
Generalization through Memorization: Nearest Neighbor Language Models
Introduced kNN-LMs, which extend LMs with nearest neighbor search in embedding space, achieving a new SOTA perplexity on Wikitext-103, without additional training!
Also show that kNN-LM can efficiently scale up LMs to larger training sets and allows for effective domain adaptation, by simply varying the nearest neighbor datastore without further training. It seems to be helpful in predicting long tail patterns, such as factual knowledge!
code available soon
Paper: https://arxiv.org/abs/1911.00172
#nlp #generalization #kNN
Introduced kNN-LMs, which extend LMs with nearest neighbor search in embedding space, achieving a new SOTA perplexity on Wikitext-103, without additional training!
Also show that kNN-LM can efficiently scale up LMs to larger training sets and allows for effective domain adaptation, by simply varying the nearest neighbor datastore without further training. It seems to be helpful in predicting long tail patterns, such as factual knowledge!
code available soon
Paper: https://arxiv.org/abs/1911.00172
#nlp #generalization #kNN
{kind=link}
Rethinking Generalization of Neural Models: A Named Entity Recognition Case Study
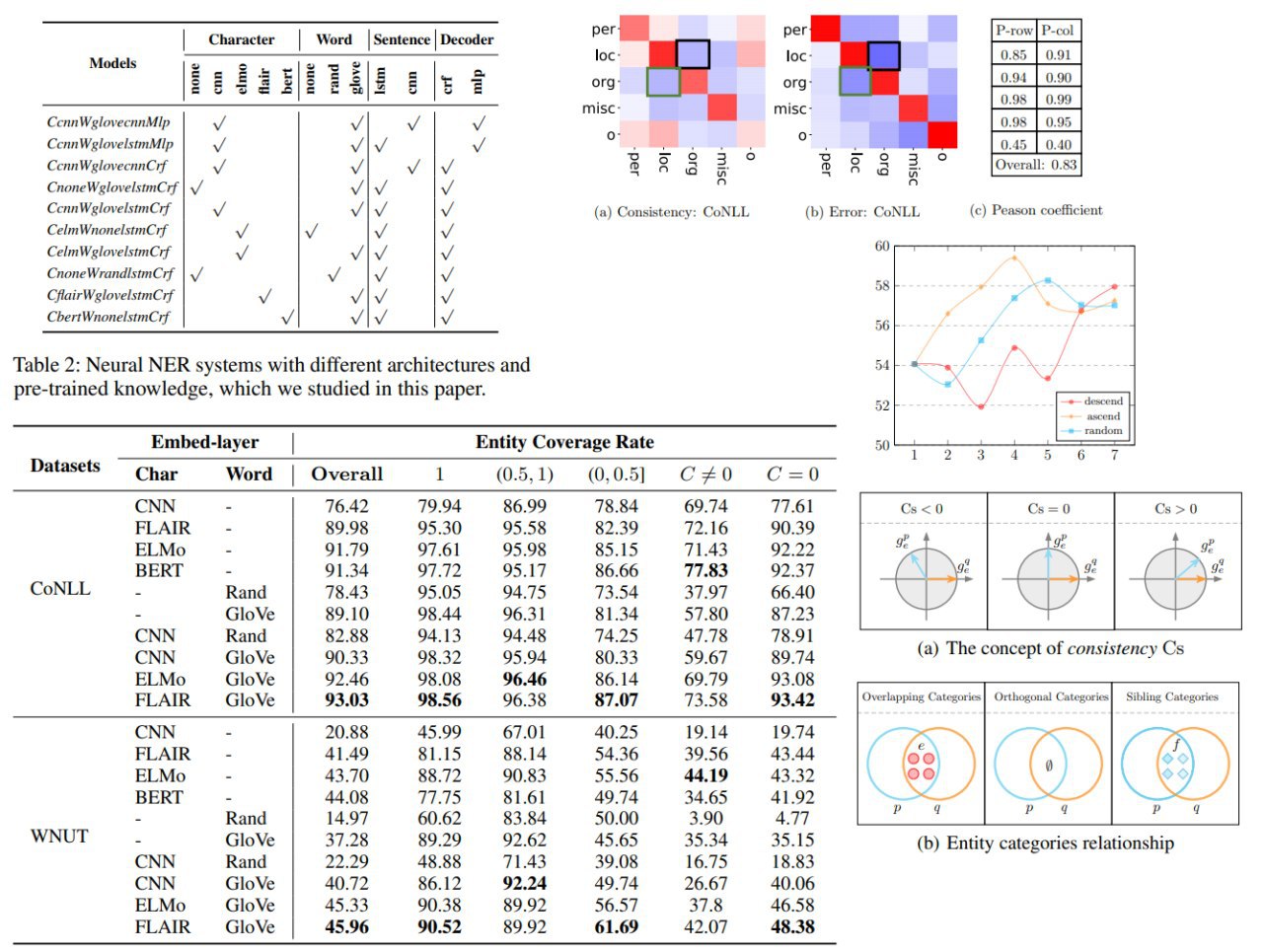
Authors use the NER task to analyze the generalization behavior of existing models from different perspectives. Experiments with in-depth analyses diagnose the bottleneck of existing neural NER models in terms of breakdown performance analysis, annotation errors, dataset bias, and category relationships, which suggest directions for improvement.
The authors also release two datasets for future research: ReCoNLL and PLONER.
The main findings of the paper:
– the performance of existing models (including the state-of-the-art model) heavily influenced by the degree to which test entities have been seen in the training set with the same label
– the proposed measure enables to detect human annotation errors.
Once these errors are fixed, previous models can achieve new state-of-the-art results
– authors introduce two measures to characterize the data bias and the cross-dataset generalization experiment shows that the performance of NER systems is influenced not only by whether the test entity has been seen in the training set but also by whether the context of the test entity has been observed
– providing more training samples is not a guarantee of better results. A targeted increase in training samples will make it more profitable
– the relationship between entity categories influences the difficulty of model learning, which leads to some hard test samples that are difficult to solve using common learning methods
Paper: https://arxiv.org/abs/2001.03844
Github: https://github.com/pfliu-nlp/Named-Entity-Recognition-NER-Papers
Website: http://pfliu.com/InterpretNER/
#nlp #generalization #NER #annotations #dataset
Authors use the NER task to analyze the generalization behavior of existing models from different perspectives. Experiments with in-depth analyses diagnose the bottleneck of existing neural NER models in terms of breakdown performance analysis, annotation errors, dataset bias, and category relationships, which suggest directions for improvement.
The authors also release two datasets for future research: ReCoNLL and PLONER.
The main findings of the paper:
– the performance of existing models (including the state-of-the-art model) heavily influenced by the degree to which test entities have been seen in the training set with the same label
– the proposed measure enables to detect human annotation errors.
Once these errors are fixed, previous models can achieve new state-of-the-art results
– authors introduce two measures to characterize the data bias and the cross-dataset generalization experiment shows that the performance of NER systems is influenced not only by whether the test entity has been seen in the training set but also by whether the context of the test entity has been observed
– providing more training samples is not a guarantee of better results. A targeted increase in training samples will make it more profitable
– the relationship between entity categories influences the difficulty of model learning, which leads to some hard test samples that are difficult to solve using common learning methods
Paper: https://arxiv.org/abs/2001.03844
Github: https://github.com/pfliu-nlp/Named-Entity-Recognition-NER-Papers
Website: http://pfliu.com/InterpretNER/
#nlp #generalization #NER #annotations #dataset
{kind=link}