
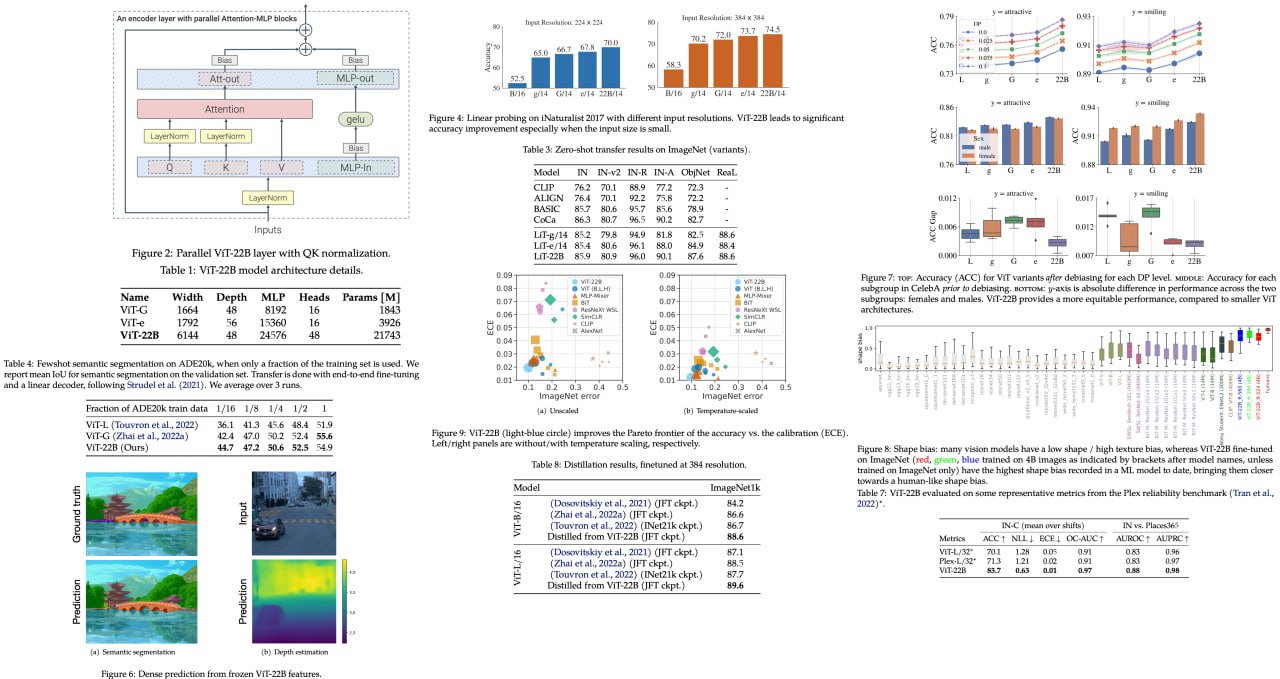
Scaling Vision Transformers to 22 Billion Parameters
Google Research authors present a recipe for training a highly efficient and stable Vision Transformer (ViT-22B) with 22B parameters, the largest dense ViT model to date. Experiments reveal that as the model's scale increases, its performance on downstream tasks improves. Additionally, ViT-22B shows an improved tradeoff between fairness and performance, state-of-the-art alignment with human visual perception in terms of shape/texture bias, and improved robustness. The authors suggest that ViT-22B demonstrates the potential for achieving “LLM-like” scaling in vision models and takes important steps toward that goal.
Paper: https://arxiv.org/abs/2302.05442
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-vit-22
#deeplearning #cv #transformer #sota
Google Research authors present a recipe for training a highly efficient and stable Vision Transformer (ViT-22B) with 22B parameters, the largest dense ViT model to date. Experiments reveal that as the model's scale increases, its performance on downstream tasks improves. Additionally, ViT-22B shows an improved tradeoff between fairness and performance, state-of-the-art alignment with human visual perception in terms of shape/texture bias, and improved robustness. The authors suggest that ViT-22B demonstrates the potential for achieving “LLM-like” scaling in vision models and takes important steps toward that goal.
Paper: https://arxiv.org/abs/2302.05442
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-vit-22
#deeplearning #cv #transformer #sota
{kind=link}
Hyena Hierarchy: Towards Larger Convolutional Language Models
Attention has been a cornerstone of deep learning, but it comes at a steep cost: quadratic expense in sequence length. This can limit the amount of context accessible, making it challenging for subquadratic methods like low-rank and sparse approximations to achieve comparable performance. That's where Hyena comes in!
