Приветственный пост
Рады приветствовать всех на нашем канале!
Вы устали от скучного, монотонного, обезличенного контента по плюсам?
Тогда мы идем к вам!
Здесь не будет бесполезных 30 IQ постов, сгенеренных ChatGPT, накрученных подписчиков и активности.
Канал ведут два сеньора, Денис и Владимир, которые искренне хотят делится своими знаниями по С++ и создать самое уютное коммьюнити позитивных прогеров в телеге!
(ну вы поняли, да? с++, плюс плюс, плюс типа
позитивный?.. ай ладно)
Жмакай и попадешь в наш чат. Там обсуждения не привязаны к постам, можете общаться на любые темы.
Материалы для новичка
ГАЙДЫ:
Мини-гайд по собеседованиям
Гайд по тестовым заданиям
Гайд по категория выражения и мув-семантике
Гайд по inline
Дальше пойдет список хэштегов, которыми вы можете пользоваться для более удобной навигации по каналу и для быстрого поиска группы постов по интересующей теме:
#algorithms
#datastructures
#cppcore
#stl
#goodoldc
#cpp11
#cpp14
#cpp17
#cpp20
#commercial
#net
#database
#hardcore
#memory
#goodpractice
#howitworks
#NONSTANDARD
#interview
#digest
#OS
#tools
#optimization
#performance
#fun
#compiler
#design
#exception
#guide
#задачки
#base
#quiz
#concurrency
#ЧЗХ
#ревью
Рады приветствовать всех на нашем канале!
Вы устали от скучного, монотонного, обезличенного контента по плюсам?
Тогда мы идем к вам!
Здесь не будет бесполезных 30 IQ постов, сгенеренных ChatGPT, накрученных подписчиков и активности.
Канал ведут два сеньора, Денис и Владимир, которые искренне хотят делится своими знаниями по С++ и создать самое уютное коммьюнити позитивных прогеров в телеге!
(ну вы поняли, да? с++, плюс плюс, плюс типа
позитивный?.. ай ладно)
Жмакай и попадешь в наш чат. Там обсуждения не привязаны к постам, можете общаться на любые темы.
Материалы для новичка
ГАЙДЫ:
Мини-гайд по собеседованиям
Гайд по тестовым заданиям
Гайд по категория выражения и мув-семантике
Гайд по inline
Дальше пойдет список хэштегов, которыми вы можете пользоваться для более удобной навигации по каналу и для быстрого поиска группы постов по интересующей теме:
#algorithms
#datastructures
#cppcore
#stl
#goodoldc
#cpp11
#cpp14
#cpp17
#cpp20
#commercial
#net
#database
#hardcore
#memory
#goodpractice
#howitworks
#NONSTANDARD
#interview
#digest
#OS
#tools
#optimization
#performance
#fun
#compiler
#design
#exception
#guide
#задачки
#base
#quiz
#concurrency
#ЧЗХ
#ревью
Telegram
Грокаем C++ Chat
You’ve been invited to join this group on Telegram.
🔥38❤19👍15🤔2🐳1
База алгоритмов STL
Когда я только изучал плюсы, меня приводило в ступор обилие и разнообразие в стандартной библиотеке. Контейнеры еще куда ни шло. Их довольно немного, а, при знании их устройства, с ними довольно комфортно работать per se.
Но вот алгоритмы…
Их дохрена, хрен их запомнишь и хрен поймешь еще, когда их использовать.
А что, если я скажу, что в бэкэнд разработке в 99% случаев будут использоваться только три алгоритма?
Естественно, в этот список не входят пустышки, типа
std::swap и прочей тривиальщины.
В следующих постах буду раскрывать каждый из этих
алгоритмов.
Stay Cool.
#STL #algorithms
Когда я только изучал плюсы, меня приводило в ступор обилие и разнообразие в стандартной библиотеке. Контейнеры еще куда ни шло. Их довольно немного, а, при знании их устройства, с ними довольно комфортно работать per se.
Но вот алгоритмы…
Их дохрена, хрен их запомнишь и хрен поймешь еще, когда их использовать.
А что, если я скажу, что в бэкэнд разработке в 99% случаев будут использоваться только три алгоритма?
Естественно, в этот список не входят пустышки, типа
std::swap и прочей тривиальщины.
В следующих постах буду раскрывать каждый из этих
алгоритмов.
Stay Cool.
#STL #algorithms
{kind=link}
👍28🤡6❤3🔥3
Сортировка
std::sort - самый нужный и наиболее часто используемый алгоритм из библиотеки STL. Не зря мир серьезных алгоритмов маленькие хакеры начинают познавать с сортировки. Конечно после изучения всех базовых концепций языка и программных сущностей. Это реально нужная на практике вещь.
Давайте на пальцах.
Есть у вас вектор для каких-то объектов. Вы заполняете этот вектор объектами просто с помощью push_back. Здесь есть 2 варианта.
Первый вариант - порядок элементов неважен, работаем со всеми элементами по очереди или только с крайними(ну например очередь задач или список слушателей евентов класса). Тут все просто, испотльзуй методы контейнера и живи счастливо.
Второй вариант - вы хотите переупорядочить элементы в контейнере или сделать вставку/удаление/поиск/изменение элемента из середины контейнера. Тут все сложнее. Для начала надо подумать, потому что вы скорее всего выбрали неправильный контейнер. Алгоритмы find, remove и тому подобное - от Иблиса. Может показаться, что линейная сложность не проблема, не так уж это и много. Но нет. Вряд ли вам нужно один раз найти какой-то элемент к контейнере и скорее всего там будет квадратичная сложность. Про удаление я вообще молчу, внутреннее устройство вектора даст вашему первомансу отдохнуть.
Присмотритесь к ассоциативным контейнерам, когда вам нужны такие операции. И если нужно переупорядочивать элементы, то тоже проверьте себя еще раз.
Проверили? Идем дальше. У нас остается вектор и вы хотите его переупорядочить. Переупорядочить - назначить отношение порядка. Значит можно сказать, какой элемент идет за каким. Значит можно сказать, какой элемент "меньше" другого. Так и приходим к сортировке.
По факту, сортировка - единственный алгоритм, который реально можно применить для последовательных контейнеров. Ну ладно не единственный. Но это уже тема для другого поста.
Stay cool.
#STL #algorithms
std::sort - самый нужный и наиболее часто используемый алгоритм из библиотеки STL. Не зря мир серьезных алгоритмов маленькие хакеры начинают познавать с сортировки. Конечно после изучения всех базовых концепций языка и программных сущностей. Это реально нужная на практике вещь.
Давайте на пальцах.
Есть у вас вектор для каких-то объектов. Вы заполняете этот вектор объектами просто с помощью push_back. Здесь есть 2 варианта.
Первый вариант - порядок элементов неважен, работаем со всеми элементами по очереди или только с крайними(ну например очередь задач или список слушателей евентов класса). Тут все просто, испотльзуй методы контейнера и живи счастливо.
Второй вариант - вы хотите переупорядочить элементы в контейнере или сделать вставку/удаление/поиск/изменение элемента из середины контейнера. Тут все сложнее. Для начала надо подумать, потому что вы скорее всего выбрали неправильный контейнер. Алгоритмы find, remove и тому подобное - от Иблиса. Может показаться, что линейная сложность не проблема, не так уж это и много. Но нет. Вряд ли вам нужно один раз найти какой-то элемент к контейнере и скорее всего там будет квадратичная сложность. Про удаление я вообще молчу, внутреннее устройство вектора даст вашему первомансу отдохнуть.
