
Data Version Control
open-source version control system for ML projects
DVC is a new type of experiment management software that has been built on top of the existing engineering toolset particularly on a source code version control system (currently Git). DVC reduces the gap between existing tools and data science needs, allowing users to take advantage of experiment management software while reusing existing skills and intuition.
Key features:
[0] simple command line Git-like experience. It does not require installing and maintaining any databases. It does not depend on any proprietary online services
[1] management and versioning of datasets and ML models. Data is saved in S3, Google Cloud, Azure, Alibaba cloud, SSH server, HDFS, or even local HDD RAID
[2] makes projects reproducible and shareable; helping to answer questions about how a model was built
[3] helps manage experiments with Git tags/branches and metrics tracking
The main commands :feelsgoodmeme:
webpage: https://dvc.org
docs: https://dvc.org/doc
github: https://github.com/iterative/dvc
:ods: channel: #tool_dvc
#dvc #version #control #ml #projects #system #git
open-source version control system for ML projects
DVC is a new type of experiment management software that has been built on top of the existing engineering toolset particularly on a source code version control system (currently Git). DVC reduces the gap between existing tools and data science needs, allowing users to take advantage of experiment management software while reusing existing skills and intuition.
Key features:
[0] simple command line Git-like experience. It does not require installing and maintaining any databases. It does not depend on any proprietary online services
[1] management and versioning of datasets and ML models. Data is saved in S3, Google Cloud, Azure, Alibaba cloud, SSH server, HDFS, or even local HDD RAID
[2] makes projects reproducible and shareable; helping to answer questions about how a model was built
[3] helps manage experiments with Git tags/branches and metrics tracking
The main commands :feelsgoodmeme:
$ dvc add <name_file>$ dvc run <name_file>$ dvc [push/pull]webpage: https://dvc.org
docs: https://dvc.org/doc
github: https://github.com/iterative/dvc
:ods: channel: #tool_dvc
#dvc #version #control #ml #projects #system #git
{kind=link}
Abstraction and Reasoning Challenge winners
There is a very interesting challenge by #Francois Chollet about can a computer learn complex abstract tasks through maybe reasoning from a few examples?
And here is the first place with descriptions!
https://www.kaggle.com/c/abstraction-and-reasoning-challenge/discussion/154597
But author doubts about his solution brings us to AGI, but it's interesting to look through :)
"This DSL is solved by enumeration (exploiting duplicates) + a greedy stacking combiner. Everything is implemented efficiently in C++ (with no dependencies) and running in parallel."
There are 10k lines of code and a bunch of tricks that you can read about on the link.
Though second and third place also interesting – you can find it in discussion section here https://www.kaggle.com/c/abstraction-and-reasoning-challenge/discussion
The 3d place even almost don't use ML :)
So, nothing close to general reasoning here : )
#kaggle #chollet #AGI #stacking
There is a very interesting challenge by #Francois Chollet about can a computer learn complex abstract tasks through maybe reasoning from a few examples?
And here is the first place with descriptions!
https://www.kaggle.com/c/abstraction-and-reasoning-challenge/discussion/154597
But author doubts about his solution brings us to AGI, but it's interesting to look through :)
"This DSL is solved by enumeration (exploiting duplicates) + a greedy stacking combiner. Everything is implemented efficiently in C++ (with no dependencies) and running in parallel."
There are 10k lines of code and a bunch of tricks that you can read about on the link.
Though second and third place also interesting – you can find it in discussion section here https://www.kaggle.com/c/abstraction-and-reasoning-challenge/discussion
The 3d place even almost don't use ML :)
So, nothing close to general reasoning here : )
#kaggle #chollet #AGI #stacking
Punch to face project
The team of Punch To Face (supported by ODS.ai) is bringing AI to the sports channels. The main goal of the project is a full 3D reconstruction of MMA fights in Virtual Reality.
Youtube: https://youtu.be/l_4FK8nBmEA
Story on Twitter: https://twitter.com/punch_to_face/
#CV #3D #AR #VR
The team of Punch To Face (supported by ODS.ai) is bringing AI to the sports channels. The main goal of the project is a full 3D reconstruction of MMA fights in Virtual Reality.
