцию(в ситуациях, где это свойство решает).
Начиная с 23 стандарта функция становится constexpr, что не может не радовать любителей compile-time вычислений.
Для языка С тоже кстати есть похожая сущность. Только там это макрос
#define signbit( arg ) /* implementation defined */
И для него гарантируется такое поведение: для положительных чисел возвращаем ноль, а для отрицательных - ненулевое целое число.
Мне кажется, что в повседневной разработке(там где не нужно выжимать все возможные такты и кода) плюсовое решение будет более предпочтительным, по сравнению с аналогами. Говорящее название и поддержка стандрата - наши главные друзья.
Look for signs in life. Stay cool.
#cpp23 #cpp11 #goodoldc
{kind=link}
👍13❤7🔥7
Еще одно отличие С от С++
Это вот прям такое, мажорное отличие. Скажете его на собесе - все охренеют, вам руку пожмут через вебку и возьмут вас на работу сразу же(но это не точно).
В языке С нет проблемы Static initialization order fiasco!
Как же так? В С тоже есть статики и тоже есть разные единицы трансляции. Почему так?
Таким образом, в С статическая переменная со скалярным типом может быть инициализирована только константным выражением. Это не constexpr, а просто выражение, которое компилятор в состоянии вычислить во время компиляции. Если тип переменной представляет собой массив со скалярным типом элемента, то каждый инициализатор должен быть константным выражением и так далее. Поскольку такие выражения не могут ни вызывать побочных эффектов, ни зависеть от побочных эффектов, вызванных любыми другими вычислениями, изменение порядка вычисление константных выражений не влияет на результат. А значит и никакого фиаско нет!
Единственные неконстантные выражения, которые могут быть вычислены перед main, - это те, которые вызываются из среды выполнения C. Вот почему объекты FILE, на которые указывают stdin, stdout и stderr, уже доступны для использования сразу же после начала main.
Стандартный C не позволяет пользователям регистрировать свой собственный код запуска перед основным, хотя GCC предоставляет расширение под названием constructor (возможна массонская связь с конструкторами из C++), которое вы можете использовать для воссоздания SIOF в C. Но это, как говорится, НЕСТАНДАРТ и у каждого свой путь в могилу.
Целью Страуструпа было сделать пользовательские типы пригодными для использования везде, где есть встроенные типы. Это означало, что C++ должен был разрешать глобальным переменным быть кастомными типами, что означает, что их конструкторы будут вызываться во время запуска программы. Поскольку в начале C++ не было функций constexpr, такие вызовы конструкторов никогда не могли быть постоянными выражениями. И так, родилось чудовище, погубившее много наших ребят - Static initialization order fiasco.
В процессе стандартизации C++ вопрос о порядке выполнения статической инициализации был спорной темой. Я думаю, что вы согласитесь с тем, что идеальная ситуация - это когда каждая статическая переменная была инициализирована до ее использования. К сожалению, для этого требуется технология компоновки, которой в те дни не существовало (и, вероятно, до сих пор не существует?). Инициализация статической переменной может включать вызовы функций, и эти функции могут быть определены в другой TU, что означает, что вам нужно будет выполнить анализ всей программы, чтобы успешно отсортировать статические переменные в порядке зависимостей. Стоит отметить, что даже если бы C++ мог быть разработан таким образом, он все равно не полностью предотвратил бы проблемы с порядком инициализации. Представьте, если бы у вас была какая-то библиотека, где предварительным условием функции использования было то, что функция init() была вызвана в какой-то момент в прошлом и повлияла на нужную для инициализацию переменную. Компилятор не может увидеть такие зависимости, которые есть только у программиста в голове. По коду этого совсем не видно. Поэтому, думаю, что даже полноценный анализ кода не помог бы решить проблему.
В конечном счете, ограниченные гарантии порядка инициализации, которые мы получили в C++98, были лучшими, которые мы могли получить в данных обстоятельствах. С помощью народного "а вот сделали бы по-человечески", возможно, многие из нас высказали пару ласковых о том, что тот стандарт не был полным без функций constexpr и что статические переменные должны иметь только константную инициализацию. Но такого рода размышления надо оставить это нытикам и нюням. А настоящие программисты прогают на том, что есть. В тех условиях, в которых возможно.
Don't complain to your life. Work on it and stay cool.
#cppcore #goodoldc
Это вот прям такое, мажорное отличие. Скажете его на собесе - все охренеют, вам руку пожмут через вебку и возьмут вас на работу сразу же(но это не точно).
В языке С нет проблемы Static initialization order fiasco!
Как же так? В С тоже есть статики и тоже есть разные единицы трансляции. Почему так?
All the expressions in an initializer
for an object that has static storage
duration or in an initializer list for an
object that has aggregate or union type
shall be constant expressions.
Таким образом, в С статическая переменная со скалярным типом может быть инициализирована только константным выражением. Это не constexpr, а просто выражение, которое компилятор в состоянии вычислить во время компиляции. Если тип переменной представляет собой массив со скалярным типом элемента, то каждый инициализатор должен быть константным выражением и так далее. Поскольку такие выражения не могут ни вызывать побочных эффектов, ни зависеть от побочных эффектов, вызванных любыми другими вычислениями, изменение порядка вычисление константных выражений не влияет на результат. А значит и никакого фиаско нет!
Единственные неконстантные выражения, которые могут быть вычислены перед main, - это те, которые вызываются из среды выполнения C. Вот почему объекты FILE, на которые указывают stdin, stdout и stderr, уже доступны для использования сразу же после начала main.
