
VirTex: Learning Visual Representations from Textual Annotations
The authors offer an alternative approach to pre-training backbones for CV tasks – using semantically dense captions to learn visual representations.
Recent methods have explored unsupervised pretraining to scale to vast quantities of unlabeled images. In contrast, the authors aim to learn high-quality visual representations from fewer images. They revisit supervised pretraining and seek data-efficient alternatives to classification-based pretraining.
VirTex (CNN + Transformer) is pre-trained on COCO captions. On downstream tasks it can reach performance similar to pre-training on ImageNet, but with 10x less images!
Paper: https://arxiv.org/abs/2006.06666
Code: https://github.com/kdexd/virtex
Site: https://kdexd.github.io/virtex/
#imagecaptioning #cv #visual #annotation #transformer #pretraining #transferlearning #deeplearning #paper
The authors offer an alternative approach to pre-training backbones for CV tasks – using semantically dense captions to learn visual representations.
Recent methods have explored unsupervised pretraining to scale to vast quantities of unlabeled images. In contrast, the authors aim to learn high-quality visual representations from fewer images. They revisit supervised pretraining and seek data-efficient alternatives to classification-based pretraining.
VirTex (CNN + Transformer) is pre-trained on COCO captions. On downstream tasks it can reach performance similar to pre-training on ImageNet, but with 10x less images!
Paper: https://arxiv.org/abs/2006.06666
Code: https://github.com/kdexd/virtex
Site: https://kdexd.github.io/virtex/
#imagecaptioning #cv #visual #annotation #transformer #pretraining #transferlearning #deeplearning #paper
{kind=link}
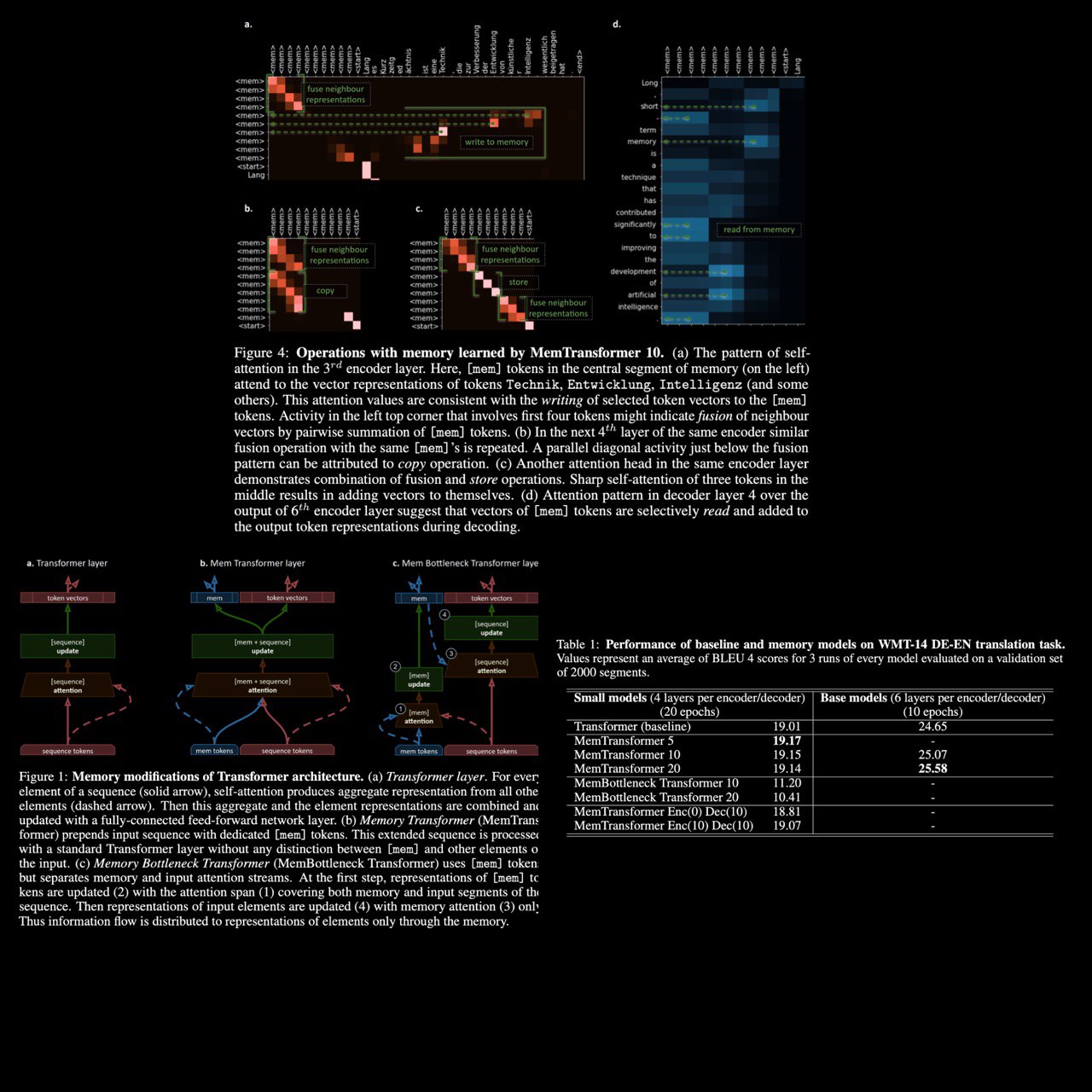
Memory Transformer
Burtsev & Sapunov
The authors proposed and studied two memory augmented architectures MemTransformer and MemBottleneck Transformer. Qualitative analysis of attention patterns produced by the transformer heads trained to solve machine translation task suggests that both models successfully discovered basic operations for memory control. Attention maps show evidence for the presence of memory read/write as well as some in-memory processing operations such as copying and summation.
