
Updating Pre-trained Word Vectors and Text Classifiers using Monolingual Alignment
The authors drew inspiration from the way #multilingual word vectors are learned. They treated general-purpose and domain-specific corpora as separate languages and used a word-embedding model to learn independent vectors from each. Then they aligned the vectors from one corpus with those from another.
To align word vectors from two corpora, common words are used to find a consistent way to represent all words. For example, if one corpus is [human, cat] and the other is [cat, dog], the model applies a transformation that unifies the dog word vectors while retaining the relative positions of the word vectors between cats, dogs, and humans.
A word-embedding model learns independent word vectors from both corpora.
The authors use a loss function called #RCSLS for training. RCSLS balances two objectives: General-purpose vectors that are close together remain close together, while general-purpose vectors that far apart remain far apart. Common words in the two corpora now have duplicate vectors. Averaging them produces a single vector representation.
They consider applications to word embedding and text, classification models. Show that the proposed approach yields good performance in all setups and outperforms a baseline consisting of fine-tuning the model on new data.
paper: https://arxiv.org/abs/1910.06241
#nlp
The authors drew inspiration from the way #multilingual word vectors are learned. They treated general-purpose and domain-specific corpora as separate languages and used a word-embedding model to learn independent vectors from each. Then they aligned the vectors from one corpus with those from another.
To align word vectors from two corpora, common words are used to find a consistent way to represent all words. For example, if one corpus is [human, cat] and the other is [cat, dog], the model applies a transformation that unifies the dog word vectors while retaining the relative positions of the word vectors between cats, dogs, and humans.
A word-embedding model learns independent word vectors from both corpora.
The authors use a loss function called #RCSLS for training. RCSLS balances two objectives: General-purpose vectors that are close together remain close together, while general-purpose vectors that far apart remain far apart. Common words in the two corpora now have duplicate vectors. Averaging them produces a single vector representation.
They consider applications to word embedding and text, classification models. Show that the proposed approach yields good performance in all setups and outperforms a baseline consisting of fine-tuning the model on new data.
paper: https://arxiv.org/abs/1910.06241
#nlp
{kind=link}
Emerging Cross-lingual Structure in Pretrained Language Models
tl;dr – dissect mBERT & XLM and show monolingual BERTs are similar
They offer an ablation study on bilingual #MLM considering all relevant factors. Sharing only the top 2 layers of the #transformer finally break cross-lingual transfer.
Factors importance: parameter sharing >> domain similarity, anchor points, language universal softmax, joint BPE
We can align monolingual BERT representation at word-level & sentence level with orthogonal mapping. CKA visualizes the similarity of monitoring. & billing. BERT
Paper: https://arxiv.org/abs/1911.01464
#nlp #multilingual
tl;dr – dissect mBERT & XLM and show monolingual BERTs are similar
They offer an ablation study on bilingual #MLM considering all relevant factors. Sharing only the top 2 layers of the #transformer finally break cross-lingual transfer.
Factors importance: parameter sharing >> domain similarity, anchor points, language universal softmax, joint BPE
We can align monolingual BERT representation at word-level & sentence level with orthogonal mapping. CKA visualizes the similarity of monitoring. & billing. BERT
Paper: https://arxiv.org/abs/1911.01464
#nlp #multilingual
{kind=link}
Towards Lingua Franca Named Entity Recognition with BERT
The authors present a simple and effective recipe for building #multilingual #NER systems with #BERT.
