
We got reached by a fellow DS channel editor, who's work definately deserves your attention: @machinelearning24x7. This is channel covering area similar to ours, lead by 'Machine Learning India' community.
Hope you find theirs work interesting!
Hope you find theirs work interesting!
Forwarded from Age Of Geeks
Analytics India Magazine: AI-Based System Can Now Turn Brainwaves Into Text.
https://analyticsindiamag.com/ai-based-system-can-now-turn-brainwaves-into-text/
https://analyticsindiamag.com/ai-based-system-can-now-turn-brainwaves-into-text/
Analytics India Magazine
AI-Based System Can Now Turn Brainwaves Into Text
Scientists have developed an AI system that converts brain activity into text result in transforming communication for those can’t speak.
Live U-Net implementation online session today
Famous Abhishek Thakur (First 4x GM on Kaggle) is going to show you how to implement the original U-Net with #PyTorch.
Session starts in 4 hours from now (at 6PM CET / 9.30PM IST), make sure you turned the notifications on if you are interested.
YouTube Link: https://www.youtube.com/watch?v=u1loyDCoGbE
#Livecoding #Unet
Famous Abhishek Thakur (First 4x GM on Kaggle) is going to show you how to implement the original U-Net with #PyTorch.
Session starts in 4 hours from now (at 6PM CET / 9.30PM IST), make sure you turned the notifications on if you are interested.
YouTube Link: https://www.youtube.com/watch?v=u1loyDCoGbE
#Livecoding #Unet
YouTube
Implementing original U-Net from scratch using PyTorch
In this video, I show you how to implement original UNet paper using PyTorch. UNet paper can be found here: https://arxiv.org/abs/1505.04597
Please subscribe and like the video to help me keep motivated to make awesome videos like this one. :)
To buy my…
Please subscribe and like the video to help me keep motivated to make awesome videos like this one. :)
To buy my…
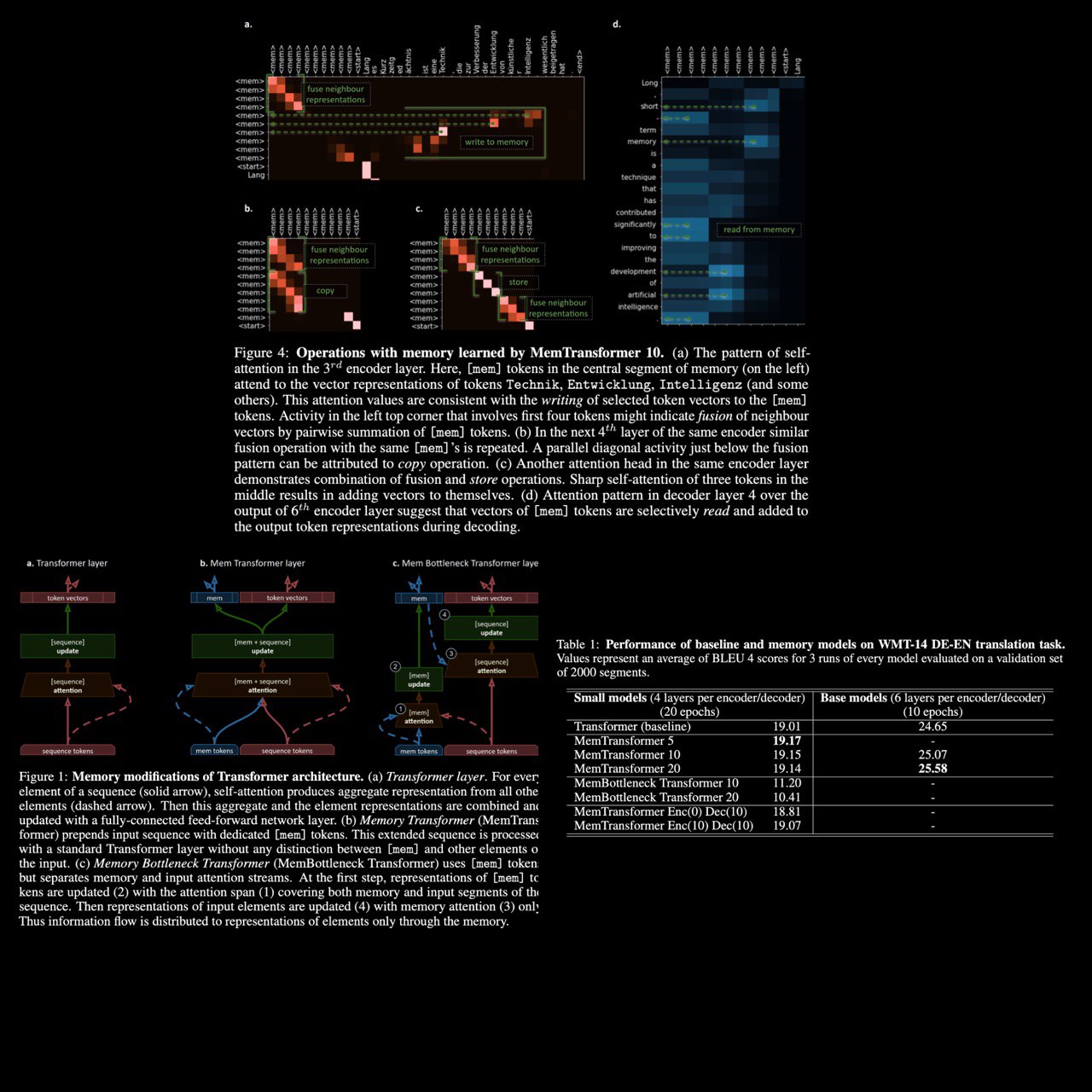
Memory Transformer
Burtsev & Sapunov
The authors proposed and studied two memory augmented architectures MemTransformer and MemBottleneck Transformer. Qualitative analysis of attention patterns produced by the transformer heads trained to solve machine translation task suggests that both models successfully discovered basic operations for memory control. Attention maps show evidence for the presence of memory read/write as well as some in-memory processing operations such as copying and summation.