Присмотритесь к ассоциативным контейнерам, когда вам нужны такие операции. И если нужно переупорядочивать элементы, то тоже проверьте себя еще раз.
Проверили? Идем дальше. У нас остается вектор и вы хотите его переупорядочить. Переупорядочить - назначить отношение порядка. Значит можно сказать, какой элемент идет за каким. Значит можно сказать, какой элемент "меньше" другого. Так и приходим к сортировке.
По факту, сортировка - единственный алгоритм, который реально можно применить для последовательных контейнеров. Ну ладно не единственный. Но это уже тема для другого поста.
Stay cool.
#STL #algorithms
{kind=link}
👍28❤7🔥2
std::lower_bound
Продолжение басни с алгоритмами в STL. Предыдущие части можете найти тут жмак и жмак
Сегодня речь пойдет про бинарный поиск. Точнее немного более прикладную его вариацию - std::lower_bound.
На самом деле не удивительно, почему в списке 3-х самых используемых алгоритмов есть этот, учитывая, что на первом месте стояла сортировка. Если что-то и искать, то искать надо в упорядоченных структурах данных. Ведь преимущества очевидны: О(n) против O(logn) (можно и за О(1), но это другая уже другая история). Поэтому следует избегать использования линейного поиска (типа std::find), а использовать подходящий контейнер и эффективный алгоритм поиска над ним.
Функция выполняет поиск в отсортированном диапазоне и возвращает итератор на первый элемент, не меньший, чем заданное значение. За счет того, что поиск происходит в упорядоченном контейнере, алгоритмическая сложность такой операции - О(logn). То есть это очень эффективный способ найти нужный элемент в контейнере. В основе алгоритма лежит бинарный поиск, где на каждой итерации цикла диапазон поиска уменьшается вдвое.
Алгоритм может использоваться, как для поиска конкретного элемента, так и для поиска диапазона значений самостоятельно (открытый диапазон) или в сочетании с upper_bound (закрытый диапазон).
Немного более вариабельным lower_bound становится в применении к деревьям. Тогда возвращаемый итератор можно использовать для эффективной вставки ноды в дерево (например методом map::emplace_hint).
И не зря довольно часто на собесах встречаются задачи на бинарный поиск. Потому что это реально маст-хэв. Поэтому его в принципе полезно знать и уметь запрогать руками.
Stay cool.
#STL #algorithms #datastructures
Продолжение басни с алгоритмами в STL. Предыдущие части можете найти тут жмак и жмак
Сегодня речь пойдет про бинарный поиск. Точнее немного более прикладную его вариацию - std::lower_bound.
На самом деле не удивительно, почему в списке 3-х самых используемых алгоритмов есть этот, учитывая, что на первом месте стояла сортировка. Если что-то и искать, то искать надо в упорядоченных структурах данных. Ведь преимущества очевидны: О(n) против O(logn) (можно и за О(1), но это другая уже другая история). Поэтому следует избегать использования линейного поиска (типа std::find), а использовать подходящий контейнер и эффективный алгоритм поиска над ним.
Функция выполняет поиск в отсортированном диапазоне и возвращает итератор на первый элемент, не меньший, чем заданное значение. За счет того, что поиск происходит в упорядоченном контейнере, алгоритмическая сложность такой операции - О(logn). То есть это очень эффективный способ найти нужный элемент в контейнере. В основе алгоритма лежит бинарный поиск, где на каждой итерации цикла диапазон поиска уменьшается вдвое.
Алгоритм может использоваться, как для поиска конкретного элемента, так и для поиска диапазона значений самостоятельно (открытый диапазон) или в сочетании с upper_bound (закрытый диапазон).
Немного более вариабельным lower_bound становится в применении к деревьям. Тогда возвращаемый итератор можно использовать для эффективной вставки ноды в дерево (например методом map::emplace_hint).
И не зря довольно часто на собесах встречаются задачи на бинарный поиск. Потому что это реально маст-хэв. Поэтому его в принципе полезно знать и уметь запрогать руками.
Stay cool.
#STL #algorithms #datastructures
👍15🔥4❤2
Как найти минимум в несортированном массиве за константу
Ответ на первый взгляд простой и понятной - хрена с два у тебя такое прокатит. Но что, если вам говорят на собесе : "Вот есть класс стека с методами push_back и pop_back и есть метод min. Нужно, чтобы метод min работал за константное время". Как ни отникивайся, придется решать. Чем мы с вами и займемся. А перед этим делом сами подумайте: как бы вы это сделали? Бывалым ценителям алгоритмических задачек этот вопрос даже каплю пота не вызовет, а вот средних работяг может заставить попотеть.
Первое, что надо понимать - если у вас просто есть готовый массив и ничего больше, то вы не найдете минимум за константное время. Нужно что-то думать. Второе, что надо понимать - очень часто можно довольно просто понизить сложность операции за счет применения правильного хранилища. Например, если превратить массив в неупорядоченное мультимножество, то сложность поиска понижается с О(n) до О(~1). И с этой мысли нужно начинать, когда от вас требуют понизить сложность. Задумайтесь. Не зря нам дали удобную обертку для массива. Мы можем контролировать, как именно будут добавляться и удаляться данные из него, а также можем хранить в этом классе какие-то дополнительные структуры.
В данном случае, решением будет добавить в класс поле current_min_stack - стек, в который будет хранить текущие минимумы для каждого элемента исходного массива. Как только вызывается push_back(value), в current_min_stack добавляется минимум из value и текущей верхушки current_min_stack. На каждый вызов pop_back мы убираем из current_min_stack его последний элемент. А на вызов min мы возвращаем последний элемент из стека текущего минимума.
Не самый эффективный способ, знаем и получше. Вот и напишите в комментах, как улучшить алгоритм.
Stay cool.
#algorithms
Ответ на первый взгляд простой и понятной - хрена с два у тебя такое прокатит. Но что, если вам говорят на собесе : "Вот есть класс стека с методами push_back и pop_back и есть метод min. Нужно, чтобы метод min работал за константное время". Как ни отникивайся, придется решать. Чем мы с вами и займемся. А перед этим делом сами подумайте: как бы вы это сделали? Бывалым ценителям алгоритмических задачек этот вопрос даже каплю пота не вызовет, а вот средних работяг может заставить попотеть.
Первое, что надо понимать - если у вас просто есть готовый массив и ничего больше, то вы не найдете минимум за константное время. Нужно что-то думать. Второе, что надо понимать - очень часто можно довольно просто понизить сложность операции за счет применения правильного хранилища. Например, если превратить массив в неупорядоченное мультимножество, то сложность поиска понижается с О(n) до О(~1). И с этой мысли нужно начинать, когда от вас требуют понизить сложность. Задумайтесь. Не зря нам дали удобную обертку для массива. Мы можем контролировать, как именно будут добавляться и удаляться данные из него, а также можем хранить в этом классе какие-то дополнительные структуры.
В данном случае, решением будет добавить в класс поле current_min_stack - стек, в который будет хранить текущие минимумы для каждого элемента исходного массива. Как только вызывается push_back(value), в current_min_stack добавляется минимум из value и текущей верхушки current_min_stack. На каждый вызов pop_back мы убираем из current_min_stack его последний элемент. А на вызов min мы возвращаем последний элемент из стека текущего минимума.