A comparison of machine translation quality shows that adding general-purpose memory in MemTransformer improves performance over the baseline. Moreover, the speed of training and final quality positively correlates with the memory size. On the other hand, MemBottleneck Transformer, with all self-attention restricted to the memory only, has significantly lower scores after training.
Memory lesion tests demonstrate that the performance of the pre-trained MemTransformer model critically depends on the presence of memory. Still, the memory controller learned by the model degrades only gradually when memory size is changed during inference. This indicates that the controller has some robustness and ability for generalization.
More interesting figures u can check out in the attachment.
paper: https://arxiv.org/abs/2006.11527.pdf
#nlp #transformer #attention #machine #translation
Burtsev & Sapunov
The authors proposed and studied two memory augmented architectures MemTransformer and MemBottleneck Transformer. Qualitative analysis of attention patterns produced by the transformer heads trained to solve machine translation task suggests that both models successfully discovered basic operations for memory control. Attention maps show evidence for the presence of memory read/write as well as some in-memory processing operations such as copying and summation.
A comparison of machine translation quality shows that adding general-purpose memory in MemTransformer improves performance over the baseline. Moreover, the speed of training and final quality positively correlates with the memory size. On the other hand, MemBottleneck Transformer, with all self-attention restricted to the memory only, has significantly lower scores after training.
Memory lesion tests demonstrate that the performance of the pre-trained MemTransformer model critically depends on the presence of memory. Still, the memory controller learned by the model degrades only gradually when memory size is changed during inference. This indicates that the controller has some robustness and ability for generalization.
More interesting figures u can check out in the attachment.
paper: https://arxiv.org/abs/2006.11527.pdf
#nlp #transformer #attention #machine #translation
{kind=link}
MDETR: Modulated Detection for End-to-End Multi-Modal Understanding
Multi-modal reasoning systems rely on a pre-trained object detector to extract regions of interest from the image. However, this crucial module is typically used as a black box, trained independently of the downstream task and on a fixed vocabulary of objects and attributes.
The authors present an end-to-end approach to multi-modal reasoning systems, which works much better than using a separate pre-trained decoder.
They pre-train the network on 1.3M text-image pairs, mined from pre-existing multi-modal datasets having explicit alignment between phrases in text and objects in the image.
Fine-tuning this model achieves new SOTA results on phrase grounding, referring expression comprehension, and segmentation tasks. The approach could be extended to visual question answering.
Furthermore, the model is capable of handling the long tail of object categories.
