
Правила константности
#новичкам
Константность - важное свойство сущности в коде. Оно не только позволяет обезопасить объекты от изменения, но еще и говорит программисту о гарантиях, которые дает та или иная функция. Допустим, принимая параметр по константной ссылке, функция говорит программисту: "расслабься, ничего я не сделаю с твоим объектом". Это повышает читаемость кода.
В С++ много чего можно сделать константным. Объекты, указатели, ссылки, параметры функции, методы класса и тд. И зачастую новичкам сложно разобраться в правилах присваивания константности. Сегодня разберемся в этом.
Не будем долго задерживаться над константными методами. Константные объекты могут вызвать только константные методы. Все. Синтаксис такой:
Теперь и константные, и неконстантные объекты могут вызывать метод Method.
Дальше все так или иначе сводится к правилам в объявлении переменных. Что в качестве поля класса, параметра функции, что объявлении обычной переменной - разницы нет. Правила одни. Поехали.
Константный объект можно объявить двумя способами:
Эти записи абсолютно эквивалентны! Это очень важно запомнить, потому что при разговоре о ссылках и указателях это играет большую роль.
Собственно также есть 2 нотации объявления массивов констант:
И 2 нотации определения ссылок:
Помните, что при создании ссылки в скоупе функции вы обязаны ее инициализировать.
При объявлении поля класса этого делать не обязательно, потому что вы не создаете объект прямо сейчас. Но вы обязаны инициализировать ссылку до входа в конструктор либо через список инициализации конструктора, либо через default member initializer, так как базового поля класса иницализируются до входа в конструктор.
При объявлении параметра функции тоже не нужно сразу инициализировать ссылку, потому что функция принимает уже существующую и инициализированую ссылку на вход.
Обычно при таком объявлении ссылку называют константной. Это не совсем верно. Ссылка при любых обстоятельствах сама по себе является константной. Как только вы забиндили ссылку на объект, она всегда будет смотреть на этот объект и изменять его. Более подробно про особенности ссылок посмотреть тут. При новом присваивании ссылки вызовется оператор присваивания и изменится существующий объект.
Когда говорят "константная ссылка" имеют ввиду ссылку на константу. И при любом виде объявления const T& ref или T const & ref она также будет ссылкой на константу.
Теперь указатели. Наверное самое сложное из всего перечисленного. Указатели, в отличии от ссылок, сами могут быть константными, да еще и указывать на константные объекты. А еще могут быть многоуровненые указатели. В общем сложно. Но есть правило: при объявлении указателя каждое появление ключевого слова const относится к тому уровню вложенности, который находится слева от этого слова. Вы просто читаете объявление справа налево и получаете правильное понимание объявления. Примеры:
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
Rely on fixed thing in your life. Stay cool.
#cppcore
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
#новичкам
Константность - важное свойство сущности в коде. Оно не только позволяет обезопасить объекты от изменения, но еще и говорит программисту о гарантиях, которые дает та или иная функция. Допустим, принимая параметр по константной ссылке, функция говорит программисту: "расслабься, ничего я не сделаю с твоим объектом". Это повышает читаемость кода.
В С++ много чего можно сделать константным. Объекты, указатели, ссылки, параметры функции, методы класса и тд. И зачастую новичкам сложно разобраться в правилах присваивания константности. Сегодня разберемся в этом.
Не будем долго задерживаться над константными методами. Константные объекты могут вызвать только константные методы. Все. Синтаксис такой:
void Class::Method(Type1 param1, Type2 param2) const {}Теперь и константные, и неконстантные объекты могут вызывать метод Method.
Дальше все так или иначе сводится к правилам в объявлении переменных. Что в качестве поля класса, параметра функции, что объявлении обычной переменной - разницы нет. Правила одни. Поехали.
Константный объект можно объявить двумя способами:
const T obj;
// Либо
T const obj;
Эти записи абсолютно эквивалентны! Это очень важно запомнить, потому что при разговоре о ссылках и указателях это играет большую роль.
Собственно также есть 2 нотации объявления массивов констант:
const T arr[5];
// либо
T const arr[5];
И 2 нотации определения ссылок:
const T& ref;
// либо
T const & ref;
Помните, что при создании ссылки в скоупе функции вы обязаны ее инициализировать.
При объявлении поля класса этого делать не обязательно, потому что вы не создаете объект прямо сейчас. Но вы обязаны инициализировать ссылку до входа в конструктор либо через список инициализации конструктора, либо через default member initializer, так как базового поля класса иницализируются до входа в конструктор.
При объявлении параметра функции тоже не нужно сразу инициализировать ссылку, потому что функция принимает уже существующую и инициализированую ссылку на вход.
Обычно при таком объявлении ссылку называют константной. Это не совсем верно. Ссылка при любых обстоятельствах сама по себе является константной. Как только вы забиндили ссылку на объект, она всегда будет смотреть на этот объект и изменять его. Более подробно про особенности ссылок посмотреть тут. При новом присваивании ссылки вызовется оператор присваивания и изменится существующий объект.
struct Type {
Type& operator=(const Type& other) {
std::cout << "copy assign" << std::endl;
return *this;
}
};
Type a{};
Type& b = a;
b = Type{};
// OUTPUT:
// copy assignКогда говорят "константная ссылка" имеют ввиду ссылку на константу. И при любом виде объявления const T& ref или T const & ref она также будет ссылкой на константу.
Теперь указатели. Наверное самое сложное из всего перечисленного. Указатели, в отличии от ссылок, сами могут быть константными, да еще и указывать на константные объекты. А еще могут быть многоуровненые указатели. В общем сложно. Но есть правило: при объявлении указателя каждое появление ключевого слова const относится к тому уровню вложенности, который находится слева от этого слова. Вы просто читаете объявление справа налево и получаете правильное понимание объявления. Примеры:
// Читаем справа налево
int * const ptr; // ptr - это константный указатель на инт
int * * const ptr; // ptr - это константный указатель на указатель на инт
int * const * const ptr; // ptr - это константный указатель на константный указатель на инт
// Самый низкий уровень, который относится к самому объекту,
// можно писать двумя способами, о которых мы говорили выше
int const * const * * const ptr; // ptr - это константный указатель на указатель
// на константный указатель на интовую константу
const int * const * * const ptr; // Тоже самое
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
Rely on fixed thing in your life. Stay cool.
#cppcore
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
{kind=link}
Шаблонный сеттер
#опытным
Увидел на ревью интересный кейс. Мы о нем уже говорили, что не сильно акцентировали внимание. Сегодня больше времени уделим одному интересному явлению.
Если у вас есть какой-то шаблонный класс, который хранит тип Т, и в этом классе есть сеттер на этот тип, то по давней привычке(еще с 98 стандарта) его можно написать вот так:
Привычка - дело хорошее и экономит ресурс мозга на выполнение действий. Не так много когнитивного внимания нужно тратить на деятельность.
Но иногда привычки ограничивают нас. Мы-то уже в modern C++ эре. И в данном случае как раз такой кейс.
Что будет, если мы захотим передать в этот метод временный объект? Например так:
На экран выведется:
Это значит, что даже если мы передаем в такой сеттер временный объект, у которого можно забрать его ресурсы и сэкономить на копировании, мы все равно не получаем этих бенефитов.
Потому что в сеттере value уже относится к категории lvalue. А при присваивании объекта от lvalue будет вызываться копирующий оператор присваивания.
А нам бы хотелось, чтобы вызывался перемещающий оператор. Как этого достичь?
Использовать универсальную ссылку. Скажет прошаренный читатель.
Для шаблонного кода мы можем пометить параметр метода двумя амперсандами и дальше внутри передавать его во все места через std::forward. Таким образом, если нам на вход пришел именованный объект, то std::forward скастует его к lvalue ссылке, а если временный, то к rvalue ссылке. И это поможет нам в нужных случая вызывать правильный оператор присваивания. И std::forward и universal reference доступны с 11-го стандарта вместе с введением мув-семантики.
Теперь мы получаем нужный вывод:
Однако этот прошаренный читатель оказался не таким уж и прошаренным! Такая штука не сработает для шаблонных параметров класса!
Универсальная ссылка(она же forwarding reference) появляется только, когда тип параметра функции Т&& и Т - шаблонной параметр самой функции. В нашем случае нет никакого вывода - тип Т известен из класса. Поэтому и никакой универсальной ссылки не появляется.
Мы просто определили метод, который принимает rvalue ссылку. При попытке передать туда lvalue будет ошибка:
Какой выход? Просто рядышком с сеттером для константной lvalue ссылки написать сеттер для rvalue ссылки.
Тогда все нормально скомпилируется и в нужных места будут вызваны нужные операторы.
Stay universal. Stay cool.
#cpp11
#опытным
Увидел на ревью интересный кейс. Мы о нем уже говорили, что не сильно акцентировали внимание. Сегодня больше времени уделим одному интересному явлению.
Если у вас есть какой-то шаблонный класс, который хранит тип Т, и в этом классе есть сеттер на этот тип, то по давней привычке(еще с 98 стандарта) его можно написать вот так:
template <class T>
struct TemplateClass {
void SetValue(const T& value) {
value_ = value;
}
private:
T value_;
};
Привычка - дело хорошее и экономит ресурс мозга на выполнение действий. Не так много когнитивного внимания нужно тратить на деятельность.
Но иногда привычки ограничивают нас. Мы-то уже в modern C++ эре. И в данном случае как раз такой кейс.
Что будет, если мы захотим передать в этот метод временный объект? Например так:
struct ShowConstruct {
ShowConstruct() = default;
ShowConstruct(int value) : field{value} {
std::cout << "Param construct " << field << std::endl;}
ShowConstruct& operator=(const ShowConstruct& other) {
field = other.field;
std::cout << "Copy assign " << field << std::endl;
return *this;}
ShowConstruct& operator=(ShowConstruct&& other) {
field = other.field;
std::cout << "Move assign " << field << std::endl;
return *this;}
int field = 0;
};
TemplateClass<ShowConstruct> obj;
obj.SetValue(ShowConstruct{5});На экран выведется:
Param construct 5
Copy assign 5
Это значит, что даже если мы передаем в такой сеттер временный объект, у которого можно забрать его ресурсы и сэкономить на копировании, мы все равно не получаем этих бенефитов.
Потому что в сеттере value уже относится к категории lvalue. А при присваивании объекта от lvalue будет вызываться копирующий оператор присваивания.
А нам бы хотелось, чтобы вызывался перемещающий оператор. Как этого достичь?
Использовать универсальную ссылку. Скажет прошаренный читатель.
Для шаблонного кода мы можем пометить параметр метода двумя амперсандами и дальше внутри передавать его во все места через std::forward. Таким образом, если нам на вход пришел именованный объект, то std::forward скастует его к lvalue ссылке, а если временный, то к rvalue ссылке. И это поможет нам в нужных случая вызывать правильный оператор присваивания. И std::forward и universal reference доступны с 11-го стандарта вместе с введением мув-семантики.
template <class T>
struct TemplateClass {
void SetValue(T&& value) {
value_ = std::forward<T>(value);
}
private:
T value_;
};
TemplateClass<ShowConstruct> obj;
obj.SetValue(ShowConstruct{5});
Теперь мы получаем нужный вывод:
Param construct 5
Move assign 5
Однако этот прошаренный читатель оказался не таким уж и прошаренным! Такая штука не сработает для шаблонных параметров класса!
in class template argument deduction, template parameter
of a class template is never a forwarding reference
Универсальная ссылка(она же forwarding reference) появляется только, когда тип параметра функции Т&& и Т - шаблонной параметр самой функции. В нашем случае нет никакого вывода - тип Т известен из класса. Поэтому и никакой универсальной ссылки не появляется.
Мы просто определили метод, который принимает rvalue ссылку. При попытке передать туда lvalue будет ошибка:
TemplateClass<ShowConstruct> obj;
ShowConstruct lvalue{7};
obj.SetValue(lvalue);
//ERROR: rvalue reference to type 'ShowConstruct'
// cannot bind to lvalue of type 'ShowConstruct'
Какой выход? Просто рядышком с сеттером для константной lvalue ссылки написать сеттер для rvalue ссылки.
template <class T>
struct TemplateClass {
void SetValue(const T& value) {
value_ = value;
}
void SetValue(T&& value) {
value_ = std::move(value);
}
private:
T value_;
};
TemplateClass<ShowConstruct> obj;
obj.SetValue(ShowConstruct{5});
ShowConstruct lvalue{7};
obj.SetValue(lvalue);
Тогда все нормально скомпилируется и в нужных места будут вызваны нужные операторы.
