
Are Pre-trained Convolutions Better than Pre-trained Transformers?
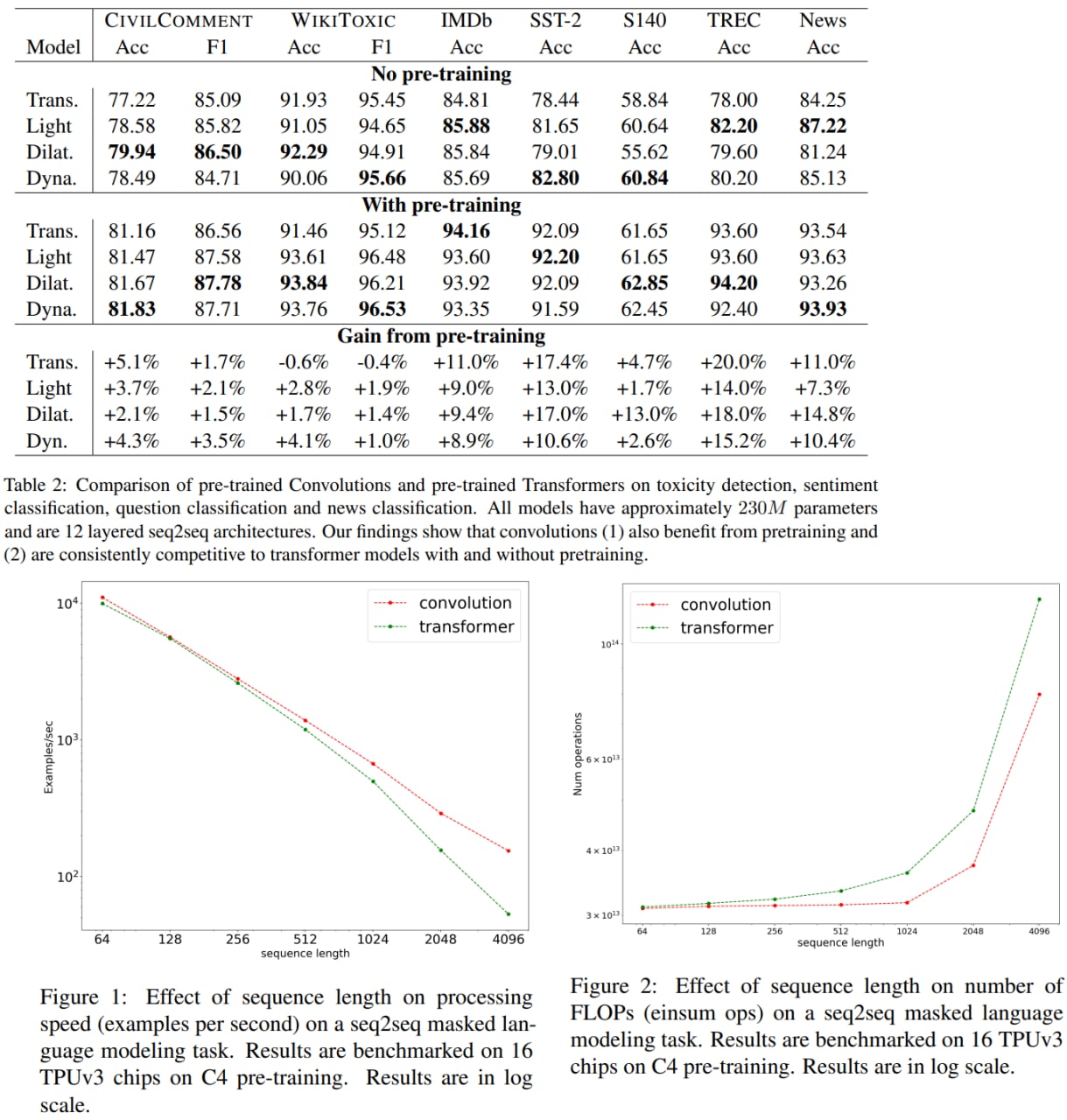
In this paper, the authors from Google Research wanted to investigate whether CNN architectures can be competitive compared to transformers on NLP problems. It turns out that pre-trained CNN models outperform pre-trained Transformers on some tasks; they also train faster and scale better to longer sequences.
Overall, the findings outlined in this paper suggest that conflating pre-training and architectural advances is misguided and that both advances should be considered independently. The authors believe their research paves the way for a healthy amount of optimism in alternative architectures.
Paper: https://arxiv.org/abs/2105.03322
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-cnnbettertransformers
#nlp #deeplearning #cnn #transformer #pretraining
In this paper, the authors from Google Research wanted to investigate whether CNN architectures can be competitive compared to transformers on NLP problems. It turns out that pre-trained CNN models outperform pre-trained Transformers on some tasks; they also train faster and scale better to longer sequences.
Overall, the findings outlined in this paper suggest that conflating pre-training and architectural advances is misguided and that both advances should be considered independently. The authors believe their research paves the way for a healthy amount of optimism in alternative architectures.
Paper: https://arxiv.org/abs/2105.03322
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-cnnbettertransformers
#nlp #deeplearning #cnn #transformer #pretraining
{kind=link}
ByT5: Towards a token-free future with pre-trained byte-to-byte models
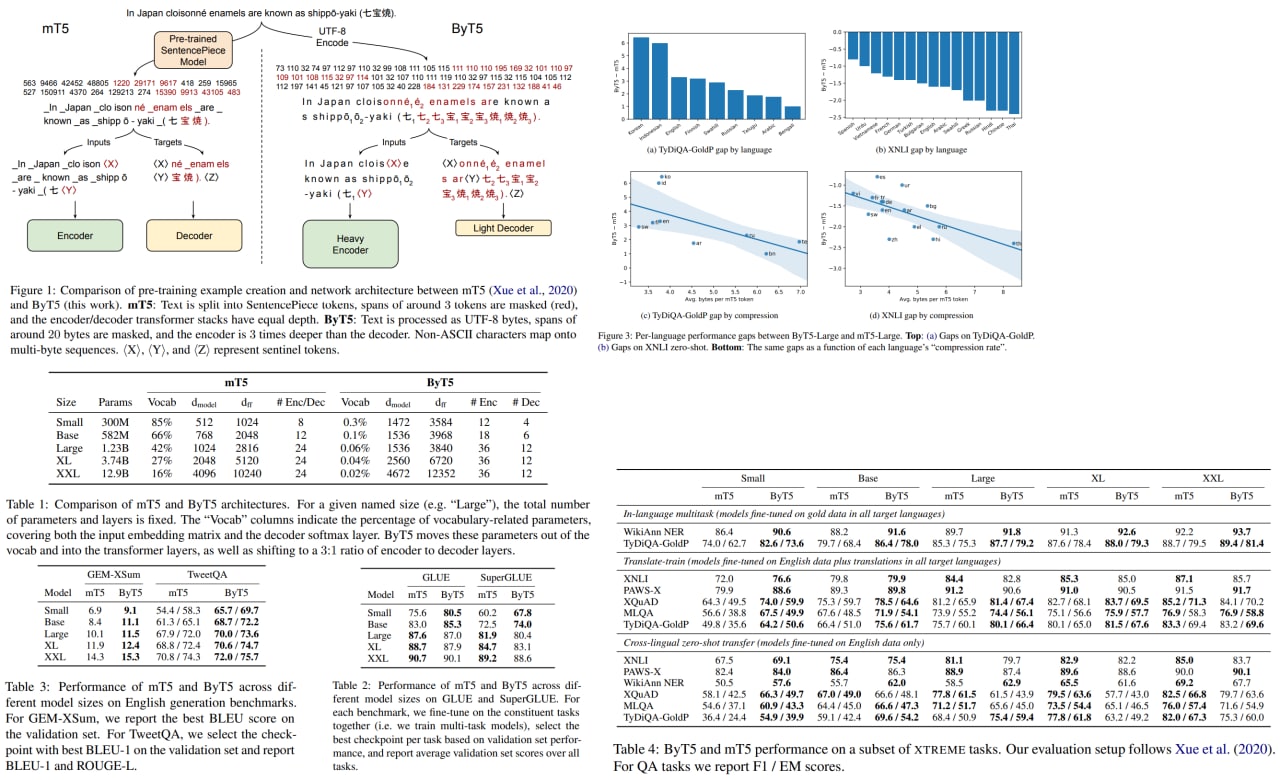
Pre-trained language models usually operate on the sequences of tokens, which are based on words or subword units.