A comparison of machine translation quality shows that adding general-purpose memory in MemTransformer improves performance over the baseline. Moreover, the speed of training and final quality positively correlates with the memory size. On the other hand, MemBottleneck Transformer, with all self-attention restricted to the memory only, has significantly lower scores after training.
Memory lesion tests demonstrate that the performance of the pre-trained MemTransformer model critically depends on the presence of memory. Still, the memory controller learned by the model degrades only gradually when memory size is changed during inference. This indicates that the controller has some robustness and ability for generalization.
More interesting figures u can check out in the attachment.
paper: https://arxiv.org/abs/2006.11527.pdf
#nlp #transformer #attention #machine #translation
Burtsev & Sapunov
The authors proposed and studied two memory augmented architectures MemTransformer and MemBottleneck Transformer. Qualitative analysis of attention patterns produced by the transformer heads trained to solve machine translation task suggests that both models successfully discovered basic operations for memory control. Attention maps show evidence for the presence of memory read/write as well as some in-memory processing operations such as copying and summation.
A comparison of machine translation quality shows that adding general-purpose memory in MemTransformer improves performance over the baseline. Moreover, the speed of training and final quality positively correlates with the memory size. On the other hand, MemBottleneck Transformer, with all self-attention restricted to the memory only, has significantly lower scores after training.
Memory lesion tests demonstrate that the performance of the pre-trained MemTransformer model critically depends on the presence of memory. Still, the memory controller learned by the model degrades only gradually when memory size is changed during inference. This indicates that the controller has some robustness and ability for generalization.
More interesting figures u can check out in the attachment.
paper: https://arxiv.org/abs/2006.11527.pdf
#nlp #transformer #attention #machine #translation
{kind=link}
🔥Logo generation autonomous system was revealed to be used in production for almost a year.
