
Evaluating gambles using dynamics
Link: https://aip.scitation.org/doi/10.1063/1.4940236
#Statistics #Gambling
Link: https://aip.scitation.org/doi/10.1063/1.4940236
#Statistics #Gambling
AIP Publishing
Evaluating gambles using dynamics
Gambles are random variables that model possible changes in wealth. Classic decision theory transforms money into utility through a utility function and defines
Valuing Life as an Asset, as a Statistic and at Gunpoint
Ever wondered, how much your life is worth? This is an article about Life as an asset evaluation. It is extremely useful for insuarance companies and as a metric to calculate compensations in case of tragic events, but it is also a key to understand, how valuable (or not) life is.
Math is beautiful.
Link: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3156911
#math #life #insurance #statistics
Ever wondered, how much your life is worth? This is an article about Life as an asset evaluation. It is extremely useful for insuarance companies and as a metric to calculate compensations in case of tragic events, but it is also a key to understand, how valuable (or not) life is.
Math is beautiful.
Link: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3156911
#math #life #insurance #statistics
IQ is largely a pseudoscientific swindle
Note by Nassim Taleb on how IQ works. He shows that high-IQ is not well-correlated with wealth or overall cognitive performance.
Link: https://medium.com/incerto/iq-is-largely-a-pseudoscientific-swindle-f131c101ba39
#statistics #iq #fallacy
Note by Nassim Taleb on how IQ works. He shows that high-IQ is not well-correlated with wealth or overall cognitive performance.
Link: https://medium.com/incerto/iq-is-largely-a-pseudoscientific-swindle-f131c101ba39
#statistics #iq #fallacy
{kind=link}
{kind=link}
Fair Regression for Health Care Spending
What happens, if fairness built into the objective function for continuous outcomes & see large improvements in group undercompensation?