Token-free models operate directly on the raw text (characters or bytes) instead. They can work with any language, are more robust to the noise, and don’t require preprocessing.
The authors use a modified mT5 architecture and show that their approach is competitive with token-level models.
Paper: https://arxiv.org/abs/2105.13626
Code: https://github.com/google-research/byt5
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-byt5
#nlp #deeplearning #transformer #pretraining
Pre-trained language models usually operate on the sequences of tokens, which are based on words or subword units.
Token-free models operate directly on the raw text (characters or bytes) instead. They can work with any language, are more robust to the noise, and don’t require preprocessing.
The authors use a modified mT5 architecture and show that their approach is competitive with token-level models.
Paper: https://arxiv.org/abs/2105.13626
Code: https://github.com/google-research/byt5
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-byt5
#nlp #deeplearning #transformer #pretraining
{kind=link}
CoAtNet: Marrying Convolution and Attention for All Data Sizes
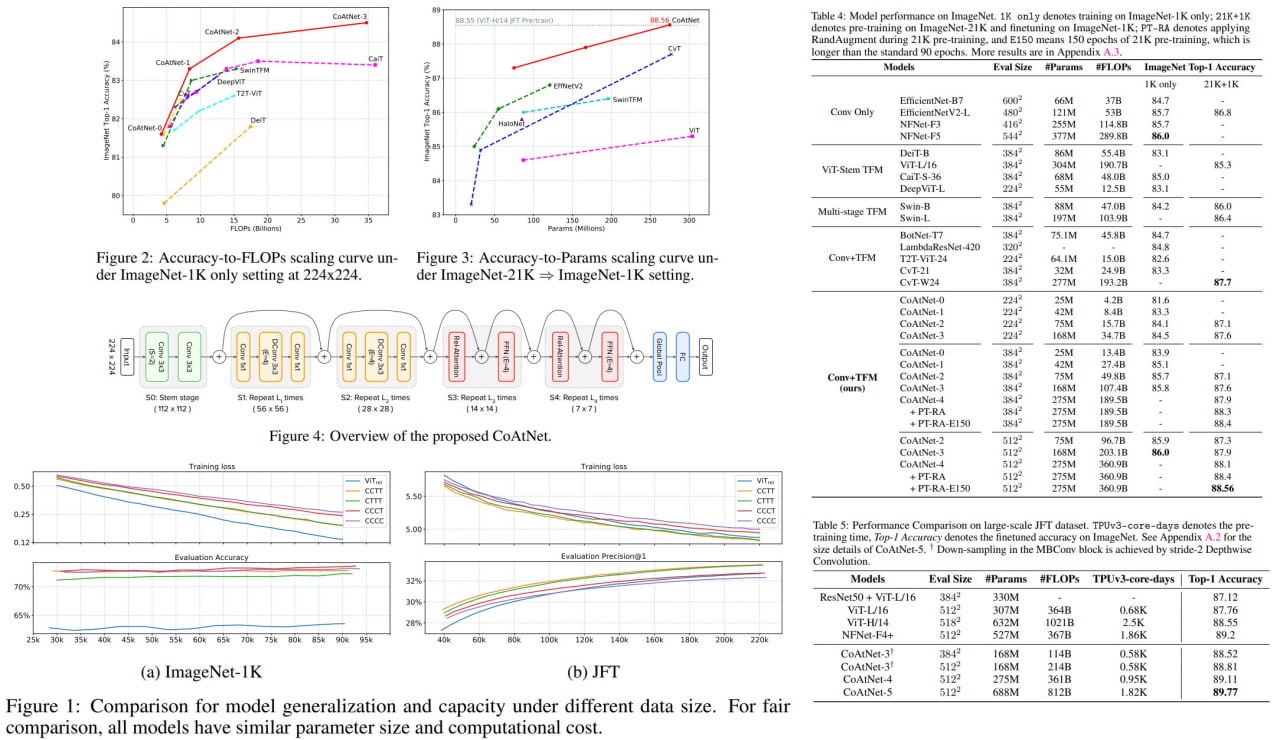
This is a paper on combining CNN and attention for Computer Vision tasks by Google Research.
The authors unify depthwise convolutions and self-attention via relative attention and vertically stack attention and convolutional layers in a specific way.
Resulting CoAtNets have good generalization, capacity and efficiency.
CoAtNet achieves 86.0% ImageNet top-1 accuracy without extra data and 89.77% with extra JFT data, outperforming the prior state of the art of both convolutional networks and Transformers. Notably, when pre-trained with 13M images from ImageNet-21K, CoAtNet achieves 88.56% top-1 accuracy, matching ViT-huge pre-trained with 300M images from JFT while using 23x less data.
Paper: https://arxiv.org/abs/2106.04803
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-coatnet
#cv #deeplearning #transformer #pretraining
This is a paper on combining CNN and attention for Computer Vision tasks by Google Research.
The authors unify depthwise convolutions and self-attention via relative attention and vertically stack attention and convolutional layers in a specific way.
Resulting CoAtNets have good generalization, capacity and efficiency.
CoAtNet achieves 86.0% ImageNet top-1 accuracy without extra data and 89.77% with extra JFT data, outperforming the prior state of the art of both convolutional networks and Transformers. Notably, when pre-trained with 13M images from ImageNet-21K, CoAtNet achieves 88.56% top-1 accuracy, matching ViT-huge pre-trained with 300M images from JFT while using 23x less data.
Paper: https://arxiv.org/abs/2106.04803
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-coatnet
#cv #deeplearning #transformer #pretraining
{kind=link}
Semi-Autoregressive Transformer for Image Captioning
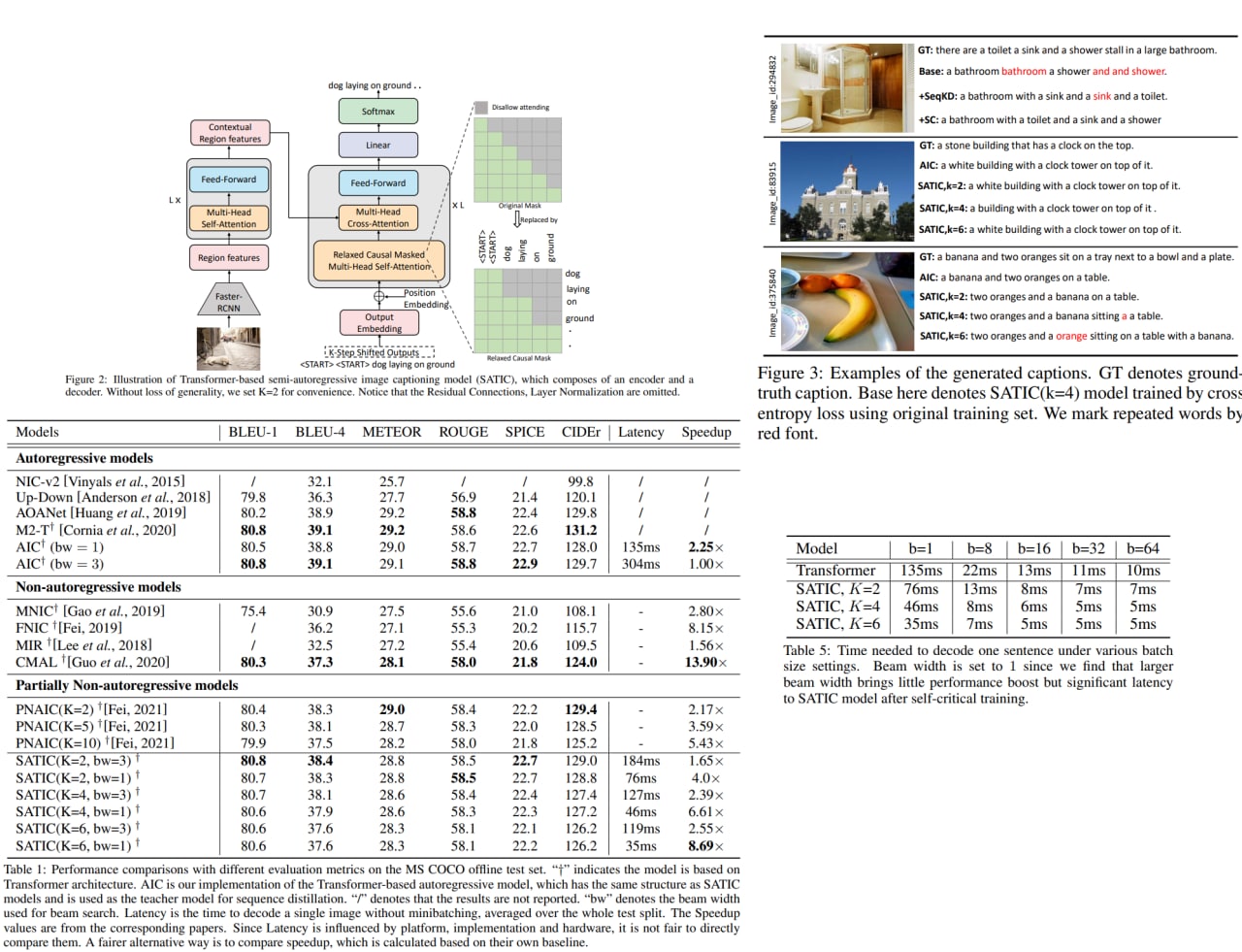
Current state-of-the-art image captioning models use autoregressive decoders - they generate one word after another, which leads to heavy latency during inference. Non-autoregressive models predict all the words in parallel; however, they suffer from quality degradation as they remove word dependence excessively.