Leading Russia-based design studio Artlebedev revealed that they experimented with using neural networks and set of algorithmic systems to design logotypes for real customers. They named system Nikolay Ironov (in russian N.Ironov sounds close to Neuronov). The system realeased 17 commercial projects, which were welcomed by the audience.
Mishief managed! 😈
Link: https://www.artlebedev.com/ironov/
Project portfolio: https://www.artlebedev.ru/nikolay-ironov/
#GAN #design #logotypes #logo #generation #generative #artlebedev
Leading Russia-based design studio Artlebedev revealed that they experimented with using neural networks and set of algorithmic systems to design logotypes for real customers. They named system Nikolay Ironov (in russian N.Ironov sounds close to Neuronov). The system realeased 17 commercial projects, which were welcomed by the audience.
Mishief managed! 😈
Link: https://www.artlebedev.com/ironov/
Project portfolio: https://www.artlebedev.ru/nikolay-ironov/
#GAN #design #logotypes #logo #generation #generative #artlebedev
{kind=link}
Data Science by ODS.ai 🦜
🤖 The NetHack Learning Environment #Facebook launched new Reinforcement Learning environment for training agents based on #NetHack game. Nethack has nothing to do with what is considered common cybersecurity now, but it is an early terminal-based Minecraft…
Update from #Facebook on #Nethack learning Environment.
Link: https://ai.facebook.com/blog/nethack-learning-environment-to-advance-deep-reinforcement-learning
Publication: https://arxiv.org/abs/2006.13760
#RL
Link: https://ai.facebook.com/blog/nethack-learning-environment-to-advance-deep-reinforcement-learning
Publication: https://arxiv.org/abs/2006.13760
#RL
Pre-training via Paraphrasing
Mike Lewis, Marjan Ghazvininejad & etc. by Facebook AI
The authors introduce MARGE, a pre-trained seq2seq model learned with an unsupervised multi-lingual multi-document paraphrasing objective.
MARGE provides an alternative to the dominant masked language modeling paradigm, where they self-supervise the reconstruction of target text by retrieving a set of related texts (in many languages) and conditioning on them to maximize the likelihood of generating the original. Showed it is possible to jointly learn to do retrieval and reconstruction, given only a random initialization.
The objective noisily captures aspects of paraphrase, translation, multi-document summarization, and information retrieval, allowing for strong zero-shot performance on several tasks. For example, with no additional task-specific training they achieve BLEU scores of up to 35.8 for document translation.
Further show that fine-tuning gives a strong performance on a range of discriminative and generative tasks in many languages, making MARGE the most generally applicable pre-training method to date.
Future work should scale MARGE to more domains and languages, and study how to more closely align pre-training objectives with different end tasks.
paper: https://arxiv.org/abs/2006.15020.pdf
#nlp #paraphrasing #unsupervise
Mike Lewis, Marjan Ghazvininejad & etc. by Facebook AI
The authors introduce MARGE, a pre-trained seq2seq model learned with an unsupervised multi-lingual multi-document paraphrasing objective.
MARGE provides an alternative to the dominant masked language modeling paradigm, where they self-supervise the reconstruction of target text by retrieving a set of related texts (in many languages) and conditioning on them to maximize the likelihood of generating the original. Showed it is possible to jointly learn to do retrieval and reconstruction, given only a random initialization.
The objective noisily captures aspects of paraphrase, translation, multi-document summarization, and information retrieval, allowing for strong zero-shot performance on several tasks. For example, with no additional task-specific training they achieve BLEU scores of up to 35.8 for document translation.
Further show that fine-tuning gives a strong performance on a range of discriminative and generative tasks in many languages, making MARGE the most generally applicable pre-training method to date.
