
New library for #DataAugmentation: SOLT.
Supports various transformations for images, masks, targets and landmarks. Fast and easy-to-use library useful in #ComputerVision and #DeepLearning
Link: https://github.com/MIPT-Oulu/solt .
Supports various transformations for images, masks, targets and landmarks. Fast and easy-to-use library useful in #ComputerVision and #DeepLearning
Link: https://github.com/MIPT-Oulu/solt .
GitHub
GitHub - MIPT-Oulu/solt: Streaming over lightweight data transformations
Streaming over lightweight data transformations. Contribute to MIPT-Oulu/solt development by creating an account on GitHub.
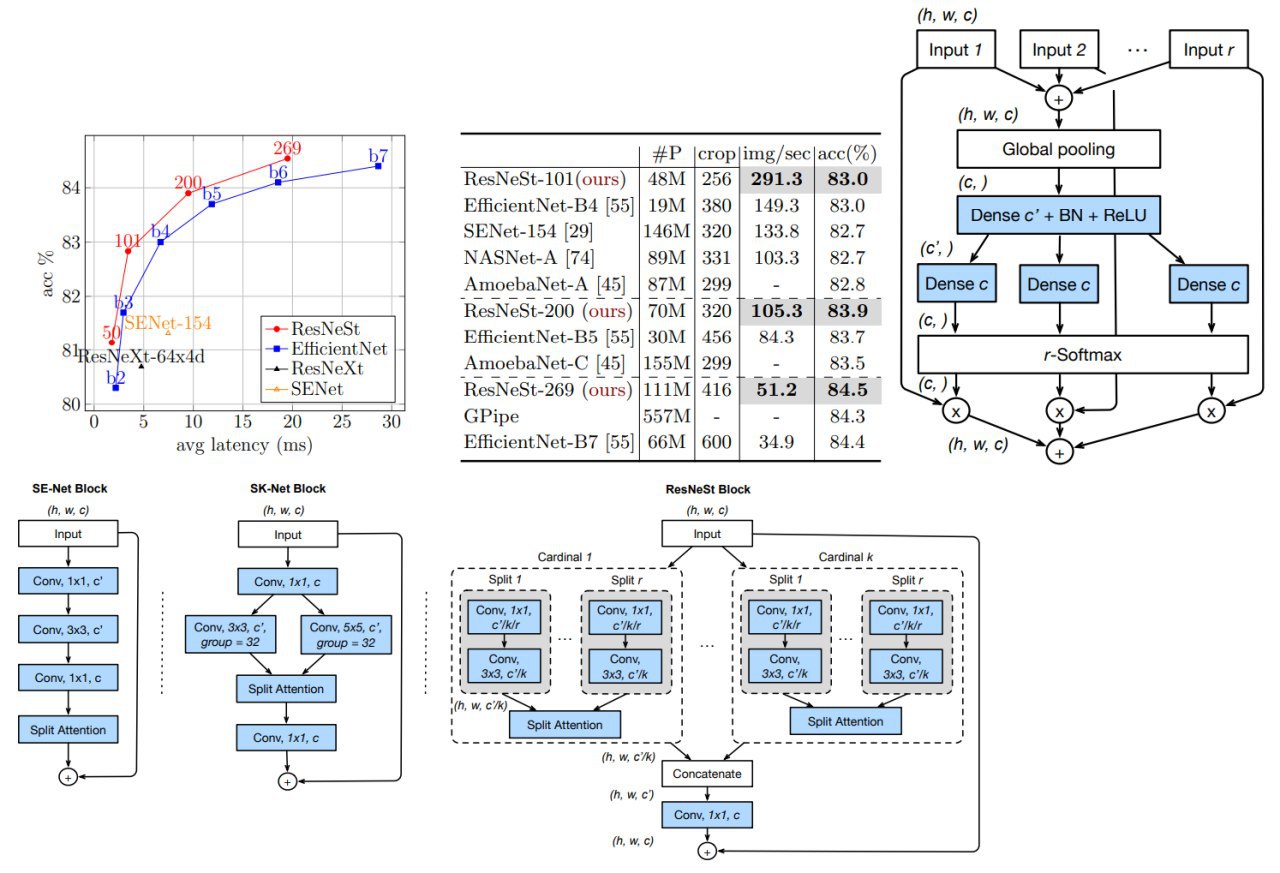
ResNeSt: Split-Attention Networks
A novel variation of ResNet architecture that outperforms other networks with similar model complexities.
Usually, downstream applications use the ResNet or one of its variants as the backbone CNN. Its simple and modular design can be easily adapted to various tasks. However, since ResNet models are originally designed for image classification, they may not be suitable for various downstream applications because of the limited receptive-field size and lack of cross-channel interaction.
Main contributions of the paper:
- Split-Attention block. Each block divides the feature-map into several groups (along the channel dimension) and finer-grained subgroups or splits, where the feature representation of each group is determined via a weighted combination of the representations of its splits. By stacking several Split-Attention blocks, they get a ResNet-like network called ResNeSt (
- a lot of large scale benchmarks on image classification and transfer learning.
Models utilizing a ResNeSt backbone are able to achieve SOTA performance on several tasks, namely: image classification, object detection, instance segmentation, and semantic segmentation.