The authors suggest a semi-autoregressive approach to image captioning to improve a trade-off between speed and quality: the model keeps the autoregressive property in global but generates words parallelly in local. Experiments on MSCOCO show that SATIC can achieve a better trade-off without bells and whistles.
Paper: https://arxiv.org/abs/2106.09436
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-satic
#imagecaptioning #deeplearning #transformer
Current state-of-the-art image captioning models use autoregressive decoders - they generate one word after another, which leads to heavy latency during inference. Non-autoregressive models predict all the words in parallel; however, they suffer from quality degradation as they remove word dependence excessively.
The authors suggest a semi-autoregressive approach to image captioning to improve a trade-off between speed and quality: the model keeps the autoregressive property in global but generates words parallelly in local. Experiments on MSCOCO show that SATIC can achieve a better trade-off without bells and whistles.
Paper: https://arxiv.org/abs/2106.09436
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-satic
#imagecaptioning #deeplearning #transformer
{kind=link}
Long-Short Transformer: Efficient Transformers for Language and Vision
This paper offers a new approach to solving the problem of quadratic time and memory complexities of self-attention in Transformers. The authors propose Long-Short Transformer (Transformer-LS), an efficient self-attention mechanism for modeling long sequences with linear complexity for both language and vision tasks. It aggregates a novel long-range attention with dynamic projection to model distant correlations and a short-term attention to capture fine-grained local correlations. A dual normalization is used to deal with the scale mismatch between the two attention mechanisms. Transformer-LS can be applied to both autoregressive and bidirectional models without additional complexity.
This method outperforms the state-of-the-art models on multiple tasks in language and vision domains. For instance, Transformer-LS achieves 0.97 test BPC on enwik8 using half the number of parameters than previous methods, while being faster and is able to handle 3× as long sequences. On ImageNet, it can obtain 84.1% Top-1 accuracy, while being more scalable on high-resolution images.
Paper: https://arxiv.org/abs/2107.02192
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-transformerls
#deeplearning #cv #nlp #transformer #attention
This paper offers a new approach to solving the problem of quadratic time and memory complexities of self-attention in Transformers. The authors propose Long-Short Transformer (Transformer-LS), an efficient self-attention mechanism for modeling long sequences with linear complexity for both language and vision tasks. It aggregates a novel long-range attention with dynamic projection to model distant correlations and a short-term attention to capture fine-grained local correlations. A dual normalization is used to deal with the scale mismatch between the two attention mechanisms. Transformer-LS can be applied to both autoregressive and bidirectional models without additional complexity.
This method outperforms the state-of-the-art models on multiple tasks in language and vision domains. For instance, Transformer-LS achieves 0.97 test BPC on enwik8 using half the number of parameters than previous methods, while being faster and is able to handle 3× as long sequences. On ImageNet, it can obtain 84.1% Top-1 accuracy, while being more scalable on high-resolution images.
Paper: https://arxiv.org/abs/2107.02192
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-transformerls
#deeplearning #cv #nlp #transformer #attention
{kind=link}
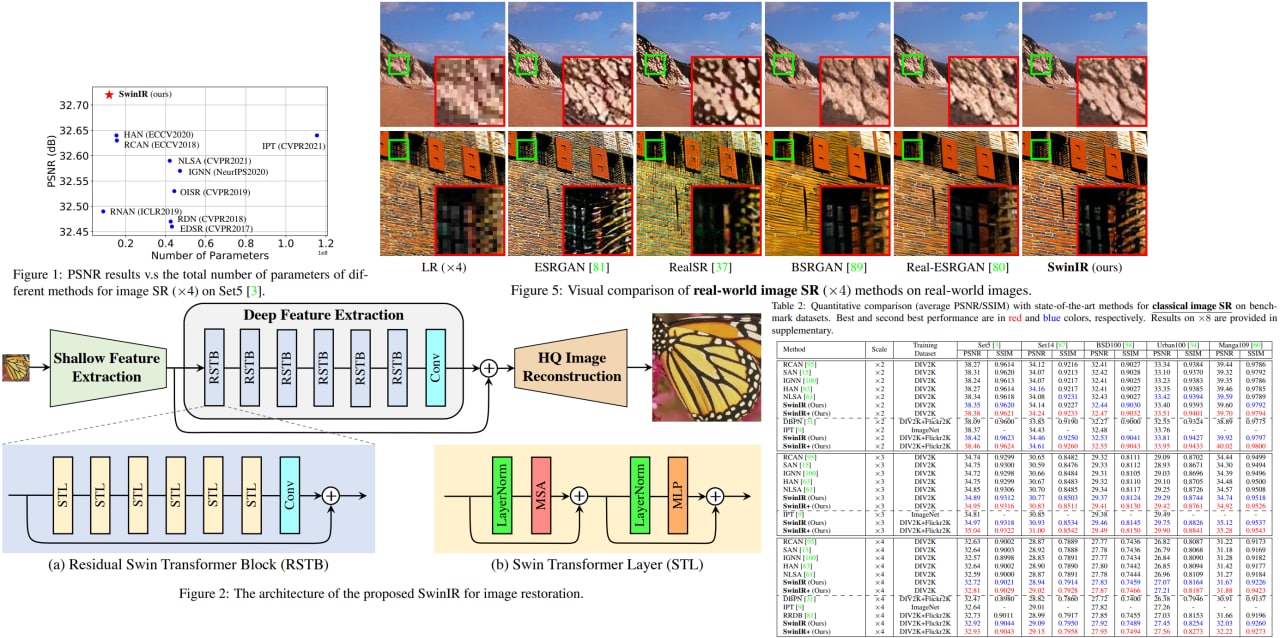
SwinIR: Image Restoration Using Swin Transformer
Image restoration is a long-standing low-level vision problem that aims to restore high-quality images from low-quality images (e.g., downscaled, noisy, and compressed images). While state-of-the-art image restoration methods are based on convolutional neural networks, few attempts have been made with Transformers, which show impressive performance on high-level vision tasks.
The authors use a model SwinIR based on the Swin Transformers. Experimental results demonstrate that SwinIR outperforms state-of-the-art methods on different tasks (image super-resolution, image denoising, and JPEG compression artifact reduction) by up to 0.14~0.45dB, while the total number of parameters can be reduced by up to 67%.
Paper: https://arxiv.org/abs/2108.10257
Code: https://github.com/JingyunLiang/SwinIR
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-swinir
#deeplearning #cv #transformer #superresolution #imagerestoration
Image restoration is a long-standing low-level vision problem that aims to restore high-quality images from low-quality images (e.g., downscaled, noisy, and compressed images). While state-of-the-art image restoration methods are based on convolutional neural networks, few attempts have been made with Transformers, which show impressive performance on high-level vision tasks.
The authors use a model SwinIR based on the Swin Transformers. Experimental results demonstrate that SwinIR outperforms state-of-the-art methods on different tasks (image super-resolution, image denoising, and JPEG compression artifact reduction) by up to 0.14~0.45dB, while the total number of parameters can be reduced by up to 67%.
Paper: https://arxiv.org/abs/2108.10257
Code: https://github.com/JingyunLiang/SwinIR
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-swinir
#deeplearning #cv #transformer #superresolution #imagerestoration
{kind=link}
It's All in the Heads: Using Attention Heads as a Baseline for Cross-Lingual Transfer in Commonsense Reasoning
Researchers from #Yandex have discovered that the reasoning capabilities of cross-lingual Transformers are concentrated in a small set of attention heads. A new multilingual dataset could encourage research on commonsense reasoning in Russian, French, Chinese and other languages.