Stay universal. Stay cool.
#cpp11
{kind=link}
Swap idiom
Рассуждения в комментах под предыдущим постом навели меня на мысли рассказать о swap idiom.
Дело в том, что, когда у вас есть рабочие деструктор, конструктор копирования и перемещения, вы можете соединять методы, которые должны принимать константную lvalue ссылку и rvalue ссылку, в один метод, который принимает параметр по значению. То есть можно вместо 2-х методов сеттеров можно написать 1:
Этой же концепцией вдохновлено появление swap идиомы. На самом деле я немного вру, но с появлением мув-семантики идиома приобрела эти черты.
Суть в чем. Есть у вас класс, который мэнэджит какие-то ресурсы. Например самописный класс массива:
Все хорошо, но для выполнения правила 5 нам нужно определить еще и 2 оператора присваивания: перемещающий и копирующий. Обычно в них в начале очищают существующий объект и потом записываются новые данные. Покажу на примере копирующего оператора присваивания:
В такой реализации есть 3 проблемы:
❗️ Нам просто необходима проверка на самоприсвоение, чтобы в объекте остались те же данные. Но это настолько редкий кейс, что каждый раз при присвоении тратить время на проверку не очень хочется. А хочется операторы без этой проверки.
❗️ У нас есть только базовая гарантия исключений. Если из new бросится исключение, то состояние изменяемого объекта хоть и останется согласованным, но оно все равно изменится. А операция не завершится до конца. Хотелось бы строгой гарантии безопасности исключений.
❗️ Мы повторяем код. Помимо проверки самоприсваивания и очищения ресурсов тупо повторяется код копирующего конструктора. Хочется этого не делать.
Чтобы решить эти проблемы, мы можем сделать интересную штуку - принимать параметр оператора присваивания на обычное значение. Тогда на входе оператора у нас уже будет готовый скопированный(или перемещенный объект) и нам нужно будет лишь поменять содержимое этих двух объектов местами. И нам не нужно беспокоиться о том, что останется в параметре функции - он все равно удалится после выхода из нее. Теперь оператор будет выглядеть так:
Как же красиво! Нам осталось только реализовать функцию swap. Она может быть и методом класса, но почему бы еще не иметь просто функцию, которая свапает контент. Поэтому покажу реализацию дружественной функции.
Выглядит кратко, читаемо, да еще и исключений нет(об этом даже явно в коде можно сказать)! Ляпота.
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
Stay laconic. Stay cool.
#patter #cppcore #cpp11
Рассуждения в комментах под предыдущим постом навели меня на мысли рассказать о swap idiom.
Дело в том, что, когда у вас есть рабочие деструктор, конструктор копирования и перемещения, вы можете соединять методы, которые должны принимать константную lvalue ссылку и rvalue ссылку, в один метод, который принимает параметр по значению. То есть можно вместо 2-х методов сеттеров можно написать 1:
template <class T>
struct TemplateClass {
void SetValue(T value) {
value_ = std::move(value);
}
private:
T value_;
};
Этой же концепцией вдохновлено появление swap идиомы. На самом деле я немного вру, но с появлением мув-семантики идиома приобрела эти черты.
Суть в чем. Есть у вас класс, который мэнэджит какие-то ресурсы. Например самописный класс массива:
class SimpleArray
{
public:
SimpleArray(std::size_t size = 0)
: mSize(size),
mArray(mSize ? new intmSize : nullptr) {}
SimpleArray(const SimpleArray& other)
: mSize(other.mSize),
mArray(mSize ? new int[mSize] : nullptr) {
std::copy(other.mArray, other.mArray + mSize, mArray);
}
SimpleArray(simple_array&& other) noexcept
: mSize(other.mSize),
mArray(other.mArray) {other.mArray = nullptr;}
~SimpleArray()
{
delete [] mArray;
}
private:
std::size_t mSize;
int* mArray;
};
Все хорошо, но для выполнения правила 5 нам нужно определить еще и 2 оператора присваивания: перемещающий и копирующий. Обычно в них в начале очищают существующий объект и потом записываются новые данные. Покажу на примере копирующего оператора присваивания:
SimpleArray& operator=(const SimpleArray& other) {
if (this != &other) {
delete [] mArray;
mArray = nullptr;
mSize = 0;
mSize = other.mSize;
mArray = mSize ? new int[mSize] : nullptr;
std::copy(other.mArray, other.mArray + mSize, mArray);
}
return *this;
}В такой реализации есть 3 проблемы:
❗️ Нам просто необходима проверка на самоприсвоение, чтобы в объекте остались те же данные. Но это настолько редкий кейс, что каждый раз при присвоении тратить время на проверку не очень хочется. А хочется операторы без этой проверки.
❗️ У нас есть только базовая гарантия исключений. Если из new бросится исключение, то состояние изменяемого объекта хоть и останется согласованным, но оно все равно изменится. А операция не завершится до конца. Хотелось бы строгой гарантии безопасности исключений.
❗️ Мы повторяем код. Помимо проверки самоприсваивания и очищения ресурсов тупо повторяется код копирующего конструктора. Хочется этого не делать.
Чтобы решить эти проблемы, мы можем сделать интересную штуку - принимать параметр оператора присваивания на обычное значение. Тогда на входе оператора у нас уже будет готовый скопированный(или перемещенный объект) и нам нужно будет лишь поменять содержимое этих двух объектов местами. И нам не нужно беспокоиться о том, что останется в параметре функции - он все равно удалится после выхода из нее. Теперь оператор будет выглядеть так:
SimpleArray& operator=(SimpleArray other) noexcept {
swap(*this, other);
return *this;
}Как же красиво! Нам осталось только реализовать функцию swap. Она может быть и методом класса, но почему бы еще не иметь просто функцию, которая свапает контент. Поэтому покажу реализацию дружественной функции.
friend void swap(SimpleArray& first, SimpleArray& second) noexcept {
using std::swap;
swap(first.mSize, second.mSize);
swap(first.mArray, second.mArray);
}Выглядит кратко, читаемо, да еще и исключений нет(об этом даже явно в коде можно сказать)! Ляпота.
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
Stay laconic. Stay cool.
#patter #cppcore #cpp11
{kind=link}
Разбей пару яиц
Попалась на глаза интересная логическая задача, решил с вами тут поделиться. Мне понравилось, что в ней нет какого-то твиста или секретного приема, не зная которые до ответа не дойти. Все решается очень плавно, даже как будто бы итеративно.
Условие: у вас есть 2 яйца и 100 этажный дом. Яйца у вас очень крепкие(мы же плюсовики), поэтому если их сбрасывать из окон этого дома, то они не будут биться. Однако рано или поздно физика победит и, начиная с какого-то номера этажа N, яйца все-таки будут разбиваться. Вы можете перемещаться в доме вверх и вниз в любой последовательности. Какое минимальное количество бросков гарантировано понадобится, чтобы установить нужный этаж под номером N?
Знакомых с решением, прошу воздержаться от комментариев. Всех остальных призываю к обсуждению решения. Уверен, оно вам понравится своей красотой)
Ответ будет, как всегда вечером.
Хватит яйца мять, пора их разбивать!
Challenge yourself. Stay cool.
#задачки
Попалась на глаза интересная логическая задача, решил с вами тут поделиться. Мне понравилось, что в ней нет какого-то твиста или секретного приема, не зная которые до ответа не дойти. Все решается очень плавно, даже как будто бы итеративно.
Условие: у вас есть 2 яйца и 100 этажный дом. Яйца у вас очень крепкие(мы же плюсовики), поэтому если их сбрасывать из окон этого дома, то они не будут биться. Однако рано или поздно физика победит и, начиная с какого-то номера этажа N, яйца все-таки будут разбиваться. Вы можете перемещаться в доме вверх и вниз в любой последовательности. Какое минимальное количество бросков гарантировано понадобится, чтобы установить нужный этаж под номером N?
Знакомых с решением, прошу воздержаться от комментариев. Всех остальных призываю к обсуждению решения. Уверен, оно вам понравится своей красотой)
Ответ будет, как всегда вечером.
Хватит яйца мять, пора их разбивать!
Challenge yourself. Stay cool.
#задачки
Ответ
Буду описывать мои мысли, которые мне приходили в голову при решении.
Самое базовое, что надо понимать: если есть всего одно яйцо, то стратегия всегда одна - идти снизу вверх и подряд с каждого этажа скидывать, пока яйцо не разобьется.
Число 2 как бы намекает на то, что нужно что-то уполовинить. Но если мы сбросим с 50-го этажа и яйцо разобъется, это нам не сильно сократит задачу - придется в худшем случае еще 49 раз бросить.
Но можно шаги по-другому уполовинить - ходить через один этаж. Как только первое яйцо разобьется, можно пойти на этаж ниже и сбросить оттуда второе яйцо. Так мы точно определим нужный этаж. В этом случае мы гарантировано найдем нужный этаж за 51 бросок.
Той же логикой можно увеличивать шаг - идти через 3/4/5 и тд этажей. Тогда после того, как первое яйцо разобьется, мы пойдем с предыдущего посещенного этажа вверх и будем подряд бросать. Формула для нахождения гарантированного количества шагов c помощью такого методв - (100 // step) + (step - 1) - 1.
Путем нехитрых математико-алгебраических вычислений придем к тому, что оптимальный вариант - идти через 10 этажей. Да и число красивое. В этом случае мы сможем найти нужный этаж за 18 бросков.
Но оптимальное ли это решение?
Вообще говоря, нам очень нравится ходить через много этажей. Но не нравится потом много раз бросать после первого разбитого яйца.
Если не привязываться к гарантированности, то для малых N нам выгодно ходить с большим шагом. Потому что на поиски рэнджа этажей нам потребуется немного бросков. И этот фактор становится все менее важным, с увеличением N.
Можно было бы как-то соединить: ходить в начале с большим шагом, но с каждым броском первого яйца его уменьшать, пока нам вообще второе яйцо не понадобится или пока не наступит 100 этаж.
Так можно и соединить. Давайте с каждым броском первого яйца уменьшать шаг на 1 этаж. И к сотому этажу пусть у нас шаг уменьшится до минимума. Получается, что нам нужно начинать с шага в 14. После того, как бросили с 14-го, идем на 27. Потом на 39. И так далее.
Прикол в чем - нам всегда нужно будет максимум 14 бросков для нахождения нужного этажа.
Это и является ответом.
А я говорил, что задача красивая)
Solve your problems. Stay cool.
Буду описывать мои мысли, которые мне приходили в голову при решении.
Самое базовое, что надо понимать: если есть всего одно яйцо, то стратегия всегда одна - идти снизу вверх и подряд с каждого этажа скидывать, пока яйцо не разобьется.
Число 2 как бы намекает на то, что нужно что-то уполовинить. Но если мы сбросим с 50-го этажа и яйцо разобъется, это нам не сильно сократит задачу - придется в худшем случае еще 49 раз бросить.
Но можно шаги по-другому уполовинить - ходить через один этаж. Как только первое яйцо разобьется, можно пойти на этаж ниже и сбросить оттуда второе яйцо. Так мы точно определим нужный этаж. В этом случае мы гарантировано найдем нужный этаж за 51 бросок.
Той же логикой можно увеличивать шаг - идти через 3/4/5 и тд этажей. Тогда после того, как первое яйцо разобьется, мы пойдем с предыдущего посещенного этажа вверх и будем подряд бросать. Формула для нахождения гарантированного количества шагов c помощью такого методв - (100 // step) + (step - 1) - 1.
Путем нехитрых математико-алгебраических вычислений придем к тому, что оптимальный вариант - идти через 10 этажей. Да и число красивое. В этом случае мы сможем найти нужный этаж за 18 бросков.
Но оптимальное ли это решение?
Вообще говоря, нам очень нравится ходить через много этажей. Но не нравится потом много раз бросать после первого разбитого яйца.
