
DensePose: Dense Human Pose Estimation In The Wild
Facebook AI Research group presented a paper on pose estimation. That will help Facebook with better understanding of the processed videos.
NEW: DensePose-COCO, a large-scale ground-truth dataset with image-to-surface correspondences manually annotated on 50K COCO images.
Project website: http://densepose.org/
Arxiv: https://arxiv.org/abs/1802.00434
#facebook #fair #cvpr #cv #CNN #dataset
Facebook AI Research group presented a paper on pose estimation. That will help Facebook with better understanding of the processed videos.
NEW: DensePose-COCO, a large-scale ground-truth dataset with image-to-surface correspondences manually annotated on 50K COCO images.
Project website: http://densepose.org/
Arxiv: https://arxiv.org/abs/1802.00434
#facebook #fair #cvpr #cv #CNN #dataset
arXiv.org
DensePose: Dense Human Pose Estimation In The Wild
In this work, we establish dense correspondences between RGB image and a surface-based representation of the human body, a task we refer to as dense human pose estimation. We first gather dense...
ModaNet: A Large-Scale Street Fashion Dataset with Polygon Annotations
Latest segmentation and detection approaches (DeepLabV3+, FasterRCNN) applied to street fashion images. Arxiv paper contains information about both: net and dataset.
Arxiv link: https://arxiv.org/abs/1807.01394
Paperdoll dataset: http://vision.is.tohoku.ac.jp/~kyamagu/research/paperdoll/
#segmentation #dataset #fashion #sv
Latest segmentation and detection approaches (DeepLabV3+, FasterRCNN) applied to street fashion images. Arxiv paper contains information about both: net and dataset.
Arxiv link: https://arxiv.org/abs/1807.01394
Paperdoll dataset: http://vision.is.tohoku.ac.jp/~kyamagu/research/paperdoll/
#segmentation #dataset #fashion #sv
vision.is.tohoku.ac.jp
Kota Yamaguchi - PaperDoll Parsing
Kota Yamaguchi's website
Hey, our fellow colleagues at OpenDataScience community are labeling a meme dataset. You can help them with the markup just by viewing memes in this bot: @MemezoidBot
#DataSet #labeling
#DataSet #labeling
27.23TB of research data in torrents! Includes dataset such as:
- Breast Cancer Cell Segmentation
- Liver Tumor Segmentation
- MRI Lesion Segmentation in Multiple Sclerosis
- Electron Microscopy, Hippocampus
- Digital Surface & Digital Terrain Model
And courses recordings, including:
- Introduction to Computer Science [CS50x] [Harvard] [2018]
- Artificial Intelligence(EDX)
- Richard Feynman's Lectures on Physics (The Messenger Lectures) (🔥)
- [Coursera] Machine Learning (Stanford University) (ml)
- [Coursera] Natural Language Processing (Stanford University) (nlp)
- [Coursera] Neural Networks for Machine Learning (University of Toronto) (neuralnets)
http://academictorrents.com/
#course #torrent #dataset
- Breast Cancer Cell Segmentation
- Liver Tumor Segmentation
- MRI Lesion Segmentation in Multiple Sclerosis
- Electron Microscopy, Hippocampus
- Digital Surface & Digital Terrain Model
And courses recordings, including:
- Introduction to Computer Science [CS50x] [Harvard] [2018]
- Artificial Intelligence(EDX)
- Richard Feynman's Lectures on Physics (The Messenger Lectures) (🔥)
- [Coursera] Machine Learning (Stanford University) (ml)
- [Coursera] Natural Language Processing (Stanford University) (nlp)
- [Coursera] Neural Networks for Machine Learning (University of Toronto) (neuralnets)
http://academictorrents.com/
#course #torrent #dataset
Academic Torrents
A distributed system for sharing enormous datasets - for researchers, by researchers. The result is a scalable, secure, and fault-tolerant repository for data, with blazing fast download speeds.
#Google introduced Conceptual Captions, a new dataset and challenge for image captioning consisting of ~3.3 million image/caption pairs for the machine learning community to train and evaluate their own image captioning models.