Link: https://research.yandex.com/news/a-few-attention-heads-for-reasoning-in-multiple-languages
ArXiV: https://arxiv.org/abs/2106.12066
#transformer #nlu #nlp
Researchers from #Yandex have discovered that the reasoning capabilities of cross-lingual Transformers are concentrated in a small set of attention heads. A new multilingual dataset could encourage research on commonsense reasoning in Russian, French, Chinese and other languages.
Link: https://research.yandex.com/news/a-few-attention-heads-for-reasoning-in-multiple-languages
ArXiV: https://arxiv.org/abs/2106.12066
#transformer #nlu #nlp
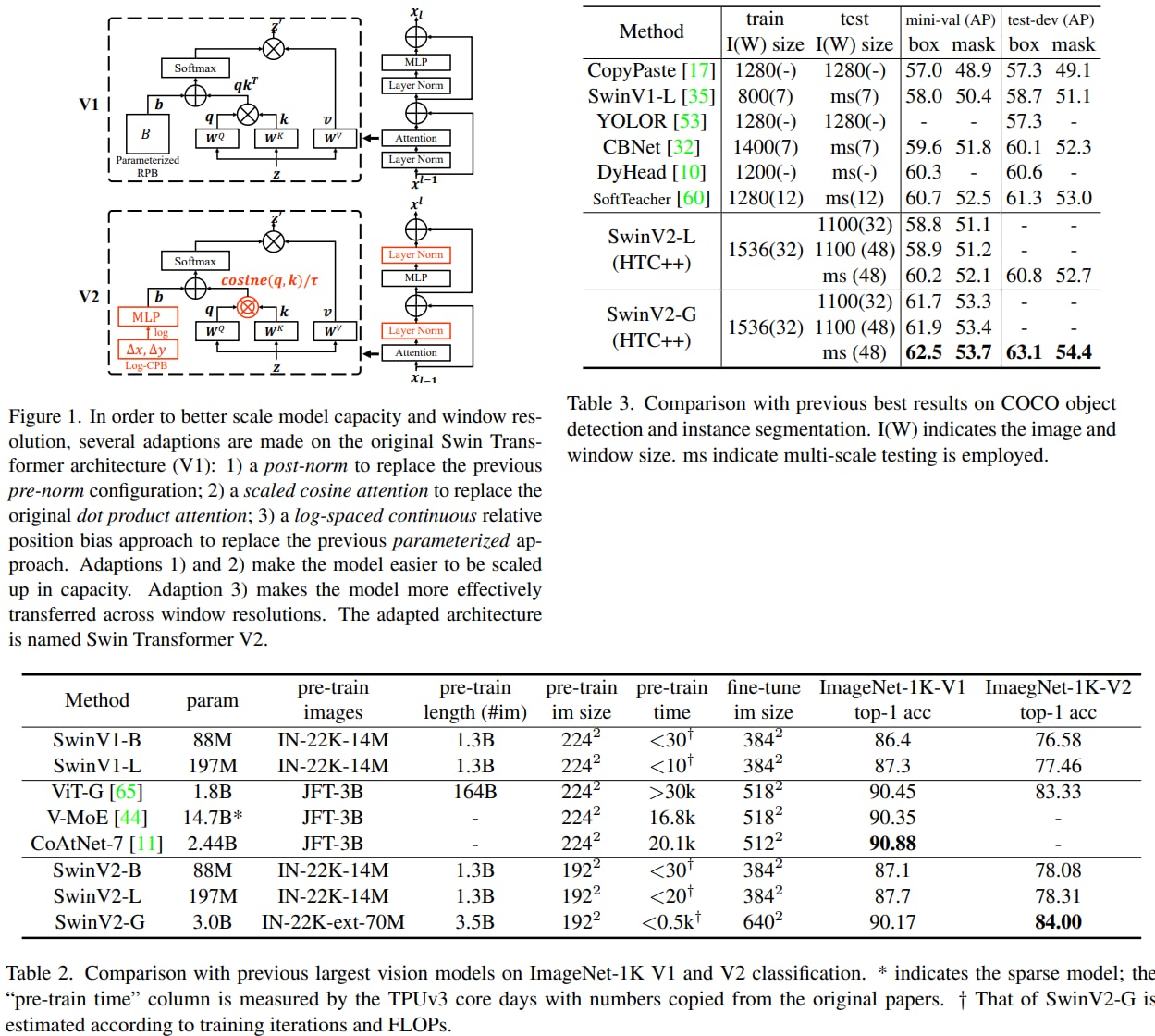
Swin Transformer V2: Scaling Up Capacity and Resolution
The authors present techniques for scaling Swin Transformer up to 3 billion parameters and making it capable of training with images of up to 1,536×1,536 resolution.
Vision models have the following difficulties when trying to scale them up: instability issues at scale, high GPU memory consumption for high-resolution images, and the fact that downstream tasks usually require high-resolution images/windows, while the models are pretrained on lower resolutions and the transfer isn't always efficient.
The authors introduce the following technics to circumvent those problems:
- a post normalization technique and a scaled cosine attention approach to improve the stability of large vision models;
- a log-spaced continuous position bias technique to effectively transfer models pre-trained at low-resolution images and windows to their higher-resolution counterparts;
In addition, they share how they were able to decrease GPU consumption significantly.
Swin Transformer V2 sets new records on four representative vision benchmarks: 84.0% top-1 accuracy on ImageNet-V2 image classification, 63.1 / 54.4 box / mask mAP on COCO object detection, 59.9 mIoU on ADE20K semantic segmentation, and 86.8% top-1 accuracy on Kinetics-400 video action classification.
Paper: https://arxiv.org/abs/2111.09883
Code: https://github.com/microsoft/Swin-Transformer
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-swin-v2
#deeplearning #cv #transformer
The authors present techniques for scaling Swin Transformer up to 3 billion parameters and making it capable of training with images of up to 1,536×1,536 resolution.
Vision models have the following difficulties when trying to scale them up: instability issues at scale, high GPU memory consumption for high-resolution images, and the fact that downstream tasks usually require high-resolution images/windows, while the models are pretrained on lower resolutions and the transfer isn't always efficient.
The authors introduce the following technics to circumvent those problems:
- a post normalization technique and a scaled cosine attention approach to improve the stability of large vision models;
- a log-spaced continuous position bias technique to effectively transfer models pre-trained at low-resolution images and windows to their higher-resolution counterparts;
In addition, they share how they were able to decrease GPU consumption significantly.
Swin Transformer V2 sets new records on four representative vision benchmarks: 84.0% top-1 accuracy on ImageNet-V2 image classification, 63.1 / 54.4 box / mask mAP on COCO object detection, 59.9 mIoU on ADE20K semantic segmentation, and 86.8% top-1 accuracy on Kinetics-400 video action classification.
Paper: https://arxiv.org/abs/2111.09883
Code: https://github.com/microsoft/Swin-Transformer
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-swin-v2
#deeplearning #cv #transformer
{kind=link}
NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion
In this paper, Microsoft Research Asia and Peking University researchers share a unified multimodal (texts, images, videos, sketches) pre-trained model called NÜWA that can generate new or manipulate existing visual data for various visual synthesis tasks. Furthermore, they have designed a 3D transformer encoder-decoder framework with a 3D Nearby Attention (3DNA) mechanism to consider the nature of the visual data and reduce the computational complexity.
NÜWA achieves state-of-the-art results on text-to-image generation, text-to-video generation, video prediction, and several other tasks and demonstrates good results on zero-shot text-guided image and video manipulation tasks.
Paper: https://arxiv.org/abs/2111.12417
Code: https://github.com/microsoft/NUWA
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-nuwa
#deeplearning #cv #transformer #pretraining
In this paper, Microsoft Research Asia and Peking University researchers share a unified multimodal (texts, images, videos, sketches) pre-trained model called NÜWA that can generate new or manipulate existing visual data for various visual synthesis tasks. Furthermore, they have designed a 3D transformer encoder-decoder framework with a 3D Nearby Attention (3DNA) mechanism to consider the nature of the visual data and reduce the computational complexity.
NÜWA achieves state-of-the-art results on text-to-image generation, text-to-video generation, video prediction, and several other tasks and demonstrates good results on zero-shot text-guided image and video manipulation tasks.
