
Ассемблер инициализации статических локальных переменных
#опытным
Пример из предыдущего поста - рабочая версия паттерна. Однако, нам, вообще говоря, можно всего этого не писать. Ведь начиная с С++11 нам гарантируют тред-сэйф инициализацию статических локальных переменных и можно просто писать:
Мы посмотрели, как вся защита может выглядеть на уровне С++ кода. Но в примере сверху никакой защиты на этом уровне нет. А это значит, что она лежит ниже, на уровне машинных инструкций. Которые мы можем с горем-пополам прочитать в виде ассемблера.
Сейчас будет очень страшно, но я попытался оставить самые важные куски и места и опустил неважное. Показываю ассемблер под x86-64, сгенерированный gcc.
Так как код оперирует объектом, а не указателем, то и в ассемблере это отражено. Но да не особо это важно. Сейчас все поймете. Для удобства обращения к коду, пометил строчки номерами.
Итак, мы входим в функцию. И тут же на первой строчке у нас появляется строжевая гвардия для переменной
На метке .L19 мы берем лок с помощью вызова __cxa_guard_acquire, которая используется для залочивания мьютексов. И снова проверяем переменную-гард на пустоту(напоминаем себе, что она в eax загружена), если до сих пор она нулевая, то прыгаем в .L20. Если уже не ноль, то есть переменная инициализирована, то проваливаемся в .L9, где кладем созданную переменную в регистр возврата значения на 9-й строчке и выходим из функции(10 и 11). Это была вторая проверка
На метке .L20 мы на 12-й строчке кладем наш неинициализированный синглтон в регистр для последующей обработки, а именно для конструирования объекта. На 13-й строчке кладем адрес гарда в регистр, чтобы чуть позже записать туда ненулевое значение aka синглтон инициализирован. Далее мы отпускаем лок с помощью __cxa_guard_release, делаем все необходимые завершающие действия и выходим из функции.
Повторю, что тут много всего пропущено для краткости и наглядности, но вы уже сейчас можете сравнить этот ассемблер с плюсовым кодом из вчерашнего поста и сразу же заметите практически однозначное соответствие. Именно так и выглядит DCLP на ассемблере.
Стоит еще раз обратить внимание на то, что __cxa_guard_acquire и __cxa_guard_release - это не барьеры памяти! Это захват мьютекса. Барьеры памяти напрямую здесь не нужны. Нам важно только защитить гард-переменную для синглтона, потому что проверяется только она.
Для пытливых читателей оставлю ссылочку на годболт с примером, чтобы желающие могли поиграться.
Dig deeper. Stay cool.
#concurrency #cppcore
#опытным
Пример из предыдущего поста - рабочая версия паттерна. Однако, нам, вообще говоря, можно всего этого не писать. Ведь начиная с С++11 нам гарантируют тред-сэйф инициализацию статических локальных переменных и можно просто писать:
Singleton& Singleton::getInstance() {
static Singleton instance;
return instance;
}
Мы посмотрели, как вся защита может выглядеть на уровне С++ кода. Но в примере сверху никакой защиты на этом уровне нет. А это значит, что она лежит ниже, на уровне машинных инструкций. Которые мы можем с горем-пополам прочитать в виде ассемблера.
Сейчас будет очень страшно, но я попытался оставить самые важные куски и места и опустил неважное. Показываю ассемблер под x86-64, сгенерированный gcc.
Singleton::getInstance():
1 movzbl guard variable for Singleton::getInstance()::instance(%rip), %eax
2 testb %al, %al
3 je .L19
4 movl $Singleton::getInstance()::instance, %eax
5 ret
.L19:
...
6 call __cxa_guard_acquire
7 testl %eax, %eax
8 jne .L20
.L9:
9 movl $Singleton::getInstance()::instance, %eax
10 popq %rbx
11 ret
.L20:
12 movl $Singleton::getInstance()::instance, %esi
{Constructor}
13 movl $guard variable for Singleton::getInstance()::instance, %edi
14 call __cxa_guard_release
{safe instance and return}
Так как код оперирует объектом, а не указателем, то и в ассемблере это отражено. Но да не особо это важно. Сейчас все поймете. Для удобства обращения к коду, пометил строчки номерами.
Итак, мы входим в функцию. И тут же на первой строчке у нас появляется строжевая гвардия для переменной
instance. Гвардия защищена барьером памяти и она показывает, инициализирована уже instance или нет. Так как мы без указателей, то вместо загрузки указателя и установки барьера памяти тут просто происходит загрузка гард-переменной для instance в регистр eax. Дальше на второй строчке мы проверяем, была ли инициализирована instance. al - это младший байт регистра eax. Соотвественно, если al - ноль, то инструкция testb выставляет zero-flag и в условном прыжке на 3-ей строчке мы прыгаем по метке. Если al - не ноль, то наш синглтон уже инициализирован и мы можем вернуть его из функции. Получается, что это наша первая проверка на ноль.На метке .L19 мы берем лок с помощью вызова __cxa_guard_acquire, которая используется для залочивания мьютексов. И снова проверяем переменную-гард на пустоту(напоминаем себе, что она в eax загружена), если до сих пор она нулевая, то прыгаем в .L20. Если уже не ноль, то есть переменная инициализирована, то проваливаемся в .L9, где кладем созданную переменную в регистр возврата значения на 9-й строчке и выходим из функции(10 и 11). Это была вторая проверка
На метке .L20 мы на 12-й строчке кладем наш неинициализированный синглтон в регистр для последующей обработки, а именно для конструирования объекта. На 13-й строчке кладем адрес гарда в регистр, чтобы чуть позже записать туда ненулевое значение aka синглтон инициализирован. Далее мы отпускаем лок с помощью __cxa_guard_release, делаем все необходимые завершающие действия и выходим из функции.
Повторю, что тут много всего пропущено для краткости и наглядности, но вы уже сейчас можете сравнить этот ассемблер с плюсовым кодом из вчерашнего поста и сразу же заметите практически однозначное соответствие. Именно так и выглядит DCLP на ассемблере.
Стоит еще раз обратить внимание на то, что __cxa_guard_acquire и __cxa_guard_release - это не барьеры памяти! Это захват мьютекса. Барьеры памяти напрямую здесь не нужны. Нам важно только защитить гард-переменную для синглтона, потому что проверяется только она.
Для пытливых читателей оставлю ссылочку на годболт с примером, чтобы желающие могли поиграться.
Dig deeper. Stay cool.
#concurrency #cppcore
{kind=link}
XOR Swap
Есть такая интересная техника для свопинга содержимого двух переменных без надобности во временной третьей! Стандартный подход выглядит примерно так:
Все мы с программистких пеленок уже выучили это. И примерно так и реализована функция std::swap из стандартной библиотеки. Однако вот вам задали на собесе вопрос: "вот у вас есть 2 числа, но я хочу, чтобы вы обменяли их значения без временной переменной?". Какие мысли? Подумайте пару секунд.
Как всегда, на помощь приходит магия математики и битовых операций. Можно использовать 3 подряд операции xor над этими числами и мы получим нужный результат.
Доказывать сие утверждения я, конечно, не буду. Однако можете почитать в английской вики, там все подробно выводится из свойств Исключающего ИЛИ.
Тут есть один интересный момент, что в случае подачи на вход функции одной и той же переменной, то произойдет эффект зануления. Первый же xor занулит x, а значит и y. Поэтому в самом начале стоит условие на проверку одинакового адреса.
При подаче на вход просто одинаковых значений, все работает и без условия.
Ну и работает это дело только с целочисленными параметрами.
Но предостерегаю вас - не используйте эту технику в современных программах! Результаты этих трех ксоров напрямую зависят друг от друга по цепочке. А значит параллелизма на уровне инструкций можно не ждать.
Современные компиляторы вполне могут и соптимизировать третью переменную и вы ее вовсе не увидите в ассемблере. Да и еще и вариант с доп переменной тупо быстрее работает. Всего 2 store'а и 2 load'а, которые еще и распараллелить можно, против 3 затратных ксоров. Да и даже довольно тяжеловесная XCHG работает быстрее, чем 3 xor'а.
Зачем я это все рассказываю тогда, если эта техника уже никому не уперлась? Для ретроспективы событий. Дело в том, что раньше люди писали программы без компиляторов, напрямую на ассемблере. Плюс в то время компьютеры имели такое маленькое количество памяти, что биться приходилось буквально за каждый байт. А используя операции xor, мы экономим 33% памяти на эту операцию. Довольно неплохо. В стародавние времена как только не извращались люди, чтобы выжимать все из железа. Эх, были времена...
Понимание тонкостей операции xor и ее возможных приложений делают ее довольно мощным инструментом в низкоуровневых вычислениях. А в некоторых задачах вы и вовсе никогда даже не подумаете, что они могут наиболее эффективным образом решаться с помощью xor.
Learn technics from the past. Stay cool.
#cppcore #fun #algorithms
Есть такая интересная техника для свопинга содержимого двух переменных без надобности во временной третьей! Стандартный подход выглядит примерно так:
template <class T>
void swap(T& lhs, T& rhs) {
T tmp = std::move(lhs);
lhs = std::move(rhs);
rhs = std::move(tmp);
}
Все мы с программистких пеленок уже выучили это. И примерно так и реализована функция std::swap из стандартной библиотеки. Однако вот вам задали на собесе вопрос: "вот у вас есть 2 числа, но я хочу, чтобы вы обменяли их значения без временной переменной?". Какие мысли? Подумайте пару секунд.
Как всегда, на помощь приходит магия математики и битовых операций. Можно использовать 3 подряд операции xor над этими числами и мы получим нужный результат.
template <class T, typename std::enable_if_t<std::is_integral_v<T>> = 0>
void swap(T& x, T& y) {
if (&x == &y)
return;
x = x ^ y;
y = x ^ y;
x = x ^ y;
}
Доказывать сие утверждения я, конечно, не буду. Однако можете почитать в английской вики, там все подробно выводится из свойств Исключающего ИЛИ.
Тут есть один интересный момент, что в случае подачи на вход функции одной и той же переменной, то произойдет эффект зануления. Первый же xor занулит x, а значит и y. Поэтому в самом начале стоит условие на проверку одинакового адреса.
При подаче на вход просто одинаковых значений, все работает и без условия.
Ну и работает это дело только с целочисленными параметрами.
Но предостерегаю вас - не используйте эту технику в современных программах! Результаты этих трех ксоров напрямую зависят друг от друга по цепочке. А значит параллелизма на уровне инструкций можно не ждать.
Современные компиляторы вполне могут и соптимизировать третью переменную и вы ее вовсе не увидите в ассемблере. Да и еще и вариант с доп переменной тупо быстрее работает. Всего 2 store'а и 2 load'а, которые еще и распараллелить можно, против 3 затратных ксоров. Да и даже довольно тяжеловесная XCHG работает быстрее, чем 3 xor'а.
Зачем я это все рассказываю тогда, если эта техника уже никому не уперлась? Для ретроспективы событий. Дело в том, что раньше люди писали программы без компиляторов, напрямую на ассемблере. Плюс в то время компьютеры имели такое маленькое количество памяти, что биться приходилось буквально за каждый байт. А используя операции xor, мы экономим 33% памяти на эту операцию. Довольно неплохо. В стародавние времена как только не извращались люди, чтобы выжимать все из железа. Эх, были времена...
Понимание тонкостей операции xor и ее возможных приложений делают ее довольно мощным инструментом в низкоуровневых вычислениях. А в некоторых задачах вы и вовсе никогда даже не подумаете, что они могут наиболее эффективным образом решаться с помощью xor.
Learn technics from the past. Stay cool.
#cppcore #fun #algorithms
{kind=link}
Порядок вызовов конструкторов и деструкторов дочерних классов
#новичкам
Сегодня такой, довольно попсовый пост. Но, как говорится, это база и это нужно знать.
Вот есть у вас какая-то иерархия классов.
Что мы увидим в консоли, если запустим этот код? Вот это:
Мы имеем 2 невиртуальные ветки наследования в класса MostDerived. В самих классах могут быть виртуальные функции, это роли не играет. В этом случае правила конструирования объекта такое: переходим в самую левую ветку и вызываем поочереди констукторы базовых классов сверху вниз. Как только дошли до MostDerived, переходим вправо в следующую ветку и также вызываем конструкторы сверху вниз. И только после этого конструируем MostDerived.
