
DensePose: Dense Human Pose Estimation In The Wild
Facebook AI Research group presented a paper on pose estimation. That will help Facebook with better understanding of the processed videos.
NEW: DensePose-COCO, a large-scale ground-truth dataset with image-to-surface correspondences manually annotated on 50K COCO images.
Project website: http://densepose.org/
Arxiv: https://arxiv.org/abs/1802.00434
#facebook #fair #cvpr #cv #CNN #dataset
Facebook AI Research group presented a paper on pose estimation. That will help Facebook with better understanding of the processed videos.
NEW: DensePose-COCO, a large-scale ground-truth dataset with image-to-surface correspondences manually annotated on 50K COCO images.
Project website: http://densepose.org/
Arxiv: https://arxiv.org/abs/1802.00434
#facebook #fair #cvpr #cv #CNN #dataset
arXiv.org
DensePose: Dense Human Pose Estimation In The Wild
In this work, we establish dense correspondences between RGB image and a surface-based representation of the human body, a task we refer to as dense human pose estimation. We first gather dense...
Face recognition is now available as a JS-package with the help of face-api.js. It is built on top of #Tensorflow (js version).
https://itnext.io/face-api-js-javascript-api-for-face-recognition-in-the-browser-with-tensorflow-js-bcc2a6c4cf07?gi=a277ad002e2a
#cv #js #tf #dl #cnn
https://itnext.io/face-api-js-javascript-api-for-face-recognition-in-the-browser-with-tensorflow-js-bcc2a6c4cf07?gi=a277ad002e2a
#cv #js #tf #dl #cnn
Medium
face-api.js — JavaScript API for Face Recognition in the Browser with tensorflow.js
A JavaScript API for Face Detection, Face Recognition and Face Landmark Detection
Faster R-CNN and Mask R-CNN in #PyTorch 1.0
Another release from #Facebook.
Mask R-CNN Benchmark: a fast and modular implementation for Faster R-CNN and Mask R-CNN written entirely in @PyTorch 1.0. It brings up to 30% speedup compared to mmdetection during training.
Webcam demo and ipynb file are available.
Github: https://github.com/facebookresearch/maskrcnn-benchmark
#CNN #CV #segmentation #detection
Another release from #Facebook.
Mask R-CNN Benchmark: a fast and modular implementation for Faster R-CNN and Mask R-CNN written entirely in @PyTorch 1.0. It brings up to 30% speedup compared to mmdetection during training.
Webcam demo and ipynb file are available.
Github: https://github.com/facebookresearch/maskrcnn-benchmark
#CNN #CV #segmentation #detection
GitHub
GitHub - facebookresearch/maskrcnn-benchmark: Fast, modular reference implementation of Instance Segmentation and Object Detection…
Fast, modular reference implementation of Instance Segmentation and Object Detection algorithms in PyTorch. - facebookresearch/maskrcnn-benchmark
How Many Samples are Needed to Learn a Convolutional Neural Network
Article questioning fact that CNNs use a more compact representation than the Fully-connected Neural Network (FNN) and thus require fewer training samples to accurately estimate their parameters.
ArXiV: https://arxiv.org/abs/1805.07883
#CNN #nn
Article questioning fact that CNNs use a more compact representation than the Fully-connected Neural Network (FNN) and thus require fewer training samples to accurately estimate their parameters.
ArXiV: https://arxiv.org/abs/1805.07883
#CNN #nn
Deep learning cheatsheets, covering content of Stanford’s CS 230 class.
CNN: https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-convolutional-neural-networks
RNN: https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-recurrent-neural-networks
TipsAndTricks: https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-deep-learning-tips-and-tricks
#cheatsheet #Stanford #dl #cnn #rnn #tipsntricks
CNN: https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-convolutional-neural-networks
RNN: https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-recurrent-neural-networks
TipsAndTricks: https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-deep-learning-tips-and-tricks
#cheatsheet #Stanford #dl #cnn #rnn #tipsntricks
stanford.edu
CS 230 - Convolutional Neural Networks Cheatsheet
Teaching page of Shervine Amidi, Graduate Student at Stanford University.