ResNeSt-50 achieves 81.13% top-1 accuracy on ImageNet using a single crop-size of 224 × 224, outperforming previous best ResNet variant by more than 1% accuracy
Paper: https://arxiv.org/abs/2004.08955
Github: https://github.com/zhanghang1989/ResNeSt
#computervision #deeplearning #resnet #image #backbone #downstream #sota
A novel variation of ResNet architecture that outperforms other networks with similar model complexities.
Usually, downstream applications use the ResNet or one of its variants as the backbone CNN. Its simple and modular design can be easily adapted to various tasks. However, since ResNet models are originally designed for image classification, they may not be suitable for various downstream applications because of the limited receptive-field size and lack of cross-channel interaction.
Main contributions of the paper:
- Split-Attention block. Each block divides the feature-map into several groups (along the channel dimension) and finer-grained subgroups or splits, where the feature representation of each group is determined via a weighted combination of the representations of its splits. By stacking several Split-Attention blocks, they get a ResNet-like network called ResNeSt (
S stands for “split”). This architecture requires no more computation than existing ResNet-variants, and is easy to be adopted as a backbone for other vision tasks- a lot of large scale benchmarks on image classification and transfer learning.
Models utilizing a ResNeSt backbone are able to achieve SOTA performance on several tasks, namely: image classification, object detection, instance segmentation, and semantic segmentation.
ResNeSt-50 achieves 81.13% top-1 accuracy on ImageNet using a single crop-size of 224 × 224, outperforming previous best ResNet variant by more than 1% accuracy
Paper: https://arxiv.org/abs/2004.08955
Github: https://github.com/zhanghang1989/ResNeSt
#computervision #deeplearning #resnet #image #backbone #downstream #sota
{kind=link}
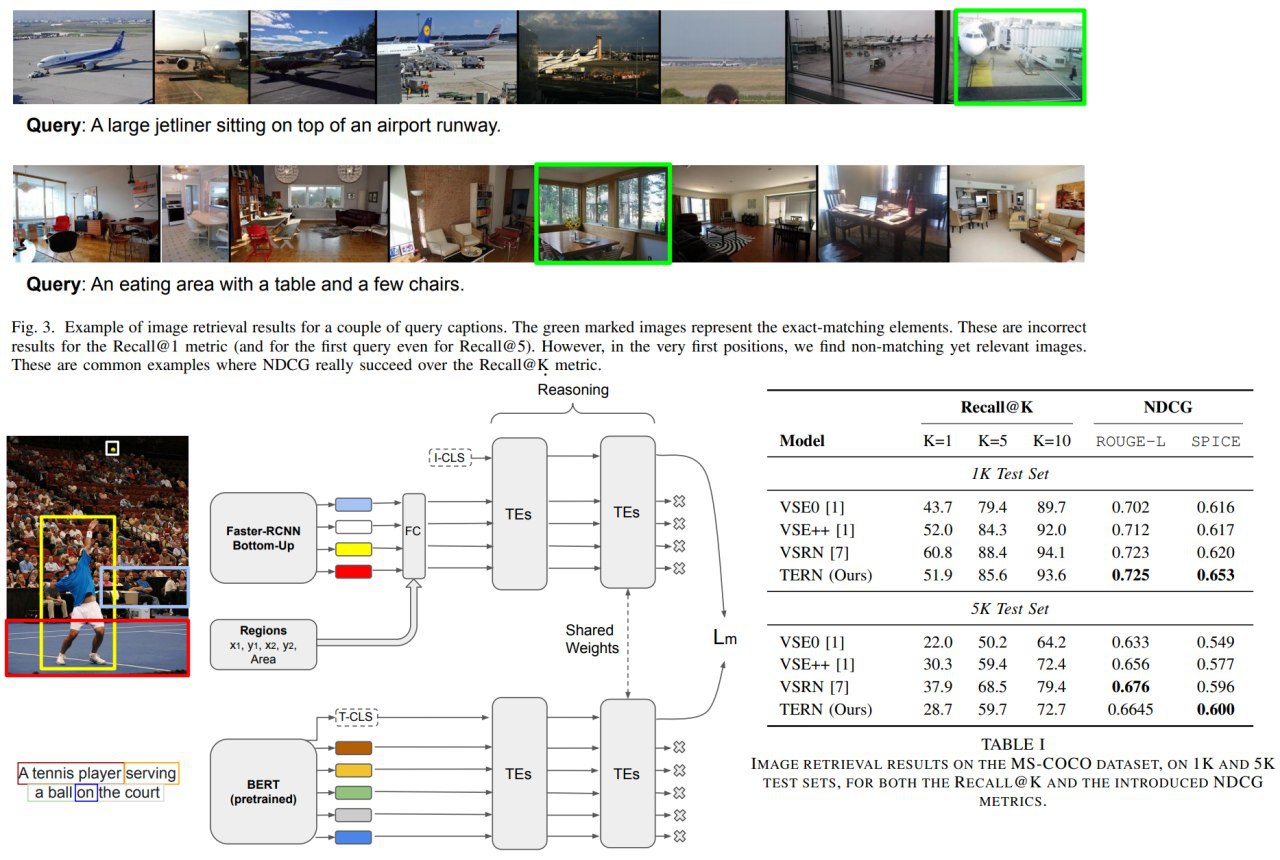
Transformer Reasoning Network for Image-Text Matching and Retrieval
A new approach for image-text matching using Faster-RCNN Bottom-Up and BERT.