Link: https://ai.googleblog.com/2018/09/conceptual-captions-new-dataset-and.html
#dataset
Link: https://ai.googleblog.com/2018/09/conceptual-captions-new-dataset-and.html
#dataset
Google AI Blog
Conceptual Captions: A New Dataset and Challenge for Image Captioning
Posted by Piyush Sharma, Software Engineer and Radu Soricut, Research Scientist, Google AI The web is filled with billions of images, help...
And #Google also launched #DataSet search. This is a huge breakthrough for the DS community, because now it will be easier to access some interesting data.
https://toolbox.google.com/datasetsearch
https://toolbox.google.com/datasetsearch
Google announced the updated YouTube-8M dataset
Updated set now includes a subset with verified 5-s segment level labels, along with the 3rd Large-Scale Video Understanding Challenge and Workshop at #ICCV19.
Link: https://ai.googleblog.com/2019/06/announcing-youtube-8m-segments-dataset.html
#Google #YouTube #CV #DL #Video #dataset
Updated set now includes a subset with verified 5-s segment level labels, along with the 3rd Large-Scale Video Understanding Challenge and Workshop at #ICCV19.
Link: https://ai.googleblog.com/2019/06/announcing-youtube-8m-segments-dataset.html
#Google #YouTube #CV #DL #Video #dataset
{kind=link}
New dataset with adversarial examples
Natural Adversarial Examples are real-world and unmodified examples which cause classifiers to be consistently confused. The new dataset has 7,500 images, which we personally labeled over several months.
ArXiV: https://arxiv.org/abs/1907.07174
Dataset and code: https://github.com/hendrycks/natural-adv-examples
