
Open-source library provides explanation for machine learning through diverse counterfactuals
This is a development of #interpretable ML. Library to explore “what-if” scenarios for ML models.
Blog post: https://www.microsoft.com/en-us/research/blog/open-source-library-provides-explanation-for-machine-learning-through-diverse-counterfactuals/
Paper: https://www.microsoft.com/en-us/research/publication/explaining-machine-learning-classifiers-through-diverse-counterfactual-examples/
Github: https://github.com/microsoft/dice
#Microsoft #ML #opensource
This is a development of #interpretable ML. Library to explore “what-if” scenarios for ML models.
Blog post: https://www.microsoft.com/en-us/research/blog/open-source-library-provides-explanation-for-machine-learning-through-diverse-counterfactuals/
Paper: https://www.microsoft.com/en-us/research/publication/explaining-machine-learning-classifiers-through-diverse-counterfactual-examples/
Github: https://github.com/microsoft/dice
#Microsoft #ML #opensource
Microsoft Research
DiCE: Employing counterfactuals to explain machine learning algorithms
Microsoft researchers & collaborators created an open-source library to explore “what-if” scenarios for machine learning models. Learn how their method generates multiple diverse counterfactuals at once & gives insight into ML algorithm decision making.
Data Science by ODS.ai 🦜
We have collected 26 responses so far, which gives us 2% conversion rate. Please invest your time in filling in the form, it is to your benefit as reader. This is especially important if you might find yourself under-represented in the questionnaire results…
👏Right after the request in channel, number of responses spiked to 70!
Thank you for all your time, but to-date 150 responses are not enough to be statistically correct representation of our audience.
Please, fill in the questionnaire form. Please, invest some of your time into the filling the form, because it will be very benefitial to the channel and audience.
Especially, if you are not that often reader, because you can be under-represented in this poll!
This is you chance to influence channel policy, don’t lose it, vote:
https://forms.gle/BzueRFAw3WFS8uk67
Thank you for all your time, but to-date 150 responses are not enough to be statistically correct representation of our audience.
Please, fill in the questionnaire form. Please, invest some of your time into the filling the form, because it will be very benefitial to the channel and audience.
Especially, if you are not that often reader, because you can be under-represented in this poll!
This is you chance to influence channel policy, don’t lose it, vote:
https://forms.gle/BzueRFAw3WFS8uk67
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday at 10:30 (some people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts. We are expecting from 8 to 14 people.
An autonomous AI racecar using NVIDIA Jetson Nano
Usually DS means some blue collar work. Rare cases suggest physical interactions. This set by #NVidia allows to build $400/$600 toy car capable of #selfdriving.
#JetRacer comes with a couple examples to get you up and running. The examples are in the format of Jupyter Notebooks, which are interactive documents which combine text, code, and visualization. Once you've completed the notebooks, start tweaking them to create your own racing software!
Github: https://github.com/NVIDIA-AI-IOT/jetracer
#autonomousvehicle #rl #jupyter #physical
Usually DS means some blue collar work. Rare cases suggest physical interactions. This set by #NVidia allows to build $400/$600 toy car capable of #selfdriving.
#JetRacer comes with a couple examples to get you up and running. The examples are in the format of Jupyter Notebooks, which are interactive documents which combine text, code, and visualization. Once you've completed the notebooks, start tweaking them to create your own racing software!
Github: https://github.com/NVIDIA-AI-IOT/jetracer
#autonomousvehicle #rl #jupyter #physical
Nomadlist Open Data portal
#OpenStartup is a concept of sharing usually private business data and KPIs. Nomadlist is a great example of this concept, sharing yearly revenue, and most importantly, valuable insights, like the auto-refund data.
#OpenData Portal: https://nomadlist.com/open
Auto-refund thread: https://twitter.com/levelsio/status/1222444905244479489
Nomadlist URL: https://nomadlist.com
#OpenStartup is a concept of sharing usually private business data and KPIs. Nomadlist is a great example of this concept, sharing yearly revenue, and most importantly, valuable insights, like the auto-refund data.
#OpenData Portal: https://nomadlist.com/open
Auto-refund thread: https://twitter.com/levelsio/status/1222444905244479489
Nomadlist URL: https://nomadlist.com
{kind=link}
A new approach for NER on partially labeled datasets.
One of the common problems with NER modeling is the lack of datasets covering all required slot types. Often there are several datasets that have labels for different entities.