Future work should scale MARGE to more domains and languages, and study how to more closely align pre-training objectives with different end tasks.
paper: https://arxiv.org/abs/2006.15020.pdf
#nlp #paraphrasing #unsupervise
{kind=link}
(Re)Discovering Protein Structure and Function Through Language Modeling
Trained solely on unsupervised language modeling, the Transformer's attention mechanism recovers high-level structural (folding) and functional properties of proteins!
Why this is important: traditional protein modelling requires lots of computational power. This might be a key to more efficient structure modelling. Protein structure => function. Function => faster drug research and understanding of diseases mechanisms.
Blog: https://blog.einstein.ai/provis/
Paper: https://arxiv.org/abs/2006.15222
Code: https://github.com/salesforce/provis
#DL #NLU #proteinmodelling #bio #biolearning #insilico
Trained solely on unsupervised language modeling, the Transformer's attention mechanism recovers high-level structural (folding) and functional properties of proteins!
Why this is important: traditional protein modelling requires lots of computational power. This might be a key to more efficient structure modelling. Protein structure => function. Function => faster drug research and understanding of diseases mechanisms.
Blog: https://blog.einstein.ai/provis/
Paper: https://arxiv.org/abs/2006.15222
Code: https://github.com/salesforce/provis
#DL #NLU #proteinmodelling #bio #biolearning #insilico
🎙Mozilla’s Common Voice project
Mozilla launched a project to make digitalization of human voice more open and accessable. Anyone is eligible to download the dataset to use it for building #voicerecognition or #voicegeneration ML systems.
Most importantly, anyone can take a part in the project and make sure that her/his voice with all the accents and personal manner of speech features such as altitude, speed, clarity and timbre are accounted for in the models are to built.
Why is that important: if you have speech defects and you are not happy how machine speech translation works for you, or how well #Alexa or #Siri gets you, you should spend some time recording your voice for the Common Voice, to increase the probability of upcoming voice recognition model working great for you.
Project: https://voice.mozilla.org
Venturebeat article: https://venturebeat.com/2020/07/01/mozilla-common-voice-updates-will-help-train-the-hey-firefox-wakeword-for-voice-based-web-browsing/
#open #SpeechToText #TextToSpeech #DL #mozilla #audiolearning #voicerecognition
Mozilla launched a project to make digitalization of human voice more open and accessable. Anyone is eligible to download the dataset to use it for building #voicerecognition or #voicegeneration ML systems.
Most importantly, anyone can take a part in the project and make sure that her/his voice with all the accents and personal manner of speech features such as altitude, speed, clarity and timbre are accounted for in the models are to built.
Why is that important: if you have speech defects and you are not happy how machine speech translation works for you, or how well #Alexa or #Siri gets you, you should spend some time recording your voice for the Common Voice, to increase the probability of upcoming voice recognition model working great for you.
Project: https://voice.mozilla.org
Venturebeat article: https://venturebeat.com/2020/07/01/mozilla-common-voice-updates-will-help-train-the-hey-firefox-wakeword-for-voice-based-web-browsing/
#open #SpeechToText #TextToSpeech #DL #mozilla #audiolearning #voicerecognition
Data Science by ODS.ai 🦜
🎙Mozilla’s Common Voice project Mozilla launched a project to make digitalization of human voice more open and accessable. Anyone is eligible to download the dataset to use it for building #voicerecognition or #voicegeneration ML systems. Most importantly…
Please share this message to your friends, especially to those who speak funny, strange. If you have a friend, whom you can’t understand sometimes when she/he is anxious / excited, you will help them a lot.
And if you ever heard from someone that they can’t get you, you are speaking to fast, slow, or losing sounds, you should definately record some pieces for this project.
And if you ever heard from someone that they can’t get you, you are speaking to fast, slow, or losing sounds, you should definately record some pieces for this project.
