
Using ‘radioactive data’ to detect if a data set was used for training
The authors have developed a new technique to mark the images in a data set so that researchers can determine whether a particular machine learning model has been trained using those images. This can help researchers and engineers to keep track of which data set was used to train a model so they can better understand how various data sets affect the performance of different neural networks.
The key points:
- the marks are harmless and have no impact on the classification accuracy of models, but are detectable with high confidence in a neural network;
- the image features are moved in a particular direction (the carrier) that has been sampled randomly and independently of the data
- after a model is trained on such data, its classifier will align with the direction of the carrier
- the method works in such a way that it is difficult to detect whether a data set is radioactive and to remove the marks from the trained model.
blogpost: https://ai.facebook.com/blog/using-radioactive-data-to-detect-if-a-data-set-was-used-for-training/
paper: https://arxiv.org/abs/2002.00937
#cv #cnn #datavalidation #image #data
The authors have developed a new technique to mark the images in a data set so that researchers can determine whether a particular machine learning model has been trained using those images. This can help researchers and engineers to keep track of which data set was used to train a model so they can better understand how various data sets affect the performance of different neural networks.
The key points:
- the marks are harmless and have no impact on the classification accuracy of models, but are detectable with high confidence in a neural network;
- the image features are moved in a particular direction (the carrier) that has been sampled randomly and independently of the data
- after a model is trained on such data, its classifier will align with the direction of the carrier
- the method works in such a way that it is difficult to detect whether a data set is radioactive and to remove the marks from the trained model.
blogpost: https://ai.facebook.com/blog/using-radioactive-data-to-detect-if-a-data-set-was-used-for-training/
paper: https://arxiv.org/abs/2002.00937
#cv #cnn #datavalidation #image #data
{kind=link}
Image Segmentation: tips and tricks from 39 Kaggle competitions
this article gave you some background into #image #segmentation tips and tricks
also, collect some tools and frameworks that you can use to start competing
the author overview:
* architectures
* training tricks
* losses
* pre-processing