Не самый эффективный способ, знаем и получше. Вот и напишите в комментах, как улучшить алгоритм.
Stay cool.
#algorithms
{kind=link}
👍24🔥6❤4👎2🤪1
Проверяем число на степень двойки
У меня всегда была страсть к решению разного рода задачек и меня всегда восхищало то, как более компетентные люди используют неочевидные способы решения таких задач. Это всегда подстегивает энтузиазм и желание изучать новое. Сегодняшняя тема однажды привела меня в шоковое состояние, когда я проверял своё решение.
Казалось бы. Очень простая задача. Узнать, является ли число степенью двойки. Решаем через цикл, пока число не равно единице, делим на два и если ни при одном делении нет остатка - число является степенью двойки. Если хоть один остаток от деления был, тогда не является.
Или сдвигаем число вправо побитово на один бит на каждой итерации и если он нулевой всегда, то возвращаем true.
Написали, запускаем тесты. Тесты проходят. Победа. Небольшая конечно, задача-то плевая. А потом ты заходишь в решения и видишь, что кто-то решил эту задачу за константную сложность. What. The. Fuck. ???
Чтобы самостоятельно решить задачу за константу, нужно глубоко шарить за системы счисления. Чтобы понять, как решать, глубоко шарить не нужно, там все просто. Попробуйте подумать пару минут, я подожду……….
Решили? Надеюсь у нас здесь сборник гениев и все решили. А для таких, как я, рассказываю.
Когда число является степенью основания системы счисления, оно представляется как единица с несколькими нулями, например, 1000 в двоичной - это 8, 10000 - это 16. Ну вы поняли. С десятичной же тоже самое. Причём количество нулей равно показателю степени числа.
Ещё вводные. Если мы вычтем единицу из нашего числа, то получим новое число, количество разрядов которого ровно на один меньше, и каждая цифра которого сменится с нуля на единицу. Например, 100 - 1 = 11, 1000 - 1 = 111, 10000 - 1 = 1111.
Теперь магия. Когда мы применим операцию логического И к исходному числу Х и к числу Х - 1, то мы получим ноль. Х & (Х - 1) = 0.
Вот так вот. Всего 3 простейшие операции помогут вам определить, является ли число степенью двойки.
Строгое доказательство данного утверждения опущу за ненадобностью, смельчаки в комментах могут попробовать его оформить.
А вы знаете какие-нибудь удивительные решения простых задачек? Оставьте ответ в комментах.
Stay optimized. Stay cool.
#algorithms #fun
У меня всегда была страсть к решению разного рода задачек и меня всегда восхищало то, как более компетентные люди используют неочевидные способы решения таких задач. Это всегда подстегивает энтузиазм и желание изучать новое. Сегодняшняя тема однажды привела меня в шоковое состояние, когда я проверял своё решение.
Казалось бы. Очень простая задача. Узнать, является ли число степенью двойки. Решаем через цикл, пока число не равно единице, делим на два и если ни при одном делении нет остатка - число является степенью двойки. Если хоть один остаток от деления был, тогда не является.
Или сдвигаем число вправо побитово на один бит на каждой итерации и если он нулевой всегда, то возвращаем true.
Написали, запускаем тесты. Тесты проходят. Победа. Небольшая конечно, задача-то плевая. А потом ты заходишь в решения и видишь, что кто-то решил эту задачу за константную сложность. What. The. Fuck. ???
Чтобы самостоятельно решить задачу за константу, нужно глубоко шарить за системы счисления. Чтобы понять, как решать, глубоко шарить не нужно, там все просто. Попробуйте подумать пару минут, я подожду……….
Решили? Надеюсь у нас здесь сборник гениев и все решили. А для таких, как я, рассказываю.
Когда число является степенью основания системы счисления, оно представляется как единица с несколькими нулями, например, 1000 в двоичной - это 8, 10000 - это 16. Ну вы поняли. С десятичной же тоже самое. Причём количество нулей равно показателю степени числа.
Ещё вводные. Если мы вычтем единицу из нашего числа, то получим новое число, количество разрядов которого ровно на один меньше, и каждая цифра которого сменится с нуля на единицу. Например, 100 - 1 = 11, 1000 - 1 = 111, 10000 - 1 = 1111.
Теперь магия. Когда мы применим операцию логического И к исходному числу Х и к числу Х - 1, то мы получим ноль. Х & (Х - 1) = 0.
Вот так вот. Всего 3 простейшие операции помогут вам определить, является ли число степенью двойки.
Строгое доказательство данного утверждения опущу за ненадобностью, смельчаки в комментах могут попробовать его оформить.
А вы знаете какие-нибудь удивительные решения простых задачек? Оставьте ответ в комментах.
Stay optimized. Stay cool.
#algorithms #fun
{kind=link}
👍21❤5🔥5
std::transform
Последний пост из серии про 3 самых нужных алгоритма STL. Предыдущая часть тут.
Часто при работе с текстом или с сырыми числовыми данными нам нужно каким-то образом предобработать все это дело. Ну например, привести все буквы к нижнему регистру. Или поменять все небуквенные символы в пробелы. Или занулить все отрицательные числа в массиве. Эти задачи больше приближены к обработке пользовательского ввода или файлов с данными. Поэтому, хоть и не очень часто, но тут и там встречаются в бэкэнд приложениях. И такую простую предобработку объектов может на себя взять алгоритм std::transform.
Не такой уж он из себя какой-то особенный алгоритм. Просто проходится по одному ренджу, применяет к элементам операцию и записывает в другую последовательность. По факту, просто проход по итераторам, ничего супералгоритмического. Я могу и сам запросто такое написать, не опасаясь долгой отладки. Однако у std::transform полно преимуществ, по сравнению с таким подходом.
1️⃣ Это стандартный именованный алгоритм. Все плюсовые программисты знают, что это такое и будут быстрее понимать ваш код.
2️⃣ Стандартные алгоритмы обычно написаны оптимально и работают быстрее, чем самописный код.
3️⃣ Универсальный обобщенный интерфейс. Я могу записывать обработанные данные в любой другой контейнер или в тот же самый. Главное, чтобы типы контейнеров и возвращаемого значения унарного оператора метчились.
Почему этот алгоритм достоин оказаться в тройке полезнейших? Я немного наврал во введении о сфере его применения. Дело в том, что бэкэнд-приложения построены вокруг data flow. То есть от пользователей получают какие-то данные и дальше эти данные проходят длинный цикл обработки, сохранения, кэширования и прочих безобразий. Данные на протяжении своего цикла жизни претерпевают различные преобразования. В одном случае данные представлены в атомарном семантическом виде: запрос, сообщение, геопозиция и так далее. И преобразовываются они атомарно. А в других случаях мы имеем семантическую группу данных для обработки: буквы в тексте, несколько текстов, пиксели для изображения и тд. И эти данные надо как-то трансформировать в другие данные по ходу того самого flow. Вот именно для такого широкого контекста задач хорошо применим std::transform. Просто для поддержки этого утверждения приведу несколько примеров конкретных задач. Нормализация численного массива, применение фильтров к изображениям, манипуляции со строками, манипуляции буквами в строках, шифрование набора текстов, хеширование набора объектов, преобразование даты и времени между разными часовыми поясами, преобразование географических координат, бесконечное множество математических преобразований. Вроде увесисто и убедительно получилось.
