
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday (tomorrow) at 10:30 (some people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts. We are expecting from 7 to 11 people.
Cross-Lingual Ability of Multilingual BERT: An Empirical Study to #ICLR2020
In this work, the authors provide a comprehensive study of the contribution of different components in multilingual #BERT (M-BERT) to its cross-lingual ability.
They study the impact of linguistic properties of the languages, the architecture of the model, and the learning objectives. The experimental study is done in the context of three typologically different languages – #Spanish, #Hindi, & #Russian – & using two conceptually different #NLP tasks, textual entailment & #NER.
Also, they construct a new corpus – Fake-English (#enfake), by shifting the Unicode of each character in English Wikipedia text by a large constant so that there is strictly no character overlap with any other Wikipedia text.
And, in this work, they consider Fake-English as a different language.
Among their key conclusions are the fact that the lexical overlap between languages plays a negligible role in the cross-lingual success, while the depth of the network is an integral part of it.
paper: https://arxiv.org/abs/1912.07840
In this work, the authors provide a comprehensive study of the contribution of different components in multilingual #BERT (M-BERT) to its cross-lingual ability.
They study the impact of linguistic properties of the languages, the architecture of the model, and the learning objectives. The experimental study is done in the context of three typologically different languages – #Spanish, #Hindi, & #Russian – & using two conceptually different #NLP tasks, textual entailment & #NER.
Also, they construct a new corpus – Fake-English (#enfake), by shifting the Unicode of each character in English Wikipedia text by a large constant so that there is strictly no character overlap with any other Wikipedia text.
And, in this work, they consider Fake-English as a different language.
Among their key conclusions are the fact that the lexical overlap between languages plays a negligible role in the cross-lingual success, while the depth of the network is an integral part of it.
paper: https://arxiv.org/abs/1912.07840
{kind=link}
Deep Learning State of the Art (2020) | MIT Deep Learning Series by @lexfridman
https://youtu.be/0VH1Lim8gL8
slides: http://bit.ly/2QEfbAm
https://youtu.be/0VH1Lim8gL8
slides: http://bit.ly/2QEfbAm
YouTube
Deep Learning State of the Art (2020)
Lecture on most recent research and developments in deep learning, and hopes for 2020. This is not intended to be a list of SOTA benchmark results, but rather a set of highlights of machine learning and AI innovations and progress in academia, industry, and…
Data Science by ODS.ai 🦜
YouTokenToMe, new tool for text tokenisation from VK team Meet new enhanced tokenisation tool on steroids. Works 7-10 times faster alphabetic languages and 40 to 50 times faster on logographic languages, than alternatives. Under the hood (watch source)…
New rust tokenization library from #HuggingFace
Tokenization is a process of converting strings in model input tensors. Library provides BPE/Byte-Level-BPE/WordPiece/SentencePiece tokenization, computes exhaustive set of outputs (offset mappings, attention masks, special token masks).
Library has python and node.js bindings.
The quoted post contains information on another fast #tokenization implementation. Looking forward for speed comparison.
Install:
Github: https://github.com/huggingface/tokenizers/tree/master/tokenizers
#NLU #NLP #Transformers #Rust #NotOnlyPython
Tokenization is a process of converting strings in model input tensors. Library provides BPE/Byte-Level-BPE/WordPiece/SentencePiece tokenization, computes exhaustive set of outputs (offset mappings, attention masks, special token masks).
Library has python and node.js bindings.
The quoted post contains information on another fast #tokenization implementation. Looking forward for speed comparison.
Install:
pip install tokenizersGithub: https://github.com/huggingface/tokenizers/tree/master/tokenizers
#NLU #NLP #Transformers #Rust #NotOnlyPython
GitHub
tokenizers/tokenizers at main · huggingface/tokenizers
💥 Fast State-of-the-Art Tokenizers optimized for Research and Production - huggingface/tokenizers
Online speech recognition with wav2letter@anywhere
Facebook have open-sourced wav2letter@anywhere, an inference framework for online speech recognition that delivers state-of-the-art performance.
Link: https://ai.facebook.com/blog/online-speech-recognition-with-wav2letteranywhere/
#wav2letter #audiolearning #soundlearning #sound #acoustic #audio #facebook
Facebook have open-sourced wav2letter@anywhere, an inference framework for online speech recognition that delivers state-of-the-art performance.