Стандартный C не позволяет пользователям регистрировать свой собственный код запуска перед основным, хотя GCC предоставляет расширение под названием constructor (возможна массонская связь с конструкторами из C++), которое вы можете использовать для воссоздания SIOF в C. Но это, как говорится, НЕСТАНДАРТ и у каждого свой путь в могилу.
Целью Страуструпа было сделать пользовательские типы пригодными для использования везде, где есть встроенные типы. Это означало, что C++ должен был разрешать глобальным переменным быть кастомными типами, что означает, что их конструкторы будут вызываться во время запуска программы. Поскольку в начале C++ не было функций constexpr, такие вызовы конструкторов никогда не могли быть постоянными выражениями. И так, родилось чудовище, погубившее много наших ребят - Static initialization order fiasco.
В процессе стандартизации C++ вопрос о порядке выполнения статической инициализации был спорной темой. Я думаю, что вы согласитесь с тем, что идеальная ситуация - это когда каждая статическая переменная была инициализирована до ее использования. К сожалению, для этого требуется технология компоновки, которой в те дни не существовало (и, вероятно, до сих пор не существует?). Инициализация статической переменной может включать вызовы функций, и эти функции могут быть определены в другой TU, что означает, что вам нужно будет выполнить анализ всей программы, чтобы успешно отсортировать статические переменные в порядке зависимостей. Стоит отметить, что даже если бы C++ мог быть разработан таким образом, он все равно не полностью предотвратил бы проблемы с порядком инициализации. Представьте, если бы у вас была какая-то библиотека, где предварительным условием функции использования было то, что функция init() была вызвана в какой-то момент в прошлом и повлияла на нужную для инициализацию переменную. Компилятор не может увидеть такие зависимости, которые есть только у программиста в голове. По коду этого совсем не видно. Поэтому, думаю, что даже полноценный анализ кода не помог бы решить проблему.
В конечном счете, ограниченные гарантии порядка инициализации, которые мы получили в C++98, были лучшими, которые мы могли получить в данных обстоятельствах. С помощью народного "а вот сделали бы по-человечески", возможно, многие из нас высказали пару ласковых о том, что тот стандарт не был полным без функций constexpr и что статические переменные должны иметь только константную инициализацию. Но такого рода размышления надо оставить это нытикам и нюням. А настоящие программисты прогают на том, что есть. В тех условиях, в которых возможно.
Don't complain to your life. Work on it and stay cool.
#cppcore #goodoldc
{kind=link}
🔥20👍11🤯6❤3🤮1😭1
Вызываем функцию в глобальном скоупе
В отличие от С в С++ можно вызывать код до входа в main. В С нельзя вызывать функции в глобальном скоупе, и глобальные переменные там должны быть инициализированы константным выражение. Однако для С++ пришлось ослабить правила. Это было нужно для возможности создания объектов кастомных классов, как глобальных переменных. Для создания объектов нужны конструкторы. А это обычные функции.
Поэтому в плюсах можно выполнять пользовательский код до main. Но этот код должен содержаться внутри конструкторов и вызываемых ими функциях.
Но просто так вызвать рандомную функция я не могу. Это запрещено.
"Ну блин. Мне очень надо. Может как-то договоримся?"
Со стандартом не договоришься. Но обходные пути все же можно найти.
Например так:
Здесь мы пользуемся уникальными свойствами оператора запятая: результат первого операнда вычисляется до вычисления второго и после просто отбрасывается. А значение всего выражения задается вторым операндом.
Получается, что здесь мы создаем статическую переменную-пустышку, чтобы получить возможность оперировать в глобальном скоупе. Инициализаторы глобальных переменных в С++ могут быть вычисляемыми. Поэтому мы используем свойство оператора запятой, чтобы беспоследственно вычислить some_function, а инициализировать dummy нулем.
Вероятнее всего, вам никогда не понадобиться так вызывать функцию. Однако оператор запятая - уникальный инструмент и может выручить даже в таких непростых ситуациях.
Have unique tools in your arsenal. Stay cool.
#cppcore #goodoldc
В отличие от С в С++ можно вызывать код до входа в main. В С нельзя вызывать функции в глобальном скоупе, и глобальные переменные там должны быть инициализированы константным выражение. Однако для С++ пришлось ослабить правила. Это было нужно для возможности создания объектов кастомных классов, как глобальных переменных. Для создания объектов нужны конструкторы. А это обычные функции.
Поэтому в плюсах можно выполнять пользовательский код до main. Но этот код должен содержаться внутри конструкторов и вызываемых ими функциях.
Но просто так вызвать рандомную функция я не могу. Это запрещено.
"Ну блин. Мне очень надо. Может как-то договоримся?"
Со стандартом не договоришься. Но обходные пути все же можно найти.
Например так:
static int dummy = (some_function(), 0);
int main() {}
Здесь мы пользуемся уникальными свойствами оператора запятая: результат первого операнда вычисляется до вычисления второго и после просто отбрасывается. А значение всего выражения задается вторым операндом.
Получается, что здесь мы создаем статическую переменную-пустышку, чтобы получить возможность оперировать в глобальном скоупе. Инициализаторы глобальных переменных в С++ могут быть вычисляемыми. Поэтому мы используем свойство оператора запятой, чтобы беспоследственно вычислить some_function, а инициализировать dummy нулем.
Вероятнее всего, вам никогда не понадобиться так вызывать функцию. Однако оператор запятая - уникальный инструмент и может выручить даже в таких непростых ситуациях.
Have unique tools in your arsenal. Stay cool.
#cppcore #goodoldc
{kind=link}
👍57🔥15❤🔥7❤3
Могу ли я вызвать функцию main?
