
Single Headed Attention RNN
tl;dr: stop thinking with your (#attention) head :kekeke:
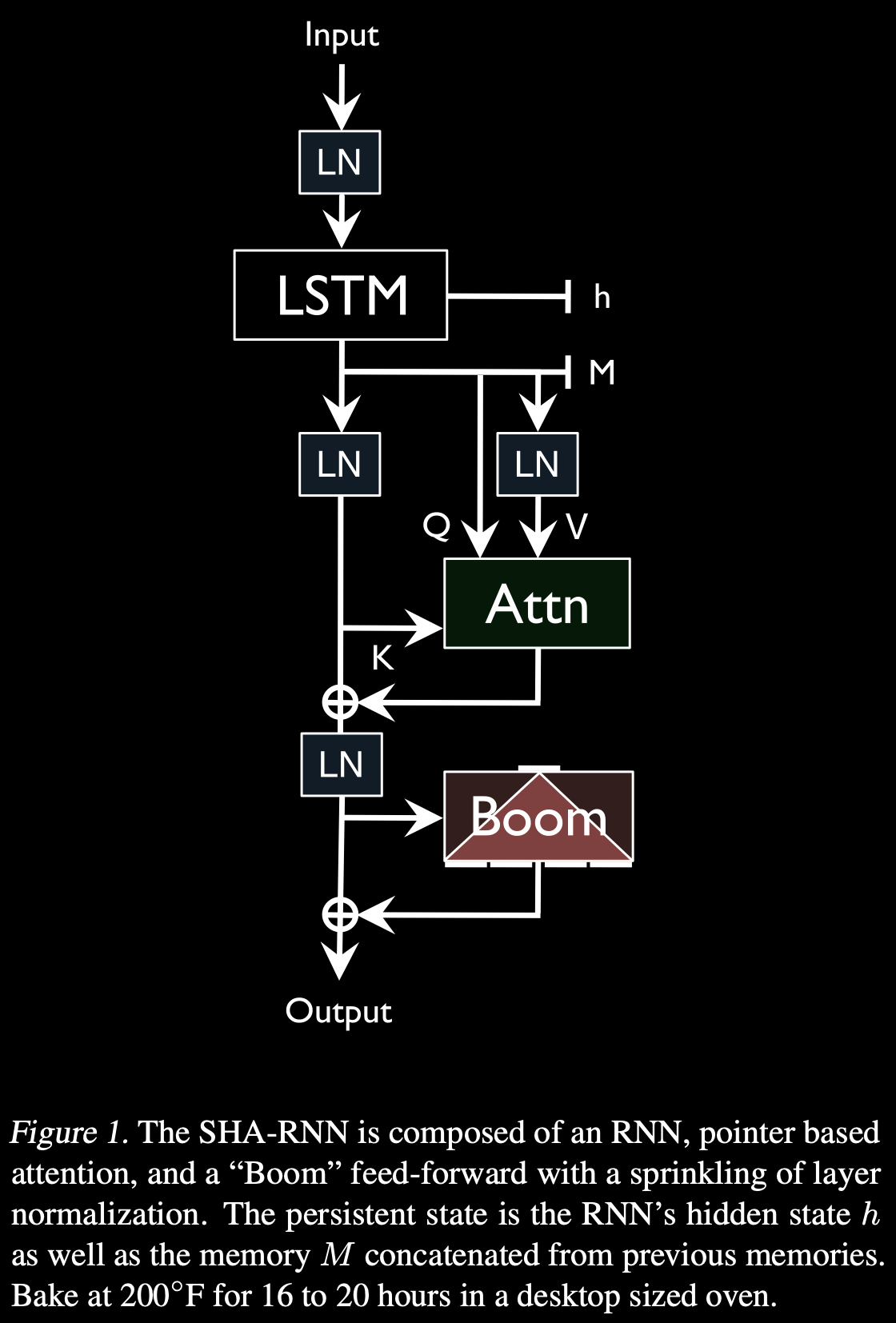
* obtain strong results on a byte level #languageModeling dataset (enwik8) in under 24 hours on a single GPU (12GB Titan V)
* support long-range dependencies (up to 5000 tokens) without increasing compute time or memory usage substantially by using a simpler attention mechanism
* avoid the fragile training process required by standard #Transformer models such as a long warmup
* back off toward a standard #LSTM allowing you to drop retained memory states (needed for a Transformer model) if memory becomes a major constraint
* provide a smaller model that features only standard components such as the LSTM, single-headed attention, and feed-forward modules such that they can easily be productionized using existing optimized tools and exported to various formats (i.e. ONNX)
paper: https://arxiv.org/abs/1911.11423
code: https://github.com/Smerity/sha-rnn
tweet: https://twitter.com/Smerity/status/1199529360954257408?s=20
tl;dr: stop thinking with your (#attention) head :kekeke:
* obtain strong results on a byte level #languageModeling dataset (enwik8) in under 24 hours on a single GPU (12GB Titan V)
* support long-range dependencies (up to 5000 tokens) without increasing compute time or memory usage substantially by using a simpler attention mechanism
* avoid the fragile training process required by standard #Transformer models such as a long warmup
* back off toward a standard #LSTM allowing you to drop retained memory states (needed for a Transformer model) if memory becomes a major constraint
* provide a smaller model that features only standard components such as the LSTM, single-headed attention, and feed-forward modules such that they can easily be productionized using existing optimized tools and exported to various formats (i.e. ONNX)
paper: https://arxiv.org/abs/1911.11423
code: https://github.com/Smerity/sha-rnn
tweet: https://twitter.com/Smerity/status/1199529360954257408?s=20
{kind=link}
Uber AI Plug and Play Language Model (PPLM)
PPLM allows a user to flexibly plug in one or more simple attribute models representing the desired control objective into a large, unconditional language modeling (LM). The method has the key property that it uses the LM as is – no training or fine-tuning is required – which enables researchers to leverage best-in-class LMs even if they don't have the extensive hardware required to train them.
