
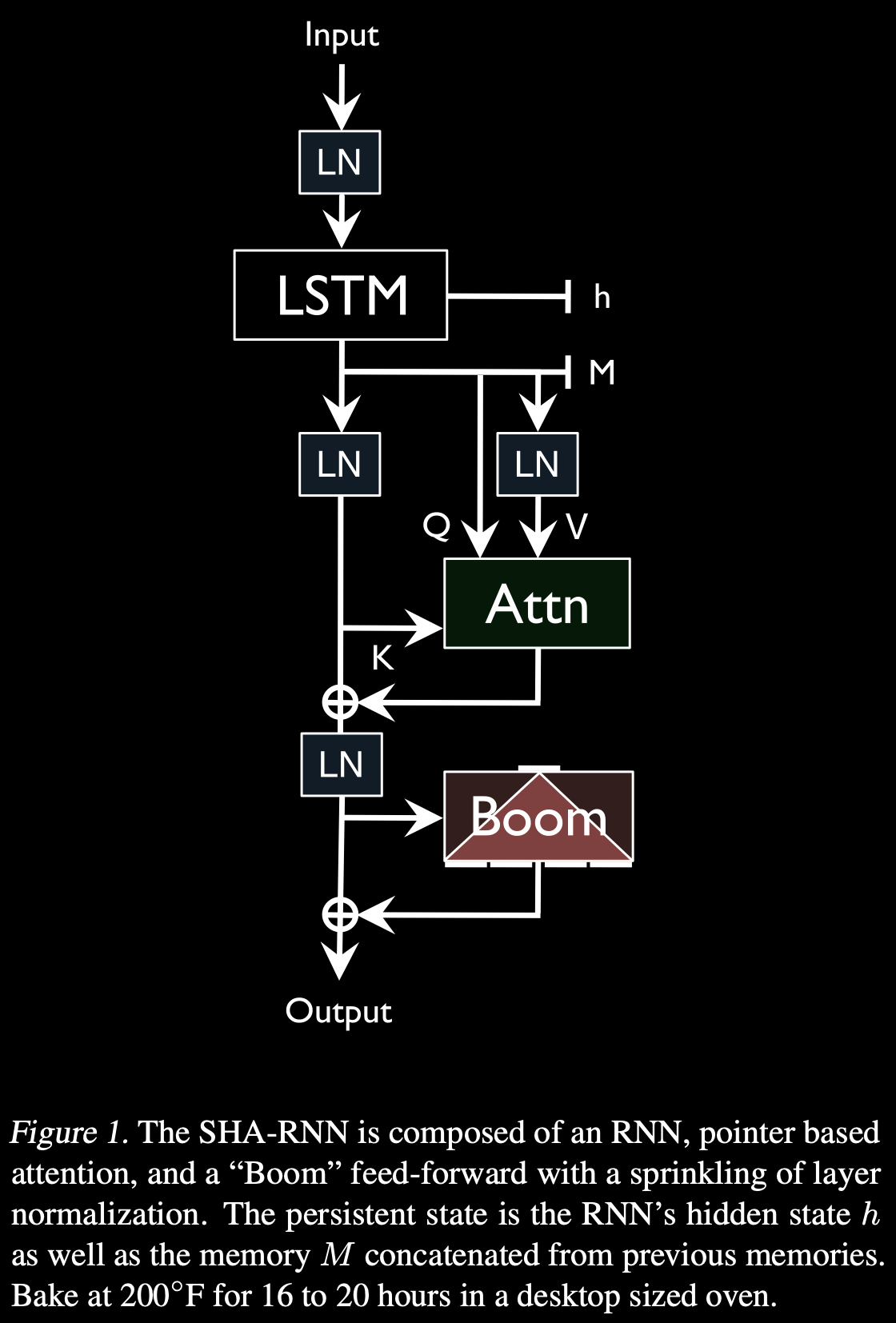
Single Headed Attention RNN
tl;dr: stop thinking with your (#attention) head :kekeke:
* obtain strong results on a byte level #languageModeling dataset (enwik8) in under 24 hours on a single GPU (12GB Titan V)
* support long-range dependencies (up to 5000 tokens) without increasing compute time or memory usage substantially by using a simpler attention mechanism
* avoid the fragile training process required by standard #Transformer models such as a long warmup
* back off toward a standard #LSTM allowing you to drop retained memory states (needed for a Transformer model) if memory becomes a major constraint
* provide a smaller model that features only standard components such as the LSTM, single-headed attention, and feed-forward modules such that they can easily be productionized using existing optimized tools and exported to various formats (i.e. ONNX)
paper: https://arxiv.org/abs/1911.11423
code: https://github.com/Smerity/sha-rnn
tweet: https://twitter.com/Smerity/status/1199529360954257408?s=20
tl;dr: stop thinking with your (#attention) head :kekeke:
* obtain strong results on a byte level #languageModeling dataset (enwik8) in under 24 hours on a single GPU (12GB Titan V)
* support long-range dependencies (up to 5000 tokens) without increasing compute time or memory usage substantially by using a simpler attention mechanism
* avoid the fragile training process required by standard #Transformer models such as a long warmup
* back off toward a standard #LSTM allowing you to drop retained memory states (needed for a Transformer model) if memory becomes a major constraint
* provide a smaller model that features only standard components such as the LSTM, single-headed attention, and feed-forward modules such that they can easily be productionized using existing optimized tools and exported to various formats (i.e. ONNX)
paper: https://arxiv.org/abs/1911.11423
code: https://github.com/Smerity/sha-rnn
tweet: https://twitter.com/Smerity/status/1199529360954257408?s=20
{kind=link}
On Identifiability in Transformers
The authors tried to understanding better transformers from identifiability.