Если не привязываться к гарантированности, то для малых N нам выгодно ходить с большим шагом. Потому что на поиски рэнджа этажей нам потребуется немного бросков. И этот фактор становится все менее важным, с увеличением N.
Можно было бы как-то соединить: ходить в начале с большим шагом, но с каждым броском первого яйца его уменьшать, пока нам вообще второе яйцо не понадобится или пока не наступит 100 этаж.
Так можно и соединить. Давайте с каждым броском первого яйца уменьшать шаг на 1 этаж. И к сотому этажу пусть у нас шаг уменьшится до минимума. Получается, что нам нужно начинать с шага в 14. После того, как бросили с 14-го, идем на 27. Потом на 39. И так далее.
Прикол в чем - нам всегда нужно будет максимум 14 бросков для нахождения нужного этажа.
Это и является ответом.
А я говорил, что задача красивая)
Solve your problems. Stay cool.
Swap idiom. Pros and cons
#опытным
В этом посте поговорили про суть swap идиомы. Сегодня обсудим ее плюсы и минусы.
Плюсы вроде как обсуждали, но я финализирую, когда можно рассмотреть внедрение swap idiom:
✅ Если у вас конструктор копирования может бросить исключение и вы можете написать небросающую функцию swap. Тогда за счет того, что захват ресурсов(копирование или перемещение во временный объект параметра функции) происходит до модификации текущего объекта, то мы получаем строгую гарантию безопасности исключений при работе с присваиванием объектов.
✅ Если вы хотите красивый, лаконичный и понятный код без повторений действий.
✅ Вы не очень беспокоитесь о потенциальных потерях производительности.
Погнали по минусам:
❗️ Не всегда можно написать nothrowing swap. Для базовых типов и указателей - да. Но swap нетривиальных типов использует временный объект. При создании которого и может возникнуть исключение. Сейчас swap делается с помощью перемещающих операций, но например в С++03 std::string мог кинуть исключение в копирующем конструкторе. Да и сейчас поля класса могут быть немувабельными и бросающими при копировании. Это надо иметь ввиду.
❗️ Каждый раз при присваивании мы выполняем 2 операции: конструктор копирования + swap или конструктор перемещения + swap. "Потери производительности" надо конечно тестить и смотреть реальные результаты, но в голове все равно надо держать потенциальные просадки.
❗️ Самостоятельно писать деструктор для менеджинга ресурсов в 2к24 - такая себе практика в большинстве случаев. Давно есть std::unique_ptr<T[]>, указатели с кастомными делитерами и прочие вещи. Одно из ключевых преимуществ идиомы - сокращение и переиспользование кода. Так вот с отсутствием деструктора вам вообще может не понадобится кастомное присваивание и вы сможете объявить операции дефолтными, поэтому надобность в идиоме сама по себе отпадет.
❗️❗️ Часто пропускаемый огромный минус: технически у нас есть оператор перемещения, который может принимать rvalue ссылки. Однако мы явным образом не реальзовывали присваивание перемещением, поэтому по правилу 5, компилятор не будет его генерировать за нас и у класса просто будет отсутствовать оператор присваивания перемещением.
И хоть текущий класс мы можем мэнэджить без присваивания перемещением, то ситуация изменится, когда мы сделаем текущий класс полем другого. Тогда у этого другого класса не будет генерироваться дефолтный оператор присваивания перемещением! Для его генерации все поля должны иметь такие операторы. А в нашем классе его нет.
Это значит, что по дефолту будет использоваться копирующее присваивания и все остальные поля нового класса будут копироваться. А вы об этом даже не знали! И получили жесткую просадку и, потенциально, некорректную логику.
Выбор использовать или не исопльзовать - как всегда за вам. Тестируйте гипотезы и выбирайте из них лучшую.
Analyse your solutions. Stay cool.
#cppcore #cpp11
#опытным
В этом посте поговорили про суть swap идиомы. Сегодня обсудим ее плюсы и минусы.
Плюсы вроде как обсуждали, но я финализирую, когда можно рассмотреть внедрение swap idiom:
✅ Если у вас конструктор копирования может бросить исключение и вы можете написать небросающую функцию swap. Тогда за счет того, что захват ресурсов(копирование или перемещение во временный объект параметра функции) происходит до модификации текущего объекта, то мы получаем строгую гарантию безопасности исключений при работе с присваиванием объектов.
✅ Если вы хотите красивый, лаконичный и понятный код без повторений действий.
✅ Вы не очень беспокоитесь о потенциальных потерях производительности.
Погнали по минусам:
❗️ Не всегда можно написать nothrowing swap. Для базовых типов и указателей - да. Но swap нетривиальных типов использует временный объект. При создании которого и может возникнуть исключение. Сейчас swap делается с помощью перемещающих операций, но например в С++03 std::string мог кинуть исключение в копирующем конструкторе. Да и сейчас поля класса могут быть немувабельными и бросающими при копировании. Это надо иметь ввиду.
❗️ Каждый раз при присваивании мы выполняем 2 операции: конструктор копирования + swap или конструктор перемещения + swap. "Потери производительности" надо конечно тестить и смотреть реальные результаты, но в голове все равно надо держать потенциальные просадки.
❗️ Самостоятельно писать деструктор для менеджинга ресурсов в 2к24 - такая себе практика в большинстве случаев. Давно есть std::unique_ptr<T[]>, указатели с кастомными делитерами и прочие вещи. Одно из ключевых преимуществ идиомы - сокращение и переиспользование кода. Так вот с отсутствием деструктора вам вообще может не понадобится кастомное присваивание и вы сможете объявить операции дефолтными, поэтому надобность в идиоме сама по себе отпадет.
❗️❗️ Часто пропускаемый огромный минус: технически у нас есть оператор перемещения, который может принимать rvalue ссылки. Однако мы явным образом не реальзовывали присваивание перемещением, поэтому по правилу 5, компилятор не будет его генерировать за нас и у класса просто будет отсутствовать оператор присваивания перемещением.
И хоть текущий класс мы можем мэнэджить без присваивания перемещением, то ситуация изменится, когда мы сделаем текущий класс полем другого. Тогда у этого другого класса не будет генерироваться дефолтный оператор присваивания перемещением! Для его генерации все поля должны иметь такие операторы. А в нашем классе его нет.
Это значит, что по дефолту будет использоваться копирующее присваивания и все остальные поля нового класса будут копироваться. А вы об этом даже не знали! И получили жесткую просадку и, потенциально, некорректную логику.
struct FirstField {
FirstField() = default;
FirstField(const FirstField& other) {
std::cout << "FirstField Copy ctor" << std::endl;
}
FirstField& operator=(FirstField other) {
std::cout << "FirstField assign" << std::endl;
return *this;
}
FirstField(FirstField&& other) {
std::cout << "FirstField Move ctor" << std::endl;
}
};
struct SecondField {
SecondField() = default;
SecondField(const SecondField& other) {
std::cout << "SecondField Copy ctor" << std::endl;
}
SecondField& operator=(const SecondField& other) {
std::cout << "SecondField Copy assign" << std::endl;
return *this;
}
SecondField(SecondField&& other) {
std::cout << "SecondField Move ctor" << std::endl;
}
SecondField& operator=(SecondField&& other) {
std::cout << "SecondField Copy assign" << std::endl;
return *this;
}
};
struct Wrapper {
FirstField ff;
SecondField sf;
};
Wrapper w;
w = std::move(Wrapper{});
// OUTPUT:
// FirstField Move ctor
// FirstField assign
// SecondField Copy assignВыбор использовать или не исопльзовать - как всегда за вам. Тестируйте гипотезы и выбирайте из них лучшую.
Analyse your solutions. Stay cool.
#cppcore #cpp11
{kind=link}
Вектор ссылок
#опытным
Не знаю, задумывались ли вы когда-нибудь создать вектор ссылок. Наверное задумывались, но не прям, чтобы пытались воплотить в жизнь. Не очень понятны кейсы применения этих сущностей. Однако они довольно хорошо подсвечивают одну интересную и базовую особенность вектора.
Дело в том, что вы не можете создать вектор ссылок. Не можете и все. Попробуйте написать что-то такое и запустить сборку:
Вылезет какая-то совершенно монструозная кракозябра, по которой мы хрен пойми, что должны понять. Это немного камней в огород бесполезных сообщений об ошибках в плюсах, но продолжим.
В сущности это происходит по одной причине. Шаблонный тип
До C++11 и появления мув-семантики элементы вектора должны были удовлетворять требованиям CopyAssignable и CopyConstructible. То есть из этих объектов должны получаться валидные копии, притом что исходный объект оказывается нетронутым. Это условие, кстати, не выполняется для запрещенного в РФ иноагента std::auto_ptr. Так вот ссылочный тип - не CopyAssignable. При попытке присвоить ссылке что-то копирования не происходит, а происходит просто перенаправление ссылки на другой объект.
После С++11 требования немного смягчились и теперь единственный критерий, которому тип элементов вектора должен удовлетворять - Erasable. Но ссылки также не попадают под этот критерий(для них не определен деструктор). Поэтому сидим без вектора ссылок. Или нет?
Можно хакнуть этот ваш сиплюсплюс и создать вектор из std::reference_wrapper. Это такая тривиальная обертка над ссылками, чтобы ими можно было оперировать, как обычными объектами. В смысле наличия у них всех специальных методов классов.
Но будьте осторожны(!), потому что есть одна большая проблема со ссылками. Вот мы создали и заполнили контейнер ссылками на какие-то объекты. И потом вышли из скоупа, где были объявлены объекты, на которые ссылки указывают. Вектор есть, ссылки есть, а объектов нет. Это чистой воды undefined behavior. Ссылки будут указывать на уже удаленные объекты. Пример:
Вывод будет такой:
Подумайте пару секунд, почему так. Переменная i меняется и мы добавляем ссылки на эту переменную в вектор. По итогу все элементы вектора указывают на одну и ту же переменную. Поэтому и элементы все одинаковы.
Но раз ссылка - это обертка над указателем, то элементы вектора по факту хранят адрес того места, где была переменная i. Поэтому все изменения ячейки памяти этой переменной будут отражаться на ссылках, даже если переменная уже удалена. Вот мы и сделали грязь: сохранили адрес ячейки и изменили его после выхода из скоупа цикла и удаления переменной i. Так обычно и происходит на стеке: переменная кладется на стек, с ней работают, она удаляется при выходе из скоупа и потом другие объект занимают место удаленной переменной в памяти. Мы здесь сымитировали такой процесс.
Так как вектор после выхода из скоупа цикла хранит висячие ссылки, то поведение в такой ситуации неопределено и наш грязный мув четко это показывает. После присваивания нового значения по указателю
Будьте аккуратны со ссылками. В этом случае проще использовать какой-нибудь умный указатель. Все будет чинно и цивильно. И никакого UB.
Be careful. Stay cool.
#cpp11 #cppcore #STL
#опытным
Не знаю, задумывались ли вы когда-нибудь создать вектор ссылок. Наверное задумывались, но не прям, чтобы пытались воплотить в жизнь. Не очень понятны кейсы применения этих сущностей. Однако они довольно хорошо подсвечивают одну интересную и базовую особенность вектора.
Дело в том, что вы не можете создать вектор ссылок. Не можете и все. Попробуйте написать что-то такое и запустить сборку:
std::vector<int&> vec;
Вылезет какая-то совершенно монструозная кракозябра, по которой мы хрен пойми, что должны понять. Это немного камней в огород бесполезных сообщений об ошибках в плюсах, но продолжим.
В сущности это происходит по одной причине. Шаблонный тип
vec не удовлетворяет требованиям к типам элементов вектора.До C++11 и появления мув-семантики элементы вектора должны были удовлетворять требованиям CopyAssignable и CopyConstructible. То есть из этих объектов должны получаться валидные копии, притом что исходный объект оказывается нетронутым. Это условие, кстати, не выполняется для запрещенного в РФ иноагента std::auto_ptr. Так вот ссылочный тип - не CopyAssignable. При попытке присвоить ссылке что-то копирования не происходит, а происходит просто перенаправление ссылки на другой объект.
После С++11 требования немного смягчились и теперь единственный критерий, которому тип элементов вектора должен удовлетворять - Erasable. Но ссылки также не попадают под этот критерий(для них не определен деструктор). Поэтому сидим без вектора ссылок. Или нет?