Hyena is a revolutionary subquadratic drop-in replacement for attention that combines implicitly parametrized long convolutions and data-controlled gating. And the results speak for themselves! Hyena significantly improves accuracy in recall and reasoning tasks on long sequences, matching attention-based models.
In fact, Hyena sets a new state-of-the-art for dense-attention-free architectures in language modeling, reaching Transformer quality with 20% less training compute at sequence length 2K. And that's not all! Hyena operators are twice as fast as optimized attention at sequence length 8K and 100x faster at sequence length 64K.
Paper: https://arxiv.org/abs/2302.10866
Code link: https://github.com/HazyResearch/safari
Project link: https://hazyresearch.stanford.edu/blog/2023-03-07-hyena
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-hyena
#deeplearning #nlp #cv #languagemodel #convolution
Attention has been a cornerstone of deep learning, but it comes at a steep cost: quadratic expense in sequence length. This can limit the amount of context accessible, making it challenging for subquadratic methods like low-rank and sparse approximations to achieve comparable performance. That's where Hyena comes in!
Hyena is a revolutionary subquadratic drop-in replacement for attention that combines implicitly parametrized long convolutions and data-controlled gating. And the results speak for themselves! Hyena significantly improves accuracy in recall and reasoning tasks on long sequences, matching attention-based models.
In fact, Hyena sets a new state-of-the-art for dense-attention-free architectures in language modeling, reaching Transformer quality with 20% less training compute at sequence length 2K. And that's not all! Hyena operators are twice as fast as optimized attention at sequence length 8K and 100x faster at sequence length 64K.
Paper: https://arxiv.org/abs/2302.10866
Code link: https://github.com/HazyResearch/safari
Project link: https://hazyresearch.stanford.edu/blog/2023-03-07-hyena
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-hyena
#deeplearning #nlp #cv #languagemodel #convolution
{kind=link}
ReBotNet: Fast Real-time Video Enhancement
The authors introduce a novel Recurrent Bottleneck Mixer Network (ReBotNet) method, designed for real-time video enhancement in practical scenarios, such as live video calls and video streams. ReBotNet employs a dual-branch framework, where one branch focuses on learning spatio-temporal features, and the other aims to enhance temporal consistency. A common decoder combines the features from both branches to generate the improved frame. This method incorporates a recurrent training approach that utilizes predictions from previous frames for more efficient enhancement and superior temporal consistency.
To assess ReBotNet, the authors use two new datasets that simulate real-world situations and show that their technique surpasses existing methods in terms of reduced computations, decreased memory requirements, and quicker inference times.
Paper: https://arxiv.org/abs/2303.13504
Project link: https://jeya-maria-jose.github.io/rebotnet-web/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-rebotnet
#deeplearning #cv #MachineLearning #VideoEnhancement #AI #Innovation #RealTimeVideo
The authors introduce a novel Recurrent Bottleneck Mixer Network (ReBotNet) method, designed for real-time video enhancement in practical scenarios, such as live video calls and video streams. ReBotNet employs a dual-branch framework, where one branch focuses on learning spatio-temporal features, and the other aims to enhance temporal consistency. A common decoder combines the features from both branches to generate the improved frame. This method incorporates a recurrent training approach that utilizes predictions from previous frames for more efficient enhancement and superior temporal consistency.
To assess ReBotNet, the authors use two new datasets that simulate real-world situations and show that their technique surpasses existing methods in terms of reduced computations, decreased memory requirements, and quicker inference times.
Paper: https://arxiv.org/abs/2303.13504
Project link: https://jeya-maria-jose.github.io/rebotnet-web/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-rebotnet
#deeplearning #cv #MachineLearning #VideoEnhancement #AI #Innovation #RealTimeVideo
{kind=link}
Segment Anything
The Segment Anything project aims to democratize image segmentation in computer vision, a core task used across various applications such as scientific imagery analysis and photo editing. Traditionally, accurate segmentation models require specialized expertise, AI training infrastructure, and large amounts of annotated data. This project introduces a new task, dataset, and model for image segmentation to overcome these challenges and make segmentation more accessible.
The researchers are releasing the Segment Anything Model (SAM) and the Segment Anything 1-Billion mask dataset (SA-1B), the largest segmentation dataset to date. These resources will enable a wide range of applications and further research into foundational models for computer vision. The SA-1B dataset is available for research purposes, while the SAM is provided under the permissive Apache 2.0 open license. Users can explore the demo to try SAM with their own images.