The key idea of the paper is using multi-task transformer-based architecture on multiple datasets.
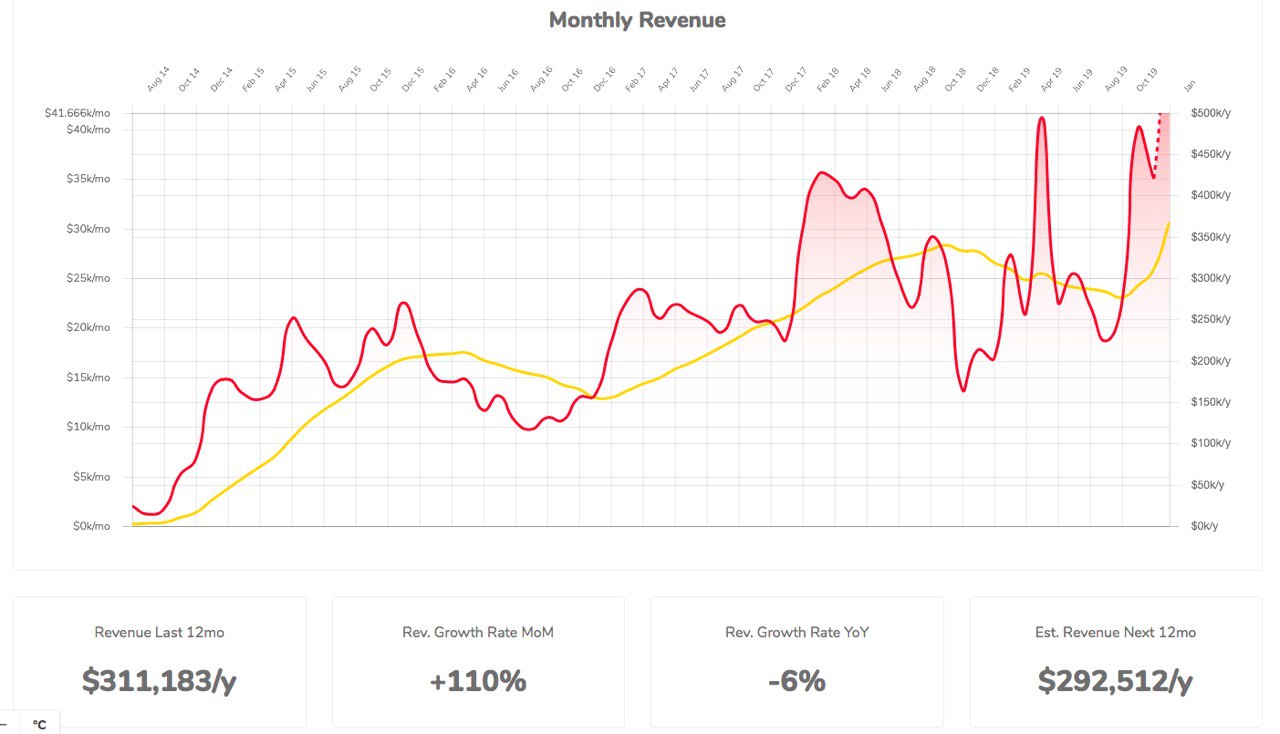
The model architecture looks like this:
- lexicon encoder layer (input is tokens with words, position and segment embeddings);
- transformer encoder, which generates the shared contextual embedding vectors;
- separate heads for each dataset.
During the training phase, it is necessary to not only train the task-dependent layers but also to fine-tune the shared language model.
Experiments were conducted on four datasets using a single Tesla K80. A single multi-task model (iterating over datasets) shows SOTA results and trains faster than separate models for each task.
Paper: https://arxiv.org/abs/2001.08904
#nlp #bert #ner #biomedical
MT-BioNER: Multi-task Learning for Biomedical Named EntityRecognition using Deep Bidirectional TransformersA new approach for NER on partially labeled datasets.
One of the common problems with NER modeling is the lack of datasets covering all required slot types. Often there are several datasets that have labels for different entities.
The key idea of the paper is using multi-task transformer-based architecture on multiple datasets.
The model architecture looks like this:
- lexicon encoder layer (input is tokens with words, position and segment embeddings);
- transformer encoder, which generates the shared contextual embedding vectors;
- separate heads for each dataset.
During the training phase, it is necessary to not only train the task-dependent layers but also to fine-tune the shared language model.
