{kind=link}

One-shot object detection
Long and complete post explaining how these one-shot detectors work and how they are trained and evaluated.
Link: https://machinethink.net/blog/object-detection/
#cv #dl #objectdetection
Long and complete post explaining how these one-shot detectors work and how they are trained and evaluated.
Link: https://machinethink.net/blog/object-detection/
#cv #dl #objectdetection
{kind=link}
Deep Neural Networks Improve Radiologists' Performance in Breast Cancer Screening
A deep convolutional neural network for breast cancer screening exam classification, trained and evaluated on over 200,000 exams (over 1,000,000 images). #nn achieves an #AUC of 0.895 in predicting whether there is a cancer in the breast, when tested on the screening population.
Link: https://arxiv.org/abs/1903.08297
#cv #dl #cancer #objectdetection
A deep convolutional neural network for breast cancer screening exam classification, trained and evaluated on over 200,000 exams (over 1,000,000 images). #nn achieves an #AUC of 0.895 in predicting whether there is a cancer in the breast, when tested on the screening population.
Link: https://arxiv.org/abs/1903.08297
#cv #dl #cancer #objectdetection
arXiv.org
Deep Neural Networks Improve Radiologists' Performance in...
We present a deep convolutional neural network for breast cancer screening exam classification, trained and evaluated on over 200,000 exams (over 1,000,000 images). Our network achieves an AUC of...
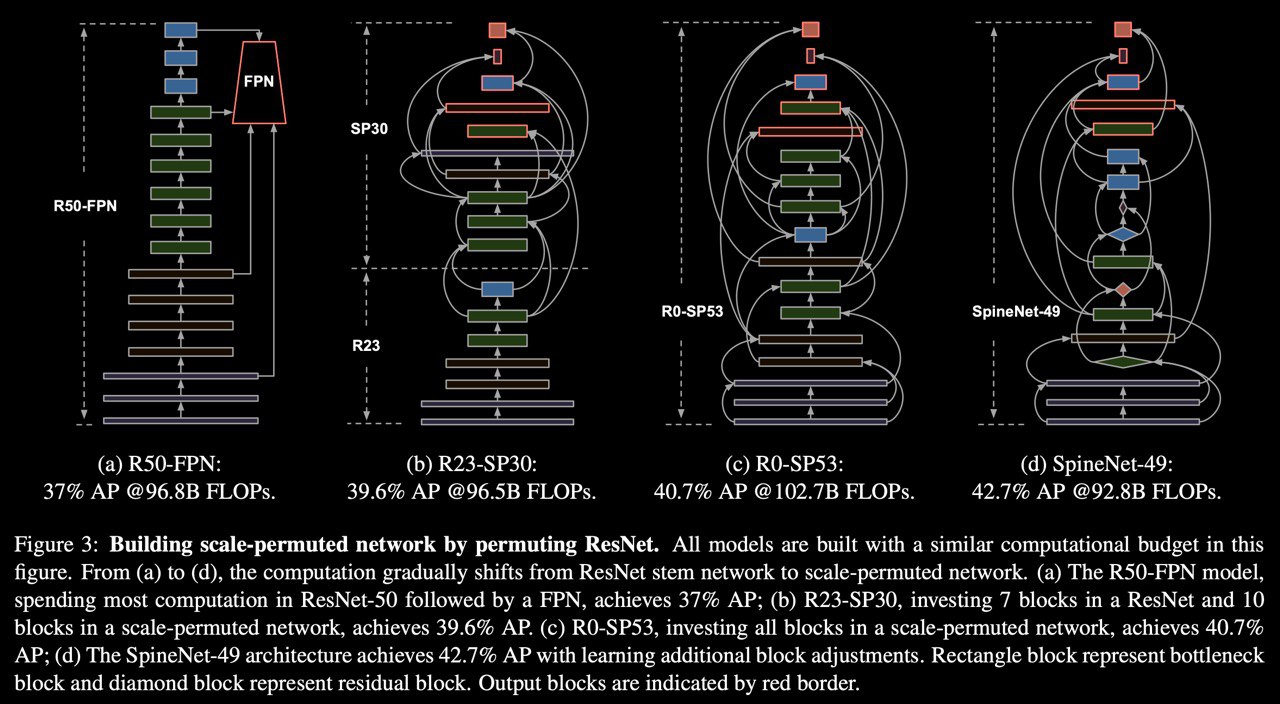
SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization
Abstract: CNN typically encodes an input image into a series of intermediate features with decreasing resolutions. While this structure is suited to classification tasks, it does not perform well for tasks requiring simultaneous recognition and localization (e.g., object detection). The encoder-decoder architectures are proposed to resolve this by applying a decoder network onto a backbone model designed for classification tasks. In this paper, we argue that encoder-decoder architecture is ineffective in generating strong multi-scale features because of the scale-decreased backbone. We propose SpineNet, a backbone with scale-permuted intermediate features and cross-scale connections that are learned on an object detection task by Neural Architecture Search. SpineNet achieves the SOTA performance of a one-stage object detector on COCO with 60% less computation and outperforms ResNet-FPN counterparts by 6% AP. SpineNet architecture can transfer to classification tasks, achieving 6% top-1 accuracy improvement on a challenging iNaturalist fine-grained dataset.
So, by Google's beloved method of creating a new SOTA, there is a new one! They just permute ResNet layers by NAS with adding resample cross-scale connections for correct connection scales output between layers. It seems that no need FPN cause the whole backbone is FPN. They train from scratch on RetinaNet just replace ResNet backbone with SpineNet and get SOTA. On two-stage detectors, there is the same result by replacing the backbone with SpineNet. If you want just classify something with that backbone it is performed very well too. So new architecture for any application!
