
🎙Mozilla’s Common Voice project
Mozilla launched a project to make digitalization of human voice more open and accessable. Anyone is eligible to download the dataset to use it for building #voicerecognition or #voicegeneration ML systems.
Most importantly, anyone can take a part in the project and make sure that her/his voice with all the accents and personal manner of speech features such as altitude, speed, clarity and timbre are accounted for in the models are to built.
Why is that important: if you have speech defects and you are not happy how machine speech translation works for you, or how well #Alexa or #Siri gets you, you should spend some time recording your voice for the Common Voice, to increase the probability of upcoming voice recognition model working great for you.
Project: https://voice.mozilla.org
Venturebeat article: https://venturebeat.com/2020/07/01/mozilla-common-voice-updates-will-help-train-the-hey-firefox-wakeword-for-voice-based-web-browsing/
#open #SpeechToText #TextToSpeech #DL #mozilla #audiolearning #voicerecognition
Mozilla launched a project to make digitalization of human voice more open and accessable. Anyone is eligible to download the dataset to use it for building #voicerecognition or #voicegeneration ML systems.
Most importantly, anyone can take a part in the project and make sure that her/his voice with all the accents and personal manner of speech features such as altitude, speed, clarity and timbre are accounted for in the models are to built.
Why is that important: if you have speech defects and you are not happy how machine speech translation works for you, or how well #Alexa or #Siri gets you, you should spend some time recording your voice for the Common Voice, to increase the probability of upcoming voice recognition model working great for you.
Project: https://voice.mozilla.org
Venturebeat article: https://venturebeat.com/2020/07/01/mozilla-common-voice-updates-will-help-train-the-hey-firefox-wakeword-for-voice-based-web-browsing/
#open #SpeechToText #TextToSpeech #DL #mozilla #audiolearning #voicerecognition
NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers
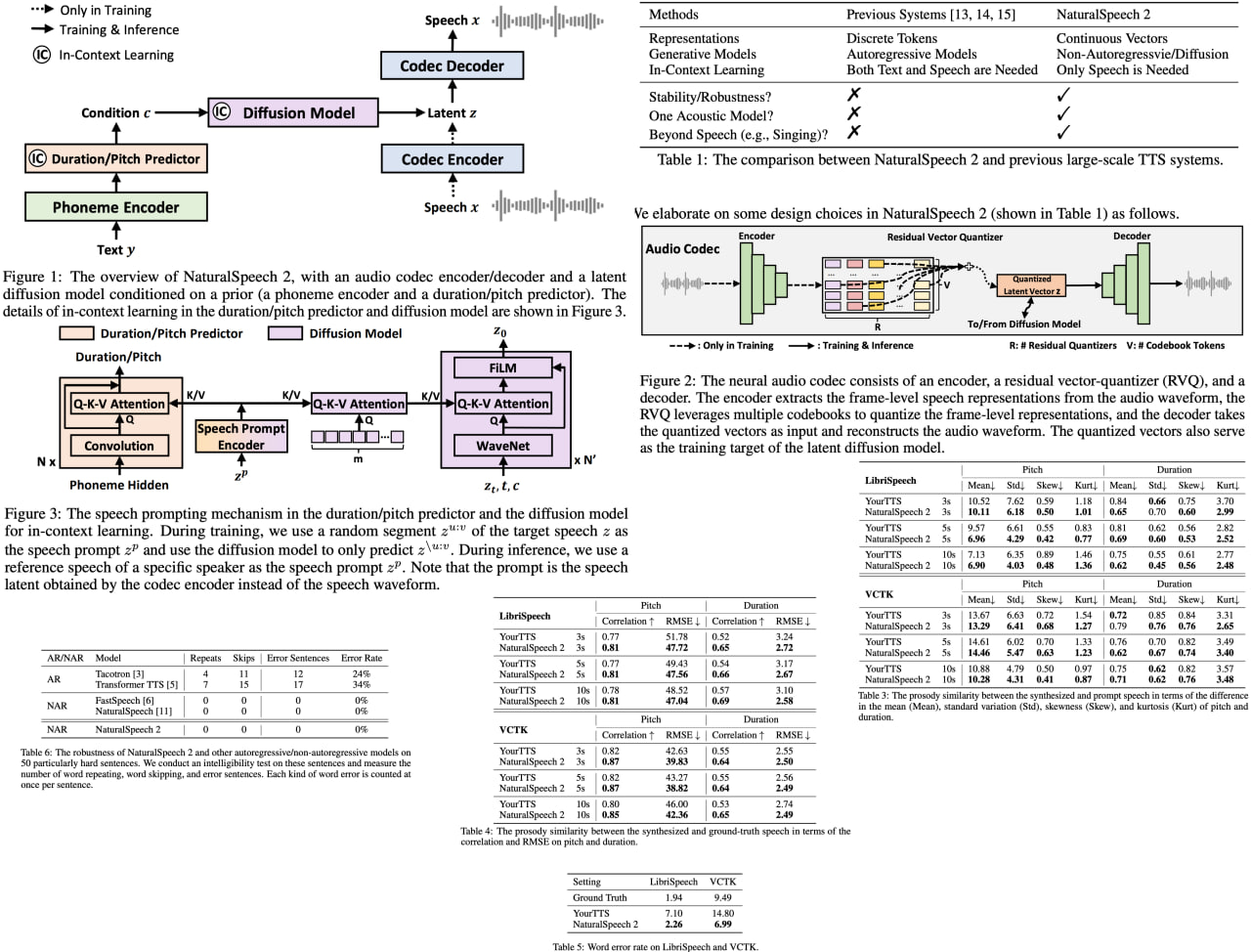
In the rapidly evolving domain of text-to-speech (TTS) technology, an exciting breakthrough has been made with the development of NaturalSpeech 2. This innovative system brings new levels of diversity to the table, by uniquely capturing a wide range of human speech characteristics such as speaker identities, prosodies, and even styles like singing. By employing a neural audio codec and residual vector quantizers, it transcends the limitations of existing TTS systems, which often suffer from unstable prosody, word skipping/repeating issues, and subpar voice quality.