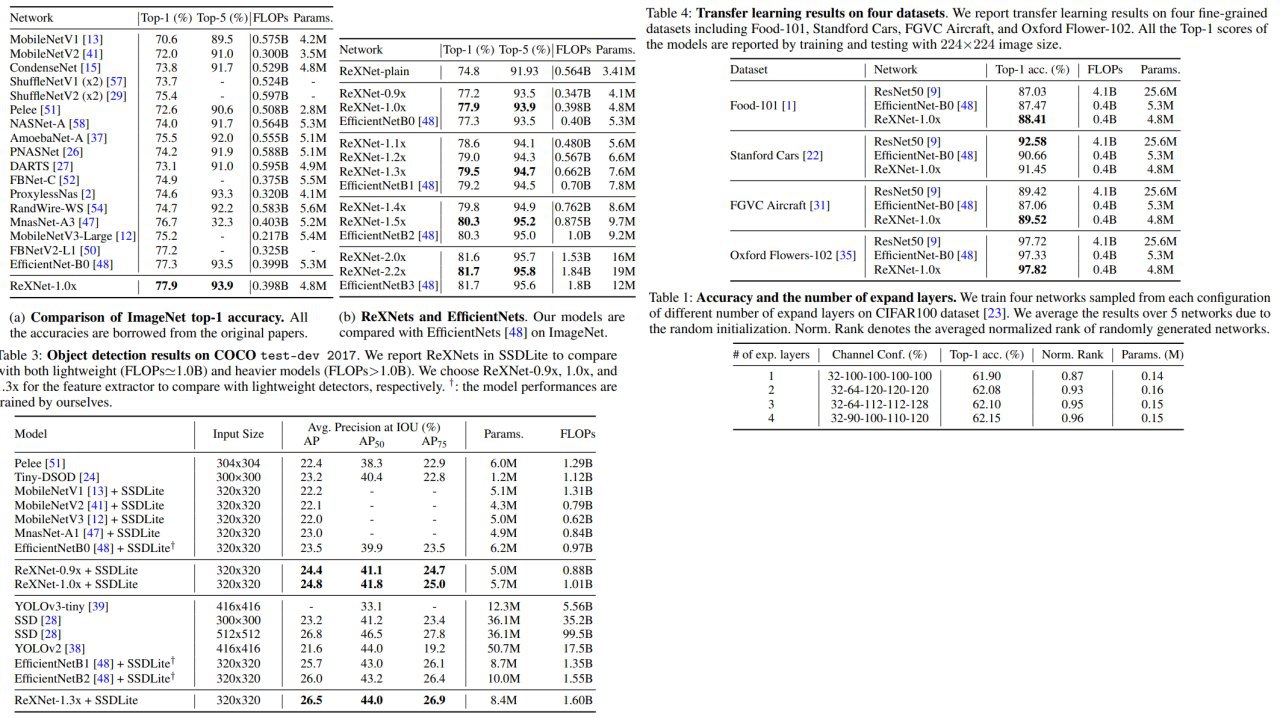
ReXNet: Diminishing Representational Bottleneck on Convolutional Neural Network
The authors propose a set of design principles that improves model performance significantly based on the analysis of representation bottlenecks.
Authors think that commonly used architectures have a representation bottleneck and try to fix it by expanding channel size, using more expand layers, and better activation functions. This also improves the performance of models on ImageNet and good results on transfer learning on classification and object detection.
Authors hope that their design ideas could be used by NAS to create even better models.
Paper: https://arxiv.org/abs/2007.00992
Code: https://github.com/clovaai/rexnet
#deeplearning #pretraining #transferlearning #computervision #pytorch
The authors propose a set of design principles that improves model performance significantly based on the analysis of representation bottlenecks.
Authors think that commonly used architectures have a representation bottleneck and try to fix it by expanding channel size, using more expand layers, and better activation functions. This also improves the performance of models on ImageNet and good results on transfer learning on classification and object detection.
Authors hope that their design ideas could be used by NAS to create even better models.