В общем случае, для n веток, можно представить, что наш наследник - корень дерева с n ветками. Так вот для такого графа конструкторы вызываются, как при обходе в глубину слева-направо.
А вот деструкторами все легко, если вы запомнили порядок вызовов конструкторов. Деструкторы выполняются в обратном порядке вызовов конструкторов соответствующих классов. Вы можете заметить, что вывод консоли из примера полностью симметричен относительно момента, когда объект уже создан.
Казалось бы, тривиальное знание для программиста. Но очень важно осознавать эти вещи для того, чтобы понять более сложные концепции или отвечать на более сложные вопросы. Например: "Зачем нужен виртуальный деструктор?", "В какой момент инициализируется указатель на виртуальную таблицу?", "Какой конкретно метод вызовется, если позвать виртуальный метод из констуруктора базового класса?". Без четкого понимания базы создания объектов, на эти вопросы конечно можно заучить ответы, но понимания никакого не будет. А программирование - это только про понимание, как и любая другая техническая дисциплина.
Поэтому
Understand essence of basic concepts. Stay cool.
#OOP #cppcore
#новичкам
Сегодня такой, довольно попсовый пост. Но, как говорится, это база и это нужно знать.
Вот есть у вас какая-то иерархия классов.
struct Base1 {
Base1() {std::cout << "Base1" << std::endl;}
~Base1() {std::cout << "~Base1" << std::endl;}
};
struct Derived1 : Base1 {
Derived1() {std::cout << "Derived1" << std::endl;}
~Derived1() {std::cout << "~Derived1" << std::endl;}
};
struct Base2 {
Base2() {std::cout << "Base2" << std::endl;}
~Base2() {std::cout << "~Base2" << std::endl;}
};
struct Derived2 : Base2 {
Derived2() {std::cout << "Derived2" << std::endl;}
~Derived2() {std::cout << "~Derived2" << std::endl;}
};
struct MostDerived: Derived2, Derived1 {
MostDerived() {std::cout << "MostDerived" << std::endl;}
~MostDerived() {std::cout << "~MostDerived" << std::endl;}
};
MostDerived{};
Что мы увидим в консоли, если запустим этот код? Вот это:
Base2
Derived2
Base1
Derived1
MostDerived
~MostDerived
~Derived1
~Base1
~Derived2
~Base2
Мы имеем 2 невиртуальные ветки наследования в класса MostDerived. В самих классах могут быть виртуальные функции, это роли не играет. В этом случае правила конструирования объекта такое: переходим в самую левую ветку и вызываем поочереди констукторы базовых классов сверху вниз. Как только дошли до MostDerived, переходим вправо в следующую ветку и также вызываем конструкторы сверху вниз. И только после этого конструируем MostDerived.
В общем случае, для n веток, можно представить, что наш наследник - корень дерева с n ветками. Так вот для такого графа конструкторы вызываются, как при обходе в глубину слева-направо.
А вот деструкторами все легко, если вы запомнили порядок вызовов конструкторов. Деструкторы выполняются в обратном порядке вызовов конструкторов соответствующих классов. Вы можете заметить, что вывод консоли из примера полностью симметричен относительно момента, когда объект уже создан.
Казалось бы, тривиальное знание для программиста. Но очень важно осознавать эти вещи для того, чтобы понять более сложные концепции или отвечать на более сложные вопросы. Например: "Зачем нужен виртуальный деструктор?", "В какой момент инициализируется указатель на виртуальную таблицу?", "Какой конкретно метод вызовется, если позвать виртуальный метод из констуруктора базового класса?". Без четкого понимания базы создания объектов, на эти вопросы конечно можно заучить ответы, но понимания никакого не будет. А программирование - это только про понимание, как и любая другая техническая дисциплина.
Поэтому
Understand essence of basic concepts. Stay cool.
#OOP #cppcore
{kind=link}
Виртуальный деструктор
#новичкам
Возможно САМЫЙ популярный вопрос на собеседованиях на джунов и мидлов. Оно и справедливо в принципе: очень простой и понятный вопрос, но ответ на него требует хорошего уровня понимания ООП в принципе и как оно конкретно работает в плюсах. Динамический полиморфизм, наследование, порядок вызовов конструкторов и деструкторов - да, это база. Но именно ее и нужно проверить у начинающих и продолжающих разработчиков.
Обычно они заходят немного издалека и просят вангануть, что выведется в консоль для примерно такого кода:
Вроде ничего сложного, но вот надо все штуки вспомнить, как там объекты создаются, в каком порядке что вызывается. Для начинающих тут часто затупки начинаются.
В коде вроде все хорошо написано и невнимательный кандидат может выдать вот это:
Вот тут-то его и подловили! На самом деле никакого деструктора наследника вызвано не будет и соответственно ресурсы не освободятся. Интервьюер дает наводку посмотреть на деструктор базового класса. И кандидат с красным лицом кричит: "Деструктор - невиртуальный! По указателю на базовый класс вызовется сразу деструктор базового класса, а деструктор дочернего не вызовется. Будет утечка памяти". Его так на курсах научили говорить. И дальше он выдает правильный вывод программы.
И тут интервьюер говорит: "А что будет, если наследник не будет содержать никаких полей? Какие проблемы будут у этого кода?".
И молодой разработчик в ступоре: он же знает, что невиртуальный деструктор приводит к утечкам. Но тут вроде как и утекать нечему. И говорит, что вроде как и проблем не будет.
Естественно, это неправда.
Если с виду ничего плохого не может произойти и даже при запуске программы ничего плохого не происходит - это не значит, что в программе нет проблем. Стандарт говорит:
Отсутствие виртуального деструктора при удалении через базовый класс приводит к неопределенному поведению. И точка. Можете даже больше не упоминать утечки. Потому что может память утечь, а может и Пентагон задудосится от такой программы. Никто не знает.
Для корректного поведения полиморфных объектов и вызова деструктора дочернего класса вам обязательно нужен виртуальный деструктор базового класса.
Часто встречал эту проблему у младших разработчиков, да и сам я спотыкался на этом. Но теперь наши подписчики вооружены и опасны!
Stay armed. Stay cool.
#cppcore #interview
#новичкам
Возможно САМЫЙ популярный вопрос на собеседованиях на джунов и мидлов. Оно и справедливо в принципе: очень простой и понятный вопрос, но ответ на него требует хорошего уровня понимания ООП в принципе и как оно конкретно работает в плюсах. Динамический полиморфизм, наследование, порядок вызовов конструкторов и деструкторов - да, это база. Но именно ее и нужно проверить у начинающих и продолжающих разработчиков.
Обычно они заходят немного издалека и просят вангануть, что выведется в консоль для примерно такого кода:
struct Resource {
Resource() { std::cout << "Resourse has been acquired\n";}
~Resource() { std::cout << "Resource has been released\n";}
};
struct Base {
Base() { std::cout << "Base Constructor Called\n";}
~Base() { std::cout << "Base Destructor called\n";}
};
struct Derived1: Base {
Derived1() {
ptr = std::make_unique<Resource>();
std::cout << "Derived constructor called\n";
}
~Derived1() {std::cout << "Derived destructor called\n";}
private:
std::unique_ptr<Resource> ptr;
};
int main() {
Base *b = new Derived1();
delete b;
}
Вроде ничего сложного, но вот надо все штуки вспомнить, как там объекты создаются, в каком порядке что вызывается. Для начинающих тут часто затупки начинаются.
В коде вроде все хорошо написано и невнимательный кандидат может выдать вот это:
Base Constructor Called
Resourse has been acquired
Derived constructor called
Derived destructor called
Resource has been released
Base Destructor called
Вот тут-то его и подловили! На самом деле никакого деструктора наследника вызвано не будет и соответственно ресурсы не освободятся. Интервьюер дает наводку посмотреть на деструктор базового класса. И кандидат с красным лицом кричит: "Деструктор - невиртуальный! По указателю на базовый класс вызовется сразу деструктор базового класса, а деструктор дочернего не вызовется. Будет утечка памяти". Его так на курсах научили говорить. И дальше он выдает правильный вывод программы.
И тут интервьюер говорит: "А что будет, если наследник не будет содержать никаких полей? Какие проблемы будут у этого кода?".
И молодой разработчик в ступоре: он же знает, что невиртуальный деструктор приводит к утечкам. Но тут вроде как и утекать нечему. И говорит, что вроде как и проблем не будет.
Естественно, это неправда.
Если с виду ничего плохого не может произойти и даже при запуске программы ничего плохого не происходит - это не значит, что в программе нет проблем. Стандарт говорит:
if the static type of the object to be deleted
is different from its dynamic type, the static type
shall be a base class of the dynamic type of
the object to be deleted and the static type
shall have a virtual destructor or
the behavior is undefined.
Отсутствие виртуального деструктора при удалении через базовый класс приводит к неопределенному поведению. И точка. Можете даже больше не упоминать утечки. Потому что может память утечь, а может и Пентагон задудосится от такой программы. Никто не знает.
Для корректного поведения полиморфных объектов и вызова деструктора дочернего класса вам обязательно нужен виртуальный деструктор базового класса.
Часто встречал эту проблему у младших разработчиков, да и сам я спотыкался на этом. Но теперь наши подписчики вооружены и опасны!
Stay armed. Stay cool.
#cppcore #interview
{kind=link}
Default member initializer
#новичкам
Представьте себе большой класс, определенный целиком в одном файле. Этак строк на 300-400. Обычно принято в таком порядке описывать класс: конструкторы, деструктор, методы и только потом поля. Вариации могут быть разными, но из моей практики одно остается неизменным: объявления конструктора и полей находятся в разных концах тела класса. И вот бывают случаи, когда при создании объекта какие-то поля получают свое значение не из внешних параметров, а какие-то заранее заданные. Дефолтовые.
И вообще было бы очень приятненько видеть значения по умолчанию полей каждый раз, когда мы встречаем их объявления в теле класса. Если бегло читать код, то часто приходится смотреть на список полей. И было бы просто удобно не возвращаться к конструкторам каждый раз, чтобы вспомнить эти значения, а иметь их сразу рядом с объявлением полей.
Такие удобства появились у нас в C++11 - default member initializer. Это именно то, что и хотелось иметь в описанных выше ситуациях. Пример
Здесь мы создает простой шаблонный класс стека с одной особенностью: в каждый момент времени вы можете из этого стека получить самое минимальное значение из тех элементов, которые содержатся в этом стеке. Кстати, вам задачка на подумать, как такое можно сделать.
Пример здесь сильно укороченный. Если реализовывать все по чесноку, то реализация такого шаблонного класса займет приличное количество места. Вариантов методов и конструкторов может быть миллион. И я не очень хочу в них возвращаться, чтобы узнать, какое изначальное состояние имеет поле min_elem. А здесь мы сразу видим: у пустого стека примем значение минимального элемента, как максимально возможное значение этого типа. Тогда при добавлении в стек первого элемента для обновления минимума мы можем пользоваться тем же условием, что и для добавления остальных элементов
Limit<T> - шаблонный класс, который хранит максимальное и минимальное значение для заданного шаблонного типа. Это может быть реализовано как угодно: через явные специализации, через if constexpr и так далее. Шаблонная магия в общем. Кто хочет, опять же, может в комментах попрактиковаться в реализации этого класса.
Кто не знал - пользуйтесь, вещь полезная.
Stay useful. Stay cool.
#cpp11 #cppcore
#новичкам
Представьте себе большой класс, определенный целиком в одном файле. Этак строк на 300-400. Обычно принято в таком порядке описывать класс: конструкторы, деструктор, методы и только потом поля. Вариации могут быть разными, но из моей практики одно остается неизменным: объявления конструктора и полей находятся в разных концах тела класса. И вот бывают случаи, когда при создании объекта какие-то поля получают свое значение не из внешних параметров, а какие-то заранее заданные. Дефолтовые.
