
REALM: Integrating Retrieval into Language Representation Models
by google research
A new paper from google with a novel approach for language model pre-training, which augments a language representation model with a knowledge retriever.
The idea is the following: we take a sentence or a piece of text and augment it with additional knowledge (pass original text and additional texts to the model).
An example:
The masked text is:
Knowledge retriever could add the following information to it:
blog post: https://ai.googleblog.com/2020/08/realm-integrating-retrieval-into.html
paper: https://arxiv.org/abs/2002.08909
github: https://github.com/google-research/language/tree/master/language/realm
#nlp #languagemodel #knowledgeretriever #icml2020
by google research
A new paper from google with a novel approach for language model pre-training, which augments a language representation model with a knowledge retriever.
The idea is the following: we take a sentence or a piece of text and augment it with additional knowledge (pass original text and additional texts to the model).
An example:
The masked text is:
We paid twenty __ at the Buckingham Palace gift shop.
Knowledge retriever could add the following information to it:
Buckingham Palace is the London residence of the British monarchy.The official currency of the United Kingdom is the Pound.blog post: https://ai.googleblog.com/2020/08/realm-integrating-retrieval-into.html
paper: https://arxiv.org/abs/2002.08909
github: https://github.com/google-research/language/tree/master/language/realm
#nlp #languagemodel #knowledgeretriever #icml2020
{kind=link}
LLaMA: Open and Efficient Foundation Language Models
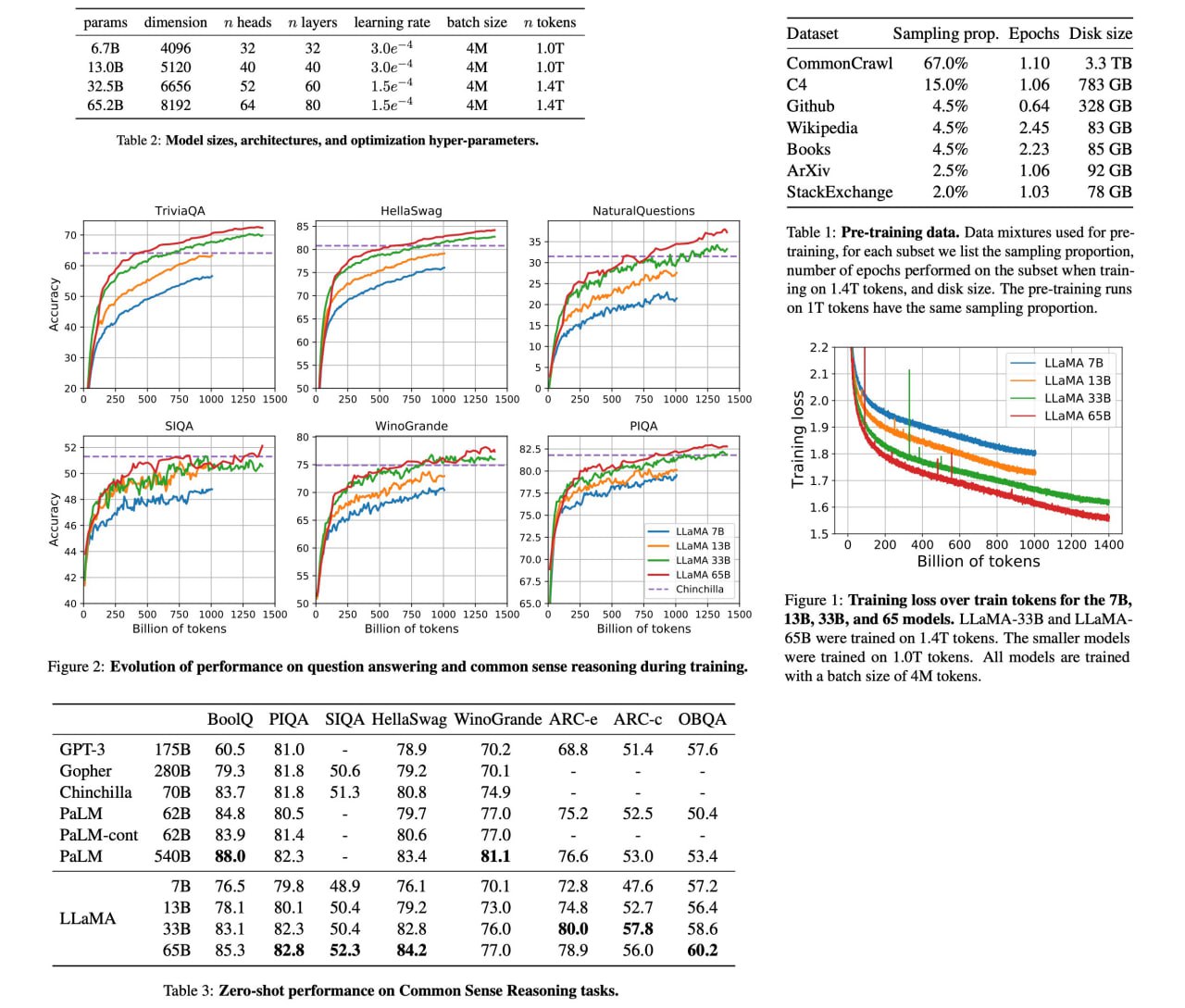
LLaMA is a set of large language models, ranging from 7B to 65B parameters, that have been trained on publicly available datasets containing trillions of tokens. The LLaMA-13B model performs better than GPT-3 (175B) on most benchmarks, and the LLaMA-65B model is competitive with other state-of-the-art models, such as Chinchilla70B and PaLM-540B. This suggests that it is possible to achieve excellent performance in language modeling without relying on proprietary or inaccessible datasets.
