
DarkBERT: A Language Model for the Dark Side of the Internet
The researchers have developed a novel model called DarkBERT, which specifically focuses on the linguistically complex and often misunderstood domain of the Dark Web. This innovative model stands out due to its unique pretraining on Dark Web data, which allows it to handle the extreme lexical and structural diversity characteristic of the Dark Web. This is a critical development considering the clear differences that exist in language use between the Dark Web and the Surface Web, a factor that can often hinder accurate textual analysis.
DarkBERT isn't just a novelty, but a robust, high-performing language model that consistently outshines current popular models like BERT and RoBERTa in various use cases. These findings shed light on the considerable advantages that a domain-specific model like DarkBERT can offer. More than anything else, DarkBERT promises to be a vital resource for future research on the Dark Web, setting a new standard for language models in this intriguing and intricate realm.
Paper link: https://arxiv.org/abs/2305.08596
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-darkbert
#deeplearning #nlp #darkweb #cybersecurity
The researchers have developed a novel model called DarkBERT, which specifically focuses on the linguistically complex and often misunderstood domain of the Dark Web. This innovative model stands out due to its unique pretraining on Dark Web data, which allows it to handle the extreme lexical and structural diversity characteristic of the Dark Web. This is a critical development considering the clear differences that exist in language use between the Dark Web and the Surface Web, a factor that can often hinder accurate textual analysis.
DarkBERT isn't just a novelty, but a robust, high-performing language model that consistently outshines current popular models like BERT and RoBERTa in various use cases. These findings shed light on the considerable advantages that a domain-specific model like DarkBERT can offer. More than anything else, DarkBERT promises to be a vital resource for future research on the Dark Web, setting a new standard for language models in this intriguing and intricate realm.
Paper link: https://arxiv.org/abs/2305.08596
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-darkbert
#deeplearning #nlp #darkweb #cybersecurity
{kind=link}
Chain of Hindsight Aligns Language Models with Feedback
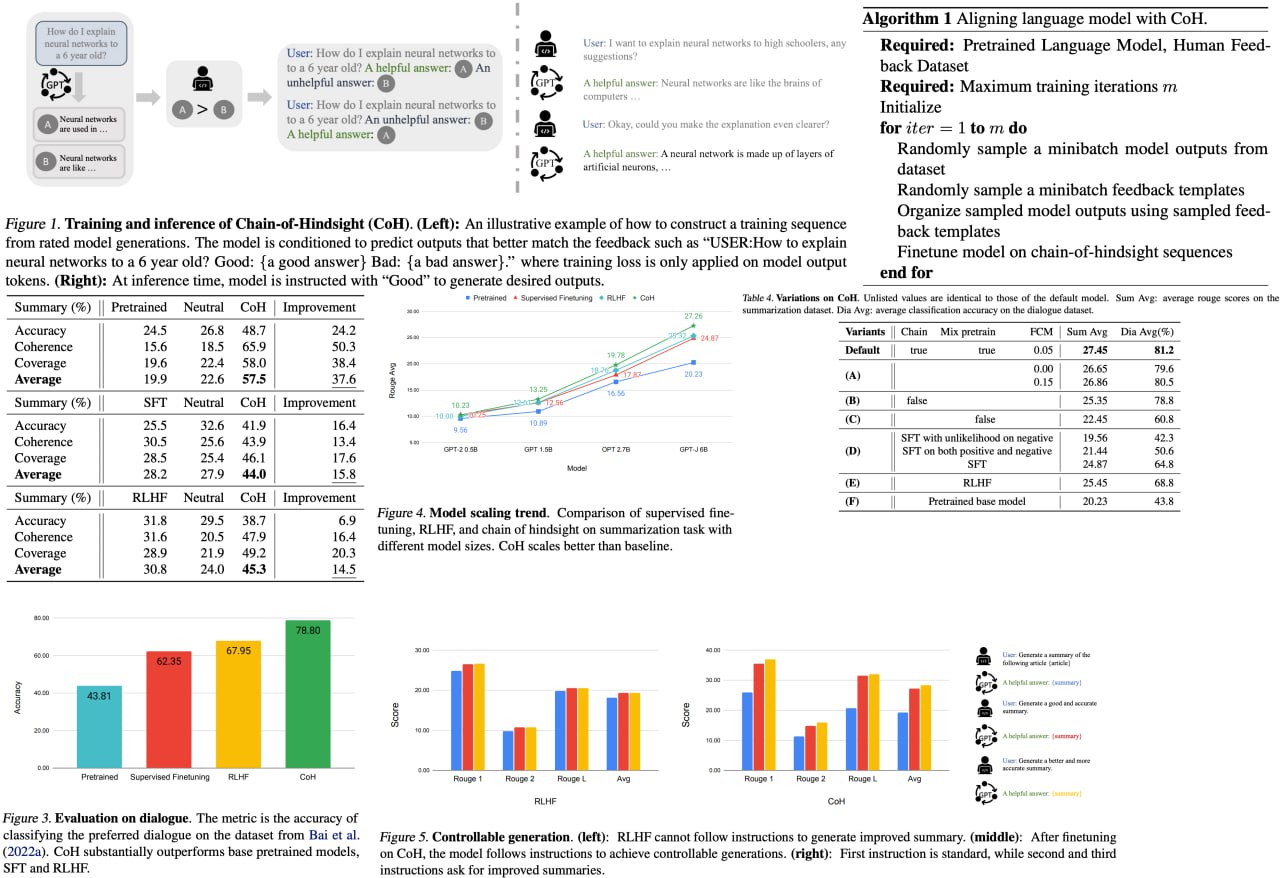
AI language models are becoming a major part of our digital world. The challenge, however, lies in aligning these models with human preferences to be genuinely useful and valuable. Current methods, although successful in many ways, have limitations - they are either inefficient in utilizing data or depend heavily on challenging reward functions and reinforcement learning.
Here comes "Chain of Hindsight," an exciting, novel technique inspired by human learning mechanisms. It can learn from any form of feedback, even transforming it into language for fine-tuning the model. This approach conditions the model on a sequence of model generations paired with feedback, helping it learn to correct negative attributes or errors. It is significantly outperforming previous methods, particularly showing major strides in summarization and dialogue tasks.
Paper link: https://arxiv.org/abs/2302.02676
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-coh
#deeplearning #nlp #llm
AI language models are becoming a major part of our digital world. The challenge, however, lies in aligning these models with human preferences to be genuinely useful and valuable. Current methods, although successful in many ways, have limitations - they are either inefficient in utilizing data or depend heavily on challenging reward functions and reinforcement learning.
Here comes "Chain of Hindsight," an exciting, novel technique inspired by human learning mechanisms. It can learn from any form of feedback, even transforming it into language for fine-tuning the model. This approach conditions the model on a sequence of model generations paired with feedback, helping it learn to correct negative attributes or errors. It is significantly outperforming previous methods, particularly showing major strides in summarization and dialogue tasks.
Paper link: https://arxiv.org/abs/2302.02676
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-coh
#deeplearning #nlp #llm
{kind=link}
QLoRA: Efficient Finetuning of Quantized LLMs
Thia paper introduces QLoRA, a novel finetuning approach that decreases memory usage significantly, while maintaining impressive performance. Imagine this - a 65 billion parameter model finetuned on a single 48GB GPU, while preserving full 16-bit task performance. This method involves backpropagating gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters, a method that opens up new frontiers in machine learning. The icing on the cake is their high-performing model family, Guanaco, which trumps all previously released models on the Vicuna benchmark, achieving a staggering 99.3% of the performance level of ChatGPT with just 24 hours of finetuning on a single GPU.
The study also unveils several innovative techniques to conserve memory without compromising performance. These include 4-bit NormalFloat (NF4), an innovative data type that is theoretically optimal for normally distributed weights, double quantization for average memory footprint reduction, and paged optimizers to handle memory spikes. The QLoRA approach was applied to finetune more than 1000 models, leading to a detailed analysis of instruction following and chatbot performance across various model types and scales. The results affirm that QLoRA finetuning on a small, high-quality dataset yields state-of-the-art results, even with smaller models than previously used. A notable finding is that GPT-4 evaluations offer a cost-effective alternative to human evaluation. All models and code, including CUDA kernels for 4-bit training, have been released by the researchers.