Experiments were conducted on four datasets using a single Tesla K80. A single multi-task model (iterating over datasets) shows SOTA results and trains faster than separate models for each task.
Paper: https://arxiv.org/abs/2001.08904
#nlp #bert #ner #biomedical
{kind=link}
HiPlot: High-dimensional interactive plots made easy
Interactive parameters' performance #visualization tool. This new Facebook AI's release enables researchers to more easily evaluate the influence of their hyperparameters, such as learning rate, regularizations, and architecture.
Link: https://ai.facebook.com/blog/hiplot-high-dimensional-interactive-plots-made-easy
Github: https://github.com/facebookresearch/hiplot
Demo: https://facebookresearch.github.io/hiplot/_static/demo/demo_basic_usage.html
Pip:
#hyperopt #facebook #opensource
Interactive parameters' performance #visualization tool. This new Facebook AI's release enables researchers to more easily evaluate the influence of their hyperparameters, such as learning rate, regularizations, and architecture.
Link: https://ai.facebook.com/blog/hiplot-high-dimensional-interactive-plots-made-easy
Github: https://github.com/facebookresearch/hiplot
Demo: https://facebookresearch.github.io/hiplot/_static/demo/demo_basic_usage.html
Pip:
pip install hiplot#hyperopt #facebook #opensource
SGLB: Stochastic Gradient Langevin Boosting
In this paper, the authors introduce Stochastic Gradient Langevin Boosting (SGLB) – a powerful and efficient ML framework, which may deal with a wide range of loss functions and has provable generalization guarantees. The method is based on a special form of Langevin Diffusion equation specifically designed for gradient boosting. This allows guarantee the global convergence, while standard gradient boosting algorithms can guarantee only local optima, which is a problem for multimodal loss functions. To illustrate the advantages of SGLB, they apply it to a classification task with
The algorithm is implemented as a part of the CatBoost gradient boosting library and outperforms classic gradient boosting methods.
paper: https://arxiv.org/abs/2001.07248
release: https://github.com/catboost/catboost/releases/tag/v0.21
#langevin #boosting #catboost
In this paper, the authors introduce Stochastic Gradient Langevin Boosting (SGLB) – a powerful and efficient ML framework, which may deal with a wide range of loss functions and has provable generalization guarantees. The method is based on a special form of Langevin Diffusion equation specifically designed for gradient boosting. This allows guarantee the global convergence, while standard gradient boosting algorithms can guarantee only local optima, which is a problem for multimodal loss functions. To illustrate the advantages of SGLB, they apply it to a classification task with
0-1 loss function, which is known to be multimodal, and to a standard Logistic regression task that is convex.The algorithm is implemented as a part of the CatBoost gradient boosting library and outperforms classic gradient boosting methods.
paper: https://arxiv.org/abs/2001.07248
release: https://github.com/catboost/catboost/releases/tag/v0.21
#langevin #boosting #catboost
{kind=link}
Data Science by ODS.ai 🦜
🔝Great OpenDataScience Channel Audience Research The first audience research was done on 25.06.18 and it is time to update our knowledge on what are we. Please fill in this form: https://forms.gle/GGNgukYNQbAZPtmk8 all the collected data will be used to…
👏After the weekend total number of collected responses is 222.
Thank you for the answers, but we still need more data to make any decisions about channel policy. If you still haven’t filled in the form, please do so.
We need your opinion, we need to know more, we need you!
Google form: https://forms.gle/GGNgukYNQbAZPtmk8
Thank you for the answers, but we still need more data to make any decisions about channel policy. If you still haven’t filled in the form, please do so.
We need your opinion, we need to know more, we need you!
Google form: https://forms.gle/GGNgukYNQbAZPtmk8
Google Docs
@opendatascience audience research 2020
Hey, this is a form to study the audience of our channel to post more relevant and interesting content for you. Please fill in.
However, first question with residence country is not obligatory, channel administration will highly appreciate any answers, for…
However, first question with residence country is not obligatory, channel administration will highly appreciate any answers, for…
+22 responses 💪 !
Thank you!
30% of audience are in GMT+3 for now.
To make analysis of audience more reliable, diverse and robust, we need more respondents from other timezones.
Vote for diversity!
Google form: https://forms.gle/GGNgukYNQbAZPtmk8
Thank you!
30% of audience are in GMT+3 for now.
To make analysis of audience more reliable, diverse and robust, we need more respondents from other timezones.
Vote for diversity!