#опытным
Вопрос из разряда "а что если" и особо практического смысла не имеет. Но когда это нас останавливало? Без знаний стандарта на этот вопрос вряд ли можно ответить правильно, но я попробую хотя бы приблизится к этому.
Прородителем плюсов был язык С, поэтому давайте сначала посмотрим, что там творится по этому поводу.
В C нет запрета вызывать main(). А все, что не запрещено - разрешено. Вот и вы легко можете вызвать main() из любого места программы.
Можно даже рекурсивно вызвать главную функцию и из этого можно придумать что-то более менее рабочее. Например:
Если это запускать, как 'recursive_main 1 2 3', то вывод будет такой:
Но вы скорее попадете на переполнение стека от неконтролируемой рекурсии, чем сделаете что-то полезное.
Ну и конечно, в С сложно сделать так, чтобы код выполнялся в глобальной области.
А вот в С++ это сделать суперпросто. В конструкторах глобальных объектов. И вот здесь уже интересно. Инициализация глобальных переменных имеет свой определенный порядок. Что будет, если мы в этот порядок вклинимся и запустим программу раньше?
Такое чувство, что ничего хорошего мы не получим.
В случае с рекурсией любой код теоретически может уйти в переполнение, поэтому как будто и не особо важно, main это или нет. Не запрещать же рекурсию из-за возможности ее никогда не остановить.
Но вот если мы можем прервать подготовку программы к вызову main ее преждевременным вызовом - у нас 100% возникнут проблемы.
Скорее всего это одна из мажорных причин, почему в С++ нельзя вызывать main никаким образом. Если происходит обратное, то программа считается ill-formed.
Компиляторы по идее должны тут же прервать компиляцию при упоминании main в коде. Но вы же знаете эти компиляторы. Слишком много им свободы дали. Скорее всего, вы сможете скомпилировать свой код с вызовом main и все заработает. Только если прописать какой-нибудь --pedantic флаг, то вам скажут "атата, так делать низя".
В общем, не думаю, что у вас было желание когда-то вызвать main. Однако сейчас вы точно знаете, что так делать нельзя)
Follow the rules. Stay cool.
#cppcore #goodoldc
#опытным
Вопрос из разряда "а что если" и особо практического смысла не имеет. Но когда это нас останавливало? Без знаний стандарта на этот вопрос вряд ли можно ответить правильно, но я попробую хотя бы приблизится к этому.
Прородителем плюсов был язык С, поэтому давайте сначала посмотрим, что там творится по этому поводу.
В C нет запрета вызывать main(). А все, что не запрещено - разрешено. Вот и вы легко можете вызвать main() из любого места программы.
Можно даже рекурсивно вызвать главную функцию и из этого можно придумать что-то более менее рабочее. Например:
#include <stdio.h>
int main (int argc, char *argv[]) {
printf ("Running main with argc = %d, last = '%s'\n",
argc, argv[argc-1]);
if (argc > 1)
return main(argc - 1, argv);
return 0;
}
Если это запускать, как 'recursive_main 1 2 3', то вывод будет такой:
Running main with argc = 4, last = '3'
Running main with argc = 3, last = '2'
Running main with argc = 2, last = '1'
Running main with argc = 1, last = './recursive_main'
Но вы скорее попадете на переполнение стека от неконтролируемой рекурсии, чем сделаете что-то полезное.
Ну и конечно, в С сложно сделать так, чтобы код выполнялся в глобальной области.
А вот в С++ это сделать суперпросто. В конструкторах глобальных объектов. И вот здесь уже интересно. Инициализация глобальных переменных имеет свой определенный порядок. Что будет, если мы в этот порядок вклинимся и запустим программу раньше?
Такое чувство, что ничего хорошего мы не получим.
В случае с рекурсией любой код теоретически может уйти в переполнение, поэтому как будто и не особо важно, main это или нет. Не запрещать же рекурсию из-за возможности ее никогда не остановить.
Но вот если мы можем прервать подготовку программы к вызову main ее преждевременным вызовом - у нас 100% возникнут проблемы.
Скорее всего это одна из мажорных причин, почему в С++ нельзя вызывать main никаким образом. Если происходит обратное, то программа считается ill-formed.
Компиляторы по идее должны тут же прервать компиляцию при упоминании main в коде. Но вы же знаете эти компиляторы. Слишком много им свободы дали. Скорее всего, вы сможете скомпилировать свой код с вызовом main и все заработает. Только если прописать какой-нибудь --pedantic флаг, то вам скажут "атата, так делать низя".
В общем, не думаю, что у вас было желание когда-то вызвать main. Однако сейчас вы точно знаете, что так делать нельзя)
Follow the rules. Stay cool.
#cppcore #goodoldc
{kind=link}
❤27😁18👍13❤🔥6
Проблемы С-style массивов
#опытным
В наследство от языка С С++ достались статические массивы. Так называемые С-style массивы. Это проверенные средства языка, успешно решающие свои задачи. Но у них есть серьезные недостатки, которые в основном связаны с низкоуровневостью этого инструмента.
Давайте кратко повторим, что такое C-style массив.
Это непрерывная последовательность элементов одного типа и память под них выделяется на стеке(или реже в статический области, если массив глобальный) и автоматически освобождается при выходе из функции.
Определяется сишный массив вот так:
Размер памяти, занимаемый массивом равняется количеству его элементов помноженному на размер типа данных:
Соответственно, для получения количества элементов массива, нужно поделить sizeof от массива на размер типа данных, которые он хранит.
В чем же его недостатки?
❗️ Массивы нельзя сравнивать напрямую, а только поэлементно. Напрямую сравниваются указатели на первый элемент.