#Dataset #Adversarial
Natural Adversarial Examples are real-world and unmodified examples which cause classifiers to be consistently confused. The new dataset has 7,500 images, which we personally labeled over several months.
ArXiV: https://arxiv.org/abs/1907.07174
Dataset and code: https://github.com/hendrycks/natural-adv-examples
#Dataset #Adversarial
{kind=link}
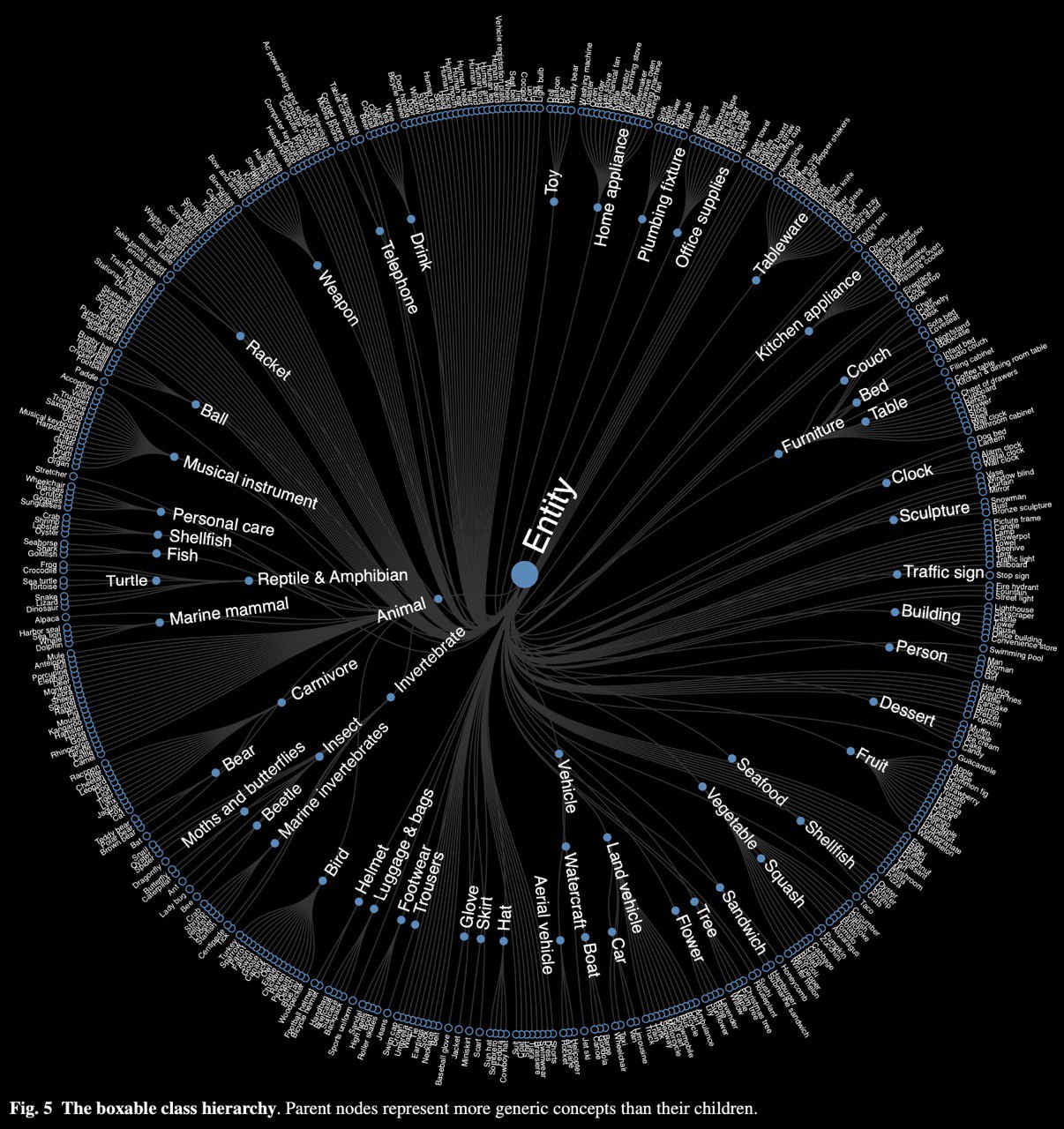
The Open Images Dataset V4 by GoogleAI
#GoogleAI present #OpenImagesV4, a #dataset of 9.2M images with unified annotations for:
– image #classification
– object #detection
– visual relationship detection
30.1M image-level labels for 19.8k concepts, 15.4M bounding boxes for 600 object classes
paper: https://arxiv.org/abs/1811.00982v2
#GoogleAI present #OpenImagesV4, a #dataset of 9.2M images with unified annotations for:
– image #classification
– object #detection
– visual relationship detection
30.1M image-level labels for 19.8k concepts, 15.4M bounding boxes for 600 object classes
paper: https://arxiv.org/abs/1811.00982v2
{kind=link}
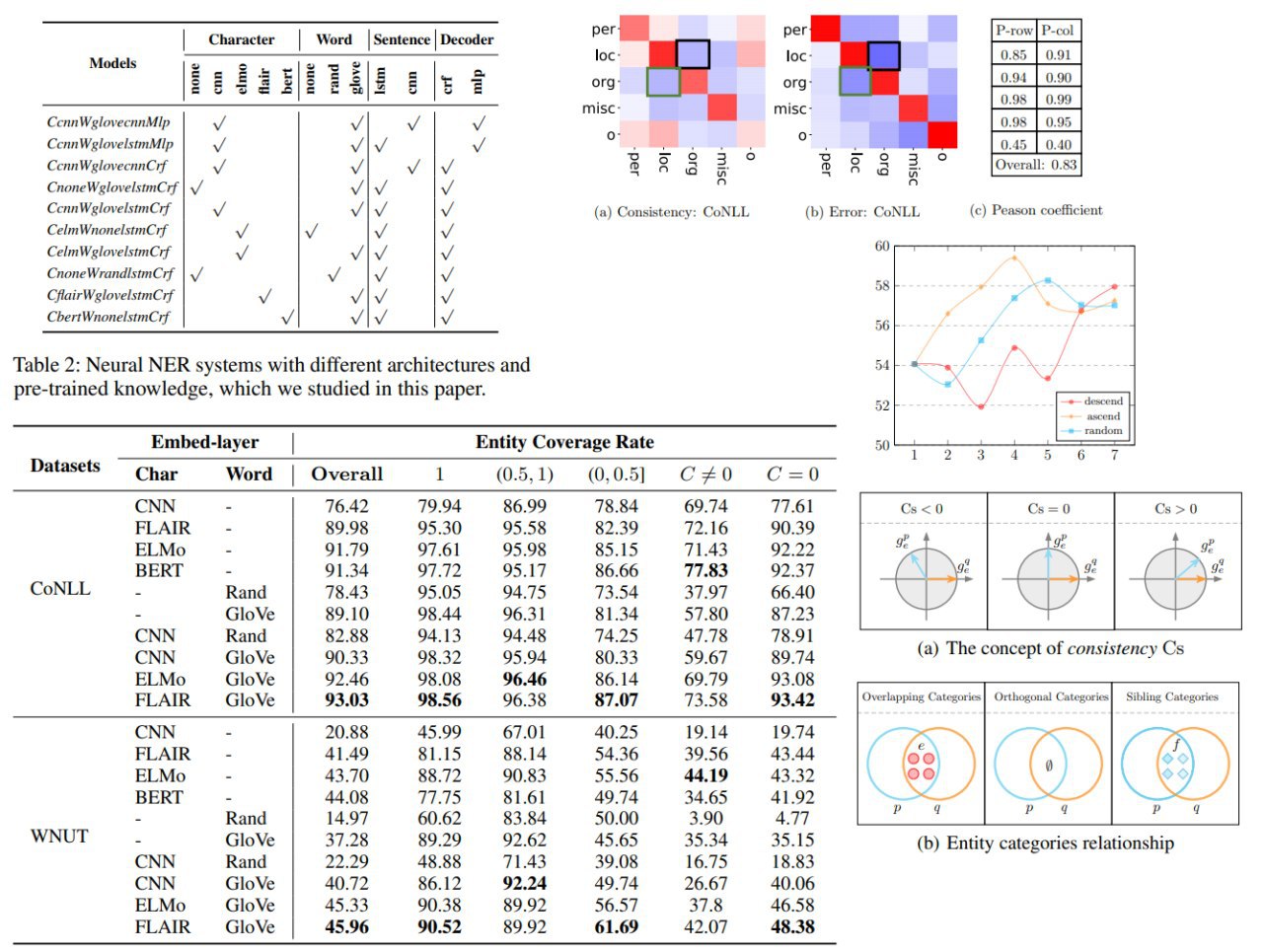
Rethinking Generalization of Neural Models: A Named Entity Recognition Case Study
Authors use the NER task to analyze the generalization behavior of existing models from different perspectives. Experiments with in-depth analyses diagnose the bottleneck of existing neural NER models in terms of breakdown performance analysis, annotation errors, dataset bias, and category relationships, which suggest directions for improvement.
The authors also release two datasets for future research: ReCoNLL and PLONER.
The main findings of the paper:
– the performance of existing models (including the state-of-the-art model) heavily influenced by the degree to which test entities have been seen in the training set with the same label
– the proposed measure enables to detect human annotation errors.
Once these errors are fixed, previous models can achieve new state-of-the-art results
– authors introduce two measures to characterize the data bias and the cross-dataset generalization experiment shows that the performance of NER systems is influenced not only by whether the test entity has been seen in the training set but also by whether the context of the test entity has been observed
– providing more training samples is not a guarantee of better results. A targeted increase in training samples will make it more profitable
– the relationship between entity categories influences the difficulty of model learning, which leads to some hard test samples that are difficult to solve using common learning methods
Paper: https://arxiv.org/abs/2001.03844
Github: https://github.com/pfliu-nlp/Named-Entity-Recognition-NER-Papers
Website: http://pfliu.com/InterpretNER/
#nlp #generalization #NER #annotations #dataset
Authors use the NER task to analyze the generalization behavior of existing models from different perspectives. Experiments with in-depth analyses diagnose the bottleneck of existing neural NER models in terms of breakdown performance analysis, annotation errors, dataset bias, and category relationships, which suggest directions for improvement.
The authors also release two datasets for future research: ReCoNLL and PLONER.
