
Use Machine Learning to filter messages in the browser
Article on filtering messages during #Twitch streaming with #tensorflow.
Link: https://dev.to/embiem/use-machine-learning-to-filter-messages-in-the-browser-4i19
#DL #NN #NLP #tensorflowjs
Article on filtering messages during #Twitch streaming with #tensorflow.
Link: https://dev.to/embiem/use-machine-learning-to-filter-messages-in-the-browser-4i19
#DL #NN #NLP #tensorflowjs
DEV Community
Use Machine Learning to filter messages in the browser
Use an Artifical Neural Network to classify messages as "spam" or "no spam"
Neural Networks seem to follow a puzzlingly simple strategy to classify images
Interesting article on how actually #NN see images and what helps to distinct different classes.
Link: https://medium.com/bethgelab/neural-networks-seem-to-follow-a-puzzlingly-simple-strategy-to-classify-images-f4229317261f
#BagNet #ResNet #Dl #CV
Interesting article on how actually #NN see images and what helps to distinct different classes.
Link: https://medium.com/bethgelab/neural-networks-seem-to-follow-a-puzzlingly-simple-strategy-to-classify-images-f4229317261f
#BagNet #ResNet #Dl #CV
{kind=link}
Data Science by ODS.ai 🦜
Neural networks #architecture #cheatsheet #nn
One of the most complete lists of #NN types.
Link: http://www.asimovinstitute.org/neural-network-zoo/
Link: http://www.asimovinstitute.org/neural-network-zoo/
The Asimov Institute
The Neural Network Zoo - The Asimov Institute
With new neural network architectures popping up every now and then, it’s hard to keep track of them all. Knowing all the abbreviations being thrown around (DCIGN, BiLSTM, DCGAN, anyone?) can be a bit overwhelming at first. So I decided to compose a cheat…
Deep Neural Networks Improve Radiologists' Performance in Breast Cancer Screening
A deep convolutional neural network for breast cancer screening exam classification, trained and evaluated on over 200,000 exams (over 1,000,000 images). #nn achieves an #AUC of 0.895 in predicting whether there is a cancer in the breast, when tested on the screening population.
Link: https://arxiv.org/abs/1903.08297
#cv #dl #cancer #objectdetection
A deep convolutional neural network for breast cancer screening exam classification, trained and evaluated on over 200,000 exams (over 1,000,000 images). #nn achieves an #AUC of 0.895 in predicting whether there is a cancer in the breast, when tested on the screening population.
Link: https://arxiv.org/abs/1903.08297
#cv #dl #cancer #objectdetection
A Recipe for Training Neural Networks by Andrej Karpathy
New article written by Andrej Karpathy distilling a bunch of useful heuristics for training neural nets. The post is full of real-world knowledge and how-to details that are not taught in books and often take endless hours to learn the hard way.
Link: https://karpathy.github.io/2019/04/25/recipe/
#tipsandtricks #karpathy #tutorial #nn #ml #dl
New article written by Andrej Karpathy distilling a bunch of useful heuristics for training neural nets. The post is full of real-world knowledge and how-to details that are not taught in books and often take endless hours to learn the hard way.
Link: https://karpathy.github.io/2019/04/25/recipe/
#tipsandtricks #karpathy #tutorial #nn #ml #dl
karpathy.github.io
A Recipe for Training Neural Networks
Musings of a Computer Scientist.
The lottery ticket hypothesis: finding sparse, trainable neural networks
Best paper award at #ICLR2019 main idea: dense, randomly-initialized, networks contain sparse subnetworks that trained in isolation reach test accuracy comparable to the original network. Thus compressing the original network up to 10% its original size.
Paper: https://arxiv.org/pdf/1803.03635.pdf
#nn #research
Best paper award at #ICLR2019 main idea: dense, randomly-initialized, networks contain sparse subnetworks that trained in isolation reach test accuracy comparable to the original network. Thus compressing the original network up to 10% its original size.
Paper: https://arxiv.org/pdf/1803.03635.pdf
#nn #research
Yet another good intro into difference between artificial neural network and biological one.
If you're getting started in Data Science, you need to start with the basic building building block of Neural Networks - a Perceptron. To understand what it is, there's this good link to get started with.
Link: https://towardsdatascience.com/the-differences-between-artificial-and-biological-neural-networks-a8b46db828b7
#nn #entrylevel #beginner
If you're getting started in Data Science, you need to start with the basic building building block of Neural Networks - a Perceptron. To understand what it is, there's this good link to get started with.
Link: https://towardsdatascience.com/the-differences-between-artificial-and-biological-neural-networks-a8b46db828b7
#nn #entrylevel #beginner
Medium
The differences between Artificial and Biological Neural Networks
They differ in size, topology, speed, fault-tolerance, power consumption, the way signals are sent and received and the way they learn.