Paper: https://arxiv.org/abs/2104.12763
Code: https://github.com/ashkamath/mdetr
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-mdetr
#deeplearning #multimodalreasoning #transformer
Multi-modal reasoning systems rely on a pre-trained object detector to extract regions of interest from the image. However, this crucial module is typically used as a black box, trained independently of the downstream task and on a fixed vocabulary of objects and attributes.
The authors present an end-to-end approach to multi-modal reasoning systems, which works much better than using a separate pre-trained decoder.
They pre-train the network on 1.3M text-image pairs, mined from pre-existing multi-modal datasets having explicit alignment between phrases in text and objects in the image.
Fine-tuning this model achieves new SOTA results on phrase grounding, referring expression comprehension, and segmentation tasks. The approach could be extended to visual question answering.
Furthermore, the model is capable of handling the long tail of object categories.
Paper: https://arxiv.org/abs/2104.12763
Code: https://github.com/ashkamath/mdetr
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-mdetr
#deeplearning #multimodalreasoning #transformer
{kind=link}
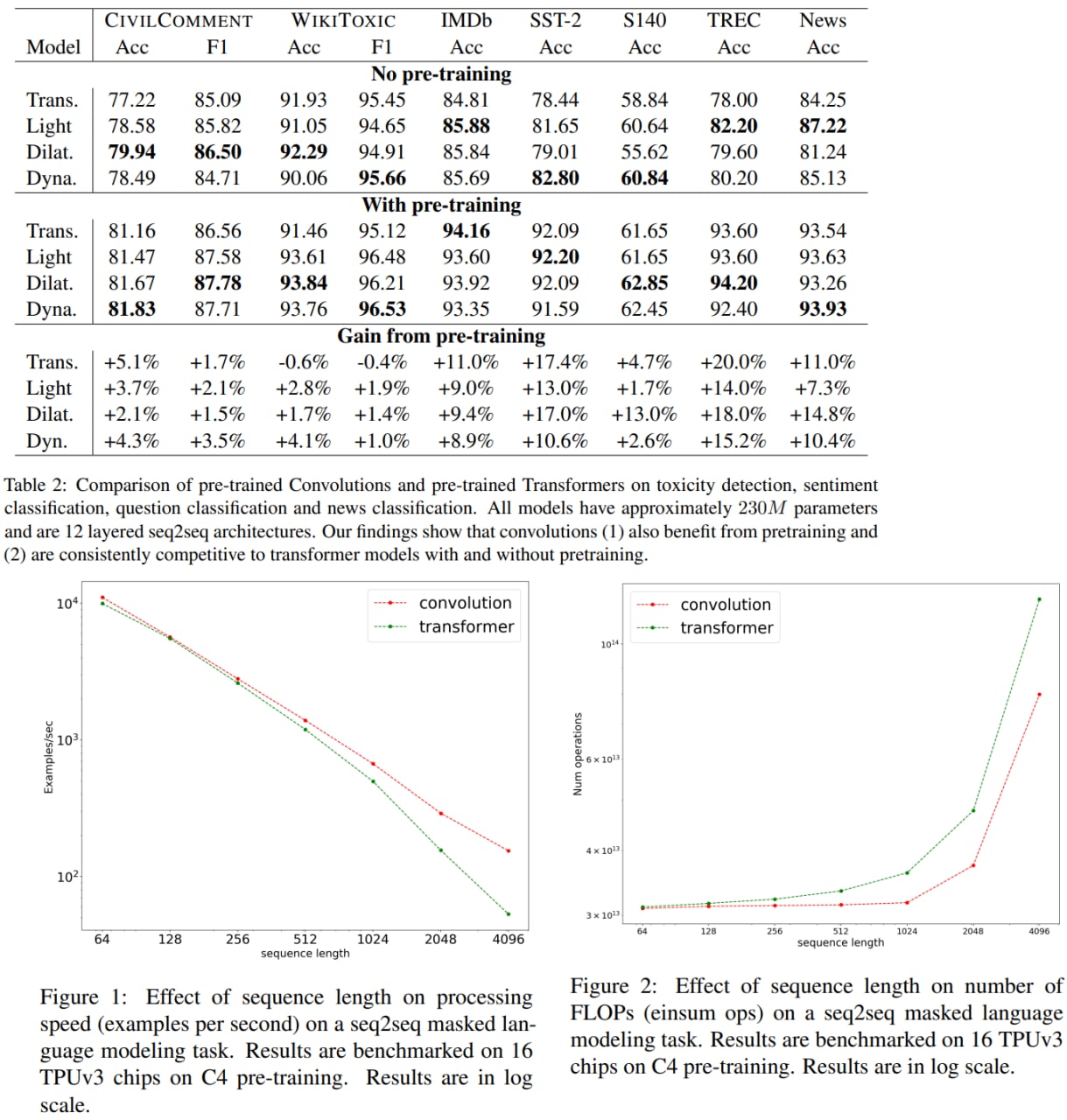
Are Pre-trained Convolutions Better than Pre-trained Transformers?
In this paper, the authors from Google Research wanted to investigate whether CNN architectures can be competitive compared to transformers on NLP problems. It turns out that pre-trained CNN models outperform pre-trained Transformers on some tasks; they also train faster and scale better to longer sequences.
Overall, the findings outlined in this paper suggest that conflating pre-training and architectural advances is misguided and that both advances should be considered independently. The authors believe their research paves the way for a healthy amount of optimism in alternative architectures.
Paper: https://arxiv.org/abs/2105.03322
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-cnnbettertransformers
#nlp #deeplearning #cnn #transformer #pretraining
In this paper, the authors from Google Research wanted to investigate whether CNN architectures can be competitive compared to transformers on NLP problems. It turns out that pre-trained CNN models outperform pre-trained Transformers on some tasks; they also train faster and scale better to longer sequences.
Overall, the findings outlined in this paper suggest that conflating pre-training and architectural advances is misguided and that both advances should be considered independently. The authors believe their research paves the way for a healthy amount of optimism in alternative architectures.
Paper: https://arxiv.org/abs/2105.03322
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-cnnbettertransformers
#nlp #deeplearning #cnn #transformer #pretraining
{kind=link}
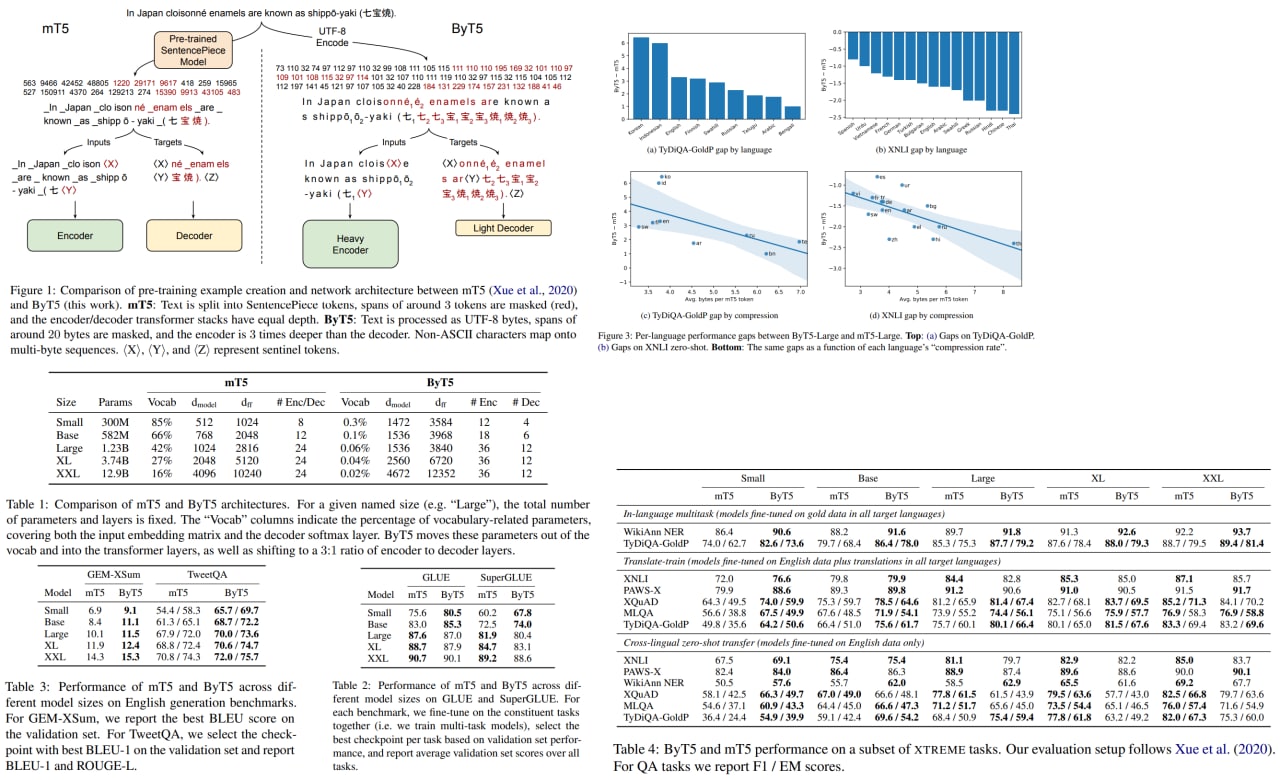
ByT5: Towards a token-free future with pre-trained byte-to-byte models
Pre-trained language models usually operate on the sequences of tokens, which are based on words or subword units.
