
spaCy meets PyTorch-Transformers: Fine-tune BERT, XLNet and GPT-2
Including pretrained models.
Link: https://explosion.ai/blog/spacy-pytorch-transformers
Pip:
#Transformers #SpaCy #NLP #NLU #PyTorch #Bert #XLNet #GPT
Including pretrained models.
Link: https://explosion.ai/blog/spacy-pytorch-transformers
Pip:
pip install spacy-pytorch-transformers#Transformers #SpaCy #NLP #NLU #PyTorch #Bert #XLNet #GPT
explosion.ai
spaCy meets Transformers: Fine-tune BERT, XLNet and GPT-2 · Explosion
Huge transformer models like BERT, GPT-2 and XLNet have set a new standard for accuracy on almost every NLP leaderboard. You can now use these models in spaCy, via a new interface library we've developed that connects spaCy to Hugging Face's awesome implementations.
Encoder-decoders in Transformers: a hybrid pre-trained architecture for seq2seq
by huggingface
In this post briefly goes through the (modern) history of #transformers and the comeback of the encoder-decoder architecture.
The author walk through the implementation of encoder-decoders in the transformers library, show you can use them for your projects, and give you a taste of what is coming in the next releases.
Blog: https://medium.com/huggingface/encoder-decoders-in-transformers-a-hybrid-pre-trained-architecture-for-seq2seq-af4d7bf14bb8
by huggingface
In this post briefly goes through the (modern) history of #transformers and the comeback of the encoder-decoder architecture.
The author walk through the implementation of encoder-decoders in the transformers library, show you can use them for your projects, and give you a taste of what is coming in the next releases.
Blog: https://medium.com/huggingface/encoder-decoders-in-transformers-a-hybrid-pre-trained-architecture-for-seq2seq-af4d7bf14bb8
Data Science by ODS.ai 🦜
YouTokenToMe, new tool for text tokenisation from VK team Meet new enhanced tokenisation tool on steroids. Works 7-10 times faster alphabetic languages and 40 to 50 times faster on logographic languages, than alternatives. Under the hood (watch source)…
New rust tokenization library from #HuggingFace
Tokenization is a process of converting strings in model input tensors. Library provides BPE/Byte-Level-BPE/WordPiece/SentencePiece tokenization, computes exhaustive set of outputs (offset mappings, attention masks, special token masks).
Library has python and node.js bindings.
The quoted post contains information on another fast #tokenization implementation. Looking forward for speed comparison.
Install:
Github: https://github.com/huggingface/tokenizers/tree/master/tokenizers
#NLU #NLP #Transformers #Rust #NotOnlyPython
Tokenization is a process of converting strings in model input tensors. Library provides BPE/Byte-Level-BPE/WordPiece/SentencePiece tokenization, computes exhaustive set of outputs (offset mappings, attention masks, special token masks).
Library has python and node.js bindings.
The quoted post contains information on another fast #tokenization implementation. Looking forward for speed comparison.
Install:
pip install tokenizersGithub: https://github.com/huggingface/tokenizers/tree/master/tokenizers
#NLU #NLP #Transformers #Rust #NotOnlyPython
GitHub
tokenizers/tokenizers at main · huggingface/tokenizers
💥 Fast State-of-the-Art Tokenizers optimized for Research and Production - huggingface/tokenizers
#DeepPavlov & #transformers
and now at 🤗 you can also use the next models:
-
-
-
-
-
-
page: https://huggingface.co/DeepPavlov
colab tutorial: here
and now at 🤗 you can also use the next models:
-
DeepPavlov/bert-base-bg-cs-pl-ru-cased-
DeepPavlov/bert-base-cased-conversational-
DeepPavlov/bert-base-multilingual-cased-sentence-
DeepPavlov/rubert-base-cased-conversational-
DeepPavlov/rubert-base-cased-sentence-
DeepPavlov/rubert-base-casedpage: https://huggingface.co/DeepPavlov
colab tutorial: here
{kind=link}
How to generate text: using different decoding methods for language generation with Transformers
by huggingface
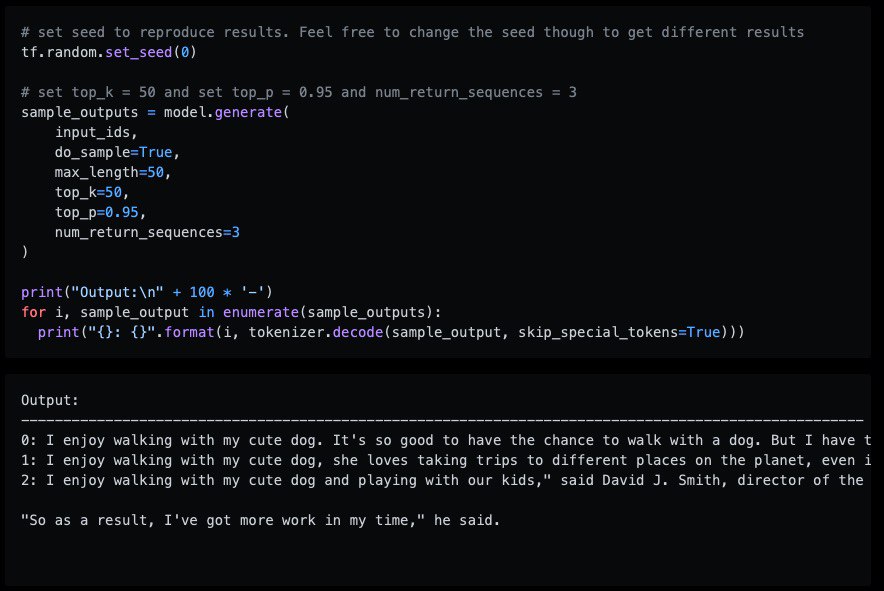
in this blog, the author talk about how to generate text and compared some approaches like:
– greedy search
– beam search
– top-K sampling
– top-p (nucleus) sampling
blog post: https://huggingface.co/blog/how-to-generate