Можно хакнуть этот ваш сиплюсплюс и создать вектор из std::reference_wrapper. Это такая тривиальная обертка над ссылками, чтобы ими можно было оперировать, как обычными объектами. В смысле наличия у них всех специальных методов классов.
Но будьте осторожны(!), потому что есть одна большая проблема со ссылками. Вот мы создали и заполнили контейнер ссылками на какие-то объекты. И потом вышли из скоупа, где были объявлены объекты, на которые ссылки указывают. Вектор есть, ссылки есть, а объектов нет. Это чистой воды undefined behavior. Ссылки будут указывать на уже удаленные объекты. Пример:
std::vector<std::reference_wrapper<int>> vec;
int * p = nullptr;
{
int i;
for (i = 0, p = &i; i < 5; i++) {
vec.emplace_back(i);
}
}
*p = 10;
for (int i = 0; i < 5; i++) {
std::cout << vec[i] << std::endl;
}
Вывод будет такой:
10
10
10
10
10
Подумайте пару секунд, почему так. Переменная i меняется и мы добавляем ссылки на эту переменную в вектор. По итогу все элементы вектора указывают на одну и ту же переменную. Поэтому и элементы все одинаковы.
Но раз ссылка - это обертка над указателем, то элементы вектора по факту хранят адрес того места, где была переменная i. Поэтому все изменения ячейки памяти этой переменной будут отражаться на ссылках, даже если переменная уже удалена. Вот мы и сделали грязь: сохранили адрес ячейки и изменили его после выхода из скоупа цикла и удаления переменной i. Так обычно и происходит на стеке: переменная кладется на стек, с ней работают, она удаляется при выходе из скоупа и потом другие объект занимают место удаленной переменной в памяти. Мы здесь сымитировали такой процесс.
Так как вектор после выхода из скоупа цикла хранит висячие ссылки, то поведение в такой ситуации неопределено и наш грязный мув четко это показывает. После присваивания нового значения по указателю
p все ссылки будут иметь то же самое значение. Хотя изначально такая ситуация вообще не предполагалась.Будьте аккуратны со ссылками. В этом случае проще использовать какой-нибудь умный указатель. Все будет чинно и цивильно. И никакого UB.
Be careful. Stay cool.
#cpp11 #cppcore #STL
{kind=link}
Вектор констант
В прошлый раз мы рассмотрели вектор ссылок. А давайте чуть углубимся сюда и посмотрим, как будет себя вести вектор констант.
Константные объекты уже удовлетворяют требованию Erasable. Для них либо определен деструктор(пользовательские объекты), либо это константные тривиальные типы, которые тоже Erasable.
Казалось бы на этом можно закончить пост, можно создавать и ладно, много бубнить не нужно об этом. Но вот при использовании этой сущности могут возникать интересные эффекты.
Ничего сверхъестественного. Просто создаем вектор, заполняем его и выводим. Что может пойти не так?
Это дело не соберется на методе push_back. Тип А - тривиально копируемый, что не допускается при вызове этого метода. Но как только мы добавим нетривиальный деструктор или конструктор копирования - все заработает нормально. Этот же факт значит, что для любых тривиальных типов вы не сможете добавлять так элементы в вектор констант. Не знаю, какие рассуждения лежат за этим, знающие могут оставить свои мысли в комментах.
Но это ладно. Дальше мы хотим поработать с этим вектором и, например, отсортировать его.
И тоже натыкаемся на ошибку компиляции. Внутри себя std::sort использует std::swap, которая меняет значения своих операндов inplace. Это значит, что мы должны иметь возможность присваивать объектам другие данные. А для константных объектов сделать это будет очень проблематично.
Метод erase также нерабочий из-за отсутствия возможности присваивания. erase позволяет удалять элементы из середины вектора. Для этого придется "сдвигать" все элементы справа от удаляемых, чтобы заполнить пустоту. Делается это либо перемещением, либо копированием. Но для константных объектов очевидно запрещено вызывать оператор присваивания.
И хотя, интерфейс такого контейнера будет ограничен, мы все равно можем использовать читающие алгоритмы над ним. Например, подсчитывать какую-нибудь статистику по элементам. Также мы можем в рантайме свободно добавлять и удалять элементы из контейнера. Через emplace_back и pop_back. И это выгодно выделяет вектор констант на фоне константного вектора. Вы не хотите изменять сами элементы, но хотите иметь возможность изменять их множество и выполнять различные читающие операции над ним. Именно для этих задач и подходит вектор констант. Главное - аккуратнее с интерфейсом)
УПД: В комментах указали на критические неточности в посте, завтра будет опровержение
Be careful. Stay cool.
В прошлый раз мы рассмотрели вектор ссылок. А давайте чуть углубимся сюда и посмотрим, как будет себя вести вектор констант.
Константные объекты уже удовлетворяют требованию Erasable. Для них либо определен деструктор(пользовательские объекты), либо это константные тривиальные типы, которые тоже Erasable.
Казалось бы на этом можно закончить пост, можно создавать и ладно, много бубнить не нужно об этом. Но вот при использовании этой сущности могут возникать интересные эффекты.
struct A {
A(int num) : a{num} {}
int a;
};
std::vector<const A> vec;
for (int i = 0; i < 5; i++) {
vec.push_back(i);
}
for (int i = 0; i < 5; i++) {
std::cout << vec[i].a << std::endl;
}Ничего сверхъестественного. Просто создаем вектор, заполняем его и выводим. Что может пойти не так?
Это дело не соберется на методе push_back. Тип А - тривиально копируемый, что не допускается при вызове этого метода. Но как только мы добавим нетривиальный деструктор или конструктор копирования - все заработает нормально. Этот же факт значит, что для любых тривиальных типов вы не сможете добавлять так элементы в вектор констант. Не знаю, какие рассуждения лежат за этим, знающие могут оставить свои мысли в комментах.
Но это ладно. Дальше мы хотим поработать с этим вектором и, например, отсортировать его.
struct A {
A(int num) : a{num} {}
~A() {} // Important here
int a;
};
std::vector<const A> vec;
for (int i = 0; i < 5; i++) {
vec.push_back(i);
}
std::sort(vec.begin(), vec.end())И тоже натыкаемся на ошибку компиляции. Внутри себя std::sort использует std::swap, которая меняет значения своих операндов inplace. Это значит, что мы должны иметь возможность присваивать объектам другие данные. А для константных объектов сделать это будет очень проблематично.
Метод erase также нерабочий из-за отсутствия возможности присваивания. erase позволяет удалять элементы из середины вектора. Для этого придется "сдвигать" все элементы справа от удаляемых, чтобы заполнить пустоту. Делается это либо перемещением, либо копированием. Но для константных объектов очевидно запрещено вызывать оператор присваивания.
И хотя, интерфейс такого контейнера будет ограничен, мы все равно можем использовать читающие алгоритмы над ним. Например, подсчитывать какую-нибудь статистику по элементам. Также мы можем в рантайме свободно добавлять и удалять элементы из контейнера. Через emplace_back и pop_back. И это выгодно выделяет вектор констант на фоне константного вектора. Вы не хотите изменять сами элементы, но хотите иметь возможность изменять их множество и выполнять различные читающие операции над ним. Именно для этих задач и подходит вектор констант. Главное - аккуратнее с интерфейсом)
УПД: В комментах указали на критические неточности в посте, завтра будет опровержение
Be careful. Stay cool.
{kind=link}
Переобуваемся
В прошлом посте я сказал, что лигитимно создавать вектор констант. Ну и конечно я не просто так написал весь этот пост от балды, все проверял на своей машинке. Хз, что в голове было у компилятора, но он пропускал вектор констант. Больше не буду полагаться на эту шайтан-машину. Да простит Бог его душу, а мы сейчас поправим то, что было написано вчера.
Нормальные компиляторы не соберут вам программу с вектором констант, потому что существуют ограничения, наложенные на аллокаторы. Стандартный вектор объявляется вот так:
Заметим, что шаблонный тип аллокатора совпадает с шаблонным типом элементов вектора. То есть мы будем инстанцировать аллокатор с тем же шаблонным параметром, что и элементы вектора.
А на все аллокаторы, которые могут работать со стандартной библиотекой, наложены ограничения. Одно из них гласит, что шаблонный параметр Т аллокатора должен быть cv-unqualified типом. То есть константные типы туда не входят.
Ну вот собственно и все. Сам контейнер здесь действительно не при чем, ограничения заложены в аллокатор. Спасибо Игорю за то, что подметил ошибку в посте.
Если вы все-таки рьяно хотите вектор констант, то можете рассмотреть варианты оборачивания элементов в умные указатели:
Тогда шаблонный тип, с которым инстанцируется вектор и аллокатор, будет неконстантным и ограничения влиять не будут. И вы можете любые операции с этим вектором делать: хоть сортировки, хоть вставку посередине.
В том числе для таких ситуаций в нашем коммьюнити находятся крутые специалисты. Когда написание постов поставлено на поток, то ошибки неизбежны. Да они и в принципе неизбежны, мы тоже люди и многого не знаем. Иногда еще и инструментарий подводит. И это замечательно, что у нас в канале есть люди, которые вдумчиво читают посты и могут дать адекватную критику по фактам. От этого выигрывают все: критики экологично повышают свою значимость с своих глазах и глазах подписчиков, а в коммьюнити не пропускается ошибочная информация.
Не бойтесь делать ошибки, они уменьшают объем вашего незнания.
Make mistakes. Stay cool.
#cppcore
В прошлом посте я сказал, что лигитимно создавать вектор констант. Ну и конечно я не просто так написал весь этот пост от балды, все проверял на своей машинке. Хз, что в голове было у компилятора, но он пропускал вектор констант. Больше не буду полагаться на эту шайтан-машину. Да простит Бог его душу, а мы сейчас поправим то, что было написано вчера.
Нормальные компиляторы не соберут вам программу с вектором констант, потому что существуют ограничения, наложенные на аллокаторы. Стандартный вектор объявляется вот так:
template<
class T,
class Allocator = std::allocator<T>
> class vector;
Заметим, что шаблонный тип аллокатора совпадает с шаблонным типом элементов вектора. То есть мы будем инстанцировать аллокатор с тем же шаблонным параметром, что и элементы вектора.
А на все аллокаторы, которые могут работать со стандартной библиотекой, наложены ограничения. Одно из них гласит, что шаблонный параметр Т аллокатора должен быть cv-unqualified типом. То есть константные типы туда не входят.
Ну вот собственно и все. Сам контейнер здесь действительно не при чем, ограничения заложены в аллокатор. Спасибо Игорю за то, что подметил ошибку в посте.
Если вы все-таки рьяно хотите вектор констант, то можете рассмотреть варианты оборачивания элементов в умные указатели:
std::vector<std::unique_ptr<const Type>> vec;
Тогда шаблонный тип, с которым инстанцируется вектор и аллокатор, будет неконстантным и ограничения влиять не будут. И вы можете любые операции с этим вектором делать: хоть сортировки, хоть вставку посередине.
В том числе для таких ситуаций в нашем коммьюнити находятся крутые специалисты. Когда написание постов поставлено на поток, то ошибки неизбежны. Да они и в принципе неизбежны, мы тоже люди и многого не знаем. Иногда еще и инструментарий подводит. И это замечательно, что у нас в канале есть люди, которые вдумчиво читают посты и могут дать адекватную критику по фактам. От этого выигрывают все: критики экологично повышают свою значимость с своих глазах и глазах подписчиков, а в коммьюнити не пропускается ошибочная информация.
Не бойтесь делать ошибки, они уменьшают объем вашего незнания.
Make mistakes. Stay cool.
#cppcore
{kind=link}
Странный размер std::unordered_map
#опытным
Стандартная ситуация. Создаем контейнер, резервируем подходящий размер для ожидаемого количества элементов в коллекции и запихиваем элементы. Все просто. Но это с каким-нибудь вектором все просто. А хэш-мапа - дело нетривиальное. Смотрим на код:
Все, как обычно. А теперь вывод:
WTF? Я же сказал выделить в мапе 6 бакетов, а не 7. Какой непослушный компилятор!
Вообще, поведение странное, но может там просто всегда +1 по какой-то причине?
Поменяем map_size на 9 и посмотрим вывод:
Again. WTF? Уже на 2 разница. Нужна новая гипотеза... Попробуем третье число. Возьмем 13.