❗️ Мимикрирование под массивы разрешает странную семантику с условиями и арифметическими операциями.
❗️В С разрешены [массивы переменной длины](https://t.me/grokaemcpp/56) на уровне стандарта. И синтаксис у них ровно такой же, как и у статических массивов, только при его создании размер указывается не константой, а переменной. В С++ это не стандартная фича, а расширения компилятора. То есть нельзя писать кроссплатформенный код с использованием массивов переменной длины. Но за счет идентичного синтаксиса очень легко спутать один вид массива с другим и похерить переменосимость.
❗️ От синтаксиса сочетания функций и массивов хочется вырвать себе глаза, закрыть компьютер и уйти жить в лес:
❗️Массив не инкапсулирует в себе свой размер. Его нужно всегда вычислять, как мы говорили в начале.
❗️Из-за сложности синтаксиса, вы скорее всего захотите обрабатывать массивы с помощью функций с похожей сигнатурой:
Это потенциально может привести к доступу за границы выделенной области, так как функция foo ничего не знает про то, какой реальный размер имеет область памяти, на которую указывает
В общем, сишные массивы - это не объекты и не обладают преимуществами ООП и универсальной семантики для объектов в С++.
Поэтому стандартная библиотека предоставляет нам инструмент, который решает все проблемы C-style массивов. Это контейнер std::array. О нем мы поговорим в следующий раз.
Upgrade your tools. Stay cool.
#cppcore #goodoldc
#опытным
В наследство от языка С С++ достались статические массивы. Так называемые С-style массивы. Это проверенные средства языка, успешно решающие свои задачи. Но у них есть серьезные недостатки, которые в основном связаны с низкоуровневостью этого инструмента.
Давайте кратко повторим, что такое C-style массив.
Это непрерывная последовательность элементов одного типа и память под них выделяется на стеке(или реже в статический области, если массив глобальный) и автоматически освобождается при выходе из функции.
Определяется сишный массив вот так:
// создаем массив на 5 элементов,
// которые базово инициализируются мусором
int arr1[5];
// создаем массив на 5 элементов,
// которые инициализируются нулями
int arr1[5]{};
// создаем массив и предоставляем набор элементов, с помощью
// которых компилятор вычисляет длину массива и инициализирует элементы
int arr2[] = {1, 2, 3, 4, 5};
Размер памяти, занимаемый массивом равняется количеству его элементов помноженному на размер типа данных:
constexpr size_t array_size = 5;
int arr[array_size];
sizeof(arr) == array_size * sizeof(int); // true
Соответственно, для получения количества элементов массива, нужно поделить sizeof от массива на размер типа данных, которые он хранит.
auto array_size = sizeof(arr) / sizeof(Type);
В чем же его недостатки?
❗️ Массивы нельзя сравнивать напрямую, а только поэлементно. Напрямую сравниваются указатели на первый элемент.
int arr1[] = {0, 1, 2, 3};
int arr2[] = {0, 1, 2, 3};
// ложь так как сраниваются указатели,
// а они разные для разных объектов
arr1 == arr2; ❗️ Мимикрирование под массивы разрешает странную семантику с условиями и арифметическими операциями.
// создаем пустую строку в виде массива
char arr[] = "";
// условие будет всегда true, хотя мы создали пустую строку
if (arr);
// разрешается, но зачем? что значит прибавить к массиву число?
arr + 1;
❗️В С разрешены [массивы переменной длины](https://t.me/grokaemcpp/56) на уровне стандарта. И синтаксис у них ровно такой же, как и у статических массивов, только при его создании размер указывается не константой, а переменной. В С++ это не стандартная фича, а расширения компилятора. То есть нельзя писать кроссплатформенный код с использованием массивов переменной длины. Но за счет идентичного синтаксиса очень легко спутать один вид массива с другим и похерить переменосимость.
❗️ От синтаксиса сочетания функций и массивов хочется вырвать себе глаза, закрыть компьютер и уйти жить в лес:
int foo(int arr[4]);
// На самом деле такая сигнатура полностью эквивалентна int foo(int * arr),
// что позволяет принимать в функцию массив любой длины и указатели.
// В С++ нет синтаксиса приема массива по значению.
void foo(int (&arr)[4]); // зато есть синтаксис приема массива по ссылке
// Нормального синтаксиса для возврата массива из функции также не завезли.
// Вот воркэраунды.
int get_array()[10];
auto get_array() -> int[10];
❗️Массив не инкапсулирует в себе свой размер. Его нужно всегда вычислять, как мы говорили в начале.
❗️Из-за сложности синтаксиса, вы скорее всего захотите обрабатывать массивы с помощью функций с похожей сигнатурой:
void foo(int * p, size_t size);
Это потенциально может привести к доступу за границы выделенной области, так как функция foo ничего не знает про то, какой реальный размер имеет область памяти, на которую указывает
p. Она должна доверять программисту и переданному значению size. А программисту верить - себя не уважать.В общем, сишные массивы - это не объекты и не обладают преимуществами ООП и универсальной семантики для объектов в С++.
Поэтому стандартная библиотека предоставляет нам инструмент, который решает все проблемы C-style массивов. Это контейнер std::array. О нем мы поговорим в следующий раз.
Upgrade your tools. Stay cool.
#cppcore #goodoldc
{kind=link}
🔥37👍15❤🔥3❤2😁2⚡1
Неочевидное преимущество шаблонов
#новичкам
Давайте немного разбавим рассказ о фичах 23-го стандарта чем-нибудь более приземленным
Мы знаем, что шаблоны используются как лекарство от повторения кода, а также как средство реализации полиморфизма времени компиляции. Но неужели без них нельзя обойтись?