Token-free models operate directly on the raw text (characters or bytes) instead. They can work with any language, are more robust to the noise, and don’t require preprocessing.
The authors use a modified mT5 architecture and show that their approach is competitive with token-level models.
Paper: https://arxiv.org/abs/2105.13626
Code: https://github.com/google-research/byt5
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-byt5
#nlp #deeplearning #transformer #pretraining
Pre-trained language models usually operate on the sequences of tokens, which are based on words or subword units.
Token-free models operate directly on the raw text (characters or bytes) instead. They can work with any language, are more robust to the noise, and don’t require preprocessing.
The authors use a modified mT5 architecture and show that their approach is competitive with token-level models.
Paper: https://arxiv.org/abs/2105.13626
Code: https://github.com/google-research/byt5
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-byt5
#nlp #deeplearning #transformer #pretraining
{kind=link}
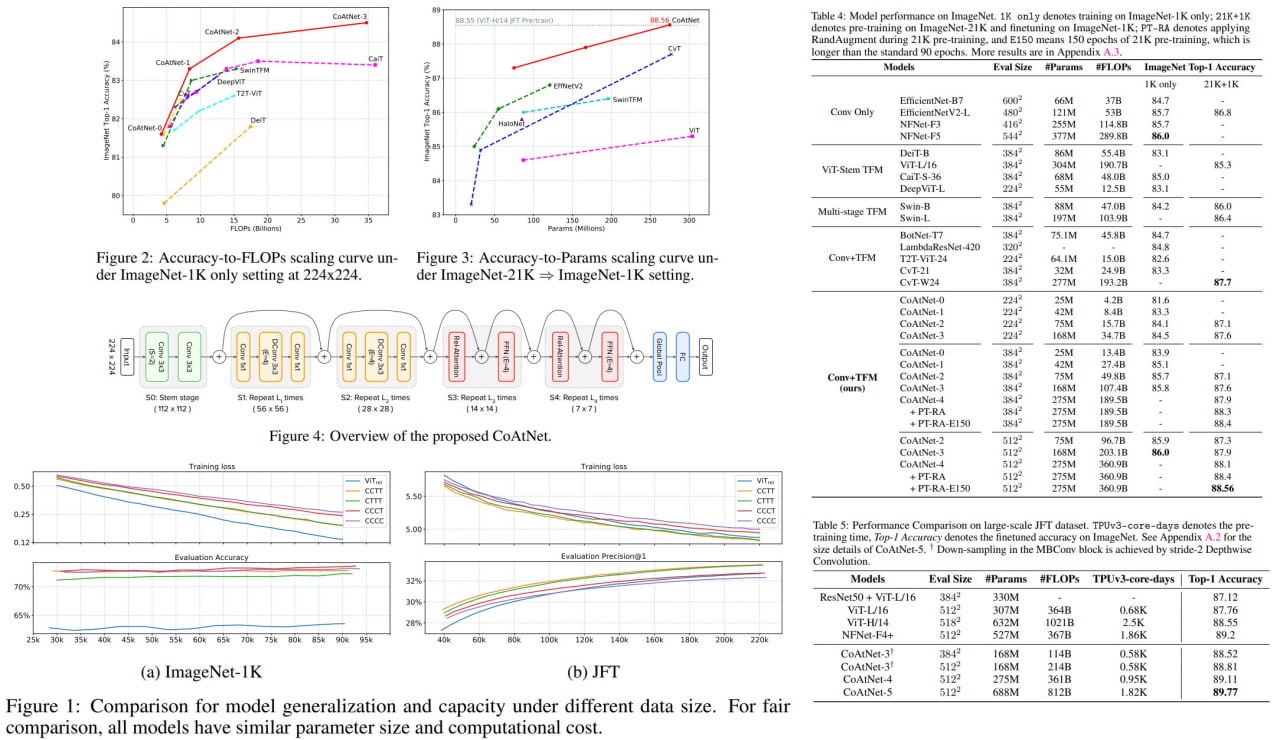
CoAtNet: Marrying Convolution and Attention for All Data Sizes
This is a paper on combining CNN and attention for Computer Vision tasks by Google Research.