They started by proving that attention weights are non-identifiable when the sequence length is longer than the attention head dimension. Thus, infinitely many attention distributions can lead to the same internal representation and model output. They propose effective attention, a method that improves the interpretability of attention weights by projecting out the null space.
Also, showed that tokens remain largely identifiable through a learned linear transformation followed by the nearest neighbor lookup based on cosine similarity. However, input tokens gradually become less identifiable in later layers.
Presented Hidden Token Attribution, a gradient-based method to quantify information mixing. This method is general and can be used to investigate contextual embeddings in self-attention based models.
paper: https://arxiv.org/abs/1908.04211
#nlp #transformer #interpretability #attention #ICLR2020
The authors tried to understanding better transformers from identifiability.
They started by proving that attention weights are non-identifiable when the sequence length is longer than the attention head dimension. Thus, infinitely many attention distributions can lead to the same internal representation and model output. They propose effective attention, a method that improves the interpretability of attention weights by projecting out the null space.
Also, showed that tokens remain largely identifiable through a learned linear transformation followed by the nearest neighbor lookup based on cosine similarity. However, input tokens gradually become less identifiable in later layers.
Presented Hidden Token Attribution, a gradient-based method to quantify information mixing. This method is general and can be used to investigate contextual embeddings in self-attention based models.
paper: https://arxiv.org/abs/1908.04211
#nlp #transformer #interpretability #attention #ICLR2020
{kind=link}
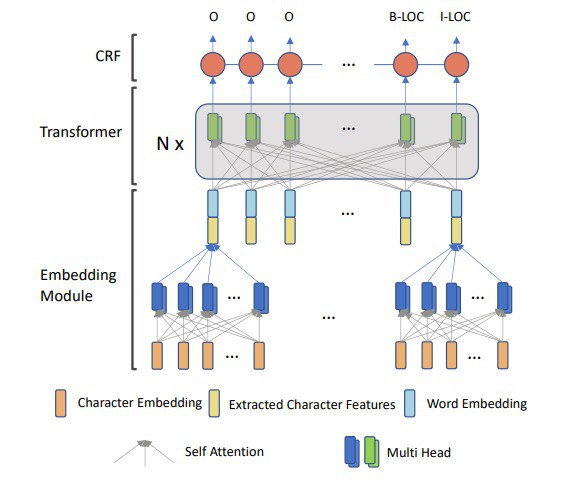
TENER: Adapting Transformer Encoder for Named Entity Recognition
The authors suggest several modifications to Transformer architecture for NER tasks.
Recently Transformer architectures were adopted in many NLP tasks and showed great results. Nevertheless, the performance of the vanilla Transformer in NER is not as good as it is in other NLP tasks.
To improve the performance of this approach for NER tasks the following improvements were implemented:
– revised relative positional encoding to use both the direction and distance information;
– un-scaled attention, as few contextual words are enough to judge its label
– using both word-embeddings and character-embeddings.
The experiments show that this approach can reach SOTA results (without considering the pre-trained language models). The adapted Transformer is also suitable for being used as the English character encoder.
Paper: https://arxiv.org/abs/1911.04474
Code: https://github.com/fastnlp/TENER
#deeplearning #nlp #transformer #attention #encoder #ner
The authors suggest several modifications to Transformer architecture for NER tasks.
Recently Transformer architectures were adopted in many NLP tasks and showed great results. Nevertheless, the performance of the vanilla Transformer in NER is not as good as it is in other NLP tasks.
