
Revealing the Dark Secrets of BERT
tl;dr:
* BERT is heavily over parametrized
* BERT does not need to be all that smart
* BERT’s success is due to ~black magic~ something other than self-attention
This work focuses on the complementary question: what happens in the fine-tuned #BERT? In particular, how much of the linguistically interpretable self-attention patterns that are presumed to be its strength are actually used to solve downstream tasks?
Using a subset of #GLUE tasks and a set of handcrafted features-of-interest, they propose the methodology and carry out a qualitative and quantitative analysis of the information encoded by the individual BERT’s heads.
Also, they show that manually disabling attention in certain heads leads to performance improvement over the regular fine-tuned BERT models.
paper: https://www.aclweb.org/anthology/D19-1445.pdf
blog post: https://text-machine-lab.github.io/blog/2020/bert-secrets/
tl;dr:
* BERT is heavily over parametrized
* BERT does not need to be all that smart
* BERT’s success is due to ~black magic~ something other than self-attention
This work focuses on the complementary question: what happens in the fine-tuned #BERT? In particular, how much of the linguistically interpretable self-attention patterns that are presumed to be its strength are actually used to solve downstream tasks?
Using a subset of #GLUE tasks and a set of handcrafted features-of-interest, they propose the methodology and carry out a qualitative and quantitative analysis of the information encoded by the individual BERT’s heads.
Also, they show that manually disabling attention in certain heads leads to performance improvement over the regular fine-tuned BERT models.
paper: https://www.aclweb.org/anthology/D19-1445.pdf
blog post: https://text-machine-lab.github.io/blog/2020/bert-secrets/
{kind=link}
XGLUE: A New Benchmark Dataset
for Cross-lingual Pre-training, Understanding and Generation
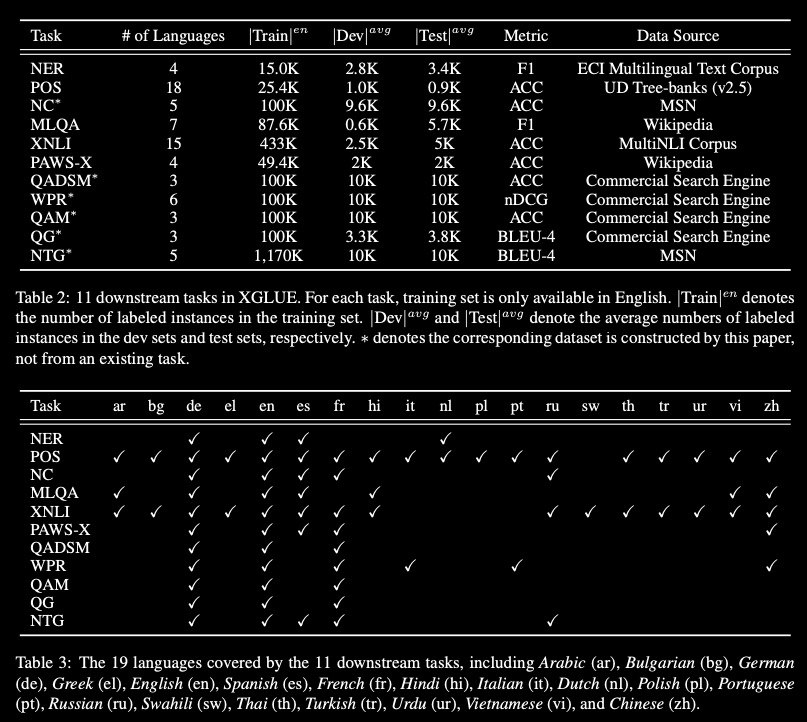
Introduced XGLUE as a new benchmark dataset to train large-scale cross-lingual pre-trained models using multilingual and bilingual corpora, and evaluate their performance across a diverse set of cross-lingual tasks.
Comparing to GLUE (Wangetal., 2019), which is labeled in English and includes natural language understanding tasks only, XGLUE has three main advantages:
[0] it provides two corpora with different sizes for cross-lingual pretraining
[1] it provides 11 diversified tasks that cover both natural language understanding and generation scenarios
[2] for each task, it provides labeled data in multiple languages.
The authors extend a recent cross-lingual pre-trained model Unicoder (Huang et al., 2019) to cover both understanding and generation tasks, which is evaluated on XGLUE as a strong baseline.
Also, they evaluate the base versions (12-layer) of Multilingual BERT, XLM, and XLM-R for comparison.
paper: https://arxiv.org/abs/2004.01401.pdf
#nlp #glue #multilingual #bilingual #xglue
for Cross-lingual Pre-training, Understanding and Generation
Introduced XGLUE as a new benchmark dataset to train large-scale cross-lingual pre-trained models using multilingual and bilingual corpora, and evaluate their performance across a diverse set of cross-lingual tasks.
Comparing to GLUE (Wangetal., 2019), which is labeled in English and includes natural language understanding tasks only, XGLUE has three main advantages:
[0] it provides two corpora with different sizes for cross-lingual pretraining
[1] it provides 11 diversified tasks that cover both natural language understanding and generation scenarios
[2] for each task, it provides labeled data in multiple languages.
The authors extend a recent cross-lingual pre-trained model Unicoder (Huang et al., 2019) to cover both understanding and generation tasks, which is evaluated on XGLUE as a strong baseline.
Also, they evaluate the base versions (12-layer) of Multilingual BERT, XLM, and XLM-R for comparison.
paper: https://arxiv.org/abs/2004.01401.pdf
#nlp #glue #multilingual #bilingual #xglue
{kind=link}