Можно и обойтись. Возьмем хрестоматийный пример std::qsort. Это скоммунизденная реализация сишной стандартной функции qsort. Сигнатура у нее такая:
Как видите, здесь много
Как это работает?
Функция qsort спроектирована так, чтобы с ее помощью можно было сортировать любые POD типы. Но не хочется как-то пеерегружать функцию сортировки для всех потенциальных типов. Поэтому придумали обход. Передавать void указатель, чтобы мочь обрабатывать данные любых типов. Но void* - это нетипизированный указатель, поэтому фунции нужно знать размер типа данных, которые она сортирует, и количество данных. А также предикат сравнения.
Вот тут немного поподробнее. Предикат для интов может выглядеть примерно так:
Предикату не нужно передавать размер типа, потому что он сам знает наперед с каким данными он работает и сможет закастить void* к нужному типу.
Вот в этом предикате и проблема. Функция qsort не знает на этапе компиляции, с каким предикатом она будет работать. Поэтому компилятор очень ограничен в оптимизации этой части: он не может заинлайнить код компаратора в код qsort. На каждый вызов компаратора будет прыжок по указателю функции. Это примерна та же причина, по которой виртуальные вызовы дорогие.
Тип шаблонных параметров, напротив, известен на этапе компиляции.
Значит код компаратора шаблонной функции может быть включен в код сортировки. Именно поэтому функция std::sort намного быстрее std::qsort при включенных оптимизациях(а без них примерно одинаково)
Казалось бы плюсы, а быстрее сишки. И такое бывает, когда используешь шаблоны.
Use advanced technics. Stay cool.
#template #goodoldc #goodpractice #compiler
#новичкам
Давайте немного разбавим рассказ о фичах 23-го стандарта чем-нибудь более приземленным
Мы знаем, что шаблоны используются как лекарство от повторения кода, а также как средство реализации полиморфизма времени компиляции. Но неужели без них нельзя обойтись?
Можно и обойтись. Возьмем хрестоматийный пример std::qsort. Это скоммунизденная реализация сишной стандартной функции qsort. Сигнатура у нее такая:
void qsort( void *ptr, std::size_t count, std::size_t size, /* c-compare-pred */* comp );
extern "C" using /* c-compare-pred */ = int(const void*, const void*);
extern "C++" using /* compare-pred */ = int(const void*, const void*);
Как видите, здесь много
void * указателей на void. В том числе с помощью него достигается полиморфизм в С(есть еще макросы, но не будем о них).Как это работает?
Функция qsort спроектирована так, чтобы с ее помощью можно было сортировать любые POD типы. Но не хочется как-то пеерегружать функцию сортировки для всех потенциальных типов. Поэтому придумали обход. Передавать void указатель, чтобы мочь обрабатывать данные любых типов. Но void* - это нетипизированный указатель, поэтому фунции нужно знать размер типа данных, которые она сортирует, и количество данных. А также предикат сравнения.
Вот тут немного поподробнее. Предикат для интов может выглядеть примерно так:
[](const void* x, const void* y)
{
const int arg1 = *static_cast<const int*>(x);
const int arg2 = *static_cast<const int*>(y);
const auto cmp = arg1 <=> arg2;
if (cmp < 0)
return -1;
if (cmp > 0)
return 1;
return 0;
}
Предикату не нужно передавать размер типа, потому что он сам знает наперед с каким данными он работает и сможет закастить void* к нужному типу.
Вот в этом предикате и проблема. Функция qsort не знает на этапе компиляции, с каким предикатом она будет работать. Поэтому компилятор очень ограничен в оптимизации этой части: он не может заинлайнить код компаратора в код qsort. На каждый вызов компаратора будет прыжок по указателю функции. Это примерна та же причина, по которой виртуальные вызовы дорогие.
Тип шаблонных параметров, напротив, известен на этапе компиляции.
template< class RandomIt, class Compare >
void sort( RandomIt first, RandomIt last, Compare comp );
Значит код компаратора шаблонной функции может быть включен в код сортировки. Именно поэтому функция std::sort намного быстрее std::qsort при включенных оптимизациях(а без них примерно одинаково)
Казалось бы плюсы, а быстрее сишки. И такое бывает, когда используешь шаблоны.
Use advanced technics. Stay cool.
#template #goodoldc #goodpractice #compiler
{kind=link}
50🔥35👍9❤5⚡2👎1
Еще одно отличие С и С++
#опытным
Продолжаем рубрику, где мы развеиваем миф о том, что С - это подмножество С++. Вот предыдущие части: тык, тык и тык.
В С давно можно инициализировать структуры с помощью так называемой designated initialization. Эта фича позволяет при создании массива или экземпляра структуры указать значения конкретным элементам и конкретным полям с указанием их имени!
Например, хочу я определить разреженный массив из 100 элементов и только 3 их них я хочу инициализировать единичками. Не проблема! В С это можно сделать одной строчкой:
В плюсах такое можно сделать только с помощью нескольких инструкций.
Не так удобно.
Можно даже задавать рэндж значений. Но это правда GNU расширение.
Теперь элементы с 31 по 41 будут инициализированы единичками. Очень удобно!
Для структур задавать значения полям можно вот так:
Нужно обязательно при инициализации указать конкретное поле, которому будет присвоено значение. При чем порядок указания полей неважен! А неупомянутые поля будут инициализированы нулем.
До С++20 в плюсах вообще не было подобного синтаксиса. Начиная с 20-х плюсов при создании объекта класса мы можем аннотировать, каким полям мы присваиваем значение. Но в плюсах намного больше ограничений: поля нужно указывать в порядке объявления в теле класса, никакой инициализации массивов и еще куча тонкостей.