Youtube: https://youtu.be/l_4FK8nBmEA
Story on Twitter: https://twitter.com/punch_to_face/
#CV #3D #AR #VR
YouTube
May 2020 - demo video: our current techniques and some tricks from research.
https://punchtoface.com/
We are looking for partners to cover our backs and accelerate our growth! If you are interested in collaborating with us, please, send us an e-mail to the following address:
welcome@punchtoface.com
If you like what we are doing…
We are looking for partners to cover our backs and accelerate our growth! If you are interested in collaborating with us, please, send us an e-mail to the following address:
welcome@punchtoface.com
If you like what we are doing…
Practitioner’s Guide to Statistical Tests
CoreML team at VK
If you want to learn how to choose the right statistical test from the many available and run it on your own data you can find the answer at this article.
The two most essential things in A/B tests are the design of the experiments and accurate analysis of the experiments’ results. In this article, the authors stuck to the most common design and compare various statistical analysis procedures, from the very standard t-test and Mann-Whitney test to state-of-the-art approaches like the reweighted bootstrap.
article: https://medium.com/@vktech/practitioners-guide-to-statistical-tests-ed2d580ef04f
github: https://github.com/marnikitta/stattests
#statistic #ab #tests #vktech
CoreML team at VK
If you want to learn how to choose the right statistical test from the many available and run it on your own data you can find the answer at this article.
The two most essential things in A/B tests are the design of the experiments and accurate analysis of the experiments’ results. In this article, the authors stuck to the most common design and compare various statistical analysis procedures, from the very standard t-test and Mann-Whitney test to state-of-the-art approaches like the reweighted bootstrap.
article: https://medium.com/@vktech/practitioners-guide-to-statistical-tests-ed2d580ef04f
github: https://github.com/marnikitta/stattests
#statistic #ab #tests #vktech
Unsupervised Translation of Programming Languages
Model provided with Python, C++ or Java source code from GitHub, automatically learns to translate between the 3 languages in a fully unsupervised way.
Again: No supervision.
The correctness is then checked by compiling and running unit tests.
ArXiV: https://arxiv.org/pdf/2006.03511.pdf
#FAIR #FacebookAI #cs #unsupervised
Model provided with Python, C++ or Java source code from GitHub, automatically learns to translate between the 3 languages in a fully unsupervised way.
Again: No supervision.
The correctness is then checked by compiling and running unit tests.
ArXiV: https://arxiv.org/pdf/2006.03511.pdf
#FAIR #FacebookAI #cs #unsupervised
{kind=link}
> titlerun
it’s a simple game at the browser title bar with keyboard input
also, u can create your map :feelgoodmeme:
link to project – https://titlerun.xyz
#game #title #browser
it’s a simple game at the browser title bar with keyboard input
also, u can create your map :feelgoodmeme:
link to project – https://titlerun.xyz
#game #title #browser
{kind=link}