А тут работает! Но это не прибавляет понимания проблемы... В чем же дело?
Из цппреференса про метод reserve:
То есть стандарт разрешает реализациям выделять больше элементов для мапы, чем мы запросили.
Легитимацию безобразия мы получили, но хотелось бы внятное объяснение причины предоставления такой возможности.
Реализации обычно выбирают bucket_count исходя из соображений быстродействия(как обычно). Тут они выбирают из двух опций:
1️⃣ Выбирают в качестве bucket_count степень двойки, то есть округляют до степени двойки в большую сторону. Это помогает эффективно маппить результат хэш функции на размер самой хэш-таблицы. Можно просто сделать битовое И и отбросить все биты, старше нашей степени. Что делается на один цикл цпу.
Но этот способ имеет негативный эффект в виде того же отбрасывания битов. То есть эти страшие биты никак не влияют на маппинг хэша на бакеты, то уменьшает равномерность распределения.
Таким способом пользуется Visual C++.
2️⃣ Поддерживают bucket_count простым числом.
Это дает крутой эффект того, что старшие биты также влияют на распределение объектов по бакетам. В этом случае даже плохие хэш-функции имеют более равномерное размещение бакетов.
Однако наивная реализация такого подхода заставляет каждый раз делить на рантаймовое значение bucket_count, что может занимать до 100 раз больше циклов.
Более быстрой альтернативой может быть использование захардкоженой таблицы простых чисел. Индекс в ней выбирается на основе запрашиваемого значения bucket_count. Таким образом компилятор может заоптимизировать деление по модулю через битовые операции, сложения, вычитания и умножения. Можете посмотреть на эти оптимизации более подробно на этом примере в годболт.
Этой реализацией пользуется GCC и Clang.
Вот такие страсти происходят у нас под носом под капотом неупорядоченной мапы.
Optimize everything. Stay cool.
#STL #optimization #compiler
#опытным
Стандартная ситуация. Создаем контейнер, резервируем подходящий размер для ожидаемого количества элементов в коллекции и запихиваем элементы. Все просто. Но это с каким-нибудь вектором все просто. А хэш-мапа - дело нетривиальное. Смотрим на код:
constexpr size_t map_size = 6;
std::unordered_map<int, int> mymap;
mymap.reserve(map_size);
for (int i = 0; i < map_size; i++) {
mymap[i] = i;
}
std::cout << "mymap has " << mymap.bucket_count() << " buckets\n";
Все, как обычно. А теперь вывод:
mymap has 7 buckets
WTF? Я же сказал выделить в мапе 6 бакетов, а не 7. Какой непослушный компилятор!
Вообще, поведение странное, но может там просто всегда +1 по какой-то причине?
Поменяем map_size на 9 и посмотрим вывод:
mymap has 11 buckets
Again. WTF? Уже на 2 разница. Нужна новая гипотеза... Попробуем третье число. Возьмем 13.
mymap has 13 buckets
А тут работает! Но это не прибавляет понимания проблемы... В чем же дело?
Из цппреференса про метод reserve:
Request a capacity change
Sets the number of buckets in the container (bucket_count) to the most appropriate to contain at least n elements.
То есть стандарт разрешает реализациям выделять больше элементов для мапы, чем мы запросили.
Легитимацию безобразия мы получили, но хотелось бы внятное объяснение причины предоставления такой возможности.
Реализации обычно выбирают bucket_count исходя из соображений быстродействия(как обычно). Тут они выбирают из двух опций:
1️⃣ Выбирают в качестве bucket_count степень двойки, то есть округляют до степени двойки в большую сторону. Это помогает эффективно маппить результат хэш функции на размер самой хэш-таблицы. Можно просто сделать битовое И и отбросить все биты, старше нашей степени. Что делается на один цикл цпу.
Но этот способ имеет негативный эффект в виде того же отбрасывания битов. То есть эти страшие биты никак не влияют на маппинг хэша на бакеты, то уменьшает равномерность распределения.
Таким способом пользуется Visual C++.
2️⃣ Поддерживают bucket_count простым числом.
Это дает крутой эффект того, что старшие биты также влияют на распределение объектов по бакетам. В этом случае даже плохие хэш-функции имеют более равномерное размещение бакетов.
Однако наивная реализация такого подхода заставляет каждый раз делить на рантаймовое значение bucket_count, что может занимать до 100 раз больше циклов.
Более быстрой альтернативой может быть использование захардкоженой таблицы простых чисел. Индекс в ней выбирается на основе запрашиваемого значения bucket_count. Таким образом компилятор может заоптимизировать деление по модулю через битовые операции, сложения, вычитания и умножения. Можете посмотреть на эти оптимизации более подробно на этом примере в годболт.
Этой реализацией пользуется GCC и Clang.
Вот такие страсти происходят у нас под носом под капотом неупорядоченной мапы.
Optimize everything. Stay cool.
#STL #optimization #compiler
{kind=link}
Ревью
#опытным
На просторах интернета нашел интересный сэмпл кода, которым захотел с вами поделиться. Интересный, потому что он очень маленький, но там есть большое пространство для тщательного #ревью.
А еще у новичков могут глаза вытечь, посмотрев на первую строчку. В общем, равнодушным никто не останется.
Оставляйте в комментах свои замечания и возможные варианты исправления ситуации.
Комментарии наиболее продуктивного критика выложу на канал вместе с ответом.
Хватит отдыхать, пора ошибки в коде искать!
Analyse your life. Stay cool.
#опытным
На просторах интернета нашел интересный сэмпл кода, которым захотел с вами поделиться. Интересный, потому что он очень маленький, но там есть большое пространство для тщательного #ревью.
А еще у новичков могут глаза вытечь, посмотрев на первую строчку. В общем, равнодушным никто не останется.
Оставляйте в комментах свои замечания и возможные варианты исправления ситуации.
Комментарии наиболее продуктивного критика выложу на канал вместе с ответом.
Хватит отдыхать, пора ошибки в коде искать!
Analyse your life. Stay cool.
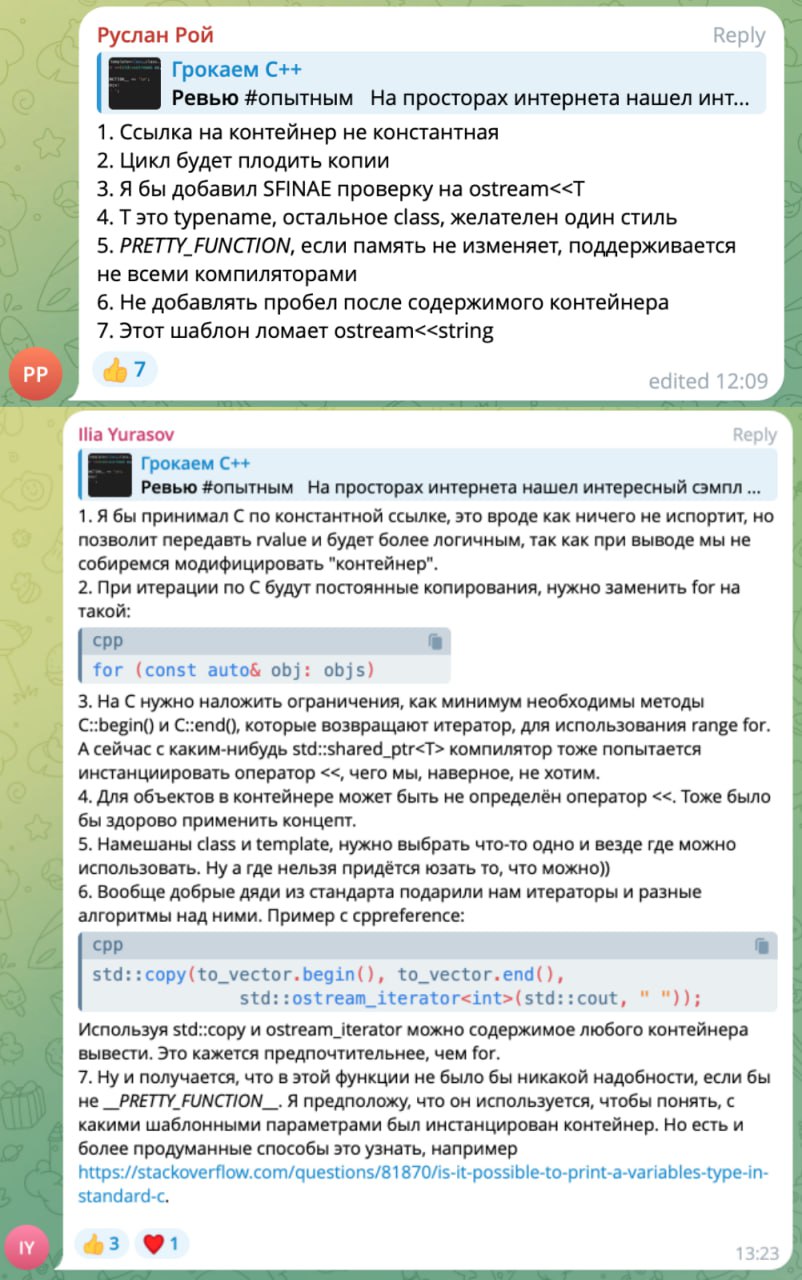
Результаты ревью
Круто вчера постарались, столько проблем нашли в этом маленьком кусочке кода. Больше всего проблем нашли два подписчика со скрина: я не смог выбрать из них одного, так как их пункты хоть и пересекаются, но все же дополняют друг друга различными мыслями. Давайте похлопаем нашим героям!👏👏👏👏👏👏
А теперь скомпануем все воедино. Напомню, что код был такой:
Сначала очевидное и то, что бросается в глаза. Все правильно поняли, что смысл кода - вывести элементы любого контейнера на выходной поток. Всвязи с этим следующие рассуждения:
❗️ Второй аргумент оператора принимается по значению, что ведет с излишним копированиям. Лучше использовать константную ссылку, так как мы не собираемся изменять значения контейнера.
❗️ В цикле тоже будут копирования, так как obj - объект, а не ссылка. Лучше использовать const auto &.
❗️ В первой строчке смешиваются class и typename. Это путает читателя, заставляя задумываться о тайном замысле использования разных ключевых слов. Лучше везде использовать class, так как Артем отметил , что до С++17 в шаблон-шаблонных параметрах нельзя было использовать typename.
❗️ Не очень выразительное название для аргумента, которым предполагается быть контейнеру. Хотя бы полностью написать Container.
❗️ Вывод элементов очень странный и кривой. Как минимум после последнего элемента будет ставиться пробел. Решить проблему можно с помощью стандартного алгоритма std::copy и интересного экспериментального итератора std::experimental::make_ostream_joiner, который может выводить элементы последовательности через разделитель, не записывая разделитель в конце! Выглядит это так:
На этом очевидные недостатки, которые мог выделить даже не очень разбирающийся в шаблонах читатель, заканчиваются.
Посмотрим чуть поглужбе. Функция используется для отладочных и учебных целей. Это понятно по использованию макроса PRETTY_FUNCTION. Он позволяет посмотреть полную сигнатуру функции с расшифровкой всех шаблонных параметров. Он довольно сильно помогает при обучении. Но к сожалению, этот макрос определен только под gcc/clang. Давайте уж не будем сильно внимание заострять на кроссплатформенности и целесообразности использования этой конструкции. В прод функция явно не пойдет. Д. А более интересные и кроссплатформенные варианты вывода сигнатуры функции можно посмотреть тут.
Однако автором этот кусок кода преподносился, как универсальный принт контейнеров STL. А вот тут уже залет! Потому что он не только не универсальный, но еще и не безопасный и корявый!.
🔞 Для класса std::string уже определен оператор вывода на поток, поэтому при наличии этого куска в общем коде мы просто не сможем выводить строку, так как компилятор найдет 2 подходящие перегрузки и не сможет из них выбрать лучшую. Можно ограничить тип контейнера с помощью sfinae/концептов.
🔞 Перегрузка не будет работать для мап. У них элементы - пары, которые не имеют собственной реализации вывода на поток. Да и вообще: если элементы "контейнера" не умеют выводиться на поток, то будет ошибка. Выход - поставить sfinae/концепт на существовании перегрузки на поток вывода для типа Т.