Paper: https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
Code: https://github.com/facebookresearch/llama
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-llama
#deeplearning #nlp #transformer #sota #languagemodel
LLaMA is a set of large language models, ranging from 7B to 65B parameters, that have been trained on publicly available datasets containing trillions of tokens. The LLaMA-13B model performs better than GPT-3 (175B) on most benchmarks, and the LLaMA-65B model is competitive with other state-of-the-art models, such as Chinchilla70B and PaLM-540B. This suggests that it is possible to achieve excellent performance in language modeling without relying on proprietary or inaccessible datasets.
Paper: https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
Code: https://github.com/facebookresearch/llama
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-llama
#deeplearning #nlp #transformer #sota #languagemodel
{kind=link}
In-Context Instruction Learning
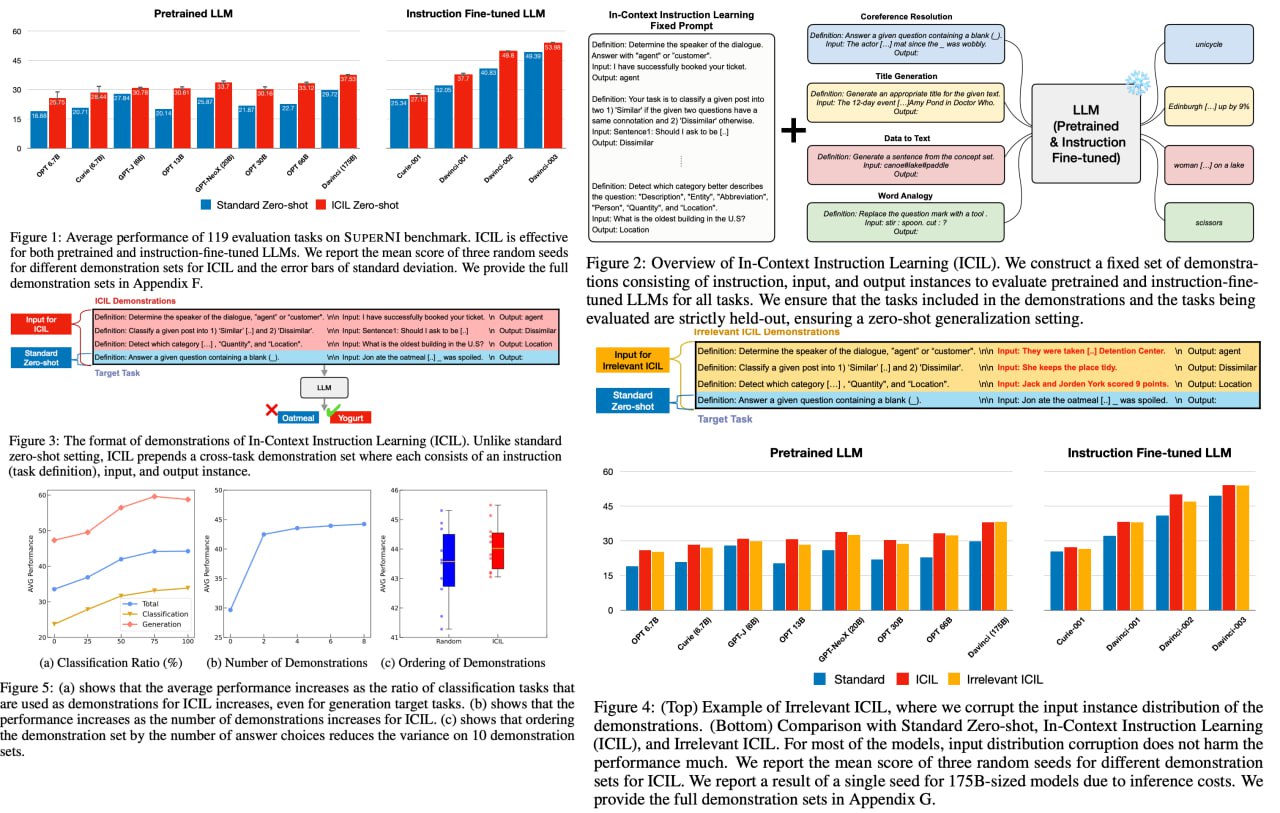
The authors introduce a novel approach called In-Context Instruction Learning (ICIL), which greatly enhances zero-shot task generalization performance for both pretrained and instruction-fine-tuned models. ICIL employs a single fixed prompt to evaluate all tasks, which is a concatenation of cross-task demonstrations. The authors demonstrate that even the most powerful instruction-fine-tuned baseline (text-davinci-003) benefits from ICIL by 9.3%, indicating that the effect of ICIL is complementary to instruction-based fine-tuning.
Paper: https://arxiv.org/abs/2302.14691
Code: https://github.com/seonghyeonye/ICIL
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-icil
#deeplearning #nlp #transformer #sota #languagemodel