The main findings of the paper:
– the performance of existing models (including the state-of-the-art model) heavily influenced by the degree to which test entities have been seen in the training set with the same label
– the proposed measure enables to detect human annotation errors.
Once these errors are fixed, previous models can achieve new state-of-the-art results
– authors introduce two measures to characterize the data bias and the cross-dataset generalization experiment shows that the performance of NER systems is influenced not only by whether the test entity has been seen in the training set but also by whether the context of the test entity has been observed
– providing more training samples is not a guarantee of better results. A targeted increase in training samples will make it more profitable
– the relationship between entity categories influences the difficulty of model learning, which leads to some hard test samples that are difficult to solve using common learning methods
Paper: https://arxiv.org/abs/2001.03844
Github: https://github.com/pfliu-nlp/Named-Entity-Recognition-NER-Papers
Website: http://pfliu.com/InterpretNER/
#nlp #generalization #NER #annotations #dataset
{kind=link}
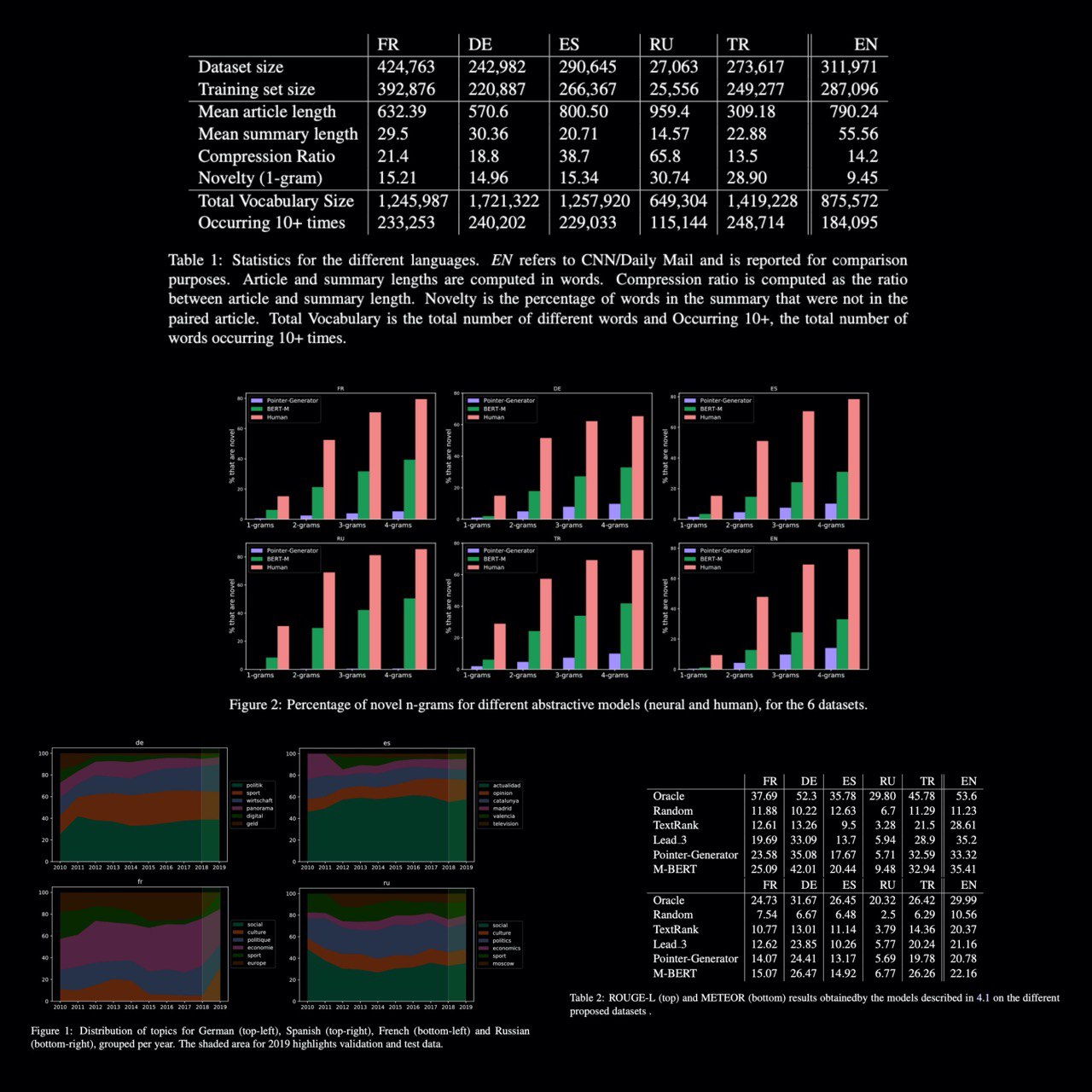
MLSUM: The Multilingual Summarization Corpus
The first large-scale MultiLingual SUMmarization dataset, comprising over 1.5M article/summary pairs in French, German, Russian, Spanish, and Turkish. Its complementary nature to the CNN/DM summarization dataset for English.
