
Simple/limited/incomplete benchmark for scalability, speed and accuracy of machine learning libraries for classification.
https://github.com/szilard/benchm-ml
#github #opensource #worthspreading
https://github.com/szilard/benchm-ml
#github #opensource #worthspreading
GitHub
GitHub - szilard/benchm-ml: A minimal benchmark for scalability, speed and accuracy of commonly used open source implementations…
A minimal benchmark for scalability, speed and accuracy of commonly used open source implementations (R packages, Python scikit-learn, H2O, xgboost, Spark MLlib etc.) of the top machine learning al...
Russian Search Engine has opened sources of the CatBoost — library which claims to be replacement of Yandex’s famous MatrixNet. Researches claim that CatBoost results are comparable with XGboost.
https://techcrunch.com/2017/07/18/yandex-open-sources-catboost-a-gradient-boosting-machine-learning-librar/
#opensource #yandex #xgboost #catboost
https://techcrunch.com/2017/07/18/yandex-open-sources-catboost-a-gradient-boosting-machine-learning-librar/
#opensource #yandex #xgboost #catboost
TechCrunch
Yandex open sources CatBoost, a gradient boosting machine learning library
Artificial intelligence is now powering a growing number of computing functions, and today the developer community today is getting another AI boost, courtesy of Yandex. Today, the Russian search giant — which, like its US counterpart Google, has extended…
Google's open source candy for all ML community:
Source-to-Source Debuggable Derivatives
https://opensource.googleblog.com/2017/11/tangent-source-to-source-debuggable.html?m=1
#opensource #nn #python #google
Source-to-Source Debuggable Derivatives
https://opensource.googleblog.com/2017/11/tangent-source-to-source-debuggable.html?m=1
#opensource #nn #python #google
Google Open Source Blog
Tangent: Source-to-Source Debuggable Derivatives
Microsoft Research announced Open Data project! This single, cloud-hosted location offers datasets representing many years of data curation and research efforts by Microsoft.
https://www.microsoft.com/en-us/research/blog/announcing-microsoft-research-open-data-datasets-by-microsoft-research-now-available-in-the-cloud/
#data #microsoft #opensource
https://www.microsoft.com/en-us/research/blog/announcing-microsoft-research-open-data-datasets-by-microsoft-research-now-available-in-the-cloud/
#data #microsoft #opensource
Microsoft Research
Announcing Microsoft Research Open Data - Datasets by Microsoft Research now available in the cloud - Microsoft Research