На этом завершаю этот цикл постов. Пользуйтесь стандартной библиотекой с умом и будет вам счастье)
Stay completed. Stay cool.
#STL #algorithms
Последний пост из серии про 3 самых нужных алгоритма STL. Предыдущая часть тут.
Часто при работе с текстом или с сырыми числовыми данными нам нужно каким-то образом предобработать все это дело. Ну например, привести все буквы к нижнему регистру. Или поменять все небуквенные символы в пробелы. Или занулить все отрицательные числа в массиве. Эти задачи больше приближены к обработке пользовательского ввода или файлов с данными. Поэтому, хоть и не очень часто, но тут и там встречаются в бэкэнд приложениях. И такую простую предобработку объектов может на себя взять алгоритм std::transform.
Не такой уж он из себя какой-то особенный алгоритм. Просто проходится по одному ренджу, применяет к элементам операцию и записывает в другую последовательность. По факту, просто проход по итераторам, ничего супералгоритмического. Я могу и сам запросто такое написать, не опасаясь долгой отладки. Однако у std::transform полно преимуществ, по сравнению с таким подходом.
1️⃣ Это стандартный именованный алгоритм. Все плюсовые программисты знают, что это такое и будут быстрее понимать ваш код.
2️⃣ Стандартные алгоритмы обычно написаны оптимально и работают быстрее, чем самописный код.
3️⃣ Универсальный обобщенный интерфейс. Я могу записывать обработанные данные в любой другой контейнер или в тот же самый. Главное, чтобы типы контейнеров и возвращаемого значения унарного оператора метчились.
Почему этот алгоритм достоин оказаться в тройке полезнейших? Я немного наврал во введении о сфере его применения. Дело в том, что бэкэнд-приложения построены вокруг data flow. То есть от пользователей получают какие-то данные и дальше эти данные проходят длинный цикл обработки, сохранения, кэширования и прочих безобразий. Данные на протяжении своего цикла жизни претерпевают различные преобразования. В одном случае данные представлены в атомарном семантическом виде: запрос, сообщение, геопозиция и так далее. И преобразовываются они атомарно. А в других случаях мы имеем семантическую группу данных для обработки: буквы в тексте, несколько текстов, пиксели для изображения и тд. И эти данные надо как-то трансформировать в другие данные по ходу того самого flow. Вот именно для такого широкого контекста задач хорошо применим std::transform. Просто для поддержки этого утверждения приведу несколько примеров конкретных задач. Нормализация численного массива, применение фильтров к изображениям, манипуляции со строками, манипуляции буквами в строках, шифрование набора текстов, хеширование набора объектов, преобразование даты и времени между разными часовыми поясами, преобразование географических координат, бесконечное множество математических преобразований. Вроде увесисто и убедительно получилось.
На этом завершаю этот цикл постов. Пользуйтесь стандартной библиотекой с умом и будет вам счастье)
Stay completed. Stay cool.
#STL #algorithms
{kind=link}
❤11🥰2👍1
Remove-erase идиома
Удаление элементов из вектора - вещь не совсем тривиальная. Безусловно, в STL есть интерфейс для этого, бери да вызывай. Проблема в том, что удаление вызывает копирование всех элементов вектора, которые находятся правее от удаляемого элемента. То есть, в среднем, сложность удаления одного элемента контейнера будет линейной. А сложность очистки всего контейнера - квадратичная. Это все очень печальные результаты. И хоть для последовательности упорядоченных элементов нет стандартного алгоритма удаления из середины, для вектора, в котором порядок неважен, такой алгоритм есть.
Нам нужно лишь свопнуть удаляемый элемент с последним элементом в векторе и очистить последнюю с конца ячейку. Таким образом, удаление будет занимать всего 2 действия, а значит сложность этой операции - константная. Звучит намного лучше.
А что, если нужно отфильтровать массив по какому-то критерию? Ну удалить все ячейки, которые обладают какими-то характеристиками. Например, из массива удалить все числа, кратные 5. Надо тогда в цикле проделать действия из предыдущего абзаца и все будет пучком.
Однако, есть ощущение, что это задача слишком общая и хотелось бы иметь для нее какое-то более элегантное решение, чем каждый раз писать цикл. Можно конечно объявить функцию, но все-таки хочется чего-то стандартного.
И такое есть. В плюсах это называется remove-erase idiom. Идиома удаления-очистки. Какой у меня прекрасный английский)
Решение хоть и стандартное, но не прям очень элегантное. Ну а что вы хотели? Это плюсы все-таки.
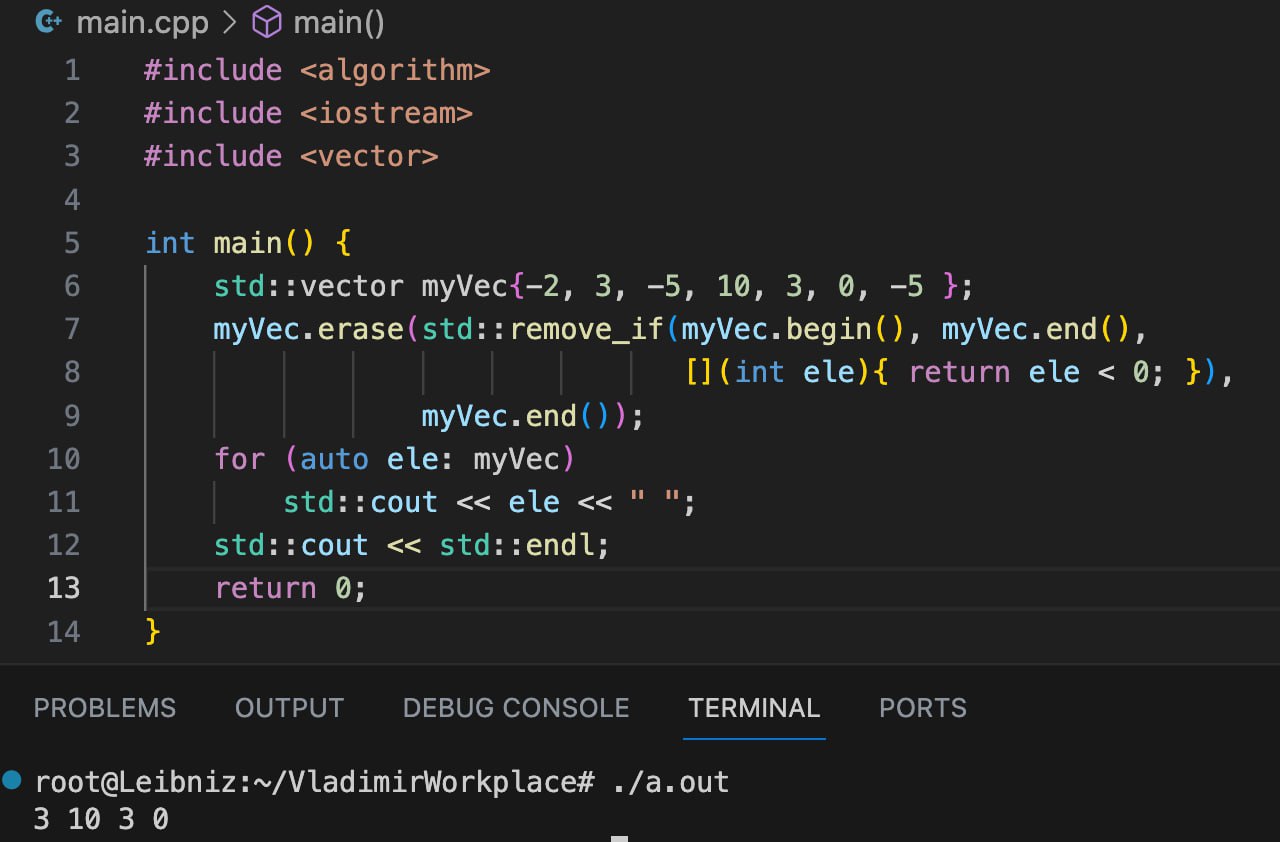
Судя по названию, надо просто скомбинировать стандартный алгоритм std::remove (или std::remove_if) и метод вектора std::vector::erase.