The authors introduce a novel approach called In-Context Instruction Learning (ICIL), which greatly enhances zero-shot task generalization performance for both pretrained and instruction-fine-tuned models. ICIL employs a single fixed prompt to evaluate all tasks, which is a concatenation of cross-task demonstrations. The authors demonstrate that even the most powerful instruction-fine-tuned baseline (text-davinci-003) benefits from ICIL by 9.3%, indicating that the effect of ICIL is complementary to instruction-based fine-tuning.
Paper: https://arxiv.org/abs/2302.14691
Code: https://github.com/seonghyeonye/ICIL
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-icil
#deeplearning #nlp #transformer #sota #languagemodel
{kind=link}
PaLM-E: An Embodied Multimodal Language Model
In this paper, the authors introduce the concept of "embodied language models," which integrate real-world sensory information with language processing. This integration enables the models to perform tasks related to robotics and perception seamlessly.
To achieve this, the models are trained end-to-end using a large language model and multiple sensory inputs, including visual and textual information. These models can tackle complex tasks such as sequential robotic manipulation planning, visual question answering, and captioning. The results of evaluations demonstrate the effectiveness of this approach, including positive transfer across different domains.
The flagship model, PaLM-E-562B, is the crown jewel of this research. It excels in robotics tasks and delivers state-of-the-art performance on OK-VQA. Despite its specialization in robotics, this model maintains its generalist language capabilities.
Paper: https://arxiv.org/abs/2303.03378
Project link: https://palm-e.github.io/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-palme
#deeplearning #nlp #transformer #sota #languagemodel #robotics
In this paper, the authors introduce the concept of "embodied language models," which integrate real-world sensory information with language processing. This integration enables the models to perform tasks related to robotics and perception seamlessly.