Link: https://ai.facebook.com/blog/online-speech-recognition-with-wav2letteranywhere/
#wav2letter #audiolearning #soundlearning #sound #acoustic #audio #facebook
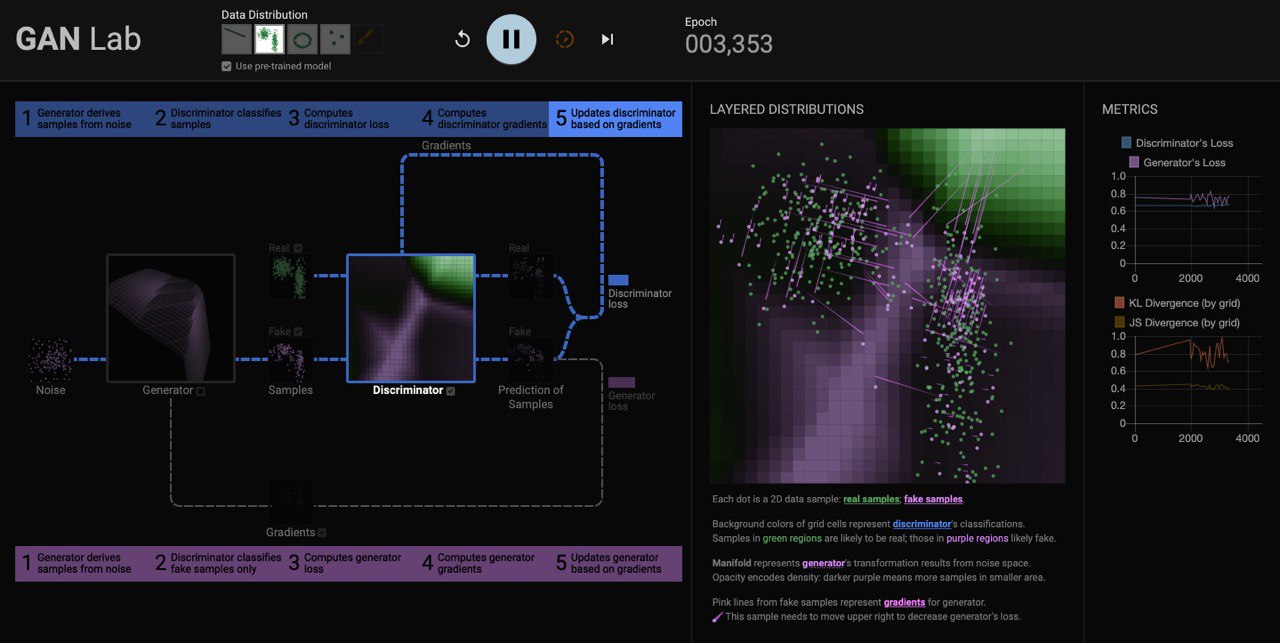
GAN Lab
Understanding Complex Deep Generative Models using Interactive Visual Experimentation
#GAN Lab is a novel interactive visualization tool for anyone to learn & experiment with Generative Adversarial Networks (GANs), a popular class of complex #DL models. With GAN Lab, you can interactively train GAN models for #2D data #distributions and visualize their inner-workings, similar to #TensorFlow Playground.
web-page: https://poloclub.github.io/ganlab/
github: https://github.com/poloclub/ganlab
paper: https://minsuk.com/research/papers/kahng-ganlab-vast2018.pdf
Understanding Complex Deep Generative Models using Interactive Visual Experimentation
#GAN Lab is a novel interactive visualization tool for anyone to learn & experiment with Generative Adversarial Networks (GANs), a popular class of complex #DL models. With GAN Lab, you can interactively train GAN models for #2D data #distributions and visualize their inner-workings, similar to #TensorFlow Playground.
web-page: https://poloclub.github.io/ganlab/
github: https://github.com/poloclub/ganlab
paper: https://minsuk.com/research/papers/kahng-ganlab-vast2018.pdf
{kind=link}
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday at 10:30 (some people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts.
