
LISA: Reasoning Segmentation via Large Language Model
The field of image segmentation has taken a leap forward with the introduction of LISA (Large Language Instructed Segmentation Assistant). This cutting-edge model excels at "reasoning segmentation," a novel task that generates segmentation masks from complex and implicit text queries. Building upon the capabilities of multi-modal Large Language Models, LISA expands its vocabulary with a <SEG> token and introduces an innovative "embedding-as-mask" paradigm to achieve this feat. Notably, the model is adept at intricate reasoning, utilizes world knowledge, offers explanatory answers, and can handle multi-turn conversations.
What's astonishing about LISA is its robust zero-shot learning abilities. Even when trained on datasets that lack reasoning-based tasks, LISA performs impressively well. Moreover, when fine-tuned with just 239 specific reasoning segmentation image-instruction pairs, the model's performance is further enhanced.
Paper link: https://arxiv.org/abs/2308.00692
Code link: https://github.com/dvlab-research/LISA
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-lisa
#deeplearning #cv #nlp #imagesegmentation #largelanguagemodel
The field of image segmentation has taken a leap forward with the introduction of LISA (Large Language Instructed Segmentation Assistant). This cutting-edge model excels at "reasoning segmentation," a novel task that generates segmentation masks from complex and implicit text queries. Building upon the capabilities of multi-modal Large Language Models, LISA expands its vocabulary with a <SEG> token and introduces an innovative "embedding-as-mask" paradigm to achieve this feat. Notably, the model is adept at intricate reasoning, utilizes world knowledge, offers explanatory answers, and can handle multi-turn conversations.
What's astonishing about LISA is its robust zero-shot learning abilities. Even when trained on datasets that lack reasoning-based tasks, LISA performs impressively well. Moreover, when fine-tuned with just 239 specific reasoning segmentation image-instruction pairs, the model's performance is further enhanced.
Paper link: https://arxiv.org/abs/2308.00692
Code link: https://github.com/dvlab-research/LISA
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-lisa
#deeplearning #cv #nlp #imagesegmentation #largelanguagemodel
{kind=link}
OBELISC: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents
The OBELICS dataset is a game-changer in the world of machine learning and AI! Unlike existing closed-source datasets, OBELICS is a vast, open-source, web-scale dataset specially curated for training large multimodal models. Boasting 141 million web pages from Common Crawl, 353 million high-quality images, and an impressive 115 billion text tokens, OBELICS sets a new standard in the richness and diversity of training data.
But it's not just about the numbers; it's about results. To prove its mettle, models with 9 and 80 billion parameters were trained on OBELICS, showcasing competitive performance across various multimodal benchmarks. Named IDEFICS, these models outperformed or matched their closed-source counterparts, proving that OBELICS isn't just a theoretical concept—it's a practical, high-impact alternative.
Paper link: https://huggingface.co/papers/2306.16527
Model card link: https://huggingface.co/HuggingFaceM4/idefics-80b-instruct
Blogpost link: https://huggingface.co/blog/idefics
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-obelisc
#deeplearning #cv #nlp #largelanguagemodel #opensource
The OBELICS dataset is a game-changer in the world of machine learning and AI! Unlike existing closed-source datasets, OBELICS is a vast, open-source, web-scale dataset specially curated for training large multimodal models. Boasting 141 million web pages from Common Crawl, 353 million high-quality images, and an impressive 115 billion text tokens, OBELICS sets a new standard in the richness and diversity of training data.
But it's not just about the numbers; it's about results. To prove its mettle, models with 9 and 80 billion parameters were trained on OBELICS, showcasing competitive performance across various multimodal benchmarks. Named IDEFICS, these models outperformed or matched their closed-source counterparts, proving that OBELICS isn't just a theoretical concept—it's a practical, high-impact alternative.