Так что вот вам еще один пример, которым вы сможете парировать интервьюера на вопрос: "верно ли что С - подмножество С++?". Иначе где вам это еще пригодится?
Be different. Stay cool.
#goodoldc #cppcore #cpp20 #interview
#опытным
Продолжаем рубрику, где мы развеиваем миф о том, что С - это подмножество С++. Вот предыдущие части: тык, тык и тык.
В С давно можно инициализировать структуры с помощью так называемой designated initialization. Эта фича позволяет при создании массива или экземпляра структуры указать значения конкретным элементам и конкретным полям с указанием их имени!
Например, хочу я определить разреженный массив из 100 элементов и только 3 их них я хочу инициализировать единичками. Не проблема! В С это можно сделать одной строчкой:
int array[100] = {[13] = 1, [45] = 1, [79] = 1};В плюсах такое можно сделать только с помощью нескольких инструкций.
int array[100] = {};
array[13] = array[45] = array[79] = 1;Не так удобно.
Можно даже задавать рэндж значений. Но это правда GNU расширение.
int array[100] = {[13] = 1, [30 ... 40] = 1, [45] = 1, [79] = 1};Теперь элементы с 31 по 41 будут инициализированы единичками. Очень удобно!
Для структур задавать значения полям можно вот так:
struct point { int x, y, z; };
struct point p1 = { .y = 2, .x = 3 };
struct point p2 = { y: 2, x: 3 };
struct point p3 = { x: 1};Нужно обязательно при инициализации указать конкретное поле, которому будет присвоено значение. При чем порядок указания полей неважен! А неупомянутые поля будут инициализированы нулем.
До С++20 в плюсах вообще не было подобного синтаксиса. Начиная с 20-х плюсов при создании объекта класса мы можем аннотировать, каким полям мы присваиваем значение. Но в плюсах намного больше ограничений: поля нужно указывать в порядке объявления в теле класса, никакой инициализации массивов и еще куча тонкостей.
Так что вот вам еще один пример, которым вы сможете парировать интервьюера на вопрос: "верно ли что С - подмножество С++?". Иначе где вам это еще пригодится?
Be different. Stay cool.
#goodoldc #cppcore #cpp20 #interview
{kind=link}
1🔥29👍10❤6❤🔥1
Динамический полиморфизм: указатели на функции и void указатели
#новичкам
C++ - разжиревший отпрыск С, поэтому в нем имеется возможность для динамического полиморфизма пользоваться сишными инструментами.
И два основных сишных инструмента дин полиморфизма - указатели на функции и void указатели.
Функции работают с аргументами и каждое имя функции при компиляции соответствует адресу этой функции в памяти. Даже если 2 функции имеют разные адреса, но одинаковый набор и порядок аргументов, в низкоуровневом коде они вызываются абсолютно единообразно. Поэтому есть такая сущность, как указатели на функции. Они могут хранить адреса любых функций с наперед заданной сигнатурой:
В коде выше с помощью одного указателя вызываются 2 разные функции. Полиморфизм? Вполне! Только вот примерчик давайте по-серьезнее возьмем:
std::bsearch - функция, которая выполняет алгоритм бинарного поиска и возвращает либо найденный элемент, либо нулевой указатель, если элемента не было в массиве. Причем он может проводить поиск в массивах разных типов по разным правилам!
Это достигается за счет использования указателя на функцию-компаратор и void указателя. К нему могут неявно приводиться указатели на любые типы, поэтому он не знает, на какой конкретный тип он указывает. Но ему это и не надо. Тот, кто имеет информацию о правильном типе(компаратор) может обратно привести void * к указателю на этот тип и работать уже с нормальным объектом.
Единственная сложность - нужен дополнительный параметр size, с помощью которого задается байтовый размер типа элемента массива.
Ну и давайте все это применим:
Есть два массива: интов и даблов. Для выполнения бинарного поиска для этих типов нужны абсолютно разные компараторы: как минимум даблы нельзя сравнивать втупую.
std::bsearch на этапе компиляции не знает, с какими типами и компараторами он будет работать. Все решения принимаются в рантайме. Но он умеет по-разному находить элементы в массивах разных типов. Именно поэтому bsearch использует инструменты именно динамического полиморфизма.
Act independently of input. Stay cool.
#cppcore #goodoldc
#новичкам
C++ - разжиревший отпрыск С, поэтому в нем имеется возможность для динамического полиморфизма пользоваться сишными инструментами.
И два основных сишных инструмента дин полиморфизма - указатели на функции и void указатели.
Функции работают с аргументами и каждое имя функции при компиляции соответствует адресу этой функции в памяти. Даже если 2 функции имеют разные адреса, но одинаковый набор и порядок аргументов, в низкоуровневом коде они вызываются абсолютно единообразно. Поэтому есть такая сущность, как указатели на функции. Они могут хранить адреса любых функций с наперед заданной сигнатурой:
int x2(int i) {
return i * 2;
}
int square(int i) {
return i * i;
}
using IntFuncPtr = int (*)(int);
IntFuncPtr func_ptr;
// Вызываем x2 через указатель
func_ptr = x2;
std::cout << "x2(5) = " << func_ptr(5) << std::endl;
// Вызываем square через указатель
func_ptr = square;
std::cout << "square(5) = " << func_ptr(5) << std::endl;В коде выше с помощью одного указателя вызываются 2 разные функции. Полиморфизм? Вполне! Только вот примерчик давайте по-серьезнее возьмем:
void *bsearch(const void *key, const void *ptr, std::size_t count,
std::size_t size, /* c-compare-pred */ *comp);
void *bsearch(const void *key, const void *ptr, std::size_t count,
std::size_t size, /* compare-pred */ *comp);
extern "C" using /* c-compare-pred */ = int(const void*, const void*);
extern "C++" using /* compare-pred */ = int(const void*, const void*);
std::bsearch - функция, которая выполняет алгоритм бинарного поиска и возвращает либо найденный элемент, либо нулевой указатель, если элемента не было в массиве. Причем он может проводить поиск в массивах разных типов по разным правилам!