И вообще было бы очень приятненько видеть значения по умолчанию полей каждый раз, когда мы встречаем их объявления в теле класса. Если бегло читать код, то часто приходится смотреть на список полей. И было бы просто удобно не возвращаться к конструкторам каждый раз, чтобы вспомнить эти значения, а иметь их сразу рядом с объявлением полей.
Такие удобства появились у нас в C++11 - default member initializer. Это именно то, что и хотелось иметь в описанных выше ситуациях. Пример
template<typename T>
struct Stack {
// rule of 5
void push(const T& elem) {...}
void push(T&& elem) {...}
T& front() {...}
T& front() const {...}
void pop() {}
T GetMinElem() {...}
private:
std::deque<T> container;
T min_elem{Limit<T>::max_value};
}
Здесь мы создает простой шаблонный класс стека с одной особенностью: в каждый момент времени вы можете из этого стека получить самое минимальное значение из тех элементов, которые содержатся в этом стеке. Кстати, вам задачка на подумать, как такое можно сделать.
Пример здесь сильно укороченный. Если реализовывать все по чесноку, то реализация такого шаблонного класса займет приличное количество места. Вариантов методов и конструкторов может быть миллион. И я не очень хочу в них возвращаться, чтобы узнать, какое изначальное состояние имеет поле min_elem. А здесь мы сразу видим: у пустого стека примем значение минимального элемента, как максимально возможное значение этого типа. Тогда при добавлении в стек первого элемента для обновления минимума мы можем пользоваться тем же условием, что и для добавления остальных элементов
if (new_elem <= min_elem)
min_elem = new_elem;
Limit<T> - шаблонный класс, который хранит максимальное и минимальное значение для заданного шаблонного типа. Это может быть реализовано как угодно: через явные специализации, через if constexpr и так далее. Шаблонная магия в общем. Кто хочет, опять же, может в комментах попрактиковаться в реализации этого класса.
Кто не знал - пользуйтесь, вещь полезная.
Stay useful. Stay cool.
#cpp11 #cppcore
{kind=link}
Сочетание member initialization list и default member initializer
#опытным
Вот здесь мы поговорили о том, почему важно соблюдать порядок следования полей класса в списке инициализации конструктора. Дело в том, что вне зависимости от того, как написан этот список, поля будут инициализироваться в порядке появления их объявления.
Также в С++11 у нас появилась фича под названием default member initializer. Это та самая штуковина, которая позволяет вам инициализировать нестатические поля класса не в конструкторе, а прям inplace. Типа того:
Фича полезная, многие ей часто пользуются. Но вот возникает вопрос: как список инициализации конструктора взаимодействует с default member initializer? Если я инициализирую поля вне конструктора и компилятор видит эти значения явным образом, то возможно эти поля и получают значение первыми? Сейчас все узнаем.
Посмотрим на такой пример:
Есть простенький класс Char, который выводит на консоль момент создания объекта. И тестовый класс, на котором мы и проводим эксперимент. И в этом эксперименте мы и проверим, в каком порядке свои значения получают поля
На самом деле здесь правило ровно такое же. Нестатические поля класса инициализируются в порядке их появления в описании класса. Поэтому вывод будет таким:
С этим разобрались.
И тут назревает вопрос: а что будет, если я в начале проициализирую поле inplace, а потом еще раз в constructor initializer list? Какая из инициализаций победит другую? Или быть может они произойдут обе в какой-то очередности?
Выглядеть это может так:
Опять в подопытные мы взяли поля
В такой ситуации default member initializer не играет никакой роли, блаженно складывает лапки и отдает бразды правления списку инициализации. Вывод будет тем же, что и в прошлом примере:
Но это только список инициализации так работает. Если для инициализации поля вы используете обычный конструктор, то оно первый раз проинициализируется с помощью default member initializer(которая обязательно происходит до входа в тело конструктора), а второй раз - в теле конструктора.
Пишите в комменты, если есть еще какие-то интересные кейсы взаимодействия этих сущностей. В будущем, разберем их на канале.
Mix things properly. Stay cool.
#cpp11 #cppcore
#опытным
Вот здесь мы поговорили о том, почему важно соблюдать порядок следования полей класса в списке инициализации конструктора. Дело в том, что вне зависимости от того, как написан этот список, поля будут инициализироваться в порядке появления их объявления.
Также в С++11 у нас появилась фича под названием default member initializer. Это та самая штуковина, которая позволяет вам инициализировать нестатические поля класса не в конструкторе, а прям inplace. Типа того:
struct Class {
int field = 5;
};
Фича полезная, многие ей часто пользуются. Но вот возникает вопрос: как список инициализации конструктора взаимодействует с default member initializer? Если я инициализирую поля вне конструктора и компилятор видит эти значения явным образом, то возможно эти поля и получают значение первыми? Сейчас все узнаем.
Посмотрим на такой пример:
struct Char {
Char(char c) : field{c} {std::cout << "Char " << field << std::endl;}
Char() = default;
char field;
};
struct TestClass {
TestClass() : a{'1'},
c{'3'},
e{'5'} {}
Char a;
Char b = '2';
Char c;
Char d = '4';
Char e;
};
Есть простенький класс Char, который выводит на консоль момент создания объекта. И тестовый класс, на котором мы и проводим эксперимент. И в этом эксперименте мы и проверим, в каком порядке свои значения получают поля
b и d, относительно a, c, e. На самом деле здесь правило ровно такое же. Нестатические поля класса инициализируются в порядке их появления в описании класса. Поэтому вывод будет таким:
Char 1
Char 2
Char 3
Char 4
Char 5
С этим разобрались.
И тут назревает вопрос: а что будет, если я в начале проициализирую поле inplace, а потом еще раз в constructor initializer list? Какая из инициализаций победит другую? Или быть может они произойдут обе в какой-то очередности?
Выглядеть это может так:
struct Char {
Char(char c) : field{c} {std::cout << "Char " << field << std::endl;}
Char() = default;
char field;
};
struct TestClass {
TestClass() : a{'1'},
b{'2'},
c{'3'},
d{'4'},
e{'5'} {}
Char a;
Char b = 'b';
Char c;
Char d = 'd';
Char e;
};
Опять в подопытные мы взяли поля
b и d и задали им значения с помощью default member initializer. А вдогонку еще и в списке инициализации присвоили им значение. В такой ситуации default member initializer не играет никакой роли, блаженно складывает лапки и отдает бразды правления списку инициализации. Вывод будет тем же, что и в прошлом примере:
Char 1
Char 2
Char 3
Char 4
Char 5
Но это только список инициализации так работает. Если для инициализации поля вы используете обычный конструктор, то оно первый раз проинициализируется с помощью default member initializer(которая обязательно происходит до входа в тело конструктора), а второй раз - в теле конструктора.
struct TestClass {
TestClass() : a{'1'},
c{'3'},
d{'4'},
e{'5'} {b = '2';}
Char a;
Char b = 'b';
Char c;
Char d = 'd';
Char e;
};
// Output
Char 1
Char b
Char 3
Char 4
Char 5
Char 2
Пишите в комменты, если есть еще какие-то интересные кейсы взаимодействия этих сущностей. В будущем, разберем их на канале.
Mix things properly. Stay cool.
#cpp11 #cppcore
Member initialization. Best practices
#новичкам
Пост по запросу подписчика. Вот его вопрос.
И реально ведь непонятно, что делать. Столько разных вариантов и возможностей можно придумать для инициализации полей класса, что голова ходит кругом. Какой метод самый оптимальный? Сейчас и будем разбираться.
Здесь я буду приводить какое-то общие и распространенные принципы. К каждому можно придраться и сказать "а у нас в проекте по-другому!". Исключения и другие подходы есть везде. Если хотите высказать свои варианты - комменты открыты.
Начну с того, что нужно предпочитать инициализировать поля либо с помощью списка инициализации конструктора, либо с помощью default member initializer. Дело в том, что все поля на самом деле инициализируются до входа в конструктор! Если списком инициализации или default member initializer'ом не установлено, как поле должно инициализироваться, то в конструктор оно попадет инициализированным по умолчанию. Именно поэтому, например, не можете в конструкторе инициализировать объект класса, у которого нет конструктора по умолчанию. Будет ошибка компиляции и у вас потребуют дефолтный конструктор. Запомните: конструктор нужен для нетривиальных вещей. С простой иницализацией справятся ctor initialization list и инициализатор по умолчанию.
Далее. Остается 2 способа, как инициализировать. Какой из них выбрать и в какой пропорции смешивать?
CppCoreGuidelies говорят нам: "Prefer default member initializers to member initializers in constructors for constant initializers".
То есть, если инициализатор константный, то используйте default member initializer.
Причина: inplace инициализатор делает явным то, что именно эти дефолтовые значения будут использоваться во всех конструкторах. Пример:
Как в этом случае читатель кода поймет, была ли инициализация j специально пропущена(что скорее всего не очень гуд) или было ли для
Более адекватный вариант:
Красота. Все в одном месте, все четко и понятно. Тут используется одна фишка: у вас есть несколько конструкторов, которые могут выставлять значения полям, а могут и не выставлять. Вы в одном месте определяете дефолтные значения и в списках инициализации конструкторов переопределяете инициализирующее значение для нужного поля, так как список подавляет инициализатор по умолчанию.
Также это более читаемый вариант, так как все дефолтные значения находятся в одном месте и не нужно бегать глазами по коду в их поисках.
Используйте default member initializer и будет вам счастье!
Stay happy. Stay cool.
#cpp11 #cppcore #goodpractice
#новичкам
Пост по запросу подписчика. Вот его вопрос.
И реально ведь непонятно, что делать. Столько разных вариантов и возможностей можно придумать для инициализации полей класса, что голова ходит кругом. Какой метод самый оптимальный? Сейчас и будем разбираться.
Здесь я буду приводить какое-то общие и распространенные принципы. К каждому можно придраться и сказать "а у нас в проекте по-другому!". Исключения и другие подходы есть везде. Если хотите высказать свои варианты - комменты открыты.
Начну с того, что нужно предпочитать инициализировать поля либо с помощью списка инициализации конструктора, либо с помощью default member initializer. Дело в том, что все поля на самом деле инициализируются до входа в конструктор! Если списком инициализации или default member initializer'ом не установлено, как поле должно инициализироваться, то в конструктор оно попадет инициализированным по умолчанию. Именно поэтому, например, не можете в конструкторе инициализировать объект класса, у которого нет конструктора по умолчанию. Будет ошибка компиляции и у вас потребуют дефолтный конструктор. Запомните: конструктор нужен для нетривиальных вещей. С простой иницализацией справятся ctor initialization list и инициализатор по умолчанию.
Далее. Остается 2 способа, как инициализировать. Какой из них выбрать и в какой пропорции смешивать?
CppCoreGuidelies говорят нам: "Prefer default member initializers to member initializers in constructors for constant initializers".
То есть, если инициализатор константный, то используйте default member initializer.
Причина: inplace инициализатор делает явным то, что именно эти дефолтовые значения будут использоваться во всех конструкторах. Пример:
class X { // BAD
int i;
string s;
int j;
public:
X() :i{666}, s{"qqq"} { } // j is uninitialized
X(int ii) :i{ii} {} // s is "" and j is uninitialized
// ...
};Как в этом случае читатель кода поймет, была ли инициализация j специально пропущена(что скорее всего не очень гуд) или было ли для
s намеренным выставление его значения в "qqq" в первом случае и в пустую строку во втором случае(почти стопроцентный баг)? Все эти ошибки могут появиться при добавлении новых полей в класс. По классике: добавили новое поле, использовали его в методах, но вот в одном месте упустили инициализацию. Кейс настолько жизненный, что мое почтение.Более адекватный вариант:
class X2 {
int i {666};
string s {"qqq"};
int j {0};
public:
X2() = default; // all members are initialized to their defaults
X2(int ii) :i{ii} {} // s and j initialized to their defaults
// ...
};Красота. Все в одном месте, все четко и понятно. Тут используется одна фишка: у вас есть несколько конструкторов, которые могут выставлять значения полям, а могут и не выставлять. Вы в одном месте определяете дефолтные значения и в списках инициализации конструкторов переопределяете инициализирующее значение для нужного поля, так как список подавляет инициализатор по умолчанию.