Google form: https://forms.gle/GGNgukYNQbAZPtmk8
Microsoft Research 2019 reflection—a year of progress on technology’s toughest challenges
Highlights:
* MT-DNN — a model for learning universal language embeddings that combines the multi-task learning and the language model pre-training of BERT.
* Guidelines for human-AI interaction design
* AirSim, coming from strong MS background with flight simulations, for AI realisting testing environment.
* Sand Dance, a data visualization tool included in Visual Studio Code
* Icecaps — a toolkit for conversation modeling
Link: https://www.microsoft.com/en-us/research/blog/microsoft-research-2019-reflection-a-year-of-progress-on-technologys-toughest-challenges/
#microsoft #yearinreview
Highlights:
* MT-DNN — a model for learning universal language embeddings that combines the multi-task learning and the language model pre-training of BERT.
* Guidelines for human-AI interaction design
* AirSim, coming from strong MS background with flight simulations, for AI realisting testing environment.
* Sand Dance, a data visualization tool included in Visual Studio Code
* Icecaps — a toolkit for conversation modeling
Link: https://www.microsoft.com/en-us/research/blog/microsoft-research-2019-reflection-a-year-of-progress-on-technologys-toughest-challenges/
#microsoft #yearinreview
Microsoft Research
Microsoft Research 2019 reflection—a year of progress on technology’s toughest challenges
In 2019, Microsoft researchers assembled guidelines for human-AI interaction design, explored gender bias in machine learning, and created numerous technologies that improved accessibility. Learn how these advances emphasize inclusivity.
Top Trends of Graph Machine Learning in 2020
In this blogpost the author shares an overview of ICLR 2020 papers on Graph Machine Learning and highlights several trends:
1. More solid theoretical understanding of GNN:
* the dimension of the node embeddings should be proportional to the size of the graph if we want GNN being able to compute a solution to popular graph problems
* under certain conditions on the weights, GCNs cannot learn anything except node degrees and connected components when the number of layers grows
* a certain readout operation after neighborhood aggregation could help capture different types of node classification
2. New cool applications of GNN:
* a way to detect and fix bugs simultaneously in Javascript code
* inferring the types of variables for languages like Python or TypeScript
* reasoning in IQ-like tests (Raven Progressive Matrices (RPM) and Diagram Syllogism (DS)) with GNNs
* an RL algorithm to optimize the cost of TensorFlow computation graphs
3. Knowledge graphs become more popular:
* an idea to embed a query into a latent space not as a single point, but as a rectangular box
* a way to work with numerical entities and rules
* the re-evaluation of the existing models and how do they perform in a fair environment
4. New frameworks for graph embeddings:
* a way to improve running time and accuracy in node classification problem for any unsupervised embedding method
* a simple baseline that does not utilize a topology of the graph (i.e. it works on the aggregated node features) performs on par with the SOTA GNNs
blog post:
https://towardsdatascience.com/top-trends-of-graph-machine-learning-in-2020-1194175351a3
#ICLR #gnn #graphs
In this blogpost the author shares an overview of ICLR 2020 papers on Graph Machine Learning and highlights several trends:
1. More solid theoretical understanding of GNN:
* the dimension of the node embeddings should be proportional to the size of the graph if we want GNN being able to compute a solution to popular graph problems
* under certain conditions on the weights, GCNs cannot learn anything except node degrees and connected components when the number of layers grows
* a certain readout operation after neighborhood aggregation could help capture different types of node classification
2. New cool applications of GNN:
* a way to detect and fix bugs simultaneously in Javascript code
* inferring the types of variables for languages like Python or TypeScript
* reasoning in IQ-like tests (Raven Progressive Matrices (RPM) and Diagram Syllogism (DS)) with GNNs
* an RL algorithm to optimize the cost of TensorFlow computation graphs
3. Knowledge graphs become more popular:
* an idea to embed a query into a latent space not as a single point, but as a rectangular box
* a way to work with numerical entities and rules
* the re-evaluation of the existing models and how do they perform in a fair environment
4. New frameworks for graph embeddings:
* a way to improve running time and accuracy in node classification problem for any unsupervised embedding method
* a simple baseline that does not utilize a topology of the graph (i.e. it works on the aggregated node features) performs on par with the SOTA GNNs
blog post:
https://towardsdatascience.com/top-trends-of-graph-machine-learning-in-2020-1194175351a3
#ICLR #gnn #graphs
{kind=link}
First movie ever upscaled and enhanced by couple of neural networks
Arrival of a Train at La Ciotat upscaled and upscaled to 4K 60 FPS
Algorithms that were used:
* Gigapixel AI by Topaz Labs for upscale
* FPS enhancement — Dain
Author on YouTube promises to experiment on the colorization and to release the update later.