* post processing
* ensembling
* tools and frameworks
link here
this article gave you some background into #image #segmentation tips and tricks
also, collect some tools and frameworks that you can use to start competing
the author overview:
* architectures
* training tricks
* losses
* pre-processing
* post processing
* ensembling
* tools and frameworks
link here
neptune.ai
Image Segmentation: Tips and Tricks from 39 Kaggle Competitions
Learn about image segmentation insights from 39 Kaggle comps: evaluation methods, ensembling techniques, and post-processing strategies.
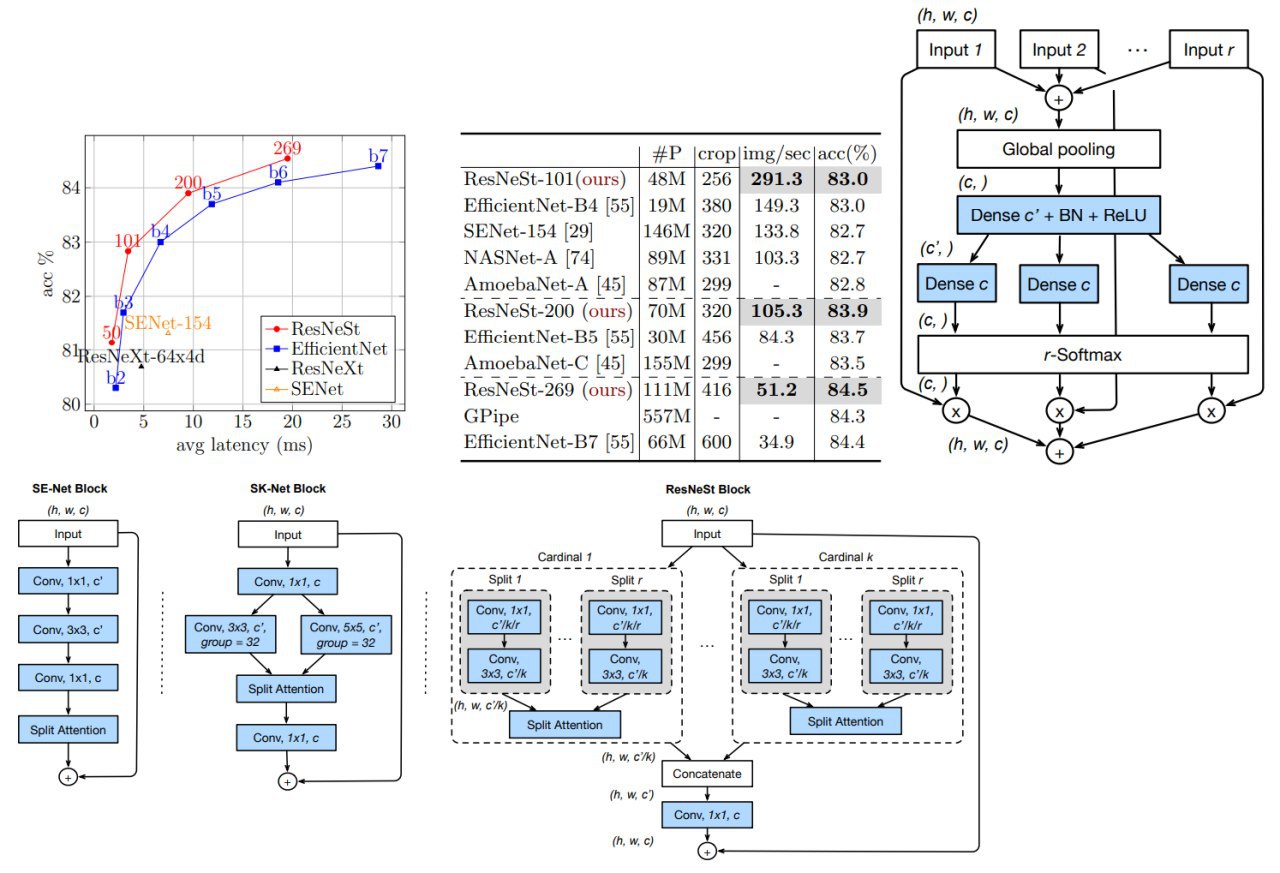
ResNeSt: Split-Attention Networks
A novel variation of ResNet architecture that outperforms other networks with similar model complexities.
Usually, downstream applications use the ResNet or one of its variants as the backbone CNN. Its simple and modular design can be easily adapted to various tasks. However, since ResNet models are originally designed for image classification, they may not be suitable for various downstream applications because of the limited receptive-field size and lack of cross-channel interaction.
Main contributions of the paper:
- Split-Attention block. Each block divides the feature-map into several groups (along the channel dimension) and finer-grained subgroups or splits, where the feature representation of each group is determined via a weighted combination of the representations of its splits. By stacking several Split-Attention blocks, they get a ResNet-like network called ResNeSt (
- a lot of large scale benchmarks on image classification and transfer learning.
Models utilizing a ResNeSt backbone are able to achieve SOTA performance on several tasks, namely: image classification, object detection, instance segmentation, and semantic segmentation.
ResNeSt-50 achieves 81.13% top-1 accuracy on ImageNet using a single crop-size of 224 × 224, outperforming previous best ResNet variant by more than 1% accuracy
Paper: https://arxiv.org/abs/2004.08955
Github: https://github.com/zhanghang1989/ResNeSt
#computervision #deeplearning #resnet #image #backbone #downstream #sota
A novel variation of ResNet architecture that outperforms other networks with similar model complexities.
Usually, downstream applications use the ResNet or one of its variants as the backbone CNN. Its simple and modular design can be easily adapted to various tasks. However, since ResNet models are originally designed for image classification, they may not be suitable for various downstream applications because of the limited receptive-field size and lack of cross-channel interaction.