Good job.
paper: https://arxiv.org/abs/1912.05027
code: Very wanted, but not release yet
#CV #ObjectDetection #GoogleResearch #NAS #SOTA
Abstract: CNN typically encodes an input image into a series of intermediate features with decreasing resolutions. While this structure is suited to classification tasks, it does not perform well for tasks requiring simultaneous recognition and localization (e.g., object detection). The encoder-decoder architectures are proposed to resolve this by applying a decoder network onto a backbone model designed for classification tasks. In this paper, we argue that encoder-decoder architecture is ineffective in generating strong multi-scale features because of the scale-decreased backbone. We propose SpineNet, a backbone with scale-permuted intermediate features and cross-scale connections that are learned on an object detection task by Neural Architecture Search. SpineNet achieves the SOTA performance of a one-stage object detector on COCO with 60% less computation and outperforms ResNet-FPN counterparts by 6% AP. SpineNet architecture can transfer to classification tasks, achieving 6% top-1 accuracy improvement on a challenging iNaturalist fine-grained dataset.
So, by Google's beloved method of creating a new SOTA, there is a new one! They just permute ResNet layers by NAS with adding resample cross-scale connections for correct connection scales output between layers. It seems that no need FPN cause the whole backbone is FPN. They train from scratch on RetinaNet just replace ResNet backbone with SpineNet and get SOTA. On two-stage detectors, there is the same result by replacing the backbone with SpineNet. If you want just classify something with that backbone it is performed very well too. So new architecture for any application!
Good job.
paper: https://arxiv.org/abs/1912.05027
code: Very wanted, but not release yet
#CV #ObjectDetection #GoogleResearch #NAS #SOTA
{kind=link}
Albumentation – fast & flexible image augmentations
Image Augmentations is a powerful technique to improve model robustness and performance. There are many image augmentations libraries on the market: torchvision, imgaug, DALI, Augmentor, SOLT, etc.
In all of them, authors focussed on variety at the cost of speed, or the speed at the cost of flexibility.
Requirements for augmentations:
* Variety: they want to have a large set of standard and exotic augmentation for image classification, segmentation, and detection in one place.
* Performance: transforms should be as fast as possible.
* Flexibility: it should be easy to add new transforms or new types of transforms.
* Conciseness: all complexity of implementation should be hidden behind the API.