Paper link: https://arxiv.org/abs/2305.14314
Code link: https://github.com/artidoro/qlora
CUDA kernels link: https://github.com/TimDettmers/bitsandbytes
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-qlora
#deeplearning #nlp #llm #quantization
Thia paper introduces QLoRA, a novel finetuning approach that decreases memory usage significantly, while maintaining impressive performance. Imagine this - a 65 billion parameter model finetuned on a single 48GB GPU, while preserving full 16-bit task performance. This method involves backpropagating gradients through a frozen, 4-bit quantized pretrained language model into Low Rank Adapters, a method that opens up new frontiers in machine learning. The icing on the cake is their high-performing model family, Guanaco, which trumps all previously released models on the Vicuna benchmark, achieving a staggering 99.3% of the performance level of ChatGPT with just 24 hours of finetuning on a single GPU.
The study also unveils several innovative techniques to conserve memory without compromising performance. These include 4-bit NormalFloat (NF4), an innovative data type that is theoretically optimal for normally distributed weights, double quantization for average memory footprint reduction, and paged optimizers to handle memory spikes. The QLoRA approach was applied to finetune more than 1000 models, leading to a detailed analysis of instruction following and chatbot performance across various model types and scales. The results affirm that QLoRA finetuning on a small, high-quality dataset yields state-of-the-art results, even with smaller models than previously used. A notable finding is that GPT-4 evaluations offer a cost-effective alternative to human evaluation. All models and code, including CUDA kernels for 4-bit training, have been released by the researchers.
Paper link: https://arxiv.org/abs/2305.14314
Code link: https://github.com/artidoro/qlora
CUDA kernels link: https://github.com/TimDettmers/bitsandbytes
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-qlora
#deeplearning #nlp #llm #quantization
{kind=link}
StableRep: Synthetic Images from Text-to-Image Models Make Strong Visual Representation Learners
In a ground-breaking exploration of visual representation learning, researchers have leveraged synthetic images produced by leading text-to-image models, specifically Stable Diffusion, achieving promising results. The study uncovers two key insights - firstly, when configured correctly, self-supervised methods trained on synthetic images can match or even outperform those trained on real images. This suggests an exciting avenue for efficient and effective representation learning, reducing the need for extensive real image datasets.
Secondly, the researchers have devised a novel approach called StableRep, a multi-positive contrastive learning method that treats multiple images, generated from the same text prompt, as mutual positives. The compelling finding is that StableRep, trained solely with synthetic images, outperforms representations learned by prominent methods such as SimCLR and CLIP, even when these used real images. In a striking demonstration, when language supervision is added, StableRep trained with 20M synthetic images outperforms CLIP trained with a whopping 50M real images. These findings not only underscore the potential of synthetic data but also pave the way for more efficient, large-scale visual representation learning.
Paper link: https://arxiv.org/abs/2306.00984
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-stablerep
#deeplearning #cv #nlp #stablediffusion #texttoimage #syntheticdata
In a ground-breaking exploration of visual representation learning, researchers have leveraged synthetic images produced by leading text-to-image models, specifically Stable Diffusion, achieving promising results. The study uncovers two key insights - firstly, when configured correctly, self-supervised methods trained on synthetic images can match or even outperform those trained on real images. This suggests an exciting avenue for efficient and effective representation learning, reducing the need for extensive real image datasets.
Secondly, the researchers have devised a novel approach called StableRep, a multi-positive contrastive learning method that treats multiple images, generated from the same text prompt, as mutual positives. The compelling finding is that StableRep, trained solely with synthetic images, outperforms representations learned by prominent methods such as SimCLR and CLIP, even when these used real images. In a striking demonstration, when language supervision is added, StableRep trained with 20M synthetic images outperforms CLIP trained with a whopping 50M real images. These findings not only underscore the potential of synthetic data but also pave the way for more efficient, large-scale visual representation learning.
Paper link: https://arxiv.org/abs/2306.00984
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-stablerep
#deeplearning #cv #nlp #stablediffusion #texttoimage #syntheticdata
{kind=link}
BiomedGPT: A Unified and Generalist Biomedical Generative Pre-trained Transformer for Vision, Language, and Multimodal Tasks
Introducing the groundbreaking Biomedical Generative Pre-trained Transformer (BiomedGPT) model, this paper revolutionizes the field of biomedicine by offering a unified and generalist approach. BiomedGPT harnesses the power of self-supervision on extensive and diverse datasets, enabling it to effortlessly handle multi-modal inputs and excel in a wide range of downstream tasks. In a series of comprehensive experiments, BiomedGPT astoundingly outperforms its predecessors, emerging as the unrivaled leader across five distinct tasks and a staggering 20 public datasets encompassing over 15 unique biomedical modalities. Its ability to deliver expansive and all-encompassing representations of biomedical data heralds a significant advancement in the field, with promising implications for improving healthcare outcomes.
Through meticulous ablation studies, the efficacy of BiomedGPT's multi-modal and multi-task pretraining approach is vividly showcased. This groundbreaking model effortlessly transfers its vast knowledge to previously unseen data, demonstrating its versatility and adaptability. The implications of this research are profound, paving the way for the development of unified and all-encompassing models for biomedicine.
Paper link: https://arxiv.org/abs/2305.17100
Code link: https://github.com/taokz/BiomedGPT
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-biomedgpt
#deeplearning #nlp #selfsupervised #gpt #biomedicine
Introducing the groundbreaking Biomedical Generative Pre-trained Transformer (BiomedGPT) model, this paper revolutionizes the field of biomedicine by offering a unified and generalist approach. BiomedGPT harnesses the power of self-supervision on extensive and diverse datasets, enabling it to effortlessly handle multi-modal inputs and excel in a wide range of downstream tasks. In a series of comprehensive experiments, BiomedGPT astoundingly outperforms its predecessors, emerging as the unrivaled leader across five distinct tasks and a staggering 20 public datasets encompassing over 15 unique biomedical modalities. Its ability to deliver expansive and all-encompassing representations of biomedical data heralds a significant advancement in the field, with promising implications for improving healthcare outcomes.
Through meticulous ablation studies, the efficacy of BiomedGPT's multi-modal and multi-task pretraining approach is vividly showcased. This groundbreaking model effortlessly transfers its vast knowledge to previously unseen data, demonstrating its versatility and adaptability. The implications of this research are profound, paving the way for the development of unified and all-encompassing models for biomedicine.
Paper link: https://arxiv.org/abs/2305.17100
Code link: https://github.com/taokz/BiomedGPT
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-biomedgpt
#deeplearning #nlp #selfsupervised #gpt #biomedicine
{kind=link}
Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision
AI-assistant agents like ChatGPT have largely depended on supervised fine-tuning and reinforcement learning from human feedback. But, this method brings its own set of challenges - high costs, potential biases, and constraints on the true potential of these AI agents. What if there was a more effective, self-sufficient way to align AI output with human intentions? Enter Self-ALIGN, a groundbreaking methodology that marries principle-driven reasoning and the generative capabilities of large language models. This promising approach takes the AI realm by storm, offering a novel way to ensure our AI models are more helpful, ethical, and reliable - all with minimal human intervention.
Self-ALIGN is a multistage process that works by generating synthetic prompts from a large language model, augmenting prompt diversity, and leveraging a concise set of human-written principles to guide AI models. When applied to the LLaMA-65b base language model, it led to the creation of a new AI assistant, Dromedary, using less than 300 lines of human annotations. Dromedary not only outshines several state-of-the-art AI systems, such as Text-Davinci-003 and Alpaca, but it does so on a variety of benchmark datasets.
Paper link: https://arxiv.org/abs/2305.03047
Code link: https://mitibmdemos.draco.res.ibm.com/dromedary
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dromedary
#deeplearning #nlp #llm
AI-assistant agents like ChatGPT have largely depended on supervised fine-tuning and reinforcement learning from human feedback. But, this method brings its own set of challenges - high costs, potential biases, and constraints on the true potential of these AI agents. What if there was a more effective, self-sufficient way to align AI output with human intentions? Enter Self-ALIGN, a groundbreaking methodology that marries principle-driven reasoning and the generative capabilities of large language models. This promising approach takes the AI realm by storm, offering a novel way to ensure our AI models are more helpful, ethical, and reliable - all with minimal human intervention.