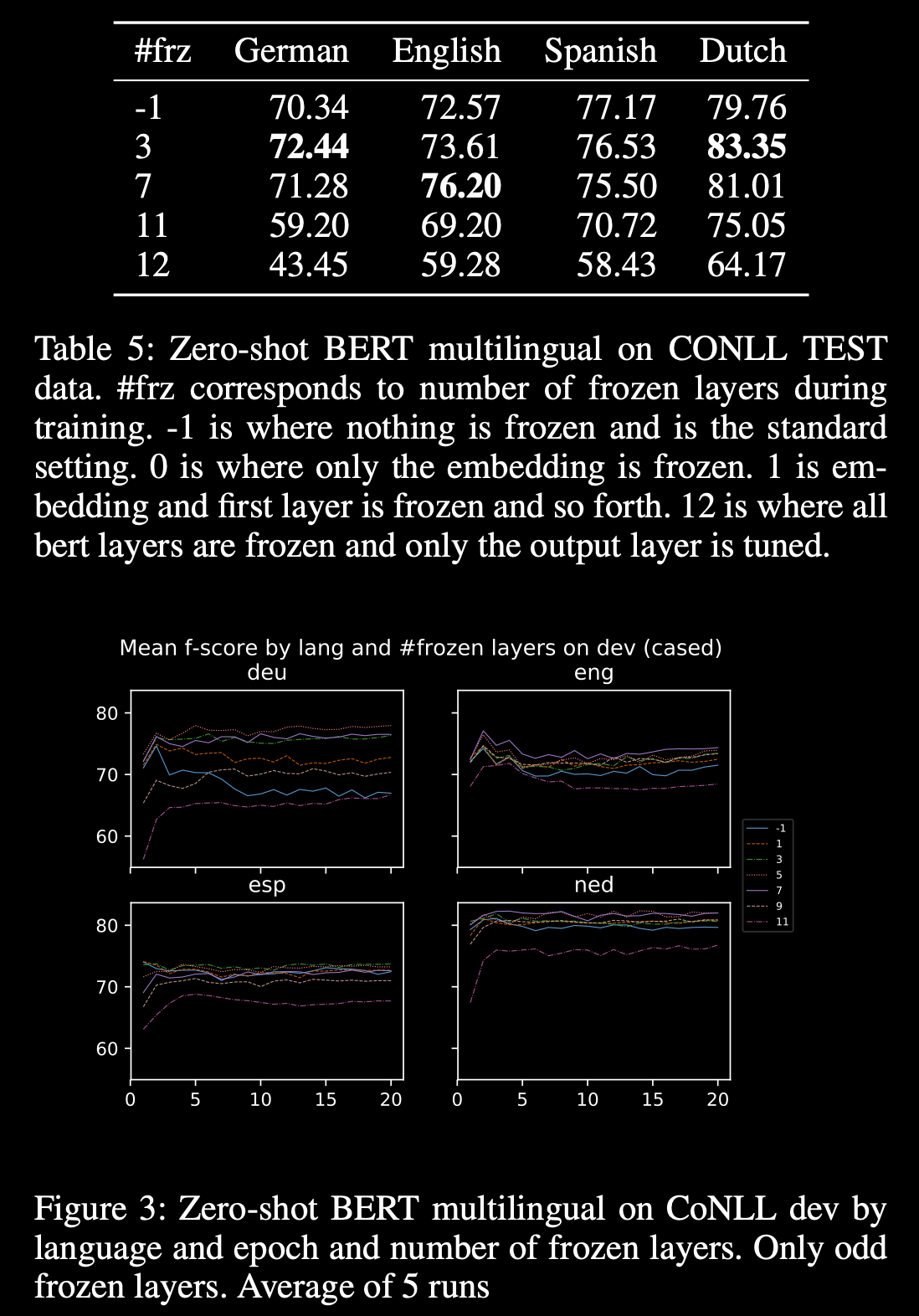
By utilizing a multilingual BERT framework, they were able to not only train a system that can perform inference on English, German, Spanish, and Dutch languages, but it performs better than the same model trained only on one language at a time, and also is able to perform 0-shot inference.
The resulting model yields #SotA results on CoNLL Spanish and Dutch, and on OntoNotes Chinese and Arabic datasets.
Also, the English trained model yields SotA results for 0-shot languages for Spanish, Dutch, and German NER, improving it by a range of 2.4F to 17.8F.