На картинке снизу можете увидеть, как конкретно эта комбинация решает задачу удаления элементов.
Stay cool.
#algorithms #STL #datastructures
Удаление элементов из вектора - вещь не совсем тривиальная. Безусловно, в STL есть интерфейс для этого, бери да вызывай. Проблема в том, что удаление вызывает копирование всех элементов вектора, которые находятся правее от удаляемого элемента. То есть, в среднем, сложность удаления одного элемента контейнера будет линейной. А сложность очистки всего контейнера - квадратичная. Это все очень печальные результаты. И хоть для последовательности упорядоченных элементов нет стандартного алгоритма удаления из середины, для вектора, в котором порядок неважен, такой алгоритм есть.
Нам нужно лишь свопнуть удаляемый элемент с последним элементом в векторе и очистить последнюю с конца ячейку. Таким образом, удаление будет занимать всего 2 действия, а значит сложность этой операции - константная. Звучит намного лучше.
А что, если нужно отфильтровать массив по какому-то критерию? Ну удалить все ячейки, которые обладают какими-то характеристиками. Например, из массива удалить все числа, кратные 5. Надо тогда в цикле проделать действия из предыдущего абзаца и все будет пучком.
Однако, есть ощущение, что это задача слишком общая и хотелось бы иметь для нее какое-то более элегантное решение, чем каждый раз писать цикл. Можно конечно объявить функцию, но все-таки хочется чего-то стандартного.
И такое есть. В плюсах это называется remove-erase idiom. Идиома удаления-очистки. Какой у меня прекрасный английский)
Решение хоть и стандартное, но не прям очень элегантное. Ну а что вы хотели? Это плюсы все-таки.
Судя по названию, надо просто скомбинировать стандартный алгоритм std::remove (или std::remove_if) и метод вектора std::vector::erase.
На картинке снизу можете увидеть, как конкретно эта комбинация решает задачу удаления элементов.
Stay cool.
#algorithms #STL #datastructures
{kind=link}
👍9🔥6❤4
Зачем для Remove-Erase идиомы нужны 2 алгоритма?
Удалить из вектора элементы по значению или подходящие под какой-то шаблон не получится напрямую через API вектора. Ну точнее получится, просто вы не хотите, чтобы получалось именно так)
Дело в том, что метод erase у вектора действительно удаляет элемент или рэндж элементов. Но как он это делает?
Вектор - массив смежных ячеек памяти, в которых находятся объекты. То есть один элемент заканчивается и начинается новый. Представим, что мы хотим удалить объект где-нибудь в середине массива. Если мы просто вызовем деструктор этого объекта(отдельную ячейку памяти вернуть системе мы не можем), то тогда у нас нарушится этот инвариант вектора, что все элементы идут друг за другом. И это чисто идейная проблема. А на практике это место в памяти еще и можно было бы также итерпретировать, как живой объект, и работать с ним. Потому что в векторе нет механизма запоминания данных об удаленных ячейках. А если удалять рэндж, то будет целая область пустующая.
Решается эта проблема метода erase сдвигом влево всех элементов, которые остались справа после удаленных. То есть либо копированием, либо перемещением объектов. Тогда все дырки заполнены, инвариантов не нарушено. Но это линейная сложность удаления. То есть на удаление каждого одиноко стоящего элемента нужно тратить линейное время. И для фильтрации всего массива понадобится уже квадратичное время, что не может не огорчать.
Хорошо. Лезем в cpp-reference и находим там алгоритмы std::remove и std:remove_if. Они принимают рендж начало-конец, ищут там конкретное значение или проверяют предикат на верность и удаляют найденные элементы. Вот что там написано про сложность:
Given
1,2) exactly
3,4) exactly
Сложность удаления найденных элементов - линейная. Ну отлично. Х*як и в рабочий код. Тесты валятся, код работает не так как ожидалось. После применения алгоритма на самом деле ничего не удалилось. Элементов столько же, только они в каком-то странном порядке. Почему?
Это я объясняю в видосе из вчерашнего поста. Довольно сложно описать работу std::remove на пальцах в тексте, поэтому и видео появилось. Но для тех, кто не смотрел кратко зарезюмирую. С помощью двух указателей нужные элементы остаются в массиве и перемещаются на свои новые места и делается это так, что в конце массива скапливаются ненужные ячейки. А возвращается из алгоритма итератор на новый конец последовательности, то есть на начало вот этого скопления. Получается std::remove ничего не удаляет, он только переупорядочивает элементы.
И это хорошо, потому что теперь мы можем действительно удалить эти элементы. Причем все разом. Делается это через уже знакомый нам метод вектора erase. Если erase очищает рэндж и этот рендж заканчивается последним элементом, то никаких копирований не происходит. Вызываются деструкторы объектов и изменяется поле, хранящее размер массива. Поэтому получается такая каша:
myVec.erase(std::remove(myVec.begin(), myVec.end(), value), myVec.end());
Собственно, когда эти 2 алгоритма применяются в одной строчке, можно наглядно увидеть причину названия идиомы.
Теперь сложность удаления будет линейной, а это уже не может не радовать.
Да, это выглядит не очень солидно, но имеем, что имеем. Хотя в 20-х плюсах эта ситуация изменилась, как-нибудь расскажу про это.
Stay based. Stay cool.
#cppcore #STL #algorithms #datastructures
Удалить из вектора элементы по значению или подходящие под какой-то шаблон не получится напрямую через API вектора. Ну точнее получится, просто вы не хотите, чтобы получалось именно так)
Дело в том, что метод erase у вектора действительно удаляет элемент или рэндж элементов. Но как он это делает?
Вектор - массив смежных ячеек памяти, в которых находятся объекты. То есть один элемент заканчивается и начинается новый. Представим, что мы хотим удалить объект где-нибудь в середине массива. Если мы просто вызовем деструктор этого объекта(отдельную ячейку памяти вернуть системе мы не можем), то тогда у нас нарушится этот инвариант вектора, что все элементы идут друг за другом. И это чисто идейная проблема. А на практике это место в памяти еще и можно было бы также итерпретировать, как живой объект, и работать с ним. Потому что в векторе нет механизма запоминания данных об удаленных ячейках. А если удалять рэндж, то будет целая область пустующая.
Решается эта проблема метода erase сдвигом влево всех элементов, которые остались справа после удаленных. То есть либо копированием, либо перемещением объектов. Тогда все дырки заполнены, инвариантов не нарушено. Но это линейная сложность удаления. То есть на удаление каждого одиноко стоящего элемента нужно тратить линейное время. И для фильтрации всего массива понадобится уже квадратичное время, что не может не огорчать.