The authors unify depthwise convolutions and self-attention via relative attention and vertically stack attention and convolutional layers in a specific way.
Resulting CoAtNets have good generalization, capacity and efficiency.
CoAtNet achieves 86.0% ImageNet top-1 accuracy without extra data and 89.77% with extra JFT data, outperforming the prior state of the art of both convolutional networks and Transformers. Notably, when pre-trained with 13M images from ImageNet-21K, CoAtNet achieves 88.56% top-1 accuracy, matching ViT-huge pre-trained with 300M images from JFT while using 23x less data.
Paper: https://arxiv.org/abs/2106.04803
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-coatnet
#cv #deeplearning #transformer #pretraining
This is a paper on combining CNN and attention for Computer Vision tasks by Google Research.
The authors unify depthwise convolutions and self-attention via relative attention and vertically stack attention and convolutional layers in a specific way.
Resulting CoAtNets have good generalization, capacity and efficiency.
CoAtNet achieves 86.0% ImageNet top-1 accuracy without extra data and 89.77% with extra JFT data, outperforming the prior state of the art of both convolutional networks and Transformers. Notably, when pre-trained with 13M images from ImageNet-21K, CoAtNet achieves 88.56% top-1 accuracy, matching ViT-huge pre-trained with 300M images from JFT while using 23x less data.
Paper: https://arxiv.org/abs/2106.04803
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-coatnet
#cv #deeplearning #transformer #pretraining
{kind=link}
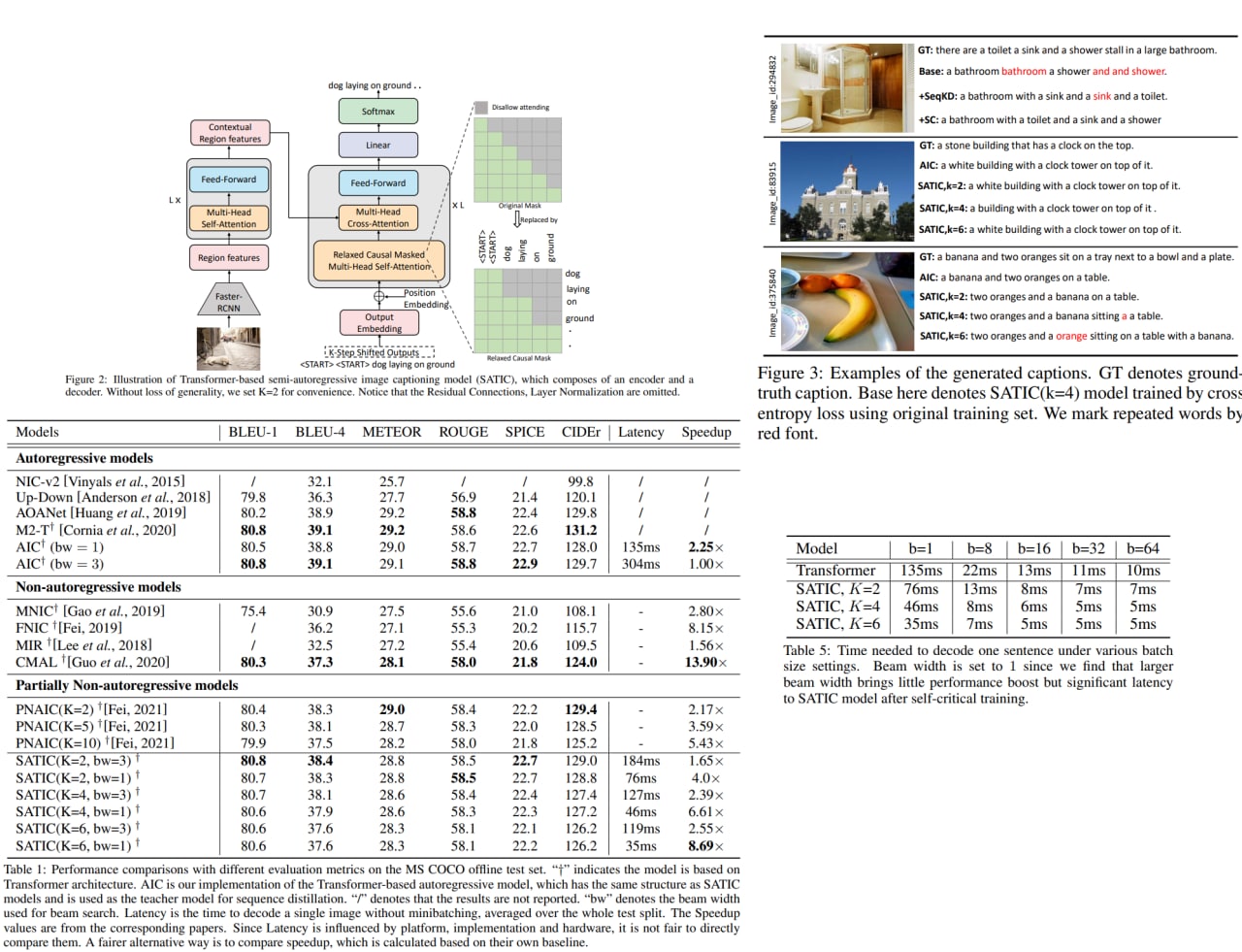
Semi-Autoregressive Transformer for Image Captioning
Current state-of-the-art image captioning models use autoregressive decoders - they generate one word after another, which leads to heavy latency during inference. Non-autoregressive models predict all the words in parallel; however, they suffer from quality degradation as they remove word dependence excessively.