🔞 В предыдущем пункте я взял слово контейнер в кавычки. Все потому что сигнатура функции способна принимать любую шаблонную тварь, даже какой-нибудь std::shared_ptr. А для него уже перегружен оператор вывода. Опять компилятор не сможет выбрать из двух одинаковых перегрузок. Поэтому было бы неплохо поставить ограничение на существование методов begin() и end().
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
Fix your flaws. Stay cool.
#template #STL #cppcore #cpp17 #cpp20
Круто вчера постарались, столько проблем нашли в этом маленьком кусочке кода. Больше всего проблем нашли два подписчика со скрина: я не смог выбрать из них одного, так как их пункты хоть и пересекаются, но все же дополняют друг друга различными мыслями. Давайте похлопаем нашим героям!👏👏👏👏👏👏
А теперь скомпануем все воедино. Напомню, что код был такой:
template<typename T, template<class,class...> class C, class... Args>
std::ostream& operator <<(std::ostream& os, C<T,Args...> objs)
{
os << PRETTY_FUNCTION << '\n';
for (auto obj : objs)
os << obj << ' ';
return os;
}
Сначала очевидное и то, что бросается в глаза. Все правильно поняли, что смысл кода - вывести элементы любого контейнера на выходной поток. Всвязи с этим следующие рассуждения:
❗️ Второй аргумент оператора принимается по значению, что ведет с излишним копированиям. Лучше использовать константную ссылку, так как мы не собираемся изменять значения контейнера.
❗️ В цикле тоже будут копирования, так как obj - объект, а не ссылка. Лучше использовать const auto &.
❗️ В первой строчке смешиваются class и typename. Это путает читателя, заставляя задумываться о тайном замысле использования разных ключевых слов. Лучше везде использовать class, так как Артем отметил , что до С++17 в шаблон-шаблонных параметрах нельзя было использовать typename.
❗️ Не очень выразительное название для аргумента, которым предполагается быть контейнеру. Хотя бы полностью написать Container.
❗️ Вывод элементов очень странный и кривой. Как минимум после последнего элемента будет ставиться пробел. Решить проблему можно с помощью стандартного алгоритма std::copy и интересного экспериментального итератора std::experimental::make_ostream_joiner, который может выводить элементы последовательности через разделитель, не записывая разделитель в конце! Выглядит это так:
std::copy(vec.begin(), vec.end(),
std::experimental::make_ostream_joiner(std::cout, ", "));
На этом очевидные недостатки, которые мог выделить даже не очень разбирающийся в шаблонах читатель, заканчиваются.
Посмотрим чуть поглужбе. Функция используется для отладочных и учебных целей. Это понятно по использованию макроса PRETTY_FUNCTION. Он позволяет посмотреть полную сигнатуру функции с расшифровкой всех шаблонных параметров. Он довольно сильно помогает при обучении. Но к сожалению, этот макрос определен только под gcc/clang. Давайте уж не будем сильно внимание заострять на кроссплатформенности и целесообразности использования этой конструкции. В прод функция явно не пойдет. Д. А более интересные и кроссплатформенные варианты вывода сигнатуры функции можно посмотреть тут.
Однако автором этот кусок кода преподносился, как универсальный принт контейнеров STL. А вот тут уже залет! Потому что он не только не универсальный, но еще и не безопасный и корявый!.
🔞 Для класса std::string уже определен оператор вывода на поток, поэтому при наличии этого куска в общем коде мы просто не сможем выводить строку, так как компилятор найдет 2 подходящие перегрузки и не сможет из них выбрать лучшую. Можно ограничить тип контейнера с помощью sfinae/концептов.
🔞 Перегрузка не будет работать для мап. У них элементы - пары, которые не имеют собственной реализации вывода на поток. Да и вообще: если элементы "контейнера" не умеют выводиться на поток, то будет ошибка. Выход - поставить sfinae/концепт на существовании перегрузки на поток вывода для типа Т.
🔞 В предыдущем пункте я взял слово контейнер в кавычки. Все потому что сигнатура функции способна принимать любую шаблонную тварь, даже какой-нибудь std::shared_ptr. А для него уже перегружен оператор вывода. Опять компилятор не сможет выбрать из двух одинаковых перегрузок. Поэтому было бы неплохо поставить ограничение на существование методов begin() и end().
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
Fix your flaws. Stay cool.
#template #STL #cppcore #cpp17 #cpp20
{kind=link}
nullptr
#новичкам
Вероятно, каждый, кто писал код на C++03, имел удовольствие использовать NULL и постоянно ударяться мизинцем ноги об этот острый уголок тумбочки. Дело в том, что NULL использовался, как обозначение нулевого указателя, который никуда не указывает. Но если он для этого и использовался - это не значит, что он таковым являлся. Да и являлся он котом в мешке. Это макрос, который мог быть определен как
Вот в этом-то и вся проблема. NULL очень явно хочет себя видеть в роли указателя, но по факту в зеркале видит число. Допустим, у нас есть 2 перегрузки одной функции: одна для инта, вторая для указателя:
Намерения ясны: мы хотим вызвать перегрузку для указателя. Но это гарантировано не произойдет! В произойдет один из двух сценариев: если NULL определен как
Проблему можно решить енамами, принимать вместо его вместо инта и передавать для нулевого spellID что-то типа NoSpell. Но надо опять городить огород. Почему все не работает из коробки?!
С приходом С++11 начало работать из коробки. Надо только забыть про NULL и использовать nullptr.
Ключевое слово nullptr обозначает литерал указателя. Это prvalue типа std::nullptr_t. И nullptr неявно приводится к нулевому значению указателя для любого типа указателя. Это объект отдельного типа, который теперь к простому инту не приводится.
Поэтому сейчас этот код отработает как надо:
Так как nullptr - значение конкретного типа std::nullptr_t, то мы может принимать в функции непосредственно этот тип, а не общий тип указателя. Такая штука используется, например, в реализации std::function, конструктор которого имеет перегрузку для std::nullptr_t и делает тоже самое, что и конструктор без аргументов.
По той же причине nullptr даже при возврате через функцию может быть приведен к типу указателя. А вот обычные null pointer константны не могут похвастаться таким свойством. Они могут приводиться к указателям только в виде литералов.
clone(nullptr) вернет тот же nullptr и все будет работать гладко. А для 0 и NULL функция вернет просто int, который сам по себе неявно не конвертится в указатель.
Думаю, что вы все и так пользуете nullptr, но этот пост обязан быть на канале.
Как говорится "Use nullptr instead of NULL, 0 or any other null pointer constant, wherever you need a generic null pointer."
Be a separate subject. Stay cool.
#cppcore #cpp11
#новичкам
Вероятно, каждый, кто писал код на C++03, имел удовольствие использовать NULL и постоянно ударяться мизинцем ноги об этот острый уголок тумбочки. Дело в том, что NULL использовался, как обозначение нулевого указателя, который никуда не указывает. Но если он для этого и использовался - это не значит, что он таковым являлся. Да и являлся он котом в мешке. Это макрос, который мог быть определен как
0 aka int zero или 0L aka zero long int, но всегда это вариация интегрального нуля. И уже эти чиселки могли быть приведены к типу указателя.Вот в этом-то и вся проблема. NULL очень явно хочет себя видеть в роли указателя, но по факту в зеркале видит число. Допустим, у нас есть 2 перегрузки одной функции: одна для инта, вторая для указателя:
class Spell { };
void castSpell(Spell* theSpell);
void castSpell(int spellID);
int main() {
castSpell(NULL);
}Намерения ясны: мы хотим вызвать перегрузку для указателя. Но это гарантировано не произойдет! В произойдет один из двух сценариев: если NULL определен как
0, то просто без объявления войны в 4 часа утра 22 июня вызовется вторая перегрузка. Если как 0L, то компилятор поругается на неоднозначный вызов: 0L может быть одинаково хорошо сконвертирован и в инт, и в указатель.Проблему можно решить енамами, принимать вместо его вместо инта и передавать для нулевого spellID что-то типа NoSpell. Но надо опять городить огород. Почему все не работает из коробки?!
С приходом С++11 начало работать из коробки. Надо только забыть про NULL и использовать nullptr.
Ключевое слово nullptr обозначает литерал указателя. Это prvalue типа std::nullptr_t. И nullptr неявно приводится к нулевому значению указателя для любого типа указателя. Это объект отдельного типа, который теперь к простому инту не приводится.
Поэтому сейчас этот код отработает как надо:
class Spell {};
void castSpell(Spell* theSpell);
void castSpell(int spellID);
int main() {
castSpell(nullptr);
}Так как nullptr - значение конкретного типа std::nullptr_t, то мы может принимать в функции непосредственно этот тип, а не общий тип указателя. Такая штука используется, например, в реализации std::function, конструктор которого имеет перегрузку для std::nullptr_t и делает тоже самое, что и конструктор без аргументов.
/*
* @brief Default construct creates an empty function call wrapper.
* @post !(bool)*this
*/
function() noexcept
: _Function_base() { }
/
* @brief Creates an empty function call wrapper.
* @post @c !(bool)*this
*/
function(nullptr_t) noexcept
: _Function_base() { }
По той же причине nullptr даже при возврате через функцию может быть приведен к типу указателя. А вот обычные null pointer константны не могут похвастаться таким свойством. Они могут приводиться к указателям только в виде литералов.
template<class T>
constexpr T clone(const T& t)
{
return t;
}
void g(int *)
{
std::cout << "Function g called\n";
}
int main()
{
g(nullptr); // Fine
g(NULL); // Fine
g(0); // Fine
g(clone(nullptr)); // Fine
// g(clone(NULL)); // ERROR: non-literal zero cannot be a null pointer constant
// g(clone(0)); // ERROR: non-literal zero cannot be a null pointer constant
}
clone(nullptr) вернет тот же nullptr и все будет работать гладко. А для 0 и NULL функция вернет просто int, который сам по себе неявно не конвертится в указатель.
Думаю, что вы все и так пользуете nullptr, но этот пост обязан быть на канале.
Как говорится "Use nullptr instead of NULL, 0 or any other null pointer constant, wherever you need a generic null pointer."
Be a separate subject. Stay cool.
#cppcore #cpp11
{kind=link}
Всем привет)
Мы для вас подготовили серию статей по выводу шаблонных параметров. Когда-то давно нас попросили рассказать про конструкцию decltype(auto), но про это сложно будет рассказывать, не разобрав по отдельности decltype и auto. Но в первую очередь нужно поговорить про вывод типов с плюсах, поэтому начнем с этого.
Здесь будет приведен список будущих тем. По мере появления постов здесь будут появляться гиперссылки для более удобного поиска. Также и сами темы могут добавляться по мере выхода статей.
Темы:
👉🏿 Вывод типов
👉🏿 Template type deduction
👉🏿 Небольшой пролог для вывода типов
👉🏿 ParamType - не cv-квалифицированная ссылка
👉🏿 ParamType - не cv-квалифицированный указатель
👉🏿 ParamType - cv-квалифицированный параметр
👉🏿 ParamType - универсальная ссылка
👉🏿 ParamType - не ссылка и не указатель
👉🏿 Аргумент шаблонной функции - массив
👉🏿 Аргумент шаблонной функции - функция
Возможно где-то вы уже это видели(привет, Скотт!). Однако оттуда мы взяли структуру, наполнение будет переформатировно и расширено.
Мы для вас подготовили серию статей по выводу шаблонных параметров. Когда-то давно нас попросили рассказать про конструкцию decltype(auto), но про это сложно будет рассказывать, не разобрав по отдельности decltype и auto. Но в первую очередь нужно поговорить про вывод типов с плюсах, поэтому начнем с этого.
Здесь будет приведен список будущих тем. По мере появления постов здесь будут появляться гиперссылки для более удобного поиска. Также и сами темы могут добавляться по мере выхода статей.
Темы:
👉🏿 Вывод типов
👉🏿 Template type deduction
👉🏿 Небольшой пролог для вывода типов
👉🏿 ParamType - не cv-квалифицированная ссылка
👉🏿 ParamType - не cv-квалифицированный указатель
👉🏿 ParamType - cv-квалифицированный параметр
👉🏿 ParamType - универсальная ссылка
👉🏿 ParamType - не ссылка и не указатель
👉🏿 Аргумент шаблонной функции - массив
👉🏿 Аргумент шаблонной функции - функция
Возможно где-то вы уже это видели(привет, Скотт!). Однако оттуда мы взяли структуру, наполнение будет переформатировно и расширено.