This is the most interesting & potentially impactful analysis of fairness in #ML for #healthcare, which can lead to significant improvement in the life of millions.
ArXiV: https://arxiv.org/abs/1901.10566
GitHub: https://github.com/zinka88/Fair-Regression
#statistics #regression
What happens, if fairness built into the objective function for continuous outcomes & see large improvements in group undercompensation?
This is the most interesting & potentially impactful analysis of fairness in #ML for #healthcare, which can lead to significant improvement in the life of millions.
ArXiV: https://arxiv.org/abs/1901.10566
GitHub: https://github.com/zinka88/Fair-Regression
#statistics #regression
{kind=link}
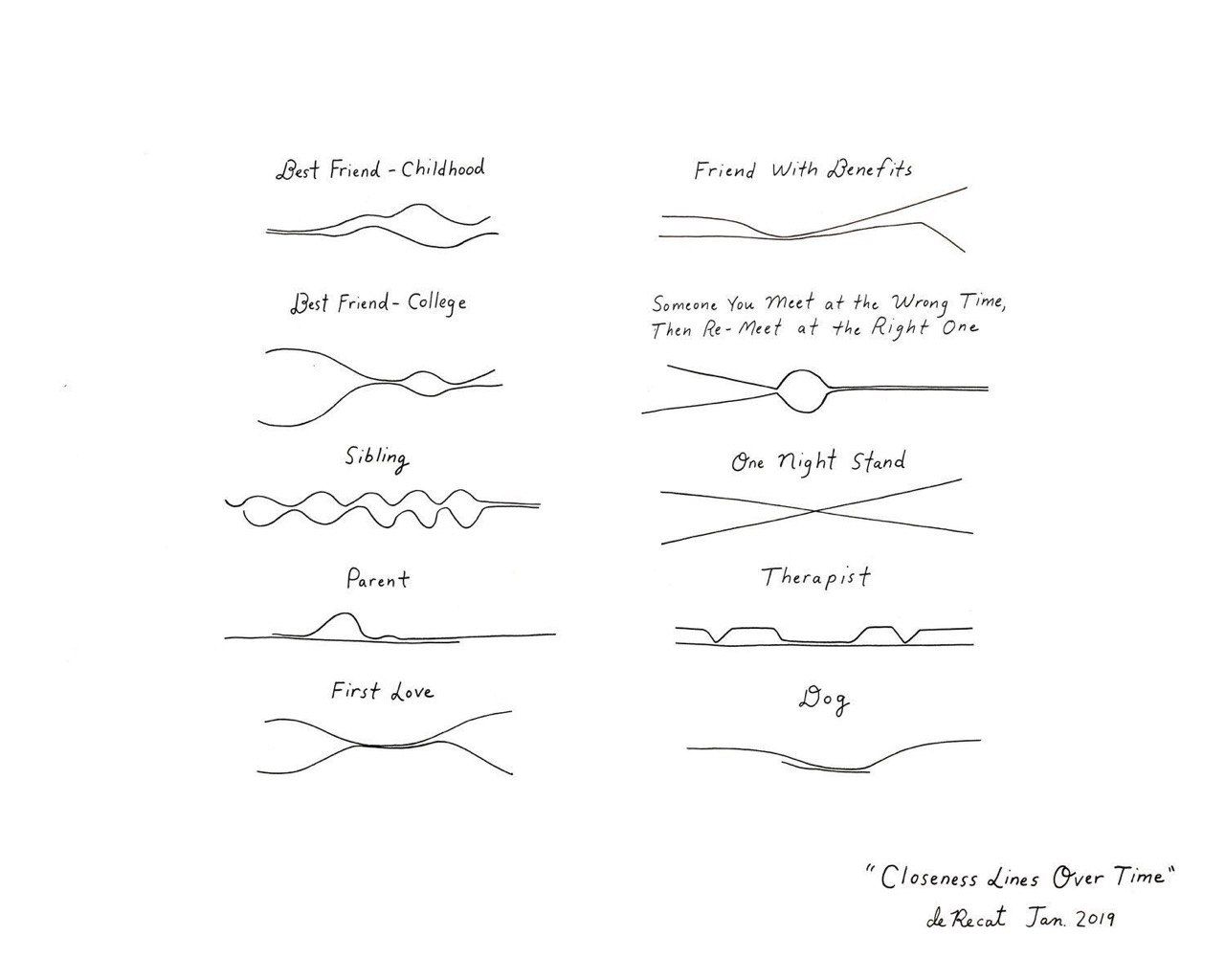
Why Financial Planning is Exciting… At Least for a Data Scientist
Great introduction into the finance world and what data scientist can lack diving into the topic.
Link: https://eng.uber.com/financial-planning-for-data-scientist/
#Financial #statistics #Uber
Great introduction into the finance world and what data scientist can lack diving into the topic.
Link: https://eng.uber.com/financial-planning-for-data-scientist/
#Financial #statistics #Uber
{kind=link}
Probabilistic foundations of econometrica: part 1
Great intro into #statistics basics.
Link: https://freakonometrics.hypotheses.org/57649
#beginner #novice #entrylevel
Great intro into #statistics basics.
Link: https://freakonometrics.hypotheses.org/57649
#beginner #novice #entrylevel
Freakonometrics
Probabilistic Foundations of Econometrics, part 1
In a series of posts, I wanted to get into details of the history and foundations of econometric and machine learning models. It will be some sort of online version of our joint paper with Emmanuel Flachaire and Antoine Ly, Econometrics and Machine Learning…
Analyzing Experiment Outcomes: Beyond Average Treatment Effects
Good #statistics article on why tail distribution and #experimentdesign matters. Quantile treatment effects (QTEs) helps to capture the inherent heterogeneity in treatment effects when riders and drivers interact within the #Uber marketplace.