how to do open-source code/research
by Thomas Wolf @HuggingFace
tl;dr:
* consider sharing your code as a tool to build on more than a snapshot of your work
* put yourself in the shoes of a master student who has to start from scratch with your code
* give clear instructions on how to run the code
* use the least amount of dependencies
* spend 4 days to do it well or more :kekeke:
* consider merging with a larger repo
* you need to keep everything clear & visible
more at twitter thread: https://twitter.com/Thom_Wolf/status/1216990543533821952?s=20
by Thomas Wolf @HuggingFace
tl;dr:
* consider sharing your code as a tool to build on more than a snapshot of your work
* put yourself in the shoes of a master student who has to start from scratch with your code
* give clear instructions on how to run the code
* use the least amount of dependencies
* spend 4 days to do it well or more :kekeke:
* consider merging with a larger repo
* you need to keep everything clear & visible
more at twitter thread: https://twitter.com/Thom_Wolf/status/1216990543533821952?s=20
{kind=link}
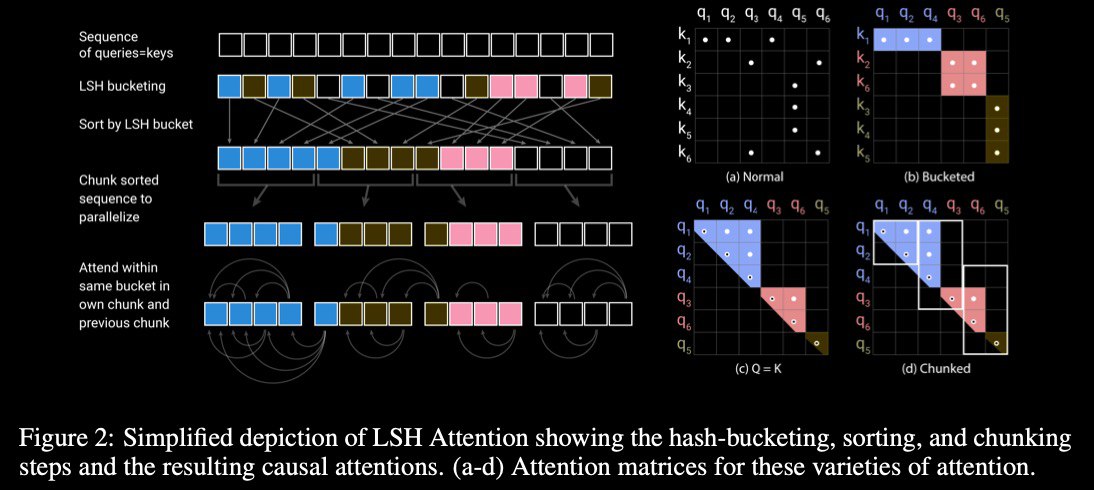
Reformer: The Efficient Transformer to #ICLR2020
tl;dr: #Reformer is a technical optimization of the original #Transformer, takes up less memory & reads more quickly
propose 3 improvements:
* reversible layers enable storing only a single copy of activations in the whole model, so the N factor disappears (where n – count of layers)
* splitting activations inside feed-forward layers & processing them in chunks removes the dff factor & saves memory inside feed-forward layers
* approximate attention computation based on locality-sensitive hashing (#LSH) replaces the O(L**2) factor in attention layers with O(L*log(L)) & so allows operating on long sequences (where L – sequence size)
Query and Keys in the Transformer can be considered one matrix, not separate.
paper: https://arxiv.org/abs/2001.04451
github: https://github.com/google/trax/tree/master/trax/models/reformer
blog post: https://ai.googleblog.com/2020/01/reformer-efficient-transformer.html
tl;dr: #Reformer is a technical optimization of the original #Transformer, takes up less memory & reads more quickly
propose 3 improvements:
* reversible layers enable storing only a single copy of activations in the whole model, so the N factor disappears (where n – count of layers)
* splitting activations inside feed-forward layers & processing them in chunks removes the dff factor & saves memory inside feed-forward layers
* approximate attention computation based on locality-sensitive hashing (#LSH) replaces the O(L**2) factor in attention layers with O(L*log(L)) & so allows operating on long sequences (where L – sequence size)
Query and Keys in the Transformer can be considered one matrix, not separate.