For each language, they selected an online newspaper from 2010 to 2019 which met the following requirements:
0 being a generalist newspaper: ensuring that a broad range of topics is represented for each language allows minimizing the risk of training topic-specific models, a fact which would hinder comparative cross-lingual analyses of the models.
1 having a large number of articles in their public online archive.
2 Providing human written highlights/summaries for the articles that can be extracted from the HTML code of the web page.
Also, in this paper, you can remember about similar other datasets
paper: https://arxiv.org/abs/2004.14900
github: https://github.com/recitalAI/MLSUM
Instructions and code will soon.
#nlp #corpus #dataset #multilingual
The first large-scale MultiLingual SUMmarization dataset, comprising over 1.5M article/summary pairs in French, German, Russian, Spanish, and Turkish. Its complementary nature to the CNN/DM summarization dataset for English.
For each language, they selected an online newspaper from 2010 to 2019 which met the following requirements:
0 being a generalist newspaper: ensuring that a broad range of topics is represented for each language allows minimizing the risk of training topic-specific models, a fact which would hinder comparative cross-lingual analyses of the models.
1 having a large number of articles in their public online archive.
2 Providing human written highlights/summaries for the articles that can be extracted from the HTML code of the web page.
Also, in this paper, you can remember about similar other datasets
paper: https://arxiv.org/abs/2004.14900
github: https://github.com/recitalAI/MLSUM
Instructions and code will soon.
#nlp #corpus #dataset #multilingual
{kind=link}
Clothing Dataset: Call for Action
Help to collect a public-domain dataset with images of clothes
Medium post: https://medium.com/data-science-insider/clothing-dataset-call-for-action-3cad023246c1
#dataset #clothing #cv #calltoarms
Help to collect a public-domain dataset with images of clothes
Medium post: https://medium.com/data-science-insider/clothing-dataset-call-for-action-3cad023246c1
#dataset #clothing #cv #calltoarms
{kind=link}
Forwarded from Spark in me (Alexander)
Ukrainian Open STT 1000 Hours
Following the path of Open STT in Russian, now you can enjoy a similar dataset in Ukrainian:
- Torrent Link
- GitHub Link
Congratulations to our Ukrainian friends for finally publishing a diverse easily downloadable dataset!
Their pages / dataset UX is still a bit rough on the edges, but compared how fast for example Common Voice accumulates data (130 hours for Russian and 43 hours for Ukrainian), UA Open STT and Open STT remain the best resource for respective languages to date.
Also unlike the majority of STT datasets which are (i) behind a paywall or sponsored by corporations (ii) have limited scope / domains (iii) fit some sort of agenda (i.e. use more GPUs than necessary, use our bloated tools, etc), this dataset is legit made by real people.
Also recently corporations have taken up the trend of rehashing publicly available data, which is cool, but unique data is still nowhere to be seen for obvious reasons (except for Common Voice, which is decent only for English).
#dataset
Following the path of Open STT in Russian, now you can enjoy a similar dataset in Ukrainian:
- Torrent Link
- GitHub Link
Congratulations to our Ukrainian friends for finally publishing a diverse easily downloadable dataset!
