
VizSeq: A Visual Analysis Toolkit for Text Generation Tasks
it's a visual analysis toolkit for {text, image, audio, video}-to-text generation system evaluation, dataset analysis, and benchmark hosting.
supports multimodal sources and multiple text references, providing visualization in Jupyter notebook or a web app interface.
also, it can be used locally or deployed onto public servers for centralized data hosting and benchmarking; covers most common n-gram based metrics accelerated with multiprocessing and also provides the latest embedding-based metrics such as BERTScore
Paper: https://arxiv.org/abs/1909.05424
Code: https://github.com/facebookresearch/vizseq
#computation #language #emnlp2019
it's a visual analysis toolkit for {text, image, audio, video}-to-text generation system evaluation, dataset analysis, and benchmark hosting.
supports multimodal sources and multiple text references, providing visualization in Jupyter notebook or a web app interface.
also, it can be used locally or deployed onto public servers for centralized data hosting and benchmarking; covers most common n-gram based metrics accelerated with multiprocessing and also provides the latest embedding-based metrics such as BERTScore
Paper: https://arxiv.org/abs/1909.05424
Code: https://github.com/facebookresearch/vizseq
#computation #language #emnlp2019
{kind=link}
Improving Transformer Models by Reordering their Sublayers
tl;dr – improve transformers by reordering their sublayers like the sandwich transformer
The authors trained random #transformer models with reordered sublayers, and find that some perform better than the baseline interleaved trans former in #language #modeling.
They observed that, on average, better models contain more self-attention #sublayers at the bottom and more feedforward sublayer at the top.
This leads them to design a new transformer stack, the sandwich transformer, which consistently improves performance over the baseline at no cost.
paper: https://ofir.io/sandwich_transformer.pdf
tl;dr – improve transformers by reordering their sublayers like the sandwich transformer
The authors trained random #transformer models with reordered sublayers, and find that some perform better than the baseline interleaved trans former in #language #modeling.
They observed that, on average, better models contain more self-attention #sublayers at the bottom and more feedforward sublayer at the top.
This leads them to design a new transformer stack, the sandwich transformer, which consistently improves performance over the baseline at no cost.
paper: https://ofir.io/sandwich_transformer.pdf
{kind=link}
The Cost of Training NLP Models: A Concise Overview
The authors review the cost of training large-scale language models, and the drivers of these costs.
More at the paper: https://arxiv.org/abs/2004.08900
#nlp #language
The authors review the cost of training large-scale language models, and the drivers of these costs.
More at the paper: https://arxiv.org/abs/2004.08900
#nlp #language
{kind=link}
GPT-3: Language Models are Few-Shot Learners
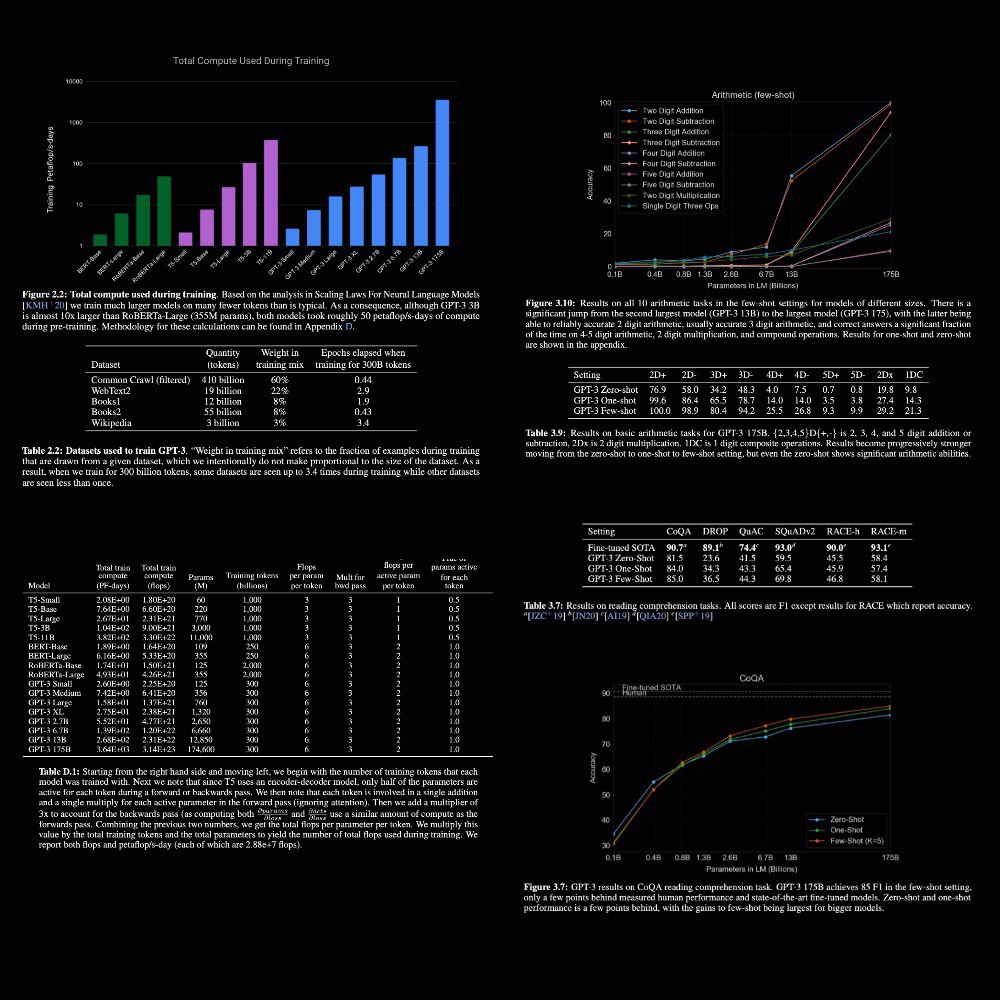
#openAI train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting
Their model applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model.
Achieves strong performance on many NLP datasets, including translation, q&a, and cloze tasks, as well as several tasks that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic.