🥇Parameter optimization in neural networks.
Play with three interactive visualizations and develop your intuition for optimizing model parameters.
Link: https://www.deeplearning.ai/ai-notes/optimization/
#interactive #demo #optimization #parameteroptimization #novice #entrylevel #beginner #goldcontent #nn #neuralnetwork
Play with three interactive visualizations and develop your intuition for optimizing model parameters.
Link: https://www.deeplearning.ai/ai-notes/optimization/
#interactive #demo #optimization #parameteroptimization #novice #entrylevel #beginner #goldcontent #nn #neuralnetwork
The HSIC Bottleneck: Deep Learning without Back-Propagation
An alternative to conventional backpropagation, that has a number of distinct advantages.
Link: https://arxiv.org/abs/1908.01580
#nn #backpropagation #DL #theory
An alternative to conventional backpropagation, that has a number of distinct advantages.
Link: https://arxiv.org/abs/1908.01580
#nn #backpropagation #DL #theory
arXiv.org
The HSIC Bottleneck: Deep Learning without Back-Propagation
We introduce the HSIC (Hilbert-Schmidt independence criterion) bottleneck for training deep neural networks. The HSIC bottleneck is an alternative to the conventional cross-entropy loss and...
And the Bit Goes Down: Revisiting the Quantization of Neural Networks
Researchers at Facebook AI Research found a way to compress neural networks with minimal sacrifice in accuracy.
Works only on fully connected and CNN only for now.
Link: https://arxiv.org/abs/1907.05686
#nn #DL #minimization #compresson
Researchers at Facebook AI Research found a way to compress neural networks with minimal sacrifice in accuracy.
Works only on fully connected and CNN only for now.
Link: https://arxiv.org/abs/1907.05686
#nn #DL #minimization #compresson
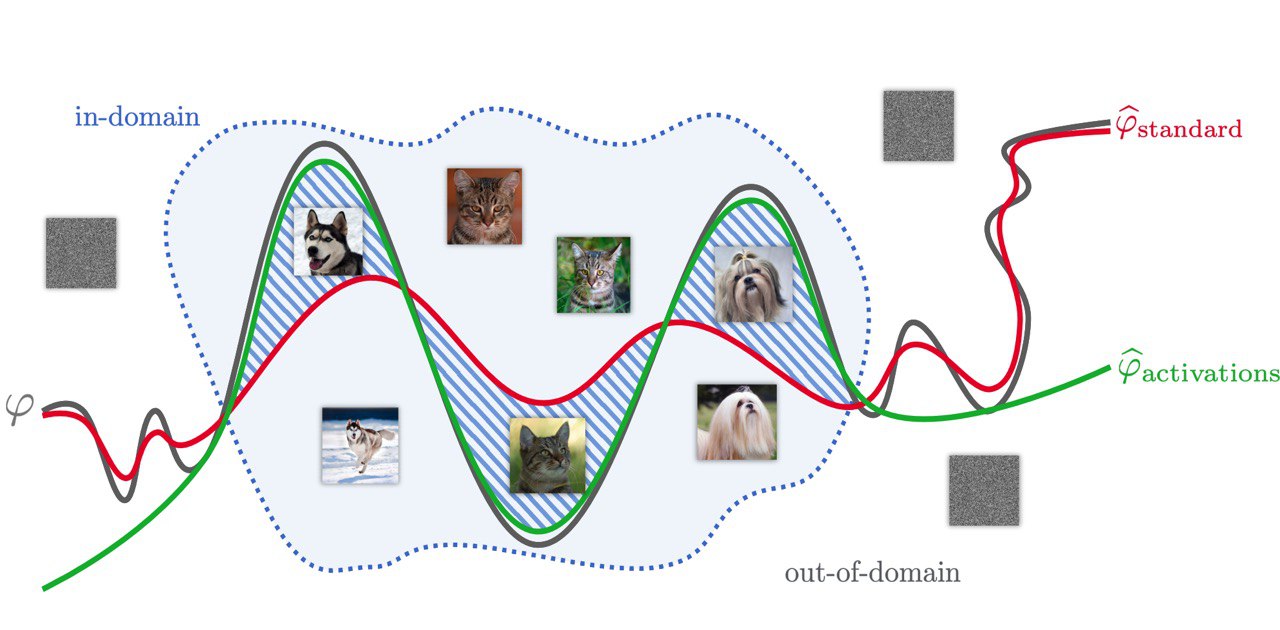{kind=link}
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
How normalization applied to layers helps to reach faster convergence.
ArXiV: https://arxiv.org/abs/1502.03167
#NeuralNetwork #nn #normalization #DL
How normalization applied to layers helps to reach faster convergence.
ArXiV: https://arxiv.org/abs/1502.03167
#NeuralNetwork #nn #normalization #DL
arXiv.org
Batch Normalization: Accelerating Deep Network Training by...