Это достигается за счет использования указателя на функцию-компаратор и void указателя. К нему могут неявно приводиться указатели на любые типы, поэтому он не знает, на какой конкретный тип он указывает. Но ему это и не надо. Тот, кто имеет информацию о правильном типе(компаратор) может обратно привести void * к указателю на этот тип и работать уже с нормальным объектом.
Единственная сложность - нужен дополнительный параметр size, с помощью которого задается байтовый размер типа элемента массива.
Ну и давайте все это применим:
int compare_doubles(const void *a, const void *b) {
static constexpr double EPSILON = 1e-9;
double diff = *(double *)b - *(double *)a;
if (std::fabs(diff) < EPSILON) {
return 0;
}
return (diff > 0) ? 1 : -1;
}
int compare_ints(const void *a, const void *b) {
return (*(int *)a - *(int *)b);
}
double double_arr[] = {5.5, 4.4, 3.3, 2.2, 1.1};
size_t double_size = sizeof(double_arr) / sizeof(double_arr[0]);
int int_arr[] = {10, 20, 30, 40, 50};
size_t int_size = sizeof(int_arr) / sizeof(int_arr[0]);
// Поиск в массиве double
double double_key = 3.30000000001; // Почти 3.3
double *double_res = (double *)std::bsearch(
&double_key, double_arr, double_size,
sizeof(double), compare_doubles);
// тут надо проверить на nullptr, но опустим это
std::cout << "Found double: " << *double_res << std::endl;
// Поиск в массиве int
int int_key = 30;
int *int_res =
(int *)std::bsearch(&int_key, int_arr, int_size,
sizeof(int), compare_ints);
std::cout << "Found int: " << *int_res << std::endl;Есть два массива: интов и даблов. Для выполнения бинарного поиска для этих типов нужны абсолютно разные компараторы: как минимум даблы нельзя сравнивать втупую.
std::bsearch на этапе компиляции не знает, с какими типами и компараторами он будет работать. Все решения принимаются в рантайме. Но он умеет по-разному находить элементы в массивах разных типов. Именно поэтому bsearch использует инструменты именно динамического полиморфизма.
Act independently of input. Stay cool.
#cppcore #goodoldc
{kind=link}
❤20👍11🔥4🤩2💯2🎄1
Третий аргумент main
#новичкам
Почти всегда вы пишите функцию main вот так:
Если вы пишите утилиту командной строки или просто хотите познать боль, то вам нужно парсить аргументы командной строки. В этом случае вы определяете main вот так:
Однако в стандарте описан еще один способ определения main:
Стандарт разрешает компиляторам давать возможность пользователям как-то по-другому задавать аргументы для main. И хоть это будет не переносимо, нам не всегда нужна кроссплатформенность.
Самая часто встречающаяся нестандартная сигнатура main следующая:
Третий аргумент main - это массив строк переменных окружения в формате "KEY=value". Массив завершается null pointer'ом.
Программа получает копию переменных окружения родительского процесса (например, терминала или скрипта). Только лишь независимую копию: изменение набора и значения переменных снаружи программы никак не влияет на то, что происходит внутри нее.
Вот минимальный примерчик:
Возможный вывод:
Вы не так часто можете увидеть этот формат сигнатуры main по уже очевидным для вас причинам:
- нестандарт
- а самое главное - это дело надо парсить. Засовывать в мапу какую-то и искать потом по ключу нужную переменную. А зачем, если есть std::getenv или его брат getenv из Сей.
Рассказываю про это, чтобы вы при встрече в таким форматом аргументов main не думали, что что-то базовое упустили при изучении плюсов. Ну или просто для расширения кругозора)
Expand your horizons. Stay cool.
#NONSTANDARD #goodoldc
#новичкам
Почти всегда вы пишите функцию main вот так:
int main() {
// some code
}Если вы пишите утилиту командной строки или просто хотите познать боль, то вам нужно парсить аргументы командной строки. В этом случае вы определяете main вот так:
int main (int argc, char* argv[]) {
// argc - количество переданных аргументов
// argv - массив из переданных аргументов
// some parsing
}Однако в стандарте описан еще один способ определения main:
int main(/ implementation-defined /) {body}Стандарт разрешает компиляторам давать возможность пользователям как-то по-другому задавать аргументы для main. И хоть это будет не переносимо, нам не всегда нужна кроссплатформенность.
Самая часто встречающаяся нестандартная сигнатура main следующая:
int main(int argc, char* argv[], char* envp[]) {}Третий аргумент main - это массив строк переменных окружения в формате "KEY=value". Массив завершается null pointer'ом.
Программа получает копию переменных окружения родительского процесса (например, терминала или скрипта). Только лишь независимую копию: изменение набора и значения переменных снаружи программы никак не влияет на то, что происходит внутри нее.
Вот минимальный примерчик:
#include <iostream>
int main(int argc, char* argv[], char* envp[]) {
std::cout << "Environment variables:\n";
for (char** env = envp; *env != nullptr; env++) {
std::cout << *env << "\n";
}
return 0;
}
Возможный вывод:
PATH=/usr/local/bin:/usr/bin:/bin
USER=grokaem_cpp
...