Understanding Convolutional Neural Networks through Visualizations in PyTorch
Explanation of how #CNN works
Link: https://towardsdatascience.com/understanding-convolutional-neural-networks-through-visualizations-in-pytorch-b5444de08b91
#PyTorch #nn #DL
Explanation of how #CNN works
Link: https://towardsdatascience.com/understanding-convolutional-neural-networks-through-visualizations-in-pytorch-b5444de08b91
#PyTorch #nn #DL
Towards Data Science
Understanding Convolutional Neural Networks through Visualizations in PyTorch
Getting down to the nitty-gritty of CNNs
{kind=link}
"Approximating CNNs with Bag-of-local-Features models works surprisingly well on ImageNet"
A "bag of words" of nets on tiny 17x17 patches suffice to reach AlexNet-level performance on ImageNet. A lot of the information is very local.
Paper: https://openreview.net/forum?id=SkfMWhAqYQ
#fun #CNN #CV #ImageNet
A "bag of words" of nets on tiny 17x17 patches suffice to reach AlexNet-level performance on ImageNet. A lot of the information is very local.
Paper: https://openreview.net/forum?id=SkfMWhAqYQ
#fun #CNN #CV #ImageNet
OpenReview
Approximating CNNs with Bag-of-local-Features models works...
Aggregating class evidence from many small image patches suffices to solve ImageNet, yields more interpretable models and can explain aspects of the decision-making of popular DNNs.
DGC-Net: Dense Geometric Correspondence network
Paper addresses the challenge of dense pixel correspondence estimation between two images. Practically, this means that it is about comparing different views of one object, which is very important to make #CV more robust.
ArXiV: https://arxiv.org/abs/1810.08393
Github: https://github.com/AaltoVision/DGC-Net
YouTube: https://www.youtube.com/watch?v=xnQMEr4FbHE
Project page: https://aaltovision.github.io/dgc-net-site/
#CNN #DL
Paper addresses the challenge of dense pixel correspondence estimation between two images. Practically, this means that it is about comparing different views of one object, which is very important to make #CV more robust.
ArXiV: https://arxiv.org/abs/1810.08393
Github: https://github.com/AaltoVision/DGC-Net
YouTube: https://www.youtube.com/watch?v=xnQMEr4FbHE
Project page: https://aaltovision.github.io/dgc-net-site/
#CNN #DL
arXiv.org
DGC-Net: Dense Geometric Correspondence Network
This paper addresses the challenge of dense pixel correspondence estimation
between two images. This problem is closely related to optical flow estimation
task where ConvNets (CNNs) have recently...
between two images. This problem is closely related to optical flow estimation
task where ConvNets (CNNs) have recently...
How to hide from the AI surveillance state with a color printout
MIT’s team studied how to fool camera with and #adversarial print, exploiting the fact that #CNN can be tricked by adversarial examples into recognizing something wrong or not recongnizing image at all.
Link: https://www.technologyreview.com/f/613409/how-to-hide-from-the-ai-surveillance-state-with-a-color-printout/
#CV #DL #MIT
MIT’s team studied how to fool camera with and #adversarial print, exploiting the fact that #CNN can be tricked by adversarial examples into recognizing something wrong or not recongnizing image at all.
Link: https://www.technologyreview.com/f/613409/how-to-hide-from-the-ai-surveillance-state-with-a-color-printout/
#CV #DL #MIT
MIT Technology Review
How to hide from the AI surveillance state with a color printout
AI-powered video technology is becoming ubiquitous, tracking our faces and bodies through stores, offices, and public spaces. In some countries the technology constitutes a powerful new layer of policing and government surveillance. Fortunately, as some researchers…
Using ‘radioactive data’ to detect if a data set was used for training
The authors have developed a new technique to mark the images in a data set so that researchers can determine whether a particular machine learning model has been trained using those images. This can help researchers and engineers to keep track of which data set was used to train a model so they can better understand how various data sets affect the performance of different neural networks.