To improve the performance of this approach for NER tasks the following improvements were implemented:
– revised relative positional encoding to use both the direction and distance information;
– un-scaled attention, as few contextual words are enough to judge its label
– using both word-embeddings and character-embeddings.
The experiments show that this approach can reach SOTA results (without considering the pre-trained language models). The adapted Transformer is also suitable for being used as the English character encoder.
Paper: https://arxiv.org/abs/1911.04474
Code: https://github.com/fastnlp/TENER
#deeplearning #nlp #transformer #attention #encoder #ner
{kind=link}
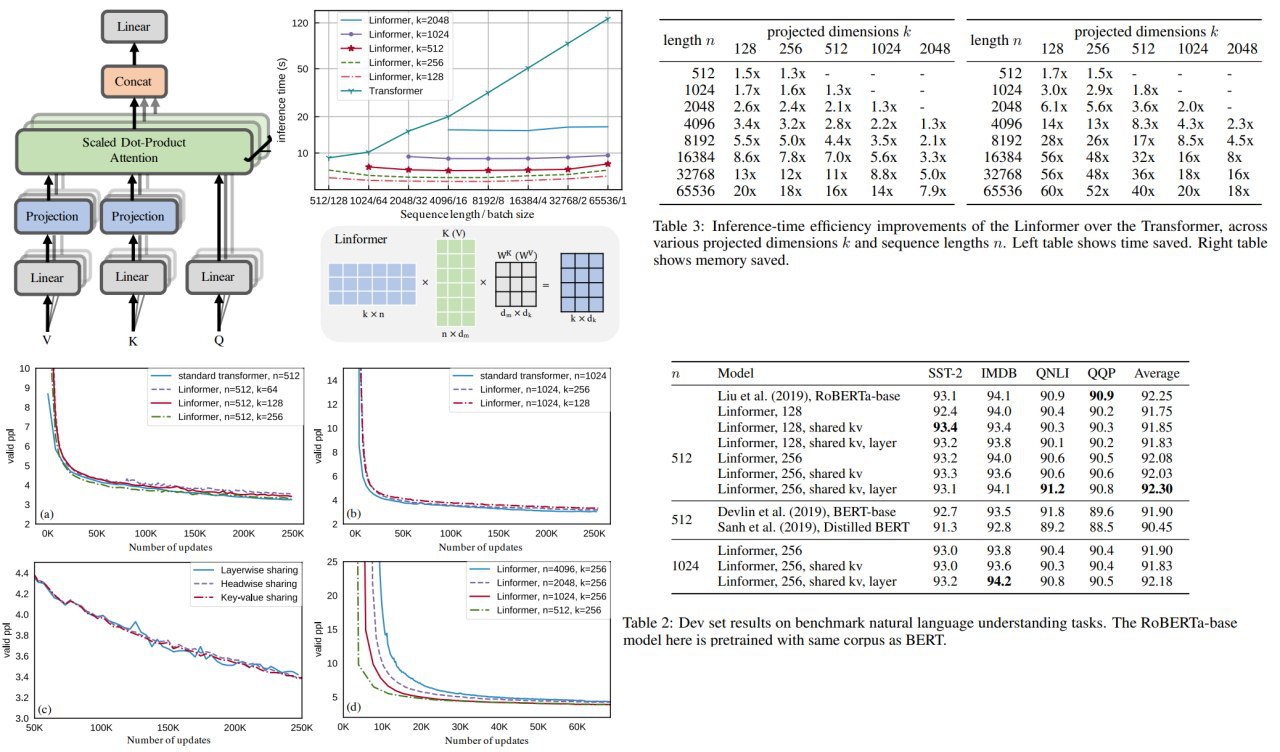
Linformer: Self-Attention with Linear Complexity
The authors prove that self-attention can be approximated by a low-rank matrix. This idea made it possible to develop a new self-attention architecture, which reduces the complexity of
Authors decompose the original scaled dot-product attention into multiple smaller attentions through linear projections, such that the combination of these operations forms a low-rank factorization of the original attention.
Also, they suggest a number of additional efficiency techniques:
– Parameter sharing between projections: Headwise, layerwise or key-value sharing
– Nonuniform projected dimension. It could be efficient to set lower projection dimension for higher levels
– General projections. Some different kind of projection instead of linear - pooling or convolution with kernel
For experiments, they use RoBERTa and train it on 64 Tesla V100 GPUs with 250k updates.
Authors show that models reach almost the same validation perplexity as in a transformer, while inference is much faster and requires less memory.