Paper: https://arxiv.org/abs/2007.00992
Code: https://github.com/clovaai/rexnet
#deeplearning #pretraining #transferlearning #computervision #pytorch
{kind=link}
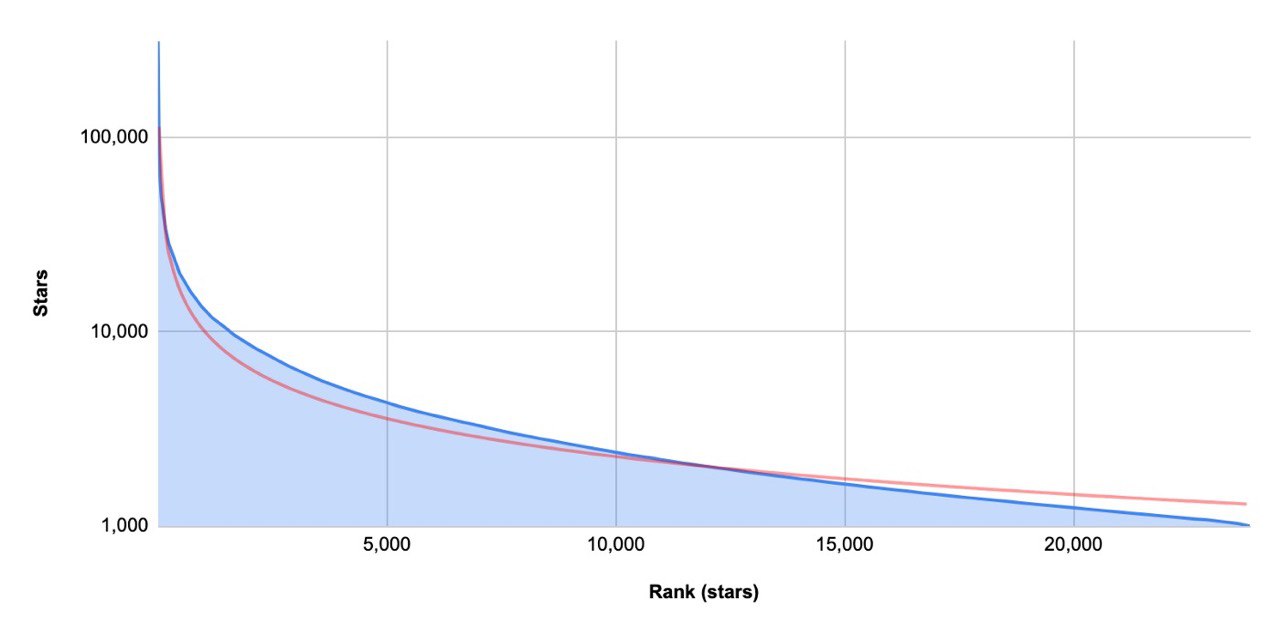
Overview of Open Source projects growth metrics
Quantative analytics of top starred repositories.
Link: https://medium.com/runacapital/open-source-growth-benchmarks-and-the-20-fastest-growing-oss-startups-d3556a669fe6
#opensource #analytics #statistics #growth
Quantative analytics of top starred repositories.