Link: https://eng.uber.com/analyzing-experiment-outcomes/
Good #statistics article on why tail distribution and #experimentdesign matters. Quantile treatment effects (QTEs) helps to capture the inherent heterogeneity in treatment effects when riders and drivers interact within the #Uber marketplace.
Link: https://eng.uber.com/analyzing-experiment-outcomes/
Pseudo-extended Markov chain Monte Carlo
Pseudo-Extended #MC for easier sampling from multimodal posteriors. Extend the target distribution and then run your favourite sampler (f.e. #HMC).
ArXiV: https://arxiv.org/abs/1708.05239
#statistics
Pseudo-Extended #MC for easier sampling from multimodal posteriors. Extend the target distribution and then run your favourite sampler (f.e. #HMC).
ArXiV: https://arxiv.org/abs/1708.05239
#statistics
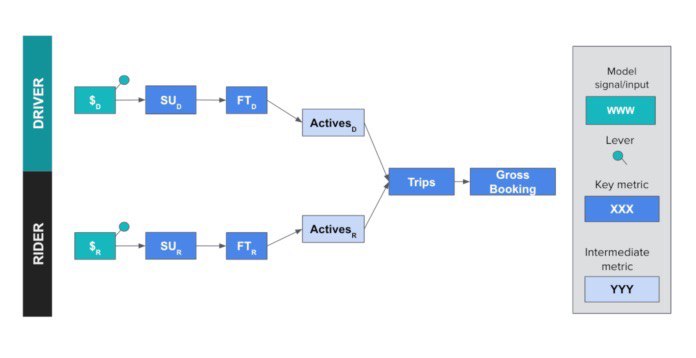
Important article in Nature about statistical significance
Scientists rise up against statistical significance — about motion to move from widely using and quoting statistical significance to confindence intervals.
Link: https://www.nature.com/articles/d41586-019-00857-9
#statistics #statsignificance #nature #science
Scientists rise up against statistical significance — about motion to move from widely using and quoting statistical significance to confindence intervals.
Link: https://www.nature.com/articles/d41586-019-00857-9
#statistics #statsignificance #nature #science
{kind=link}
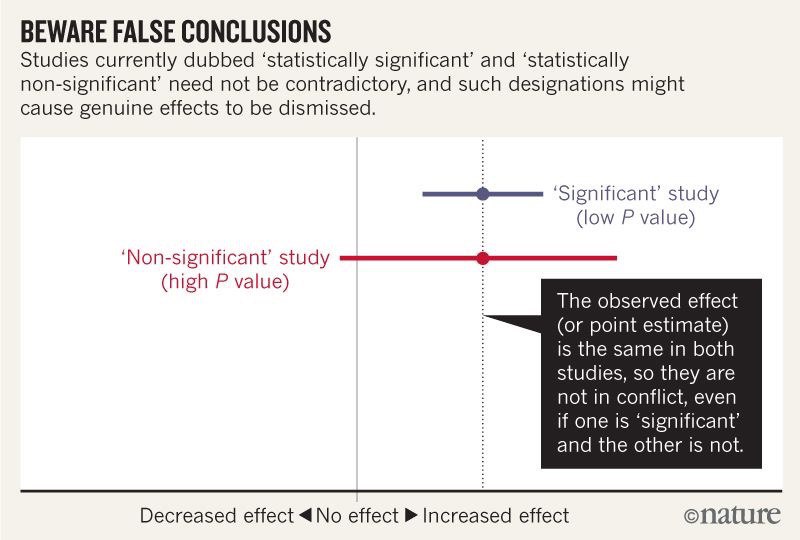
Ranking Items With Star Ratings and How Not To Sort By Average Rating
Two absolute must read articles for proper sorting handling. Sorting items with just an average score is wrong and there is some good classic statistics explanation why.
Link: https://www.evanmiller.org/ranking-items-with-star-ratings.html
Link2: https://www.evanmiller.org/how-not-to-sort-by-average-rating.html
#Statistics #rating #scoring #ranking
Two absolute must read articles for proper sorting handling. Sorting items with just an average score is wrong and there is some good classic statistics explanation why.