Paper link: https://arxiv.org/abs/2304.02643
Code link: https://github.com/facebookresearch/segment-anything
Demo link: https://segment-anything.com/demo
Blogpost link: https://ai.facebook.com/blog/segment-anything-foundation-model-image-segmentation/
Dataset link: https://ai.facebook.com/datasets/segment-anything/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-sam
#deeplearning #cv #pytorch #imagesegmentation #dataset
The Segment Anything project aims to democratize image segmentation in computer vision, a core task used across various applications such as scientific imagery analysis and photo editing. Traditionally, accurate segmentation models require specialized expertise, AI training infrastructure, and large amounts of annotated data. This project introduces a new task, dataset, and model for image segmentation to overcome these challenges and make segmentation more accessible.
The researchers are releasing the Segment Anything Model (SAM) and the Segment Anything 1-Billion mask dataset (SA-1B), the largest segmentation dataset to date. These resources will enable a wide range of applications and further research into foundational models for computer vision. The SA-1B dataset is available for research purposes, while the SAM is provided under the permissive Apache 2.0 open license. Users can explore the demo to try SAM with their own images.
Paper link: https://arxiv.org/abs/2304.02643
Code link: https://github.com/facebookresearch/segment-anything
Demo link: https://segment-anything.com/demo
Blogpost link: https://ai.facebook.com/blog/segment-anything-foundation-model-image-segmentation/
Dataset link: https://ai.facebook.com/datasets/segment-anything/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-sam
#deeplearning #cv #pytorch #imagesegmentation #dataset
{kind=link}
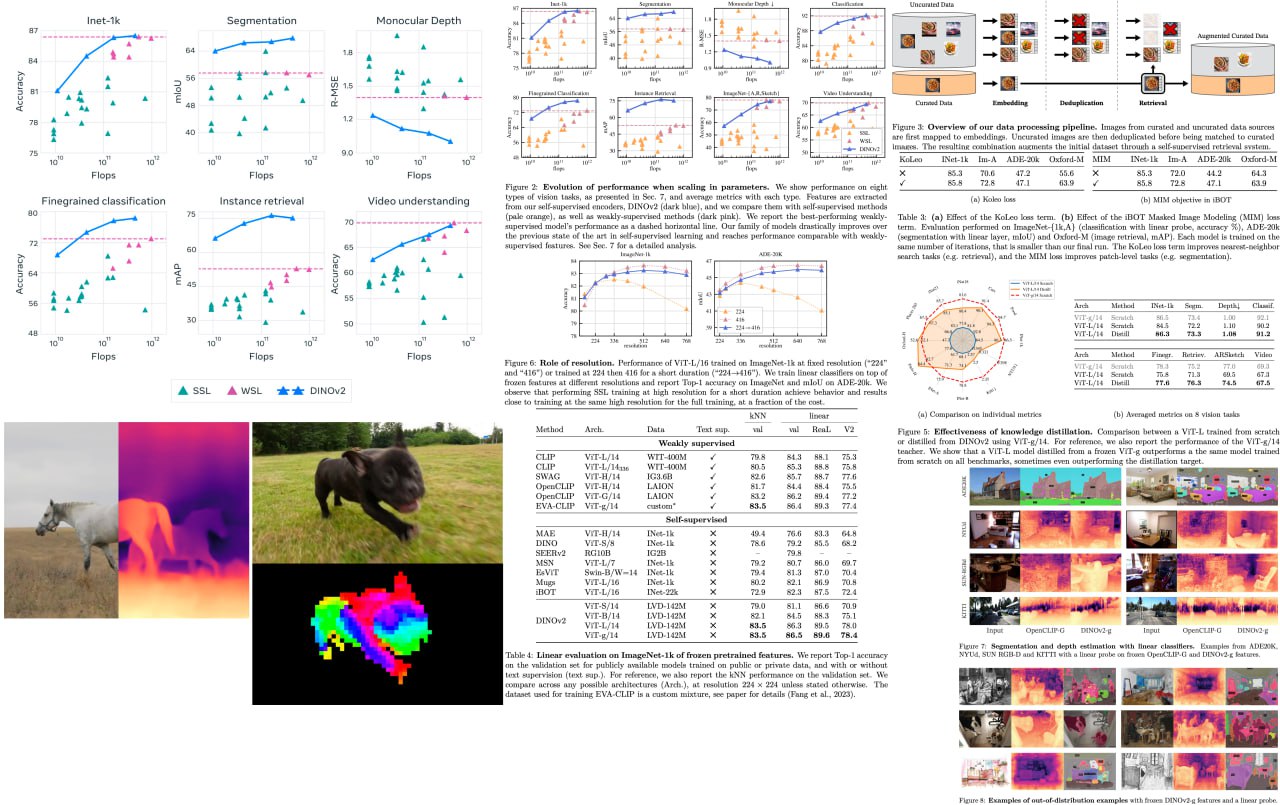
DINOv2: Learning Robust Visual Features without Supervision
Get ready for a game-changer in computer vision! Building on the groundbreaking achievements in natural language processing, foundation models are revolutionizing the way we use images in various systems. By generating all-purpose visual features that excel across diverse image distributions and tasks without finetuning, these models are set to redefine the field.