More impressively, NaturalSpeech 2 enhances the "zero-shot" capability, a crucial factor for diverse speech synthesis. By designing a unique speech prompting mechanism, it facilitates in-context learning in both the diffusion model and the duration/pitch predictor. Its expansive training on 44K hours of speech and singing data has yielded unprecedented results. NaturalSpeech 2 significantly outperforms previous TTS systems in prosody/timbre similarity, robustness, and voice quality, even demonstrating novel zero-shot singing synthesis.
Project link: https://speechresearch.github.io/naturalspeech2/
Paper link: https://arxiv.org/pdf/2304.09116.pdf
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-naturalspeech2
#deeplearning #nlp #tts #texttospeech
In the rapidly evolving domain of text-to-speech (TTS) technology, an exciting breakthrough has been made with the development of NaturalSpeech 2. This innovative system brings new levels of diversity to the table, by uniquely capturing a wide range of human speech characteristics such as speaker identities, prosodies, and even styles like singing. By employing a neural audio codec and residual vector quantizers, it transcends the limitations of existing TTS systems, which often suffer from unstable prosody, word skipping/repeating issues, and subpar voice quality.
More impressively, NaturalSpeech 2 enhances the "zero-shot" capability, a crucial factor for diverse speech synthesis. By designing a unique speech prompting mechanism, it facilitates in-context learning in both the diffusion model and the duration/pitch predictor. Its expansive training on 44K hours of speech and singing data has yielded unprecedented results. NaturalSpeech 2 significantly outperforms previous TTS systems in prosody/timbre similarity, robustness, and voice quality, even demonstrating novel zero-shot singing synthesis.
Project link: https://speechresearch.github.io/naturalspeech2/
Paper link: https://arxiv.org/pdf/2304.09116.pdf
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-naturalspeech2
#deeplearning #nlp #tts #texttospeech
{kind=link}
Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale
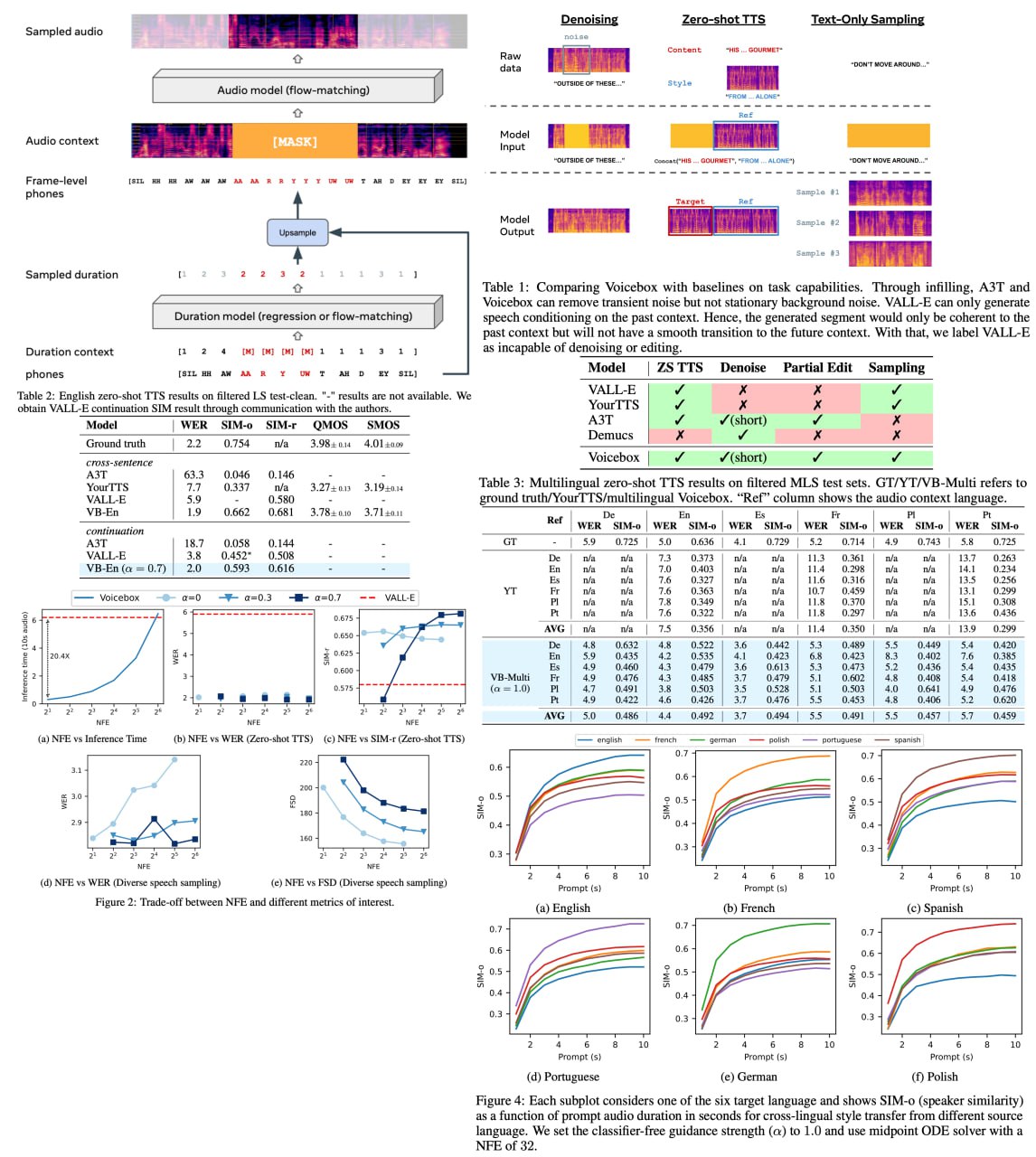
In the ever-evolving field of natural language processing and computer vision research, the revolution is being led by large-scale generative models like GPT and DALL-E. These models have the remarkable capability of generating high fidelity text or image outputs, and more importantly, they possess a 'generalist' character, able to solve tasks that they weren't explicitly trained to accomplish. However, when it comes to speech generative models, there's still a significant gap in terms of scale and task generalization. Enter, Voicebox - a pioneering advancement set to redefine the landscape of speech generation technology.