Paper: https://arxiv.org/abs/2111.12417
Code: https://github.com/microsoft/NUWA
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-nuwa
#deeplearning #cv #transformer #pretraining
{kind=link}
🦜 Hi!
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
GitHub
ultimate_posts/where_to_start at master · open-data-science/ultimate_posts
Ultimate posts for opendatascience telegram channel - open-data-science/ultimate_posts
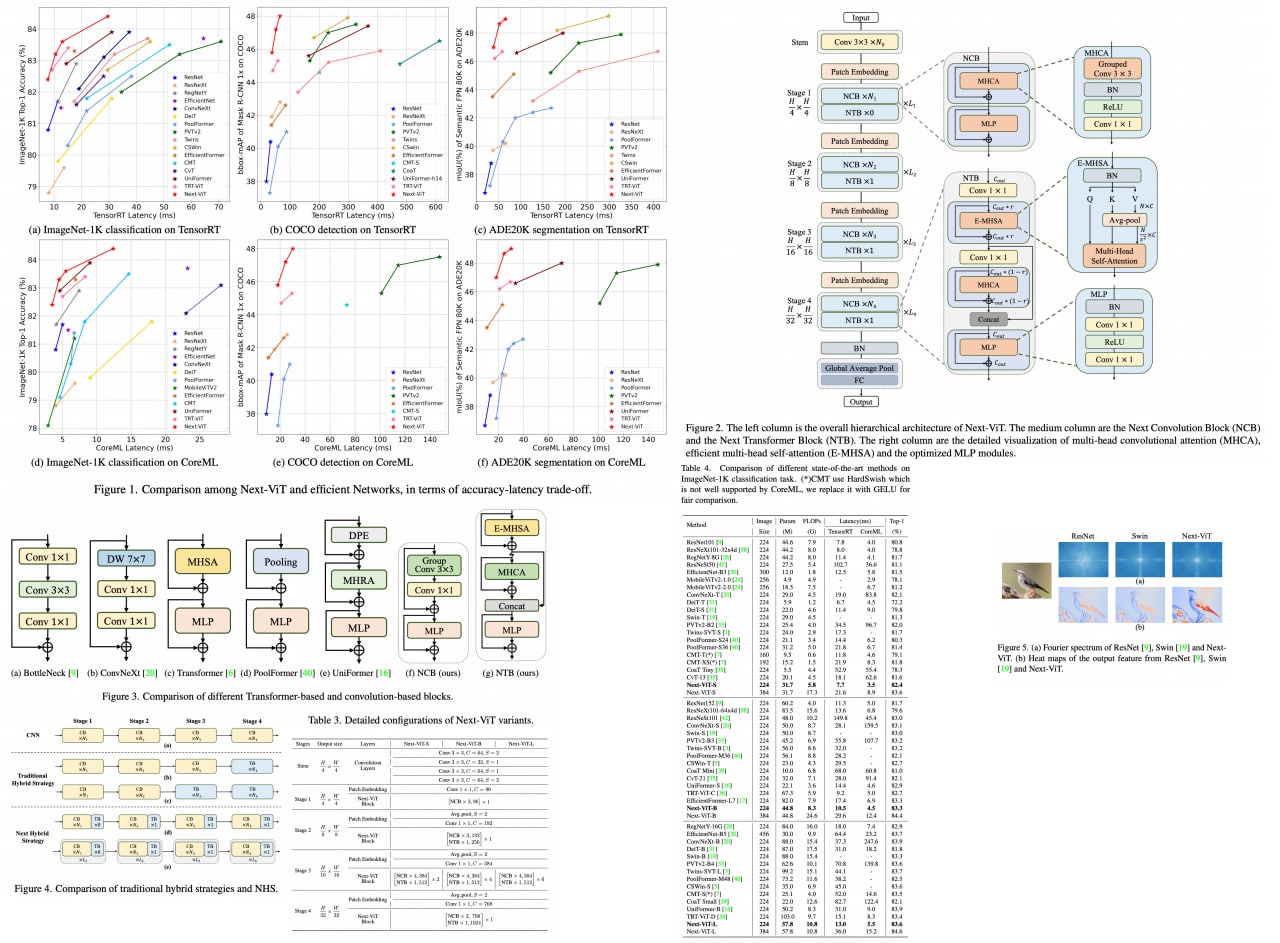
Next-ViT: Next Generation Vision Transformer for Efficient Deployment in Realistic Industrial Scenarios
While vision transformers demostrate high performance, they can't be deployed as efficiently as CNNs in realistic industrial deployment scenarios, e. g. TensorRT or CoreML.
The authors propose Next-ViT, which has a higher latency/accuracy trade-off than existing CNN and ViT models. They develop two new architecture blocks and a new paradigm to stack them. As a result, On TensorRT, Next-ViT surpasses ResNet by 5.4 mAP (from 40.4 to 45.8) on COCO detection and 8.2% mIoU (from 38.8% to 47.0%) on ADE20K segmentation. Also, it achieves comparable performance with CSWin, while the inference speed is accelerated by
3.6×. On CoreML, Next-ViT surpasses EfficientFormer by 4.6 mAP (from 42.6 to 47.2) on COCO detection and 3.5% mIoU (from 45.2% to 48.7%) on ADE20K segmentation under similar latency.
Paper: https://arxiv.org/abs/2207.05501
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-next-vit
#deeplearning #cv #transformer #computervision
While vision transformers demostrate high performance, they can't be deployed as efficiently as CNNs in realistic industrial deployment scenarios, e. g. TensorRT or CoreML.
The authors propose Next-ViT, which has a higher latency/accuracy trade-off than existing CNN and ViT models. They develop two new architecture blocks and a new paradigm to stack them. As a result, On TensorRT, Next-ViT surpasses ResNet by 5.4 mAP (from 40.4 to 45.8) on COCO detection and 8.2% mIoU (from 38.8% to 47.0%) on ADE20K segmentation. Also, it achieves comparable performance with CSWin, while the inference speed is accelerated by
3.6×. On CoreML, Next-ViT surpasses EfficientFormer by 4.6 mAP (from 42.6 to 47.2) on COCO detection and 3.5% mIoU (from 45.2% to 48.7%) on ADE20K segmentation under similar latency.
Paper: https://arxiv.org/abs/2207.05501
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-next-vit
#deeplearning #cv #transformer #computervision
{kind=link}
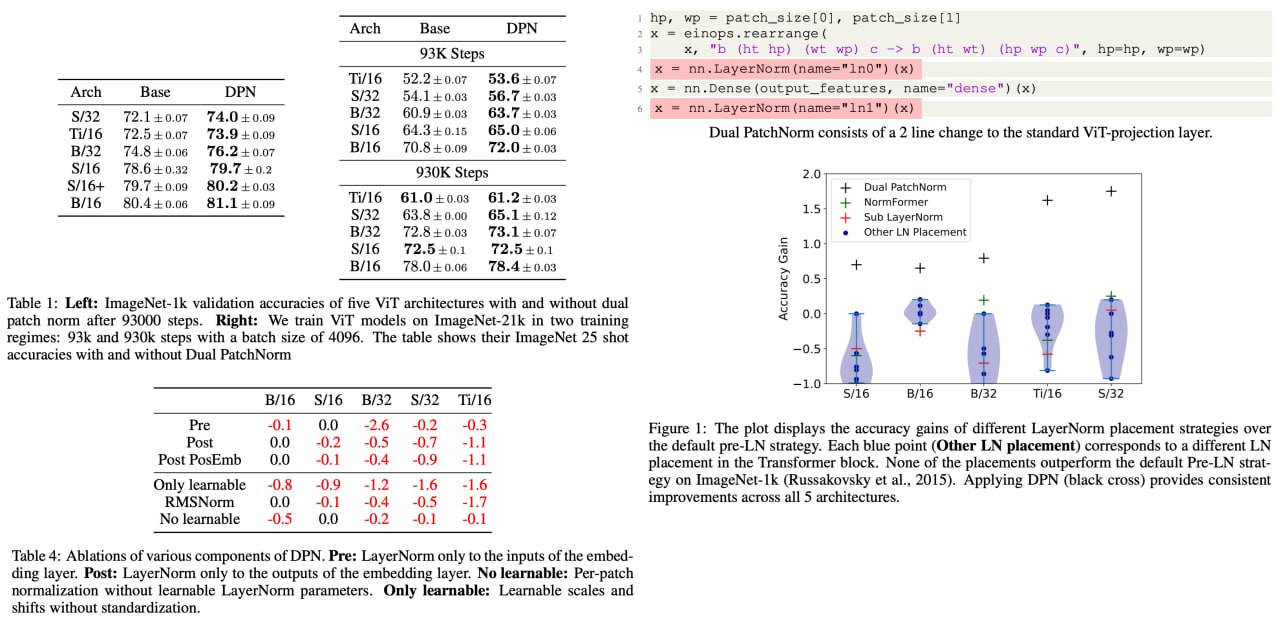
Dual PatchNorm
The authors propose a new method, Dual PatchNorm, for Vision Transformers which involves adding two Layer Normalization layers before and after the patch embedding layer. Experiments across three datasets show that this method improves the performance of well-tuned ViT models, and qualitative experiments support this.