The Microsoft Research Outreach team has worked extensively with the external research community to enable adoption of cloud-based research infrastructure over the past few years. Through this process, we experienced the ubiquity of Jim Gray’s fourth paradigm…
Google’s open source Active Question Reformulation with Reinforcement Learning
Project: https://ai.googleblog.com/2018/10/open-sourcing-active-question.html
Github: https://github.com/google/active-qa
Publication: https://ai.google/research/pubs/pub46733
#nlp #qa #google #opensource
Project: https://ai.googleblog.com/2018/10/open-sourcing-active-question.html
Github: https://github.com/google/active-qa
Publication: https://ai.google/research/pubs/pub46733
#nlp #qa #google #opensource
Googleblog
Open Sourcing Active Question Reformulation with Reinforcement Learning
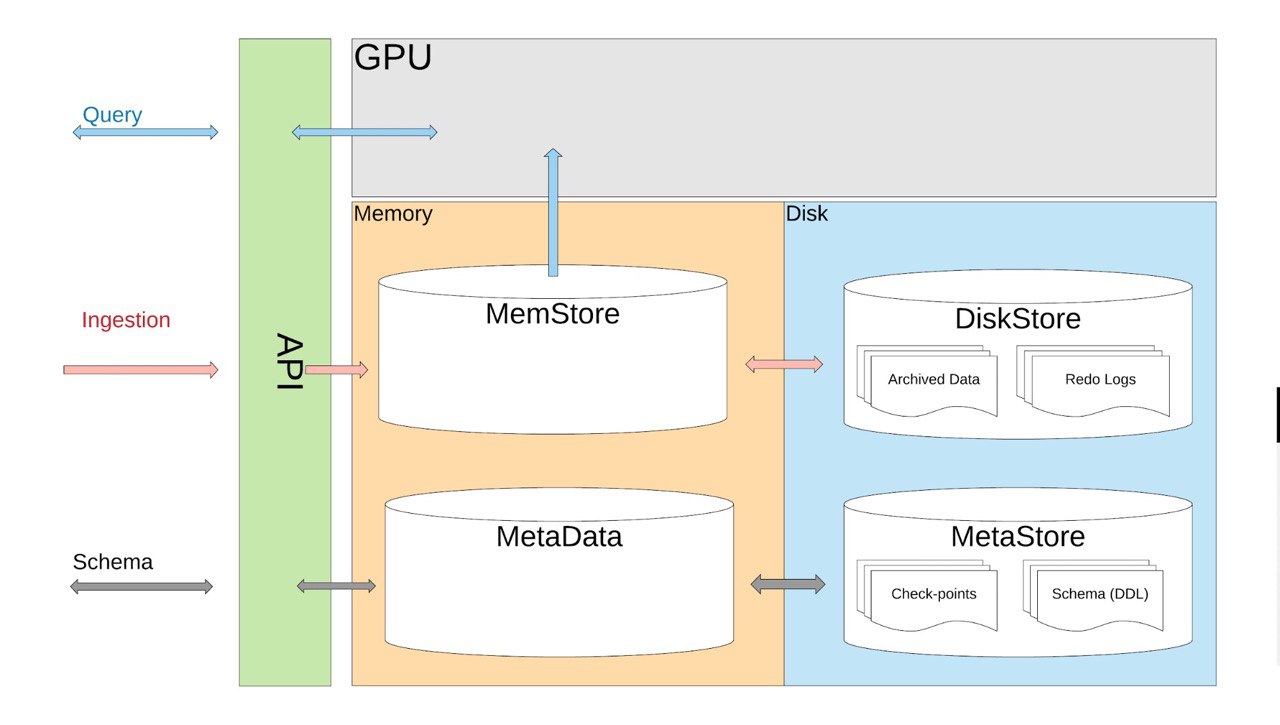
Introducing AresDB: Uber’s GPU-Powered Open Source, Real-time Analytics Engine
Link: https://eng.uber.com/aresdb/
#Uber #analytics #opensource
Link: https://eng.uber.com/aresdb/
#Uber #analytics #opensource
{kind=link}
Intro to Pythia — Visual Question Answering framework from Facebook
Pythia works in terms of #VQA by taking input picture and question and providing the answer to the latter in terms of picture semantics.
Link: https://link.medium.com/dknDKSuVqX
Previously: https://t.me/opendatascience/812
#DL #facebook #pythia #VQA #opensource
Pythia works in terms of #VQA by taking input picture and question and providing the answer to the latter in terms of picture semantics.
Link: https://link.medium.com/dknDKSuVqX
Previously: https://t.me/opendatascience/812
#DL #facebook #pythia #VQA #opensource
Medium
Pythia (Facebook) — Greek god doing Deep learning
“Artificial Intelligence” in 2019 has been exciting, Can it be more exciting than this? Guess what I found an answer for it and the answer…
Release of 27 pretrained models for NLP / NLU for PyTorch
Hugging Face open sources a new library that contains up to 27 pretrained models to conduct state-of-the-art NLP/NLU tasks.
Link: https://medium.com/dair-ai/pytorch-transformers-for-state-of-the-art-nlp-3348911ffa5b
#SOTA #NLP #NLU #PyTorch #opensource
Hugging Face open sources a new library that contains up to 27 pretrained models to conduct state-of-the-art NLP/NLU tasks.
Link: https://medium.com/dair-ai/pytorch-transformers-for-state-of-the-art-nlp-3348911ffa5b
#SOTA #NLP #NLU #PyTorch #opensource
{kind=link}
PyTorch for research
PyTorch Lightning — The PyTorch Keras for ML researchers. More control. Less boilerplate.