Хорошо. Лезем в cpp-reference и находим там алгоритмы std::remove и std:remove_if. Они принимают рендж начало-конец, ищут там конкретное значение или проверяют предикат на верность и удаляют найденные элементы. Вот что там написано про сложность:
Given
N as std::distance(first, last)1,2) exactly
N comparisons with value using operator==.3,4) exactly
N applications of the predicate p.Сложность удаления найденных элементов - линейная. Ну отлично. Х*як и в рабочий код. Тесты валятся, код работает не так как ожидалось. После применения алгоритма на самом деле ничего не удалилось. Элементов столько же, только они в каком-то странном порядке. Почему?
Это я объясняю в видосе из вчерашнего поста. Довольно сложно описать работу std::remove на пальцах в тексте, поэтому и видео появилось. Но для тех, кто не смотрел кратко зарезюмирую. С помощью двух указателей нужные элементы остаются в массиве и перемещаются на свои новые места и делается это так, что в конце массива скапливаются ненужные ячейки. А возвращается из алгоритма итератор на новый конец последовательности, то есть на начало вот этого скопления. Получается std::remove ничего не удаляет, он только переупорядочивает элементы.
И это хорошо, потому что теперь мы можем действительно удалить эти элементы. Причем все разом. Делается это через уже знакомый нам метод вектора erase. Если erase очищает рэндж и этот рендж заканчивается последним элементом, то никаких копирований не происходит. Вызываются деструкторы объектов и изменяется поле, хранящее размер массива. Поэтому получается такая каша:
myVec.erase(std::remove(myVec.begin(), myVec.end(), value), myVec.end());
Собственно, когда эти 2 алгоритма применяются в одной строчке, можно наглядно увидеть причину названия идиомы.
Теперь сложность удаления будет линейной, а это уже не может не радовать.
Да, это выглядит не очень солидно, но имеем, что имеем. Хотя в 20-х плюсах эта ситуация изменилась, как-нибудь расскажу про это.
Stay based. Stay cool.
#cppcore #STL #algorithms #datastructures
{kind=link}
❤10🔥6👍4
Идиома Remove-Erase устарела?
Снова вспомним про эту идиому. В прошлых частях тык и тык(кто не видел эту серию постов, то после первого нужно еще вот этот посмотреть) говорили о том, зачем что это такое, какую проблему решает, и как работает. А в этой части я расскажу, что это все не нужно)
Точнее будет не нужно, после того, как ваши проекты полностью перейдут на С++20.
Дело в том, что этот релиз подарил нам 2 прекрасные шаблонные функции: std::erase и std::erase_if. Чем они занимаются в контексте идиомы? А занимаются они ровно тем же, только намного красивее. Если раньше нам приходилось использовать 2 алгоритма, чтобы удалить нужные элементы из вектора, то здесь нужна всего одна функция.
std::vector<int> myVec = {1, 2, 3, 4, 5};
std::erase(myVec, 2);
И все. Больше ничего не нужно городить. И даже убрали этот некрасивый интерфейс с итераторами (по сути интерфейс крутой и функциональный, но слишком много букав писать надо). Да, для ренджей придется использовать идиому по старинке, но случаи, когда это реально необходимо, очень редки.
Вся прелесть этих функции в том, что они шаблонные. То есть могут принимать на вход любые контейнеры стандартной библиотеки. Примечательно, что для большинства контейнеров эти функции частично специализированы под этот конкретный контейнер. Писать обобщенный код теперь стало еще проще.
Stay updated. Stay cool.
#cpp20 #STL #algorithms
Снова вспомним про эту идиому. В прошлых частях тык и тык(кто не видел эту серию постов, то после первого нужно еще вот этот посмотреть) говорили о том, зачем что это такое, какую проблему решает, и как работает. А в этой части я расскажу, что это все не нужно)
Точнее будет не нужно, после того, как ваши проекты полностью перейдут на С++20.
Дело в том, что этот релиз подарил нам 2 прекрасные шаблонные функции: std::erase и std::erase_if. Чем они занимаются в контексте идиомы? А занимаются они ровно тем же, только намного красивее. Если раньше нам приходилось использовать 2 алгоритма, чтобы удалить нужные элементы из вектора, то здесь нужна всего одна функция.
std::vector<int> myVec = {1, 2, 3, 4, 5};
std::erase(myVec, 2);
И все. Больше ничего не нужно городить. И даже убрали этот некрасивый интерфейс с итераторами (по сути интерфейс крутой и функциональный, но слишком много букав писать надо). Да, для ренджей придется использовать идиому по старинке, но случаи, когда это реально необходимо, очень редки.
Вся прелесть этих функции в том, что они шаблонные. То есть могут принимать на вход любые контейнеры стандартной библиотеки. Примечательно, что для большинства контейнеров эти функции частично специализированы под этот конкретный контейнер. Писать обобщенный код теперь стало еще проще.
Stay updated. Stay cool.
#cpp20 #STL #algorithms
{kind=link}
👍16🔥9❤3
Vector vs List
Знание алгоритмов и структур данных - критично для нашей профессии. Ведь в принципе все, что мы делаем - это берем какие-то явления реального мира, создаем их представления в программе и управляем ими. От нашего понимания эффективного представления данных в памяти компьютера и управления ими зависит количество ресурсов, которое требуется на предоставление какой-то услуги, а значит и доход заказчика. Чем лучше мы знаем эти вещи, тем дешевле предоставлять услугу и тем больше мы ценны как специалисты. И наши доходы растут. Но computer science намного обширнее, чем абстрактные вещи типа теории алгоритмов или архитектуры ПО. Это еще и знание и понимание работы конкретного железа, на котором наш софт выполняется. Что важнее - непонятно. Но только в синергии можно получить топовые результаты.
Согласно теории, проход по массиву и двунаправленному списку происходит за одинаковое алгоритмическое время. O(n). То есть время прохода линейно зависит от количества элементов в структуре. И без применения знаний о принципах работы железа, можно подумать, что они взаимозаменяемы. Просто в одном случае элементы лежат рядом, а в другом - связаны ссылками. А на практике получается, что не совсем линейно и совсем не взаимозаменяемы. Расскажу подробнее о последнем.
Дело в существовании кэша у процессора. Когда мы запрашиваем доступ к одной ячейке памяти, процессор верно предполагает, что нам скорее всего будут нужны и соседние ячейки тоже. Поэтому он копирует целый интервал в памяти, называемый кэш-строкой, в свой промежуточный буфер. А доступ к этому буферу происходит намного быстрее, чем к оперативной памяти. И процессору не нужно ходить за этими рядом лежащими данными в ОЗУ, он их просто берет из кэша.
Элементы же списка хранятся в разных участках памяти и связаны между собой ссылками. В общем виде нет никакой гарантии, что они будут лежать рядом. Если конечно вы не используете кастомный аллокатор. Поэтому за каждым элементом листа процессору приходится ходит в ОЗУ.
Вот и получается, что обработка элементов списка будет происходит медленнее, чем элементов массива.
Написал простенькую программку, которая проверит разницу во времени прохода.
Получилось, что для 100кк чисел в массиве и в листе, время отличается от 1.5 до 2 раз на разных машинах. Нихрена себе такая разница. И это без оптимизаций!