Self-ALIGN is a multistage process that works by generating synthetic prompts from a large language model, augmenting prompt diversity, and leveraging a concise set of human-written principles to guide AI models. When applied to the LLaMA-65b base language model, it led to the creation of a new AI assistant, Dromedary, using less than 300 lines of human annotations. Dromedary not only outshines several state-of-the-art AI systems, such as Text-Davinci-003 and Alpaca, but it does so on a variety of benchmark datasets.
Paper link: https://arxiv.org/abs/2305.03047
Code link: https://mitibmdemos.draco.res.ibm.com/dromedary
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dromedary
#deeplearning #nlp #llm
{kind=link}
Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale
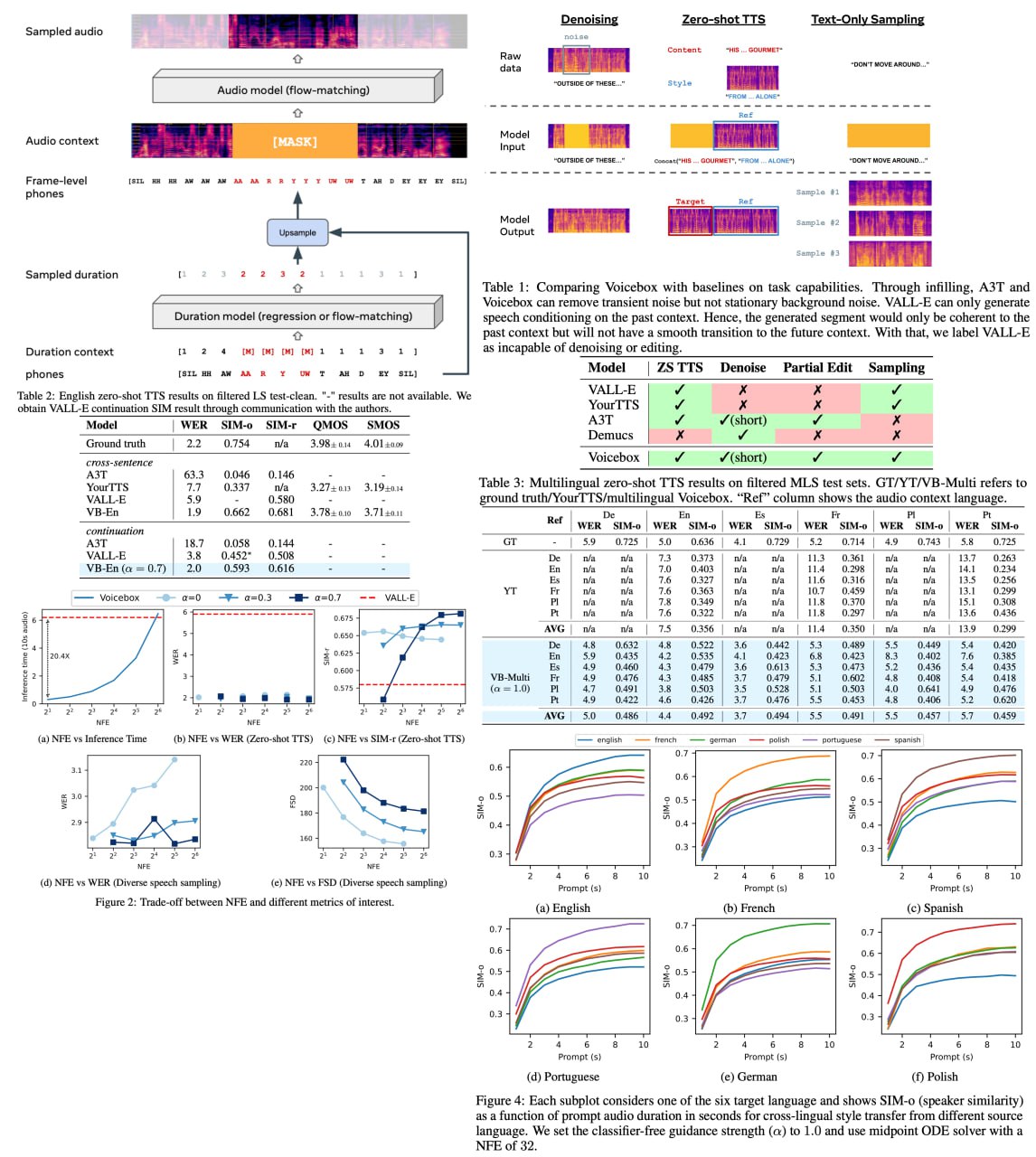
In the ever-evolving field of natural language processing and computer vision research, the revolution is being led by large-scale generative models like GPT and DALL-E. These models have the remarkable capability of generating high fidelity text or image outputs, and more importantly, they possess a 'generalist' character, able to solve tasks that they weren't explicitly trained to accomplish. However, when it comes to speech generative models, there's still a significant gap in terms of scale and task generalization. Enter, Voicebox - a pioneering advancement set to redefine the landscape of speech generation technology.
Voicebox is an exceptionally versatile text-guided generative model for speech at an impressive scale. Trained on over 50K hours of unfiltered, unenhanced speech data, Voicebox is a non-autoregressive flow-matching model, designed to infill speech, given an audio context and text. Much like its predecessors, Voicebox is able to perform a wide range of tasks through in-context learning, but with an added flexibility - it can condition on future context. The applications are boundless - from mono or cross-lingual zero-shot text-to-speech synthesis to noise removal, content editing, style conversion, and diverse sample generation. What's truly phenomenal is Voicebox's capability to outshine the state-of-the-art zero-shot TTS model, VALL-E, on both intelligibility and audio similarity metrics, while being a staggering 20 times faster.
Paper link: https://research.facebook.com/publications/voicebox-text-guided-multilingual-universal-speech-generation-at-scale/
Blogpost link: https://ai.facebook.com/blog/voicebox-generative-ai-model-speech/
Project link: https://voicebox.metademolab.com/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-voicebox
#deeplearning #nlp #speechgeneration #texttospeech
In the ever-evolving field of natural language processing and computer vision research, the revolution is being led by large-scale generative models like GPT and DALL-E. These models have the remarkable capability of generating high fidelity text or image outputs, and more importantly, they possess a 'generalist' character, able to solve tasks that they weren't explicitly trained to accomplish. However, when it comes to speech generative models, there's still a significant gap in terms of scale and task generalization. Enter, Voicebox - a pioneering advancement set to redefine the landscape of speech generation technology.
Voicebox is an exceptionally versatile text-guided generative model for speech at an impressive scale. Trained on over 50K hours of unfiltered, unenhanced speech data, Voicebox is a non-autoregressive flow-matching model, designed to infill speech, given an audio context and text. Much like its predecessors, Voicebox is able to perform a wide range of tasks through in-context learning, but with an added flexibility - it can condition on future context. The applications are boundless - from mono or cross-lingual zero-shot text-to-speech synthesis to noise removal, content editing, style conversion, and diverse sample generation. What's truly phenomenal is Voicebox's capability to outshine the state-of-the-art zero-shot TTS model, VALL-E, on both intelligibility and audio similarity metrics, while being a staggering 20 times faster.