The researchers behind this work have combined cutting-edge techniques to scale pretraining in terms of data and model size, turbocharging the training process like never before. They've devised an ingenious automatic pipeline to create a rich, diverse, and curated image dataset, setting a new standard in the self-supervised literature. To top it off, they've trained a colossal ViT model with a staggering 1 billion parameters and distilled it into a series of smaller, ultra-efficient models. These models outshine the best available all-purpose features, OpenCLIP, on most benchmarks at both image and pixel levels.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dinov2
Project link: https://dinov2.metademolab.com/
#deeplearning #cv #pytorch #imagesegmentation #sota #pretraining
Get ready for a game-changer in computer vision! Building on the groundbreaking achievements in natural language processing, foundation models are revolutionizing the way we use images in various systems. By generating all-purpose visual features that excel across diverse image distributions and tasks without finetuning, these models are set to redefine the field.
The researchers behind this work have combined cutting-edge techniques to scale pretraining in terms of data and model size, turbocharging the training process like never before. They've devised an ingenious automatic pipeline to create a rich, diverse, and curated image dataset, setting a new standard in the self-supervised literature. To top it off, they've trained a colossal ViT model with a staggering 1 billion parameters and distilled it into a series of smaller, ultra-efficient models. These models outshine the best available all-purpose features, OpenCLIP, on most benchmarks at both image and pixel levels.
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-dinov2
Project link: https://dinov2.metademolab.com/
#deeplearning #cv #pytorch #imagesegmentation #sota #pretraining
{kind=link}
ImageBind: One Embedding Space To Bind Them All
Introducing ImageBind, a groundbreaking approach that learns a joint embedding across six different modalities – images, text, audio, depth, thermal, and IMU data – using only image-paired data. This innovative method leverages recent large-scale vision-language models, extending their zero-shot capabilities to new modalities through their natural pairing with images. ImageBind unlocks a myriad of novel emergent applications 'out-of-the-box,' including cross-modal retrieval, composing modalities with arithmetic, cross-modal detection, and generation.
ImageBind's emergent capabilities improve as the strength of the image encoder increases, setting a new state-of-the-art benchmark in emergent zero-shot recognition tasks across modalities, even outperforming specialist supervised models. Furthermore, ImageBind demonstrates impressive few-shot recognition results, surpassing prior work in the field. This pioneering technique offers a fresh way to evaluate vision models for both visual and non-visual tasks, opening the door to exciting advancements in AI and machine learning.
Blogpost link: https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
Code link: https://github.com/facebookresearch/ImageBind
Paper link: https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf
Demo link: https://imagebind.metademolab.com/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-imagebind
#deeplearning #nlp #multimodal #cv #embedding
Introducing ImageBind, a groundbreaking approach that learns a joint embedding across six different modalities – images, text, audio, depth, thermal, and IMU data – using only image-paired data. This innovative method leverages recent large-scale vision-language models, extending their zero-shot capabilities to new modalities through their natural pairing with images. ImageBind unlocks a myriad of novel emergent applications 'out-of-the-box,' including cross-modal retrieval, composing modalities with arithmetic, cross-modal detection, and generation.
ImageBind's emergent capabilities improve as the strength of the image encoder increases, setting a new state-of-the-art benchmark in emergent zero-shot recognition tasks across modalities, even outperforming specialist supervised models. Furthermore, ImageBind demonstrates impressive few-shot recognition results, surpassing prior work in the field. This pioneering technique offers a fresh way to evaluate vision models for both visual and non-visual tasks, opening the door to exciting advancements in AI and machine learning.