Furthermore, the runtime signature (memory/CPU/GPU) of the model is the same as the models built on single languages, significantly simplifying its life- cycle maintenance.
paper: https://arxiv.org/abs/1912.01389
The authors present a simple and effective recipe for building #multilingual #NER systems with #BERT.
By utilizing a multilingual BERT framework, they were able to not only train a system that can perform inference on English, German, Spanish, and Dutch languages, but it performs better than the same model trained only on one language at a time, and also is able to perform 0-shot inference.
The resulting model yields #SotA results on CoNLL Spanish and Dutch, and on OntoNotes Chinese and Arabic datasets.
Also, the English trained model yields SotA results for 0-shot languages for Spanish, Dutch, and German NER, improving it by a range of 2.4F to 17.8F.
Furthermore, the runtime signature (memory/CPU/GPU) of the model is the same as the models built on single languages, significantly simplifying its life- cycle maintenance.
paper: https://arxiv.org/abs/1912.01389
{kind=link}
CCMatrix: A billion-scale bitext data set for training translation models
The authors show that margin-based bitext mining in LASER's multilingual sentence space can be applied to monolingual corpora of billions of sentences.
They are using 10 snapshots of a curated common crawl corpus CCNet totaling 32.7 billion unique sentences. Using one unified approach for 38 languages, they were able to mine 3.5 billion parallel sentences, out of which 661 million are aligned with English. 17 language pairs have more than 30 million parallel sentences, 82 more than 10 million, and most more than one million, including direct alignments between many European or Asian languages.
They train NMT systems for most of the language pairs and evaluate them on TED, WMT and WAT test sets. Also, they achieve a new SOTA for a single system on the WMT'19 test set for translation between English and German, Russian and Chinese, as well as German/French.
But, they will soon provide a script to extract the parallel data from this corpus
blog post: https://ai.facebook.com/blog/ccmatrix-a-billion-scale-bitext-data-set-for-training-translation-models/
paper: https://arxiv.org/abs/1911.04944.pdf
github: https://github.com/facebookresearch/LASER/tree/master/tasks/CCMatrix
#nlp #multilingual #laser #data #monolingual
The authors show that margin-based bitext mining in LASER's multilingual sentence space can be applied to monolingual corpora of billions of sentences.
They are using 10 snapshots of a curated common crawl corpus CCNet totaling 32.7 billion unique sentences. Using one unified approach for 38 languages, they were able to mine 3.5 billion parallel sentences, out of which 661 million are aligned with English. 17 language pairs have more than 30 million parallel sentences, 82 more than 10 million, and most more than one million, including direct alignments between many European or Asian languages.
They train NMT systems for most of the language pairs and evaluate them on TED, WMT and WAT test sets. Also, they achieve a new SOTA for a single system on the WMT'19 test set for translation between English and German, Russian and Chinese, as well as German/French.
But, they will soon provide a script to extract the parallel data from this corpus
blog post: https://ai.facebook.com/blog/ccmatrix-a-billion-scale-bitext-data-set-for-training-translation-models/
paper: https://arxiv.org/abs/1911.04944.pdf
github: https://github.com/facebookresearch/LASER/tree/master/tasks/CCMatrix
#nlp #multilingual #laser #data #monolingual
{kind=link}
TyDi QA: A Multilingual Question Answering Benchmark
it's a q&a corpus covering 11 Typologically Diverse languages: russian, english, arabic, bengali, finnish, indonesian, japanese, kiswahili, korean, telugu, thai.
the authors collected questions from people who wanted an answer but did not know the answer yet.
they showed people an interesting passage from Wikipedia written in their native language and then had them ask a question, any question, as long as it was not answered by the passage and they actually wanted to know the answer.
blog post: https://ai.googleblog.com/2020/02/tydi-qa-multilingual-question-answering.html?m=1
paper: only pdf
#nlp #qa #multilingual #data
it's a q&a corpus covering 11 Typologically Diverse languages: russian, english, arabic, bengali, finnish, indonesian, japanese, kiswahili, korean, telugu, thai.