Paper: https://arxiv.org/abs/2302.01327
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dual-patch-norm
#deeplearning #cv #transformer
The authors propose a new method, Dual PatchNorm, for Vision Transformers which involves adding two Layer Normalization layers before and after the patch embedding layer. Experiments across three datasets show that this method improves the performance of well-tuned ViT models, and qualitative experiments support this.
Paper: https://arxiv.org/abs/2302.01327
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dual-patch-norm
#deeplearning #cv #transformer
{kind=link}
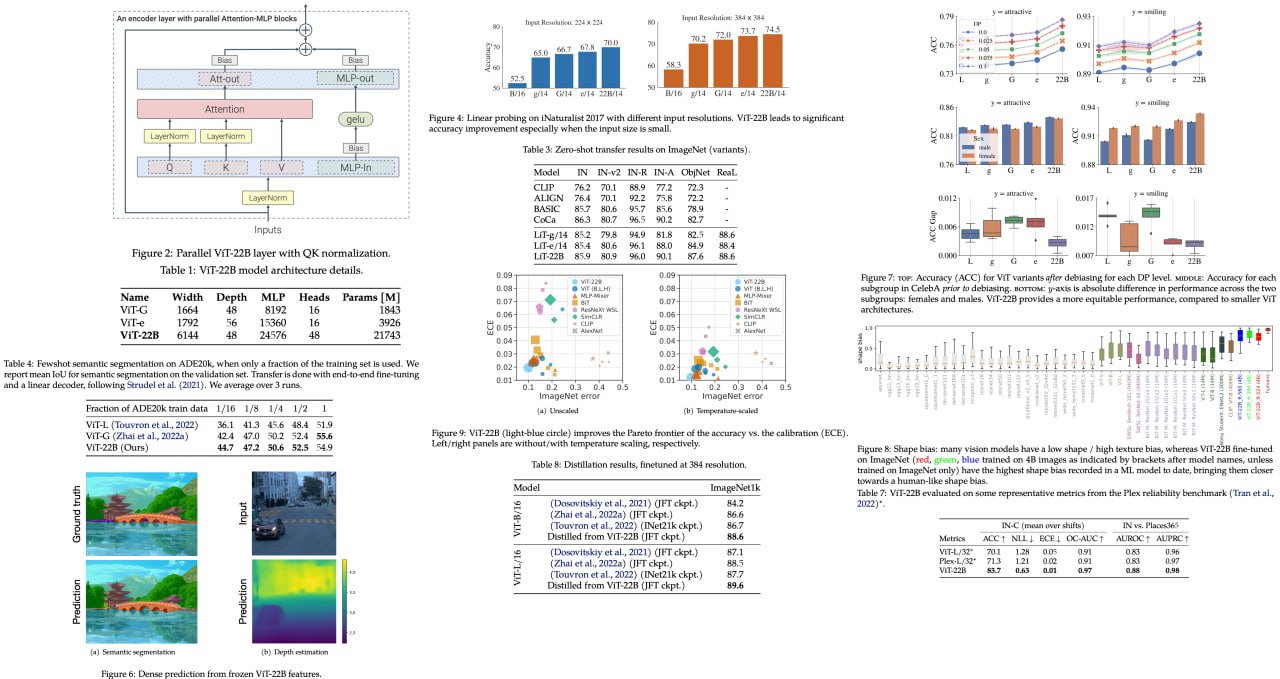
Scaling Vision Transformers to 22 Billion Parameters
Google Research authors present a recipe for training a highly efficient and stable Vision Transformer (ViT-22B) with 22B parameters, the largest dense ViT model to date. Experiments reveal that as the model's scale increases, its performance on downstream tasks improves. Additionally, ViT-22B shows an improved tradeoff between fairness and performance, state-of-the-art alignment with human visual perception in terms of shape/texture bias, and improved robustness. The authors suggest that ViT-22B demonstrates the potential for achieving “LLM-like” scaling in vision models and takes important steps toward that goal.
Paper: https://arxiv.org/abs/2302.05442
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-vit-22
#deeplearning #cv #transformer #sota
Google Research authors present a recipe for training a highly efficient and stable Vision Transformer (ViT-22B) with 22B parameters, the largest dense ViT model to date. Experiments reveal that as the model's scale increases, its performance on downstream tasks improves. Additionally, ViT-22B shows an improved tradeoff between fairness and performance, state-of-the-art alignment with human visual perception in terms of shape/texture bias, and improved robustness. The authors suggest that ViT-22B demonstrates the potential for achieving “LLM-like” scaling in vision models and takes important steps toward that goal.
Paper: https://arxiv.org/abs/2302.05442
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-vit-22
#deeplearning #cv #transformer #sota
{kind=link}
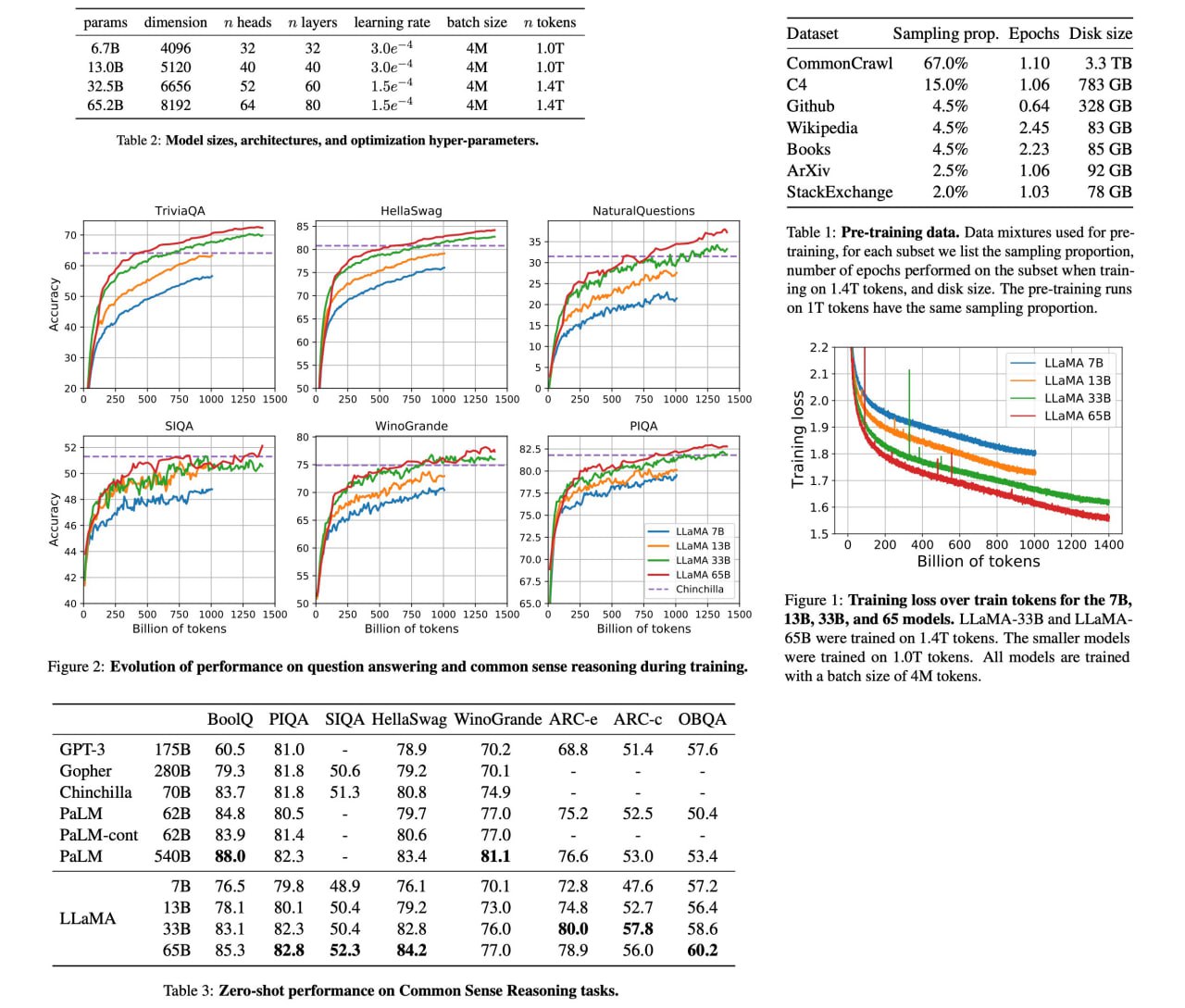
LLaMA: Open and Efficient Foundation Language Models
LLaMA is a set of large language models, ranging from 7B to 65B parameters, that have been trained on publicly available datasets containing trillions of tokens. The LLaMA-13B model performs better than GPT-3 (175B) on most benchmarks, and the LLaMA-65B model is competitive with other state-of-the-art models, such as Chinchilla70B and PaLM-540B. This suggests that it is possible to achieve excellent performance in language modeling without relying on proprietary or inaccessible datasets.
