
XGLUE: A New Benchmark Dataset
for Cross-lingual Pre-training, Understanding and Generation
Introduced XGLUE as a new benchmark dataset to train large-scale cross-lingual pre-trained models using multilingual and bilingual corpora, and evaluate their performance across a diverse set of cross-lingual tasks.
Comparing to GLUE (Wangetal., 2019), which is labeled in English and includes natural language understanding tasks only, XGLUE has three main advantages:
[0] it provides two corpora with different sizes for cross-lingual pretraining
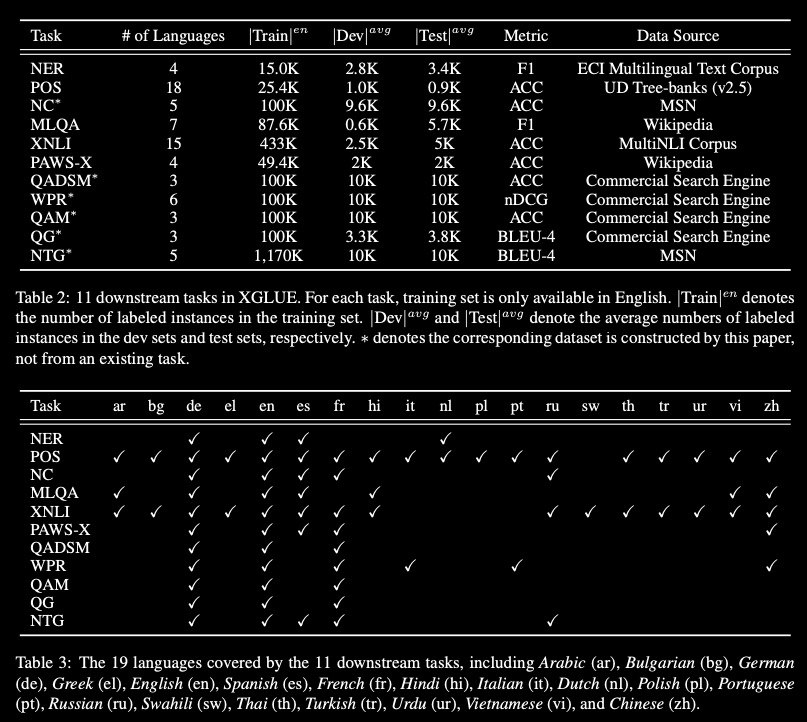
[1] it provides 11 diversified tasks that cover both natural language understanding and generation scenarios
[2] for each task, it provides labeled data in multiple languages.
The authors extend a recent cross-lingual pre-trained model Unicoder (Huang et al., 2019) to cover both understanding and generation tasks, which is evaluated on XGLUE as a strong baseline.
Also, they evaluate the base versions (12-layer) of Multilingual BERT, XLM, and XLM-R for comparison.
paper: https://arxiv.org/abs/2004.01401.pdf
#nlp #glue #multilingual #bilingual #xglue
for Cross-lingual Pre-training, Understanding and Generation
Introduced XGLUE as a new benchmark dataset to train large-scale cross-lingual pre-trained models using multilingual and bilingual corpora, and evaluate their performance across a diverse set of cross-lingual tasks.
Comparing to GLUE (Wangetal., 2019), which is labeled in English and includes natural language understanding tasks only, XGLUE has three main advantages:
[0] it provides two corpora with different sizes for cross-lingual pretraining
[1] it provides 11 diversified tasks that cover both natural language understanding and generation scenarios
[2] for each task, it provides labeled data in multiple languages.
The authors extend a recent cross-lingual pre-trained model Unicoder (Huang et al., 2019) to cover both understanding and generation tasks, which is evaluated on XGLUE as a strong baseline.
Also, they evaluate the base versions (12-layer) of Multilingual BERT, XLM, and XLM-R for comparison.
paper: https://arxiv.org/abs/2004.01401.pdf
#nlp #glue #multilingual #bilingual #xglue
{kind=link}