the authors collected questions from people who wanted an answer but did not know the answer yet.
they showed people an interesting passage from Wikipedia written in their native language and then had them ask a question, any question, as long as it was not answered by the passage and they actually wanted to know the answer.
blog post: https://ai.googleblog.com/2020/02/tydi-qa-multilingual-question-answering.html?m=1
paper: only pdf
#nlp #qa #multilingual #data
{kind=link}
XGLUE: A New Benchmark Dataset
for Cross-lingual Pre-training, Understanding and Generation
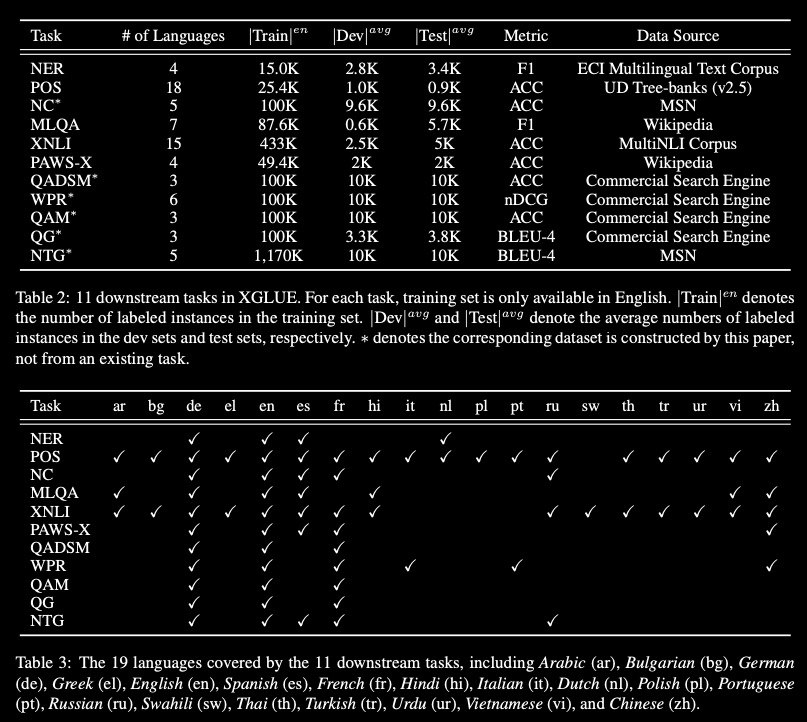
Introduced XGLUE as a new benchmark dataset to train large-scale cross-lingual pre-trained models using multilingual and bilingual corpora, and evaluate their performance across a diverse set of cross-lingual tasks.
Comparing to GLUE (Wangetal., 2019), which is labeled in English and includes natural language understanding tasks only, XGLUE has three main advantages:
[0] it provides two corpora with different sizes for cross-lingual pretraining
[1] it provides 11 diversified tasks that cover both natural language understanding and generation scenarios
[2] for each task, it provides labeled data in multiple languages.
The authors extend a recent cross-lingual pre-trained model Unicoder (Huang et al., 2019) to cover both understanding and generation tasks, which is evaluated on XGLUE as a strong baseline.
Also, they evaluate the base versions (12-layer) of Multilingual BERT, XLM, and XLM-R for comparison.
paper: https://arxiv.org/abs/2004.01401.pdf
#nlp #glue #multilingual #bilingual #xglue
for Cross-lingual Pre-training, Understanding and Generation
Introduced XGLUE as a new benchmark dataset to train large-scale cross-lingual pre-trained models using multilingual and bilingual corpora, and evaluate their performance across a diverse set of cross-lingual tasks.
Comparing to GLUE (Wangetal., 2019), which is labeled in English and includes natural language understanding tasks only, XGLUE has three main advantages:
[0] it provides two corpora with different sizes for cross-lingual pretraining
[1] it provides 11 diversified tasks that cover both natural language understanding and generation scenarios
[2] for each task, it provides labeled data in multiple languages.