Usually, downstream applications use the ResNet or one of its variants as the backbone CNN. Its simple and modular design can be easily adapted to various tasks. However, since ResNet models are originally designed for image classification, they may not be suitable for various downstream applications because of the limited receptive-field size and lack of cross-channel interaction.
Authors suggest an architecture, where images and texts are processed at first, and then their representations are combined.
Main contributions of the paper:
- TERN Architecture
- NDCG metric in addition to Recall@K
- show SOTA result on the benchmark
Paper: https://arxiv.org/abs/2004.09144
Code: https://github.com/mesnico/TERN
#computervision #deeplearning #bert #imagetextmatching
A new approach for image-text matching using Faster-RCNN Bottom-Up and BERT.
Usually, downstream applications use the ResNet or one of its variants as the backbone CNN. Its simple and modular design can be easily adapted to various tasks. However, since ResNet models are originally designed for image classification, they may not be suitable for various downstream applications because of the limited receptive-field size and lack of cross-channel interaction.
Authors suggest an architecture, where images and texts are processed at first, and then their representations are combined.
Main contributions of the paper:
- TERN Architecture
- NDCG metric in addition to Recall@K
- show SOTA result on the benchmark
Paper: https://arxiv.org/abs/2004.09144
Code: https://github.com/mesnico/TERN
#computervision #deeplearning #bert #imagetextmatching
{kind=link}
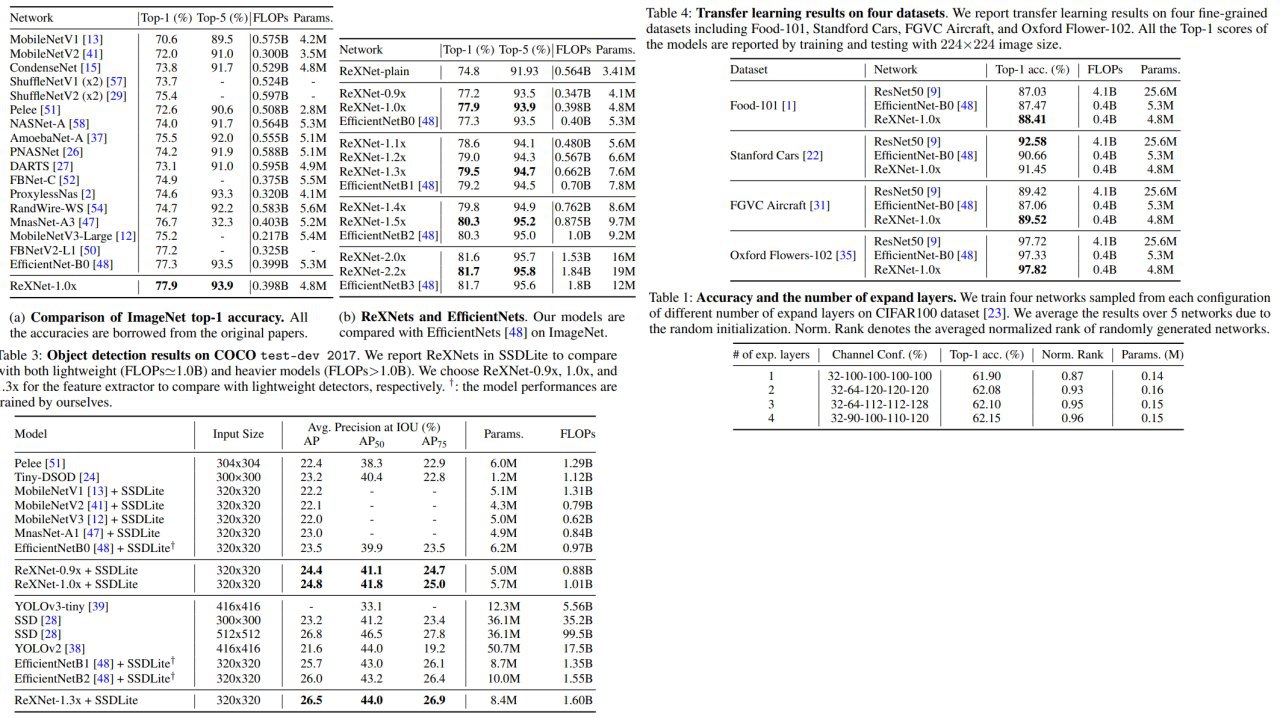
ReXNet: Diminishing Representational Bottleneck on Convolutional Neural Network
The authors propose a set of design principles that improves model performance significantly based on the analysis of representation bottlenecks.
Authors think that commonly used architectures have a representation bottleneck and try to fix it by expanding channel size, using more expand layers, and better activation functions. This also improves the performance of models on ImageNet and good results on transfer learning on classification and object detection.
Authors hope that their design ideas could be used by NAS to create even better models.