Blogpost link: https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
Code link: https://github.com/facebookresearch/ImageBind
Paper link: https://dl.fbaipublicfiles.com/imagebind/imagebind_final.pdf
Demo link: https://imagebind.metademolab.com/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-imagebind
#deeplearning #nlp #multimodal #cv #embedding
{kind=link}
Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold
Meet DragGAN, a groundbreaking approach that is set to revolutionize the way we control generative adversarial networks (GANs) and synthesize visual content! This innovative tool offers users unprecedented flexibility and precision when manipulating images, sidestepping the limitations of prior 3D models and annotated training data. With DragGAN, you can now "drag" any point of an image to a precise target position, introducing a nvel user-interactive element.
Two ingenious components underpin DragGAN's functionality: the first is a feature-based motion supervision that effortlessly guides the handle point towards the desired position, and the second is a novel point tracking approach that utilizes the discriminating features of the generator to maintain the handle points' positions. The real game-changer is that anyone can now deform an image with absolute control over pixel movements, enabling the manipulation of pose, shape, expression, and layout across diverse categories like animals, cars, humans, landscapes, and more. DragGAN outperforms its predecessors in both image manipulation and point tracking tasks, promising an exciting leap forward in AI-generated visual content!
Paper link: https://arxiv.org/abs/2305.10973
Code link: https://github.com/XingangPan/DragGAN
Project link: https://vcai.mpi-inf.mpg.de/projects/DragGAN/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-draggan
#deeplearning #cv #gan #imagemanipulation
Meet DragGAN, a groundbreaking approach that is set to revolutionize the way we control generative adversarial networks (GANs) and synthesize visual content! This innovative tool offers users unprecedented flexibility and precision when manipulating images, sidestepping the limitations of prior 3D models and annotated training data. With DragGAN, you can now "drag" any point of an image to a precise target position, introducing a nvel user-interactive element.
Two ingenious components underpin DragGAN's functionality: the first is a feature-based motion supervision that effortlessly guides the handle point towards the desired position, and the second is a novel point tracking approach that utilizes the discriminating features of the generator to maintain the handle points' positions. The real game-changer is that anyone can now deform an image with absolute control over pixel movements, enabling the manipulation of pose, shape, expression, and layout across diverse categories like animals, cars, humans, landscapes, and more. DragGAN outperforms its predecessors in both image manipulation and point tracking tasks, promising an exciting leap forward in AI-generated visual content!
Paper link: https://arxiv.org/abs/2305.10973
Code link: https://github.com/XingangPan/DragGAN
Project link: https://vcai.mpi-inf.mpg.de/projects/DragGAN/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-draggan