Paper: https://arxiv.org/abs/2006.04768
#deeplearning #attention #transformer #efficience #memoryoptimization #inferencespeed
The authors prove that self-attention can be approximated by a low-rank matrix. This idea made it possible to develop a new self-attention architecture, which reduces the complexity of
O(N^2) to O(N) in both time and space.Authors decompose the original scaled dot-product attention into multiple smaller attentions through linear projections, such that the combination of these operations forms a low-rank factorization of the original attention.
Also, they suggest a number of additional efficiency techniques:
– Parameter sharing between projections: Headwise, layerwise or key-value sharing
– Nonuniform projected dimension. It could be efficient to set lower projection dimension for higher levels
– General projections. Some different kind of projection instead of linear - pooling or convolution with kernel
n and stride kFor experiments, they use RoBERTa and train it on 64 Tesla V100 GPUs with 250k updates.
Authors show that models reach almost the same validation perplexity as in a transformer, while inference is much faster and requires less memory.
Paper: https://arxiv.org/abs/2006.04768
#deeplearning #attention #transformer #efficience #memoryoptimization #inferencespeed
{kind=link}
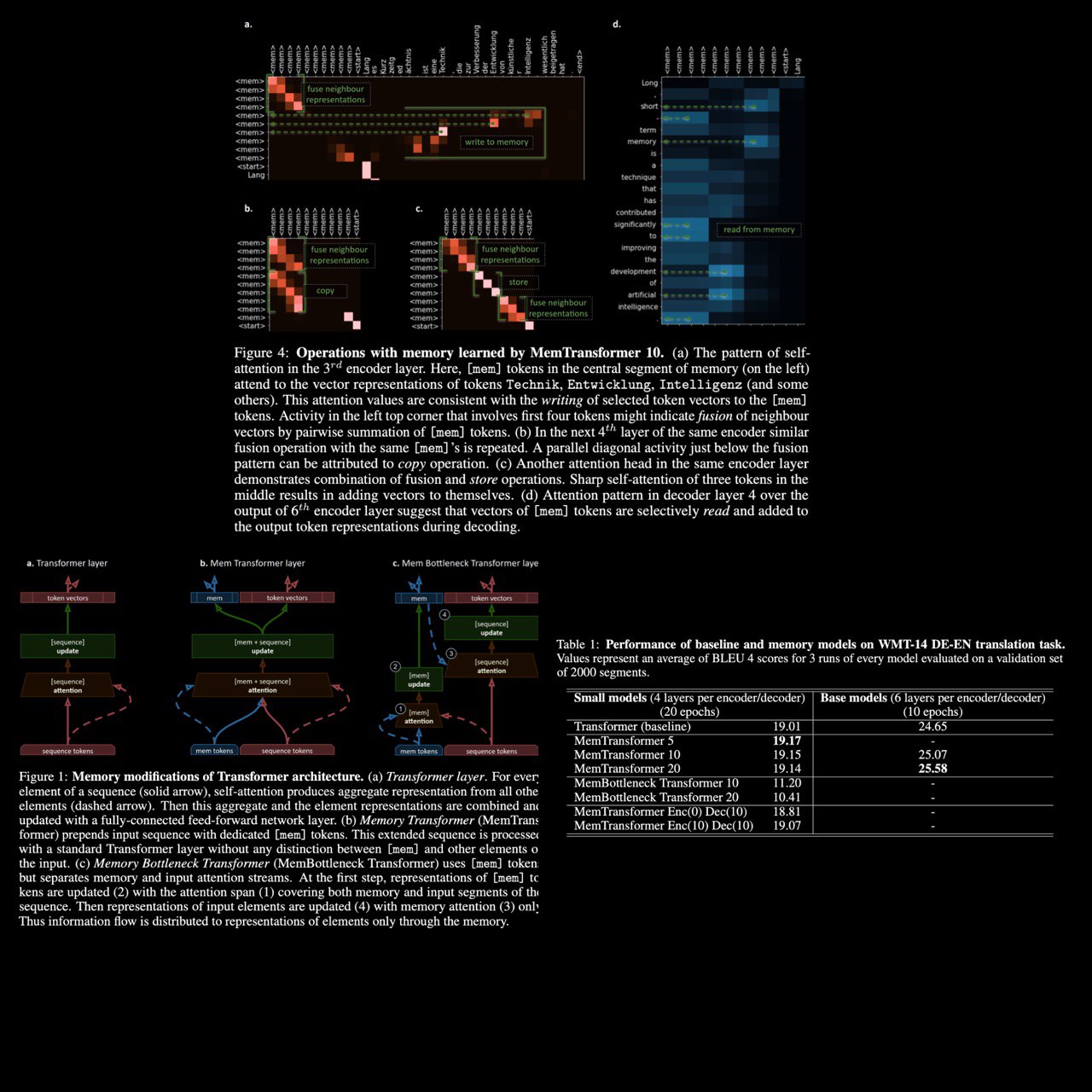
Memory Transformer
Burtsev & Sapunov
The authors proposed and studied two memory augmented architectures MemTransformer and MemBottleneck Transformer. Qualitative analysis of attention patterns produced by the transformer heads trained to solve machine translation task suggests that both models successfully discovered basic operations for memory control. Attention maps show evidence for the presence of memory read/write as well as some in-memory processing operations such as copying and summation.
