
Cross-Lingual Ability of Multilingual BERT: An Empirical Study to #ICLR2020
In this work, the authors provide a comprehensive study of the contribution of different components in multilingual #BERT (M-BERT) to its cross-lingual ability.
They study the impact of linguistic properties of the languages, the architecture of the model, and the learning objectives. The experimental study is done in the context of three typologically different languages – #Spanish, #Hindi, & #Russian – & using two conceptually different #NLP tasks, textual entailment & #NER.
Also, they construct a new corpus – Fake-English (#enfake), by shifting the Unicode of each character in English Wikipedia text by a large constant so that there is strictly no character overlap with any other Wikipedia text.
And, in this work, they consider Fake-English as a different language.
Among their key conclusions are the fact that the lexical overlap between languages plays a negligible role in the cross-lingual success, while the depth of the network is an integral part of it.
paper: https://arxiv.org/abs/1912.07840
In this work, the authors provide a comprehensive study of the contribution of different components in multilingual #BERT (M-BERT) to its cross-lingual ability.
They study the impact of linguistic properties of the languages, the architecture of the model, and the learning objectives. The experimental study is done in the context of three typologically different languages – #Spanish, #Hindi, & #Russian – & using two conceptually different #NLP tasks, textual entailment & #NER.
Also, they construct a new corpus – Fake-English (#enfake), by shifting the Unicode of each character in English Wikipedia text by a large constant so that there is strictly no character overlap with any other Wikipedia text.
And, in this work, they consider Fake-English as a different language.
Among their key conclusions are the fact that the lexical overlap between languages plays a negligible role in the cross-lingual success, while the depth of the network is an integral part of it.
paper: https://arxiv.org/abs/1912.07840
{kind=link}
Reformer: The Efficient Transformer to #ICLR2020
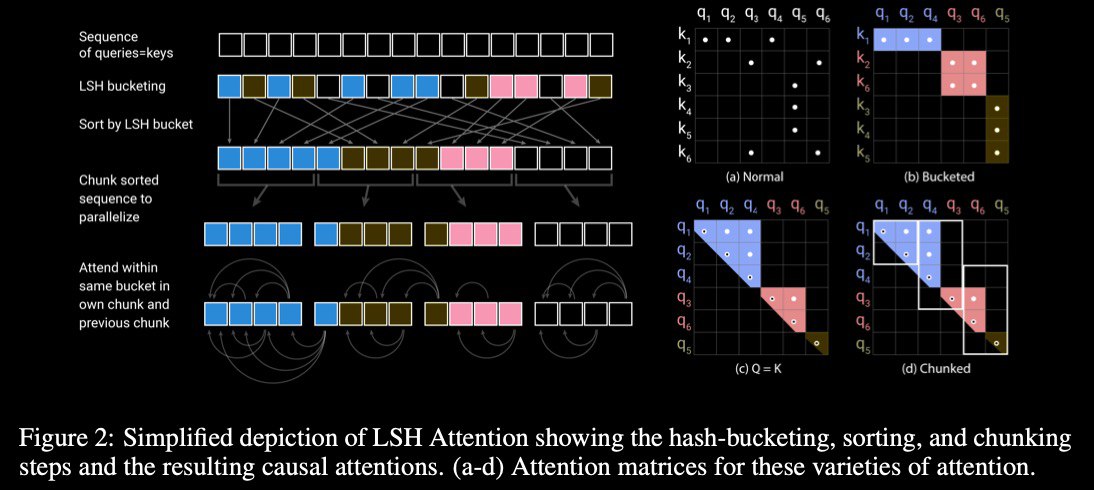
tl;dr: #Reformer is a technical optimization of the original #Transformer, takes up less memory & reads more quickly
propose 3 improvements:
* reversible layers enable storing only a single copy of activations in the whole model, so the N factor disappears (where n – count of layers)
* splitting activations inside feed-forward layers & processing them in chunks removes the dff factor & saves memory inside feed-forward layers
* approximate attention computation based on locality-sensitive hashing (#LSH) replaces the O(L**2) factor in attention layers with O(L*log(L)) & so allows operating on long sequences (where L – sequence size)
Query and Keys in the Transformer can be considered one matrix, not separate.
paper: https://arxiv.org/abs/2001.04451
github: https://github.com/google/trax/tree/master/trax/models/reformer
blog post: https://ai.googleblog.com/2020/01/reformer-efficient-transformer.html
tl;dr: #Reformer is a technical optimization of the original #Transformer, takes up less memory & reads more quickly
propose 3 improvements:
* reversible layers enable storing only a single copy of activations in the whole model, so the N factor disappears (where n – count of layers)
* splitting activations inside feed-forward layers & processing them in chunks removes the dff factor & saves memory inside feed-forward layers
* approximate attention computation based on locality-sensitive hashing (#LSH) replaces the O(L**2) factor in attention layers with O(L*log(L)) & so allows operating on long sequences (where L – sequence size)
Query and Keys in the Transformer can be considered one matrix, not separate.
paper: https://arxiv.org/abs/2001.04451
github: https://github.com/google/trax/tree/master/trax/models/reformer
blog post: https://ai.googleblog.com/2020/01/reformer-efficient-transformer.html
{kind=link}
On Identifiability in Transformers
The authors tried to understanding better transformers from identifiability.