Вы не так часто можете увидеть этот формат сигнатуры main по уже очевидным для вас причинам:
- нестандарт
- а самое главное - это дело надо парсить. Засовывать в мапу какую-то и искать потом по ключу нужную переменную. А зачем, если есть std::getenv или его брат getenv из Сей.
Рассказываю про это, чтобы вы при встрече в таким форматом аргументов main не думали, что что-то базовое упустили при изучении плюсов. Ну или просто для расширения кругозора)
Expand your horizons. Stay cool.
#NONSTANDARD #goodoldc
{kind=link}
👍52❤19🔥4😱4
or and not
#новичкам
В С/C++ всегда был не очень дружелюбный синтаксис операторов. Показать вот такой код человеку, который не в зуб ногой в программировании:
есть вероятность, что он подумает, что его прокляли шаманы тумба-юмба.
Однако знали ли вы, что в С/C++ есть альтернативный синтаксис токенов? Символы операторов заменяются на короткие слова и код выше становится почти питонячьим:
Выглядит свежо! Хотя было доступно еще с С++98.
Вот полный список альтернативных токенов:
Последние токены для скобок - это конечно дичь. Но остальные - вполне интересные варианты.
В сях альтернативные токены были введены в С95, поэтому до этого момента токенов не было в языке. Но даже с их введением все продолжали использовать привычный синтаксис. Видимо поэтому мы так до сих пор и остались на уровне наскальной живописи.
А вы используете в продакшен коде альтернативные токены?
Evolve. Stay cool.
#fun #goodoldc
#новичкам
В С/C++ всегда был не очень дружелюбный синтаксис операторов. Показать вот такой код человеку, который не в зуб ногой в программировании:
if (x > 0 && y < 10 || !z) {
// ...
}есть вероятность, что он подумает, что его прокляли шаманы тумба-юмба.
Однако знали ли вы, что в С/C++ есть альтернативный синтаксис токенов? Символы операторов заменяются на короткие слова и код выше становится почти питонячьим:
if (x > 0 and y < 10 or not z) {
// ...
}Выглядит свежо! Хотя было доступно еще с С++98.
Вот полный список альтернативных токенов:
&& - and
&= - and_eq
& - bitand
| - bitor
~ - compl
!= - not_eq
|| - or
|= - or_eq
^ - xor
^= - xor_eq
{ - <%
} - %>
[ - <:
] - :>
# - %:
## - %:%:
Последние токены для скобок - это конечно дичь. Но остальные - вполне интересные варианты.
В сях альтернативные токены были введены в С95, поэтому до этого момента токенов не было в языке. Но даже с их введением все продолжали использовать привычный синтаксис. Видимо поэтому мы так до сих пор и остались на уровне наскальной живописи.
А вы используете в продакшен коде альтернативные токены?
Evolve. Stay cool.
#fun #goodoldc
{kind=link}
❤39👍11🔥7😱5👎3
ssize_t
#новичкам
Есть такой интересный тип ssize_t. Интересный он, потому что в отличии от стандартных типов имеет несимметричный относительно нуля диапазон значений [-1, SSIZE_MAX]. То есть это знаковый тип, но с нюансом, что отрицательное значение может быть только одно: -1.
Зачем такой тип нужен?
В posix api есть много функций, которые возвращают количество байт. Но так как это С и там нет исключений, а об ошибках как-то надо говорить, то значение -1 является индикатором ошибки:
Если вы работаете с сырыми дескрипторами, то явно пользуетесь функциями read и write, которые возвращают количество считанных или записанных байт соответственно. Если что-то пошло не так, то вместо количества байт возвращается -1:
Но почему этого типа нет в С++ стандарте? С его помощью мы бы могли например решить задачу итерации по контейнеру в обратном порядке из предыдущего поста.
Ответ простой, если подумать. Этот тип нужен только для апи, которое возвращает -1, как ошибку. В С++ есть исключения, объекты и шаблоны. С помощью этих трех инструментов можно как душе вздумается сообщать об ошибках. И это будет лучше и экспрессивнее, чем просто -1.
Use the right tool. Stay cool.
#cppcore #goodoldc #NONSTANDARD
#новичкам
Есть такой интересный тип ssize_t. Интересный он, потому что в отличии от стандартных типов имеет несимметричный относительно нуля диапазон значений [-1, SSIZE_MAX]. То есть это знаковый тип, но с нюансом, что отрицательное значение может быть только одно: -1.
Зачем такой тип нужен?
В posix api есть много функций, которые возвращают количество байт. Но так как это С и там нет исключений, а об ошибках как-то надо говорить, то значение -1 является индикатором ошибки:
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void buf, size_t count);
Если вы работаете с сырыми дескрипторами, то явно пользуетесь функциями read и write, которые возвращают количество считанных или записанных байт соответственно. Если что-то пошло не так, то вместо количества байт возвращается -1:
char buffer[1024];
ssize_t bytes_read = read(fd, buffer, sizeof(buffer));
if (bytes_read == -1) { / Обработка ошибки */ }
Но почему этого типа нет в С++ стандарте? С его помощью мы бы могли например решить задачу итерации по контейнеру в обратном порядке из предыдущего поста.
Ответ простой, если подумать. Этот тип нужен только для апи, которое возвращает -1, как ошибку. В С++ есть исключения, объекты и шаблоны. С помощью этих трех инструментов можно как душе вздумается сообщать об ошибках. И это будет лучше и экспрессивнее, чем просто -1.
Use the right tool. Stay cool.
#cppcore #goodoldc #NONSTANDARD
{kind=link}
🔥38👍19❤10😁3👎1