Также это более читаемый вариант, так как все дефолтные значения находятся в одном месте и не нужно бегать глазами по коду в их поисках.
Используйте default member initializer и будет вам счастье!
Stay happy. Stay cool.
#cpp11 #cppcore #goodpractice
{kind=link}
Short circuit для кастомных операторов
#опытным
Есть одно важное уточнение, которое не было упомянуто в посте про short-circuit операторы, но несколько комментаторов на это указывали. Прочитайте, кстати, пост, если впервые видите словосочетание short circuit.
В плюсах короткосхемностью обладают операторы && и ||. Из коробки их операндами могут быть переменные логического, целочисленного и указательного типа. Однако они все так или иначе приводятся к типу булеан. Поэтому в принципе корректно говорить, что логические операторы работают только с логическими типами. Что в целом довольно логичная логика.
Однако есть в этом Эдеме есть и змий искуситель, который портит всю малину. Эти операторы можно перегружать для кастомных типов. И тогда они теряют свои короткосхемные свойства.
Взгляните на следующий код:
Здесь мы создаем самую простую структурку и перегружаем для нее оператор логического И. Дальше, чтобы проверить ленивость вычисления оператора, пишем простую функцию, которая при исполнении изменяет статическую переменную. Так мы сможем наверняка убедиться, выполнилась ли функция или нет: если выполнилась, то переменная check будет выставлена в единицу, если нет, то останется нулем.
И вывод будет реально "1". Что выглядит довольно печально.
Ну и кстати, такое поведение довольно легко объяснить. Когда мы перегружаем операторы, то мы создаем новые функции. И я хочу акцентировать на этом внимание: это именно пользовательские функции, как бы они там не назывались. А аргументы пользовательских функций должны быть вычислены ДО захода в функцию. Поэтому любые операнды должны быть полностью вычислены до вычисления значения всего выражения. Это и приводит к отсутствию свойства short circuit.
Хотя в том виде, в котором оператор перегружен в коде выше, внутри него используется short circuit операция и на самом деле второй операнд не будет учитываться, если у вызываемого объекта поле класса равно нулю. Но за счет того, что мы обязаны вычислить второй операнд, то просто технически не выполняются требования короткой схемы вычислений.
Встроеные же операторы реализованы на более низком уровне и не являются в прямом смысле функциями. И в эту реализацию изначально заложен короткосхемный функционал.
Однако есть способ разрешить ленивое вычисление логического И или ИЛИ для кастомных типов. Но об этом в следующий раз.
Don't loose your properties. Stay cool
#cppcore
#опытным
Есть одно важное уточнение, которое не было упомянуто в посте про short-circuit операторы, но несколько комментаторов на это указывали. Прочитайте, кстати, пост, если впервые видите словосочетание short circuit.
В плюсах короткосхемностью обладают операторы && и ||. Из коробки их операндами могут быть переменные логического, целочисленного и указательного типа. Однако они все так или иначе приводятся к типу булеан. Поэтому в принципе корректно говорить, что логические операторы работают только с логическими типами. Что в целом довольно логичная логика.
Однако есть в этом Эдеме есть и змий искуситель, который портит всю малину. Эти операторы можно перегружать для кастомных типов. И тогда они теряют свои короткосхемные свойства.
Взгляните на следующий код:
struct CustomStruct
{
int number = 0;
bool operator&&(const CustomStruct& other)
{
return number && other.number;
}
};
static int check = 0;
CustomStruct func()
{
check = 1;
return CustomStruct{};
}
int main() {
CustomStruct a{};
a && func();
std::cout << check << std::endl;
}
Здесь мы создаем самую простую структурку и перегружаем для нее оператор логического И. Дальше, чтобы проверить ленивость вычисления оператора, пишем простую функцию, которая при исполнении изменяет статическую переменную. Так мы сможем наверняка убедиться, выполнилась ли функция или нет: если выполнилась, то переменная check будет выставлена в единицу, если нет, то останется нулем.
И вывод будет реально "1". Что выглядит довольно печально.
Ну и кстати, такое поведение довольно легко объяснить. Когда мы перегружаем операторы, то мы создаем новые функции. И я хочу акцентировать на этом внимание: это именно пользовательские функции, как бы они там не назывались. А аргументы пользовательских функций должны быть вычислены ДО захода в функцию. Поэтому любые операнды должны быть полностью вычислены до вычисления значения всего выражения. Это и приводит к отсутствию свойства short circuit.
Хотя в том виде, в котором оператор перегружен в коде выше, внутри него используется short circuit операция и на самом деле второй операнд не будет учитываться, если у вызываемого объекта поле класса равно нулю. Но за счет того, что мы обязаны вычислить второй операнд, то просто технически не выполняются требования короткой схемы вычислений.
Встроеные же операторы реализованы на более низком уровне и не являются в прямом смысле функциями. И в эту реализацию изначально заложен короткосхемный функционал.
Однако есть способ разрешить ленивое вычисление логического И или ИЛИ для кастомных типов. Но об этом в следующий раз.
Don't loose your properties. Stay cool
#cppcore
{kind=link}
Short circuit операторы для кастомных типов
Свойство короткосхемности в плюсах, как мы все уже знаем, имеют 2 оператора: логическое И и логическое ИЛИ. Но здесь есть проблема, что они теряют это свойство, если их перегружают. Давайте немножко углубимся в философию и порассуждаем кое над чем.
Что вообще такое логическое И и что оно делает?(я говорю только про И для краткости, те же рассуждения применяются и к ИЛИ) Эта логическая функция aka коньюнкция. Она отображает множество {0, 1}^N в {0, 1}. То есть она принимает N аргументов, каждый из которых может иметь только в двух значений 0 или 1, и результатом ее работы тоже является одно из двух значений: 0 и 1. Результатом будет 0, если хотя бы один из аргументов имеем значение 0. В обратном случае, результатом будет 1.
Что это нам дает.
А то, что операндами по строгому математическому определению могут быть только булевые значения. То есть, когда вы делаете логическое И с любыми объектами, на самом деле вы не хотите перегружать этот оператор для работы со своими объектами. Вы хотите(может и не осознанно) ровно такую же логику работы, как и у встроенного оператора: приводить операнды к true или false на ходу. Потому что Логическое И работает с бинарными сущностями. Это просто из определения исходит, что операнды должны быть бинарными. Поэтому на самом деле нужно не перегружать оператор, а научить компилятор преобразовывать объект в тип bool. Тогда вы сможете насладиться всеми чудесами вычислений по короткой схеме.
Пример из прошлого поста можно переписать вот так:
Теперь мы научили компилятор преобразовывать объекты нашего кастомного класса в булы и вместо перегруженного оператора используем встроенный. И вуаля, вывод этого кода будет "0". То есть функция func не выполнилась, потому что результат выражения стал ясен после вычисления первого операнда и смысла от вычисления второго нет.
Вот так получается, что нет смысла перегружать операторы логического И и ИЛИ для кастомных объектов. На самом деле нужно перегрузить оператор приведения к булевому значению. И будет вам счастье.
Define things properly. Stay cool.
#cppcore
Свойство короткосхемности в плюсах, как мы все уже знаем, имеют 2 оператора: логическое И и логическое ИЛИ. Но здесь есть проблема, что они теряют это свойство, если их перегружают. Давайте немножко углубимся в философию и порассуждаем кое над чем.
Что вообще такое логическое И и что оно делает?(я говорю только про И для краткости, те же рассуждения применяются и к ИЛИ) Эта логическая функция aka коньюнкция. Она отображает множество {0, 1}^N в {0, 1}. То есть она принимает N аргументов, каждый из которых может иметь только в двух значений 0 или 1, и результатом ее работы тоже является одно из двух значений: 0 и 1. Результатом будет 0, если хотя бы один из аргументов имеем значение 0. В обратном случае, результатом будет 1.
Что это нам дает.
А то, что операндами по строгому математическому определению могут быть только булевые значения. То есть, когда вы делаете логическое И с любыми объектами, на самом деле вы не хотите перегружать этот оператор для работы со своими объектами. Вы хотите(может и не осознанно) ровно такую же логику работы, как и у встроенного оператора: приводить операнды к true или false на ходу. Потому что Логическое И работает с бинарными сущностями. Это просто из определения исходит, что операнды должны быть бинарными. Поэтому на самом деле нужно не перегружать оператор, а научить компилятор преобразовывать объект в тип bool. Тогда вы сможете насладиться всеми чудесами вычислений по короткой схеме.
Пример из прошлого поста можно переписать вот так:
struct CustomStruct
{
int number = 0;
explicit operator bool() const
{
return number;
}
};
static int check = 0;
CustomStruct func()
{
check = 1;
return CustomStruct{};
}
int main() {
CustomStruct a{};
a && func();
std::cout << check << std::endl;
}
Теперь мы научили компилятор преобразовывать объекты нашего кастомного класса в булы и вместо перегруженного оператора используем встроенный. И вуаля, вывод этого кода будет "0". То есть функция func не выполнилась, потому что результат выражения стал ясен после вычисления первого операнда и смысла от вычисления второго нет.
Вот так получается, что нет смысла перегружать операторы логического И и ИЛИ для кастомных объектов. На самом деле нужно перегрузить оператор приведения к булевому значению. И будет вам счастье.
Define things properly. Stay cool.
#cppcore
{kind=link}
Виртуальный деструктор и std::shared_ptr
#опытным
Плюсы - поистине удивительный язык. Вот подписчик изучил у нас на канале пользу виртуального деструктора и пошел в комментарии. А там Василий прислал пример, который говорит о том, что в определенном случае виртульность деструктора не важна и без него все работает корректно. И подписчик действительно удивляется: "What the fuck is going on?!?!?!?". Разберем все по порядку.
Пример вот такой:
Прикол в том, что при удалении p1 вызовется деструктор наследованного класса:
Почему так?
Во время создания std::shared_ptr вы можете задать свой кастомный делитер. Но даже если вы его не предоставили, делитер все равно создается. Просто компилятор сам выведет по его мнению подходящий удалятель. И сохранит его в контрол блок умного указателя.
Так вот логично, что, если мы создаем указатель от объекта тип Derived, то и делитер выбирается соотвествующий. И в контрол блоке правого шареда будет делитер, который удаляет Derived*. Далее при присваивании указатель на этот конкретный контрол блок копируется левому шареду. После этого контрольный блок
Именно поэтому и вызывается деструктор наследника.
Если мы попытаемся создать std::shared_ptr вот так:
то никакой магии уже не будет и деструктор наследника не вызовется. Потому что делитер ничего не будет знать о наследнике, так как мы явным образом привели указатель наследника в указателю на базовый класс.
Ну и с уникальным указателем с одним шаблонным параметров такая штука тоже не сработает. Там делитер оптимизирован и выбирается по умолчанию std::default_delete для типа шаблонного параметра, он не хранится в объекте. Поэтому для такой строчки:
для p1 не вызовется деструктор наследника, потому что делитер типа std::unique_ptr<Base> удаляет только указатели на базовый класс. Чтобы объект удалялся корректно, нужен виртуальный деструктор базового класса. Без него никак.
Хоть такой интересный момент в плюсах и существует - не нужно на него полагаться. Одними шаредами жизнь не заканчивается, а классы должны вести себя корректно. Поэтому виртуальный деструктор - наше все!
Stay amazed. Stay cool.
#cpp11 #cppcore
#опытным
Плюсы - поистине удивительный язык. Вот подписчик изучил у нас на канале пользу виртуального деструктора и пошел в комментарии. А там Василий прислал пример, который говорит о том, что в определенном случае виртульность деструктора не важна и без него все работает корректно. И подписчик действительно удивляется: "What the fuck is going on?!?!?!?". Разберем все по порядку.
Пример вот такой:
struct Base {
~Base() {
std::cout << "Base::~Base()" << std::endl;
}
};
struct Derived : Base {
~Derived() {
std::cout << "Derived::~Derived()" << std::endl;
}
};
int main() {
std::shared_ptr<Base> p1 = std::make_shared<Derived>();
}Прикол в том, что при удалении p1 вызовется деструктор наследованного класса:
Derived::~Derived()
Base::~Base()
Почему так?
