
DeepLearning ru:
Clockwork Convnets for Video Semantic Segmentation.
Adaptive video processing by incorporating data-driven clocks.
We define a novel family of "clockwork" convnets driven by fixed or adaptive clock signals that schedule the processing of different layers at different update rates according to their semantic stability. We design a pipeline schedule to reduce latency for real-time recognition and a fixed-rate schedule to reduce overall computation. Finally, we extend clockwork scheduling to adaptive video processing by incorporating data-driven clocks that can be tuned on unlabeled video.
https://arxiv.org/pdf/1608.03609v1.pdf
https://github.com/shelhamer/clockwork-fcn
http://www.gitxiv.com/posts/89zR7ATtd729JEJAg/clockwork-convnets-for-video-semantic-segmentation
#dl #CV #Caffe #video #Segmentation
Clockwork Convnets for Video Semantic Segmentation.
Adaptive video processing by incorporating data-driven clocks.
We define a novel family of "clockwork" convnets driven by fixed or adaptive clock signals that schedule the processing of different layers at different update rates according to their semantic stability. We design a pipeline schedule to reduce latency for real-time recognition and a fixed-rate schedule to reduce overall computation. Finally, we extend clockwork scheduling to adaptive video processing by incorporating data-driven clocks that can be tuned on unlabeled video.
https://arxiv.org/pdf/1608.03609v1.pdf
https://github.com/shelhamer/clockwork-fcn
http://www.gitxiv.com/posts/89zR7ATtd729JEJAg/clockwork-convnets-for-video-semantic-segmentation
#dl #CV #Caffe #video #Segmentation
GitHub
shelhamer/clockwork-fcn
Clockwork Convnets for Video Semantic Segmenation. Contribute to shelhamer/clockwork-fcn development by creating an account on GitHub.
Deep Bilateral Learning for Real-Time Image Enhancement
Video about image auto-enhancing with neural networks.
https://www.youtube.com/watch?v=GAe0qKKQY_I
#cv #dl #autoenhance #mit #youtube #video
Video about image auto-enhancing with neural networks.
https://www.youtube.com/watch?v=GAe0qKKQY_I
#cv #dl #autoenhance #mit #youtube #video
YouTube
Deep Bilateral Learning for Real-Time Image Enhancement
Performance is a critical challenge in mobile image processing. Given a reference imaging pipeline, or even human-adjusted pairs of images, we seek to reproduce the enhancements and enable real-time evaluation. For this, we introduce a new neural network…
STMVis - Visual Analysis for Recurrent Neural Networks
LSTMVis a visual analysis tool for recurrent neural networks with a focus on understanding these hidden state dynamics. The tool allows a user to select a hypothesis input range to focus on local state changes, to match these states changes to similar patterns in a large data set, and to align these results with structural annotations from their domain. We provide data for the tool to analyze specific hidden state properties on dataset containing nesting, phrase structure, and chord progressions, and demonstrate how the tool can be used to isolate patterns for further statistical analysis.
http://lstm.seas.harvard.edu/
#harvard #video #dl #rnn
LSTMVis a visual analysis tool for recurrent neural networks with a focus on understanding these hidden state dynamics. The tool allows a user to select a hypothesis input range to focus on local state changes, to match these states changes to similar patterns in a large data set, and to align these results with structural annotations from their domain. We provide data for the tool to analyze specific hidden state properties on dataset containing nesting, phrase structure, and chord progressions, and demonstrate how the tool can be used to isolate patterns for further statistical analysis.
http://lstm.seas.harvard.edu/
#harvard #video #dl #rnn
lstm.seas.harvard.edu
LSTMVis
A visual analysis tool for recurrent neural networks
Architecture for real-time scene annotation (BlitzNet)
http://thoth.inrialpes.fr/research/blitznet/
ArxiV: https://arxiv.org/abs/1708.02813
GitHub: https://github.com/dvornikita/blitznet
#ICCV #github #dl #video
http://thoth.inrialpes.fr/research/blitznet/
ArxiV: https://arxiv.org/abs/1708.02813
GitHub: https://github.com/dvornikita/blitznet
#ICCV #github #dl #video
GitHub
GitHub - dvornikita/blitznet: Deep neural network for object detection and semantic segmentation in real-time. Official code for…
Deep neural network for object detection and semantic segmentation in real-time. Official code for the paper "BlitzNet: A Real-Time Deep Network for Scene Understanding" - GitHub ...
A cool paper from Facebook AI (not from FAIR!) about detecting and reading text in images, at scale.