To achieve this, the models are trained end-to-end using a large language model and multiple sensory inputs, including visual and textual information. These models can tackle complex tasks such as sequential robotic manipulation planning, visual question answering, and captioning. The results of evaluations demonstrate the effectiveness of this approach, including positive transfer across different domains.
The flagship model, PaLM-E-562B, is the crown jewel of this research. It excels in robotics tasks and delivers state-of-the-art performance on OK-VQA. Despite its specialization in robotics, this model maintains its generalist language capabilities.
Paper: https://arxiv.org/abs/2303.03378
Project link: https://palm-e.github.io/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-palme
#deeplearning #nlp #transformer #sota #languagemodel #robotics
{kind=link}
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models
ChatGPT is a language interface with distinctive conversational competency and reasoning capabilities across many domains. However, it is currently unable to process or generate images from the visual world. To address this limitation, the authors propose a system called Visual ChatGPT that incorporates different Visual Foundation Models to enable users to interact with ChatGPT using both language and images. The system is capable of handling complex visual questions or instructions that require multiple AI models and steps. Additionally, it allows for feedback and corrections.
Rather than creating a new multimodal ChatGPT from scratch, the authors propose building Visual ChatGPT by incorporating various (22) Visual Foundation Models (VFMs) directly into ChatGPT. To facilitate the integration of these VFMs, the authors introduce a Prompt Manager that supports several functions. These include specifying the input-output formats of each VFM, converting visual information to language format, and managing the histories, priorities, and conflicts of different VFMs. With the Prompt Manager's help, ChatGPT can use these VFMs iteratively and receive their feedback until it satisfies the users' requirements or reaches the end condition.
Paper: https://arxiv.org/abs/2303.04671
Code link: https://github.com/microsoft/visual-chatgpt
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-palme
#deeplearning #nlp #transformer #sota #languagemodel #visual
ChatGPT is a language interface with distinctive conversational competency and reasoning capabilities across many domains. However, it is currently unable to process or generate images from the visual world. To address this limitation, the authors propose a system called Visual ChatGPT that incorporates different Visual Foundation Models to enable users to interact with ChatGPT using both language and images. The system is capable of handling complex visual questions or instructions that require multiple AI models and steps. Additionally, it allows for feedback and corrections.
Rather than creating a new multimodal ChatGPT from scratch, the authors propose building Visual ChatGPT by incorporating various (22) Visual Foundation Models (VFMs) directly into ChatGPT. To facilitate the integration of these VFMs, the authors introduce a Prompt Manager that supports several functions. These include specifying the input-output formats of each VFM, converting visual information to language format, and managing the histories, priorities, and conflicts of different VFMs. With the Prompt Manager's help, ChatGPT can use these VFMs iteratively and receive their feedback until it satisfies the users' requirements or reaches the end condition.
Paper: https://arxiv.org/abs/2303.04671
Code link: https://github.com/microsoft/visual-chatgpt
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-palme
#deeplearning #nlp #transformer #sota #languagemodel #visual
{kind=link}
Hyena Hierarchy: Towards Larger Convolutional Language Models
Attention has been a cornerstone of deep learning, but it comes at a steep cost: quadratic expense in sequence length. This can limit the amount of context accessible, making it challenging for subquadratic methods like low-rank and sparse approximations to achieve comparable performance. That's where Hyena comes in!
Hyena is a revolutionary subquadratic drop-in replacement for attention that combines implicitly parametrized long convolutions and data-controlled gating. And the results speak for themselves! Hyena significantly improves accuracy in recall and reasoning tasks on long sequences, matching attention-based models.
In fact, Hyena sets a new state-of-the-art for dense-attention-free architectures in language modeling, reaching Transformer quality with 20% less training compute at sequence length 2K. And that's not all! Hyena operators are twice as fast as optimized attention at sequence length 8K and 100x faster at sequence length 64K.
Paper: https://arxiv.org/abs/2302.10866
Code link: https://github.com/HazyResearch/safari
Project link: https://hazyresearch.stanford.edu/blog/2023-03-07-hyena
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-hyena
#deeplearning #nlp #cv #languagemodel #convolution
Attention has been a cornerstone of deep learning, but it comes at a steep cost: quadratic expense in sequence length. This can limit the amount of context accessible, making it challenging for subquadratic methods like low-rank and sparse approximations to achieve comparable performance. That's where Hyena comes in!