To date
The library was adopted by academics, Kaggle, and other communities.
ODS: #tool_albumentations
Link: https://albumentations.ai/
Github: https://github.com/albumentations-team/albumentations
Paper: https://www.mdpi.com/2078-2489/11/2/125
P.S. Following trend setup by #Catalyst team, we provide extensive description of project with the help of its creators.
#guestpost #augmentation #CV #DL #imageprocessing #ods #objectdetection #imageclassification #tool
Image Augmentations is a powerful technique to improve model robustness and performance. There are many image augmentations libraries on the market: torchvision, imgaug, DALI, Augmentor, SOLT, etc.
In all of them, authors focussed on variety at the cost of speed, or the speed at the cost of flexibility.
Requirements for augmentations:
* Variety: they want to have a large set of standard and exotic augmentation for image classification, segmentation, and detection in one place.
* Performance: transforms should be as fast as possible.
* Flexibility: it should be easy to add new transforms or new types of transforms.
* Conciseness: all complexity of implementation should be hidden behind the API.
Albumentations were born out of necessity. The authors were actively participating in various Deep Learning competitions. To get to the top they needed something better than what was already available. All of them, independently, started working on more powerful augmentation pipelines. Later they merged their efforts and released the code in the form of the library.To date
Albumentations has more than 70 transforms and supports image classification, #segmentation, object and keypoint detection tasks.The library was adopted by academics, Kaggle, and other communities.
ODS: #tool_albumentations
Link: https://albumentations.ai/
Github: https://github.com/albumentations-team/albumentations
Paper: https://www.mdpi.com/2078-2489/11/2/125
P.S. Following trend setup by #Catalyst team, we provide extensive description of project with the help of its creators.
#guestpost #augmentation #CV #DL #imageprocessing #ods #objectdetection #imageclassification #tool
GitHub
GitHub - albumentations-team/albumentations: Fast and flexible image augmentation library. Paper about the library: https://www.mdpi.com/2078…
Fast and flexible image augmentation library. Paper about the library: https://www.mdpi.com/2078-2489/11/2/125 - albumentations-team/albumentations
End-to-End Object Detection with Transformers
Authors present a new method that views object detection as a direct set prediction problem.
This approach simplifies the detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression procedure or anchor generation that explicitly encode our prior knowledge about the task.
The main ingredients of the new framework, called DEtection TRansformer or DETR, are a set-based global loss that forces unique predictions via bipartite matching, and a transformer encoder-decoder architecture
DETR demonstrates accuracy and run-time performance on par with the well-established and highly-optimized Faster RCNN baseline on the challenging COCO object detection dataset. Moreover, DETR can be easily generalized to produce panoptic segmentation in a unified manner
Paper: https://arxiv.org/abs/2005.12872
Code: https://github.com/facebookresearch/detr
#deeplearning #objectdetection #transformer #coco
Authors present a new method that views object detection as a direct set prediction problem.
This approach simplifies the detection pipeline, effectively removing the need for many hand-designed components like a non-maximum suppression procedure or anchor generation that explicitly encode our prior knowledge about the task.