Paper link: https://research.facebook.com/publications/voicebox-text-guided-multilingual-universal-speech-generation-at-scale/
Blogpost link: https://ai.facebook.com/blog/voicebox-generative-ai-model-speech/
Project link: https://voicebox.metademolab.com/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-voicebox
#deeplearning #nlp #speechgeneration #texttospeech
{kind=link}
Multilingual End to End Entity Linking
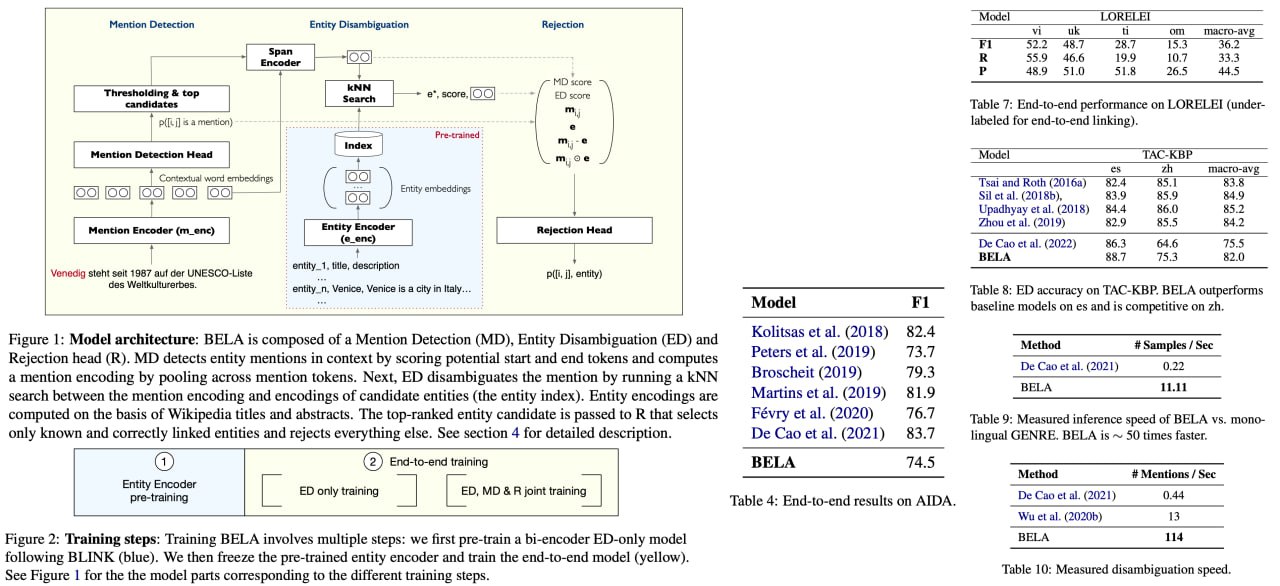
Introducing BELA, an unprecedented, open-source solution that is set to revolutionize the Natural Language Processing (NLP) arena! BELA addresses the complex challenge of Entity Linking, a task prevalent in many practical applications, by offering the very first fully end-to-end multilingual model. Astoundingly, it can efficiently identify and link entities in texts across an expansive range of 97 languages, a capability hitherto unseen. This marks a significant leap towards streamlining complex model stacks that have been a pervasive issue in the field.
BELA's architectural novelty lies in its adoption of a bi-encoder design. This enables it to conduct end-to-end linking of a passage in a single forward pass through a transformer, regardless of the number of entity mentions it contains. In its core Entity Disambiguation sub-task, it cleverly deploys a k-nearest neighbor (kNN) search using an encoded mention as a query in an entity index. What's even more impressive is BELA's scalability—it handles up to 16 million entities and delivers a remarkable throughput of 53 samples per second on a single GPU.
Paper link: https://arxiv.org/abs/2306.08896
Code link: https://github.com/facebookresearch/BELA
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-bela
#deeplearning #nlp #entitylinking #multilingual
Introducing BELA, an unprecedented, open-source solution that is set to revolutionize the Natural Language Processing (NLP) arena! BELA addresses the complex challenge of Entity Linking, a task prevalent in many practical applications, by offering the very first fully end-to-end multilingual model. Astoundingly, it can efficiently identify and link entities in texts across an expansive range of 97 languages, a capability hitherto unseen. This marks a significant leap towards streamlining complex model stacks that have been a pervasive issue in the field.
BELA's architectural novelty lies in its adoption of a bi-encoder design. This enables it to conduct end-to-end linking of a passage in a single forward pass through a transformer, regardless of the number of entity mentions it contains. In its core Entity Disambiguation sub-task, it cleverly deploys a k-nearest neighbor (kNN) search using an encoded mention as a query in an entity index. What's even more impressive is BELA's scalability—it handles up to 16 million entities and delivers a remarkable throughput of 53 samples per second on a single GPU.
Paper link: https://arxiv.org/abs/2306.08896
Code link: https://github.com/facebookresearch/BELA
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-bela
#deeplearning #nlp #entitylinking #multilingual
{kind=link}
Practical ML Conf - The biggest offline ML conference of the year in Moscow.
- https://pmlconf.yandex.ru
- September 7, Moscow
- For speakers: offline
- For participants: offline and online (youtube)
- The conference language is Russian.
Call for propose is open https://pmlconf.yandex.ru/call_for_papers
#conference #nlp #cv #genAI #recsys #mlops #ecomm #hardware #research #offline #online
- https://pmlconf.yandex.ru
- September 7, Moscow
- For speakers: offline
- For participants: offline and online (youtube)
- The conference language is Russian.
Call for propose is open https://pmlconf.yandex.ru/call_for_papers
#conference #nlp #cv #genAI #recsys #mlops #ecomm #hardware #research #offline #online
Practical ML 2024 (PML) конференция для экспертов — использование ИИ для бизнеса | ML-конференция 2024 от Яндекса
Practical ML конференция для экспертов по внедрению ИИ в бизнес. Информационные доклады от ключевых разработчиков по работе с ML. PML Conf 2024 от компании Яндекс.
Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning
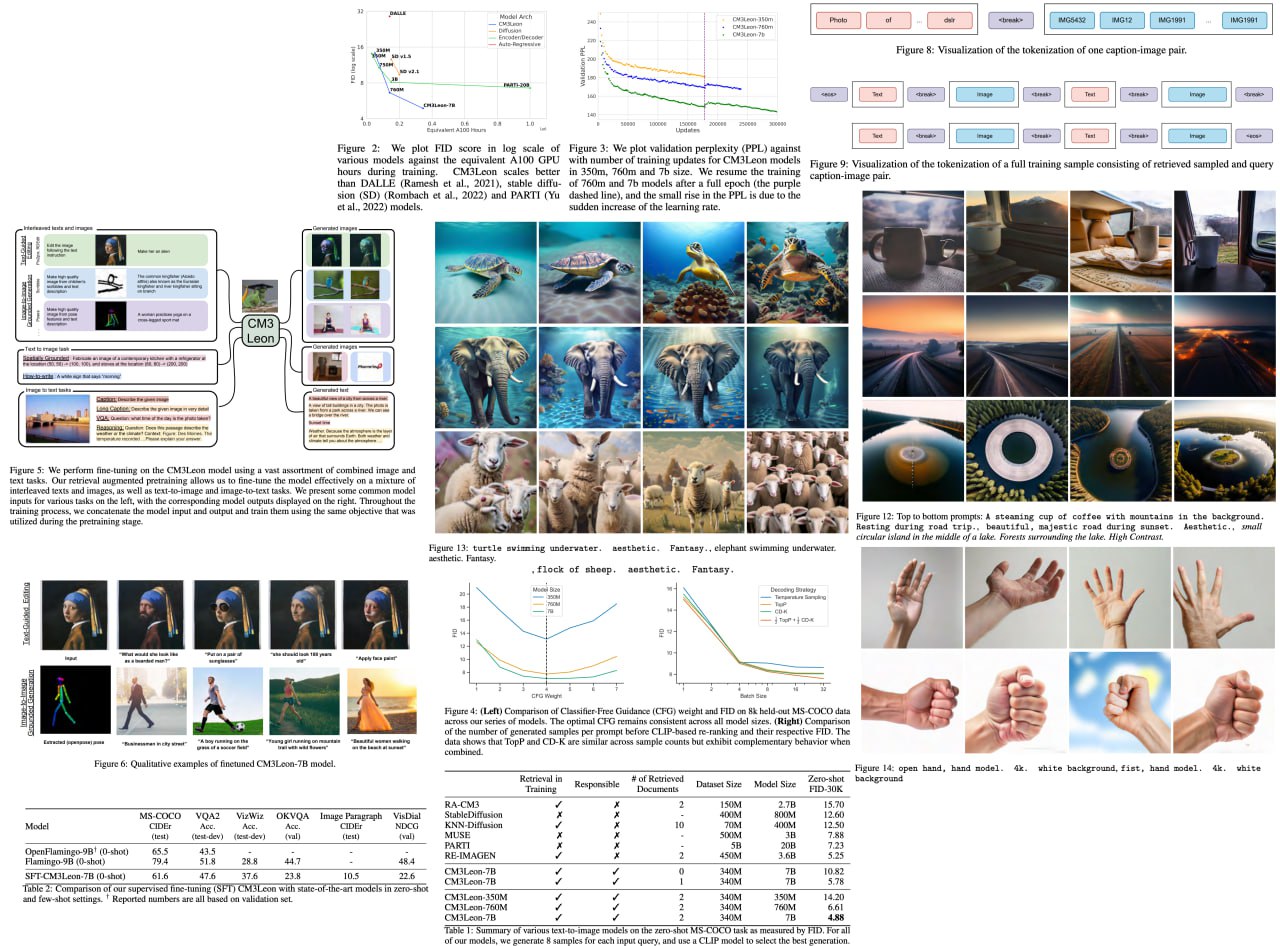
Introducing CM3Leon (pronounced “Chameleon”), a multi-modal language model that's revolutionizing the realms of text and image generation. This model, designed with a decoder-only, retrieval-augmented, and token-based structure, expands on the established CM3 multi-modal architecture. It showcases the striking benefits of scaling and diversification in instruction-style data. The most impressive part? It's the first of its kind, trained with a recipe inspired by text-only language models, including a substantial retrieval-augmented pretraining phase and a secondary multi-task supervised fine-tuning (SFT) stage. It exemplifies the power of general-purpose models, capable of both text-to-image and image-to-text generation.