Paper: https://arxiv.org/abs/2007.00992
Code: https://github.com/clovaai/rexnet
#deeplearning #pretraining #transferlearning #computervision #pytorch
The authors propose a set of design principles that improves model performance significantly based on the analysis of representation bottlenecks.
Authors think that commonly used architectures have a representation bottleneck and try to fix it by expanding channel size, using more expand layers, and better activation functions. This also improves the performance of models on ImageNet and good results on transfer learning on classification and object detection.
Authors hope that their design ideas could be used by NAS to create even better models.
Paper: https://arxiv.org/abs/2007.00992
Code: https://github.com/clovaai/rexnet
#deeplearning #pretraining #transferlearning #computervision #pytorch
{kind=link}
👍1
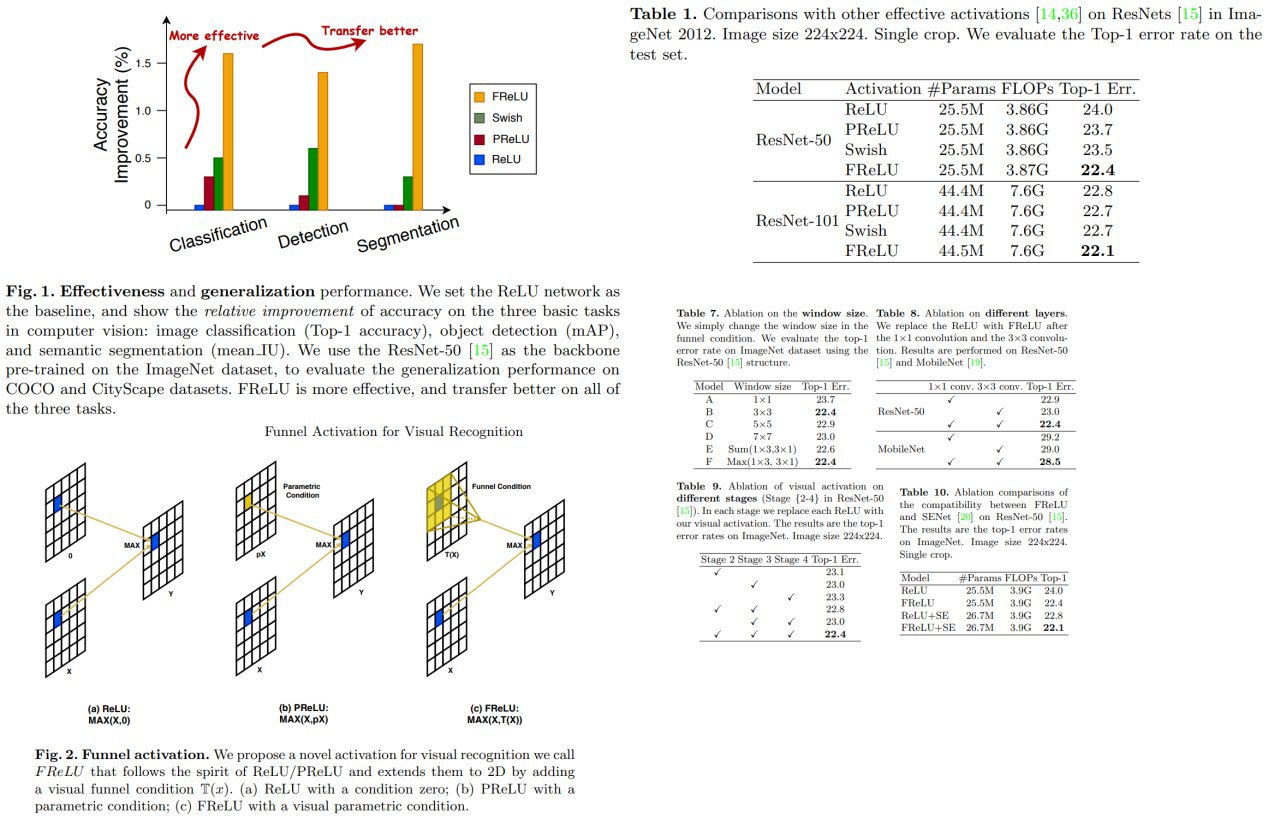
Funnel Activation for Visual Recognition
Authors offer a new activation function for image recognition tasks, called Funnel activation (FReLU), that extends ReLU and PReLU to a 2D activation by adding a negligible overhead of spatial condition.
Extensive experiments on COCO, ImageNet and CityScape show significant improvement and robustness.
Paper: https://arxiv.org/abs/2007.11824
Code: https://github.com/megvii-model/FunnelAct
#deeplearning #activationfunction #computervision #pytorch
Authors offer a new activation function for image recognition tasks, called Funnel activation (FReLU), that extends ReLU and PReLU to a 2D activation by adding a negligible overhead of spatial condition.
Extensive experiments on COCO, ImageNet and CityScape show significant improvement and robustness.