The main ingredients of the new framework, called DEtection TRansformer or DETR, are a set-based global loss that forces unique predictions via bipartite matching, and a transformer encoder-decoder architecture
DETR demonstrates accuracy and run-time performance on par with the well-established and highly-optimized Faster RCNN baseline on the challenging COCO object detection dataset. Moreover, DETR can be easily generalized to produce panoptic segmentation in a unified manner
Paper: https://arxiv.org/abs/2005.12872
Code: https://github.com/facebookresearch/detr
#deeplearning #objectdetection #transformer #coco
{kind=link}
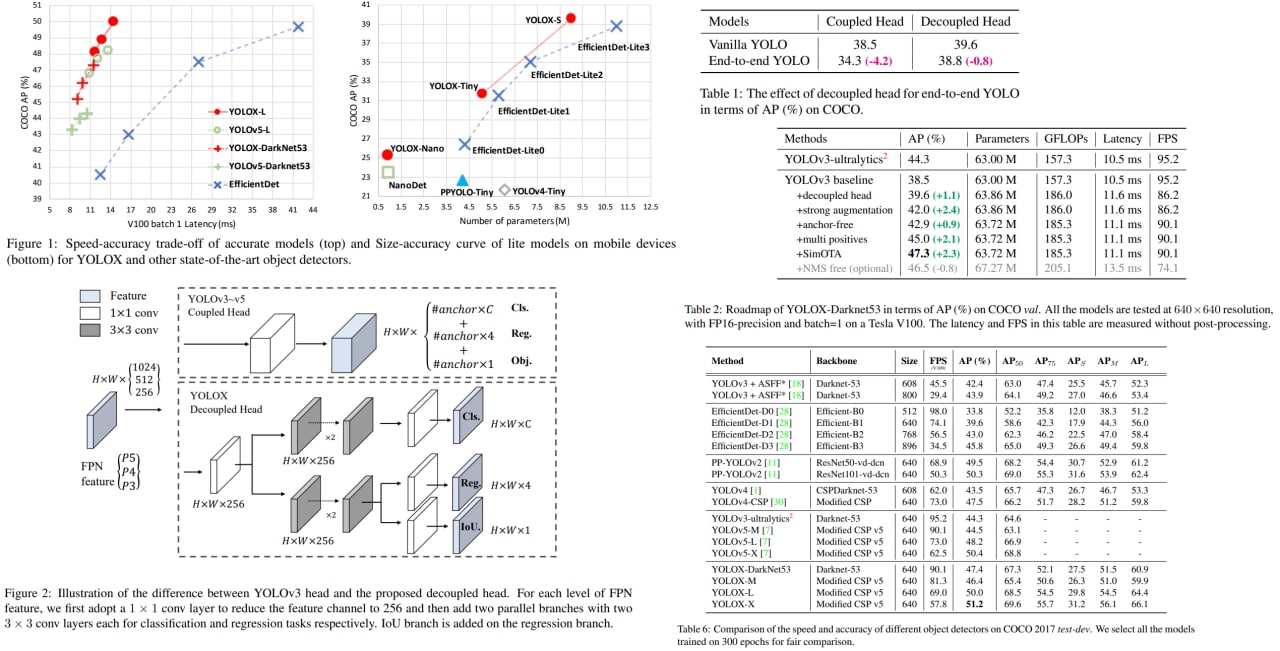
YOLOX: Exceeding YOLO Series in 2021
This paper presents a new high-performance variation of YOLO - YOLOX. Now it has an anchor-free detector, a decoupled head, and uses the leading label assignment strategy SimOTA.
Thanks to these changes, it reaches state-of-the-art results across a large scale range of models. For example, YOLOX-Nano gets 25.3% AP on COCO (+1.8% to NanoDet), YOLOX-L achieves 50.0% AP on COCO (+1.8 to YOLOv5-L).
For YOLOv3, one of the most widely used detectors in industry, they boost it to 47.3% AP on COCO, outperforming the current best practice by 3.0% AP.
The authors won the 1st Place on Streaming Perception Challenge (Workshop on Autonomous Driving at CVPR 2021) using a single YOLOX-L model.
They also provide deploy versions with ONNX, TensorRT, NCNN, and Openvino supported.
Paper: https://arxiv.org/abs/2107.08430
Code: https://github.com/Megvii-BaseDetection/YOLOX
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-yolox
#deeplearning #cv #objectdetection #endtoend #anchorfree
This paper presents a new high-performance variation of YOLO - YOLOX. Now it has an anchor-free detector, a decoupled head, and uses the leading label assignment strategy SimOTA.
Thanks to these changes, it reaches state-of-the-art results across a large scale range of models. For example, YOLOX-Nano gets 25.3% AP on COCO (+1.8% to NanoDet), YOLOX-L achieves 50.0% AP on COCO (+1.8 to YOLOv5-L).
For YOLOv3, one of the most widely used detectors in industry, they boost it to 47.3% AP on COCO, outperforming the current best practice by 3.0% AP.