They started by proving that attention weights are non-identifiable when the sequence length is longer than the attention head dimension. Thus, infinitely many attention distributions can lead to the same internal representation and model output. They propose effective attention, a method that improves the interpretability of attention weights by projecting out the null space.
Also, showed that tokens remain largely identifiable through a learned linear transformation followed by the nearest neighbor lookup based on cosine similarity. However, input tokens gradually become less identifiable in later layers.
Presented Hidden Token Attribution, a gradient-based method to quantify information mixing. This method is general and can be used to investigate contextual embeddings in self-attention based models.
paper: https://arxiv.org/abs/1908.04211
#nlp #transformer #interpretability #attention #ICLR2020
The authors tried to understanding better transformers from identifiability.
They started by proving that attention weights are non-identifiable when the sequence length is longer than the attention head dimension. Thus, infinitely many attention distributions can lead to the same internal representation and model output. They propose effective attention, a method that improves the interpretability of attention weights by projecting out the null space.
Also, showed that tokens remain largely identifiable through a learned linear transformation followed by the nearest neighbor lookup based on cosine similarity. However, input tokens gradually become less identifiable in later layers.
Presented Hidden Token Attribution, a gradient-based method to quantify information mixing. This method is general and can be used to investigate contextual embeddings in self-attention based models.
paper: https://arxiv.org/abs/1908.04211
#nlp #transformer #interpretability #attention #ICLR2020
{kind=link}
Survey of machine-learning experimental methods at NeurIPS2019 and ICLR2020
Good thread about what ML scientists do experiments on their papers
twitter: https://twitter.com/deliprao/status/1235697595919421440
report: https://hal.archives-ouvertes.fr/hal-02447823/document
#Survey #NeurIPS #ICLR #Experiments #ml
Good thread about what ML scientists do experiments on their papers
twitter: https://twitter.com/deliprao/status/1235697595919421440
report: https://hal.archives-ouvertes.fr/hal-02447823/document
#Survey #NeurIPS #ICLR #Experiments #ml
Twitter
Delip Rao
Survey of #MachineLearning experimental methods (aka "how do ML folks do their experiments") at #NeurIPS2019 and #ICLR2020, a thread of results:
Recurrent Hierarchical Topic-Guided Neural Language Models
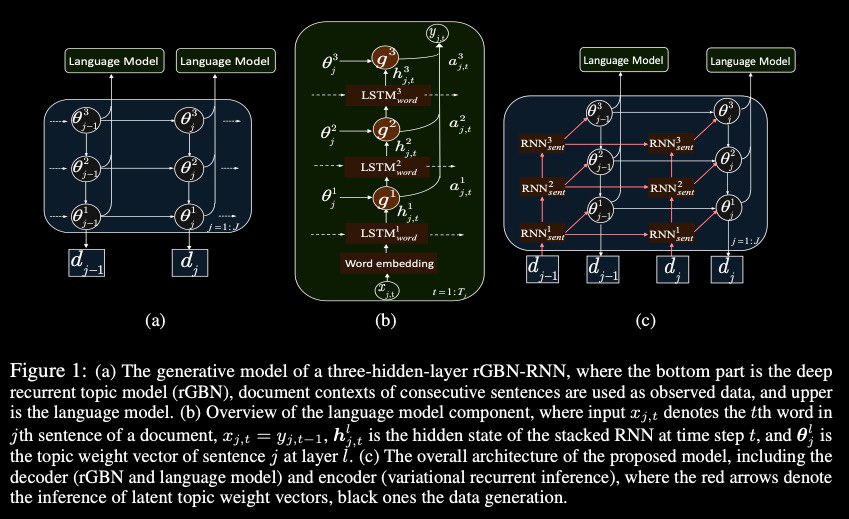
The authors propose a recurrent gamma belief network (rGBN) guided neural language modeling framework, a novel method to learn a language model and a deep recurrent topic model simultaneously.
For scalable inference, they develop hybrid SG-MCMC and recurrent autoencoding variational inference, allowing efficient end-to-end training.
Experiments results conducted on real-world corpora demonstrate that the proposed models outperform a variety of shallow-topic-model-guided neural language models, and effectively generate the sentences from the designated multi-level topics or noise while inferring the interpretable hierarchical latent topic structure of the document and hierarchical multiscale structures of sequences.
paper: https://openreview.net/forum?id=Byl1W1rtvH
#ICLR2020 #nlm #nlg
The authors propose a recurrent gamma belief network (rGBN) guided neural language modeling framework, a novel method to learn a language model and a deep recurrent topic model simultaneously.
For scalable inference, they develop hybrid SG-MCMC and recurrent autoencoding variational inference, allowing efficient end-to-end training.
Experiments results conducted on real-world corpora demonstrate that the proposed models outperform a variety of shallow-topic-model-guided neural language models, and effectively generate the sentences from the designated multi-level topics or noise while inferring the interpretable hierarchical latent topic structure of the document and hierarchical multiscale structures of sequences.
paper: https://openreview.net/forum?id=Byl1W1rtvH
#ICLR2020 #nlm #nlg
{kind=link}