С ними разница вообще 6-8 раз. Это кстати еще один повод для того, чтобы понимать, как именно мы работаем на уровне железа и какие структуры данных хорошо ложатся на разные оптимизации.
Конечно, в реальных приложениях обработка - обычно более дорогая операция, чем просто инкремент и в процентном соотношении затраты на доступ к элементам будут другие. Но для того и пишутся такие тесты, чтобы максимально подсветить проблему.
Stay based. Stay cool.
#STL #algorithms #cppcore
Знание алгоритмов и структур данных - критично для нашей профессии. Ведь в принципе все, что мы делаем - это берем какие-то явления реального мира, создаем их представления в программе и управляем ими. От нашего понимания эффективного представления данных в памяти компьютера и управления ими зависит количество ресурсов, которое требуется на предоставление какой-то услуги, а значит и доход заказчика. Чем лучше мы знаем эти вещи, тем дешевле предоставлять услугу и тем больше мы ценны как специалисты. И наши доходы растут. Но computer science намного обширнее, чем абстрактные вещи типа теории алгоритмов или архитектуры ПО. Это еще и знание и понимание работы конкретного железа, на котором наш софт выполняется. Что важнее - непонятно. Но только в синергии можно получить топовые результаты.
Согласно теории, проход по массиву и двунаправленному списку происходит за одинаковое алгоритмическое время. O(n). То есть время прохода линейно зависит от количества элементов в структуре. И без применения знаний о принципах работы железа, можно подумать, что они взаимозаменяемы. Просто в одном случае элементы лежат рядом, а в другом - связаны ссылками. А на практике получается, что не совсем линейно и совсем не взаимозаменяемы. Расскажу подробнее о последнем.
Дело в существовании кэша у процессора. Когда мы запрашиваем доступ к одной ячейке памяти, процессор верно предполагает, что нам скорее всего будут нужны и соседние ячейки тоже. Поэтому он копирует целый интервал в памяти, называемый кэш-строкой, в свой промежуточный буфер. А доступ к этому буферу происходит намного быстрее, чем к оперативной памяти. И процессору не нужно ходить за этими рядом лежащими данными в ОЗУ, он их просто берет из кэша.
Элементы же списка хранятся в разных участках памяти и связаны между собой ссылками. В общем виде нет никакой гарантии, что они будут лежать рядом. Если конечно вы не используете кастомный аллокатор. Поэтому за каждым элементом листа процессору приходится ходит в ОЗУ.
Вот и получается, что обработка элементов списка будет происходит медленнее, чем элементов массива.
Написал простенькую программку, которая проверит разницу во времени прохода.
Получилось, что для 100кк чисел в массиве и в листе, время отличается от 1.5 до 2 раз на разных машинах. Нихрена себе такая разница. И это без оптимизаций!
С ними разница вообще 6-8 раз. Это кстати еще один повод для того, чтобы понимать, как именно мы работаем на уровне железа и какие структуры данных хорошо ложатся на разные оптимизации.
Конечно, в реальных приложениях обработка - обычно более дорогая операция, чем просто инкремент и в процентном соотношении затраты на доступ к элементам будут другие. Но для того и пишутся такие тесты, чтобы максимально подсветить проблему.
Stay based. Stay cool.
#STL #algorithms #cppcore
{kind=link}
🔥31👍3❤2👎1
std::for_each
Все мы знаем эту знаменитую шаблонную функцию из стандартной библиотеки. Она позволяет применить унарную операцию для каждого элемента последовательности.
Чем она хороша? В подходящих условиях она дает больше семантики по сравнению с "конкурентами".
Например, есть range-based-for цикл. Он записывается примерно так:
В этом подходе к обработке набора данных нет ничего плохого. Но нам позволено слишком много свободы. Мы можем выйти из цикла, перейти к следующей итерации в середине текущей и так далее. И уже сама эта возможность заставляет читающего код больше напрягаться и искать сложную логику.
Но если такой логики нет и мы просто делаем определенную операцию над каждым элементом, то создается совершенно лишнее напряжение, которого можно было бы избежать. И этому побегу поможет std::for_each.
Функция имеет явную семантику: для каждого элемента последовательности выполняется вот эта функция. И все. Думать много не нужно. Нужно просто понять, как преобразуется или обрабатывается элемент и дело в шляпе.
Но не каждый знает, что эта функция возвращает не void, а тот же тип унарной операции, что мы передали в нее. Значит мы можем использовать stateful операции, то есть функциональные объекты, и сохранять результат вычислений в этом объекте не используя никакие глобальные переменные, ссылки и прочее. Стандарт гарантирует, что возвращаемое значение for_each содержит финальное состояния функтора после завершения операций над всеми элементами.
Эта особенность может пригодиться, когда помимо обработки элемента необходимо собрать по ним статистику. Допустим, я хочу убрать из массива строк все пробелы и сосчитать, сколько в среднем на каждую строку приходится пробелов. И тут как бы вроде скорее всего наверное вероятно лучше std::transform подходит(по семантике основной операции), но все портит сбор статистики. Можно засунуть в трансформ лямбду со ссылкой на внешний счетчик, но по смыслу это уже не будет чистая трансформация строк. Поэтому можно подобрать менее точечный по предназначению алгоритм, но он лучше подходит этой ситуации. Единственное, что лямбду нельзя будет использовать.
Пример:
Здесь мы используем функтор SpaceHandler, для которого перегружен оператор круглые скобки. За счет чего мы в этом операторе может сохранять вычисления в поля класса SpaceHandler. Чем мы и воспользовались для подсчета статистики.
Большое неудобство с этими лямбдами, но нам пока не позволено доставать из них поля класса, так что выживаем, как можем.
Кстати, с С++20 std::for_each стал constexpr, что позволяет удобнее обрабатывать наборы данных во время компиляции .
Use proper tools. Stay cool.
#cppcore #cpp20 #algorithms
Все мы знаем эту знаменитую шаблонную функцию из стандартной библиотеки. Она позволяет применить унарную операцию для каждого элемента последовательности.
Чем она хороша? В подходящих условиях она дает больше семантики по сравнению с "конкурентами".
Например, есть range-based-for цикл. Он записывается примерно так:
for(auto & traitor: traitors) {
// exquisitely torture the traitor
}
В этом подходе к обработке набора данных нет ничего плохого. Но нам позволено слишком много свободы. Мы можем выйти из цикла, перейти к следующей итерации в середине текущей и так далее. И уже сама эта возможность заставляет читающего код больше напрягаться и искать сложную логику.
Но если такой логики нет и мы просто делаем определенную операцию над каждым элементом, то создается совершенно лишнее напряжение, которого можно было бы избежать. И этому побегу поможет std::for_each.
Функция имеет явную семантику: для каждого элемента последовательности выполняется вот эта функция. И все. Думать много не нужно. Нужно просто понять, как преобразуется или обрабатывается элемент и дело в шляпе.
Но не каждый знает, что эта функция возвращает не void, а тот же тип унарной операции, что мы передали в нее. Значит мы можем использовать stateful операции, то есть функциональные объекты, и сохранять результат вычислений в этом объекте не используя никакие глобальные переменные, ссылки и прочее. Стандарт гарантирует, что возвращаемое значение for_each содержит финальное состояния функтора после завершения операций над всеми элементами.