#nlp #nlg #transformers
by huggingface
in this blog, the author talk about how to generate text and compared some approaches like:
– greedy search
– beam search
– top-K sampling
– top-p (nucleus) sampling
blog post: https://huggingface.co/blog/how-to-generate
#nlp #nlg #transformers
{kind=link}
The Reformer – Pushing the limits of language modeling
Patrick von Platen @ huggingface
The Reformer model was introduced by Kitaev, Kaiser et al. `20 – it is one of the most memory-efficient transformer models for long sequence modeling as of today.
The goal of this blog post is to give an in-depth understanding of each of the next four Reformer features:
[0] reformer self-attention layer – how to efficiently implement self-attention without being restricted to a local context?
[1] chunked feed forward layers – how to get a better time-memory trade-off for large feed forward layers?
[2] reversible residual layers – how to drastically reduce memory consumption in training by a smart residual architecture?
[3] axial positional encodings – how to make positional encodings usable for extremely large input sequences?
This long blog post can better allow you to understand how the model works to correctly set configurations
blog post: https://huggingface.co/blog/reformer
#nlp #reformer #huggingface #transformers
Patrick von Platen @ huggingface
The Reformer model was introduced by Kitaev, Kaiser et al. `20 – it is one of the most memory-efficient transformer models for long sequence modeling as of today.
The goal of this blog post is to give an in-depth understanding of each of the next four Reformer features:
[0] reformer self-attention layer – how to efficiently implement self-attention without being restricted to a local context?
[1] chunked feed forward layers – how to get a better time-memory trade-off for large feed forward layers?
[2] reversible residual layers – how to drastically reduce memory consumption in training by a smart residual architecture?
[3] axial positional encodings – how to make positional encodings usable for extremely large input sequences?
This long blog post can better allow you to understand how the model works to correctly set configurations
blog post: https://huggingface.co/blog/reformer
#nlp #reformer #huggingface #transformers
huggingface.co
The Reformer - Pushing the limits of language modeling
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
how gpt3 works. a visual thread
short thread with cool animations how gpt-3 works by jay alammar
collected twitter thread: https://threader.app/thread/1285498971960598529
#nlp #transformers #gpt3 #jayalammar
short thread with cool animations how gpt-3 works by jay alammar
collected twitter thread: https://threader.app/thread/1285498971960598529
#nlp #transformers #gpt3 #jayalammar
Language-agnostic BERT Sentence Embedding
Authors adopt multilingual BERT to produce language-agnostic sentence embeddings for 109 languages.
The model combines a masked language model (MLM) and a translation language model (TLM) pretraining with a translation ranking task using bi-directional dual encoders.
The resulting multilingual sentence embeddings improve average bi-text retrieval accuracy over 112 languages to 83.7% on Tatoeba (previous state-of-the-art was 65.5%)
blogpost: https://ai.googleblog.com/2020/08/language-agnostic-bert-sentence.html
paper: https://arxiv.org/abs/2007.01852
bodel on tf hub: https://tfhub.dev/google/LaBSE/1
#deeplearning #transformers #nlp #tensorflow #sentenceembeddings
Authors adopt multilingual BERT to produce language-agnostic sentence embeddings for 109 languages.
The model combines a masked language model (MLM) and a translation language model (TLM) pretraining with a translation ranking task using bi-directional dual encoders.
The resulting multilingual sentence embeddings improve average bi-text retrieval accuracy over 112 languages to 83.7% on Tatoeba (previous state-of-the-art was 65.5%)
blogpost: https://ai.googleblog.com/2020/08/language-agnostic-bert-sentence.html
paper: https://arxiv.org/abs/2007.01852
bodel on tf hub: https://tfhub.dev/google/LaBSE/1
#deeplearning #transformers #nlp #tensorflow #sentenceembeddings
{kind=link}