Во время создания std::shared_ptr вы можете задать свой кастомный делитер. Но даже если вы его не предоставили, делитер все равно создается. Просто компилятор сам выведет по его мнению подходящий удалятель. И сохранит его в контрол блок умного указателя.
Так вот логично, что, если мы создаем указатель от объекта тип Derived, то и делитер выбирается соотвествующий. И в контрол блоке правого шареда будет делитер, который удаляет Derived*. Далее при присваивании указатель на этот конкретный контрол блок копируется левому шареду. После этого контрольный блок
p1 содержит тот самый изначальный делитер, который условно говоря сделает перед удалением указателя каст к классу наследника(delete static_cast<Derived*>(ptr)).Именно поэтому и вызывается деструктор наследника.
Если мы попытаемся создать std::shared_ptr вот так:
std::shared_ptr<Base> shared(static_cast<Base*>(new Derived));
то никакой магии уже не будет и деструктор наследника не вызовется. Потому что делитер ничего не будет знать о наследнике, так как мы явным образом привели указатель наследника в указателю на базовый класс.
Ну и с уникальным указателем с одним шаблонным параметров такая штука тоже не сработает. Там делитер оптимизирован и выбирается по умолчанию std::default_delete для типа шаблонного параметра, он не хранится в объекте. Поэтому для такой строчки:
std::unique_ptr<Base> p1 = std::make_unique<Derived>();
для p1 не вызовется деструктор наследника, потому что делитер типа std::unique_ptr<Base> удаляет только указатели на базовый класс. Чтобы объект удалялся корректно, нужен виртуальный деструктор базового класса. Без него никак.
Хоть такой интересный момент в плюсах и существует - не нужно на него полагаться. Одними шаредами жизнь не заканчивается, а классы должны вести себя корректно. Поэтому виртуальный деструктор - наше все!
Stay amazed. Stay cool.
#cpp11 #cppcore
{kind=link}
Опасности использования директив препроцессора
Вчерашний способ выбора ветки кода имеет несколько недостатков:
⛔️ Препроцессор работает с буквами/текстом программы, но не понимает программных сущностей. Это значит, что типабезопасность уходит из окна, и открывается простор для разного рода трудноотловимых багов.
⛔️ При компиляции проверяется только та ветка, которая попадет в итоговый код. Если вы не протестировали сборку своего кода для разных значений внешних параметров, а такое бывает например когда пока что есть только одно значение, а другое будет только в будущем. И в будущем скорее всего придется отлаживать элементарную сборку, потому что в код попадет непроверенная ветка.
⛔️ Вы ограничены возможностями препроцессора. Это значит, что вы не можете использовать в условии compile-time вычисления (аля результат работы constexpr функции).
⛔️ Отсюда же вытекает отсутствие возможности проверки условий, основанных на шаблонных параметрах кода. Это все из-за того, что препроцессор работает до начала компиляции программы. Он в душе не знает, что вы вообще программу пишите. Ему в целом ничего не мешает обработать текст Войны и Мира. Именно из-за отсутствия понимания контекста программы, мы и не можем проверять условия, основанные на compile-time значениях или шаблонных параметрах. Если вы хотите проверить, указатель ли к вам пришел в функцию или нет, или собрать какую-то метрику с constexpr массива и на ее основе принять решение - у вас ничего не выйдет.
⛔️ Вы очень сильно ограничены возможностями препроцессора. Попробуйте например сравнить какой-нибудь макрос с фиксированной строкой. Спойлер: у вас скорее всего ничего не выйдет. Например, как в примере из поста выше мы не можем написать так:
Поэтому и приходилось определять тип циферками.
Это конечно мем: сущность, которая работает с текстом программы, то есть со строками, не может работать со строками.
⛔️ С препроцессором в принципе опасно работать и еще труднее отлаживать магические баги. Могут возникнуть например вот такие трудноотловимые ошибки. Вам придется смотреть уже обработанную единицу трансляции, причем иногда даже не понимая, где может быть проблема. А со всеми включенными бинарниками и преобразованиями препроцессора это делать очень долго и больно. А потом оказывается, что какой-то умник заменил в макросах функцию DontWorryBeHappy на ILovePainGiveMeMore.
В комментах @xiran22 скидывал пример библиотечки, написанной с помощью макросов. Вот она, можете посмотреть. Это не только пример сложности понимания кода и всех проблем выше. Тут просто плохая архитектура, затыки которой решаются макросами.
Поделитесь в комментах своими интересными кейсами простреленных ступней из-за макросов.
Avoid dangerous tools. Stay cool.
#compiler #cppcore
Вчерашний способ выбора ветки кода имеет несколько недостатков:
⛔️ Препроцессор работает с буквами/текстом программы, но не понимает программных сущностей. Это значит, что типабезопасность уходит из окна, и открывается простор для разного рода трудноотловимых багов.
⛔️ При компиляции проверяется только та ветка, которая попадет в итоговый код. Если вы не протестировали сборку своего кода для разных значений внешних параметров, а такое бывает например когда пока что есть только одно значение, а другое будет только в будущем. И в будущем скорее всего придется отлаживать элементарную сборку, потому что в код попадет непроверенная ветка.
⛔️ Вы ограничены возможностями препроцессора. Это значит, что вы не можете использовать в условии compile-time вычисления (аля результат работы constexpr функции).
⛔️ Отсюда же вытекает отсутствие возможности проверки условий, основанных на шаблонных параметрах кода. Это все из-за того, что препроцессор работает до начала компиляции программы. Он в душе не знает, что вы вообще программу пишите. Ему в целом ничего не мешает обработать текст Войны и Мира. Именно из-за отсутствия понимания контекста программы, мы и не можем проверять условия, основанные на compile-time значениях или шаблонных параметрах. Если вы хотите проверить, указатель ли к вам пришел в функцию или нет, или собрать какую-то метрику с constexpr массива и на ее основе принять решение - у вас ничего не выйдет.
⛔️ Вы очень сильно ограничены возможностями препроцессора. Попробуйте например сравнить какой-нибудь макрос с фиксированной строкой. Спойлер: у вас скорее всего ничего не выйдет. Например, как в примере из поста выше мы не можем написать так:
int DotProduct(const std::vector<int>& vec1, const std::vector<int>& vec2)
{
int result = 0;
#if CPU_TYPE == "INTEL"
// mmx|sse|avx code
#elif CPU_TYPE == "ARM"
// arm neon code
#else
static_assert(0, "NO CPU_TYPE IS SPECIFIED");
#endif
return result;
}
Поэтому и приходилось определять тип циферками.
Это конечно мем: сущность, которая работает с текстом программы, то есть со строками, не может работать со строками.
⛔️ С препроцессором в принципе опасно работать и еще труднее отлаживать магические баги. Могут возникнуть например вот такие трудноотловимые ошибки. Вам придется смотреть уже обработанную единицу трансляции, причем иногда даже не понимая, где может быть проблема. А со всеми включенными бинарниками и преобразованиями препроцессора это делать очень долго и больно. А потом оказывается, что какой-то умник заменил в макросах функцию DontWorryBeHappy на ILovePainGiveMeMore.
В комментах @xiran22 скидывал пример библиотечки, написанной с помощью макросов. Вот она, можете посмотреть. Это не только пример сложности понимания кода и всех проблем выше. Тут просто плохая архитектура, затыки которой решаются макросами.
Поделитесь в комментах своими интересными кейсами простреленных ступней из-за макросов.
Avoid dangerous tools. Stay cool.
#compiler #cppcore
{kind=link}
Правила константности
#новичкам
Константность - важное свойство сущности в коде. Оно не только позволяет обезопасить объекты от изменения, но еще и говорит программисту о гарантиях, которые дает та или иная функция. Допустим, принимая параметр по константной ссылке, функция говорит программисту: "расслабься, ничего я не сделаю с твоим объектом". Это повышает читаемость кода.
В С++ много чего можно сделать константным. Объекты, указатели, ссылки, параметры функции, методы класса и тд. И зачастую новичкам сложно разобраться в правилах присваивания константности. Сегодня разберемся в этом.
Не будем долго задерживаться над константными методами. Константные объекты могут вызвать только константные методы. Все. Синтаксис такой:
Теперь и константные, и неконстантные объекты могут вызывать метод Method.
Дальше все так или иначе сводится к правилам в объявлении переменных. Что в качестве поля класса, параметра функции, что объявлении обычной переменной - разницы нет. Правила одни. Поехали.
Константный объект можно объявить двумя способами:
Эти записи абсолютно эквивалентны! Это очень важно запомнить, потому что при разговоре о ссылках и указателях это играет большую роль.
Собственно также есть 2 нотации объявления массивов констант:
И 2 нотации определения ссылок:
Помните, что при создании ссылки в скоупе функции вы обязаны ее инициализировать.
При объявлении поля класса этого делать не обязательно, потому что вы не создаете объект прямо сейчас. Но вы обязаны инициализировать ссылку до входа в конструктор либо через список инициализации конструктора, либо через default member initializer, так как базового поля класса иницализируются до входа в конструктор.
При объявлении параметра функции тоже не нужно сразу инициализировать ссылку, потому что функция принимает уже существующую и инициализированую ссылку на вход.
Обычно при таком объявлении ссылку называют константной. Это не совсем верно. Ссылка при любых обстоятельствах сама по себе является константной. Как только вы забиндили ссылку на объект, она всегда будет смотреть на этот объект и изменять его. Более подробно про особенности ссылок посмотреть тут. При новом присваивании ссылки вызовется оператор присваивания и изменится существующий объект.
Когда говорят "константная ссылка" имеют ввиду ссылку на константу. И при любом виде объявления const T& ref или T const & ref она также будет ссылкой на константу.
Теперь указатели. Наверное самое сложное из всего перечисленного. Указатели, в отличии от ссылок, сами могут быть константными, да еще и указывать на константные объекты. А еще могут быть многоуровненые указатели. В общем сложно. Но есть правило: при объявлении указателя каждое появление ключевого слова const относится к тому уровню вложенности, который находится слева от этого слова. Вы просто читаете объявление справа налево и получаете правильное понимание объявления. Примеры:
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
Rely on fixed thing in your life. Stay cool.
#cppcore
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
#новичкам
Константность - важное свойство сущности в коде. Оно не только позволяет обезопасить объекты от изменения, но еще и говорит программисту о гарантиях, которые дает та или иная функция. Допустим, принимая параметр по константной ссылке, функция говорит программисту: "расслабься, ничего я не сделаю с твоим объектом". Это повышает читаемость кода.
В С++ много чего можно сделать константным. Объекты, указатели, ссылки, параметры функции, методы класса и тд. И зачастую новичкам сложно разобраться в правилах присваивания константности. Сегодня разберемся в этом.
Не будем долго задерживаться над константными методами. Константные объекты могут вызвать только константные методы. Все. Синтаксис такой:
void Class::Method(Type1 param1, Type2 param2) const {}Теперь и константные, и неконстантные объекты могут вызывать метод Method.
Дальше все так или иначе сводится к правилам в объявлении переменных. Что в качестве поля класса, параметра функции, что объявлении обычной переменной - разницы нет. Правила одни. Поехали.
Константный объект можно объявить двумя способами:
const T obj;
// Либо
T const obj;
Эти записи абсолютно эквивалентны! Это очень важно запомнить, потому что при разговоре о ссылках и указателях это играет большую роль.
Собственно также есть 2 нотации объявления массивов констант:
const T arr[5];
// либо
T const arr[5];
И 2 нотации определения ссылок:
const T& ref;
// либо
T const & ref;
Помните, что при создании ссылки в скоупе функции вы обязаны ее инициализировать.
При объявлении поля класса этого делать не обязательно, потому что вы не создаете объект прямо сейчас. Но вы обязаны инициализировать ссылку до входа в конструктор либо через список инициализации конструктора, либо через default member initializer, так как базового поля класса иницализируются до входа в конструктор.
При объявлении параметра функции тоже не нужно сразу инициализировать ссылку, потому что функция принимает уже существующую и инициализированую ссылку на вход.