Эта особенность может пригодиться, когда помимо обработки элемента необходимо собрать по ним статистику. Допустим, я хочу убрать из массива строк все пробелы и сосчитать, сколько в среднем на каждую строку приходится пробелов. И тут как бы вроде скорее всего наверное вероятно лучше std::transform подходит(по семантике основной операции), но все портит сбор статистики. Можно засунуть в трансформ лямбду со ссылкой на внешний счетчик, но по смыслу это уже не будет чистая трансформация строк. Поэтому можно подобрать менее точечный по предназначению алгоритм, но он лучше подходит этой ситуации. Единственное, что лямбду нельзя будет использовать.
Пример:
struct SpaceHandler {
void operator()(std::string& str) {
auto new_end_it = std::remove_if(str.begin(), str.end(), [](const auto & ch){ return ch == ' ';});
space_count += str.size() - std::distance(str.begin(), new_end_it);
str.erase(new_end_it, str.end());
}
int space_count {0};
};
int main() {
std::vector<std::string> container = {"Ole-ole-ole ole", "C++ is great!",
"Just a random string just to make third elem"};
int i = std::for_each(container.begin(), container.end(), SpaceHandler()).space_count;
std::for_each(container.begin(), container.end(), [](const auto& str) { std::cout << str << std::endl;});
std::cout << "Average number of spaces is " << static_cast<double>(i) / container.size() << std::endl;
}
//Output
Ole-ole-oleole
C++isgreat!
Justarandomstringjusttomakethirdelem
Average number of spaces is 3.66667
Здесь мы используем функтор SpaceHandler, для которого перегружен оператор круглые скобки. За счет чего мы в этом операторе может сохранять вычисления в поля класса SpaceHandler. Чем мы и воспользовались для подсчета статистики.
Большое неудобство с этими лямбдами, но нам пока не позволено доставать из них поля класса, так что выживаем, как можем.
Кстати, с С++20 std::for_each стал constexpr, что позволяет удобнее обрабатывать наборы данных во время компиляции .
Use proper tools. Stay cool.
#cppcore #cpp20 #algorithms
{kind=link}
👍34🔥7❤3😁2💩2
XOR Swap
Есть такая интересная техника для свопинга содержимого двух переменных без надобности во временной третьей! Стандартный подход выглядит примерно так:
Все мы с программистких пеленок уже выучили это. И примерно так и реализована функция std::swap из стандартной библиотеки. Однако вот вам задали на собесе вопрос: "вот у вас есть 2 числа, но я хочу, чтобы вы обменяли их значения без временной переменной?". Какие мысли? Подумайте пару секунд.
Как всегда, на помощь приходит магия математики и битовых операций. Можно использовать 3 подряд операции xor над этими числами и мы получим нужный результат.
Доказывать сие утверждения я, конечно, не буду. Однако можете почитать в английской вики, там все подробно выводится из свойств Исключающего ИЛИ.
Тут есть один интересный момент, что в случае подачи на вход функции одной и той же переменной, то произойдет эффект зануления. Первый же xor занулит x, а значит и y. Поэтому в самом начале стоит условие на проверку одинакового адреса.
При подаче на вход просто одинаковых значений, все работает и без условия.
Ну и работает это дело только с целочисленными параметрами.
Но предостерегаю вас - не используйте эту технику в современных программах! Результаты этих трех ксоров напрямую зависят друг от друга по цепочке. А значит параллелизма на уровне инструкций можно не ждать.
Современные компиляторы вполне могут и соптимизировать третью переменную и вы ее вовсе не увидите в ассемблере. Да и еще и вариант с доп переменной тупо быстрее работает. Всего 2 store'а и 2 load'а, которые еще и распараллелить можно, против 3 затратных ксоров. Да и даже довольно тяжеловесная XCHG работает быстрее, чем 3 xor'а.
Зачем я это все рассказываю тогда, если эта техника уже никому не уперлась? Для ретроспективы событий. Дело в том, что раньше люди писали программы без компиляторов, напрямую на ассемблере. Плюс в то время компьютеры имели такое маленькое количество памяти, что биться приходилось буквально за каждый байт. А используя операции xor, мы экономим 33% памяти на эту операцию. Довольно неплохо. В стародавние времена как только не извращались люди, чтобы выжимать все из железа. Эх, были времена...
Понимание тонкостей операции xor и ее возможных приложений делают ее довольно мощным инструментом в низкоуровневых вычислениях. А в некоторых задачах вы и вовсе никогда даже не подумаете, что они могут наиболее эффективным образом решаться с помощью xor.
Learn technics from the past. Stay cool.
#cppcore #fun #algorithms
Есть такая интересная техника для свопинга содержимого двух переменных без надобности во временной третьей! Стандартный подход выглядит примерно так:
template <class T>
void swap(T& lhs, T& rhs) {
T tmp = std::move(lhs);
lhs = std::move(rhs);
rhs = std::move(tmp);
}
Все мы с программистких пеленок уже выучили это. И примерно так и реализована функция std::swap из стандартной библиотеки. Однако вот вам задали на собесе вопрос: "вот у вас есть 2 числа, но я хочу, чтобы вы обменяли их значения без временной переменной?". Какие мысли? Подумайте пару секунд.
Как всегда, на помощь приходит магия математики и битовых операций. Можно использовать 3 подряд операции xor над этими числами и мы получим нужный результат.
template <class T, typename std::enable_if_t<std::is_integral_v<T>> = 0>
void swap(T& x, T& y) {
if (&x == &y)
return;
x = x ^ y;
y = x ^ y;
x = x ^ y;
}
Доказывать сие утверждения я, конечно, не буду. Однако можете почитать в английской вики, там все подробно выводится из свойств Исключающего ИЛИ.
Тут есть один интересный момент, что в случае подачи на вход функции одной и той же переменной, то произойдет эффект зануления. Первый же xor занулит x, а значит и y. Поэтому в самом начале стоит условие на проверку одинакового адреса.
При подаче на вход просто одинаковых значений, все работает и без условия.
Ну и работает это дело только с целочисленными параметрами.
Но предостерегаю вас - не используйте эту технику в современных программах! Результаты этих трех ксоров напрямую зависят друг от друга по цепочке. А значит параллелизма на уровне инструкций можно не ждать.
Современные компиляторы вполне могут и соптимизировать третью переменную и вы ее вовсе не увидите в ассемблере. Да и еще и вариант с доп переменной тупо быстрее работает. Всего 2 store'а и 2 load'а, которые еще и распараллелить можно, против 3 затратных ксоров. Да и даже довольно тяжеловесная XCHG работает быстрее, чем 3 xor'а.
Зачем я это все рассказываю тогда, если эта техника уже никому не уперлась? Для ретроспективы событий. Дело в том, что раньше люди писали программы без компиляторов, напрямую на ассемблере. Плюс в то время компьютеры имели такое маленькое количество памяти, что биться приходилось буквально за каждый байт. А используя операции xor, мы экономим 33% памяти на эту операцию. Довольно неплохо. В стародавние времена как только не извращались люди, чтобы выжимать все из железа. Эх, были времена...
Понимание тонкостей операции xor и ее возможных приложений делают ее довольно мощным инструментом в низкоуровневых вычислениях. А в некоторых задачах вы и вовсе никогда даже не подумаете, что они могут наиболее эффективным образом решаться с помощью xor.
Learn technics from the past. Stay cool.
#cppcore #fun #algorithms
{kind=link}
🔥36👍16❤10😍2😁1🙏1