paper: https://arxiv.org/abs/2001.04451
github: https://github.com/google/trax/tree/master/trax/models/reformer
blog post: https://ai.googleblog.com/2020/01/reformer-efficient-transformer.html
{kind=link}
AI & Art
some artist use the large collections of #data & #ML #algorithms to create mesmerizing & dynamic #installations
watch the video —> https://youtu.be/I-EIVlHvHRM
some artist use the large collections of #data & #ML #algorithms to create mesmerizing & dynamic #installations
watch the video —> https://youtu.be/I-EIVlHvHRM
YouTube
How This Guy Uses A.I. to Create Art | Obsessed | WIRED
Artist Refik Anadol doesn't work with paintbrushes or clay. Instead, he uses large collections of data and machine learning algorithms to create mesmerizing and dynamic installations.
Machine Hallucination at Artechouse NYC: https://www.artechouse.com/nyc…
Machine Hallucination at Artechouse NYC: https://www.artechouse.com/nyc…
Revealing the Dark Secrets of BERT
tl;dr:
* BERT is heavily over parametrized
* BERT does not need to be all that smart
* BERT’s success is due to ~black magic~ something other than self-attention
This work focuses on the complementary question: what happens in the fine-tuned #BERT? In particular, how much of the linguistically interpretable self-attention patterns that are presumed to be its strength are actually used to solve downstream tasks?
Using a subset of #GLUE tasks and a set of handcrafted features-of-interest, they propose the methodology and carry out a qualitative and quantitative analysis of the information encoded by the individual BERT’s heads.
Also, they show that manually disabling attention in certain heads leads to performance improvement over the regular fine-tuned BERT models.
paper: https://www.aclweb.org/anthology/D19-1445.pdf
blog post: https://text-machine-lab.github.io/blog/2020/bert-secrets/
tl;dr:
* BERT is heavily over parametrized
* BERT does not need to be all that smart
* BERT’s success is due to ~black magic~ something other than self-attention
This work focuses on the complementary question: what happens in the fine-tuned #BERT? In particular, how much of the linguistically interpretable self-attention patterns that are presumed to be its strength are actually used to solve downstream tasks?
Using a subset of #GLUE tasks and a set of handcrafted features-of-interest, they propose the methodology and carry out a qualitative and quantitative analysis of the information encoded by the individual BERT’s heads.
Also, they show that manually disabling attention in certain heads leads to performance improvement over the regular fine-tuned BERT models.
paper: https://www.aclweb.org/anthology/D19-1445.pdf
blog post: https://text-machine-lab.github.io/blog/2020/bert-secrets/
{kind=link}
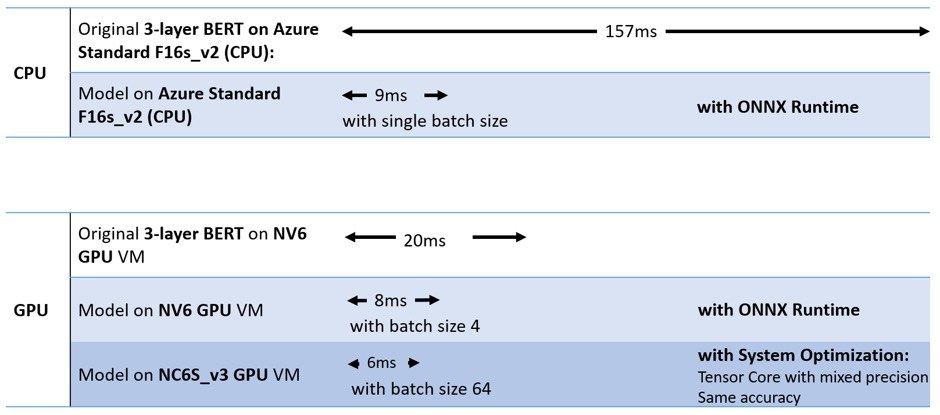
Microsoft open sources breakthrough optimizations for transformer inference on GPU and CPU
How?
#Transformer models like #BERT consist of a graph of many operators. Graph optimization, ranging from small graph simplifications and node eliminations to more complex node fusions and layout optimizations, is an essential technique built into #ONNX Runtime.