Their pages / dataset UX is still a bit rough on the edges, but compared how fast for example Common Voice accumulates data (130 hours for Russian and 43 hours for Ukrainian), UA Open STT and Open STT remain the best resource for respective languages to date.
Also unlike the majority of STT datasets which are (i) behind a paywall or sponsored by corporations (ii) have limited scope / domains (iii) fit some sort of agenda (i.e. use more GPUs than necessary, use our bloated tools, etc), this dataset is legit made by real people.
Also recently corporations have taken up the trend of rehashing publicly available data, which is cool, but unique data is still nowhere to be seen for obvious reasons (except for Common Voice, which is decent only for English).
#dataset
GitHub
GitHub - snakers4/open_stt: Open STT
Open STT. Contribute to snakers4/open_stt development by creating an account on GitHub.
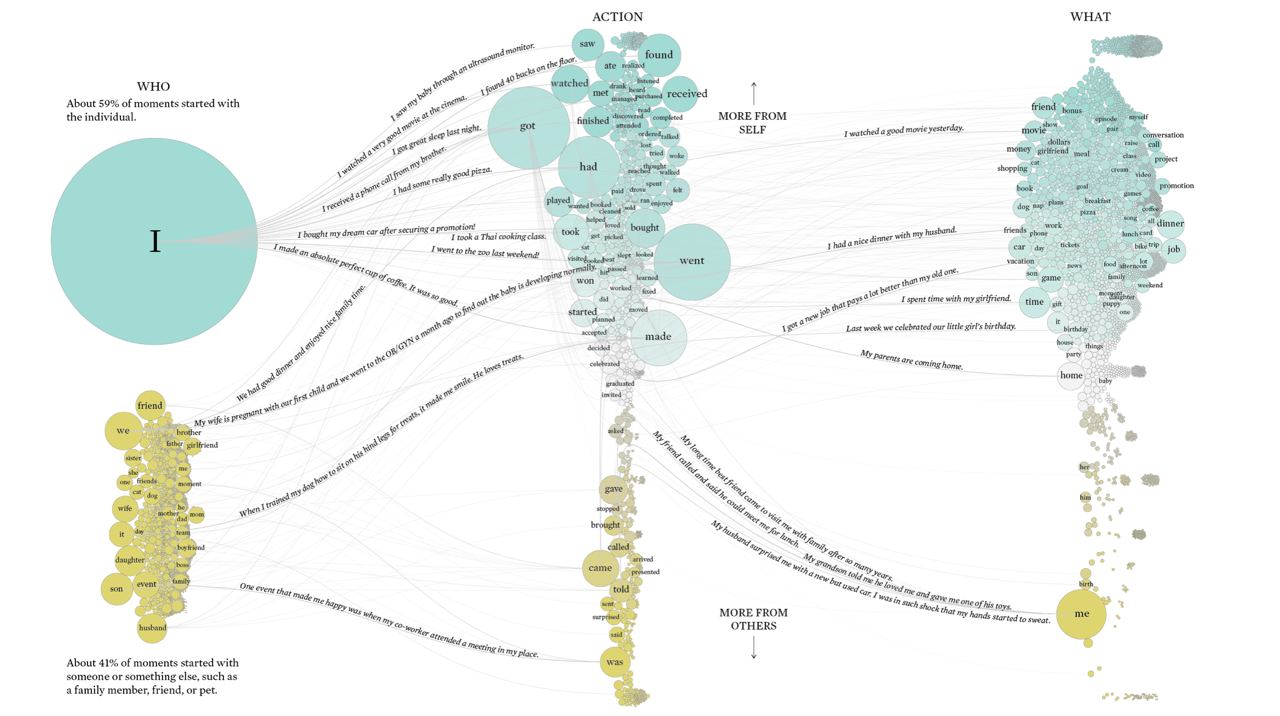
Counting Happiness and Where it Comes From
Researches asked 10 000 Mechanical Turk participants to name 10 things which are making them happy, resulting in creation of HappyDB.
And since that DB is open, Nathan Yau analyzed and vizualized this database in the perspective of subjects and actions, producing intersting visualization.