Paper: https://arxiv.org/abs/2007.11824
Code: https://github.com/megvii-model/FunnelAct
#deeplearning #activationfunction #computervision #pytorch
{kind=link}
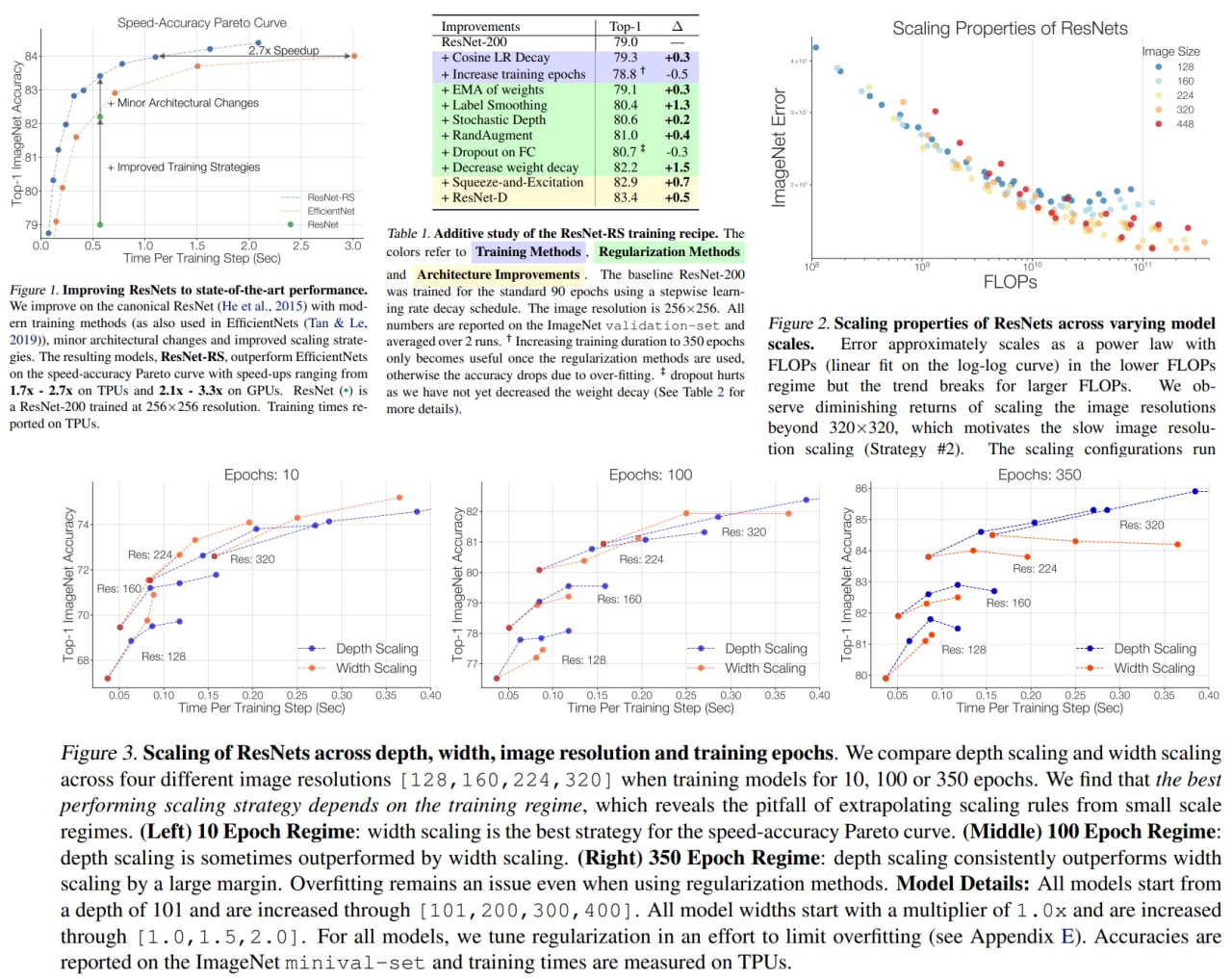
Revisiting ResNets: Improved Training and Scaling Strategies
The authors of the paper (from Google Brain and UC Berkeley) have decided to analyze the effects of the model architecture, training, and scaling strategies separately and concluded that these strategies might have a higher impact on the score than the architecture.
They offer two new strategies:
- scale model depth if overfitting is possible, scale model width otherwise
- increase image resolution slower than recommended in previous papers
Based on these ideas, the new architecture ResNet-RS was developed. It is 2.1x–3.3x faster than EfficientNets on GPU while reaching similar accuracy on ImageNet.
In semi-supervised learning, ResNet-RS achieves 86.2% top-1 ImageNet accuracy while being 4.7x faster than EfficientNet-NoisyStudent.
Transfer learning on downstream tasks also has improved performance.
The authors suggest using these ResNet-RS as a baseline for further research.
Paper: https://arxiv.org/abs/2103.07579
Code and checkpoints are available in TensorFlow:
https://github.com/tensorflow/models/tree/master/official/vision/beta
https://github.com/tensorflow/tpu/tree/master/models/official/resnet/resnet_rs
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-resnetsr
#deeplearning #computervision #sota
The authors of the paper (from Google Brain and UC Berkeley) have decided to analyze the effects of the model architecture, training, and scaling strategies separately and concluded that these strategies might have a higher impact on the score than the architecture.