Since the BERT model is mainly composed of stacked transformer cells, we optimize each cell by fusing key sub-graphs of multiple elementary operators into single kernels for both CPU and GPU, including Self-Attention, LayerNormalization, and Gelu layers. This significantly reduces memory copy between numerous elementary computations.
Additionally, in the CPU implementation of Self-Attention, the columns of matrix Q, K, and V are partitioned based on the number of self-attention heads. With this optimization, we can significantly increase the parallelization and fully leverage available CPU cores. Moreover, the transpose op following the full connection of Q, K, and V can be computed within GEMM, which further reduces the computation cost.
blog post: https://cloudblogs.microsoft.com/opensource/2020/01/21/microsoft-onnx-open-source-optimizations-transformer-inference-gpu-cpu/
How?
#Transformer models like #BERT consist of a graph of many operators. Graph optimization, ranging from small graph simplifications and node eliminations to more complex node fusions and layout optimizations, is an essential technique built into #ONNX Runtime.
Since the BERT model is mainly composed of stacked transformer cells, we optimize each cell by fusing key sub-graphs of multiple elementary operators into single kernels for both CPU and GPU, including Self-Attention, LayerNormalization, and Gelu layers. This significantly reduces memory copy between numerous elementary computations.
Additionally, in the CPU implementation of Self-Attention, the columns of matrix Q, K, and V are partitioned based on the number of self-attention heads. With this optimization, we can significantly increase the parallelization and fully leverage available CPU cores. Moreover, the transpose op following the full connection of Q, K, and V can be computed within GEMM, which further reduces the computation cost.
blog post: https://cloudblogs.microsoft.com/opensource/2020/01/21/microsoft-onnx-open-source-optimizations-transformer-inference-gpu-cpu/
{kind=link}
AI Career Pathways: Put Yourself on the Right Track
by deeplearning.ai (founder Andrew Ng)
tl;dr: at the picture
This report aims to clarify what #AI organizations are, what tasks you will work on, and the existing career tracks. It can help learners around the world choose a career track that matches their skills, background, and aspirations.
report: https://www.workera.ai/candidates/report/
by deeplearning.ai (founder Andrew Ng)
tl;dr: at the picture
This report aims to clarify what #AI organizations are, what tasks you will work on, and the existing career tracks. It can help learners around the world choose a career track that matches their skills, background, and aspirations.
report: https://www.workera.ai/candidates/report/
{kind=link}
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday at 10:30 (some people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts. We are expecting from 5 to 14 people.
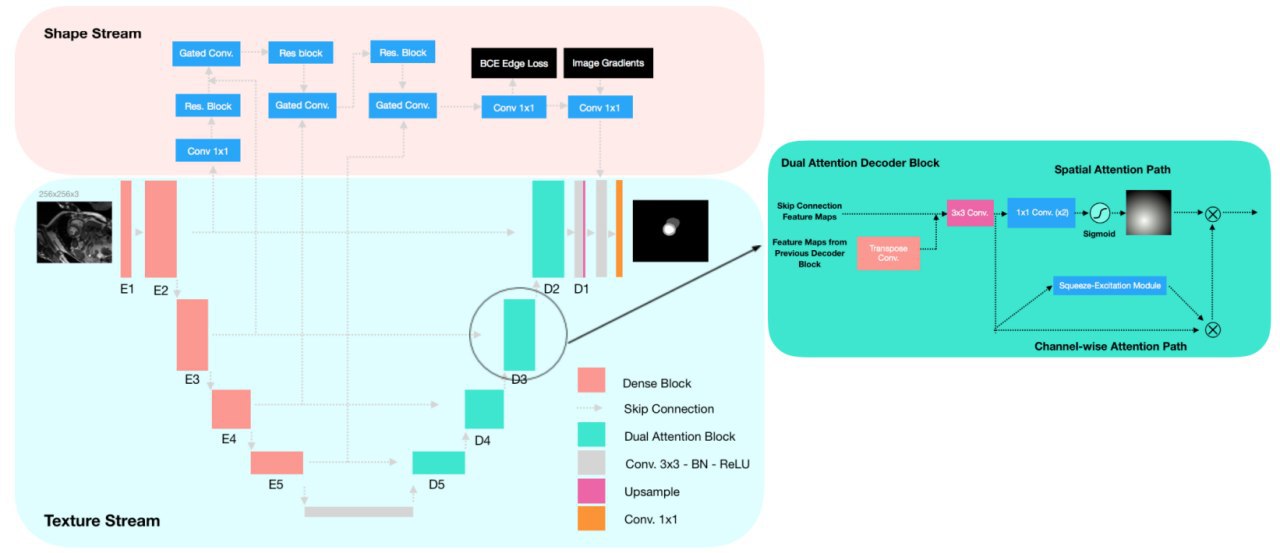
SAUNet: Shape Attentive U-Net for Interpretable Medical Image Segmentation
New approach for interpreting medical image segmentation models.