Hope that daily reading @opendatascience makes you at least content, if not happy.
Happines reason visualization link: https://flowingdata.com/2021/07/29/counting-happiness
HappyDB link: https://megagon.ai/projects/happydb-a-happiness-database-of-100000-happy-moments/
#dataset #emotions #visualization
Researches asked 10 000 Mechanical Turk participants to name 10 things which are making them happy, resulting in creation of HappyDB.
And since that DB is open, Nathan Yau analyzed and vizualized this database in the perspective of subjects and actions, producing intersting visualization.
Hope that daily reading @opendatascience makes you at least content, if not happy.
Happines reason visualization link: https://flowingdata.com/2021/07/29/counting-happiness
HappyDB link: https://megagon.ai/projects/happydb-a-happiness-database-of-100000-happy-moments/
#dataset #emotions #visualization
{kind=link}
🦜 Hi!
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
GitHub
ultimate_posts/where_to_start at master · open-data-science/ultimate_posts
Ultimate posts for opendatascience telegram channel - open-data-science/ultimate_posts
Forwarded from Machinelearning
🗿 StyleNeRF: A Style-based 3D-Aware Generator for High-resolution Image Synthesis
Github: https://github.com/facebookresearch/StyleNeRF
Video: http://jiataogu.me/style_nerf
Paper: https://arxiv.org/abs/2110.08985
Project: http://jiataogu.me/style_nerf/
Dataset: https://github.com/facebookresearch/StyleNeRF#dataset
@ai_machinelearning_big_data
Github: https://github.com/facebookresearch/StyleNeRF
Video: http://jiataogu.me/style_nerf
Paper: https://arxiv.org/abs/2110.08985
Project: http://jiataogu.me/style_nerf/
Dataset: https://github.com/facebookresearch/StyleNeRF#dataset
@ai_machinelearning_big_data
Segment Anything
The Segment Anything project aims to democratize image segmentation in computer vision, a core task used across various applications such as scientific imagery analysis and photo editing. Traditionally, accurate segmentation models require specialized expertise, AI training infrastructure, and large amounts of annotated data. This project introduces a new task, dataset, and model for image segmentation to overcome these challenges and make segmentation more accessible.
The researchers are releasing the Segment Anything Model (SAM) and the Segment Anything 1-Billion mask dataset (SA-1B), the largest segmentation dataset to date. These resources will enable a wide range of applications and further research into foundational models for computer vision. The SA-1B dataset is available for research purposes, while the SAM is provided under the permissive Apache 2.0 open license. Users can explore the demo to try SAM with their own images.
Paper link: https://arxiv.org/abs/2304.02643
Code link: https://github.com/facebookresearch/segment-anything
Demo link: https://segment-anything.com/demo
Blogpost link: https://ai.facebook.com/blog/segment-anything-foundation-model-image-segmentation/
Dataset link: https://ai.facebook.com/datasets/segment-anything/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-sam
#deeplearning #cv #pytorch #imagesegmentation #dataset
The Segment Anything project aims to democratize image segmentation in computer vision, a core task used across various applications such as scientific imagery analysis and photo editing. Traditionally, accurate segmentation models require specialized expertise, AI training infrastructure, and large amounts of annotated data. This project introduces a new task, dataset, and model for image segmentation to overcome these challenges and make segmentation more accessible.
The researchers are releasing the Segment Anything Model (SAM) and the Segment Anything 1-Billion mask dataset (SA-1B), the largest segmentation dataset to date. These resources will enable a wide range of applications and further research into foundational models for computer vision. The SA-1B dataset is available for research purposes, while the SAM is provided under the permissive Apache 2.0 open license. Users can explore the demo to try SAM with their own images.
Paper link: https://arxiv.org/abs/2304.02643
Code link: https://github.com/facebookresearch/segment-anything
Demo link: https://segment-anything.com/demo
Blogpost link: https://ai.facebook.com/blog/segment-anything-foundation-model-image-segmentation/
Dataset link: https://ai.facebook.com/datasets/segment-anything/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-sam
#deeplearning #cv #pytorch #imagesegmentation #dataset
{kind=link}