Training Deep Neural Networks is complicated by the fact that the distribution of each layer's inputs changes during training, as the parameters of the previous layers change. This slows down the...
Classification and Loss Evaluation - Softmax and Cross Entropy Loss
Nice notes on softmax cross entropy loss and how to implement it in numpy.
Link: https://deepnotes.io/softmax-crossentropy
#nn #entrylevel #wheretostart
Nice notes on softmax cross entropy loss and how to implement it in numpy.
Link: https://deepnotes.io/softmax-crossentropy
#nn #entrylevel #wheretostart
Parasdahal
Softmax and Cross Entropy Loss
Understanding the intuition and maths behind softmax and the cross entropy loss - the ubiquitous combination in classification algorithms.
27,600 V100 GPUs, 0.5 PB data, and a neural net with 220,000,000 weights
If you wonder, it all was used to address scientific inverse problem in materials imaging.
ArXiV: https://arxiv.org/pdf/1909.11150.pdf
#ItIsNotAboutSize #nn #dl
If you wonder, it all was used to address scientific inverse problem in materials imaging.
ArXiV: https://arxiv.org/pdf/1909.11150.pdf
#ItIsNotAboutSize #nn #dl
Applying deep learning to Airbnb search
Story of how #Airbnb research team moved from using #GBDT (gradient boosting) to #NN (neural networks) for search, with all the metrics and hypothesises.
Link: https://blog.acolyer.org/2019/10/09/applying-deep-learning-to-airbnb-search/
Story of how #Airbnb research team moved from using #GBDT (gradient boosting) to #NN (neural networks) for search, with all the metrics and hypothesises.
Link: https://blog.acolyer.org/2019/10/09/applying-deep-learning-to-airbnb-search/
Two papers stating random architecture search is a competitive (in some cases superior) baseline for NAS methods.
These are papers demonstrating that Neural Architecture Search can be stohastic.
Paper 1: https://arxiv.org/abs/1902.08142
Paper 2: https://arxiv.org/abs/1902.07638
#NAS #nn #DL
These are papers demonstrating that Neural Architecture Search can be stohastic.
Paper 1: https://arxiv.org/abs/1902.08142
Paper 2: https://arxiv.org/abs/1902.07638
#NAS #nn #DL
All the vector algebra you need for understanding neural networks
Article contains great explanations and description of matrix calculus you need to know and understand to really grok neural networks.
Link: https://explained.ai/matrix-calculus/index.html
#WhereToStart #entrylevel #novice #base #DL #nn
Article contains great explanations and description of matrix calculus you need to know and understand to really grok neural networks.
Link: https://explained.ai/matrix-calculus/index.html
#WhereToStart #entrylevel #novice #base #DL #nn
explained.ai
The Matrix Calculus You Need For Deep Learning
Most of us last saw calculus in school, but derivatives are a critical part of machine learning, particularly deep neural networks, which are trained by optimizing a loss function. This article is an attempt to explain all the matrix calculus you need in…
Free eBook from Stanford: Introduction to Applied Linear Algebra – Vectors, Matrices, and Least Squares
Base material you need to understand how neural networks and other #ML algorithms work.
Link: https://web.stanford.edu/~boyd/vmls/
#Stanford #MOOC #WhereToStart #free #ebook #algebra #linalg #NN
Base material you need to understand how neural networks and other #ML algorithms work.
Link: https://web.stanford.edu/~boyd/vmls/
#Stanford #MOOC #WhereToStart #free #ebook #algebra #linalg #NN
Characterising Bias in Compressed Models
Popular compression techniques turned out to amplify bias in deep neural networks.
ArXiV: https://arxiv.org/abs/2010.03058
#NN #DL #bias
Popular compression techniques turned out to amplify bias in deep neural networks.