The key points:
- the marks are harmless and have no impact on the classification accuracy of models, but are detectable with high confidence in a neural network;
- the image features are moved in a particular direction (the carrier) that has been sampled randomly and independently of the data
- after a model is trained on such data, its classifier will align with the direction of the carrier
- the method works in such a way that it is difficult to detect whether a data set is radioactive and to remove the marks from the trained model.
blogpost: https://ai.facebook.com/blog/using-radioactive-data-to-detect-if-a-data-set-was-used-for-training/
paper: https://arxiv.org/abs/2002.00937
#cv #cnn #datavalidation #image #data
The authors have developed a new technique to mark the images in a data set so that researchers can determine whether a particular machine learning model has been trained using those images. This can help researchers and engineers to keep track of which data set was used to train a model so they can better understand how various data sets affect the performance of different neural networks.
The key points:
- the marks are harmless and have no impact on the classification accuracy of models, but are detectable with high confidence in a neural network;
- the image features are moved in a particular direction (the carrier) that has been sampled randomly and independently of the data
- after a model is trained on such data, its classifier will align with the direction of the carrier
- the method works in such a way that it is difficult to detect whether a data set is radioactive and to remove the marks from the trained model.
blogpost: https://ai.facebook.com/blog/using-radioactive-data-to-detect-if-a-data-set-was-used-for-training/
paper: https://arxiv.org/abs/2002.00937
#cv #cnn #datavalidation #image #data
{kind=link}
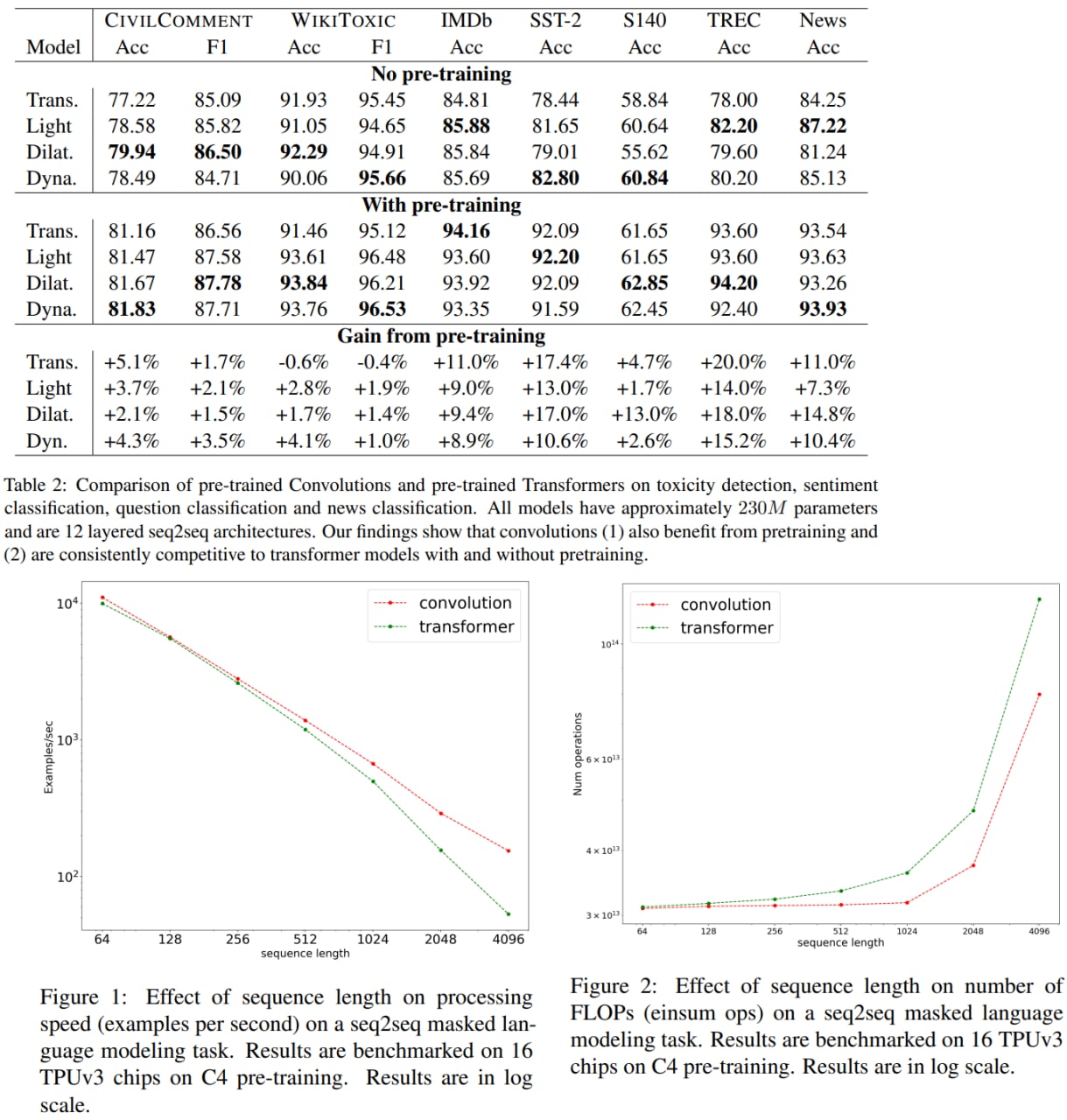