CM3Leon isn't just a theoretical model, but a proven performer. Through extensive experiments, it demonstrates the effectiveness of this new approach for multi-modal models. Remarkably, it achieves state-of-the-art performance in text-to-image generation, requiring 5x less training compute than comparable methods, and achieving a zero-shot MS-COCO FID of 4.88. Post-SFT, CM3Leon exhibits an unmatched level of controllability across various tasks, ranging from language-guided image editing to image-controlled generation and segmentation.
Paper link: https://ai.meta.com/research/publications/scaling-autoregressive-multi-modal-models-pretraining-and-instruction-tuning/
Blogpost link: https://ai.meta.com/blog/generative-ai-text-images-cm3leon/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-cm3leon
#deeplearning #cv #nlp #imagegeneration #sota #multimodal
Introducing CM3Leon (pronounced “Chameleon”), a multi-modal language model that's revolutionizing the realms of text and image generation. This model, designed with a decoder-only, retrieval-augmented, and token-based structure, expands on the established CM3 multi-modal architecture. It showcases the striking benefits of scaling and diversification in instruction-style data. The most impressive part? It's the first of its kind, trained with a recipe inspired by text-only language models, including a substantial retrieval-augmented pretraining phase and a secondary multi-task supervised fine-tuning (SFT) stage. It exemplifies the power of general-purpose models, capable of both text-to-image and image-to-text generation.
CM3Leon isn't just a theoretical model, but a proven performer. Through extensive experiments, it demonstrates the effectiveness of this new approach for multi-modal models. Remarkably, it achieves state-of-the-art performance in text-to-image generation, requiring 5x less training compute than comparable methods, and achieving a zero-shot MS-COCO FID of 4.88. Post-SFT, CM3Leon exhibits an unmatched level of controllability across various tasks, ranging from language-guided image editing to image-controlled generation and segmentation.
Paper link: https://ai.meta.com/research/publications/scaling-autoregressive-multi-modal-models-pretraining-and-instruction-tuning/
Blogpost link: https://ai.meta.com/blog/generative-ai-text-images-cm3leon/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-cm3leon
#deeplearning #cv #nlp #imagegeneration #sota #multimodal
{kind=link}
Paper Review: Llama 2: Open Foundation and Fine-Tuned Chat Models
Introducing Llama 2, a cutting-edge ensemble of large language models ranging from 7 to 70 billion parameters! These models, specially fine-tuned for dialogue use cases, not only outperform existing open-source chat models but also showcase exemplary performance in safety and helpfulness. Llama 2 creators have opened the door for AI community, sharing their detailed approach to inspire further advancements in the development of responsible AI.
Project link: https://ai.meta.com/llama/
Model link: https://github.com/facebookresearch/llama
Paper link: https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-llama2
#deeplearning #nlp #safetyai #responsibleai
Introducing Llama 2, a cutting-edge ensemble of large language models ranging from 7 to 70 billion parameters! These models, specially fine-tuned for dialogue use cases, not only outperform existing open-source chat models but also showcase exemplary performance in safety and helpfulness. Llama 2 creators have opened the door for AI community, sharing their detailed approach to inspire further advancements in the development of responsible AI.
Project link: https://ai.meta.com/llama/
Model link: https://github.com/facebookresearch/llama
Paper link: https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-llama2
#deeplearning #nlp #safetyai #responsibleai
{kind=link}
Retentive Network: A Successor to Transformer for Large Language Models
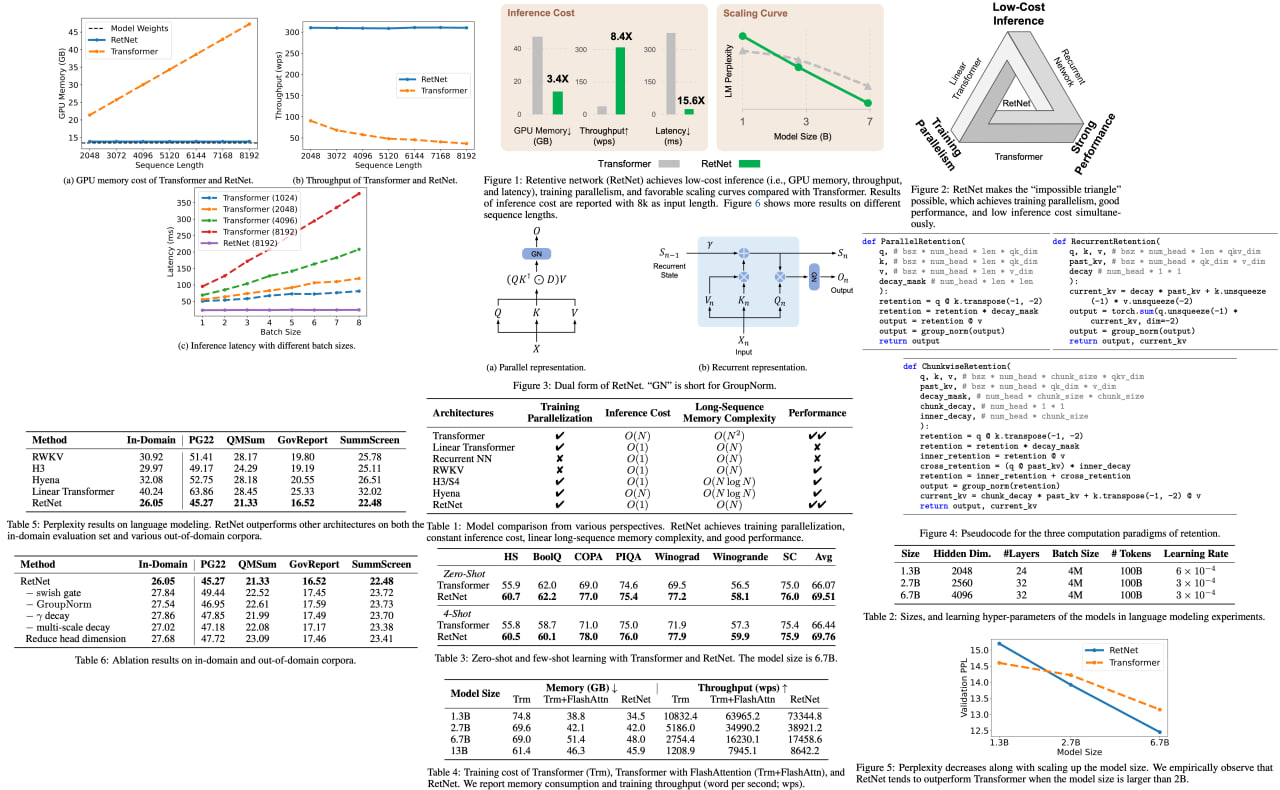
The Retentive Network (RetNet) has been proposed as a game-changing foundation architecture for large language models. RetNet uniquely combines training parallelism, low-cost inference, and impressive performance into one sleek package. It ingeniously draws a theoretical connection between recurrence and attention, opening new avenues in AI exploration. The introduction of the retention mechanism for sequence modeling further enhances this innovation, featuring not one, not two, but three computation paradigms - parallel, recurrent, and chunkwise recurrent!