U-Net and other image segmentation models work quite well on medical data, but still aren't widely adopted. One of the reasons is the lack of reproducibility as well as robustness issues.
The key idea of the paper is using the additional stream in U-Net with shape features to increase robustness and use the output of this stream (attention map) that can be used or interpretability.
Modifications to the basic U-Net architecture:
- use dense blocks from DenseNet-121 as the encoder.
- use dual attention decoder block (with spatial and channel-wise attention paths)
- make the second stream using object shape (contour)
- dual-task loss function: cross-entropy + dice + edge loss (bce loss of the predicted shape boundaries)
Shape and spatial attention maps can be used for interpretation.
Paper: https://arxiv.org/abs/2001.07645
Code: https://github.com/sunjesse/shape-attentive-unet
#unet #imagesegmentation #interpretability #segmentation
New approach for interpreting medical image segmentation models.
U-Net and other image segmentation models work quite well on medical data, but still aren't widely adopted. One of the reasons is the lack of reproducibility as well as robustness issues.
The key idea of the paper is using the additional stream in U-Net with shape features to increase robustness and use the output of this stream (attention map) that can be used or interpretability.
Modifications to the basic U-Net architecture:
- use dense blocks from DenseNet-121 as the encoder.
- use dual attention decoder block (with spatial and channel-wise attention paths)
- make the second stream using object shape (contour)
- dual-task loss function: cross-entropy + dice + edge loss (bce loss of the predicted shape boundaries)
Shape and spatial attention maps can be used for interpretation.
Paper: https://arxiv.org/abs/2001.07645
Code: https://github.com/sunjesse/shape-attentive-unet
#unet #imagesegmentation #interpretability #segmentation
{kind=link}
Natural Language Processing News
by Sebastian Ruder
* NLP progress
* Retrospectives and look ahead
* New NLP courses
* Independent research initiatives
* Interviews
* Resources
* Tools
* Articles and blog posts
* Papers + blog post
* Paper picks
blog post: http://newsletter.ruder.io/issues/nlp-progress-restrospectives-and-look-ahead-new-nlp-courses-independent-research-initiatives-interviews-lots-of-resources-217744
#nlp #progress #news #ruder
by Sebastian Ruder
* NLP progress
* Retrospectives and look ahead
* New NLP courses
* Independent research initiatives