The authors won the 1st Place on Streaming Perception Challenge (Workshop on Autonomous Driving at CVPR 2021) using a single YOLOX-L model.
They also provide deploy versions with ONNX, TensorRT, NCNN, and Openvino supported.
Paper: https://arxiv.org/abs/2107.08430
Code: https://github.com/Megvii-BaseDetection/YOLOX
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-yolox
#deeplearning #cv #objectdetection #endtoend #anchorfree
{kind=link}
❤1👍1
Cut and Learn for Unsupervised Object Detection and Instance Segmentation
CutLER (Cut-and-LEaRn) is a new approach for training unsupervised object detection and segmentation models without using any human labels. It uses a combination of a MaskCut approach to generate object masks and a robust loss function to learn a detector. The model is simple and compatible with different detection architectures and can detect multiple objects. It is a zero-shot detector, meaning it performs well without additional in-domain data and is robust against domain shifts across various types of images. CutLER can also be used as a pretrained model for supervised detection and improves performance on few-shot benchmarks. Results show improved performance over previous work, including being a zero-shot unsupervised detector and surpassing other low-shot detectors with finetuning.
Paper: https://arxiv.org/abs/2301.11320
Code link: https://github.com/facebookresearch/CutLER1
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-cutler
#deeplearning #cv #objectdetection #imagesegmentation
CutLER (Cut-and-LEaRn) is a new approach for training unsupervised object detection and segmentation models without using any human labels. It uses a combination of a MaskCut approach to generate object masks and a robust loss function to learn a detector. The model is simple and compatible with different detection architectures and can detect multiple objects. It is a zero-shot detector, meaning it performs well without additional in-domain data and is robust against domain shifts across various types of images. CutLER can also be used as a pretrained model for supervised detection and improves performance on few-shot benchmarks. Results show improved performance over previous work, including being a zero-shot unsupervised detector and surpassing other low-shot detectors with finetuning.
Paper: https://arxiv.org/abs/2301.11320
Code link: https://github.com/facebookresearch/CutLER1
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-cutler