Link: https://www.evanmiller.org/ranking-items-with-star-ratings.html
Link2: https://www.evanmiller.org/how-not-to-sort-by-average-rating.html
#Statistics #rating #scoring #ranking
www.evanmiller.org
How Not To Sort By Average Rating
Users are rating items on your website. How do you know what the highest-rated items are?
The female problem: how male bias in medical trials ruined women's health
Intersting article on #bias in #medical trials and how proper #statistics training is still important.
Link: https://www.theguardian.com/lifeandstyle/2019/nov/13/the-female-problem-male-bias-in-medical-trials
Intersting article on #bias in #medical trials and how proper #statistics training is still important.
Link: https://www.theguardian.com/lifeandstyle/2019/nov/13/the-female-problem-male-bias-in-medical-trials
the Guardian
The female problem: how male bias in medical trials ruined women's health
Centuries of female exclusion has meant women’s diseases are often missed, misdiagnosed or remain a total mystery
📚Guest post on great example of book abandonment at GoodReads
An excellent new article from Gwern on analyzing abandoned (hard to finish, hard to read) books on Goodreads. This write up includes step by step instructions with source code, even the way he parsed the data from the website without an API.
It’s a shame analysis like this does not come from an online book subscription service like Bookmate or MyBook. They have vastly superior datasets and many able data scientists. I am quite sure amazon kindle team does prepare internal reports like that for some evil business purposes, but that’s a whole different story.
During my time at video game database company RAWG.io we’ve compiled ‘most abandoned’ and ‘most addictive’ reports for video games.
Do you make a popular service with valuable user behavior data? Funny data analysis reports are a good way to get some attention to your product. Take a lead from Pornhub, they are great at publicizing their data.
Link: https://www.gwern.net/GoodReads
Pornhub Insights: https://www.pornhub.com/insights/
—
This is a guest post by Samat Galimov, who writes about technology, programming and management in Russian on @ctodaily.
#DataAnalysis #GoodReads #statistics #greatstats #talkingnumbers
An excellent new article from Gwern on analyzing abandoned (hard to finish, hard to read) books on Goodreads. This write up includes step by step instructions with source code, even the way he parsed the data from the website without an API.
It’s a shame analysis like this does not come from an online book subscription service like Bookmate or MyBook. They have vastly superior datasets and many able data scientists. I am quite sure amazon kindle team does prepare internal reports like that for some evil business purposes, but that’s a whole different story.
During my time at video game database company RAWG.io we’ve compiled ‘most abandoned’ and ‘most addictive’ reports for video games.
Do you make a popular service with valuable user behavior data? Funny data analysis reports are a good way to get some attention to your product. Take a lead from Pornhub, they are great at publicizing their data.
Link: https://www.gwern.net/GoodReads
Pornhub Insights: https://www.pornhub.com/insights/
—
This is a guest post by Samat Galimov, who writes about technology, programming and management in Russian on @ctodaily.
#DataAnalysis #GoodReads #statistics #greatstats #talkingnumbers
gwern.net
The Most ‘Abandoned’ Books on GoodReads
<p>Which books on GoodReads are most difficult to finish? Estimating proportions in December 2019 gives an entirely different result than absolute counts.</p>
P-value, explained, one more time with demos
Article includes not only great explanation of what is #pvalue, but how it works and how it can be used to make a correct conclusions.
Link:https://www.freecodecamp.org/news/what-is-statistical-significance-p-value-defined-and-how-to-calculate-it/
#entrylevel #dsformanagers #tutorial #explained #interactive #statistics
Article includes not only great explanation of what is #pvalue, but how it works and how it can be used to make a correct conclusions.