* Interviews
* Resources
* Tools
* Articles and blog posts
* Papers + blog post
* Paper picks
blog post: http://newsletter.ruder.io/issues/nlp-progress-restrospectives-and-look-ahead-new-nlp-courses-independent-research-initiatives-interviews-lots-of-resources-217744
#nlp #progress #news #ruder
{kind=link}
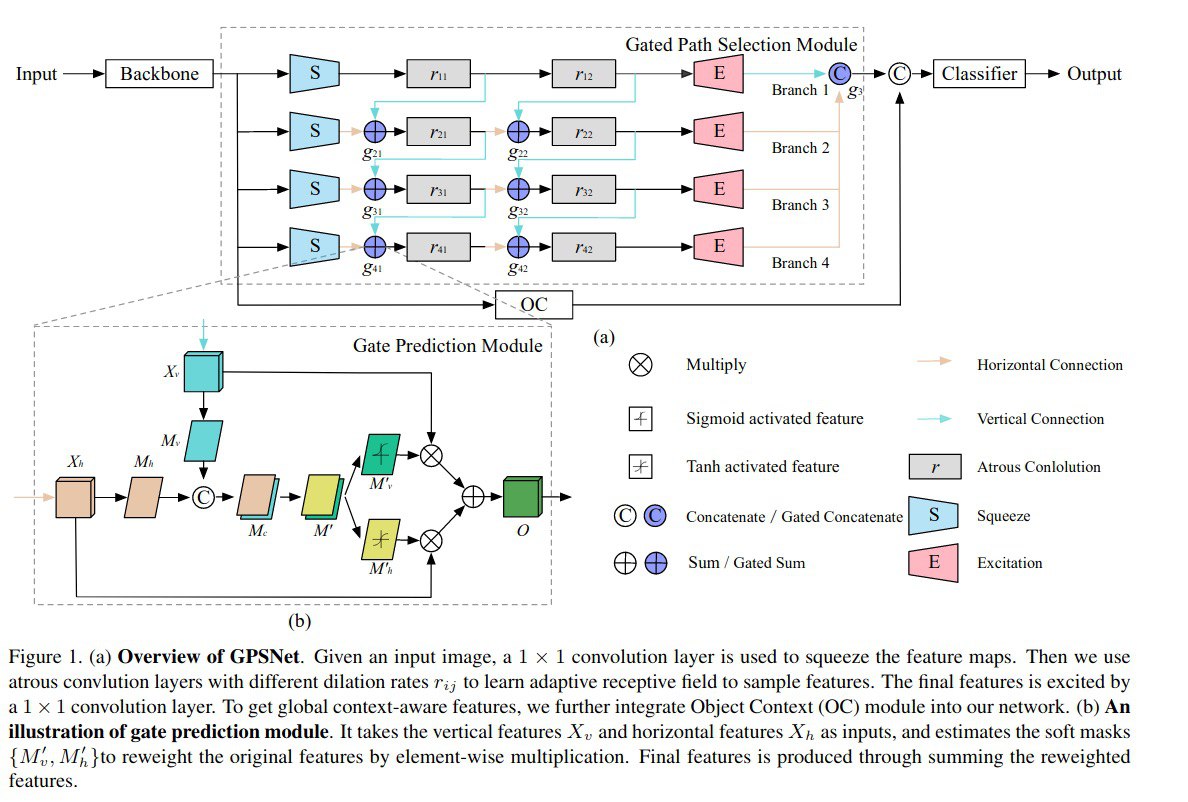
Gated Path Selection Network for Semantic Segmentation
A new approach for improving APSS-like networks for image segmentation.
Atrous Spatial Pyramid Pooling (ASPP) is an architecture that concatenates multiple atrous-convolved features using different dilution rates.
In this paper, authors develop a novel architecture named GPSNet, which aims to densely capture semantic context and to learn adaptive receptive fields, which are flexible to model various geometric deformations.
They designed architecture with multiple branches called SuperNet. The main characteristics are the following:
- it stacks a series of bottlenecked branches which consist of differently tuned dilation convolutions;
- multiple dense connections;
- a new module - Gate Prediction, which produces soft masks;
- improved sampling.
This approach was tested on Cityscapes и ADE20K datasets and showed better quality than other ASPP architectures, but still not as good as the current SOTA.
An ablation study shows that all changes introduced in this paper improve the score.
GPS module is lightweight and can be easily used in other models with ASPP architecture.
paper: https://deepai.org/publication/gated-path-selection-network-for-semantic-segmentation
#cv #semantic #segmentation #ASPP
A new approach for improving APSS-like networks for image segmentation.
Atrous Spatial Pyramid Pooling (ASPP) is an architecture that concatenates multiple atrous-convolved features using different dilution rates.
In this paper, authors develop a novel architecture named GPSNet, which aims to densely capture semantic context and to learn adaptive receptive fields, which are flexible to model various geometric deformations.
They designed architecture with multiple branches called SuperNet. The main characteristics are the following:
- it stacks a series of bottlenecked branches which consist of differently tuned dilation convolutions;
- multiple dense connections;
- a new module - Gate Prediction, which produces soft masks;
- improved sampling.
This approach was tested on Cityscapes и ADE20K datasets and showed better quality than other ASPP architectures, but still not as good as the current SOTA.