Github: https://github.com/williamFalcon/pytorch-lightning
#PyTorch #Research #OpenSource
PyTorch Lightning — The PyTorch Keras for ML researchers. More control. Less boilerplate.
Github: https://github.com/williamFalcon/pytorch-lightning
#PyTorch #Research #OpenSource
GitHub
GitHub - Lightning-AI/pytorch-lightning: Pretrain, finetune and deploy AI models on multiple GPUs, TPUs with zero code changes.
Pretrain, finetune and deploy AI models on multiple GPUs, TPUs with zero code changes. - Lightning-AI/pytorch-lightning
Open-source library provides explanation for machine learning through diverse counterfactuals
This is a development of #interpretable ML. Library to explore “what-if” scenarios for ML models.
Blog post: https://www.microsoft.com/en-us/research/blog/open-source-library-provides-explanation-for-machine-learning-through-diverse-counterfactuals/
Paper: https://www.microsoft.com/en-us/research/publication/explaining-machine-learning-classifiers-through-diverse-counterfactual-examples/
Github: https://github.com/microsoft/dice
#Microsoft #ML #opensource
This is a development of #interpretable ML. Library to explore “what-if” scenarios for ML models.
Blog post: https://www.microsoft.com/en-us/research/blog/open-source-library-provides-explanation-for-machine-learning-through-diverse-counterfactuals/
Paper: https://www.microsoft.com/en-us/research/publication/explaining-machine-learning-classifiers-through-diverse-counterfactual-examples/
Github: https://github.com/microsoft/dice
#Microsoft #ML #opensource
Microsoft Research
DiCE: Employing counterfactuals to explain machine learning algorithms
Microsoft researchers & collaborators created an open-source library to explore “what-if” scenarios for machine learning models. Learn how their method generates multiple diverse counterfactuals at once & gives insight into ML algorithm decision making.
HiPlot: High-dimensional interactive plots made easy
Interactive parameters' performance #visualization tool. This new Facebook AI's release enables researchers to more easily evaluate the influence of their hyperparameters, such as learning rate, regularizations, and architecture.
Link: https://ai.facebook.com/blog/hiplot-high-dimensional-interactive-plots-made-easy
Github: https://github.com/facebookresearch/hiplot
Demo: https://facebookresearch.github.io/hiplot/_static/demo/demo_basic_usage.html
Pip:
#hyperopt #facebook #opensource
Interactive parameters' performance #visualization tool. This new Facebook AI's release enables researchers to more easily evaluate the influence of their hyperparameters, such as learning rate, regularizations, and architecture.
Link: https://ai.facebook.com/blog/hiplot-high-dimensional-interactive-plots-made-easy
Github: https://github.com/facebookresearch/hiplot
Demo: https://facebookresearch.github.io/hiplot/_static/demo/demo_basic_usage.html
Pip:
pip install hiplot#hyperopt #facebook #opensource
Data Science by ODS.ai 🦜
☺️526 responses collected thanks to you! Now we are looking for a volunteer to perform an #exploratory analysis of responses an publish it as a an example on github in a form of #jupyter notebook. If you are familiar with git, jupyter, basics of #exploratory…
Our channel audience data
On 9th of February we announced that we are going to share the results of the audience research with you. And here is the release. Please feel free to open issues, suggest improvements or corrections and submit pull requests.
Stay tuned for further releases, we are going to develop concept of Ultimate posts in the form of updated github repositories, containing all the best information, insights and materials on various topics.
Project github pages site: https://open-data-science.github.io/ods_channel_stats_eda/
Github: https://github.com/open-data-science/ods_channel_stats_eda
Non-verbous audience stats: https://open-data-science.github.io/ods_channel_stats_eda/research_eda_concise_version.html
#audience #eda #opensource #introspect
On 9th of February we announced that we are going to share the results of the audience research with you. And here is the release. Please feel free to open issues, suggest improvements or corrections and submit pull requests.