Вывод типов
#новичкам
С++ - статически типизированный язык, что значит, что типы всех объектов должны быть известны на этапе компиляции. Это хорошо для безопасности программы и предсказуемости поведения, но не очень хорошо с точки зрения удобства написания программы. Не всегда мне хочется писать что-то типа "im::so::tired::of::typing::long<types>::iterator". Точнее никогда.
Да, есть алиасы и синонимы, это нужные и полезные вещи. Но не на все же гигадлинные типы их вводить.
Очень хочется, чтобы работу по "написанию" типов делал кто-то за нас. Ведь в конце концов, все сигнатуры функций и методов известны, нормальные пацаны используют явные плюсовые касты, инициализаторы обычно представляют из себя понятные типы. Да, есть всякие приколы с неявным приведением типов и неэксплисит конструкторами от одного аргумента. Но попробовать-то стоит?
Так и подумали создатели С++11 и решили ввести для решения этой проблемы ключевое слово auto. На самом деле они ничего не вводили, а вдохнули новую жизнь в уже существующее ключевое слово. У нас даже пост про это есть.
Вещь - суперполезная и нужная. Сохраняет много пальчиковых усилий ленивым разработчикам. Например, у меня есть набор коллекций данных, каждая из которых связана с определенным идентификатором. Этот набор можно описать довольно просто:
Так вот, чтобы по этой мапе проитерироваться раньше нужно было писать вот так:
Это конечно никуда не годится, выглядит ужасно, нечитаемо, да и код повторяется. Теперь подключаем 11-у плюсы и случается магия:
А добавив заклинание под называнием range-based-for, получим:
Не идеально, это вам не питон. Но уже ощутимо приятнее и короче раза в 3.
Но тут встает вопрос: а как вообще эти типы-то выводятся? Есть наверное какие-то правила, алгоритм, по которому компилятор выводит тип?
Есть. Иначе это было бы магией(хотя грустновато без нее в нашем мире).
Его можно запомнить довольно легко. Поэтому в нескольких следующих постах мы будем разбирать эту тему.
А вообще знаете, что существует 3 вида вывода типов? Может и больше, но 3 точно есть, обещаю)
Delegate your work. Stay cool.
#cpp11
#новичкам
С++ - статически типизированный язык, что значит, что типы всех объектов должны быть известны на этапе компиляции. Это хорошо для безопасности программы и предсказуемости поведения, но не очень хорошо с точки зрения удобства написания программы. Не всегда мне хочется писать что-то типа "im::so::tired::of::typing::long<types>::iterator". Точнее никогда.
Да, есть алиасы и синонимы, это нужные и полезные вещи. Но не на все же гигадлинные типы их вводить.
Очень хочется, чтобы работу по "написанию" типов делал кто-то за нас. Ведь в конце концов, все сигнатуры функций и методов известны, нормальные пацаны используют явные плюсовые касты, инициализаторы обычно представляют из себя понятные типы. Да, есть всякие приколы с неявным приведением типов и неэксплисит конструкторами от одного аргумента. Но попробовать-то стоит?
Так и подумали создатели С++11 и решили ввести для решения этой проблемы ключевое слово auto. На самом деле они ничего не вводили, а вдохнули новую жизнь в уже существующее ключевое слово. У нас даже пост про это есть.
Вещь - суперполезная и нужная. Сохраняет много пальчиковых усилий ленивым разработчикам. Например, у меня есть набор коллекций данных, каждая из которых связана с определенным идентификатором. Этот набор можно описать довольно просто:
std::unordered_map<std::string, std::vector<Customer>> data;
Так вот, чтобы по этой мапе проитерироваться раньше нужно было писать вот так:
for (std::unordered_map<std::string, std::vector<Customer> >::iterator it = data.begin(); it != data.end(); it++) {...}Это конечно никуда не годится, выглядит ужасно, нечитаемо, да и код повторяется. Теперь подключаем 11-у плюсы и случается магия:
for (auto it = data.begin(); it != data.end(); it++) {...}А добавив заклинание под называнием range-based-for, получим:
for (const auto& elem: data) {...}Не идеально, это вам не питон. Но уже ощутимо приятнее и короче раза в 3.
Но тут встает вопрос: а как вообще эти типы-то выводятся? Есть наверное какие-то правила, алгоритм, по которому компилятор выводит тип?
Есть. Иначе это было бы магией(хотя грустновато без нее в нашем мире).
Его можно запомнить довольно легко. Поэтому в нескольких следующих постах мы будем разбирать эту тему.
А вообще знаете, что существует 3 вида вывода типов? Может и больше, но 3 точно есть, обещаю)
Delegate your work. Stay cool.
#cpp11
Опасности std::unordered_map
#опытным
Когда писал прошлый пост, я хотел сразу вставить в пример range-based-for, чтобы показать одну приколюху. Но решил, что это заслуживает отдельного поста.
В копилку полезности auto.
Вдруг вы решили не пользоваться этой фичей и пишите вот так:
Вроде бы все хорошо и выглядит, как надо. И ожидать мы в консоли будем такой вывод:
При заполнении вектора кастомеры копируются из временных объектов, вызывается копирующий конструктор с принтом, и далее вывод цикла.
Однако на самом деле вывод будет такой:
Мы этого совсем не ожидали. Откуда еще 2 копии?!!
Дело в том, что в нашей неупорядоченной мапе хранятся не std::pair<std::string, std::vector<Customer>>, а std::pair<const std::string, std::vector<Customer>>. Это в принципе особенность std::unordered_map: ключ мапы - неизменяемый объект, поэтому обобщенно мапа хранит std::pair<const Key, Value>.
И у компилятора не получается забиндить пару с константным ключом к паре с неконстантным. Но делать-то что-то надо. Поэтому он просто делает копию пары, лежащей в мапе, и переменная цикла item ссылается на этот временный объект. Дальше временный объект уничтожается после завершения своей итерации цикла и уходит в историю, как тот, кого не ждали, кто просто так пожрал ресурсы, ничего полезного не сделал и ушел. Осуждаю таких наглецов.
Ну и естественно, эта проблема просто решается использованием ключевого слова auto.
Теперь у нас есть ожидаемый вывод.
Make your life easier. Stay cool.
#cpp11 #STL
#опытным
Когда писал прошлый пост, я хотел сразу вставить в пример range-based-for, чтобы показать одну приколюху. Но решил, что это заслуживает отдельного поста.
В копилку полезности auto.
Вдруг вы решили не пользоваться этой фичей и пишите вот так:
struct Customer{
Customer(int num) : data{num} {}
Customer(const Customer& other) {
data = other.data;
std::cout << "Copy ctor" << std::endl;
}
private:
int data;
};
std::unordered_map<std::string, std::vector<Customer>> data;
data["qwe"] = {Customer{1}, Customer{2}};
for (const std::pair<std::string, std::vector<Customer>>& item : data) {
std::cout << "Idle print" << std::endl;
}Вроде бы все хорошо и выглядит, как надо. И ожидать мы в консоли будем такой вывод:
Copy ctor
Copy ctor
Idle print
При заполнении вектора кастомеры копируются из временных объектов, вызывается копирующий конструктор с принтом, и далее вывод цикла.
Однако на самом деле вывод будет такой:
Copy ctor
Copy ctor
Copy ctor
Copy ctor
Idle print
Мы этого совсем не ожидали. Откуда еще 2 копии?!!
Дело в том, что в нашей неупорядоченной мапе хранятся не std::pair<std::string, std::vector<Customer>>, а std::pair<const std::string, std::vector<Customer>>. Это в принципе особенность std::unordered_map: ключ мапы - неизменяемый объект, поэтому обобщенно мапа хранит std::pair<const Key, Value>.
И у компилятора не получается забиндить пару с константным ключом к паре с неконстантным. Но делать-то что-то надо. Поэтому он просто делает копию пары, лежащей в мапе, и переменная цикла item ссылается на этот временный объект. Дальше временный объект уничтожается после завершения своей итерации цикла и уходит в историю, как тот, кого не ждали, кто просто так пожрал ресурсы, ничего полезного не сделал и ушел. Осуждаю таких наглецов.
Ну и естественно, эта проблема просто решается использованием ключевого слова auto.
struct Customer{
Customer(int num) : data{num} {}
Customer(const Customer& other) {
data = other.data;
std::cout << "Copy ctor" << std::endl;
}
private:
int data;
};
std::unordered_map<std::string, std::vector<Customer>> data;
data["qwe"] = {Customer{1}, Customer{2}};
for (const auto& item : data) {
std::cout << "Idle print" << std::endl;
}
Теперь у нас есть ожидаемый вывод.
Make your life easier. Stay cool.
#cpp11 #STL
{kind=link}
Template type deduction
#новичкам
Пользователи 98-го стандарта недоумевали, почему они обязаны при наличии инициализатора указывать полный тип переменной при ее определении. "Если я еще раз напишу полный тип итератора, то я устрою Роскомнадзор", "Вы что, хотите, чтобы я пальцы стёр?!" и тд. У многих были такие мысли. И это, вообще говоря, было очень странно, потому что компилятор уже на тот момент мог сам выводить тип на основе типа другого выражения!
В шаблонах.
Вам же не обязательно писать в шаблонных функциях тип шаблонного аргумента. В некоторых случаях компилятор за вас это может сделать.
Здесь выведется 10 и, как вы видите, для функции my_size мы не указывали явным образом шаблонный тип.
Ну и раз уже есть наработанная схема, к которой разработчики уже привыкли, то почему бы именно ее не использовать в качестве основы вывода типов для auto? Этим риторическим вопросом задались контрибьютеры в 11-й стандарт и теперь у нас действительно есть ключевое слово auto, для которого вывод типов практически ничем не отличается от вывода типов для шаблонных функций!
Поэтому надо понимать, что это за зверь такой, чтобы осознанно использовать auto.
Чтобы мы все понимали, о чем конкретно будем говорить, посмотрим на следующий псевдокод:
Все будем разбирать на примере подобной шаблонной функции. Так вот процесс вывода типов ParamType и Т на основании типа выражения expression - это и есть вывод шаблонных типов.
Небольшой пример:
В случае c my_size ParamType - const std::vector<T>&, а тип T - int. В случае с fun ParamType принимает вид типа Т, обвешанного побрякушками, типа const- и ссылочного квалификаторов. Здесь ParamType = const T&, а Т = int.
То есть ParamType - все то, что стоит слева от имени шаблонного параметра, и на основе выведенного ParamType уже принимается решение о типе Т. Поэтому очень важно понимать не только, какой тип имеет expression, но и какой вид принимает ParamType. Есть всего 3 мажорных варианта:
1) ParamType - указатель или ссылка, но не универсальная ссылка.
2) ParamType - универсальная ссылка.
3) ParamType - ни указатель, ни ссылка.
Все это в следующих постах будем раскрывать подробнее.
Use deduction. Stay cool.
#cppcore #template
#новичкам
Пользователи 98-го стандарта недоумевали, почему они обязаны при наличии инициализатора указывать полный тип переменной при ее определении. "Если я еще раз напишу полный тип итератора, то я устрою Роскомнадзор", "Вы что, хотите, чтобы я пальцы стёр?!" и тд. У многих были такие мысли. И это, вообще говоря, было очень странно, потому что компилятор уже на тот момент мог сам выводить тип на основе типа другого выражения!
В шаблонах.
Вам же не обязательно писать в шаблонных функциях тип шаблонного аргумента. В некоторых случаях компилятор за вас это может сделать.
template <class Container>
size_t my_size(const Container& container)
{
return container.size();
}
std::cout << my_size(std::vector<int>(10, 0)) << std::endl;
Здесь выведется 10 и, как вы видите, для функции my_size мы не указывали явным образом шаблонный тип.
Ну и раз уже есть наработанная схема, к которой разработчики уже привыкли, то почему бы именно ее не использовать в качестве основы вывода типов для auto? Этим риторическим вопросом задались контрибьютеры в 11-й стандарт и теперь у нас действительно есть ключевое слово auto, для которого вывод типов практически ничем не отличается от вывода типов для шаблонных функций!