Paper: https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
Code: https://github.com/facebookresearch/llama
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-llama
#deeplearning #nlp #transformer #sota #languagemodel
LLaMA is a set of large language models, ranging from 7B to 65B parameters, that have been trained on publicly available datasets containing trillions of tokens. The LLaMA-13B model performs better than GPT-3 (175B) on most benchmarks, and the LLaMA-65B model is competitive with other state-of-the-art models, such as Chinchilla70B and PaLM-540B. This suggests that it is possible to achieve excellent performance in language modeling without relying on proprietary or inaccessible datasets.
Paper: https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
Code: https://github.com/facebookresearch/llama
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-llama
#deeplearning #nlp #transformer #sota #languagemodel
{kind=link}
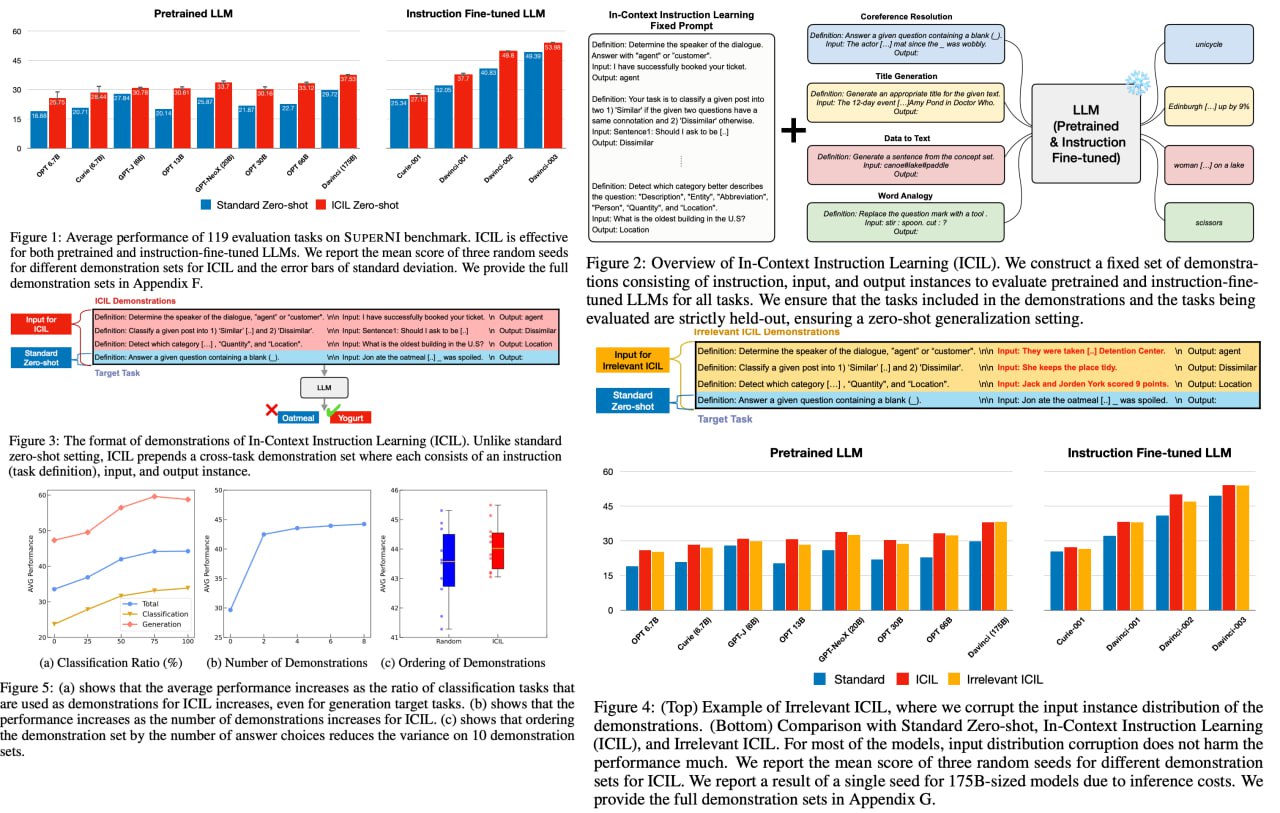
In-Context Instruction Learning
The authors introduce a novel approach called In-Context Instruction Learning (ICIL), which greatly enhances zero-shot task generalization performance for both pretrained and instruction-fine-tuned models. ICIL employs a single fixed prompt to evaluate all tasks, which is a concatenation of cross-task demonstrations. The authors demonstrate that even the most powerful instruction-fine-tuned baseline (text-davinci-003) benefits from ICIL by 9.3%, indicating that the effect of ICIL is complementary to instruction-based fine-tuning.
Paper: https://arxiv.org/abs/2302.14691
Code: https://github.com/seonghyeonye/ICIL
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-icil
#deeplearning #nlp #transformer #sota #languagemodel
The authors introduce a novel approach called In-Context Instruction Learning (ICIL), which greatly enhances zero-shot task generalization performance for both pretrained and instruction-fine-tuned models. ICIL employs a single fixed prompt to evaluate all tasks, which is a concatenation of cross-task demonstrations. The authors demonstrate that even the most powerful instruction-fine-tuned baseline (text-davinci-003) benefits from ICIL by 9.3%, indicating that the effect of ICIL is complementary to instruction-based fine-tuning.
Paper: https://arxiv.org/abs/2302.14691
Code: https://github.com/seonghyeonye/ICIL
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-icil
#deeplearning #nlp #transformer #sota #languagemodel
{kind=link}
PaLM-E: An Embodied Multimodal Language Model
In this paper, the authors introduce the concept of "embodied language models," which integrate real-world sensory information with language processing. This integration enables the models to perform tasks related to robotics and perception seamlessly.
To achieve this, the models are trained end-to-end using a large language model and multiple sensory inputs, including visual and textual information. These models can tackle complex tasks such as sequential robotic manipulation planning, visual question answering, and captioning. The results of evaluations demonstrate the effectiveness of this approach, including positive transfer across different domains.
The flagship model, PaLM-E-562B, is the crown jewel of this research. It excels in robotics tasks and delivers state-of-the-art performance on OK-VQA. Despite its specialization in robotics, this model maintains its generalist language capabilities.
Paper: https://arxiv.org/abs/2303.03378
Project link: https://palm-e.github.io/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-palme
#deeplearning #nlp #transformer #sota #languagemodel #robotics
In this paper, the authors introduce the concept of "embodied language models," which integrate real-world sensory information with language processing. This integration enables the models to perform tasks related to robotics and perception seamlessly.
To achieve this, the models are trained end-to-end using a large language model and multiple sensory inputs, including visual and textual information. These models can tackle complex tasks such as sequential robotic manipulation planning, visual question answering, and captioning. The results of evaluations demonstrate the effectiveness of this approach, including positive transfer across different domains.
The flagship model, PaLM-E-562B, is the crown jewel of this research. It excels in robotics tasks and delivers state-of-the-art performance on OK-VQA. Despite its specialization in robotics, this model maintains its generalist language capabilities.
Paper: https://arxiv.org/abs/2303.03378
Project link: https://palm-e.github.io/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-palme
#deeplearning #nlp #transformer #sota #languagemodel #robotics
{kind=link}
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
ChatGPT is a language interface with distinctive conversational competency and reasoning capabilities across many domains. However, it is currently unable to process or generate images from the visual world. To address this limitation, the authors propose a system called Visual ChatGPT that incorporates different Visual Foundation Models to enable users to interact with ChatGPT using both language and images. The system is capable of handling complex visual questions or instructions that require multiple AI models and steps. Additionally, it allows for feedback and corrections.