Hyena is a revolutionary subquadratic drop-in replacement for attention that combines implicitly parametrized long convolutions and data-controlled gating. And the results speak for themselves! Hyena significantly improves accuracy in recall and reasoning tasks on long sequences, matching attention-based models.
In fact, Hyena sets a new state-of-the-art for dense-attention-free architectures in language modeling, reaching Transformer quality with 20% less training compute at sequence length 2K. And that's not all! Hyena operators are twice as fast as optimized attention at sequence length 8K and 100x faster at sequence length 64K.
Paper: https://arxiv.org/abs/2302.10866
Code link: https://github.com/HazyResearch/safari
Project link: https://hazyresearch.stanford.edu/blog/2023-03-07-hyena
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-hyena
#deeplearning #nlp #cv #languagemodel #convolution
{kind=link}
BloombergGPT: A Large Language Model for Finance
The realm of financial technology involves a wide range of NLP applications, such as sentiment analysis, named entity recognition, and question answering. Although Large Language Models (LLMs) have demonstrated effectiveness in various tasks, no LLM specialized for the financial domain has been reported so far. This work introduces BloombergGPT, a 50-billion-parameter language model trained on an extensive range of financial data. The researchers have created a massive 363-billion-token dataset using Bloomberg's data sources, supplemented with 345 billion tokens from general-purpose datasets, potentially creating the largest domain-specific dataset to date.
BloombergGPT has been validated on standard LLM benchmarks, open financial benchmarks, and a suite of internal benchmarks that accurately reflect its intended usage. The mixed dataset training results in a model that significantly outperforms existing models on financial tasks without sacrificing performance on general LLM benchmarks. The paper also discusses modeling choices, training processes, and evaluation methodology. As a next step, the researchers plan to release training logs (Chronicles) detailing their experience in training BloombergGPT.
Paper: https://arxiv.org/abs/2303.17564
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-bloomberggpt
#deeplearning #nlp #transformer #sota #languagemodel #finance
The realm of financial technology involves a wide range of NLP applications, such as sentiment analysis, named entity recognition, and question answering. Although Large Language Models (LLMs) have demonstrated effectiveness in various tasks, no LLM specialized for the financial domain has been reported so far. This work introduces BloombergGPT, a 50-billion-parameter language model trained on an extensive range of financial data. The researchers have created a massive 363-billion-token dataset using Bloomberg's data sources, supplemented with 345 billion tokens from general-purpose datasets, potentially creating the largest domain-specific dataset to date.
BloombergGPT has been validated on standard LLM benchmarks, open financial benchmarks, and a suite of internal benchmarks that accurately reflect its intended usage. The mixed dataset training results in a model that significantly outperforms existing models on financial tasks without sacrificing performance on general LLM benchmarks. The paper also discusses modeling choices, training processes, and evaluation methodology. As a next step, the researchers plan to release training logs (Chronicles) detailing their experience in training BloombergGPT.