Поэтому надо понимать, что это за зверь такой, чтобы осознанно использовать auto.
Чтобы мы все понимали, о чем конкретно будем говорить, посмотрим на следующий псевдокод:
template <class T>
void func(ParamType param) {...}
func(expression);
Все будем разбирать на примере подобной шаблонной функции. Так вот процесс вывода типов ParamType и Т на основании типа выражения expression - это и есть вывод шаблонных типов.
Небольшой пример:
template <class T>
size_t my_size(const std::vector<T>& vec) {...}
template <class T>
void fun(const T& param) {...}
my_size(std::vector<int>(10, 0));
int i = 42;
fun(i)
В случае c my_size ParamType - const std::vector<T>&, а тип T - int. В случае с fun ParamType принимает вид типа Т, обвешанного побрякушками, типа const- и ссылочного квалификаторов. Здесь ParamType = const T&, а Т = int.
То есть ParamType - все то, что стоит слева от имени шаблонного параметра, и на основе выведенного ParamType уже принимается решение о типе Т. Поэтому очень важно понимать не только, какой тип имеет expression, но и какой вид принимает ParamType. Есть всего 3 мажорных варианта:
1) ParamType - указатель или ссылка, но не универсальная ссылка.
2) ParamType - универсальная ссылка.
3) ParamType - ни указатель, ни ссылка.
Все это в следующих постах будем раскрывать подробнее.
Use deduction. Stay cool.
#cppcore #template
{kind=link}
Небольшой пролог для вывода типов
#новичкам
Посты дальше будут довольно хардкорные, но будет очень много примеров, так что готовьтесь вовлекаться в контекст и препарировать каждый пример, чтобы прям понять, как это все работает.
А сейчас я объясню некую концепцию, которая у меня сложилась в голове по ходу изучения нюансов вывод типов. Когда-то мне она помогла выровнять и законнектить все знания по этой теме, потому что примеров в интернете мало, иногда вкинут пару фраз про определенный кейс и все. А ты сиди и голову ломай, как этот черный ящик работает.
Статей с таким количеством примеров, как в следующих постах, исчезающе мало, поэтому контент уникальный. Надеюсь, вам понравится)
Коротко напомню контекст. ParamType - тип выражения-параметра функции. T - шаблонный тип функции :
Введу такую концепцию, как слои вложенности типов. Слои есть не у всех типов, а только у тех, у кого есть вложенность)
Вложенность актуальна в основном для указателей и шаблонных типов. Тип Т вложен в указатель(указетель - отдельный тип). Тип Т вложен в шаблонный контейнер(например).
Слои могут быть у типа expression и у типа param. Так вот одна из задач вывода - правильно заматчить слои этих типов друг на друга.
Представьте, что тип expression - это капуста и листы этой капусты - слои вложенности. Чтобы из типа expression грубо получить тип Т, нужно оторвать от капусты столько слоев, сколько есть в типе ParamType. И оставшаяся качерышка - и есть выведенный тип Т. Приведу примеры.
Простой одинокий шаблонный параметр.
Здесь нулевая вложенность типа параметра(нет слоев). Какую бы кракозябру вы бы туда не засунули, тип Т будет отличаться от типа expression разве что константностью и ссылочность. От капусты ни одного листа не отрываем и в выводе типа будут участвовать все слои expression.
Засунем туда переменную типа RandomType без вложенности - в выводе T будет полностью участвовать этот тип и по итогу Т будет равен RandomType.
Если засунем шаблонный тип std::set<int> с двумя слоями вложенности: внешним для std::set и внутренним для int, то в выводе будут участвовать оба слоя и Т будет иметь такой же тип std::set<int>. Снова ни одна капуста не пострадала.
Дальше ссылка
Казалось бы ссылка - это уже индирекция(под капотом лежит указатель). Однако с помощью ссылки вы только непосредственно объектом можете управлять! Поэтому в этом смысле никакой индирекции нет и тут также нулевая вложенность и рассуждения, как для предыдущего примера.
Указатель или вектор - уже появляется вложенность: наружный тип(указатель или шаблонный вектор) и внутренний тип. Так и получается, что у нас есть внутренний и внешний слой. И за счет того, что мы определили внешний слой(сказали, что наш параметр - указатель/вектор), в выводе параметра Т участвует только внутренний слой типа expression и все что в него вложено. Передам в func указатель на инт - от этой капусты отрываем внешний листок и остается тип инт, в который и выводится Т.
Если передам двойной указатель на инт int **, то мы убираем внешний слой указателя и от типа expression остается уже одинарный указатель на int *. И соответственно Т выведется в int *.
В чем проблема и зачем это все вводить и объяснять - большинство примеров в интернете ограничиваются лишь интами и ссылками на инты. Я же хочу разобрать чуть более сложные кейсы, которые не укладываются в стандартные объяснения происходящего.
Типы шаблонных параметров приблизительно так и выводятся, как описано в этом посте. Однако есть нюансы с константностью и ссылочностью, которые придется разобрать в следующих постах.
Поддержите пост лайками, если хотите подробного разбора этой темы.
Support hardcore stuff. Stay cool.
#cppcore #template
#новичкам
Посты дальше будут довольно хардкорные, но будет очень много примеров, так что готовьтесь вовлекаться в контекст и препарировать каждый пример, чтобы прям понять, как это все работает.
А сейчас я объясню некую концепцию, которая у меня сложилась в голове по ходу изучения нюансов вывод типов. Когда-то мне она помогла выровнять и законнектить все знания по этой теме, потому что примеров в интернете мало, иногда вкинут пару фраз про определенный кейс и все. А ты сиди и голову ломай, как этот черный ящик работает.
Статей с таким количеством примеров, как в следующих постах, исчезающе мало, поэтому контент уникальный. Надеюсь, вам понравится)
Коротко напомню контекст. ParamType - тип выражения-параметра функции. T - шаблонный тип функции :
template <class T>
void func(ParamType param) {...}
func(expression);
Введу такую концепцию, как слои вложенности типов. Слои есть не у всех типов, а только у тех, у кого есть вложенность)
Вложенность актуальна в основном для указателей и шаблонных типов. Тип Т вложен в указатель(указетель - отдельный тип). Тип Т вложен в шаблонный контейнер(например).
Слои могут быть у типа expression и у типа param. Так вот одна из задач вывода - правильно заматчить слои этих типов друг на друга.
Представьте, что тип expression - это капуста и листы этой капусты - слои вложенности. Чтобы из типа expression грубо получить тип Т, нужно оторвать от капусты столько слоев, сколько есть в типе ParamType. И оставшаяся качерышка - и есть выведенный тип Т. Приведу примеры.
Простой одинокий шаблонный параметр.
template <class T>
void func(T param) {...}
Здесь нулевая вложенность типа параметра(нет слоев). Какую бы кракозябру вы бы туда не засунули, тип Т будет отличаться от типа expression разве что константностью и ссылочность. От капусты ни одного листа не отрываем и в выводе типа будут участвовать все слои expression.
Засунем туда переменную типа RandomType без вложенности - в выводе T будет полностью участвовать этот тип и по итогу Т будет равен RandomType.
Если засунем шаблонный тип std::set<int> с двумя слоями вложенности: внешним для std::set и внутренним для int, то в выводе будут участвовать оба слоя и Т будет иметь такой же тип std::set<int>. Снова ни одна капуста не пострадала.
Дальше ссылка
template <class T>
void func(T& param) {...}
Казалось бы ссылка - это уже индирекция(под капотом лежит указатель). Однако с помощью ссылки вы только непосредственно объектом можете управлять! Поэтому в этом смысле никакой индирекции нет и тут также нулевая вложенность и рассуждения, как для предыдущего примера.
template <class T>
void func(T * param) {...}
template <class T>
void func1(std::vector<T> param) {...}
Указатель или вектор - уже появляется вложенность: наружный тип(указатель или шаблонный вектор) и внутренний тип. Так и получается, что у нас есть внутренний и внешний слой. И за счет того, что мы определили внешний слой(сказали, что наш параметр - указатель/вектор), в выводе параметра Т участвует только внутренний слой типа expression и все что в него вложено. Передам в func указатель на инт - от этой капусты отрываем внешний листок и остается тип инт, в который и выводится Т.
Если передам двойной указатель на инт int **, то мы убираем внешний слой указателя и от типа expression остается уже одинарный указатель на int *. И соответственно Т выведется в int *.
В чем проблема и зачем это все вводить и объяснять - большинство примеров в интернете ограничиваются лишь интами и ссылками на инты. Я же хочу разобрать чуть более сложные кейсы, которые не укладываются в стандартные объяснения происходящего.
Типы шаблонных параметров приблизительно так и выводятся, как описано в этом посте. Однако есть нюансы с константностью и ссылочностью, которые придется разобрать в следующих постах.
Поддержите пост лайками, если хотите подробного разбора этой темы.
Support hardcore stuff. Stay cool.
#cppcore #template
{kind=link}
Как посмотреть шаблонный тип
#новичкам
Вчера Антон сделал важное замечание, что неплохо бы показать, как самому посмотреть, во что выводится тип Т в каждом конкретном случае. Собсна, погнали.
В С++ стандартными средствами конечно можно это сделать, но решение будет довольно громоздкое и некрасивое с точки зрения пользователя.
Хотелось бы что-то очень простое, желательно вообще однострочное. Обычно таких решений в плюсах нет и надо городить огород, но не в этом случае. Благодаря обширным возможностям препроцессора компиляторы зачастую определяют свои макросы, которые раскрываются в сигнатуру функции. В случае же с шаблонной функцией, они показывают и правильный выведенный шаблонный тип.
Для шланга и гцц этот макрос называется __PRETTY_FUNCTION__, а для msvc - __FUNCSIG__. Пользоваться ими можно примерно так:
Для кланга вывод будет такой:
Для msvc:
Тут на мой взгляд msvc предоставляет несколько более полный и понятный функционал, но кому как удобно.
Можете поиграться в годболте.
See through things. Stay cool.
#compiler #template
#новичкам
Вчера Антон сделал важное замечание, что неплохо бы показать, как самому посмотреть, во что выводится тип Т в каждом конкретном случае. Собсна, погнали.
В С++ стандартными средствами конечно можно это сделать, но решение будет довольно громоздкое и некрасивое с точки зрения пользователя.
Хотелось бы что-то очень простое, желательно вообще однострочное. Обычно таких решений в плюсах нет и надо городить огород, но не в этом случае. Благодаря обширным возможностям препроцессора компиляторы зачастую определяют свои макросы, которые раскрываются в сигнатуру функции. В случае же с шаблонной функцией, они показывают и правильный выведенный шаблонный тип.
Для шланга и гцц этот макрос называется __PRETTY_FUNCTION__, а для msvc - __FUNCSIG__. Пользоваться ими можно примерно так:
#if defined __clang__ || __GNUC__
#define FUNCTION_SIGNATURE __PRETTY_FUNCTION__
#elif defined __FUNCSIG__
#define FUNCTION_SIGNATURE __FUNCSIG__
#endif
template<class T>
void func(const T& param) {
std::cout << FUNCTION_SIGNATURE << std::endl;
}
func(std::vector<int>{});
Для кланга вывод будет такой:
void func(const T &) [T = std::vector<int>]
Для msvc:
void __cdecl func<class std::vector<int,class std::allocator<int> >>(const class std::vector<int,class std::allocator<int> > &)
Тут на мой взгляд msvc предоставляет несколько более полный и понятный функционал, но кому как удобно.
Можете поиграться в годболте.
See through things. Stay cool.
#compiler #template
{kind=link}
Квиз
Сегодня будет довольно противоречивый #quiz. Ничего не буду говорить. Просто задам вопрос. А подробный ответ будет вечером.
Какой результат попытки компиляции и выполнения этого кода:
Сегодня будет довольно противоречивый #quiz. Ничего не буду говорить. Просто задам вопрос. А подробный ответ будет вечером.
Какой результат попытки компиляции и выполнения этого кода:
#include <algorithm>
#include <iostream>
struct foo {
static const int qwerty = 100;
};
int main() {
std::cout << std::max(0, foo::qwerty) << std::endl;
return 0;
}