An ablation study shows that all changes introduced in this paper improve the score.
GPS module is lightweight and can be easily used in other models with ASPP architecture.
paper: https://deepai.org/publication/gated-path-selection-network-for-semantic-segmentation
#cv #semantic #segmentation #ASPP
{kind=link}
🔝Great OpenDataScience Channel Audience Research
The first audience research was done on 25.06.18 and it is time to update our knowledge on what are we.
Please fill in this form: https://forms.gle/GGNgukYNQbAZPtmk8 all the collected data will be used to benefit and it will dramatically help us to improve quality of content we share!
Google form link: https://forms.gle/GGNgukYNQbAZPtmk8
The first audience research was done on 25.06.18 and it is time to update our knowledge on what are we.
Please fill in this form: https://forms.gle/GGNgukYNQbAZPtmk8 all the collected data will be used to benefit and it will dramatically help us to improve quality of content we share!
Google form link: https://forms.gle/GGNgukYNQbAZPtmk8
Google Docs
@opendatascience audience research 2020
Hey, this is a form to study the audience of our channel to post more relevant and interesting content for you. Please fill in.
However, first question with residence country is not obligatory, channel administration will highly appreciate any answers, for…
However, first question with residence country is not obligatory, channel administration will highly appreciate any answers, for…
Data Science by ODS.ai 🦜 pinned «🔝Great OpenDataScience Channel Audience Research The first audience research was done on 25.06.18 and it is time to update our knowledge on what are we. Please fill in this form: https://forms.gle/GGNgukYNQbAZPtmk8 all the collected data will be used to…»
We have collected 26 responses so far, which gives us 2% conversion rate.
Please invest your time in filling in the form, it is to your benefit as reader.
This is especially important if you might find yourself under-represented in the questionnaire results in the end (when we have collected enought data. 26 responses now are extremely biased).
Please invest your time in filling in the form, it is to your benefit as reader.
This is especially important if you might find yourself under-represented in the questionnaire results in the end (when we have collected enought data. 26 responses now are extremely biased).
🔥Human-like chatbots from Google: Towards a Human-like Open-Domain Chatbot.
TLDR: humanity is one huge step closer to a chat-bot, which can chat about anything and has great chance of success, passing #TuringTest
What does it mean: As an example, soon you will have to be extra-cautious chatting in #dating apps, because there will be more chat-bots, who can seem humane.
This also means that there will some positive and productive applications too: more sophisticated selling operators, on-demand psychological support, you name it.
It might be surprising, but #seq2seq still works. Over 5+ years of working on neural conversational models, general progress is a fine-tune of basic approach. It is a proof that much can be still discovered, along with room for new completely different approaches.
«Perplexity is all a chatbot needs ;)» (с) Quoc Le
Blog post: https://ai.googleblog.com/2020/01/towards-conversational-agent-that-can.html
Paper: https://arxiv.org/abs/2001.09977
Demo conversations: https://github.com/google-research/google-research/tree/master/meena
#NLP #NLU #ChatBots #google #googleai
TLDR: humanity is one huge step closer to a chat-bot, which can chat about anything and has great chance of success, passing #TuringTest
What does it mean: As an example, soon you will have to be extra-cautious chatting in #dating apps, because there will be more chat-bots, who can seem humane.
This also means that there will some positive and productive applications too: more sophisticated selling operators, on-demand psychological support, you name it.
It might be surprising, but #seq2seq still works. Over 5+ years of working on neural conversational models, general progress is a fine-tune of basic approach. It is a proof that much can be still discovered, along with room for new completely different approaches.
«Perplexity is all a chatbot needs ;)» (с) Quoc Le
Blog post: https://ai.googleblog.com/2020/01/towards-conversational-agent-that-can.html
Paper: https://arxiv.org/abs/2001.09977
Demo conversations: https://github.com/google-research/google-research/tree/master/meena
#NLP #NLU #ChatBots #google #googleai
research.google
Towards a Conversational Agent that Can Chat About…Anything
Posted by Daniel Adiwardana, Senior Research Engineer, and Thang Luong, Senior Research Scientist, Google Research, Brain Team Modern conversatio...