Stay tuned for further releases, we are going to develop concept of Ultimate posts in the form of updated github repositories, containing all the best information, insights and materials on various topics.
Project github pages site: https://open-data-science.github.io/ods_channel_stats_eda/
Github: https://github.com/open-data-science/ods_channel_stats_eda
Non-verbous audience stats: https://open-data-science.github.io/ods_channel_stats_eda/research_eda_concise_version.html
#audience #eda #opensource #introspect
GitHub
GitHub - open-data-science/ods_channel_stats_eda: Public analysis of ODS Channel questionnaire statistics
Public analysis of ODS Channel questionnaire statistics - GitHub - open-data-science/ods_channel_stats_eda: Public analysis of ODS Channel questionnaire statistics
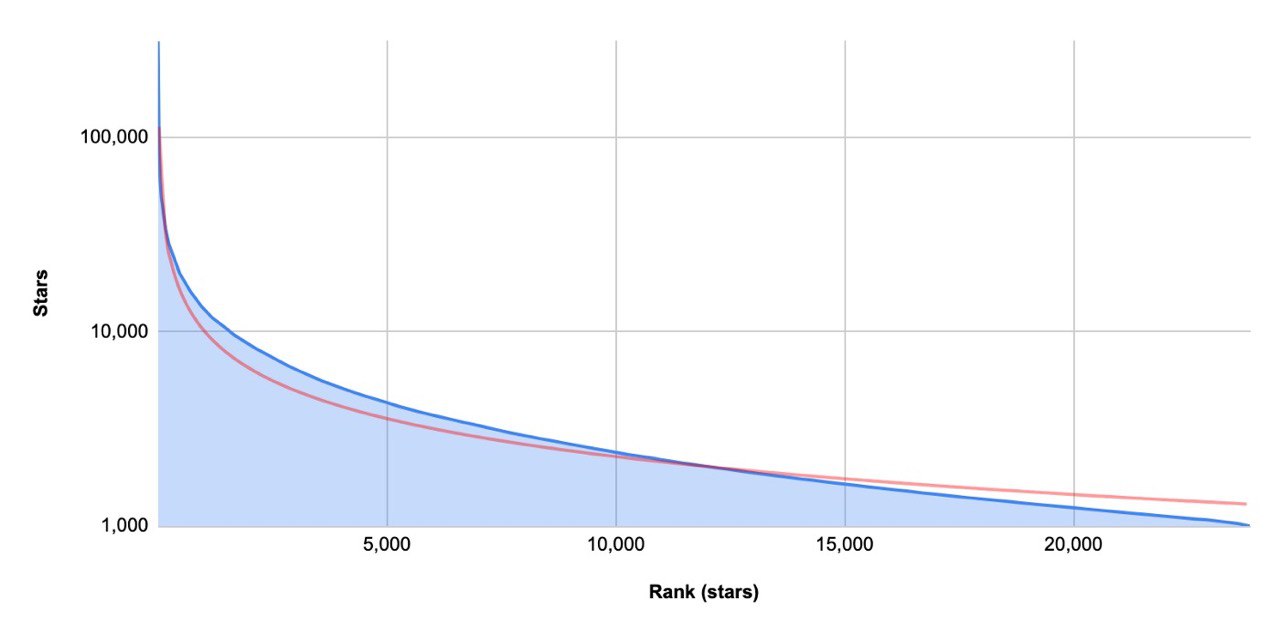
Overview of Open Source projects growth metrics
Quantative analytics of top starred repositories.
Link: https://medium.com/runacapital/open-source-growth-benchmarks-and-the-20-fastest-growing-oss-startups-d3556a669fe6
#opensource #analytics #statistics #growth
Quantative analytics of top starred repositories.
Link: https://medium.com/runacapital/open-source-growth-benchmarks-and-the-20-fastest-growing-oss-startups-d3556a669fe6
#opensource #analytics #statistics #growth
{kind=link}
Ultimate post on where to start learning DS
Most common request we received through the years was to share insights and advices on how to start career in data science and to recommend decent cources. Apparently, using hashtag #wheretostart wasn't enough so we were sharing some general advices.