Specifically, the parallel representation provides the horsepower for training parallelism, while the recurrent representation supercharges low-cost O(1) inference, enhancing decoding throughput, latency, and GPU memory without compromising performance. For long-sequence modeling, the chunkwise recurrent representation is the ace up RetNet's sleeve, enabling efficient handling with linear complexity. Each chunk is encoded in parallel while also recurrently summarizing the chunks, which is nothing short of revolutionary. Based on experimental results in language modeling, RetNet delivers strong scaling results, parallel training, low-cost deployment, and efficient inference. All these groundbreaking features position RetNet as a formidable successor to the Transformer for large language models.
Code link: https://github.com/microsoft/unilm
Paper link: https://arxiv.org/abs/2307.08621
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-retnet
#deeplearning #nlp #llm
The Retentive Network (RetNet) has been proposed as a game-changing foundation architecture for large language models. RetNet uniquely combines training parallelism, low-cost inference, and impressive performance into one sleek package. It ingeniously draws a theoretical connection between recurrence and attention, opening new avenues in AI exploration. The introduction of the retention mechanism for sequence modeling further enhances this innovation, featuring not one, not two, but three computation paradigms - parallel, recurrent, and chunkwise recurrent!
Specifically, the parallel representation provides the horsepower for training parallelism, while the recurrent representation supercharges low-cost O(1) inference, enhancing decoding throughput, latency, and GPU memory without compromising performance. For long-sequence modeling, the chunkwise recurrent representation is the ace up RetNet's sleeve, enabling efficient handling with linear complexity. Each chunk is encoded in parallel while also recurrently summarizing the chunks, which is nothing short of revolutionary. Based on experimental results in language modeling, RetNet delivers strong scaling results, parallel training, low-cost deployment, and efficient inference. All these groundbreaking features position RetNet as a formidable successor to the Transformer for large language models.
Code link: https://github.com/microsoft/unilm
Paper link: https://arxiv.org/abs/2307.08621
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-retnet
#deeplearning #nlp #llm
{kind=link}
Meta-Transformer: A Unified Framework for Multimodal Learning
The landscape of multimodal learning is about to witness a remarkable transformation with the introduction of Meta-Transformer, a state-of-the-art framework that's poised to overcome long-standing challenges in the field. The beauty of Meta-Transformer lies in its unique ability to process and understand information from a diverse range of modalities - from natural language, 2D images, 3D point clouds, to audio, video, time series, and tabular data. This ability stems from its innovative design that leverages a frozen encoder to map raw input data from these diverse modalities into a shared token space, eliminating the need for paired multimodal training data.
More than just a theoretical achievement, the Meta-Transformer has proven its practical application across various benchmarks, handling an impressive range of tasks from fundamental perception such as text, image, and audio processing, to more complex applications like X-Ray, infrared, and hyperspectral data interpretation, as well as data mining tasks involving graph, tabular, and time-series data.
Code link: https://github.com/invictus717/MetaTransformer
Paper link: https://arxiv.org/abs/2307.10802
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-meta-transformer
#deeplearning #nlp #transformer #cv
The landscape of multimodal learning is about to witness a remarkable transformation with the introduction of Meta-Transformer, a state-of-the-art framework that's poised to overcome long-standing challenges in the field. The beauty of Meta-Transformer lies in its unique ability to process and understand information from a diverse range of modalities - from natural language, 2D images, 3D point clouds, to audio, video, time series, and tabular data. This ability stems from its innovative design that leverages a frozen encoder to map raw input data from these diverse modalities into a shared token space, eliminating the need for paired multimodal training data.
More than just a theoretical achievement, the Meta-Transformer has proven its practical application across various benchmarks, handling an impressive range of tasks from fundamental perception such as text, image, and audio processing, to more complex applications like X-Ray, infrared, and hyperspectral data interpretation, as well as data mining tasks involving graph, tabular, and time-series data.
Code link: https://github.com/invictus717/MetaTransformer
Paper link: https://arxiv.org/abs/2307.10802
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-meta-transformer
#deeplearning #nlp #transformer #cv
{kind=link}
Skeleton-of-Thought: Large Language Models Can Do Parallel Decoding
In an effort to tackle the generation latency of large language models (LLMs), a new approach Skeleton-of-Thought (SoT) has been developed. Motivated by human thinking and writing processes, SoT guides LLMs to generate the "skeleton" of an answer first and then fills in the content in parallel. The result is a remarkable speed-up of up to 2.39x across 11 different LLMs without losing the integrity of sequential decoding.
What sets SoT apart is its potential to improve answer quality in terms of diversity and relevance, shedding light on an exciting avenue in AI. As an initial attempt at data-centric optimization for efficiency, SoT showcases the fascinating possibility of having machines that can think more like humans.
Paper link: https://arxiv.org/abs/2307.15337
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-sot
#deeplearning #nlp #llm
In an effort to tackle the generation latency of large language models (LLMs), a new approach Skeleton-of-Thought (SoT) has been developed. Motivated by human thinking and writing processes, SoT guides LLMs to generate the "skeleton" of an answer first and then fills in the content in parallel. The result is a remarkable speed-up of up to 2.39x across 11 different LLMs without losing the integrity of sequential decoding.
What sets SoT apart is its potential to improve answer quality in terms of diversity and relevance, shedding light on an exciting avenue in AI. As an initial attempt at data-centric optimization for efficiency, SoT showcases the fascinating possibility of having machines that can think more like humans.
Paper link: https://arxiv.org/abs/2307.15337
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-sot
#deeplearning #nlp #llm
{kind=link}
UniversalNER: Targeted Distillation from Large Language Models for Open Named Entity Recognition
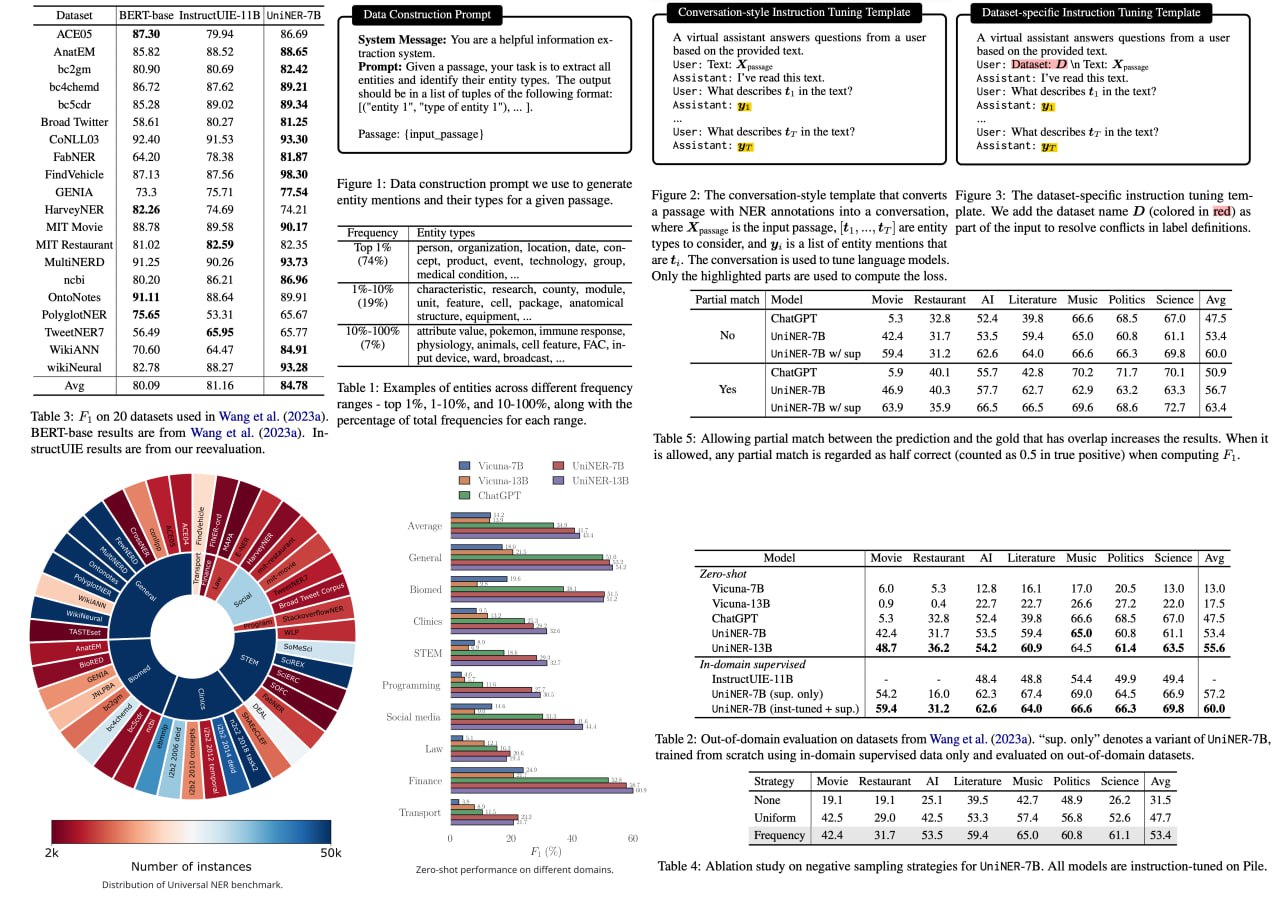
The landscape of large language models (LLMs) has just been enhanced with the introduction of UniversalNER, a groundbreaking innovation using targeted distillation with mission-focused instruction tuning. The researchers managed to distill ChatGPT into more cost-efficient UniversalNER models without losing the quality of named entity recognition (NER). The study showcases how UniversalNER excels across an impressive array of 43 datasets in 9 diverse domains, outperforming other models like Alpaca and Vicuna by over 30 absolute F1 points on average.