Обычно при таком объявлении ссылку называют константной. Это не совсем верно. Ссылка при любых обстоятельствах сама по себе является константной. Как только вы забиндили ссылку на объект, она всегда будет смотреть на этот объект и изменять его. Более подробно про особенности ссылок посмотреть тут. При новом присваивании ссылки вызовется оператор присваивания и изменится существующий объект.
struct Type {
Type& operator=(const Type& other) {
std::cout << "copy assign" << std::endl;
return *this;
}
};
Type a{};
Type& b = a;
b = Type{};
// OUTPUT:
// copy assignКогда говорят "константная ссылка" имеют ввиду ссылку на константу. И при любом виде объявления const T& ref или T const & ref она также будет ссылкой на константу.
Теперь указатели. Наверное самое сложное из всего перечисленного. Указатели, в отличии от ссылок, сами могут быть константными, да еще и указывать на константные объекты. А еще могут быть многоуровненые указатели. В общем сложно. Но есть правило: при объявлении указателя каждое появление ключевого слова const относится к тому уровню вложенности, который находится слева от этого слова. Вы просто читаете объявление справа налево и получаете правильное понимание объявления. Примеры:
// Читаем справа налево
int * const ptr; // ptr - это константный указатель на инт
int * * const ptr; // ptr - это константный указатель на указатель на инт
int * const * const ptr; // ptr - это константный указатель на константный указатель на инт
// Самый низкий уровень, который относится к самому объекту,
// можно писать двумя способами, о которых мы говорили выше
int const * const * * const ptr; // ptr - это константный указатель на указатель
// на константный указатель на интовую константу
const int * const * * const ptr; // Тоже самое
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
Rely on fixed thing in your life. Stay cool.
#cppcore
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
{kind=link}
Swap idiom
Рассуждения в комментах под предыдущим постом навели меня на мысли рассказать о swap idiom.
Дело в том, что, когда у вас есть рабочие деструктор, конструктор копирования и перемещения, вы можете соединять методы, которые должны принимать константную lvalue ссылку и rvalue ссылку, в один метод, который принимает параметр по значению. То есть можно вместо 2-х методов сеттеров можно написать 1:
Этой же концепцией вдохновлено появление swap идиомы. На самом деле я немного вру, но с появлением мув-семантики идиома приобрела эти черты.
Суть в чем. Есть у вас класс, который мэнэджит какие-то ресурсы. Например самописный класс массива:
Все хорошо, но для выполнения правила 5 нам нужно определить еще и 2 оператора присваивания: перемещающий и копирующий. Обычно в них в начале очищают существующий объект и потом записываются новые данные. Покажу на примере копирующего оператора присваивания:
В такой реализации есть 3 проблемы:
❗️ Нам просто необходима проверка на самоприсвоение, чтобы в объекте остались те же данные. Но это настолько редкий кейс, что каждый раз при присвоении тратить время на проверку не очень хочется. А хочется операторы без этой проверки.
❗️ У нас есть только базовая гарантия исключений. Если из new бросится исключение, то состояние изменяемого объекта хоть и останется согласованным, но оно все равно изменится. А операция не завершится до конца. Хотелось бы строгой гарантии безопасности исключений.
❗️ Мы повторяем код. Помимо проверки самоприсваивания и очищения ресурсов тупо повторяется код копирующего конструктора. Хочется этого не делать.
Чтобы решить эти проблемы, мы можем сделать интересную штуку - принимать параметр оператора присваивания на обычное значение. Тогда на входе оператора у нас уже будет готовый скопированный(или перемещенный объект) и нам нужно будет лишь поменять содержимое этих двух объектов местами. И нам не нужно беспокоиться о том, что останется в параметре функции - он все равно удалится после выхода из нее. Теперь оператор будет выглядеть так:
Как же красиво! Нам осталось только реализовать функцию swap. Она может быть и методом класса, но почему бы еще не иметь просто функцию, которая свапает контент. Поэтому покажу реализацию дружественной функции.
Выглядит кратко, читаемо, да еще и исключений нет(об этом даже явно в коде можно сказать)! Ляпота.
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
Stay laconic. Stay cool.
#patter #cppcore #cpp11
Рассуждения в комментах под предыдущим постом навели меня на мысли рассказать о swap idiom.
Дело в том, что, когда у вас есть рабочие деструктор, конструктор копирования и перемещения, вы можете соединять методы, которые должны принимать константную lvalue ссылку и rvalue ссылку, в один метод, который принимает параметр по значению. То есть можно вместо 2-х методов сеттеров можно написать 1:
template <class T>
struct TemplateClass {
void SetValue(T value) {
value_ = std::move(value);
}
private:
T value_;
};
Этой же концепцией вдохновлено появление swap идиомы. На самом деле я немного вру, но с появлением мув-семантики идиома приобрела эти черты.
Суть в чем. Есть у вас класс, который мэнэджит какие-то ресурсы. Например самописный класс массива:
class SimpleArray
{
public:
SimpleArray(std::size_t size = 0)
: mSize(size),
mArray(mSize ? new intmSize : nullptr) {}
SimpleArray(const SimpleArray& other)
: mSize(other.mSize),
mArray(mSize ? new int[mSize] : nullptr) {
std::copy(other.mArray, other.mArray + mSize, mArray);
}
SimpleArray(simple_array&& other) noexcept
: mSize(other.mSize),
mArray(other.mArray) {other.mArray = nullptr;}
~SimpleArray()
{
delete [] mArray;
}
private:
std::size_t mSize;
int* mArray;
};
Все хорошо, но для выполнения правила 5 нам нужно определить еще и 2 оператора присваивания: перемещающий и копирующий. Обычно в них в начале очищают существующий объект и потом записываются новые данные. Покажу на примере копирующего оператора присваивания:
SimpleArray& operator=(const SimpleArray& other) {
if (this != &other) {
delete [] mArray;
mArray = nullptr;
mSize = 0;
mSize = other.mSize;
mArray = mSize ? new int[mSize] : nullptr;
std::copy(other.mArray, other.mArray + mSize, mArray);
}
return *this;
}В такой реализации есть 3 проблемы:
❗️ Нам просто необходима проверка на самоприсвоение, чтобы в объекте остались те же данные. Но это настолько редкий кейс, что каждый раз при присвоении тратить время на проверку не очень хочется. А хочется операторы без этой проверки.
❗️ У нас есть только базовая гарантия исключений. Если из new бросится исключение, то состояние изменяемого объекта хоть и останется согласованным, но оно все равно изменится. А операция не завершится до конца. Хотелось бы строгой гарантии безопасности исключений.
❗️ Мы повторяем код. Помимо проверки самоприсваивания и очищения ресурсов тупо повторяется код копирующего конструктора. Хочется этого не делать.
Чтобы решить эти проблемы, мы можем сделать интересную штуку - принимать параметр оператора присваивания на обычное значение. Тогда на входе оператора у нас уже будет готовый скопированный(или перемещенный объект) и нам нужно будет лишь поменять содержимое этих двух объектов местами. И нам не нужно беспокоиться о том, что останется в параметре функции - он все равно удалится после выхода из нее. Теперь оператор будет выглядеть так:
SimpleArray& operator=(SimpleArray other) noexcept {
swap(*this, other);
return *this;
}Как же красиво! Нам осталось только реализовать функцию swap. Она может быть и методом класса, но почему бы еще не иметь просто функцию, которая свапает контент. Поэтому покажу реализацию дружественной функции.
friend void swap(SimpleArray& first, SimpleArray& second) noexcept {
using std::swap;
swap(first.mSize, second.mSize);
swap(first.mArray, second.mArray);
}Выглядит кратко, читаемо, да еще и исключений нет(об этом даже явно в коде можно сказать)! Ляпота.
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
Stay laconic. Stay cool.
#patter #cppcore #cpp11
{kind=link}
Swap idiom. Pros and cons
#опытным
В этом посте поговорили про суть swap идиомы. Сегодня обсудим ее плюсы и минусы.
Плюсы вроде как обсуждали, но я финализирую, когда можно рассмотреть внедрение swap idiom:
✅ Если у вас конструктор копирования может бросить исключение и вы можете написать небросающую функцию swap. Тогда за счет того, что захват ресурсов(копирование или перемещение во временный объект параметра функции) происходит до модификации текущего объекта, то мы получаем строгую гарантию безопасности исключений при работе с присваиванием объектов.
✅ Если вы хотите красивый, лаконичный и понятный код без повторений действий.
✅ Вы не очень беспокоитесь о потенциальных потерях производительности.
Погнали по минусам:
❗️ Не всегда можно написать nothrowing swap. Для базовых типов и указателей - да. Но swap нетривиальных типов использует временный объект. При создании которого и может возникнуть исключение. Сейчас swap делается с помощью перемещающих операций, но например в С++03 std::string мог кинуть исключение в копирующем конструкторе. Да и сейчас поля класса могут быть немувабельными и бросающими при копировании. Это надо иметь ввиду.
❗️ Каждый раз при присваивании мы выполняем 2 операции: конструктор копирования + swap или конструктор перемещения + swap. "Потери производительности" надо конечно тестить и смотреть реальные результаты, но в голове все равно надо держать потенциальные просадки.
❗️ Самостоятельно писать деструктор для менеджинга ресурсов в 2к24 - такая себе практика в большинстве случаев. Давно есть std::unique_ptr<T[]>, указатели с кастомными делитерами и прочие вещи. Одно из ключевых преимуществ идиомы - сокращение и переиспользование кода. Так вот с отсутствием деструктора вам вообще может не понадобится кастомное присваивание и вы сможете объявить операции дефолтными, поэтому надобность в идиоме сама по себе отпадет.
❗️❗️ Часто пропускаемый огромный минус: технически у нас есть оператор перемещения, который может принимать rvalue ссылки. Однако мы явным образом не реальзовывали присваивание перемещением, поэтому по правилу 5, компилятор не будет его генерировать за нас и у класса просто будет отсутствовать оператор присваивания перемещением.
И хоть текущий класс мы можем мэнэджить без присваивания перемещением, то ситуация изменится, когда мы сделаем текущий класс полем другого. Тогда у этого другого класса не будет генерироваться дефолтный оператор присваивания перемещением! Для его генерации все поля должны иметь такие операторы. А в нашем классе его нет.
Это значит, что по дефолту будет использоваться копирующее присваивания и все остальные поля нового класса будут копироваться. А вы об этом даже не знали! И получили жесткую просадку и, потенциально, некорректную логику.
Выбор использовать или не исопльзовать - как всегда за вам. Тестируйте гипотезы и выбирайте из них лучшую.
Analyse your solutions. Stay cool.
#cppcore #cpp11
#опытным
В этом посте поговорили про суть swap идиомы. Сегодня обсудим ее плюсы и минусы.
Плюсы вроде как обсуждали, но я финализирую, когда можно рассмотреть внедрение swap idiom:
✅ Если у вас конструктор копирования может бросить исключение и вы можете написать небросающую функцию swap. Тогда за счет того, что захват ресурсов(копирование или перемещение во временный объект параметра функции) происходит до модификации текущего объекта, то мы получаем строгую гарантию безопасности исключений при работе с присваиванием объектов.
✅ Если вы хотите красивый, лаконичный и понятный код без повторений действий.
✅ Вы не очень беспокоитесь о потенциальных потерях производительности.
Погнали по минусам:
❗️ Не всегда можно написать nothrowing swap. Для базовых типов и указателей - да. Но swap нетривиальных типов использует временный объект. При создании которого и может возникнуть исключение. Сейчас swap делается с помощью перемещающих операций, но например в С++03 std::string мог кинуть исключение в копирующем конструкторе. Да и сейчас поля класса могут быть немувабельными и бросающими при копировании. Это надо иметь ввиду.
❗️ Каждый раз при присваивании мы выполняем 2 операции: конструктор копирования + swap или конструктор перемещения + swap. "Потери производительности" надо конечно тестить и смотреть реальные результаты, но в голове все равно надо держать потенциальные просадки.