So we assembled a through guide on how to start learning machine learning and created another #ultimatepost (in a form of a github repo, so it will be keep updated and anyone can submit worthy piece of advice to it).
We welcome you to share your stories and advices on how to start rolling into data science, as well as to spread the link to the repo to those your friends who might benefit from it.
Link: Ultimate post
#entrylevel #beginner #junior #MOOC #learndatascience #courses #mlcourse #opensource
Most common request we received through the years was to share insights and advices on how to start career in data science and to recommend decent cources. Apparently, using hashtag #wheretostart wasn't enough so we were sharing some general advices.
So we assembled a through guide on how to start learning machine learning and created another #ultimatepost (in a form of a github repo, so it will be keep updated and anyone can submit worthy piece of advice to it).
We welcome you to share your stories and advices on how to start rolling into data science, as well as to spread the link to the repo to those your friends who might benefit from it.
Link: Ultimate post
#entrylevel #beginner #junior #MOOC #learndatascience #courses #mlcourse #opensource
{kind=link}
Open Software Packaging for Science
#opensource alternative to #conda.
Mamba (drop-in replacement) direct link: https://github.com/TheSnakePit/mamba
Link: https://medium.com/@QuantStack/open-software-packaging-for-science-61cecee7fc23
#python #packagemanagement
#opensource alternative to #conda.
Mamba (drop-in replacement) direct link: https://github.com/TheSnakePit/mamba
Link: https://medium.com/@QuantStack/open-software-packaging-for-science-61cecee7fc23
#python #packagemanagement
GitHub
GitHub - mamba-org/mamba: The Fast Cross-Platform Package Manager
The Fast Cross-Platform Package Manager. Contribute to mamba-org/mamba development by creating an account on GitHub.
Data Science by ODS.ai 🦜
Ultimate post on where to start learning DS Most common request we received through the years was to share insights and advices on how to start career in data science and to recommend decent cources. Apparently, using hashtag #wheretostart wasn't enough…
Hands on ML notebook series
Updated our ultimate post with a series of Jupyter notebooks that walk you through the fundamentals of Machine Learning and Deep Learning in python using Scikit-Learn and TensorFlow.
Link: https://github.com/ageron/handson-ml
#wheretostart #opensource #jupyter
Updated our ultimate post with a series of Jupyter notebooks that walk you through the fundamentals of Machine Learning and Deep Learning in python using Scikit-Learn and TensorFlow.
Link: https://github.com/ageron/handson-ml
#wheretostart #opensource #jupyter
GitHub
GitHub - ageron/handson-ml: ⛔️ DEPRECATED – See https://github.com/ageron/handson-ml3 instead.
⛔️ DEPRECATED – See https://github.com/ageron/handson-ml3 instead. - ageron/handson-ml
🦜 Hi!
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
We are the first Telegram Data Science channel.
Channel was started as a collection of notable papers, news and releases shared for the members of Open Data Science (ODS) community. Through the years of just keeping the thing going we grew to an independent online Media supporting principles of Free and Open access to the information related to Data Science.
Ultimate Posts
* Where to start learning more about Data Science. https://github.com/open-data-science/ultimate_posts/tree/master/where_to_start
* @opendatascience channel audience research. https://github.com/open-data-science/ods_channel_stats_eda
Open Data Science
ODS.ai is an international community of people anyhow related to Data Science.
Website: https://ods.ai
Hashtags
Through the years we accumulated a big collection of materials, most of them accompanied by hashtags.