PPLM lets users combine small attribute models with an LM to steer its generation. Attribute models can be 100k times smaller than the LM and still be effective in steering it
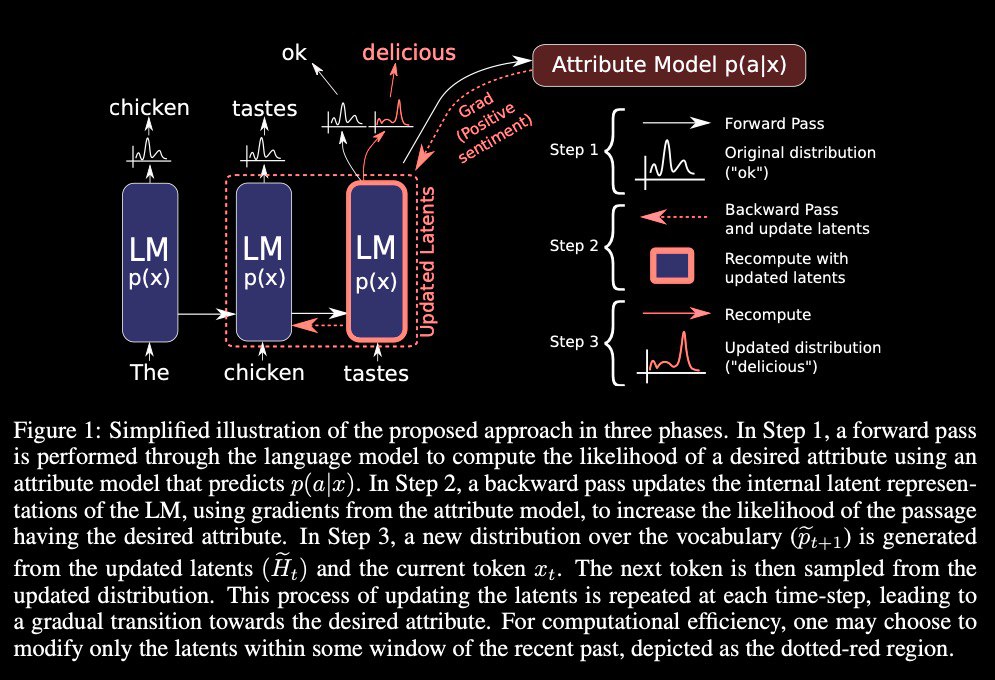
PPLM algorithm entails three simple steps to generate a sample:
* given a partially generated sentence, compute log(p(x)) and log(p(a|x)) and the gradients of each with respect to the hidden representation of the underlying language model. These quantities are both available using an efficient forward and backward pass of both models;
* use the gradients to move the hidden representation of the language model a small step in the direction of increasing log(p(a|x)) and increasing log(p(x));
* sample the next word
more at paper: https://arxiv.org/abs/1912.02164
blogpost: https://eng.uber.com/pplm/
code: https://github.com/uber-research/PPLM
online demo: https://transformer.huggingface.co/model/pplm
#nlp #lm #languagemodeling #uber #pplm
PPLM allows a user to flexibly plug in one or more simple attribute models representing the desired control objective into a large, unconditional language modeling (LM). The method has the key property that it uses the LM as is – no training or fine-tuning is required – which enables researchers to leverage best-in-class LMs even if they don't have the extensive hardware required to train them.
PPLM lets users combine small attribute models with an LM to steer its generation. Attribute models can be 100k times smaller than the LM and still be effective in steering it
PPLM algorithm entails three simple steps to generate a sample:
* given a partially generated sentence, compute log(p(x)) and log(p(a|x)) and the gradients of each with respect to the hidden representation of the underlying language model. These quantities are both available using an efficient forward and backward pass of both models;
* use the gradients to move the hidden representation of the language model a small step in the direction of increasing log(p(a|x)) and increasing log(p(x));
* sample the next word
more at paper: https://arxiv.org/abs/1912.02164
blogpost: https://eng.uber.com/pplm/
code: https://github.com/uber-research/PPLM
online demo: https://transformer.huggingface.co/model/pplm
#nlp #lm #languagemodeling #uber #pplm
{kind=link}