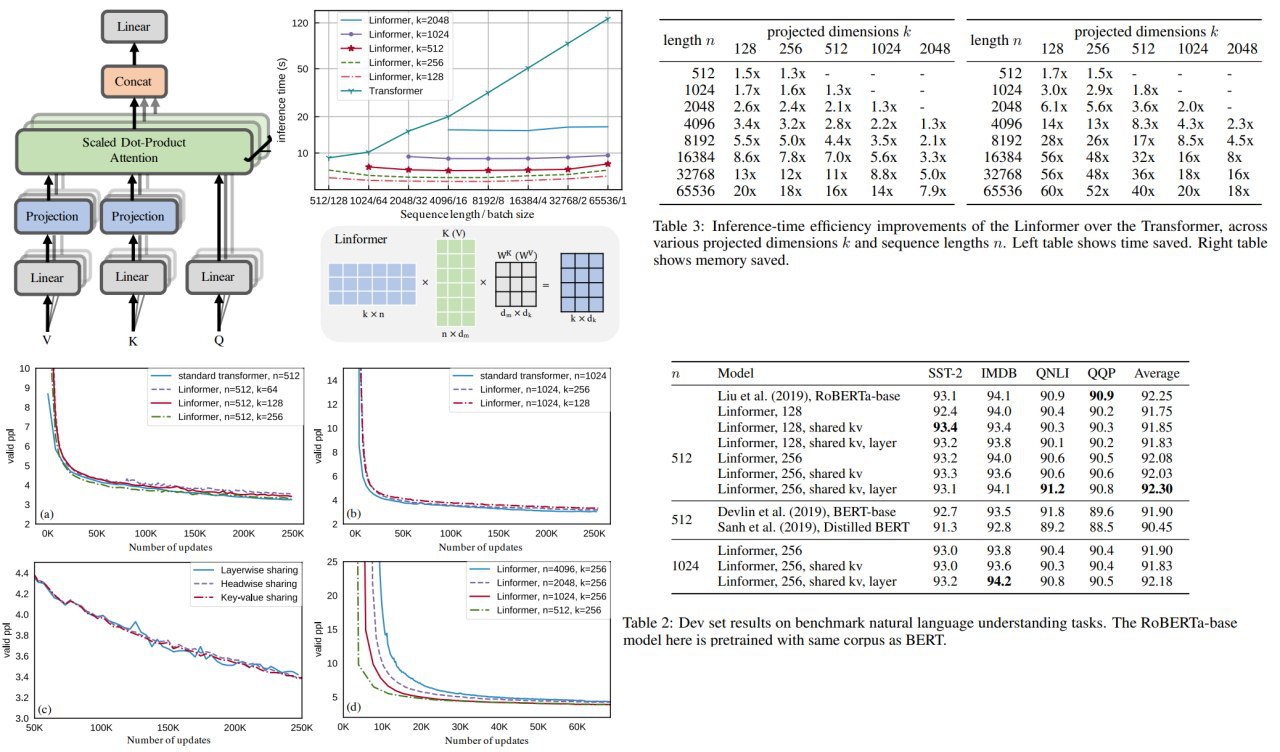
Linformer: Self-Attention with Linear Complexity
The authors prove that self-attention can be approximated by a low-rank matrix. This idea made it possible to develop a new self-attention architecture, which reduces the complexity of
Authors decompose the original scaled dot-product attention into multiple smaller attentions through linear projections, such that the combination of these operations forms a low-rank factorization of the original attention.
Also, they suggest a number of additional efficiency techniques:
– Parameter sharing between projections: Headwise, layerwise or key-value sharing
– Nonuniform projected dimension. It could be efficient to set lower projection dimension for higher levels
– General projections. Some different kind of projection instead of linear - pooling or convolution with kernel
For experiments, they use RoBERTa and train it on 64 Tesla V100 GPUs with 250k updates.
Authors show that models reach almost the same validation perplexity as in a transformer, while inference is much faster and requires less memory.
Paper: https://arxiv.org/abs/2006.04768
#deeplearning #attention #transformer #efficience #memoryoptimization #inferencespeed
The authors prove that self-attention can be approximated by a low-rank matrix. This idea made it possible to develop a new self-attention architecture, which reduces the complexity of
O(N^2) to O(N) in both time and space.Authors decompose the original scaled dot-product attention into multiple smaller attentions through linear projections, such that the combination of these operations forms a low-rank factorization of the original attention.
Also, they suggest a number of additional efficiency techniques:
– Parameter sharing between projections: Headwise, layerwise or key-value sharing
– Nonuniform projected dimension. It could be efficient to set lower projection dimension for higher levels
– General projections. Some different kind of projection instead of linear - pooling or convolution with kernel
n and stride kFor experiments, they use RoBERTa and train it on 64 Tesla V100 GPUs with 250k updates.
Authors show that models reach almost the same validation perplexity as in a transformer, while inference is much faster and requires less memory.
Paper: https://arxiv.org/abs/2006.04768
#deeplearning #attention #transformer #efficience #memoryoptimization #inferencespeed
{kind=link}
Thorough analysis of recent Tesla Model 3 accident and warning to autopilot users
Olga Uskova shared insights of her #CognitivePilot team members on #Tesla accident.
Highlights:
- Please don’t use autopilot on highways. They are still buggy and in development
- Obvious GTA-emulator training might have not been done to reach satisfactory results
- Tesla might have not been updating stereo cams + radar cooperation logic due to termination of contract with Mobileye EyeQ3
Analysis: https://www.facebook.com/uskova.oa/videos/804398560090702/
Article: https://www.thedrive.com/news/33789/autopilot-blamed-for-teslas-crash-into-overturned-truck
#autonomousdriving #selfdriving #RL #cars
Olga Uskova shared insights of her #CognitivePilot team members on #Tesla accident.