#deeplearning #cv #gan #imagemanipulation
{kind=link}
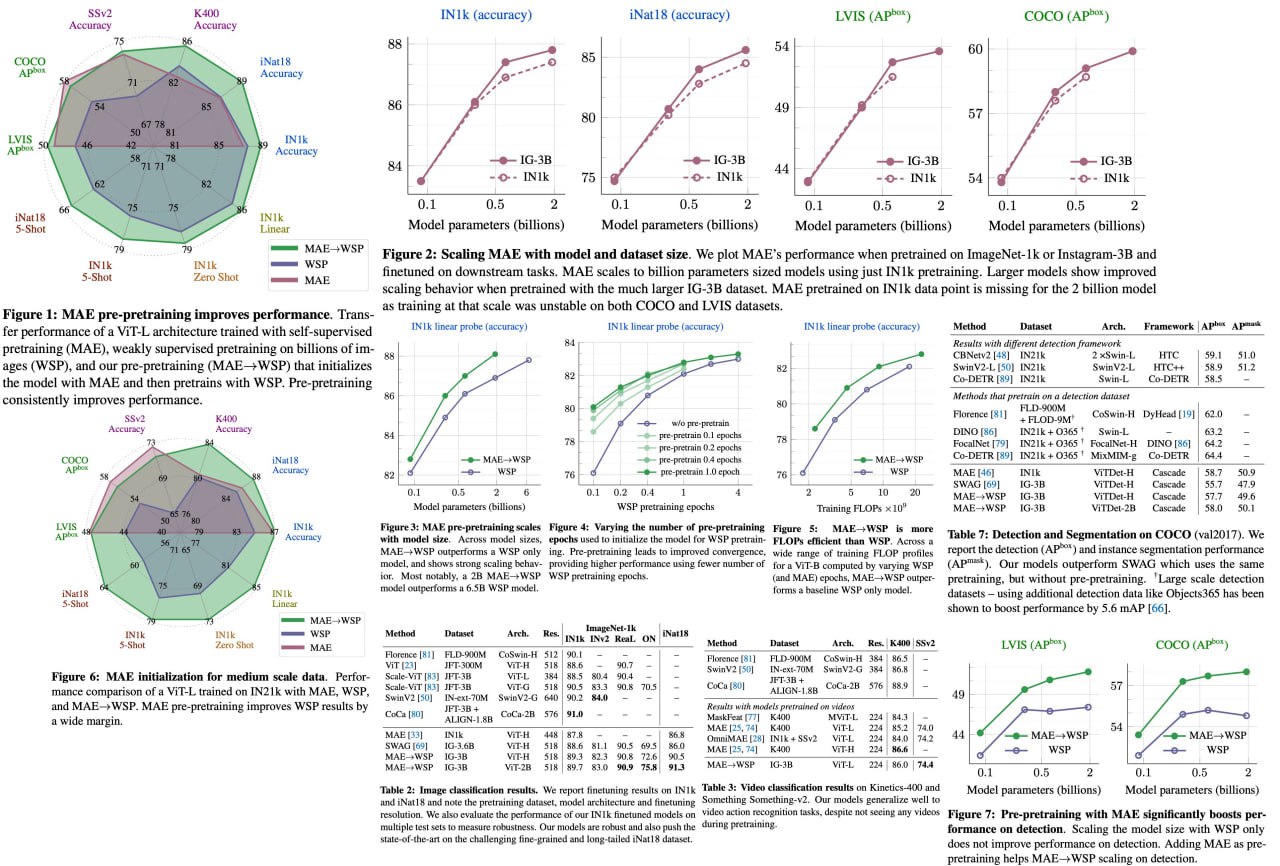
The effectiveness of MAE pre-pretraining for billion-scale pretraining
Revolutionizing the current pretrain-then-finetune paradigm of computer vision, this research has introduced an innovative pre-pretraining stage. Utilizing the Masked Autoencoder (MAE) technique for model initialization, this pre-pretraining strategy scales with the size of both the model and the data. This makes it an ideal tool for training next-generation foundation models, even on the grandest scales.
The robustness of our pre-pretraining technique is demonstrated by consistent improvement in model convergence and downstream transfer performance across diverse model scales and dataset sizes. The authors measured the effectiveness of pre-pretraining on a wide array of visual recognition tasks, and the results have been promising. The ielargest model achieved unprecedented results on iNaturalist-18 (91.3%), 1-shot ImageNet-1k (62.1%), and zero-shot transfer on Food-101 (96.0%), underlining the tremendous potential of proper model initialization, even when handling web-scale pretraining with billions of images.
Paper link: https://arxiv.org/abs/2303.13496
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-mae-pretrain
#deeplearning #cv #pretraining #selfsupervisedlearning
Revolutionizing the current pretrain-then-finetune paradigm of computer vision, this research has introduced an innovative pre-pretraining stage. Utilizing the Masked Autoencoder (MAE) technique for model initialization, this pre-pretraining strategy scales with the size of both the model and the data. This makes it an ideal tool for training next-generation foundation models, even on the grandest scales.
The robustness of our pre-pretraining technique is demonstrated by consistent improvement in model convergence and downstream transfer performance across diverse model scales and dataset sizes. The authors measured the effectiveness of pre-pretraining on a wide array of visual recognition tasks, and the results have been promising. The ielargest model achieved unprecedented results on iNaturalist-18 (91.3%), 1-shot ImageNet-1k (62.1%), and zero-shot transfer on Food-101 (96.0%), underlining the tremendous potential of proper model initialization, even when handling web-scale pretraining with billions of images.
Paper link: https://arxiv.org/abs/2303.13496
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-mae-pretrain
#deeplearning #cv #pretraining #selfsupervisedlearning
{kind=link}
StableRep: Synthetic Images from Text-to-Image Models Make Strong Visual Representation Learners
In a ground-breaking exploration of visual representation learning, researchers have leveraged synthetic images produced by leading text-to-image models, specifically Stable Diffusion, achieving promising results. The study uncovers two key insights - firstly, when configured correctly, self-supervised methods trained on synthetic images can match or even outperform those trained on real images. This suggests an exciting avenue for efficient and effective representation learning, reducing the need for extensive real image datasets.