This is very useful for detecting inappropriate content on Facebook.
The system uses R-CNN/Detectron for detecting lines of text.
The OCR uses a ConvNet applied at the level of a whole line trained with CTC.
This concept of applying a ConvNet on a whole line of text, without prior segmentation, has roots in the early days of ConvNets, for example with this NIPS 1992 paper:
"Multi-Digit Recognition Using a Space Displacement Neural Network"
by Ofer Matan, Chris Burges, Yann LeCun and John Denker.
Link: https://papers.nips.cc/paper/557-multi-digit-recognition-using-a-space-displacement-neural-network
Youtuve video with short explanation: https://youtu.be/yl3P2tYewVg
#ocr #cv #dl #rnn #facebook #yannlecun #video
This is very useful for detecting inappropriate content on Facebook.
The system uses R-CNN/Detectron for detecting lines of text.
The OCR uses a ConvNet applied at the level of a whole line trained with CTC.
This concept of applying a ConvNet on a whole line of text, without prior segmentation, has roots in the early days of ConvNets, for example with this NIPS 1992 paper:
"Multi-Digit Recognition Using a Space Displacement Neural Network"
by Ofer Matan, Chris Burges, Yann LeCun and John Denker.
Link: https://papers.nips.cc/paper/557-multi-digit-recognition-using-a-space-displacement-neural-network
Youtuve video with short explanation: https://youtu.be/yl3P2tYewVg
#ocr #cv #dl #rnn #facebook #yannlecun #video
papers.nips.cc
Multi-Digit Recognition Using a Space Displacement Neural Network
Electronic Proceedings of Neural Information Processing Systems
#MIT recent release for video labeling
Youtube: https://www.youtube.com/watch?v=JBwSk6nJOyM&feature=youtu.be
Github: https://github.com/metalbubble/TRN-pytorch
#dl #video
Youtube: https://www.youtube.com/watch?v=JBwSk6nJOyM&feature=youtu.be
Github: https://github.com/metalbubble/TRN-pytorch
#dl #video
YouTube
How a Temporal Relation Network understands what's going on there
Prediction of the on-going activity from a TRN is shown. Yes, I am playing my hands :)
Model of TRN and code are available at https://github.com/metalbubble/TRN-pytorch
Model is trained on Something-Something-V2 dataset.
Model of TRN and code are available at https://github.com/metalbubble/TRN-pytorch
Model is trained on Something-Something-V2 dataset.
🎓 Free «Advanced Deep Learning and Reinforcement Learning» course.
#DeepMind researchers have released video recordings of lectures from «Advanced Deep Learning and Reinforcement Learning» a course on deep RL taught at #UCL earlier this year.
YouTube Playlist: https://www.youtube.com/playlist?list=PLqYmG7hTraZDNJre23vqCGIVpfZ_K2RZs
#course #video #RL #DL
#DeepMind researchers have released video recordings of lectures from «Advanced Deep Learning and Reinforcement Learning» a course on deep RL taught at #UCL earlier this year.
YouTube Playlist: https://www.youtube.com/playlist?list=PLqYmG7hTraZDNJre23vqCGIVpfZ_K2RZs
#course #video #RL #DL
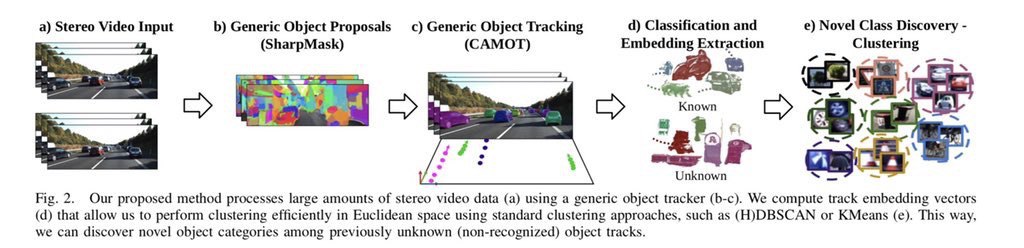
Large-Scale Object Mining for Object Discovery from Unlabeled Video
Paper about process of object discovery.
Link: https://arxiv.org/abs/1903.00362
#Video #DL #CV
Paper about process of object discovery.
Link: https://arxiv.org/abs/1903.00362
#Video #DL #CV
{kind=link}
Google announced the updated YouTube-8M dataset
Updated set now includes a subset with verified 5-s segment level labels, along with the 3rd Large-Scale Video Understanding Challenge and Workshop at #ICCV19.