A comparison of machine translation quality shows that adding general-purpose memory in MemTransformer improves performance over the baseline. Moreover, the speed of training and final quality positively correlates with the memory size. On the other hand, MemBottleneck Transformer, with all self-attention restricted to the memory only, has significantly lower scores after training.
Memory lesion tests demonstrate that the performance of the pre-trained MemTransformer model critically depends on the presence of memory. Still, the memory controller learned by the model degrades only gradually when memory size is changed during inference. This indicates that the controller has some robustness and ability for generalization.
More interesting figures u can check out in the attachment.
paper: https://arxiv.org/abs/2006.11527.pdf
#nlp #transformer #attention #machine #translation
Burtsev & Sapunov
The authors proposed and studied two memory augmented architectures MemTransformer and MemBottleneck Transformer. Qualitative analysis of attention patterns produced by the transformer heads trained to solve machine translation task suggests that both models successfully discovered basic operations for memory control. Attention maps show evidence for the presence of memory read/write as well as some in-memory processing operations such as copying and summation.
A comparison of machine translation quality shows that adding general-purpose memory in MemTransformer improves performance over the baseline. Moreover, the speed of training and final quality positively correlates with the memory size. On the other hand, MemBottleneck Transformer, with all self-attention restricted to the memory only, has significantly lower scores after training.
Memory lesion tests demonstrate that the performance of the pre-trained MemTransformer model critically depends on the presence of memory. Still, the memory controller learned by the model degrades only gradually when memory size is changed during inference. This indicates that the controller has some robustness and ability for generalization.
More interesting figures u can check out in the attachment.
paper: https://arxiv.org/abs/2006.11527.pdf
#nlp #transformer #attention #machine #translation
{kind=link}
Long-Short Transformer: Efficient Transformers for Language and Vision
This paper offers a new approach to solving the problem of quadratic time and memory complexities of self-attention in Transformers. The authors propose Long-Short Transformer (Transformer-LS), an efficient self-attention mechanism for modeling long sequences with linear complexity for both language and vision tasks. It aggregates a novel long-range attention with dynamic projection to model distant correlations and a short-term attention to capture fine-grained local correlations. A dual normalization is used to deal with the scale mismatch between the two attention mechanisms. Transformer-LS can be applied to both autoregressive and bidirectional models without additional complexity.
This method outperforms the state-of-the-art models on multiple tasks in language and vision domains. For instance, Transformer-LS achieves 0.97 test BPC on enwik8 using half the number of parameters than previous methods, while being faster and is able to handle 3× as long sequences. On ImageNet, it can obtain 84.1% Top-1 accuracy, while being more scalable on high-resolution images.
Paper: https://arxiv.org/abs/2107.02192
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-transformerls
#deeplearning #cv #nlp #transformer #attention
This paper offers a new approach to solving the problem of quadratic time and memory complexities of self-attention in Transformers. The authors propose Long-Short Transformer (Transformer-LS), an efficient self-attention mechanism for modeling long sequences with linear complexity for both language and vision tasks. It aggregates a novel long-range attention with dynamic projection to model distant correlations and a short-term attention to capture fine-grained local correlations. A dual normalization is used to deal with the scale mismatch between the two attention mechanisms. Transformer-LS can be applied to both autoregressive and bidirectional models without additional complexity.
This method outperforms the state-of-the-art models on multiple tasks in language and vision domains. For instance, Transformer-LS achieves 0.97 test BPC on enwik8 using half the number of parameters than previous methods, while being faster and is able to handle 3× as long sequences. On ImageNet, it can obtain 84.1% Top-1 accuracy, while being more scalable on high-resolution images.
Paper: https://arxiv.org/abs/2107.02192
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-transformerls
#deeplearning #cv #nlp #transformer #attention
{kind=link}
🦜 Hi!
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
GitHub
ultimate_posts/where_to_start at master · open-data-science/ultimate_posts
Ultimate posts for opendatascience telegram channel - open-data-science/ultimate_posts