Highlights:
- Please don’t use autopilot on highways. They are still buggy and in development
- Obvious GTA-emulator training might have not been done to reach satisfactory results
- Tesla might have not been updating stereo cams + radar cooperation logic due to termination of contract with Mobileye EyeQ3
Analysis: https://www.facebook.com/uskova.oa/videos/804398560090702/
Article: https://www.thedrive.com/news/33789/autopilot-blamed-for-teslas-crash-into-overturned-truck
#autonomousdriving #selfdriving #RL #cars
self-supervised learning
the recent time more & more talk about self-supervised learning; maybe because each year increase data, how to know
the authors (lilian weng @ openai) cover the main ideas in this area on
• images (distortion, patches, colorization, generative modeling, contrastive predictive coding, momentum contrast)
• videos (tracking, frame sequence, video colorization)
• control problems (multi-view metric learning, autonomous goal generation)
btw, this article is being updated
article: https://lilianweng.github.io/lil-log/2019/11/10/self-supervised-learning.html
#selfsupervised #learning #pretext #unlabel
the recent time more & more talk about self-supervised learning; maybe because each year increase data, how to know
the authors (lilian weng @ openai) cover the main ideas in this area on
• images (distortion, patches, colorization, generative modeling, contrastive predictive coding, momentum contrast)
• videos (tracking, frame sequence, video colorization)
• control problems (multi-view metric learning, autonomous goal generation)
btw, this article is being updated
article: https://lilianweng.github.io/lil-log/2019/11/10/self-supervised-learning.html
#selfsupervised #learning #pretext #unlabel
{kind=link}
How Tesla Truck design affects design of all autonomous vehicles
#design #selfdriving #autonomousvehicle #rl #scania
#design #selfdriving #autonomousvehicle #rl #scania
Data Science by ODS.ai 🦜
Thorough analysis of recent Tesla Model 3 accident and warning to autopilot users Olga Uskova shared insights of her #CognitivePilot team members on #Tesla accident. Highlights: - Please don’t use autopilot on highways. They are still buggy and in development…
If you wanna explore #selfdriving problems more and haven’t seen it yet, you are welcome to checkout this post.
VirTex: Learning Visual Representations from Textual Annotations
The authors offer an alternative approach to pre-training backbones for CV tasks – using semantically dense captions to learn visual representations.
Recent methods have explored unsupervised pretraining to scale to vast quantities of unlabeled images. In contrast, the authors aim to learn high-quality visual representations from fewer images. They revisit supervised pretraining and seek data-efficient alternatives to classification-based pretraining.
VirTex (CNN + Transformer) is pre-trained on COCO captions. On downstream tasks it can reach performance similar to pre-training on ImageNet, but with 10x less images!
Paper: https://arxiv.org/abs/2006.06666
Code: https://github.com/kdexd/virtex
Site: https://kdexd.github.io/virtex/
#imagecaptioning #cv #visual #annotation #transformer #pretraining #transferlearning #deeplearning #paper
The authors offer an alternative approach to pre-training backbones for CV tasks – using semantically dense captions to learn visual representations.
Recent methods have explored unsupervised pretraining to scale to vast quantities of unlabeled images. In contrast, the authors aim to learn high-quality visual representations from fewer images. They revisit supervised pretraining and seek data-efficient alternatives to classification-based pretraining.
VirTex (CNN + Transformer) is pre-trained on COCO captions. On downstream tasks it can reach performance similar to pre-training on ImageNet, but with 10x less images!
Paper: https://arxiv.org/abs/2006.06666
Code: https://github.com/kdexd/virtex
Site: https://kdexd.github.io/virtex/
#imagecaptioning #cv #visual #annotation #transformer #pretraining #transferlearning #deeplearning #paper
{kind=link}
Forwarded from Graph Machine Learning
ICML 2020. Comprehensive analysis of authors, organizations, and countries.
Finally here is my post on the analysis of ICML 2020. There are several things I learned from that. For example that USA participates in 3/4 of the papers 😱 Or that DeepMind makes approximately half of all papers for UK. Or that Google does not collaborate with other companies. Or that, except the USA, there is only China that can brag about several companies that publish regularly. Or that a Japanese professor published 12 papers. And much more.
The code and data is on the github, but the cool part is that you can make your own interactive plots in colab notebook (with no installation required) including a collaboration graph between universities and companies.
Finally here is my post on the analysis of ICML 2020. There are several things I learned from that. For example that USA participates in 3/4 of the papers 😱 Or that DeepMind makes approximately half of all papers for UK. Or that Google does not collaborate with other companies. Or that, except the USA, there is only China that can brag about several companies that publish regularly. Or that a Japanese professor published 12 papers. And much more.
The code and data is on the github, but the cool part is that you can make your own interactive plots in colab notebook (with no installation required) including a collaboration graph between universities and companies.
Medium
ICML 2020. Comprehensive analysis of authors, organizations, and countries.
Who published the most?
PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization
Authors suggest an approach to the single image 3D shape reconstruction of a human body. The approach leverages representation from (1), that authors argue to be capable of processing high-resolution input images up to 1024 by 1024px.