Secondly, the researchers have devised a novel approach called StableRep, a multi-positive contrastive learning method that treats multiple images, generated from the same text prompt, as mutual positives. The compelling finding is that StableRep, trained solely with synthetic images, outperforms representations learned by prominent methods such as SimCLR and CLIP, even when these used real images. In a striking demonstration, when language supervision is added, StableRep trained with 20M synthetic images outperforms CLIP trained with a whopping 50M real images. These findings not only underscore the potential of synthetic data but also pave the way for more efficient, large-scale visual representation learning.
Paper link: https://arxiv.org/abs/2306.00984
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-stablerep
#deeplearning #cv #nlp #stablediffusion #texttoimage #syntheticdata
In a ground-breaking exploration of visual representation learning, researchers have leveraged synthetic images produced by leading text-to-image models, specifically Stable Diffusion, achieving promising results. The study uncovers two key insights - firstly, when configured correctly, self-supervised methods trained on synthetic images can match or even outperform those trained on real images. This suggests an exciting avenue for efficient and effective representation learning, reducing the need for extensive real image datasets.
Secondly, the researchers have devised a novel approach called StableRep, a multi-positive contrastive learning method that treats multiple images, generated from the same text prompt, as mutual positives. The compelling finding is that StableRep, trained solely with synthetic images, outperforms representations learned by prominent methods such as SimCLR and CLIP, even when these used real images. In a striking demonstration, when language supervision is added, StableRep trained with 20M synthetic images outperforms CLIP trained with a whopping 50M real images. These findings not only underscore the potential of synthetic data but also pave the way for more efficient, large-scale visual representation learning.
Paper link: https://arxiv.org/abs/2306.00984
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-stablerep
#deeplearning #cv #nlp #stablediffusion #texttoimage #syntheticdata
{kind=link}
Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
In a recent breakthrough, a novel approach for learning highly semantic image representations has been introduced that eschews the need for hand-crafted data augmentations. The strategy, known as Image-based Joint-Embedding Predictive Architecture (I-JEPA), offers a refreshing, non-generative pathway to self-supervised learning from images. The concept underpinning I-JEPA is deceptively simple, yet incredibly powerful: it takes a single context block from an image and predicts the representations of various target blocks within the same image.
I-JEPA's core design principle - its masking strategy - plays a pivotal role in shaping the system's semantic prowess. The key is to sample target blocks at a sufficiently large, semantic scale while using a context block that provides ample, spatially distributed information. When integrated with Vision Transformers, I-JEPA exhibits impressive scalability. To illustrate, a ViT-Huge/14 model was trained on ImageNet using just 16 A100 GPUs in under 72 hours, delivering robust performance across a wide spectrum of tasks, including linear classification, object counting, and depth prediction.
Paper link: https://arxiv.org/abs/2301.08243
Code link: https://github.com/facebookresearch/ijepa
Blogpost link: https://ai.facebook.com/blog/yann-lecun-ai-model-i-jepa/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-ijepa
#deeplearning #cv #selfsupervisedlearning
In a recent breakthrough, a novel approach for learning highly semantic image representations has been introduced that eschews the need for hand-crafted data augmentations. The strategy, known as Image-based Joint-Embedding Predictive Architecture (I-JEPA), offers a refreshing, non-generative pathway to self-supervised learning from images. The concept underpinning I-JEPA is deceptively simple, yet incredibly powerful: it takes a single context block from an image and predicts the representations of various target blocks within the same image.
I-JEPA's core design principle - its masking strategy - plays a pivotal role in shaping the system's semantic prowess. The key is to sample target blocks at a sufficiently large, semantic scale while using a context block that provides ample, spatially distributed information. When integrated with Vision Transformers, I-JEPA exhibits impressive scalability. To illustrate, a ViT-Huge/14 model was trained on ImageNet using just 16 A100 GPUs in under 72 hours, delivering robust performance across a wide spectrum of tasks, including linear classification, object counting, and depth prediction.
Paper link: https://arxiv.org/abs/2301.08243
Code link: https://github.com/facebookresearch/ijepa
Blogpost link: https://ai.facebook.com/blog/yann-lecun-ai-model-i-jepa/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-ijepa
#deeplearning #cv #selfsupervisedlearning
{kind=link}