Link: https://medium.com/runacapital/open-source-growth-benchmarks-and-the-20-fastest-growing-oss-startups-d3556a669fe6
#opensource #analytics #statistics #growth
{kind=link}
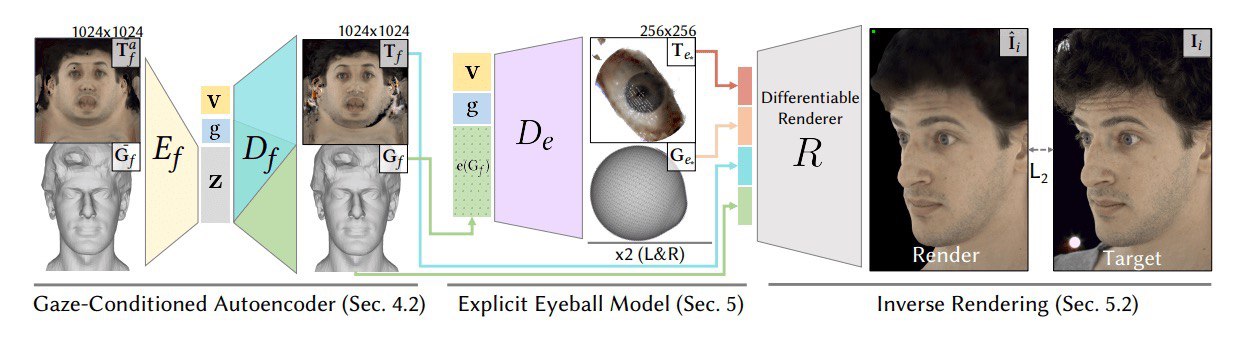
Making Animoji or any other 3D avatar more human-like
#Facebook researchers suggested an approach for more precise facial and gaze expression tracking.
Review: https://syncedreview.com/2020/07/07/facebook-introduces-integrated-eye-face-model-for-3d-immersion-in-remote-communication/
Paper: https://research.fb.com/wp-content/uploads/2020/06/The-Eyes-Have-It-An-Integrated-Eye-and-Face-Model-for-Photorealistic-Facial-Animation.pdf
#eyetracking #cv #dl #3davatar #videolearning #facerecognition
#Facebook researchers suggested an approach for more precise facial and gaze expression tracking.
Review: https://syncedreview.com/2020/07/07/facebook-introduces-integrated-eye-face-model-for-3d-immersion-in-remote-communication/
Paper: https://research.fb.com/wp-content/uploads/2020/06/The-Eyes-Have-It-An-Integrated-Eye-and-Face-Model-for-Photorealistic-Facial-Animation.pdf
#eyetracking #cv #dl #3davatar #videolearning #facerecognition
{kind=link}
Soon we will give a try to certain solution which will allow commenting on the posts in this channel.
Therefore, we will at first release the Ultimate Post on #wheretostart with Data Science, describing various entry points, books and courses. We want to provide extensive and thorough manual (just check out the name we chose), so we would be grateful if you can submit any resourses on getting starting with DS (any sphere) through our bot @opendatasciencebot (make sure you add your username, so we can reach you back)
You are most welcome to share:
Favourite books, youtube playlists, courses or even success stories.
Therefore, we will at first release the Ultimate Post on #wheretostart with Data Science, describing various entry points, books and courses. We want to provide extensive and thorough manual (just check out the name we chose), so we would be grateful if you can submit any resourses on getting starting with DS (any sphere) through our bot @opendatasciencebot (make sure you add your username, so we can reach you back)
You are most welcome to share:
Favourite books, youtube playlists, courses or even success stories.
A new SOTA on voice separation model that distinguishes multiple speakers simultaneously
Pandemic given a sufficient rise to new technologies covering voice communication. Noise cancelling is required more than ever and now #Facebook introduced a new method for separating as many as five voices speaking simultaneously into a single microphone. It pushes state of the art on multiple benchmarks, including ones with challenging noise and reverberations.
Blogpost: https://ai.facebook.com/blog/a-new-state-of-the-art-voice-separation-model-that-distinguishes-multiple-speakers-simultaneously
Paper: https://arxiv.org/pdf/2003.01531.pdf
#SOTA #FacebookAI #voicerecognition #soundlearning #DL
Pandemic given a sufficient rise to new technologies covering voice communication. Noise cancelling is required more than ever and now #Facebook introduced a new method for separating as many as five voices speaking simultaneously into a single microphone. It pushes state of the art on multiple benchmarks, including ones with challenging noise and reverberations.
Blogpost: https://ai.facebook.com/blog/a-new-state-of-the-art-voice-separation-model-that-distinguishes-multiple-speakers-simultaneously
Paper: https://arxiv.org/pdf/2003.01531.pdf
#SOTA #FacebookAI #voicerecognition #soundlearning #DL
Forwarded from Graph Machine Learning
Knowledge Graphs at ACL 2020
Another brilliant post by Michael Galkin on usage of knowledge graphs in NLP at ACL 2020.