They offer two new strategies:
- scale model depth if overfitting is possible, scale model width otherwise
- increase image resolution slower than recommended in previous papers
Based on these ideas, the new architecture ResNet-RS was developed. It is 2.1x–3.3x faster than EfficientNets on GPU while reaching similar accuracy on ImageNet.
In semi-supervised learning, ResNet-RS achieves 86.2% top-1 ImageNet accuracy while being 4.7x faster than EfficientNet-NoisyStudent.
Transfer learning on downstream tasks also has improved performance.
The authors suggest using these ResNet-RS as a baseline for further research.
Paper: https://arxiv.org/abs/2103.07579
Code and checkpoints are available in TensorFlow:
https://github.com/tensorflow/models/tree/master/official/vision/beta
https://github.com/tensorflow/tpu/tree/master/models/official/resnet/resnet_rs
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-resnetsr
#deeplearning #computervision #sota
{kind=link}
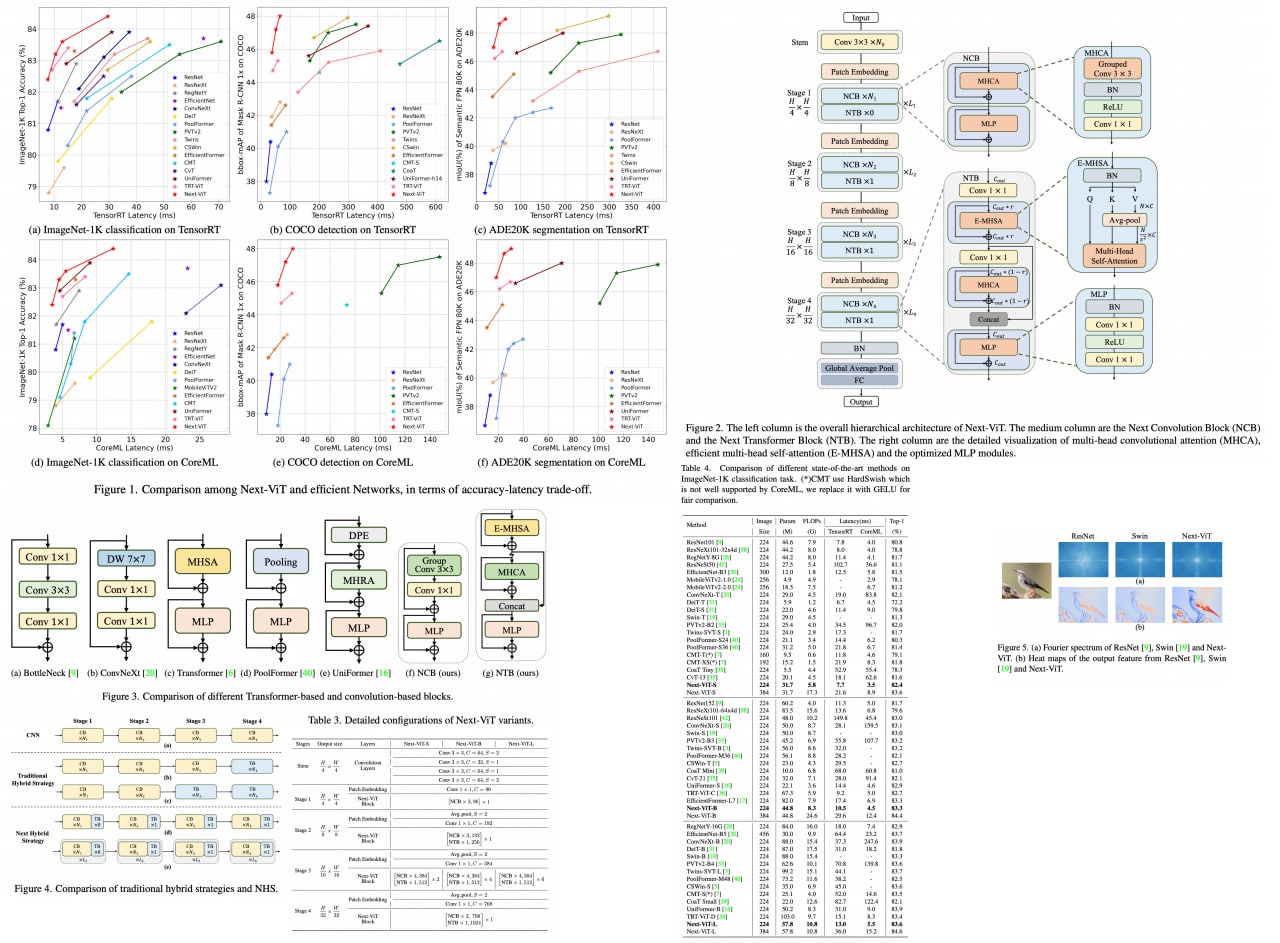
Next-ViT: Next Generation Vision Transformer for Efficient Deployment in Realistic Industrial Scenarios
While vision transformers demostrate high performance, they can't be deployed as efficiently as CNNs in realistic industrial deployment scenarios, e. g. TensorRT or CoreML.