YouTube: https://m.youtube.com/watch?v=3RYNThid23g
Author’s channel (in Russian): @denissexy
#upscale #dl #videoprocessing
Arrival of a Train at La Ciotat upscaled and upscaled to 4K 60 FPS
Algorithms that were used:
* Gigapixel AI by Topaz Labs for upscale
* FPS enhancement — Dain
Author on YouTube promises to experiment on the colorization and to release the update later.
YouTube: https://m.youtube.com/watch?v=3RYNThid23g
Author’s channel (in Russian): @denissexy
#upscale #dl #videoprocessing
Using ‘radioactive data’ to detect if a data set was used for training
The authors have developed a new technique to mark the images in a data set so that researchers can determine whether a particular machine learning model has been trained using those images. This can help researchers and engineers to keep track of which data set was used to train a model so they can better understand how various data sets affect the performance of different neural networks.
The key points:
- the marks are harmless and have no impact on the classification accuracy of models, but are detectable with high confidence in a neural network;
- the image features are moved in a particular direction (the carrier) that has been sampled randomly and independently of the data
- after a model is trained on such data, its classifier will align with the direction of the carrier
- the method works in such a way that it is difficult to detect whether a data set is radioactive and to remove the marks from the trained model.
blogpost: https://ai.facebook.com/blog/using-radioactive-data-to-detect-if-a-data-set-was-used-for-training/
paper: https://arxiv.org/abs/2002.00937
#cv #cnn #datavalidation #image #data
The authors have developed a new technique to mark the images in a data set so that researchers can determine whether a particular machine learning model has been trained using those images. This can help researchers and engineers to keep track of which data set was used to train a model so they can better understand how various data sets affect the performance of different neural networks.
The key points:
- the marks are harmless and have no impact on the classification accuracy of models, but are detectable with high confidence in a neural network;
- the image features are moved in a particular direction (the carrier) that has been sampled randomly and independently of the data
- after a model is trained on such data, its classifier will align with the direction of the carrier
- the method works in such a way that it is difficult to detect whether a data set is radioactive and to remove the marks from the trained model.
blogpost: https://ai.facebook.com/blog/using-radioactive-data-to-detect-if-a-data-set-was-used-for-training/
paper: https://arxiv.org/abs/2002.00937
#cv #cnn #datavalidation #image #data
{kind=link}
ODS breakfast in Paris! ☕️ 🇫🇷 See you this Saturday at 10:30 (some people come around 11:00) at Malongo Café, 50 Rue Saint-André des Arts. We are expecting from 9 to 19 people. Tableoverflow 💥 is possible.
REST: Robust and Efficient Neural Networks for Sleep Monitoring in the Wild
New approach for sleep monitoring.
Nowadays a lot of people suffer from sleep disorders thataffects their daily functioning, long-term health and longevity. Thelong-term effects of sleep deprivation and sleep disorders includean increased risk of hypertension, diabetes, obesity, depression, heart attack, and stroke. As a result sleep monitoring is a very important topic.
Currently automatical documentation of sleep stages isn't robust against noises (which can be introduced by electrical interferences (e.g., power-line) and user motions (e.g., muscle contraction, respiration)) and isn't computationaly efficient enough for fast calculations on user devices.
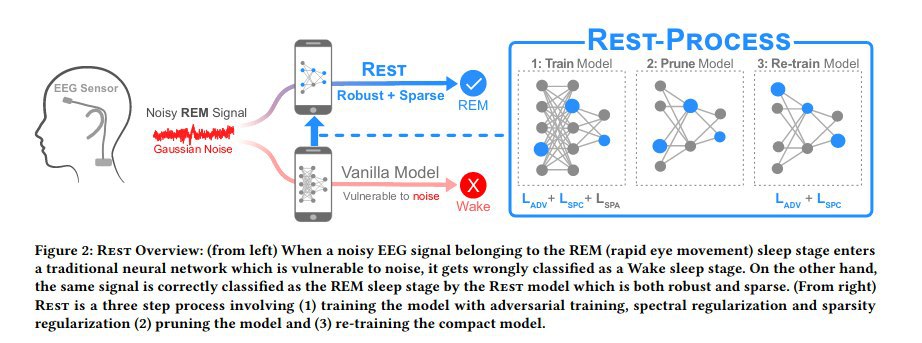
The authors offer the following improvenents:
- adversarial training and spectral regularization to improve robustness to noise
- sparsity regularization to improve energy and computational efficiency
Rest models achieves a macro-F1 score of 0.67 vs. 0.39 for the state-of-the-art model in the presence of Gaussian noise, with 19×parameter and 15×MFLOPS reduction.