The authors extend a recent cross-lingual pre-trained model Unicoder (Huang et al., 2019) to cover both understanding and generation tasks, which is evaluated on XGLUE as a strong baseline.
Also, they evaluate the base versions (12-layer) of Multilingual BERT, XLM, and XLM-R for comparison.
paper: https://arxiv.org/abs/2004.01401.pdf
#nlp #glue #multilingual #bilingual #xglue
{kind=link}
MLSUM: The Multilingual Summarization Corpus
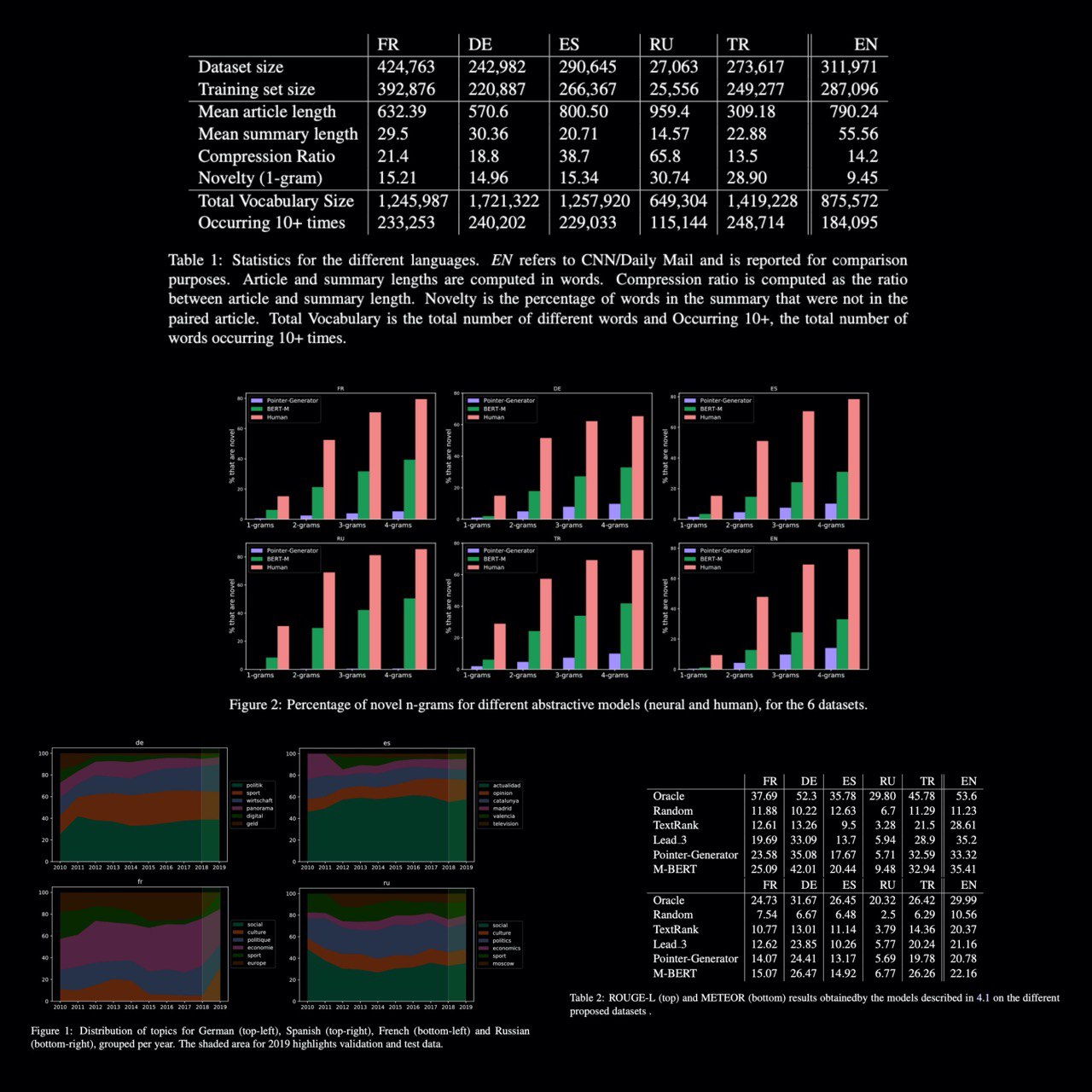
The first large-scale MultiLingual SUMmarization dataset, comprising over 1.5M article/summary pairs in French, German, Russian, Spanish, and Turkish. Its complementary nature to the CNN/DM summarization dataset for English.
