
Reformer: The Efficient Transformer to #ICLR2020
tl;dr: #Reformer is a technical optimization of the original #Transformer, takes up less memory & reads more quickly
propose 3 improvements:
* reversible layers enable storing only a single copy of activations in the whole model, so the N factor disappears (where n – count of layers)
* splitting activations inside feed-forward layers & processing them in chunks removes the dff factor & saves memory inside feed-forward layers
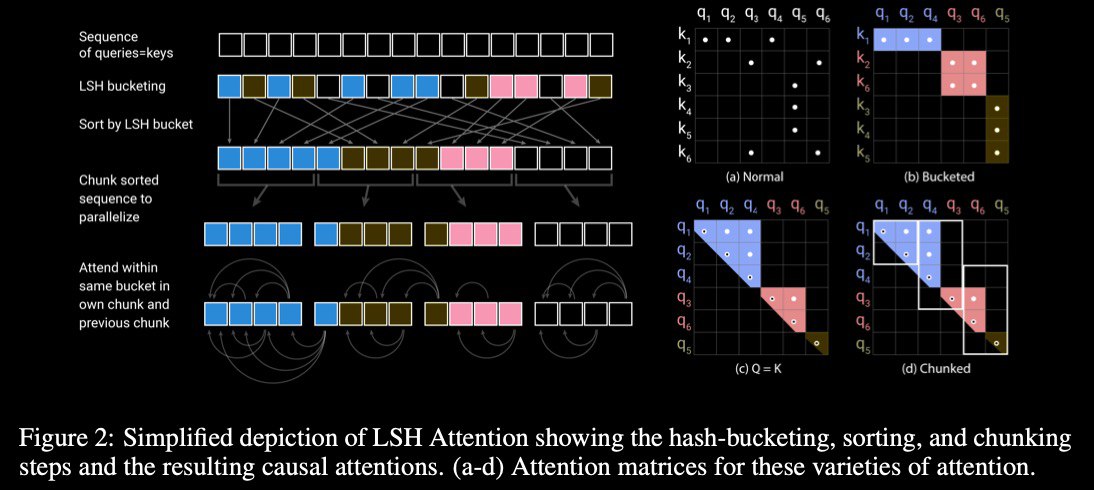
* approximate attention computation based on locality-sensitive hashing (#LSH) replaces the O(L**2) factor in attention layers with O(L*log(L)) & so allows operating on long sequences (where L – sequence size)
Query and Keys in the Transformer can be considered one matrix, not separate.
paper: https://arxiv.org/abs/2001.04451
github: https://github.com/google/trax/tree/master/trax/models/reformer
blog post: https://ai.googleblog.com/2020/01/reformer-efficient-transformer.html
tl;dr: #Reformer is a technical optimization of the original #Transformer, takes up less memory & reads more quickly
propose 3 improvements:
* reversible layers enable storing only a single copy of activations in the whole model, so the N factor disappears (where n – count of layers)
* splitting activations inside feed-forward layers & processing them in chunks removes the dff factor & saves memory inside feed-forward layers
* approximate attention computation based on locality-sensitive hashing (#LSH) replaces the O(L**2) factor in attention layers with O(L*log(L)) & so allows operating on long sequences (where L – sequence size)
Query and Keys in the Transformer can be considered one matrix, not separate.
paper: https://arxiv.org/abs/2001.04451
github: https://github.com/google/trax/tree/master/trax/models/reformer
blog post: https://ai.googleblog.com/2020/01/reformer-efficient-transformer.html
{kind=link}
The Reformer – Pushing the limits of language modeling
Patrick von Platen @ huggingface
The Reformer model was introduced by Kitaev, Kaiser et al. `20 – it is one of the most memory-efficient transformer models for long sequence modeling as of today.
The goal of this blog post is to give an in-depth understanding of each of the next four Reformer features:
[0] reformer self-attention layer – how to efficiently implement self-attention without being restricted to a local context?
[1] chunked feed forward layers – how to get a better time-memory trade-off for large feed forward layers?
[2] reversible residual layers – how to drastically reduce memory consumption in training by a smart residual architecture?
[3] axial positional encodings – how to make positional encodings usable for extremely large input sequences?
This long blog post can better allow you to understand how the model works to correctly set configurations
blog post: https://huggingface.co/blog/reformer
#nlp #reformer #huggingface #transformers
Patrick von Platen @ huggingface
The Reformer model was introduced by Kitaev, Kaiser et al. `20 – it is one of the most memory-efficient transformer models for long sequence modeling as of today.
The goal of this blog post is to give an in-depth understanding of each of the next four Reformer features:
[0] reformer self-attention layer – how to efficiently implement self-attention without being restricted to a local context?
[1] chunked feed forward layers – how to get a better time-memory trade-off for large feed forward layers?
[2] reversible residual layers – how to drastically reduce memory consumption in training by a smart residual architecture?
[3] axial positional encodings – how to make positional encodings usable for extremely large input sequences?
This long blog post can better allow you to understand how the model works to correctly set configurations
blog post: https://huggingface.co/blog/reformer
#nlp #reformer #huggingface #transformers
huggingface.co
The Reformer - Pushing the limits of language modeling
We’re on a journey to advance and democratize artificial intelligence through open source and open science.