#deeplearning #cv #objectdetection #imagesegmentation
{kind=link}
👍19👎4⚡2🙊2🔥1
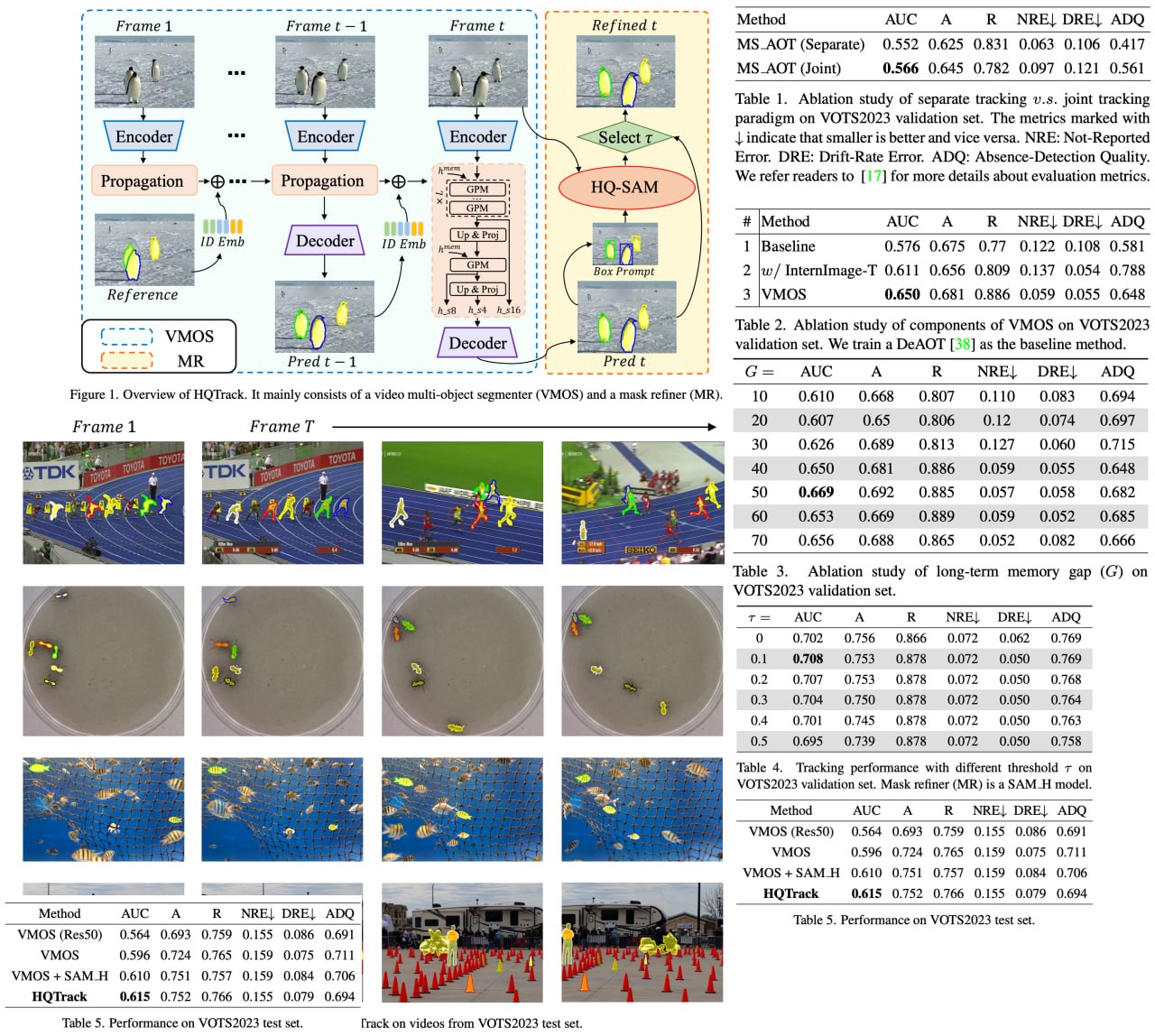
Tracking Anything in High Quality
Visual object tracking, a cornerstone of computer vision, is being revolutionized by the ever-increasing power of perception algorithms, facilitating the unification of single/multi-object and box/mask-based tracking. In this thrilling technological panorama, the Segment Anything Model stands out, drawing significant attention from researchers around the globe.
HQTrack is ingeniously constructed with a video multi-object segmenter and a mask refiner. VMOS, given an object in the initial frame, works its magic by propagating object masks to the current frame. However, its initial results may not be perfect due to limited training data, but that's where the MR comes in, refining these results and significantly enhancing the tracking mask quality. HQTrack claimed an impressive second place in the prestigious Visual Object Tracking and Segmentation challenge, all without resorting to any tricks such as test-time data augmentations and model ensembles.
Code link: https://github.com/jiawen-zhu/HQTrack
Paper link: https://arxiv.org/abs/2307.13974
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-hqtrack
#deeplearning #objectdetection #objecttracking
Visual object tracking, a cornerstone of computer vision, is being revolutionized by the ever-increasing power of perception algorithms, facilitating the unification of single/multi-object and box/mask-based tracking. In this thrilling technological panorama, the Segment Anything Model stands out, drawing significant attention from researchers around the globe.
HQTrack is ingeniously constructed with a video multi-object segmenter and a mask refiner. VMOS, given an object in the initial frame, works its magic by propagating object masks to the current frame. However, its initial results may not be perfect due to limited training data, but that's where the MR comes in, refining these results and significantly enhancing the tracking mask quality. HQTrack claimed an impressive second place in the prestigious Visual Object Tracking and Segmentation challenge, all without resorting to any tricks such as test-time data augmentations and model ensembles.
Code link: https://github.com/jiawen-zhu/HQTrack
Paper link: https://arxiv.org/abs/2307.13974
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-hqtrack
#deeplearning #objectdetection #objecttracking
{kind=link}
👍9❤4