For each language, they selected an online newspaper from 2010 to 2019 which met the following requirements:
0 being a generalist newspaper: ensuring that a broad range of topics is represented for each language allows minimizing the risk of training topic-specific models, a fact which would hinder comparative cross-lingual analyses of the models.
1 having a large number of articles in their public online archive.
2 Providing human written highlights/summaries for the articles that can be extracted from the HTML code of the web page.
Also, in this paper, you can remember about similar other datasets
paper: https://arxiv.org/abs/2004.14900
github: https://github.com/recitalAI/MLSUM
Instructions and code will soon.
#nlp #corpus #dataset #multilingual
The first large-scale MultiLingual SUMmarization dataset, comprising over 1.5M article/summary pairs in French, German, Russian, Spanish, and Turkish. Its complementary nature to the CNN/DM summarization dataset for English.
For each language, they selected an online newspaper from 2010 to 2019 which met the following requirements:
0 being a generalist newspaper: ensuring that a broad range of topics is represented for each language allows minimizing the risk of training topic-specific models, a fact which would hinder comparative cross-lingual analyses of the models.
1 having a large number of articles in their public online archive.
2 Providing human written highlights/summaries for the articles that can be extracted from the HTML code of the web page.
Also, in this paper, you can remember about similar other datasets
paper: https://arxiv.org/abs/2004.14900
github: https://github.com/recitalAI/MLSUM
Instructions and code will soon.
#nlp #corpus #dataset #multilingual
{kind=link}
Phoenix: Democratizing ChatGPT across Languages
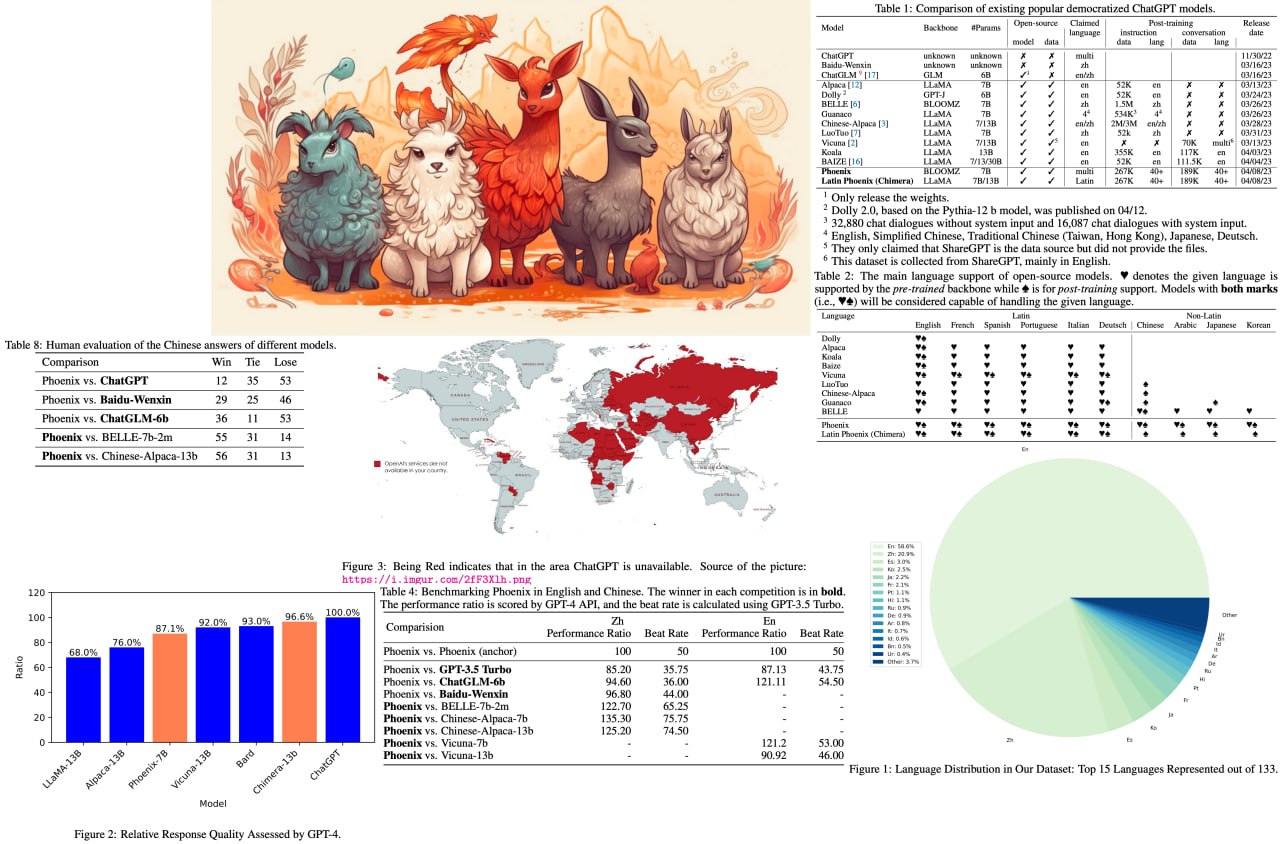
Introducing "Phoenix," a revolutionary multilingual ChatGPT that's breaking barriers in AI language models! By excelling in languages with limited resources and demonstrating competitive performance in English and Chinese models, Phoenix is set to transform accessibility for people around the world.
The methodology behind Phoenix combines instructions and conversations data to create a more well-rounded language model, leveraging the multi-lingual nature of the data to understand and interact with diverse languages.
Paper link: https://arxiv.org/abs/2304.10453
Code link: https://github.com/FreedomIntelligence/LLMZoo
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-phoenix-llm
#deeplearning #nlp #Phoenix #ChatGPT #multilingual #languagemodel
Introducing "Phoenix," a revolutionary multilingual ChatGPT that's breaking barriers in AI language models! By excelling in languages with limited resources and demonstrating competitive performance in English and Chinese models, Phoenix is set to transform accessibility for people around the world.
The methodology behind Phoenix combines instructions and conversations data to create a more well-rounded language model, leveraging the multi-lingual nature of the data to understand and interact with diverse languages.
