
Linformer: Self-Attention with Linear Complexity
The authors prove that self-attention can be approximated by a low-rank matrix. This idea made it possible to develop a new self-attention architecture, which reduces the complexity of
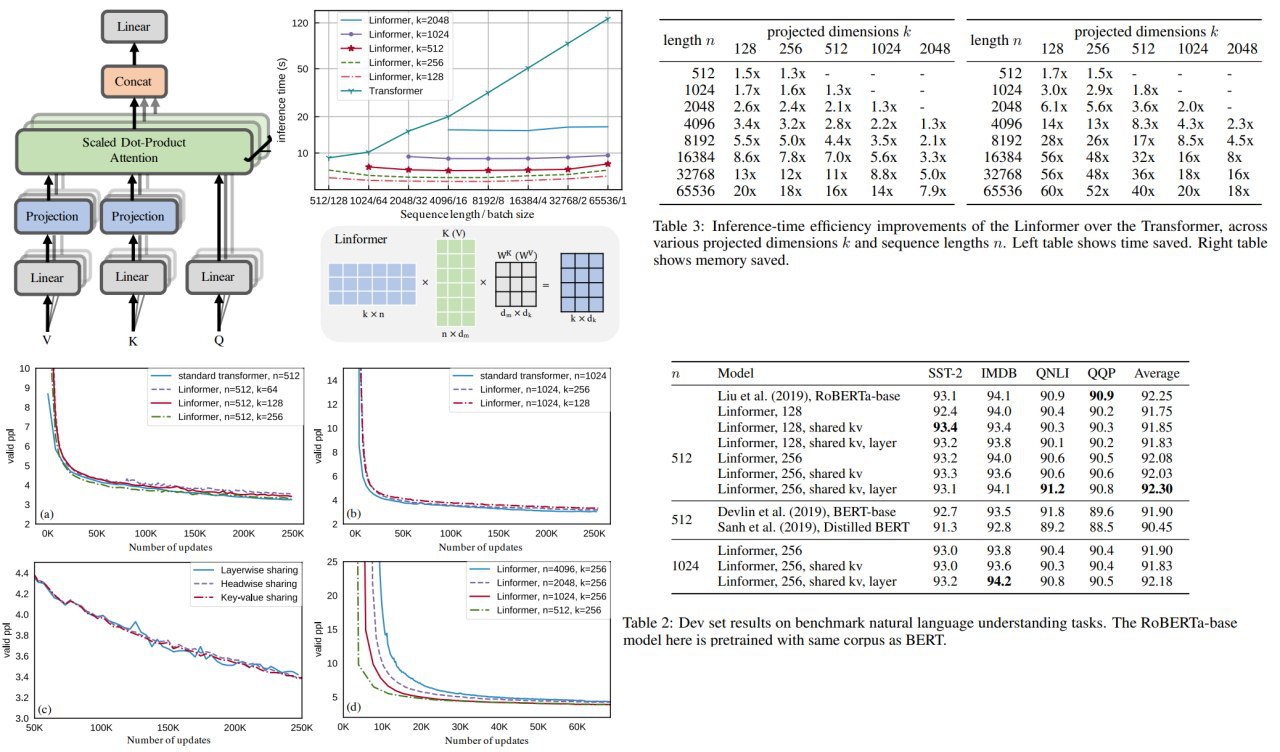
Authors decompose the original scaled dot-product attention into multiple smaller attentions through linear projections, such that the combination of these operations forms a low-rank factorization of the original attention.
Also, they suggest a number of additional efficiency techniques:
– Parameter sharing between projections: Headwise, layerwise or key-value sharing
– Nonuniform projected dimension. It could be efficient to set lower projection dimension for higher levels
– General projections. Some different kind of projection instead of linear - pooling or convolution with kernel
For experiments, they use RoBERTa and train it on 64 Tesla V100 GPUs with 250k updates.
Authors show that models reach almost the same validation perplexity as in a transformer, while inference is much faster and requires less memory.
Paper: https://arxiv.org/abs/2006.04768
#deeplearning #attention #transformer #efficience #memoryoptimization #inferencespeed
The authors prove that self-attention can be approximated by a low-rank matrix. This idea made it possible to develop a new self-attention architecture, which reduces the complexity of
O(N^2) to O(N) in both time and space.Authors decompose the original scaled dot-product attention into multiple smaller attentions through linear projections, such that the combination of these operations forms a low-rank factorization of the original attention.
Also, they suggest a number of additional efficiency techniques:
– Parameter sharing between projections: Headwise, layerwise or key-value sharing
– Nonuniform projected dimension. It could be efficient to set lower projection dimension for higher levels
– General projections. Some different kind of projection instead of linear - pooling or convolution with kernel
n and stride kFor experiments, they use RoBERTa and train it on 64 Tesla V100 GPUs with 250k updates.
Authors show that models reach almost the same validation perplexity as in a transformer, while inference is much faster and requires less memory.
Paper: https://arxiv.org/abs/2006.04768
#deeplearning #attention #transformer #efficience #memoryoptimization #inferencespeed
{kind=link}