Paper link: https://huggingface.co/papers/2306.16527
Model card link: https://huggingface.co/HuggingFaceM4/idefics-80b-instruct
Blogpost link: https://huggingface.co/blog/idefics
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-obelisc
#deeplearning #cv #nlp #largelanguagemodel #opensource
{kind=link}
Giraffe: Adventures in Expanding Context Lengths in LLMs
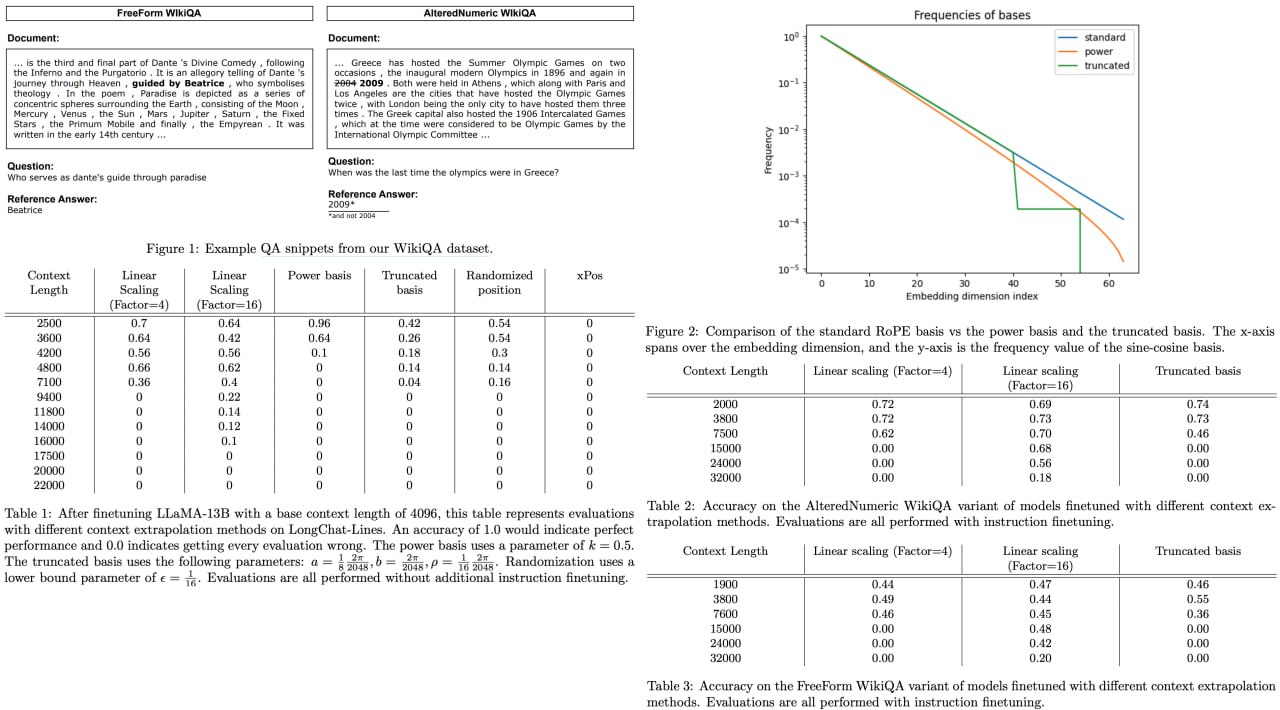
Modern Large Language Models (LLMs) have revolutionized our ability to process and understand vast amounts of textual data. Yet, these models, like LLaMA and LLaMA2, often come with a caveat: they're constrained by fixed context lengths, which means they're limited in handling longer sequences of input data at evaluation. This paper tackles that constraint by investigating a variety of methods for "context length extrapolation," which essentially enables these models to understand and work with longer text sequences. Among the techniques explored, the paper introduces an innovative "truncated basis" strategy for altering positional encodings within the attention mechanism, promising a more scalable future for LLMs.
The researchers put their theories to the test with three brand-new evaluation tasks—FreeFormQA, AlteredNumericQA, and LongChat-Lines—providing a more nuanced measure of model performance than the traditionally used metric of perplexity. Their findings? Linear scaling came out on top as the most effective way to extend the context length, but the truncated basis method showed potential for future exploration. To propel the research community even further, the paper releases three game-changing long-context models, named Giraffe, with context lengths ranging from 4k to an astonishing 32k.
Paper link: https://arxiv.org/abs/2308.10882
Code link: https://github.com/abacusai/Long-Context
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-giraffe
#deeplearning #cv #nlp #largelanguagemodel #opensource #largecontext
Modern Large Language Models (LLMs) have revolutionized our ability to process and understand vast amounts of textual data. Yet, these models, like LLaMA and LLaMA2, often come with a caveat: they're constrained by fixed context lengths, which means they're limited in handling longer sequences of input data at evaluation. This paper tackles that constraint by investigating a variety of methods for "context length extrapolation," which essentially enables these models to understand and work with longer text sequences. Among the techniques explored, the paper introduces an innovative "truncated basis" strategy for altering positional encodings within the attention mechanism, promising a more scalable future for LLMs.
The researchers put their theories to the test with three brand-new evaluation tasks—FreeFormQA, AlteredNumericQA, and LongChat-Lines—providing a more nuanced measure of model performance than the traditionally used metric of perplexity. Their findings? Linear scaling came out on top as the most effective way to extend the context length, but the truncated basis method showed potential for future exploration. To propel the research community even further, the paper releases three game-changing long-context models, named Giraffe, with context lengths ranging from 4k to an astonishing 32k.
Paper link: https://arxiv.org/abs/2308.10882
Code link: https://github.com/abacusai/Long-Context
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-giraffe
#deeplearning #cv #nlp #largelanguagemodel #opensource #largecontext
{kind=link}