Are Pre-trained Convolutions Better than Pre-trained Transformers?
In this paper, the authors from Google Research wanted to investigate whether CNN architectures can be competitive compared to transformers on NLP problems. It turns out that pre-trained CNN models outperform pre-trained Transformers on some tasks; they also train faster and scale better to longer sequences.
Overall, the findings outlined in this paper suggest that conflating pre-training and architectural advances is misguided and that both advances should be considered independently. The authors believe their research paves the way for a healthy amount of optimism in alternative architectures.
Paper: https://arxiv.org/abs/2105.03322
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-cnnbettertransformers
#nlp #deeplearning #cnn #transformer #pretraining
In this paper, the authors from Google Research wanted to investigate whether CNN architectures can be competitive compared to transformers on NLP problems. It turns out that pre-trained CNN models outperform pre-trained Transformers on some tasks; they also train faster and scale better to longer sequences.
Overall, the findings outlined in this paper suggest that conflating pre-training and architectural advances is misguided and that both advances should be considered independently. The authors believe their research paves the way for a healthy amount of optimism in alternative architectures.
Paper: https://arxiv.org/abs/2105.03322
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-cnnbettertransformers
#nlp #deeplearning #cnn #transformer #pretraining
{kind=link}
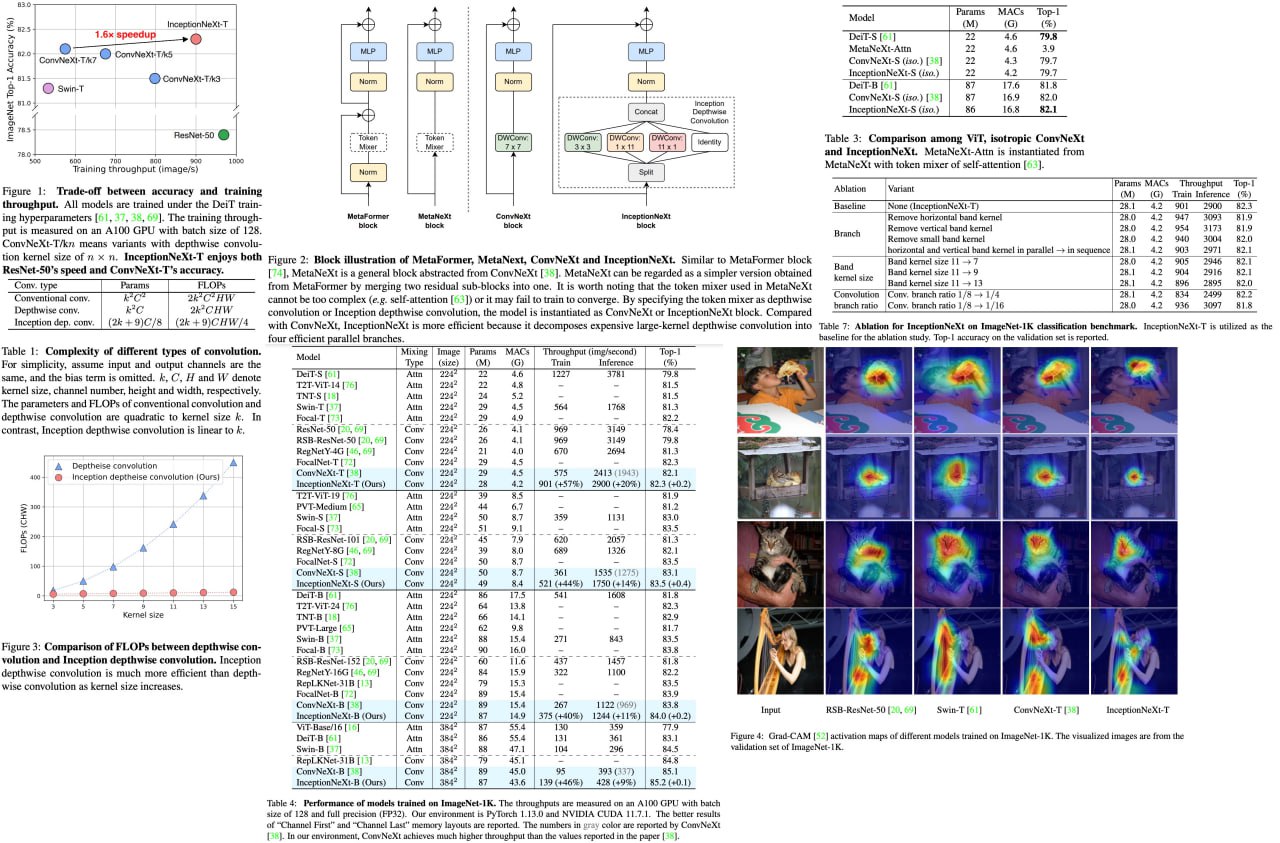
InceptionNeXt: When Inception Meets ConvNeXt
Large-kernel convolutions, such as those employed in ConvNeXt, can improve model performance but often come at the cost of efficiency due to high memory access costs. Although reducing kernel size may increase speed, it often leads to significant performance degradation.