ArXiV: https://arxiv.org/abs/2010.03058
#NN #DL #bias
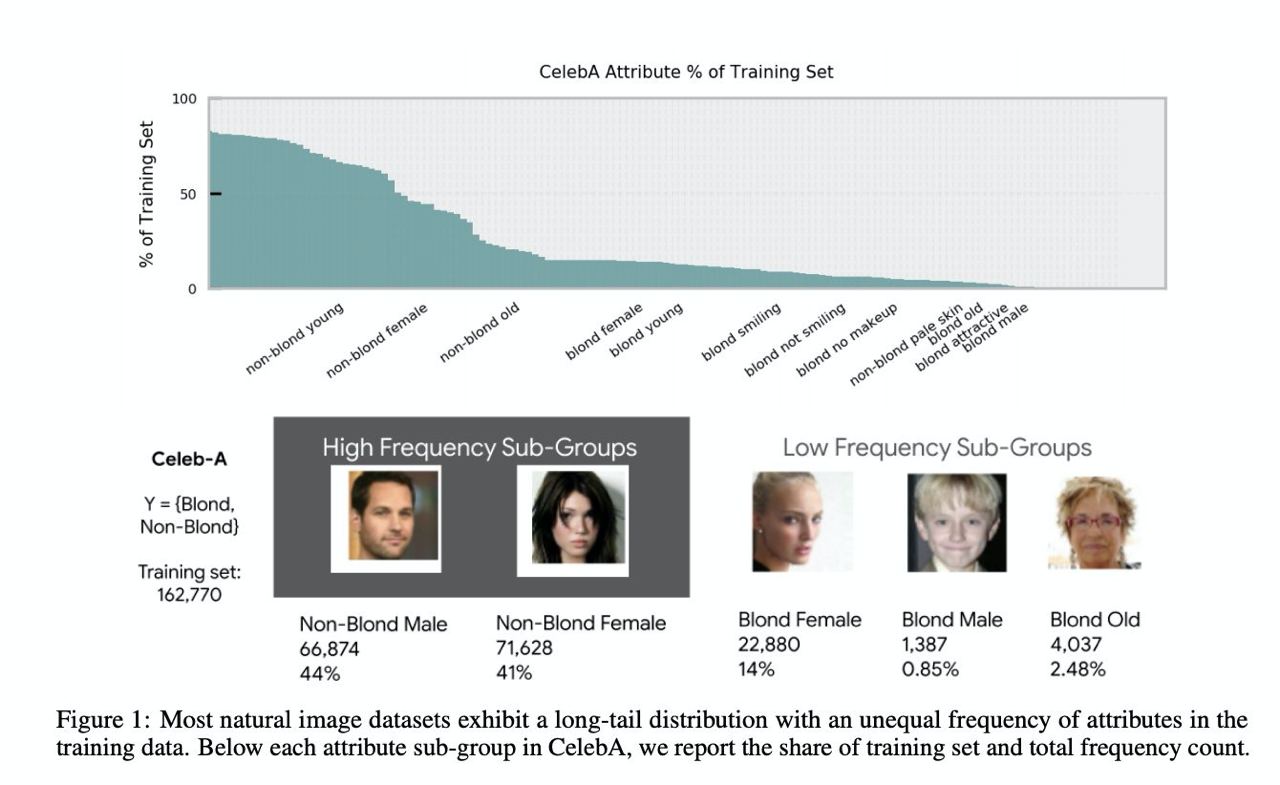{kind=link}
Towards Causal Representation Learning
Work on how neural networks derive casual variables from low-level observations.
Link: https://arxiv.org/abs/2102.11107
#casuallearning #bengio #nn #DL
Work on how neural networks derive casual variables from low-level observations.
Link: https://arxiv.org/abs/2102.11107
#casuallearning #bengio #nn #DL
Deep Neural Nets: 33 years ago and 33 years from now
Great post by Andrej Karpathy on the progress #CV made in 33 years.
Author's ideas on what would a time traveler from 2055 think about the performance of current networks:
* 2055 neural nets are basically the same as 2022 neural nets on the macro level, except bigger.
* Our datasets and models today look like a joke. Both are somewhere around 10,000,000X larger.
* One can train 2022 state of the art models in ~1 minute by training naively on their personal computing device as a weekend fun project.
* Today’s models are not optimally formulated, and just changing some of the details of the model, loss function, augmentation or the optimizer we can about halve the error.
* Our datasets are too small, and modest gains would come from scaling up the dataset alone.
* Further gains are actually not possible without expanding the computing infrastructure and investing into some R&D on effectively training models on that scale.
Website: https://karpathy.github.io/2022/03/14/lecun1989/
OG Paper link: http://yann.lecun.com/exdb/publis/pdf/lecun-89e.pdf
#karpathy #archeology #cv #nn
Great post by Andrej Karpathy on the progress #CV made in 33 years.
Author's ideas on what would a time traveler from 2055 think about the performance of current networks:
* 2055 neural nets are basically the same as 2022 neural nets on the macro level, except bigger.
* Our datasets and models today look like a joke. Both are somewhere around 10,000,000X larger.
* One can train 2022 state of the art models in ~1 minute by training naively on their personal computing device as a weekend fun project.
* Today’s models are not optimally formulated, and just changing some of the details of the model, loss function, augmentation or the optimizer we can about halve the error.
* Our datasets are too small, and modest gains would come from scaling up the dataset alone.
* Further gains are actually not possible without expanding the computing infrastructure and investing into some R&D on effectively training models on that scale.
Website: https://karpathy.github.io/2022/03/14/lecun1989/
OG Paper link: http://yann.lecun.com/exdb/publis/pdf/lecun-89e.pdf
#karpathy #archeology #cv #nn
karpathy.github.io
Deep Neural Nets: 33 years ago and 33 years from now
Musings of a Computer Scientist.