The authors suggest a semi-autoregressive approach to image captioning to improve a trade-off between speed and quality: the model keeps the autoregressive property in global but generates words parallelly in local. Experiments on MSCOCO show that SATIC can achieve a better trade-off without bells and whistles.
Paper: https://arxiv.org/abs/2106.09436
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-satic
#imagecaptioning #deeplearning #transformer
Current state-of-the-art image captioning models use autoregressive decoders - they generate one word after another, which leads to heavy latency during inference. Non-autoregressive models predict all the words in parallel; however, they suffer from quality degradation as they remove word dependence excessively.
The authors suggest a semi-autoregressive approach to image captioning to improve a trade-off between speed and quality: the model keeps the autoregressive property in global but generates words parallelly in local. Experiments on MSCOCO show that SATIC can achieve a better trade-off without bells and whistles.
Paper: https://arxiv.org/abs/2106.09436
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-satic
#imagecaptioning #deeplearning #transformer
{kind=link}
Long-Short Transformer: Efficient Transformers for Language and Vision
This paper offers a new approach to solving the problem of quadratic time and memory complexities of self-attention in Transformers. The authors propose Long-Short Transformer (Transformer-LS), an efficient self-attention mechanism for modeling long sequences with linear complexity for both language and vision tasks. It aggregates a novel long-range attention with dynamic projection to model distant correlations and a short-term attention to capture fine-grained local correlations. A dual normalization is used to deal with the scale mismatch between the two attention mechanisms. Transformer-LS can be applied to both autoregressive and bidirectional models without additional complexity.
This method outperforms the state-of-the-art models on multiple tasks in language and vision domains. For instance, Transformer-LS achieves 0.97 test BPC on enwik8 using half the number of parameters than previous methods, while being faster and is able to handle 3× as long sequences. On ImageNet, it can obtain 84.1% Top-1 accuracy, while being more scalable on high-resolution images.
Paper: https://arxiv.org/abs/2107.02192
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-transformerls
#deeplearning #cv #nlp #transformer #attention
This paper offers a new approach to solving the problem of quadratic time and memory complexities of self-attention in Transformers. The authors propose Long-Short Transformer (Transformer-LS), an efficient self-attention mechanism for modeling long sequences with linear complexity for both language and vision tasks. It aggregates a novel long-range attention with dynamic projection to model distant correlations and a short-term attention to capture fine-grained local correlations. A dual normalization is used to deal with the scale mismatch between the two attention mechanisms. Transformer-LS can be applied to both autoregressive and bidirectional models without additional complexity.
This method outperforms the state-of-the-art models on multiple tasks in language and vision domains. For instance, Transformer-LS achieves 0.97 test BPC on enwik8 using half the number of parameters than previous methods, while being faster and is able to handle 3× as long sequences. On ImageNet, it can obtain 84.1% Top-1 accuracy, while being more scalable on high-resolution images.
Paper: https://arxiv.org/abs/2107.02192
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-transformerls
#deeplearning #cv #nlp #transformer #attention
{kind=link}
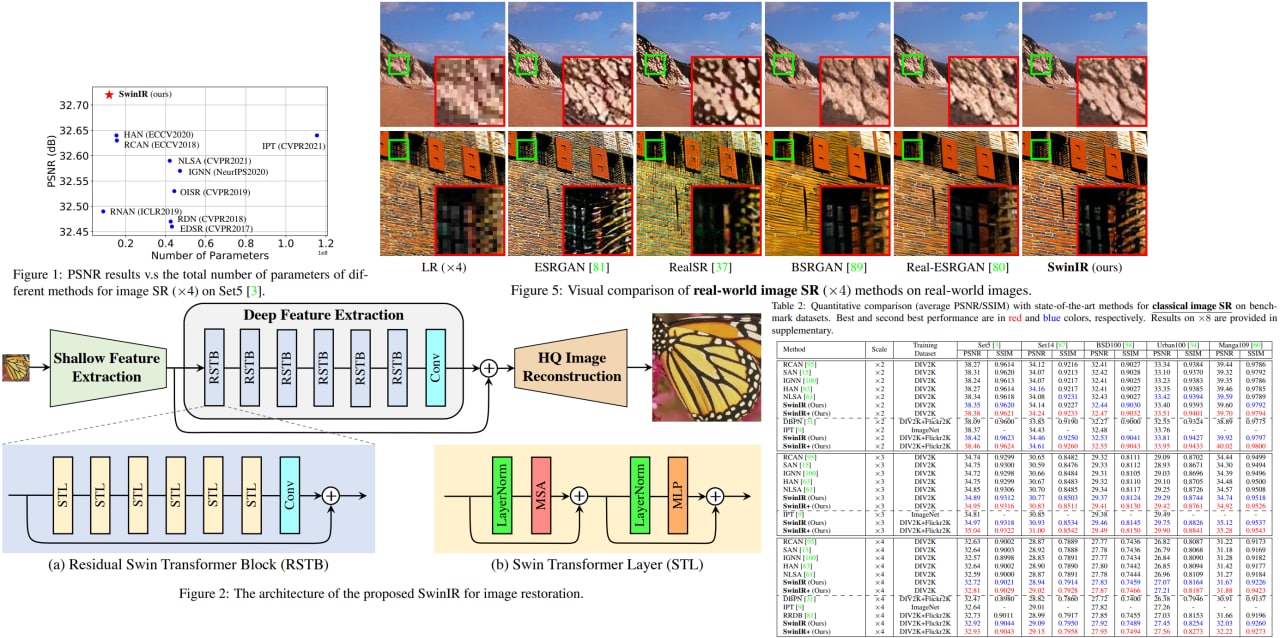
SwinIR: Image Restoration Using Swin Transformer
Image restoration is a long-standing low-level vision problem that aims to restore high-quality images from low-quality images (e.g., downscaled, noisy, and compressed images). While state-of-the-art image restoration methods are based on convolutional neural networks, few attempts have been made with Transformers, which show impressive performance on high-level vision tasks.