Link:https://www.freecodecamp.org/news/what-is-statistical-significance-p-value-defined-and-how-to-calculate-it/
#entrylevel #dsformanagers #tutorial #explained #interactive #statistics
freeCodeCamp.org
What is Statistical Significance? P Value Defined and How to Calculate It
By Peter Gleeson P values are one of the most widely used concepts in statistical analysis. They are used by researchers, analysts and statisticians to draw insights from data and make informed decisions. Along with statistical significance, they are...
Tail risk of contagious diseases
Fresh N. Taleb’s and Pasquale Cirillo’s article on risks of fat tail distribution.
Article: https://www.nature.com/articles/s41567-020-0921-x
#statistics #fattail
Fresh N. Taleb’s and Pasquale Cirillo’s article on risks of fat tail distribution.
Article: https://www.nature.com/articles/s41567-020-0921-x
#statistics #fattail
Nature
Tail risk of contagious diseases
Nature Physics - This Perspective argues that an approach called extreme value theory is appropriate for understanding the so-called tail risk of epidemic outbreaks, in particular by demonstrating...
Overview of Open Source projects growth metrics
Quantative analytics of top starred repositories.
Link: https://medium.com/runacapital/open-source-growth-benchmarks-and-the-20-fastest-growing-oss-startups-d3556a669fe6
#opensource #analytics #statistics #growth
Quantative analytics of top starred repositories.
Link: https://medium.com/runacapital/open-source-growth-benchmarks-and-the-20-fastest-growing-oss-startups-d3556a669fe6
#opensource #analytics #statistics #growth
{kind=link}
Benford’s Law, DS and the 2020 Election
This law can be used for the very basic check on wether the data was artificially generated or not. It assumes that lower digits have higher probability of occuring.
And there can be nothing better for #reproducibleresearch concept promotion, than #openresearch on poll data, because it shows that those can and should be transparent and open.
With the help of the repo below anyone can check compliance of poll data results with the #BenfordsLaw on unofficial (or official if you are able to get that data).
KDnuggets tutorial: https://www.kdnuggets.com/2020/09/diy-election-fraud-analysis-benfords-law.html
Github repo with examples on unofficial US election data: https://github.com/cjph8914/2020_benfords
#statistics
This law can be used for the very basic check on wether the data was artificially generated or not. It assumes that lower digits have higher probability of occuring.
And there can be nothing better for #reproducibleresearch concept promotion, than #openresearch on poll data, because it shows that those can and should be transparent and open.
With the help of the repo below anyone can check compliance of poll data results with the #BenfordsLaw on unofficial (or official if you are able to get that data).
KDnuggets tutorial: https://www.kdnuggets.com/2020/09/diy-election-fraud-analysis-benfords-law.html
Github repo with examples on unofficial US election data: https://github.com/cjph8914/2020_benfords
#statistics
KDnuggets
DIY Election Fraud Analysis Using Benford's Law - KDnuggets
In this article, we will talk about a Do-It-Yourself approach towards election analysis and coming to a conclusion whether the elections were conducted fairly or not.
🔥Everything You Always Wanted To Know About GitHub (But Were Afraid To Ask)
ClickHouse team provided extensive statistics on GitHub, including but not limited to distribution of repositories by star count, top repositories by stars, affinity list, top labels etc.
All the data is available for download with instructions for ClickHouse import
Link: https://gh.clickhouse.tech/explorer/
#GitHub #ClickHouse #Yandex #statistics #EDA #engineerketing
ClickHouse team provided extensive statistics on GitHub, including but not limited to distribution of repositories by star count, top repositories by stars, affinity list, top labels etc.
All the data is available for download with instructions for ClickHouse import
Link: https://gh.clickhouse.tech/explorer/
#GitHub #ClickHouse #Yandex #statistics #EDA #engineerketing
🦜 Hi!
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
GitHub
ultimate_posts/where_to_start at master · open-data-science/ultimate_posts
Ultimate posts for opendatascience telegram channel - open-data-science/ultimate_posts