The model is also deployed onto a Pixel 2 smartphone. It achieves 17x energy reduction and 9x faster inference compared to uncompressed models.
Paper: https://arxiv.org/abs/2001.11363
Code: https://github.com/duggalrahul/REST
#deeplearning #compression #adversarial #sleepstaging
New approach for sleep monitoring.
Nowadays a lot of people suffer from sleep disorders thataffects their daily functioning, long-term health and longevity. Thelong-term effects of sleep deprivation and sleep disorders includean increased risk of hypertension, diabetes, obesity, depression, heart attack, and stroke. As a result sleep monitoring is a very important topic.
Currently automatical documentation of sleep stages isn't robust against noises (which can be introduced by electrical interferences (e.g., power-line) and user motions (e.g., muscle contraction, respiration)) and isn't computationaly efficient enough for fast calculations on user devices.
The authors offer the following improvenents:
- adversarial training and spectral regularization to improve robustness to noise
- sparsity regularization to improve energy and computational efficiency
Rest models achieves a macro-F1 score of 0.67 vs. 0.39 for the state-of-the-art model in the presence of Gaussian noise, with 19×parameter and 15×MFLOPS reduction.
The model is also deployed onto a Pixel 2 smartphone. It achieves 17x energy reduction and 9x faster inference compared to uncompressed models.
Paper: https://arxiv.org/abs/2001.11363
Code: https://github.com/duggalrahul/REST
#deeplearning #compression #adversarial #sleepstaging
{kind=link}
P-value, explained, one more time with demos
Article includes not only great explanation of what is #pvalue, but how it works and how it can be used to make a correct conclusions.
Link:https://www.freecodecamp.org/news/what-is-statistical-significance-p-value-defined-and-how-to-calculate-it/
#entrylevel #dsformanagers #tutorial #explained #interactive #statistics
Article includes not only great explanation of what is #pvalue, but how it works and how it can be used to make a correct conclusions.
Link:https://www.freecodecamp.org/news/what-is-statistical-significance-p-value-defined-and-how-to-calculate-it/
#entrylevel #dsformanagers #tutorial #explained #interactive #statistics
freeCodeCamp.org
What is Statistical Significance? P Value Defined and How to Calculate It
By Peter Gleeson P values are one of the most widely used concepts in statistical analysis. They are used by researchers, analysts and statisticians to draw insights from data and make informed decisions. Along with statistical significance, they are...
Please vote in our Mega Imprtant Audience Research!
So far we have collected 384 responses, which is really cool!
But we need more filled questinnaires to know YOU and YOUR PREFERENCES better.
Some to-date data about residency:
* 🇮🇹 There are 4.5% of people who reside in Italy
* 🇧🇷 Brazil — 3.2%
* 🇫🇷 France — 1.9%
* 🇳🇬 Nigeria — 1.1%
* 🇪🇸 Spain — 5.6%
Please, fill in the form https://forms.gle/GGNgukYNQbAZPtmk8 to help us provide better and more relevant content for you!
So far we have collected 384 responses, which is really cool!
But we need more filled questinnaires to know YOU and YOUR PREFERENCES better.
Some to-date data about residency:
* 🇮🇹 There are 4.5% of people who reside in Italy
* 🇧🇷 Brazil — 3.2%
* 🇫🇷 France — 1.9%
* 🇳🇬 Nigeria — 1.1%
* 🇪🇸 Spain — 5.6%
Please, fill in the form https://forms.gle/GGNgukYNQbAZPtmk8 to help us provide better and more relevant content for you!
Google Docs
@opendatascience audience research 2020
Hey, this is a form to study the audience of our channel to post more relevant and interesting content for you. Please fill in.
However, first question with residence country is not obligatory, channel administration will highly appreciate any answers, for…
However, first question with residence country is not obligatory, channel administration will highly appreciate any answers, for…