Voicebox is an exceptionally versatile text-guided generative model for speech at an impressive scale. Trained on over 50K hours of unfiltered, unenhanced speech data, Voicebox is a non-autoregressive flow-matching model, designed to infill speech, given an audio context and text. Much like its predecessors, Voicebox is able to perform a wide range of tasks through in-context learning, but with an added flexibility - it can condition on future context. The applications are boundless - from mono or cross-lingual zero-shot text-to-speech synthesis to noise removal, content editing, style conversion, and diverse sample generation. What's truly phenomenal is Voicebox's capability to outshine the state-of-the-art zero-shot TTS model, VALL-E, on both intelligibility and audio similarity metrics, while being a staggering 20 times faster.
Paper link: https://research.facebook.com/publications/voicebox-text-guided-multilingual-universal-speech-generation-at-scale/
Blogpost link: https://ai.facebook.com/blog/voicebox-generative-ai-model-speech/
Project link: https://voicebox.metademolab.com/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-voicebox
#deeplearning #nlp #speechgeneration #texttospeech
In the ever-evolving field of natural language processing and computer vision research, the revolution is being led by large-scale generative models like GPT and DALL-E. These models have the remarkable capability of generating high fidelity text or image outputs, and more importantly, they possess a 'generalist' character, able to solve tasks that they weren't explicitly trained to accomplish. However, when it comes to speech generative models, there's still a significant gap in terms of scale and task generalization. Enter, Voicebox - a pioneering advancement set to redefine the landscape of speech generation technology.
Voicebox is an exceptionally versatile text-guided generative model for speech at an impressive scale. Trained on over 50K hours of unfiltered, unenhanced speech data, Voicebox is a non-autoregressive flow-matching model, designed to infill speech, given an audio context and text. Much like its predecessors, Voicebox is able to perform a wide range of tasks through in-context learning, but with an added flexibility - it can condition on future context. The applications are boundless - from mono or cross-lingual zero-shot text-to-speech synthesis to noise removal, content editing, style conversion, and diverse sample generation. What's truly phenomenal is Voicebox's capability to outshine the state-of-the-art zero-shot TTS model, VALL-E, on both intelligibility and audio similarity metrics, while being a staggering 20 times faster.
Paper link: https://research.facebook.com/publications/voicebox-text-guided-multilingual-universal-speech-generation-at-scale/
Blogpost link: https://ai.facebook.com/blog/voicebox-generative-ai-model-speech/
Project link: https://voicebox.metademolab.com/
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-voicebox
#deeplearning #nlp #speechgeneration #texttospeech
{kind=link}