❗️ Самостоятельно писать деструктор для менеджинга ресурсов в 2к24 - такая себе практика в большинстве случаев. Давно есть std::unique_ptr<T[]>, указатели с кастомными делитерами и прочие вещи. Одно из ключевых преимуществ идиомы - сокращение и переиспользование кода. Так вот с отсутствием деструктора вам вообще может не понадобится кастомное присваивание и вы сможете объявить операции дефолтными, поэтому надобность в идиоме сама по себе отпадет.
❗️❗️ Часто пропускаемый огромный минус: технически у нас есть оператор перемещения, который может принимать rvalue ссылки. Однако мы явным образом не реальзовывали присваивание перемещением, поэтому по правилу 5, компилятор не будет его генерировать за нас и у класса просто будет отсутствовать оператор присваивания перемещением.
И хоть текущий класс мы можем мэнэджить без присваивания перемещением, то ситуация изменится, когда мы сделаем текущий класс полем другого. Тогда у этого другого класса не будет генерироваться дефолтный оператор присваивания перемещением! Для его генерации все поля должны иметь такие операторы. А в нашем классе его нет.
Это значит, что по дефолту будет использоваться копирующее присваивания и все остальные поля нового класса будут копироваться. А вы об этом даже не знали! И получили жесткую просадку и, потенциально, некорректную логику.
struct FirstField {
FirstField() = default;
FirstField(const FirstField& other) {
std::cout << "FirstField Copy ctor" << std::endl;
}
FirstField& operator=(FirstField other) {
std::cout << "FirstField assign" << std::endl;
return *this;
}
FirstField(FirstField&& other) {
std::cout << "FirstField Move ctor" << std::endl;
}
};
struct SecondField {
SecondField() = default;
SecondField(const SecondField& other) {
std::cout << "SecondField Copy ctor" << std::endl;
}
SecondField& operator=(const SecondField& other) {
std::cout << "SecondField Copy assign" << std::endl;
return *this;
}
SecondField(SecondField&& other) {
std::cout << "SecondField Move ctor" << std::endl;
}
SecondField& operator=(SecondField&& other) {
std::cout << "SecondField Copy assign" << std::endl;
return *this;
}
};
struct Wrapper {
FirstField ff;
SecondField sf;
};
Wrapper w;
w = std::move(Wrapper{});
// OUTPUT:
// FirstField Move ctor
// FirstField assign
// SecondField Copy assignВыбор использовать или не исопльзовать - как всегда за вам. Тестируйте гипотезы и выбирайте из них лучшую.
Analyse your solutions. Stay cool.
#cppcore #cpp11
{kind=link}
Вектор ссылок
#опытным
Не знаю, задумывались ли вы когда-нибудь создать вектор ссылок. Наверное задумывались, но не прям, чтобы пытались воплотить в жизнь. Не очень понятны кейсы применения этих сущностей. Однако они довольно хорошо подсвечивают одну интересную и базовую особенность вектора.
Дело в том, что вы не можете создать вектор ссылок. Не можете и все. Попробуйте написать что-то такое и запустить сборку:
Вылезет какая-то совершенно монструозная кракозябра, по которой мы хрен пойми, что должны понять. Это немного камней в огород бесполезных сообщений об ошибках в плюсах, но продолжим.
В сущности это происходит по одной причине. Шаблонный тип
До C++11 и появления мув-семантики элементы вектора должны были удовлетворять требованиям CopyAssignable и CopyConstructible. То есть из этих объектов должны получаться валидные копии, притом что исходный объект оказывается нетронутым. Это условие, кстати, не выполняется для запрещенного в РФ иноагента std::auto_ptr. Так вот ссылочный тип - не CopyAssignable. При попытке присвоить ссылке что-то копирования не происходит, а происходит просто перенаправление ссылки на другой объект.
После С++11 требования немного смягчились и теперь единственный критерий, которому тип элементов вектора должен удовлетворять - Erasable. Но ссылки также не попадают под этот критерий(для них не определен деструктор). Поэтому сидим без вектора ссылок. Или нет?
Можно хакнуть этот ваш сиплюсплюс и создать вектор из std::reference_wrapper. Это такая тривиальная обертка над ссылками, чтобы ими можно было оперировать, как обычными объектами. В смысле наличия у них всех специальных методов классов.
Но будьте осторожны(!), потому что есть одна большая проблема со ссылками. Вот мы создали и заполнили контейнер ссылками на какие-то объекты. И потом вышли из скоупа, где были объявлены объекты, на которые ссылки указывают. Вектор есть, ссылки есть, а объектов нет. Это чистой воды undefined behavior. Ссылки будут указывать на уже удаленные объекты. Пример:
Вывод будет такой:
Подумайте пару секунд, почему так. Переменная i меняется и мы добавляем ссылки на эту переменную в вектор. По итогу все элементы вектора указывают на одну и ту же переменную. Поэтому и элементы все одинаковы.
Но раз ссылка - это обертка над указателем, то элементы вектора по факту хранят адрес того места, где была переменная i. Поэтому все изменения ячейки памяти этой переменной будут отражаться на ссылках, даже если переменная уже удалена. Вот мы и сделали грязь: сохранили адрес ячейки и изменили его после выхода из скоупа цикла и удаления переменной i. Так обычно и происходит на стеке: переменная кладется на стек, с ней работают, она удаляется при выходе из скоупа и потом другие объект занимают место удаленной переменной в памяти. Мы здесь сымитировали такой процесс.
Так как вектор после выхода из скоупа цикла хранит висячие ссылки, то поведение в такой ситуации неопределено и наш грязный мув четко это показывает. После присваивания нового значения по указателю
Будьте аккуратны со ссылками. В этом случае проще использовать какой-нибудь умный указатель. Все будет чинно и цивильно. И никакого UB.
Be careful. Stay cool.
#cpp11 #cppcore #STL
#опытным
Не знаю, задумывались ли вы когда-нибудь создать вектор ссылок. Наверное задумывались, но не прям, чтобы пытались воплотить в жизнь. Не очень понятны кейсы применения этих сущностей. Однако они довольно хорошо подсвечивают одну интересную и базовую особенность вектора.
Дело в том, что вы не можете создать вектор ссылок. Не можете и все. Попробуйте написать что-то такое и запустить сборку:
std::vector<int&> vec;
Вылезет какая-то совершенно монструозная кракозябра, по которой мы хрен пойми, что должны понять. Это немного камней в огород бесполезных сообщений об ошибках в плюсах, но продолжим.
В сущности это происходит по одной причине. Шаблонный тип
vec не удовлетворяет требованиям к типам элементов вектора.До C++11 и появления мув-семантики элементы вектора должны были удовлетворять требованиям CopyAssignable и CopyConstructible. То есть из этих объектов должны получаться валидные копии, притом что исходный объект оказывается нетронутым. Это условие, кстати, не выполняется для запрещенного в РФ иноагента std::auto_ptr. Так вот ссылочный тип - не CopyAssignable. При попытке присвоить ссылке что-то копирования не происходит, а происходит просто перенаправление ссылки на другой объект.
После С++11 требования немного смягчились и теперь единственный критерий, которому тип элементов вектора должен удовлетворять - Erasable. Но ссылки также не попадают под этот критерий(для них не определен деструктор). Поэтому сидим без вектора ссылок. Или нет?
Можно хакнуть этот ваш сиплюсплюс и создать вектор из std::reference_wrapper. Это такая тривиальная обертка над ссылками, чтобы ими можно было оперировать, как обычными объектами. В смысле наличия у них всех специальных методов классов.
Но будьте осторожны(!), потому что есть одна большая проблема со ссылками. Вот мы создали и заполнили контейнер ссылками на какие-то объекты. И потом вышли из скоупа, где были объявлены объекты, на которые ссылки указывают. Вектор есть, ссылки есть, а объектов нет. Это чистой воды undefined behavior. Ссылки будут указывать на уже удаленные объекты. Пример:
std::vector<std::reference_wrapper<int>> vec;
int * p = nullptr;
{
int i;
for (i = 0, p = &i; i < 5; i++) {
vec.emplace_back(i);
}
}
*p = 10;
for (int i = 0; i < 5; i++) {
std::cout << vec[i] << std::endl;
}
Вывод будет такой:
10
10
10
10
10
Подумайте пару секунд, почему так. Переменная i меняется и мы добавляем ссылки на эту переменную в вектор. По итогу все элементы вектора указывают на одну и ту же переменную. Поэтому и элементы все одинаковы.
Но раз ссылка - это обертка над указателем, то элементы вектора по факту хранят адрес того места, где была переменная i. Поэтому все изменения ячейки памяти этой переменной будут отражаться на ссылках, даже если переменная уже удалена. Вот мы и сделали грязь: сохранили адрес ячейки и изменили его после выхода из скоупа цикла и удаления переменной i. Так обычно и происходит на стеке: переменная кладется на стек, с ней работают, она удаляется при выходе из скоупа и потом другие объект занимают место удаленной переменной в памяти. Мы здесь сымитировали такой процесс.
Так как вектор после выхода из скоупа цикла хранит висячие ссылки, то поведение в такой ситуации неопределено и наш грязный мув четко это показывает. После присваивания нового значения по указателю
p все ссылки будут иметь то же самое значение. Хотя изначально такая ситуация вообще не предполагалась.Будьте аккуратны со ссылками. В этом случае проще использовать какой-нибудь умный указатель. Все будет чинно и цивильно. И никакого UB.
Be careful. Stay cool.
#cpp11 #cppcore #STL
{kind=link}
Переобуваемся
В прошлом посте я сказал, что лигитимно создавать вектор констант. Ну и конечно я не просто так написал весь этот пост от балды, все проверял на своей машинке. Хз, что в голове было у компилятора, но он пропускал вектор констант. Больше не буду полагаться на эту шайтан-машину. Да простит Бог его душу, а мы сейчас поправим то, что было написано вчера.
Нормальные компиляторы не соберут вам программу с вектором констант, потому что существуют ограничения, наложенные на аллокаторы. Стандартный вектор объявляется вот так:
Заметим, что шаблонный тип аллокатора совпадает с шаблонным типом элементов вектора. То есть мы будем инстанцировать аллокатор с тем же шаблонным параметром, что и элементы вектора.
А на все аллокаторы, которые могут работать со стандартной библиотекой, наложены ограничения. Одно из них гласит, что шаблонный параметр Т аллокатора должен быть cv-unqualified типом. То есть константные типы туда не входят.
Ну вот собственно и все. Сам контейнер здесь действительно не при чем, ограничения заложены в аллокатор. Спасибо Игорю за то, что подметил ошибку в посте.
Если вы все-таки рьяно хотите вектор констант, то можете рассмотреть варианты оборачивания элементов в умные указатели:
Тогда шаблонный тип, с которым инстанцируется вектор и аллокатор, будет неконстантным и ограничения влиять не будут. И вы можете любые операции с этим вектором делать: хоть сортировки, хоть вставку посередине.
В том числе для таких ситуаций в нашем коммьюнити находятся крутые специалисты. Когда написание постов поставлено на поток, то ошибки неизбежны. Да они и в принципе неизбежны, мы тоже люди и многого не знаем. Иногда еще и инструментарий подводит. И это замечательно, что у нас в канале есть люди, которые вдумчиво читают посты и могут дать адекватную критику по фактам. От этого выигрывают все: критики экологично повышают свою значимость с своих глазах и глазах подписчиков, а в коммьюнити не пропускается ошибочная информация.
Не бойтесь делать ошибки, они уменьшают объем вашего незнания.
Make mistakes. Stay cool.
#cppcore
В прошлом посте я сказал, что лигитимно создавать вектор констант. Ну и конечно я не просто так написал весь этот пост от балды, все проверял на своей машинке. Хз, что в голове было у компилятора, но он пропускал вектор констант. Больше не буду полагаться на эту шайтан-машину. Да простит Бог его душу, а мы сейчас поправим то, что было написано вчера.
Нормальные компиляторы не соберут вам программу с вектором констант, потому что существуют ограничения, наложенные на аллокаторы. Стандартный вектор объявляется вот так:
template<
class T,
class Allocator = std::allocator<T>
> class vector;
Заметим, что шаблонный тип аллокатора совпадает с шаблонным типом элементов вектора. То есть мы будем инстанцировать аллокатор с тем же шаблонным параметром, что и элементы вектора.