Paper: https://arxiv.org/abs/2303.17564
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-bloomberggpt
#deeplearning #nlp #transformer #sota #languagemodel #finance
{kind=link}
Phoenix: Democratizing ChatGPT across Languages
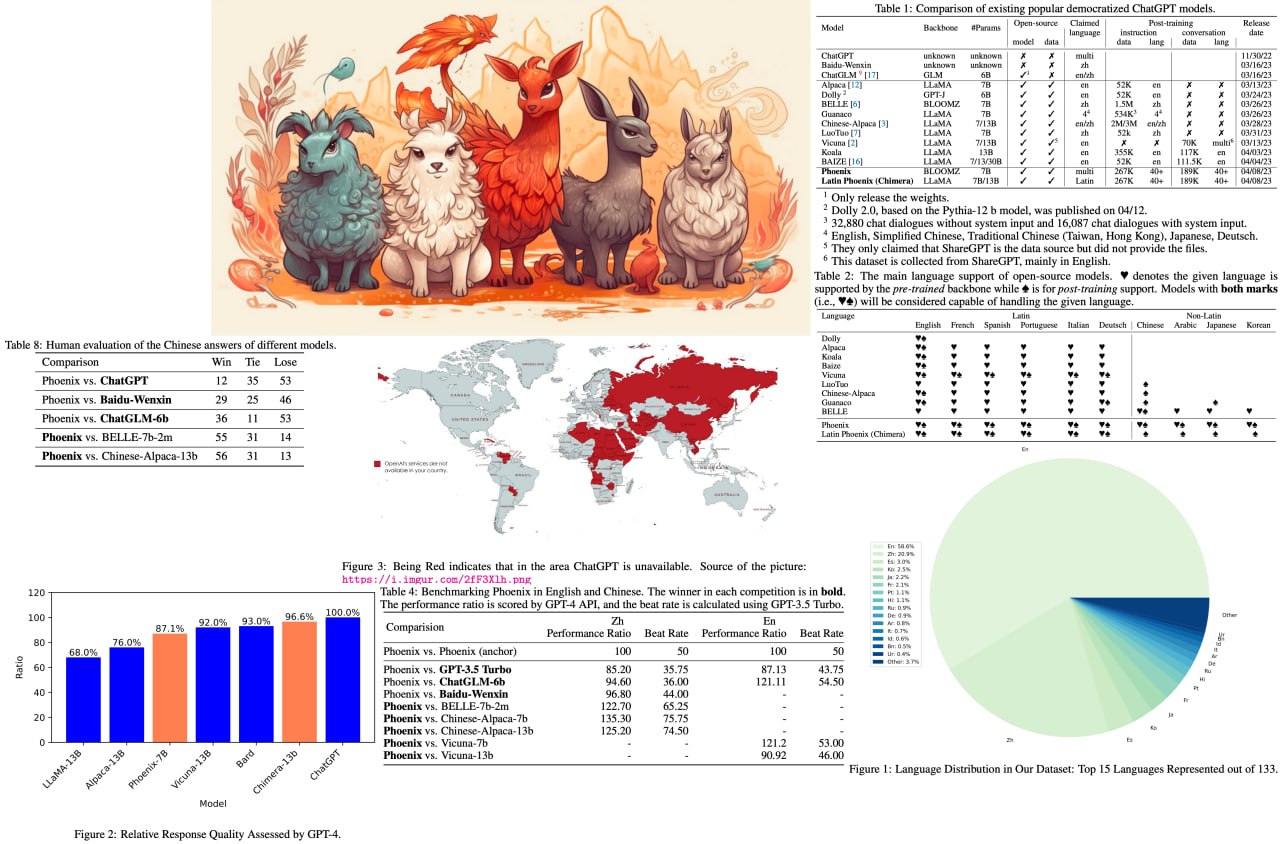
Introducing "Phoenix," a revolutionary multilingual ChatGPT that's breaking barriers in AI language models! By excelling in languages with limited resources and demonstrating competitive performance in English and Chinese models, Phoenix is set to transform accessibility for people around the world.
The methodology behind Phoenix combines instructions and conversations data to create a more well-rounded language model, leveraging the multi-lingual nature of the data to understand and interact with diverse languages.
Paper link: https://arxiv.org/abs/2304.10453
Code link: https://github.com/FreedomIntelligence/LLMZoo
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-phoenix-llm
#deeplearning #nlp #Phoenix #ChatGPT #multilingual #languagemodel
Introducing "Phoenix," a revolutionary multilingual ChatGPT that's breaking barriers in AI language models! By excelling in languages with limited resources and demonstrating competitive performance in English and Chinese models, Phoenix is set to transform accessibility for people around the world.
The methodology behind Phoenix combines instructions and conversations data to create a more well-rounded language model, leveraging the multi-lingual nature of the data to understand and interact with diverse languages.
Paper link: https://arxiv.org/abs/2304.10453
Code link: https://github.com/FreedomIntelligence/LLMZoo
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-phoenix-llm
#deeplearning #nlp #Phoenix #ChatGPT #multilingual #languagemodel
{kind=link}