The main idea of PIFu (1) is to represent a 3D shape as a function that defines the surface and the texture (both being parametrized by the MLP). This allows not to store the whole 3D volume as in voxel-based methods, but one can easily convert this representation to a mesh via a marching cube algorithm. Despite being more memory efficient, (1) still was not able to operate on the resolutions higher than 512 by 512px
Authors suggest an idea that pushes (1) even further, allowing to process images up to 1024 by 1024. They design a two-level pipeline with two PIFu modules, one for coarse shape estimation that operates on 512 by 512 px image and another one for fine-grained prediction, which takes 1024 by 1024px as an input as well as the features from the coarse level.
The model needs ground truth 3D poses thus authors use RenderPeople (2) dataset of 500 3D human models.
Paper: https://arxiv.org/pdf/2004.00452.pdf
Code: https://github.com/facebookresearch/pifuhd
Project: https://shunsukesaito.github.io/PIFuHD/
Colab: https://colab.research.google.com/drive/11z58bl3meSzo6kFqkahMa35G5jmh2Wgt
(1) Saito, S., Huang, Z., Natsume, R., Morishima, S., Kanazawa, A., & Li, H. (2019). Pifu: Pixel-aligned implicit function for high-resolution clothed human digitization. In Proceedings of the IEEE International Conference on Computer Vision (pp. 2304-2314).
(2) https://renderpeople.com/3d-people/
#3d #reconstruction #humandigitalization #singleimage
Authors suggest an approach to the single image 3D shape reconstruction of a human body. The approach leverages representation from (1), that authors argue to be capable of processing high-resolution input images up to 1024 by 1024px.
The main idea of PIFu (1) is to represent a 3D shape as a function that defines the surface and the texture (both being parametrized by the MLP). This allows not to store the whole 3D volume as in voxel-based methods, but one can easily convert this representation to a mesh via a marching cube algorithm. Despite being more memory efficient, (1) still was not able to operate on the resolutions higher than 512 by 512px
Authors suggest an idea that pushes (1) even further, allowing to process images up to 1024 by 1024. They design a two-level pipeline with two PIFu modules, one for coarse shape estimation that operates on 512 by 512 px image and another one for fine-grained prediction, which takes 1024 by 1024px as an input as well as the features from the coarse level.
The model needs ground truth 3D poses thus authors use RenderPeople (2) dataset of 500 3D human models.
Paper: https://arxiv.org/pdf/2004.00452.pdf
Code: https://github.com/facebookresearch/pifuhd
Project: https://shunsukesaito.github.io/PIFuHD/
Colab: https://colab.research.google.com/drive/11z58bl3meSzo6kFqkahMa35G5jmh2Wgt
(1) Saito, S., Huang, Z., Natsume, R., Morishima, S., Kanazawa, A., & Li, H. (2019). Pifu: Pixel-aligned implicit function for high-resolution clothed human digitization. In Proceedings of the IEEE International Conference on Computer Vision (pp. 2304-2314).
(2) https://renderpeople.com/3d-people/
#3d #reconstruction #humandigitalization #singleimage
{kind=link}
Image GPT
by openai
The authors have shown that by trading off 2-D knowledge for scale and by choosing predictive features from the middle of the network, a sequence transformer can be competitive with top convolutional nets for unsupervised image classification.
Notably, they achieved their results by directly applying the GPT-2 language model to image generation. Their results suggest that due to its simplicity and generality, a sequence transformer given sufficient compute might ultimately be an effective way to learn excellent features in many domains.
There are two methods they use to assess model performance:
[0] linear probe, uses the trained model to extract features from the images in the downstream dataset and then fits a logistic regression to the labels
[1] fine-tunes the entire model on the downstream dataset :youknow:
blog: https://openai.com/blog/image-gpt/
papers:
icml 2020 (v1)
(v2)
github (code is provided as-is, no updates expected): https://github.com/openai/image-gpt
#openai #gpt2 #language #image #icml2020
by openai
The authors have shown that by trading off 2-D knowledge for scale and by choosing predictive features from the middle of the network, a sequence transformer can be competitive with top convolutional nets for unsupervised image classification.
Notably, they achieved their results by directly applying the GPT-2 language model to image generation. Their results suggest that due to its simplicity and generality, a sequence transformer given sufficient compute might ultimately be an effective way to learn excellent features in many domains.
There are two methods they use to assess model performance:
[0] linear probe, uses the trained model to extract features from the images in the downstream dataset and then fits a logistic regression to the labels
[1] fine-tunes the entire model on the downstream dataset :youknow:
blog: https://openai.com/blog/image-gpt/
papers:
icml 2020 (v1)
(v2)
github (code is provided as-is, no updates expected): https://github.com/openai/image-gpt
#openai #gpt2 #language #image #icml2020