Main contributions of the paper:
- Split-Attention block. Each block divides the feature-map into several groups (along the channel dimension) and finer-grained subgroups or splits, where the feature representation of each group is determined via a weighted combination of the representations of its splits. By stacking several Split-Attention blocks, they get a ResNet-like network called ResNeSt (
S stands for “split”). This architecture requires no more computation than existing ResNet-variants, and is easy to be adopted as a backbone for other vision tasks- a lot of large scale benchmarks on image classification and transfer learning.
Models utilizing a ResNeSt backbone are able to achieve SOTA performance on several tasks, namely: image classification, object detection, instance segmentation, and semantic segmentation.
ResNeSt-50 achieves 81.13% top-1 accuracy on ImageNet using a single crop-size of 224 × 224, outperforming previous best ResNet variant by more than 1% accuracy
Paper: https://arxiv.org/abs/2004.08955
Github: https://github.com/zhanghang1989/ResNeSt
#computervision #deeplearning #resnet #image #backbone #downstream #sota
{kind=link}
Image GPT
by openai
The authors have shown that by trading off 2-D knowledge for scale and by choosing predictive features from the middle of the network, a sequence transformer can be competitive with top convolutional nets for unsupervised image classification.
Notably, they achieved their results by directly applying the GPT-2 language model to image generation. Their results suggest that due to its simplicity and generality, a sequence transformer given sufficient compute might ultimately be an effective way to learn excellent features in many domains.
There are two methods they use to assess model performance:
[0] linear probe, uses the trained model to extract features from the images in the downstream dataset and then fits a logistic regression to the labels
[1] fine-tunes the entire model on the downstream dataset :youknow:
blog: https://openai.com/blog/image-gpt/
papers:
icml 2020 (v1)
(v2)
github (code is provided as-is, no updates expected): https://github.com/openai/image-gpt
#openai #gpt2 #language #image #icml2020
by openai
The authors have shown that by trading off 2-D knowledge for scale and by choosing predictive features from the middle of the network, a sequence transformer can be competitive with top convolutional nets for unsupervised image classification.
Notably, they achieved their results by directly applying the GPT-2 language model to image generation. Their results suggest that due to its simplicity and generality, a sequence transformer given sufficient compute might ultimately be an effective way to learn excellent features in many domains.
There are two methods they use to assess model performance:
[0] linear probe, uses the trained model to extract features from the images in the downstream dataset and then fits a logistic regression to the labels
[1] fine-tunes the entire model on the downstream dataset :youknow:
blog: https://openai.com/blog/image-gpt/
papers:
icml 2020 (v1)
(v2)
github (code is provided as-is, no updates expected): https://github.com/openai/image-gpt
#openai #gpt2 #language #image #icml2020
Data Science by ODS.ai 🦜
Big step after first DALL·E — DALL·E 2 In January 2021, OpenAI introduced DALL·E. One year later, their newest system, DALL·E 2, generates more realistic and accurate images with 4x greater resolution. The first DALL·E is a transformer model. It receives…
DALL·E Now Available in Beta
#Dalle by #openai was released for public (though obviously moderated) access. Join waitlist to play around.
Images are also available for commercial use.
By default user can generate 460 images, further generations (or variations on generated images) will be available on paid plan.
Link: https://openai.com/blog/dall-e-now-available-in-beta/
#image #CV #GAN #generation #generatinveart
#Dalle by #openai was released for public (though obviously moderated) access. Join waitlist to play around.
Images are also available for commercial use.
By default user can generate 460 images, further generations (or variations on generated images) will be available on paid plan.
Link: https://openai.com/blog/dall-e-now-available-in-beta/
#image #CV #GAN #generation #generatinveart
Openai
DALL·E now available in beta
We’ll invite 1 million people from our waitlist over the coming weeks. Users can create with DALL·E using free credits that refill every month, and buy additional credits in 115-generation increments for $15.