The authors propose Next-ViT, which has a higher latency/accuracy trade-off than existing CNN and ViT models. They develop two new architecture blocks and a new paradigm to stack them. As a result, On TensorRT, Next-ViT surpasses ResNet by 5.4 mAP (from 40.4 to 45.8) on COCO detection and 8.2% mIoU (from 38.8% to 47.0%) on ADE20K segmentation. Also, it achieves comparable performance with CSWin, while the inference speed is accelerated by
3.6×. On CoreML, Next-ViT surpasses EfficientFormer by 4.6 mAP (from 42.6 to 47.2) on COCO detection and 3.5% mIoU (from 45.2% to 48.7%) on ADE20K segmentation under similar latency.
Paper: https://arxiv.org/abs/2207.05501
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-next-vit
#deeplearning #cv #transformer #computervision
While vision transformers demostrate high performance, they can't be deployed as efficiently as CNNs in realistic industrial deployment scenarios, e. g. TensorRT or CoreML.
The authors propose Next-ViT, which has a higher latency/accuracy trade-off than existing CNN and ViT models. They develop two new architecture blocks and a new paradigm to stack them. As a result, On TensorRT, Next-ViT surpasses ResNet by 5.4 mAP (from 40.4 to 45.8) on COCO detection and 8.2% mIoU (from 38.8% to 47.0%) on ADE20K segmentation. Also, it achieves comparable performance with CSWin, while the inference speed is accelerated by
3.6×. On CoreML, Next-ViT surpasses EfficientFormer by 4.6 mAP (from 42.6 to 47.2) on COCO detection and 3.5% mIoU (from 45.2% to 48.7%) on ADE20K segmentation under similar latency.
Paper: https://arxiv.org/abs/2207.05501
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-next-vit
#deeplearning #cv #transformer #computervision
{kind=link}
👍24❤2😁2🔥1👏1
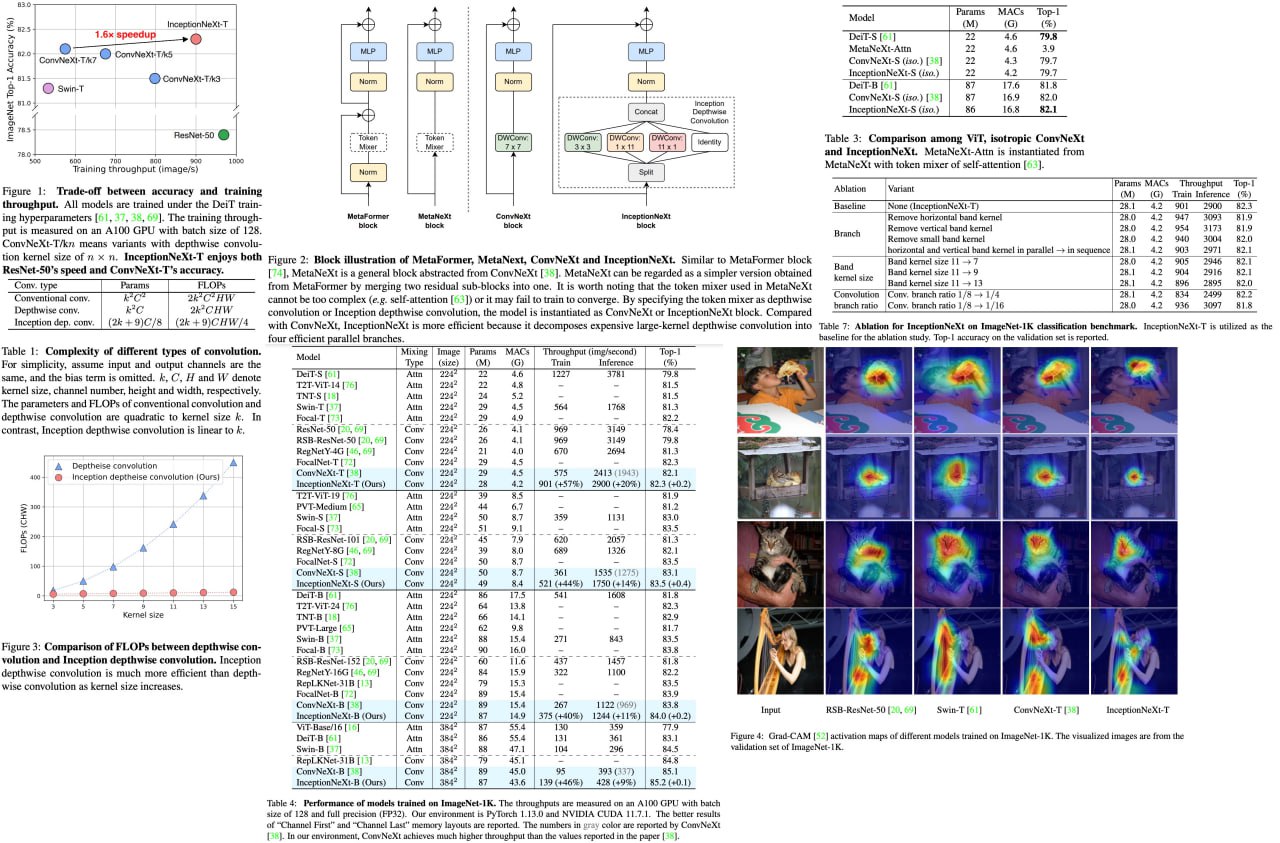
InceptionNeXt: When Inception Meets ConvNeXt
Large-kernel convolutions, such as those employed in ConvNeXt, can improve model performance but often come at the cost of efficiency due to high memory access costs. Although reducing kernel size may increase speed, it often leads to significant performance degradation.