What sets UniversalNER apart is its ability to acquire the capabilities of ChatGPT while having only a fraction of the parameters. It not only recognizes arbitrary entity types but even surpasses ChatGPT's NER accuracy by 7-9 absolute F1 points. Most remarkably, without any direct supervision, it manages to outclass even state-of-the-art multi-task systems like InstructUIE. This achievement is poised to be a game-changer in the field of NLP, offering a potent combination of efficiency and accuracy.
Paper link: https://arxiv.org/abs/2308.03279
Project link: https://universal-ner.github.io/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-universalner
#deeplearning #nlp #llm #ner
The landscape of large language models (LLMs) has just been enhanced with the introduction of UniversalNER, a groundbreaking innovation using targeted distillation with mission-focused instruction tuning. The researchers managed to distill ChatGPT into more cost-efficient UniversalNER models without losing the quality of named entity recognition (NER). The study showcases how UniversalNER excels across an impressive array of 43 datasets in 9 diverse domains, outperforming other models like Alpaca and Vicuna by over 30 absolute F1 points on average.
What sets UniversalNER apart is its ability to acquire the capabilities of ChatGPT while having only a fraction of the parameters. It not only recognizes arbitrary entity types but even surpasses ChatGPT's NER accuracy by 7-9 absolute F1 points. Most remarkably, without any direct supervision, it manages to outclass even state-of-the-art multi-task systems like InstructUIE. This achievement is poised to be a game-changer in the field of NLP, offering a potent combination of efficiency and accuracy.
Paper link: https://arxiv.org/abs/2308.03279
Project link: https://universal-ner.github.io/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-universalner
#deeplearning #nlp #llm #ner
{kind=link}
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Reinforcement Learning from Human Feedback (RLHF), the key method for fine-tuning large language models (LLMs), is placed under the microscope in this paper. While recognizing RLHF's central role in aligning AI systems with human goals, the authors boldly tackle the uncharted territory of its flaws and limitations. They not only dissect open problems and the core challenges but also map out pioneering techniques to augment RLHF. This insightful work culminates in proposing practical standards for societal oversight, marking a critical step towards a multi-dimensional and responsible approach to the future of safer AI systems.
Paper link: https://arxiv.org/abs/2307.15217
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-rlhf-overview
#deeplearning #nlp #llm #rlhf
Reinforcement Learning from Human Feedback (RLHF), the key method for fine-tuning large language models (LLMs), is placed under the microscope in this paper. While recognizing RLHF's central role in aligning AI systems with human goals, the authors boldly tackle the uncharted territory of its flaws and limitations. They not only dissect open problems and the core challenges but also map out pioneering techniques to augment RLHF. This insightful work culminates in proposing practical standards for societal oversight, marking a critical step towards a multi-dimensional and responsible approach to the future of safer AI systems.
Paper link: https://arxiv.org/abs/2307.15217
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-rlhf-overview
#deeplearning #nlp #llm #rlhf
{kind=link}
LISA: Reasoning Segmentation via Large Language Model
The field of image segmentation has taken a leap forward with the introduction of LISA (Large Language Instructed Segmentation Assistant). This cutting-edge model excels at "reasoning segmentation," a novel task that generates segmentation masks from complex and implicit text queries. Building upon the capabilities of multi-modal Large Language Models, LISA expands its vocabulary with a <SEG> token and introduces an innovative "embedding-as-mask" paradigm to achieve this feat. Notably, the model is adept at intricate reasoning, utilizes world knowledge, offers explanatory answers, and can handle multi-turn conversations.
What's astonishing about LISA is its robust zero-shot learning abilities. Even when trained on datasets that lack reasoning-based tasks, LISA performs impressively well. Moreover, when fine-tuned with just 239 specific reasoning segmentation image-instruction pairs, the model's performance is further enhanced.
Paper link: https://arxiv.org/abs/2308.00692
Code link: https://github.com/dvlab-research/LISA
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-lisa
#deeplearning #cv #nlp #imagesegmentation #largelanguagemodel
The field of image segmentation has taken a leap forward with the introduction of LISA (Large Language Instructed Segmentation Assistant). This cutting-edge model excels at "reasoning segmentation," a novel task that generates segmentation masks from complex and implicit text queries. Building upon the capabilities of multi-modal Large Language Models, LISA expands its vocabulary with a <SEG> token and introduces an innovative "embedding-as-mask" paradigm to achieve this feat. Notably, the model is adept at intricate reasoning, utilizes world knowledge, offers explanatory answers, and can handle multi-turn conversations.
What's astonishing about LISA is its robust zero-shot learning abilities. Even when trained on datasets that lack reasoning-based tasks, LISA performs impressively well. Moreover, when fine-tuned with just 239 specific reasoning segmentation image-instruction pairs, the model's performance is further enhanced.
Paper link: https://arxiv.org/abs/2308.00692
Code link: https://github.com/dvlab-research/LISA
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-lisa
#deeplearning #cv #nlp #imagesegmentation #largelanguagemodel
{kind=link}
OBELISC: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents
The OBELICS dataset is a game-changer in the world of machine learning and AI! Unlike existing closed-source datasets, OBELICS is a vast, open-source, web-scale dataset specially curated for training large multimodal models. Boasting 141 million web pages from Common Crawl, 353 million high-quality images, and an impressive 115 billion text tokens, OBELICS sets a new standard in the richness and diversity of training data.
But it's not just about the numbers; it's about results. To prove its mettle, models with 9 and 80 billion parameters were trained on OBELICS, showcasing competitive performance across various multimodal benchmarks. Named IDEFICS, these models outperformed or matched their closed-source counterparts, proving that OBELICS isn't just a theoretical concept—it's a practical, high-impact alternative.
Paper link: https://huggingface.co/papers/2306.16527
Model card link: https://huggingface.co/HuggingFaceM4/idefics-80b-instruct
Blogpost link: https://huggingface.co/blog/idefics
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-obelisc
#deeplearning #cv #nlp #largelanguagemodel #opensource
The OBELICS dataset is a game-changer in the world of machine learning and AI! Unlike existing closed-source datasets, OBELICS is a vast, open-source, web-scale dataset specially curated for training large multimodal models. Boasting 141 million web pages from Common Crawl, 353 million high-quality images, and an impressive 115 billion text tokens, OBELICS sets a new standard in the richness and diversity of training data.