Rather than creating a new multimodal ChatGPT from scratch, the authors propose building Visual ChatGPT by incorporating various (22) Visual Foundation Models (VFMs) directly into ChatGPT. To facilitate the integration of these VFMs, the authors introduce a Prompt Manager that supports several functions. These include specifying the input-output formats of each VFM, converting visual information to language format, and managing the histories, priorities, and conflicts of different VFMs. With the Prompt Manager's help, ChatGPT can use these VFMs iteratively and receive their feedback until it satisfies the users' requirements or reaches the end condition.
Paper: https://arxiv.org/abs/2303.04671
Code link: https://github.com/microsoft/visual-chatgpt
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-palme
#deeplearning #nlp #transformer #sota #languagemodel #visual
ChatGPT is a language interface with distinctive conversational competency and reasoning capabilities across many domains. However, it is currently unable to process or generate images from the visual world. To address this limitation, the authors propose a system called Visual ChatGPT that incorporates different Visual Foundation Models to enable users to interact with ChatGPT using both language and images. The system is capable of handling complex visual questions or instructions that require multiple AI models and steps. Additionally, it allows for feedback and corrections.
Rather than creating a new multimodal ChatGPT from scratch, the authors propose building Visual ChatGPT by incorporating various (22) Visual Foundation Models (VFMs) directly into ChatGPT. To facilitate the integration of these VFMs, the authors introduce a Prompt Manager that supports several functions. These include specifying the input-output formats of each VFM, converting visual information to language format, and managing the histories, priorities, and conflicts of different VFMs. With the Prompt Manager's help, ChatGPT can use these VFMs iteratively and receive their feedback until it satisfies the users' requirements or reaches the end condition.
Paper: https://arxiv.org/abs/2303.04671
Code link: https://github.com/microsoft/visual-chatgpt
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-palme
#deeplearning #nlp #transformer #sota #languagemodel #visual
{kind=link}
BloombergGPT: A Large Language Model for Finance
The realm of financial technology involves a wide range of NLP applications, such as sentiment analysis, named entity recognition, and question answering. Although Large Language Models (LLMs) have demonstrated effectiveness in various tasks, no LLM specialized for the financial domain has been reported so far. This work introduces BloombergGPT, a 50-billion-parameter language model trained on an extensive range of financial data. The researchers have created a massive 363-billion-token dataset using Bloomberg's data sources, supplemented with 345 billion tokens from general-purpose datasets, potentially creating the largest domain-specific dataset to date.
BloombergGPT has been validated on standard LLM benchmarks, open financial benchmarks, and a suite of internal benchmarks that accurately reflect its intended usage. The mixed dataset training results in a model that significantly outperforms existing models on financial tasks without sacrificing performance on general LLM benchmarks. The paper also discusses modeling choices, training processes, and evaluation methodology. As a next step, the researchers plan to release training logs (Chronicles) detailing their experience in training BloombergGPT.
Paper: https://arxiv.org/abs/2303.17564
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-bloomberggpt
#deeplearning #nlp #transformer #sota #languagemodel #finance
The realm of financial technology involves a wide range of NLP applications, such as sentiment analysis, named entity recognition, and question answering. Although Large Language Models (LLMs) have demonstrated effectiveness in various tasks, no LLM specialized for the financial domain has been reported so far. This work introduces BloombergGPT, a 50-billion-parameter language model trained on an extensive range of financial data. The researchers have created a massive 363-billion-token dataset using Bloomberg's data sources, supplemented with 345 billion tokens from general-purpose datasets, potentially creating the largest domain-specific dataset to date.
BloombergGPT has been validated on standard LLM benchmarks, open financial benchmarks, and a suite of internal benchmarks that accurately reflect its intended usage. The mixed dataset training results in a model that significantly outperforms existing models on financial tasks without sacrificing performance on general LLM benchmarks. The paper also discusses modeling choices, training processes, and evaluation methodology. As a next step, the researchers plan to release training logs (Chronicles) detailing their experience in training BloombergGPT.
Paper: https://arxiv.org/abs/2303.17564
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-bloomberggpt
#deeplearning #nlp #transformer #sota #languagemodel #finance
{kind=link}
Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles
In the rapidly evolving landscape of artificial intelligence, a groundbreaking approach to supervised classification performance has been born. Modern hierarchical vision transformers have been known to incorporate various vision-specific components, aiming to enhance accuracies and produce desirable FLOP counts. However, these augmentations have led to slower processing times compared to their vanilla ViT counterparts. In this exciting research, we challenge the necessity of such additional complexities.
Enter Hiera, an innovative and significantly simplified hierarchical vision transformer that champions efficiency without compromising accuracy. By deploying a potent visual pretext task, MAE, we're able to eliminate the bells-and-whistles from a state-of-the-art multi-stage vision transformer. The result? A lean, mean machine learning model that not only outperforms its predecessors in terms of accuracy but also achieves superior speed, both during inference and training. Tested across a diverse array of image and video recognition tasks, Hiera stands as a beacon of progress in the field of computer vision.
Paper link: https://arxiv.org/abs/2306.00989
Code link: https://github.com/facebookresearch/hiera
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-hiera
#deeplearning #cv #transformer #sota
In the rapidly evolving landscape of artificial intelligence, a groundbreaking approach to supervised classification performance has been born. Modern hierarchical vision transformers have been known to incorporate various vision-specific components, aiming to enhance accuracies and produce desirable FLOP counts. However, these augmentations have led to slower processing times compared to their vanilla ViT counterparts. In this exciting research, we challenge the necessity of such additional complexities.
Enter Hiera, an innovative and significantly simplified hierarchical vision transformer that champions efficiency without compromising accuracy. By deploying a potent visual pretext task, MAE, we're able to eliminate the bells-and-whistles from a state-of-the-art multi-stage vision transformer. The result? A lean, mean machine learning model that not only outperforms its predecessors in terms of accuracy but also achieves superior speed, both during inference and training. Tested across a diverse array of image and video recognition tasks, Hiera stands as a beacon of progress in the field of computer vision.
Paper link: https://arxiv.org/abs/2306.00989
Code link: https://github.com/facebookresearch/hiera
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-hiera
#deeplearning #cv #transformer #sota
{kind=link}
Meta-Transformer: A Unified Framework for Multimodal Learning
The landscape of multimodal learning is about to witness a remarkable transformation with the introduction of Meta-Transformer, a state-of-the-art framework that's poised to overcome long-standing challenges in the field. The beauty of Meta-Transformer lies in its unique ability to process and understand information from a diverse range of modalities - from natural language, 2D images, 3D point clouds, to audio, video, time series, and tabular data. This ability stems from its innovative design that leverages a frozen encoder to map raw input data from these diverse modalities into a shared token space, eliminating the need for paired multimodal training data.
More than just a theoretical achievement, the Meta-Transformer has proven its practical application across various benchmarks, handling an impressive range of tasks from fundamental perception such as text, image, and audio processing, to more complex applications like X-Ray, infrared, and hyperspectral data interpretation, as well as data mining tasks involving graph, tabular, and time-series data.
Code link: https://github.com/invictus717/MetaTransformer
Paper link: https://arxiv.org/abs/2307.10802
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-meta-transformer
#deeplearning #nlp #transformer #cv
The landscape of multimodal learning is about to witness a remarkable transformation with the introduction of Meta-Transformer, a state-of-the-art framework that's poised to overcome long-standing challenges in the field. The beauty of Meta-Transformer lies in its unique ability to process and understand information from a diverse range of modalities - from natural language, 2D images, 3D point clouds, to audio, video, time series, and tabular data. This ability stems from its innovative design that leverages a frozen encoder to map raw input data from these diverse modalities into a shared token space, eliminating the need for paired multimodal training data.
More than just a theoretical achievement, the Meta-Transformer has proven its practical application across various benchmarks, handling an impressive range of tasks from fundamental perception such as text, image, and audio processing, to more complex applications like X-Ray, infrared, and hyperspectral data interpretation, as well as data mining tasks involving graph, tabular, and time-series data.
Code link: https://github.com/invictus717/MetaTransformer
Paper link: https://arxiv.org/abs/2307.10802
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-meta-transformer
#deeplearning #nlp #transformer #cv
{kind=link}