Link: https://ai.googleblog.com/2019/06/announcing-youtube-8m-segments-dataset.html
#Google #YouTube #CV #DL #Video #dataset
Updated set now includes a subset with verified 5-s segment level labels, along with the 3rd Large-Scale Video Understanding Challenge and Workshop at #ICCV19.
Link: https://ai.googleblog.com/2019/06/announcing-youtube-8m-segments-dataset.html
#Google #YouTube #CV #DL #Video #dataset
{kind=link}
Simultaneous food and facial recognition at a Foxconn factory canteen, Shenzhen China
#video #foodlearning #facerecogniction #dl #cv #foxconn
#video #foodlearning #facerecogniction #dl #cv #foxconn
Facebook open sourced video alignment algorithms that detect identical and near identical videos to build more robust defenses against harmful visual content.
Project page: https://newsroom.fb.com/news/2019/08/open-source-photo-video-matching/
Code: https://github.com/facebookresearch/videoalignment
#Facebook #video #cv #dl
Project page: https://newsroom.fb.com/news/2019/08/open-source-photo-video-matching/
Code: https://github.com/facebookresearch/videoalignment
#Facebook #video #cv #dl
Meta
Open-Sourcing Photo- and Video-Matching Technology to Make the Internet Safer | Meta
We're sharing some of the tech we use to fight abuse on our platform with others.
Deep Fake Challenge by Facebook team
#Facebook launches a competition to fight deep fakes. Unfortunately, results of this competition will be obviously used to create better fakes, to the cheers of the people, wishing to watch the Matrix with Bruce Lee or more questionable deep fake applications.
Link: https://ai.facebook.com/blog/deepfake-detection-challenge/
#deepfake #video #cv #dl
#Facebook launches a competition to fight deep fakes. Unfortunately, results of this competition will be obviously used to create better fakes, to the cheers of the people, wishing to watch the Matrix with Bruce Lee or more questionable deep fake applications.
Link: https://ai.facebook.com/blog/deepfake-detection-challenge/
#deepfake #video #cv #dl
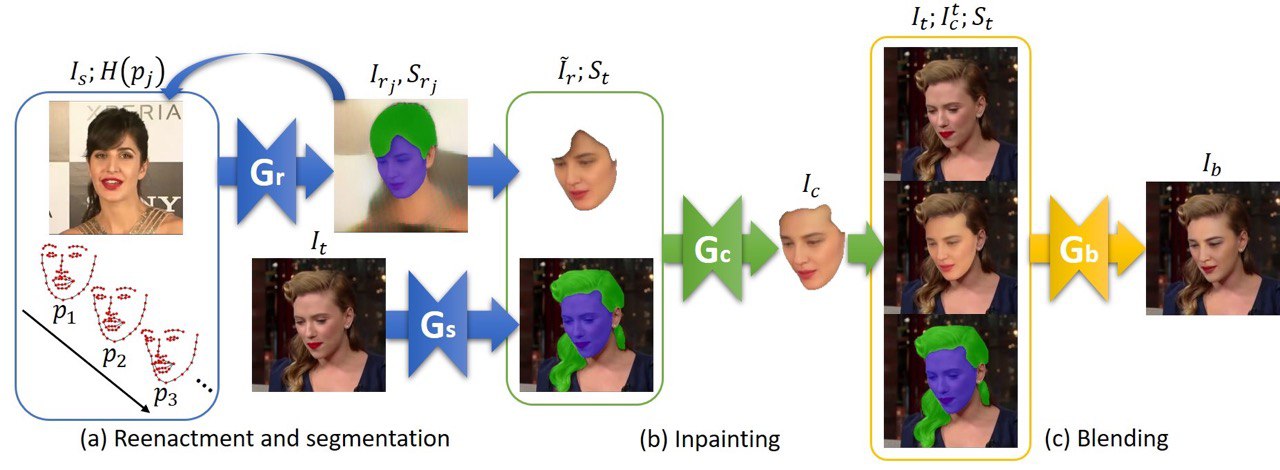
FSGAN: Subject Agnostic Face Swapping and Reenactment
New paper on #DeepFakes creation
YouTube demo: https://www.youtube.com/watch?v=duo-tHbSdMk
Link: https://nirkin.com/fsgan/
ArXiV: https://arxiv.org/pdf/1908.05932.pdf
#FaceSwap #DL #Video #CV
New paper on #DeepFakes creation
YouTube demo: https://www.youtube.com/watch?v=duo-tHbSdMk
Link: https://nirkin.com/fsgan/
ArXiV: https://arxiv.org/pdf/1908.05932.pdf
#FaceSwap #DL #Video #CV
{kind=link}
Barak Obama’s deep fake video used as intro to MIT 6.S191 class
Brilliant idea to win attention of students and to demonstrate at the very beggining of the course one of the applications of the materials they have to stydy.