The authors use a model SwinIR based on the Swin Transformers. Experimental results demonstrate that SwinIR outperforms state-of-the-art methods on different tasks (image super-resolution, image denoising, and JPEG compression artifact reduction) by up to 0.14~0.45dB, while the total number of parameters can be reduced by up to 67%.
Paper: https://arxiv.org/abs/2108.10257
Code: https://github.com/JingyunLiang/SwinIR
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-swinir
#deeplearning #cv #transformer #superresolution #imagerestoration
Image restoration is a long-standing low-level vision problem that aims to restore high-quality images from low-quality images (e.g., downscaled, noisy, and compressed images). While state-of-the-art image restoration methods are based on convolutional neural networks, few attempts have been made with Transformers, which show impressive performance on high-level vision tasks.
The authors use a model SwinIR based on the Swin Transformers. Experimental results demonstrate that SwinIR outperforms state-of-the-art methods on different tasks (image super-resolution, image denoising, and JPEG compression artifact reduction) by up to 0.14~0.45dB, while the total number of parameters can be reduced by up to 67%.
Paper: https://arxiv.org/abs/2108.10257
Code: https://github.com/JingyunLiang/SwinIR
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-swinir
#deeplearning #cv #transformer #superresolution #imagerestoration
{kind=link}
It's All in the Heads: Using Attention Heads as a Baseline for Cross-Lingual Transfer in Commonsense Reasoning
Researchers from #Yandex have discovered that the reasoning capabilities of cross-lingual Transformers are concentrated in a small set of attention heads. A new multilingual dataset could encourage research on commonsense reasoning in Russian, French, Chinese and other languages.
Link: https://research.yandex.com/news/a-few-attention-heads-for-reasoning-in-multiple-languages
ArXiV: https://arxiv.org/abs/2106.12066
#transformer #nlu #nlp
Researchers from #Yandex have discovered that the reasoning capabilities of cross-lingual Transformers are concentrated in a small set of attention heads. A new multilingual dataset could encourage research on commonsense reasoning in Russian, French, Chinese and other languages.
Link: https://research.yandex.com/news/a-few-attention-heads-for-reasoning-in-multiple-languages
ArXiV: https://arxiv.org/abs/2106.12066
#transformer #nlu #nlp
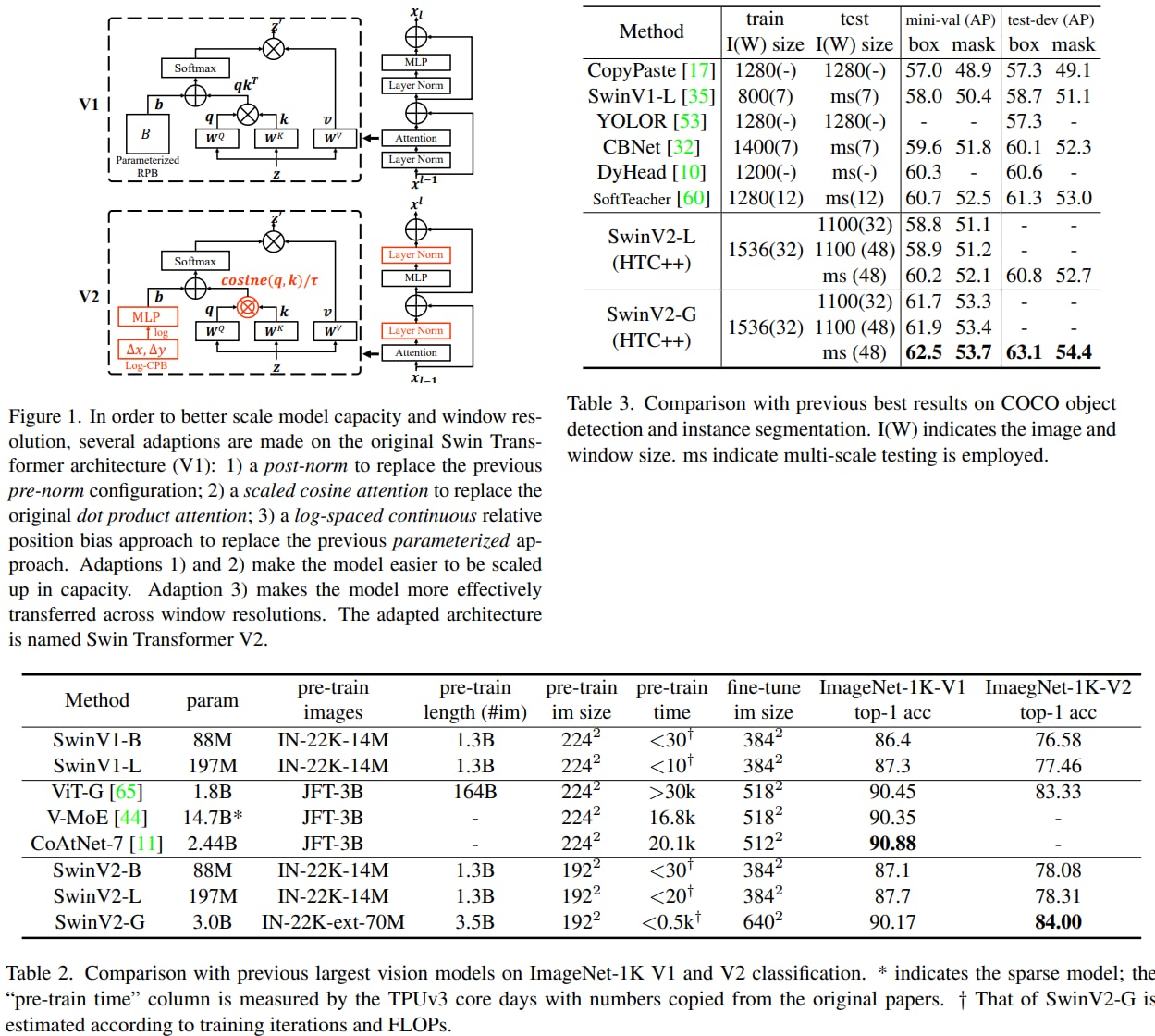
Swin Transformer V2: Scaling Up Capacity and Resolution
The authors present techniques for scaling Swin Transformer up to 3 billion parameters and making it capable of training with images of up to 1,536×1,536 resolution.