To address this issue, the authors propose InceptionNeXt, which decomposes large-kernel depthwise convolution into four parallel branches along the channel dimension. This new Inception depthwise convolution results in networks with high throughputs and competitive performance. For example, InceptionNeXt-T achieves 1.6x higher training throughputs than ConvNeX-T and a 0.2% top-1 accuracy improvement on ImageNet-1K. InceptionNeXt has the potential to serve as an economical baseline for future architecture design, helping to reduce carbon footprint.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-inceptionnext
Paper link:https://arxiv.org/abs/2303.16900
Code link: https://github.com/sail-sg/inceptionnext
#cnn #deeplearning #computervision
Large-kernel convolutions, such as those employed in ConvNeXt, can improve model performance but often come at the cost of efficiency due to high memory access costs. Although reducing kernel size may increase speed, it often leads to significant performance degradation.
To address this issue, the authors propose InceptionNeXt, which decomposes large-kernel depthwise convolution into four parallel branches along the channel dimension. This new Inception depthwise convolution results in networks with high throughputs and competitive performance. For example, InceptionNeXt-T achieves 1.6x higher training throughputs than ConvNeX-T and a 0.2% top-1 accuracy improvement on ImageNet-1K. InceptionNeXt has the potential to serve as an economical baseline for future architecture design, helping to reduce carbon footprint.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-inceptionnext
Paper link:https://arxiv.org/abs/2303.16900
Code link: https://github.com/sail-sg/inceptionnext
#cnn #deeplearning #computervision
{kind=link}
👍6
This media is not supported in your browser
VIEW IN TELEGRAM
- Less error accumulation facing occlusion/reappearance.
- A training-free memory tree for dynamic segmentation paths, boosting resilience efficiently.
- Significant improvements over SAM2 across 24 head-to-head comparisons on SA-V and LVOS.
#AIML #VideoSegmentation #SAM2Long #ComputerVision
@opendatascience
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥10👍6❤4
Forwarded from Китай.AI
🔮 CN-AI-MODELS | ИИ модели Китая
🔥 ByteDance представил Seed1.5-VL — новый лидер в мультимодальном анализе
Китайский гигант ByteDance представил модель Seed1.5-VL. Несмотря на компактные размеры (всего 20B параметров), она конкурирует с топовыми решениями вроде Gemini2.5 Pro. И она умеет "глубоко размышлять" над изображениями!
🚀 Что умеет?
- Видеоанализ: Например, по запросу «что натворил кот?» выдает таймкоды всех «преступлений»
- Точный поиск объектов: Находит товары на полке, читает ценники и считает сумму
- Распознавание эмоций: Определяет количество злых котиков на фото с указанием координат
- GUI-интеграция: Может имитировать клики пользователя в интерфейсах
💡 Технические детали:
• Архитектура:
• Обучение: 3 этапа с фокусом на OCR, визуальном grounding’е и работе с длинными последовательностями
• Инновации: гибрид RLHF/RLVR, оптимизированная балансировка нагрузки GPU
⚡️ Результаты
Модель набрала 38 топ-результатов в 60 тестах (включая 14/19 видео-тестов)
Официальный сайт | Отчет | GitHub
#КитайскийИИ #КитайAI #МультимодальныйИИ #ComputerVision #ByteDance
🔥 ByteDance представил Seed1.5-VL — новый лидер в мультимодальном анализе
Китайский гигант ByteDance представил модель Seed1.5-VL. Несмотря на компактные размеры (всего 20B параметров), она конкурирует с топовыми решениями вроде Gemini2.5 Pro. И она умеет "глубоко размышлять" над изображениями!
🚀 Что умеет?
- Видеоанализ: Например, по запросу «что натворил кот?» выдает таймкоды всех «преступлений»
- Точный поиск объектов: Находит товары на полке, читает ценники и считает сумму
- Распознавание эмоций: Определяет количество злых котиков на фото с указанием координат
- GUI-интеграция: Может имитировать клики пользователя в интерфейсах
💡 Технические детали:
• Архитектура:
ViT-532M + MoE-LLM 20B • Обучение: 3 этапа с фокусом на OCR, визуальном grounding’е и работе с длинными последовательностями
• Инновации: гибрид RLHF/RLVR, оптимизированная балансировка нагрузки GPU
⚡️ Результаты
Модель набрала 38 топ-результатов в 60 тестах (включая 14/19 видео-тестов)
Официальный сайт | Отчет | GitHub
#КитайскийИИ #КитайAI #МультимодальныйИИ #ComputerVision #ByteDance
Volcengine
火山方舟大模型体验中心-火山引擎
火山方舟大模型体验中心,免登录即可体验,畅享DeepSeek、Doubao等最新模型!火山方舟是火山引擎推出的大模型服务平台,提供模型训练、推理、评测、精调等全方位功能与服务,并重点支撑大模型生态。
❤3👍3🔥2