"Knowledge graphs demonstrate better capabilities to reveal higher-order interdependencies in otherwise unstructured data."
Content:
1. Question Answering over Structured Data
2. KG Embeddings: Hyperbolic and Hyper-relational
3. Data-to-text NLG: Prepare your Transformer
4. Conversational AI: Improving Goal-Oriented Bots
5. Information Extraction: OpenIE and Link Prediction
Another brilliant post by Michael Galkin on usage of knowledge graphs in NLP at ACL 2020.
"Knowledge graphs demonstrate better capabilities to reveal higher-order interdependencies in otherwise unstructured data."
Content:
1. Question Answering over Structured Data
2. KG Embeddings: Hyperbolic and Hyper-relational
3. Data-to-text NLG: Prepare your Transformer
4. Conversational AI: Improving Goal-Oriented Bots
5. Information Extraction: OpenIE and Link Prediction
Medium
Knowledge Graphs in Natural Language Processing @ ACL 2020
This post commemorates the first anniversary of the series where we examine advancements in NLP and Graph ML powered by knowledge graphs…
Ultimate post on where to start learning DS
Most common request we received through the years was to share insights and advices on how to start career in data science and to recommend decent cources. Apparently, using hashtag #wheretostart wasn't enough so we were sharing some general advices.
So we assembled a through guide on how to start learning machine learning and created another #ultimatepost (in a form of a github repo, so it will be keep updated and anyone can submit worthy piece of advice to it).
We welcome you to share your stories and advices on how to start rolling into data science, as well as to spread the link to the repo to those your friends who might benefit from it.
Link: Ultimate post
#entrylevel #beginner #junior #MOOC #learndatascience #courses #mlcourse #opensource
Most common request we received through the years was to share insights and advices on how to start career in data science and to recommend decent cources. Apparently, using hashtag #wheretostart wasn't enough so we were sharing some general advices.
So we assembled a through guide on how to start learning machine learning and created another #ultimatepost (in a form of a github repo, so it will be keep updated and anyone can submit worthy piece of advice to it).
We welcome you to share your stories and advices on how to start rolling into data science, as well as to spread the link to the repo to those your friends who might benefit from it.
Link: Ultimate post
#entrylevel #beginner #junior #MOOC #learndatascience #courses #mlcourse #opensource
{kind=link}
GPT-3 application for website form generation
Turns out #GPT3 model is capable of generating #JSX code (which is HTML layout for #React ) given the description of the required blocks to generate.
Author reports that there are exceptions, given current output limit of the model of 512 tokens.
Why this is important: one might suppose that in the future programmers will just write specifications and tests for the AI to generate the code. Given the speed of progress that won’t be surprising at all.
And probably the more sophisticated models will be capable of using hard output limit to produce a code for the output generation but that obviously is still an area for active research.
More realistic evaluation is that the upcoming code generation tools is that it will just allow more people to build products, following #nocode movement.
Twitter thread: https://twitter.com/sharifshameem/status/1282676454690451457
#codegeneration #NLU
Turns out #GPT3 model is capable of generating #JSX code (which is HTML layout for #React ) given the description of the required blocks to generate.
Author reports that there are exceptions, given current output limit of the model of 512 tokens.
Why this is important: one might suppose that in the future programmers will just write specifications and tests for the AI to generate the code. Given the speed of progress that won’t be surprising at all.
And probably the more sophisticated models will be capable of using hard output limit to produce a code for the output generation but that obviously is still an area for active research.
More realistic evaluation is that the upcoming code generation tools is that it will just allow more people to build products, following #nocode movement.
Twitter thread: https://twitter.com/sharifshameem/status/1282676454690451457
#codegeneration #NLU