Vision models have the following difficulties when trying to scale them up: instability issues at scale, high GPU memory consumption for high-resolution images, and the fact that downstream tasks usually require high-resolution images/windows, while the models are pretrained on lower resolutions and the transfer isn't always efficient.
The authors introduce the following technics to circumvent those problems:
- a post normalization technique and a scaled cosine attention approach to improve the stability of large vision models;
- a log-spaced continuous position bias technique to effectively transfer models pre-trained at low-resolution images and windows to their higher-resolution counterparts;
In addition, they share how they were able to decrease GPU consumption significantly.
Swin Transformer V2 sets new records on four representative vision benchmarks: 84.0% top-1 accuracy on ImageNet-V2 image classification, 63.1 / 54.4 box / mask mAP on COCO object detection, 59.9 mIoU on ADE20K semantic segmentation, and 86.8% top-1 accuracy on Kinetics-400 video action classification.
Paper: https://arxiv.org/abs/2111.09883
Code: https://github.com/microsoft/Swin-Transformer
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-swin-v2
#deeplearning #cv #transformer
The authors present techniques for scaling Swin Transformer up to 3 billion parameters and making it capable of training with images of up to 1,536×1,536 resolution.
Vision models have the following difficulties when trying to scale them up: instability issues at scale, high GPU memory consumption for high-resolution images, and the fact that downstream tasks usually require high-resolution images/windows, while the models are pretrained on lower resolutions and the transfer isn't always efficient.
The authors introduce the following technics to circumvent those problems:
- a post normalization technique and a scaled cosine attention approach to improve the stability of large vision models;
- a log-spaced continuous position bias technique to effectively transfer models pre-trained at low-resolution images and windows to their higher-resolution counterparts;
In addition, they share how they were able to decrease GPU consumption significantly.
Swin Transformer V2 sets new records on four representative vision benchmarks: 84.0% top-1 accuracy on ImageNet-V2 image classification, 63.1 / 54.4 box / mask mAP on COCO object detection, 59.9 mIoU on ADE20K semantic segmentation, and 86.8% top-1 accuracy on Kinetics-400 video action classification.
Paper: https://arxiv.org/abs/2111.09883
Code: https://github.com/microsoft/Swin-Transformer
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-swin-v2
#deeplearning #cv #transformer
{kind=link}
NÜWA: Visual Synthesis Pre-training for Neural visUal World creAtion
In this paper, Microsoft Research Asia and Peking University researchers share a unified multimodal (texts, images, videos, sketches) pre-trained model called NÜWA that can generate new or manipulate existing visual data for various visual synthesis tasks. Furthermore, they have designed a 3D transformer encoder-decoder framework with a 3D Nearby Attention (3DNA) mechanism to consider the nature of the visual data and reduce the computational complexity.
NÜWA achieves state-of-the-art results on text-to-image generation, text-to-video generation, video prediction, and several other tasks and demonstrates good results on zero-shot text-guided image and video manipulation tasks.
Paper: https://arxiv.org/abs/2111.12417
Code: https://github.com/microsoft/NUWA
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-nuwa
#deeplearning #cv #transformer #pretraining
In this paper, Microsoft Research Asia and Peking University researchers share a unified multimodal (texts, images, videos, sketches) pre-trained model called NÜWA that can generate new or manipulate existing visual data for various visual synthesis tasks. Furthermore, they have designed a 3D transformer encoder-decoder framework with a 3D Nearby Attention (3DNA) mechanism to consider the nature of the visual data and reduce the computational complexity.
NÜWA achieves state-of-the-art results on text-to-image generation, text-to-video generation, video prediction, and several other tasks and demonstrates good results on zero-shot text-guided image and video manipulation tasks.
Paper: https://arxiv.org/abs/2111.12417
Code: https://github.com/microsoft/NUWA
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-nuwa
#deeplearning #cv #transformer #pretraining
{kind=link}