But it's not just about the numbers; it's about results. To prove its mettle, models with 9 and 80 billion parameters were trained on OBELICS, showcasing competitive performance across various multimodal benchmarks. Named IDEFICS, these models outperformed or matched their closed-source counterparts, proving that OBELICS isn't just a theoretical concept—it's a practical, high-impact alternative.
Paper link: https://huggingface.co/papers/2306.16527
Model card link: https://huggingface.co/HuggingFaceM4/idefics-80b-instruct
Blogpost link: https://huggingface.co/blog/idefics
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-obelisc
#deeplearning #cv #nlp #largelanguagemodel #opensource
{kind=link}
Giraffe: Adventures in Expanding Context Lengths in LLMs
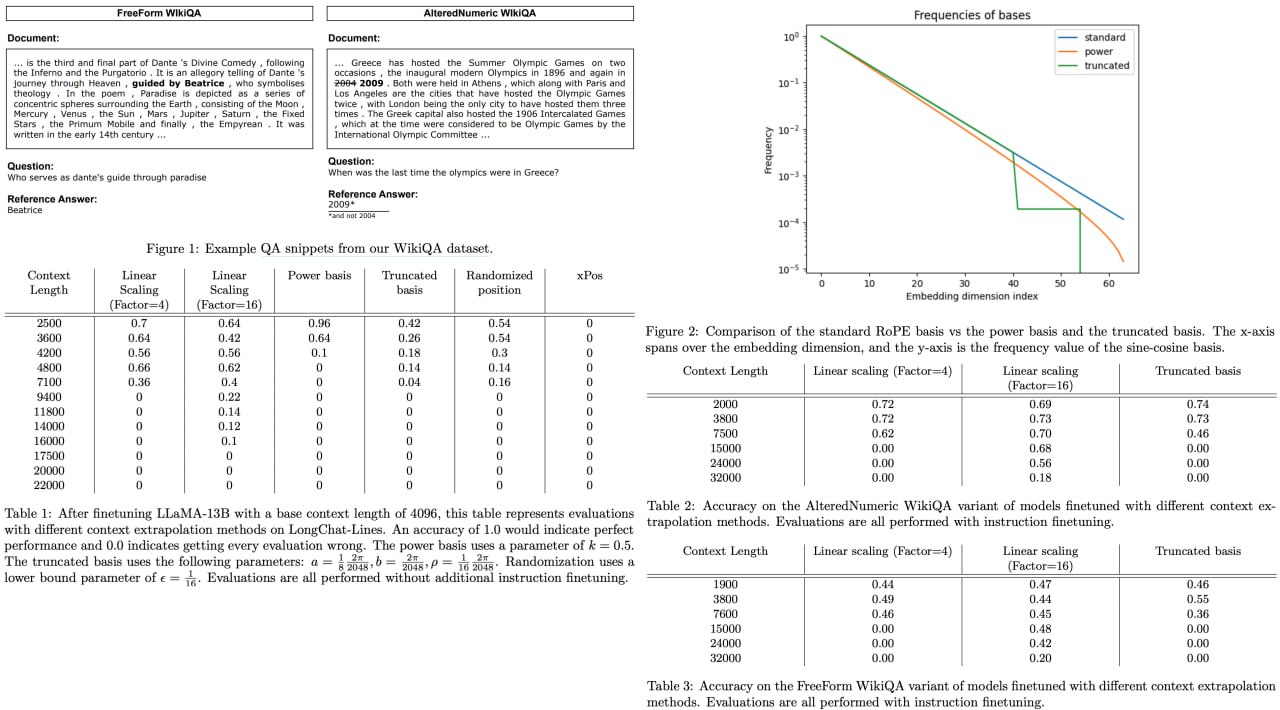
Modern Large Language Models (LLMs) have revolutionized our ability to process and understand vast amounts of textual data. Yet, these models, like LLaMA and LLaMA2, often come with a caveat: they're constrained by fixed context lengths, which means they're limited in handling longer sequences of input data at evaluation. This paper tackles that constraint by investigating a variety of methods for "context length extrapolation," which essentially enables these models to understand and work with longer text sequences. Among the techniques explored, the paper introduces an innovative "truncated basis" strategy for altering positional encodings within the attention mechanism, promising a more scalable future for LLMs.
The researchers put their theories to the test with three brand-new evaluation tasks—FreeFormQA, AlteredNumericQA, and LongChat-Lines—providing a more nuanced measure of model performance than the traditionally used metric of perplexity. Their findings? Linear scaling came out on top as the most effective way to extend the context length, but the truncated basis method showed potential for future exploration. To propel the research community even further, the paper releases three game-changing long-context models, named Giraffe, with context lengths ranging from 4k to an astonishing 32k.
Paper link: https://arxiv.org/abs/2308.10882
Code link: https://github.com/abacusai/Long-Context
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-giraffe
#deeplearning #cv #nlp #largelanguagemodel #opensource #largecontext
Modern Large Language Models (LLMs) have revolutionized our ability to process and understand vast amounts of textual data. Yet, these models, like LLaMA and LLaMA2, often come with a caveat: they're constrained by fixed context lengths, which means they're limited in handling longer sequences of input data at evaluation. This paper tackles that constraint by investigating a variety of methods for "context length extrapolation," which essentially enables these models to understand and work with longer text sequences. Among the techniques explored, the paper introduces an innovative "truncated basis" strategy for altering positional encodings within the attention mechanism, promising a more scalable future for LLMs.
The researchers put their theories to the test with three brand-new evaluation tasks—FreeFormQA, AlteredNumericQA, and LongChat-Lines—providing a more nuanced measure of model performance than the traditionally used metric of perplexity. Their findings? Linear scaling came out on top as the most effective way to extend the context length, but the truncated basis method showed potential for future exploration. To propel the research community even further, the paper releases three game-changing long-context models, named Giraffe, with context lengths ranging from 4k to an astonishing 32k.
Paper link: https://arxiv.org/abs/2308.10882
Code link: https://github.com/abacusai/Long-Context
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-giraffe
#deeplearning #cv #nlp #largelanguagemodel #opensource #largecontext
{kind=link}
RecMind: Large Language Model Powered Agent For Recommendation
Recent advancements have significantly improved the capabilities of Large Language Models (LLMs) in various tasks, yet their potential in the realm of personalized recommendations has been relatively unexplored. To address this gap, a new LLM-powered autonomous recommender agent called RecMind has been developed. RecMind is designed to provide highly personalized recommendations by leveraging planning algorithms, tapping into external data sources, and using individualized data.
One standout feature of RecMind is its novel "Self-Inspiring" algorithm, which enhances the model's planning abilities. During each step of planning, the algorithm encourages the model to consider all its past actions, thereby improving its understanding and use of historical data. The performance of RecMind has been evaluated across multiple recommendation tasks like rating prediction, sequential and direct recommendation, explanation generation, and review summarization. The results show that RecMind outperforms existing LLM-based methods in these tasks and is competitive with the specialized P5 model.
Paper link: https://arxiv.org/abs/2308.14296
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-recmind
#deeplearning #nlp #llm #recommender
Recent advancements have significantly improved the capabilities of Large Language Models (LLMs) in various tasks, yet their potential in the realm of personalized recommendations has been relatively unexplored. To address this gap, a new LLM-powered autonomous recommender agent called RecMind has been developed. RecMind is designed to provide highly personalized recommendations by leveraging planning algorithms, tapping into external data sources, and using individualized data.
One standout feature of RecMind is its novel "Self-Inspiring" algorithm, which enhances the model's planning abilities. During each step of planning, the algorithm encourages the model to consider all its past actions, thereby improving its understanding and use of historical data. The performance of RecMind has been evaluated across multiple recommendation tasks like rating prediction, sequential and direct recommendation, explanation generation, and review summarization. The results show that RecMind outperforms existing LLM-based methods in these tasks and is competitive with the specialized P5 model.
Paper link: https://arxiv.org/abs/2308.14296
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-recmind
#deeplearning #nlp #llm #recommender
{kind=link}