Paper link: https://arxiv.org/abs/2304.10453
Code link: https://github.com/FreedomIntelligence/LLMZoo
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-phoenix-llm
#deeplearning #nlp #Phoenix #ChatGPT #multilingual #languagemodel
{kind=link}
Multilingual End to End Entity Linking
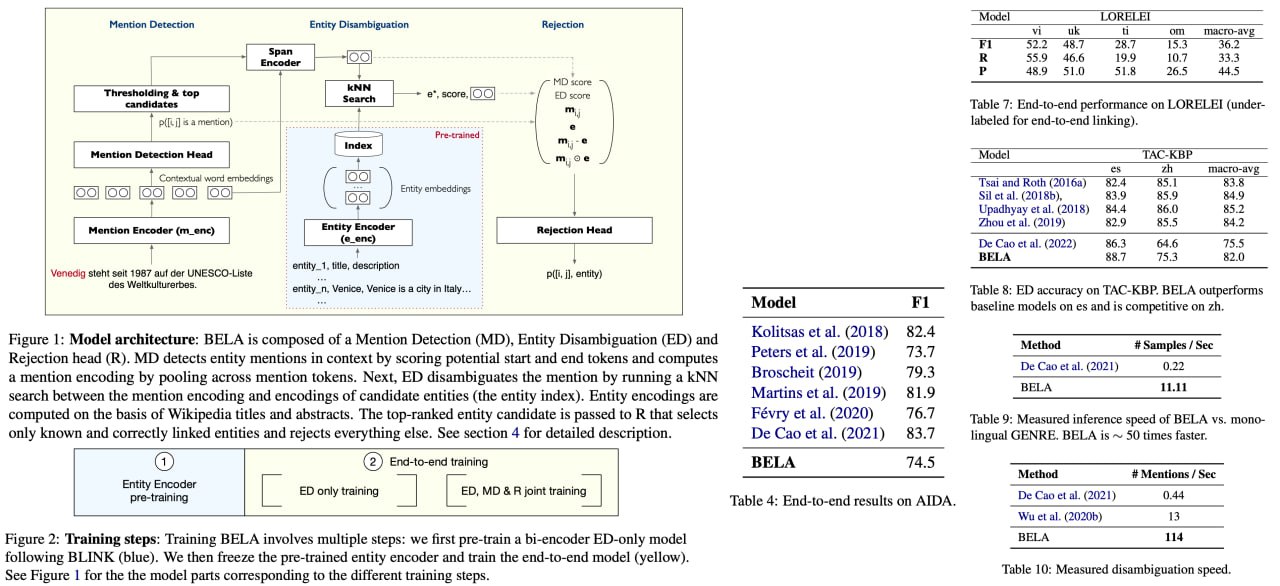
Introducing BELA, an unprecedented, open-source solution that is set to revolutionize the Natural Language Processing (NLP) arena! BELA addresses the complex challenge of Entity Linking, a task prevalent in many practical applications, by offering the very first fully end-to-end multilingual model. Astoundingly, it can efficiently identify and link entities in texts across an expansive range of 97 languages, a capability hitherto unseen. This marks a significant leap towards streamlining complex model stacks that have been a pervasive issue in the field.
BELA's architectural novelty lies in its adoption of a bi-encoder design. This enables it to conduct end-to-end linking of a passage in a single forward pass through a transformer, regardless of the number of entity mentions it contains. In its core Entity Disambiguation sub-task, it cleverly deploys a k-nearest neighbor (kNN) search using an encoded mention as a query in an entity index. What's even more impressive is BELA's scalability—it handles up to 16 million entities and delivers a remarkable throughput of 53 samples per second on a single GPU.
Paper link: https://arxiv.org/abs/2306.08896
Code link: https://github.com/facebookresearch/BELA
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-bela
#deeplearning #nlp #entitylinking #multilingual
Introducing BELA, an unprecedented, open-source solution that is set to revolutionize the Natural Language Processing (NLP) arena! BELA addresses the complex challenge of Entity Linking, a task prevalent in many practical applications, by offering the very first fully end-to-end multilingual model. Astoundingly, it can efficiently identify and link entities in texts across an expansive range of 97 languages, a capability hitherto unseen. This marks a significant leap towards streamlining complex model stacks that have been a pervasive issue in the field.
BELA's architectural novelty lies in its adoption of a bi-encoder design. This enables it to conduct end-to-end linking of a passage in a single forward pass through a transformer, regardless of the number of entity mentions it contains. In its core Entity Disambiguation sub-task, it cleverly deploys a k-nearest neighbor (kNN) search using an encoded mention as a query in an entity index. What's even more impressive is BELA's scalability—it handles up to 16 million entities and delivers a remarkable throughput of 53 samples per second on a single GPU.
Paper link: https://arxiv.org/abs/2306.08896
Code link: https://github.com/facebookresearch/BELA
A detailed unofficial overview of the paper: https://andlukyane.com/blog/paper-review-bela
#deeplearning #nlp #entitylinking #multilingual
{kind=link}