YouTube: https://www.youtube.com/watch?v=l82PxsKHxYc
#DL #DeepFake #MIT #video
Brilliant idea to win attention of students and to demonstrate at the very beggining of the course one of the applications of the materials they have to stydy.
YouTube: https://www.youtube.com/watch?v=l82PxsKHxYc
#DL #DeepFake #MIT #video
YouTube
Barack Obama: Intro to Deep Learning | MIT 6.S191
MIT Introduction to Deep Learning 6.S191 (2020)
DISCLAIMER: The following video is synthetic and was created using deep learning with simultaneous speech-to-speech translation as well as video dialogue replacement (CannyAI).
** NOTE**: The audio quality…
DISCLAIMER: The following video is synthetic and was created using deep learning with simultaneous speech-to-speech translation as well as video dialogue replacement (CannyAI).
** NOTE**: The audio quality…
Castle in the Sky
Dynamic Sky Replacement and Harmonization in Videos
Fascinating and ready to be applied for work. (With colab notebook)
The authors proposed a method to replace the sky in the video that works well in high resolution. The results are very impressive. The method runs in real-time and produces video almost without glitches and artifacts. Also, can generate for example lightning and glow on target video.
The pipeline is quite complicated and contains several tasks:
– A sky matting network to segmentation sky on video frames
– A motion estimator for sky objects
– A skybox for blending where sky and other environments on video are relighting and recoloring.
Authors say their work, in a nutshell, proposes a new framework for sky augmentation in outdoor videos. The solution is purely vision-based and it can be applied to both online and offline scenarios.
But let's take a closer look.
A sky matting module is a ResNet-like encoder and several layers upsampling decoder to solve sky pixel-wise segmentation tasks followed by a refinement stage with guided image filtering.
A motion estimator directly estimates the motion of the objects in the sky. The motion patterns are modeled by an affine matrix and optical flow.
The sky image blending module is a decoder that models a linear combination of target sky matte and aligned sky template.
Overall, the network architecture is ResNet-50 as encoder and decoder with coordConv upsampling layers with skip connections and implemented in Pytorch,
The result is presented in a very cool video https://youtu.be/zal9Ues0aOQ
site: https://jiupinjia.github.io/skyar/
paper: https://arxiv.org/abs/2010.11800
github: https://github.com/jiupinjia/SkyAR
#sky #CV #video #cool #resnet
Dynamic Sky Replacement and Harmonization in Videos
Fascinating and ready to be applied for work. (With colab notebook)
The authors proposed a method to replace the sky in the video that works well in high resolution. The results are very impressive. The method runs in real-time and produces video almost without glitches and artifacts. Also, can generate for example lightning and glow on target video.
The pipeline is quite complicated and contains several tasks:
– A sky matting network to segmentation sky on video frames
– A motion estimator for sky objects
– A skybox for blending where sky and other environments on video are relighting and recoloring.
Authors say their work, in a nutshell, proposes a new framework for sky augmentation in outdoor videos. The solution is purely vision-based and it can be applied to both online and offline scenarios.
But let's take a closer look.
A sky matting module is a ResNet-like encoder and several layers upsampling decoder to solve sky pixel-wise segmentation tasks followed by a refinement stage with guided image filtering.
A motion estimator directly estimates the motion of the objects in the sky. The motion patterns are modeled by an affine matrix and optical flow.
The sky image blending module is a decoder that models a linear combination of target sky matte and aligned sky template.
Overall, the network architecture is ResNet-50 as encoder and decoder with coordConv upsampling layers with skip connections and implemented in Pytorch,
The result is presented in a very cool video https://youtu.be/zal9Ues0aOQ
site: https://jiupinjia.github.io/skyar/
paper: https://arxiv.org/abs/2010.11800
github: https://github.com/jiupinjia/SkyAR
#sky #CV #video #cool #resnet
YouTube
Dynamic Sky Replacement and Harmonization in Videos
Preprint: Castle in the Sky: Zhengxia Zou, Dynamic Sky Replacement and Harmonization in Videos, 2020.
Project page: https://jiupinjia.github.io/skyar/
Project page: https://jiupinjia.github.io/skyar/