
SAUNet: Shape Attentive U-Net for Interpretable Medical Image Segmentation
New approach for interpreting medical image segmentation models.
U-Net and other image segmentation models work quite well on medical data, but still aren't widely adopted. One of the reasons is the lack of reproducibility as well as robustness issues.
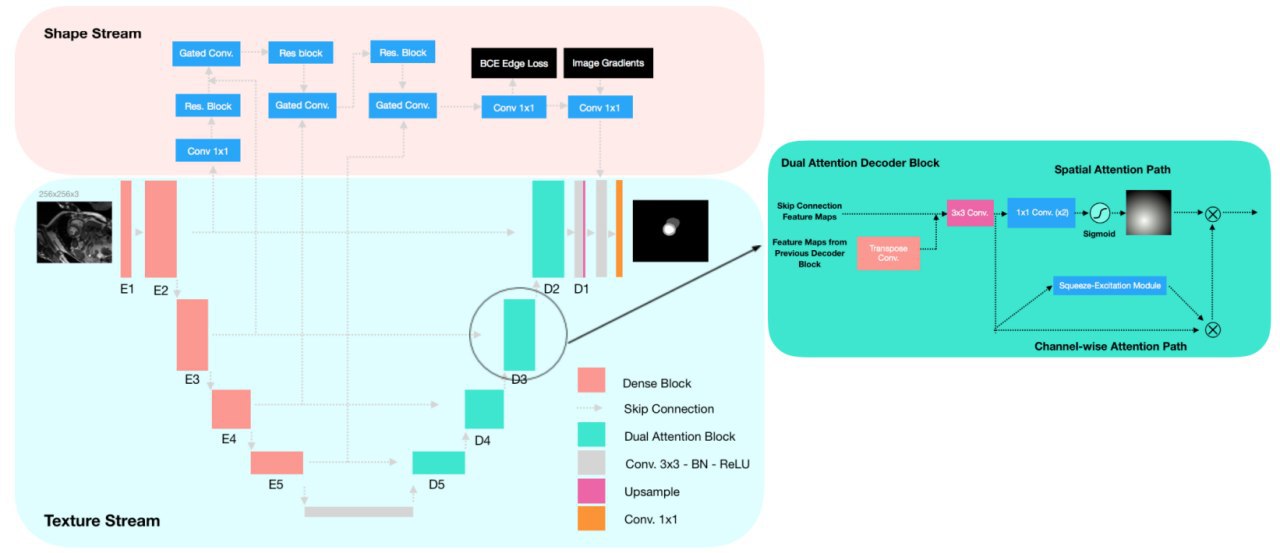
The key idea of the paper is using the additional stream in U-Net with shape features to increase robustness and use the output of this stream (attention map) that can be used or interpretability.
Modifications to the basic U-Net architecture:
- use dense blocks from DenseNet-121 as the encoder.
- use dual attention decoder block (with spatial and channel-wise attention paths)
- make the second stream using object shape (contour)
- dual-task loss function: cross-entropy + dice + edge loss (bce loss of the predicted shape boundaries)
Shape and spatial attention maps can be used for interpretation.
Paper: https://arxiv.org/abs/2001.07645
Code: https://github.com/sunjesse/shape-attentive-unet
#unet #imagesegmentation #interpretability #segmentation
New approach for interpreting medical image segmentation models.
U-Net and other image segmentation models work quite well on medical data, but still aren't widely adopted. One of the reasons is the lack of reproducibility as well as robustness issues.
The key idea of the paper is using the additional stream in U-Net with shape features to increase robustness and use the output of this stream (attention map) that can be used or interpretability.
Modifications to the basic U-Net architecture:
- use dense blocks from DenseNet-121 as the encoder.
- use dual attention decoder block (with spatial and channel-wise attention paths)
- make the second stream using object shape (contour)
- dual-task loss function: cross-entropy + dice + edge loss (bce loss of the predicted shape boundaries)
Shape and spatial attention maps can be used for interpretation.
Paper: https://arxiv.org/abs/2001.07645
Code: https://github.com/sunjesse/shape-attentive-unet
#unet #imagesegmentation #interpretability #segmentation
{kind=link}
On Identifiability in Transformers
The authors tried to understanding better transformers from identifiability.
They started by proving that attention weights are non-identifiable when the sequence length is longer than the attention head dimension. Thus, infinitely many attention distributions can lead to the same internal representation and model output. They propose effective attention, a method that improves the interpretability of attention weights by projecting out the null space.
Also, showed that tokens remain largely identifiable through a learned linear transformation followed by the nearest neighbor lookup based on cosine similarity. However, input tokens gradually become less identifiable in later layers.
Presented Hidden Token Attribution, a gradient-based method to quantify information mixing. This method is general and can be used to investigate contextual embeddings in self-attention based models.
paper: https://arxiv.org/abs/1908.04211
#nlp #transformer #interpretability #attention #ICLR2020
The authors tried to understanding better transformers from identifiability.
They started by proving that attention weights are non-identifiable when the sequence length is longer than the attention head dimension. Thus, infinitely many attention distributions can lead to the same internal representation and model output. They propose effective attention, a method that improves the interpretability of attention weights by projecting out the null space.
Also, showed that tokens remain largely identifiable through a learned linear transformation followed by the nearest neighbor lookup based on cosine similarity. However, input tokens gradually become less identifiable in later layers.
Presented Hidden Token Attribution, a gradient-based method to quantify information mixing. This method is general and can be used to investigate contextual embeddings in self-attention based models.
paper: https://arxiv.org/abs/1908.04211
#nlp #transformer #interpretability #attention #ICLR2020
{kind=link}