Also, they find that GPT-3 can generate samples of news articles in which human evaluators have difficulty distinguishing from articles written by humans.
175 billion parameters! And on some tasks, it is not performed
It is all you need to know about
paper: https://arxiv.org/abs/2005.14165.pdf
#nlp #gpt #gpt3 #language #model
#openAI train GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and test its performance in the few-shot setting
Their model applied without any gradient updates or fine-tuning, with tasks and few-shot demonstrations specified purely via text interaction with the model.
Achieves strong performance on many NLP datasets, including translation, q&a, and cloze tasks, as well as several tasks that require on-the-fly reasoning or domain adaptation, such as unscrambling words, using a novel word in a sentence, or performing 3-digit arithmetic.
Also, they find that GPT-3 can generate samples of news articles in which human evaluators have difficulty distinguishing from articles written by humans.
175 billion parameters! And on some tasks, it is not performed
It is all you need to know about
paper: https://arxiv.org/abs/2005.14165.pdf
#nlp #gpt #gpt3 #language #model
{kind=link}
Image GPT
by openai
The authors have shown that by trading off 2-D knowledge for scale and by choosing predictive features from the middle of the network, a sequence transformer can be competitive with top convolutional nets for unsupervised image classification.
Notably, they achieved their results by directly applying the GPT-2 language model to image generation. Their results suggest that due to its simplicity and generality, a sequence transformer given sufficient compute might ultimately be an effective way to learn excellent features in many domains.
There are two methods they use to assess model performance:
[0] linear probe, uses the trained model to extract features from the images in the downstream dataset and then fits a logistic regression to the labels
[1] fine-tunes the entire model on the downstream dataset :youknow:
blog: https://openai.com/blog/image-gpt/
papers:
icml 2020 (v1)
(v2)
github (code is provided as-is, no updates expected): https://github.com/openai/image-gpt
#openai #gpt2 #language #image #icml2020
by openai
The authors have shown that by trading off 2-D knowledge for scale and by choosing predictive features from the middle of the network, a sequence transformer can be competitive with top convolutional nets for unsupervised image classification.
Notably, they achieved their results by directly applying the GPT-2 language model to image generation. Their results suggest that due to its simplicity and generality, a sequence transformer given sufficient compute might ultimately be an effective way to learn excellent features in many domains.
There are two methods they use to assess model performance:
[0] linear probe, uses the trained model to extract features from the images in the downstream dataset and then fits a logistic regression to the labels
[1] fine-tunes the entire model on the downstream dataset :youknow:
blog: https://openai.com/blog/image-gpt/
papers:
icml 2020 (v1)
(v2)
github (code is provided as-is, no updates expected): https://github.com/openai/image-gpt
#openai #gpt2 #language #image #icml2020