To address this issue, the authors propose InceptionNeXt, which decomposes large-kernel depthwise convolution into four parallel branches along the channel dimension. This new Inception depthwise convolution results in networks with high throughputs and competitive performance. For example, InceptionNeXt-T achieves 1.6x higher training throughputs than ConvNeX-T and a 0.2% top-1 accuracy improvement on ImageNet-1K. InceptionNeXt has the potential to serve as an economical baseline for future architecture design, helping to reduce carbon footprint.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-inceptionnext
Paper link:https://arxiv.org/abs/2303.16900
Code link: https://github.com/sail-sg/inceptionnext
#cnn #deeplearning #computervision
Large-kernel convolutions, such as those employed in ConvNeXt, can improve model performance but often come at the cost of efficiency due to high memory access costs. Although reducing kernel size may increase speed, it often leads to significant performance degradation.
To address this issue, the authors propose InceptionNeXt, which decomposes large-kernel depthwise convolution into four parallel branches along the channel dimension. This new Inception depthwise convolution results in networks with high throughputs and competitive performance. For example, InceptionNeXt-T achieves 1.6x higher training throughputs than ConvNeX-T and a 0.2% top-1 accuracy improvement on ImageNet-1K. InceptionNeXt has the potential to serve as an economical baseline for future architecture design, helping to reduce carbon footprint.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-inceptionnext
Paper link:https://arxiv.org/abs/2303.16900
Code link: https://github.com/sail-sg/inceptionnext
#cnn #deeplearning #computervision
{kind=link}