А на все аллокаторы, которые могут работать со стандартной библиотекой, наложены ограничения. Одно из них гласит, что шаблонный параметр Т аллокатора должен быть cv-unqualified типом. То есть константные типы туда не входят.
Ну вот собственно и все. Сам контейнер здесь действительно не при чем, ограничения заложены в аллокатор. Спасибо Игорю за то, что подметил ошибку в посте.
Если вы все-таки рьяно хотите вектор констант, то можете рассмотреть варианты оборачивания элементов в умные указатели:
std::vector<std::unique_ptr<const Type>> vec;
Тогда шаблонный тип, с которым инстанцируется вектор и аллокатор, будет неконстантным и ограничения влиять не будут. И вы можете любые операции с этим вектором делать: хоть сортировки, хоть вставку посередине.
В том числе для таких ситуаций в нашем коммьюнити находятся крутые специалисты. Когда написание постов поставлено на поток, то ошибки неизбежны. Да они и в принципе неизбежны, мы тоже люди и многого не знаем. Иногда еще и инструментарий подводит. И это замечательно, что у нас в канале есть люди, которые вдумчиво читают посты и могут дать адекватную критику по фактам. От этого выигрывают все: критики экологично повышают свою значимость с своих глазах и глазах подписчиков, а в коммьюнити не пропускается ошибочная информация.
Не бойтесь делать ошибки, они уменьшают объем вашего незнания.
Make mistakes. Stay cool.
#cppcore
{kind=link}
Результаты ревью
Круто вчера постарались, столько проблем нашли в этом маленьком кусочке кода. Больше всего проблем нашли два подписчика со скрина: я не смог выбрать из них одного, так как их пункты хоть и пересекаются, но все же дополняют друг друга различными мыслями. Давайте похлопаем нашим героям!👏👏👏👏👏👏
А теперь скомпануем все воедино. Напомню, что код был такой:
Сначала очевидное и то, что бросается в глаза. Все правильно поняли, что смысл кода - вывести элементы любого контейнера на выходной поток. Всвязи с этим следующие рассуждения:
❗️ Второй аргумент оператора принимается по значению, что ведет с излишним копированиям. Лучше использовать константную ссылку, так как мы не собираемся изменять значения контейнера.
❗️ В цикле тоже будут копирования, так как obj - объект, а не ссылка. Лучше использовать const auto &.
❗️ В первой строчке смешиваются class и typename. Это путает читателя, заставляя задумываться о тайном замысле использования разных ключевых слов. Лучше везде использовать class, так как Артем отметил , что до С++17 в шаблон-шаблонных параметрах нельзя было использовать typename.
❗️ Не очень выразительное название для аргумента, которым предполагается быть контейнеру. Хотя бы полностью написать Container.
❗️ Вывод элементов очень странный и кривой. Как минимум после последнего элемента будет ставиться пробел. Решить проблему можно с помощью стандартного алгоритма std::copy и интересного экспериментального итератора std::experimental::make_ostream_joiner, который может выводить элементы последовательности через разделитель, не записывая разделитель в конце! Выглядит это так:
На этом очевидные недостатки, которые мог выделить даже не очень разбирающийся в шаблонах читатель, заканчиваются.
Посмотрим чуть поглужбе. Функция используется для отладочных и учебных целей. Это понятно по использованию макроса PRETTY_FUNCTION. Он позволяет посмотреть полную сигнатуру функции с расшифровкой всех шаблонных параметров. Он довольно сильно помогает при обучении. Но к сожалению, этот макрос определен только под gcc/clang. Давайте уж не будем сильно внимание заострять на кроссплатформенности и целесообразности использования этой конструкции. В прод функция явно не пойдет. Д. А более интересные и кроссплатформенные варианты вывода сигнатуры функции можно посмотреть тут.
Однако автором этот кусок кода преподносился, как универсальный принт контейнеров STL. А вот тут уже залет! Потому что он не только не универсальный, но еще и не безопасный и корявый!.
🔞 Для класса std::string уже определен оператор вывода на поток, поэтому при наличии этого куска в общем коде мы просто не сможем выводить строку, так как компилятор найдет 2 подходящие перегрузки и не сможет из них выбрать лучшую. Можно ограничить тип контейнера с помощью sfinae/концептов.
🔞 Перегрузка не будет работать для мап. У них элементы - пары, которые не имеют собственной реализации вывода на поток. Да и вообще: если элементы "контейнера" не умеют выводиться на поток, то будет ошибка. Выход - поставить sfinae/концепт на существовании перегрузки на поток вывода для типа Т.
🔞 В предыдущем пункте я взял слово контейнер в кавычки. Все потому что сигнатура функции способна принимать любую шаблонную тварь, даже какой-нибудь std::shared_ptr. А для него уже перегружен оператор вывода. Опять компилятор не сможет выбрать из двух одинаковых перегрузок. Поэтому было бы неплохо поставить ограничение на существование методов begin() и end().
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
Fix your flaws. Stay cool.
#template #STL #cppcore #cpp17 #cpp20
Круто вчера постарались, столько проблем нашли в этом маленьком кусочке кода. Больше всего проблем нашли два подписчика со скрина: я не смог выбрать из них одного, так как их пункты хоть и пересекаются, но все же дополняют друг друга различными мыслями. Давайте похлопаем нашим героям!👏👏👏👏👏👏
А теперь скомпануем все воедино. Напомню, что код был такой:
template<typename T, template<class,class...> class C, class... Args>
std::ostream& operator <<(std::ostream& os, C<T,Args...>& objs)
{
os << PRETTY_FUNCTION << '\n';
for (auto obj : objs)
os << obj << ' ';
return os;
}
Сначала очевидное и то, что бросается в глаза. Все правильно поняли, что смысл кода - вывести элементы любого контейнера на выходной поток. Всвязи с этим следующие рассуждения:
❗️ Второй аргумент оператора принимается по значению, что ведет с излишним копированиям. Лучше использовать константную ссылку, так как мы не собираемся изменять значения контейнера.
❗️ В цикле тоже будут копирования, так как obj - объект, а не ссылка. Лучше использовать const auto &.
❗️ В первой строчке смешиваются class и typename. Это путает читателя, заставляя задумываться о тайном замысле использования разных ключевых слов. Лучше везде использовать class, так как Артем отметил , что до С++17 в шаблон-шаблонных параметрах нельзя было использовать typename.
❗️ Не очень выразительное название для аргумента, которым предполагается быть контейнеру. Хотя бы полностью написать Container.
❗️ Вывод элементов очень странный и кривой. Как минимум после последнего элемента будет ставиться пробел. Решить проблему можно с помощью стандартного алгоритма std::copy и интересного экспериментального итератора std::experimental::make_ostream_joiner, который может выводить элементы последовательности через разделитель, не записывая разделитель в конце! Выглядит это так:
std::copy(vec.begin(), vec.end(),
std::experimental::make_ostream_joiner(std::cout, ", "));
На этом очевидные недостатки, которые мог выделить даже не очень разбирающийся в шаблонах читатель, заканчиваются.
Посмотрим чуть поглужбе. Функция используется для отладочных и учебных целей. Это понятно по использованию макроса PRETTY_FUNCTION. Он позволяет посмотреть полную сигнатуру функции с расшифровкой всех шаблонных параметров. Он довольно сильно помогает при обучении. Но к сожалению, этот макрос определен только под gcc/clang. Давайте уж не будем сильно внимание заострять на кроссплатформенности и целесообразности использования этой конструкции. В прод функция явно не пойдет. Д. А более интересные и кроссплатформенные варианты вывода сигнатуры функции можно посмотреть тут.
Однако автором этот кусок кода преподносился, как универсальный принт контейнеров STL. А вот тут уже залет! Потому что он не только не универсальный, но еще и не безопасный и корявый!.
🔞 Для класса std::string уже определен оператор вывода на поток, поэтому при наличии этого куска в общем коде мы просто не сможем выводить строку, так как компилятор найдет 2 подходящие перегрузки и не сможет из них выбрать лучшую. Можно ограничить тип контейнера с помощью sfinae/концептов.
🔞 Перегрузка не будет работать для мап. У них элементы - пары, которые не имеют собственной реализации вывода на поток. Да и вообще: если элементы "контейнера" не умеют выводиться на поток, то будет ошибка. Выход - поставить sfinae/концепт на существовании перегрузки на поток вывода для типа Т.
🔞 В предыдущем пункте я взял слово контейнер в кавычки. Все потому что сигнатура функции способна принимать любую шаблонную тварь, даже какой-нибудь std::shared_ptr. А для него уже перегружен оператор вывода. Опять компилятор не сможет выбрать из двух одинаковых перегрузок. Поэтому было бы неплохо поставить ограничение на существование методов begin() и end().
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
Fix your flaws. Stay cool.
#template #STL #cppcore #cpp17 #cpp20
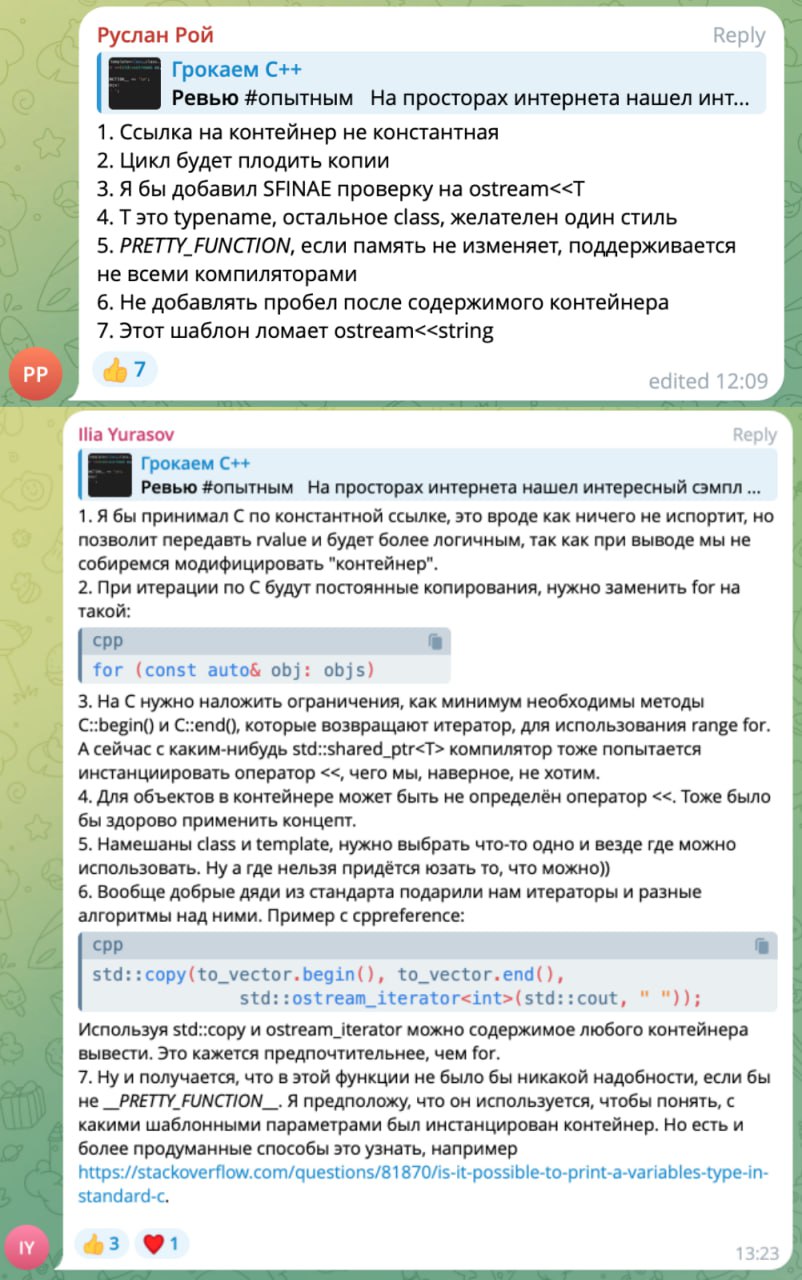{kind=link}