#deeplearning #DL — post about deep neural networks (> 1 layer)
#cv — posts related to Computer Vision. Pictures and videos
#nlp #nlu — Natural Language Processing and Natural Language Understanding. Texts and sequences
#audiolearning #speechrecognition — related to audio information processing
#ar — augmeneted reality related content
#rl — Reinforcement Learning (agents, bots and neural networks capable of playing games)
#gan #generation #generatinveart #neuralart — about neural artt and image generation
#transformer #vqgan #vae #bert #clip #StyleGAN2 #Unet #resnet #keras #Pytorch #GPT3 #GPT2 — related to special architectures or frameworks
#coding #CS — content related to software engineering sphere
#OpenAI #microsoft #Github #DeepMind #Yandex #Google #Facebook #huggingface — hashtags related to certain companies
#productionml #sota #recommendation #embeddings #selfdriving #dataset #opensource #analytics #statistics #attention #machine #translation #visualization
Chats
- Data Science Chat https://t.me/datascience_chat
- ODS Slack through invite form at website
ODS resources
* Main website: https://ods.ai
* ODS Community Telegram Channel (in Russian): @ods_ru
* ML trainings Telegram Channel: @mltrainings
* ODS Community Twitter: https://twitter.com/ods_ai
Feedback and Contacts
You are welcome to reach administration through telegram bot: @opendatasciencebot
GitHub
ultimate_posts/where_to_start at master · open-data-science/ultimate_posts
Ultimate posts for opendatascience telegram channel - open-data-science/ultimate_posts
Hi, our friends @mike0sv and @agusch1n just open-sourced MLEM - a tool that helps you deploy your ML models as part of the DVC ecosystem
It’s a Python library + Command line tool.
TLDR:
📦 MLEM can package an ML model into a Docker image or a Python package, and deploy it to Heroku (we made them promise to add SageMaker, K8s and Seldon-core soon :parrot:).
⚙️ MLEM saves all model metadata to a human-readable text file: Python environment, model methods, model input & output data schema and more.
💅 MLEM helps you turn your Git repository into a Model Registry with features like ML model lifecycle management.
Read more in release blogpost: https://dvc.org/blog/MLEM-release
Also, check out the project: https://github.com/iterative/mlem
And the website: https://mlem.ai
Guys are happy to hear your feedback, discuss how this could be helpful for you, how MLEM compares to MLflow, etc.
Ask in the comments!
#mlops #opensource #deployment #dvc
It’s a Python library + Command line tool.
TLDR:
📦 MLEM can package an ML model into a Docker image or a Python package, and deploy it to Heroku (we made them promise to add SageMaker, K8s and Seldon-core soon :parrot:).
⚙️ MLEM saves all model metadata to a human-readable text file: Python environment, model methods, model input & output data schema and more.
💅 MLEM helps you turn your Git repository into a Model Registry with features like ML model lifecycle management.
Read more in release blogpost: https://dvc.org/blog/MLEM-release
Also, check out the project: https://github.com/iterative/mlem
And the website: https://mlem.ai
Guys are happy to hear your feedback, discuss how this could be helpful for you, how MLEM compares to MLflow, etc.
Ask in the comments!
#mlops #opensource #deployment #dvc
Forwarded from DataGym Channel [Power of data]
#opensource : RuLeanALBERT от Yandex Research
2.9B трансформер для русского, которая влезет в домашнюю ПеКарню ресерчера
Мало того, что это самая большая БЕРТ-подобная модель для русского языка, которая показывает крутые результаты в бенчмарках, так еще и с кодом для fine-tuning-а
GitHub
А в статье можете узнать, как обучалась эта модель (а-ля коллаборативное глубокое обучение) на фреймворке по децентрализованному обучению Hivemind
2.9B трансформер для русского, которая влезет в домашнюю ПеКарню ресерчера
Мало того, что это самая большая БЕРТ-подобная модель для русского языка, которая показывает крутые результаты в бенчмарках, так еще и с кодом для fine-tuning-а
GitHub
А в статье можете узнать, как обучалась эта модель (а-ля коллаборативное глубокое обучение) на фреймворке по децентрализованному обучению Hivemind
GitHub
GitHub - yandex-research/RuLeanALBERT: RuLeanALBERT is a pretrained masked language model for the Russian language that uses a…
RuLeanALBERT is a pretrained masked language model for the Russian language that uses a memory-efficient architecture. - yandex-research/RuLeanALBERT