
Приветственный пост
Рады приветствовать всех на нашем канале!
Вы устали от скучного, монотонного, обезличенного контента по плюсам?
Тогда мы идем к вам!
Здесь не будет бесполезных 30 IQ постов, сгенеренных ChatGPT, накрученных подписчиков и активности.
Канал ведут два сеньора, Денис и Владимир, которые искренне хотят делится своими знаниями по С++ и создать самое уютное коммьюнити позитивных прогеров в телеге!
(ну вы поняли, да? с++, плюс плюс, плюс типа
позитивный?.. ай ладно)
Жмакай и попадешь в наш чат. Там обсуждения не привязаны к постам, можете общаться на любые темы.
Материалы для новичка
ГАЙДЫ:
Мини-гайд по собеседования
Гайд по категория выражения и мув-семантике
Гайд по inline
Дальше пойдет список хэштегов, которыми вы можете пользоваться для более удобной навигации по каналу и для быстрого поиска группы постов по интересующей теме:
#algorithms
#datastructures
#cppcore
#stl
#goodoldc
#cpp11
#cpp14
#cpp17
#cpp20
#commercial
#net
#database
#hardcore
#memory
#goodpractice
#howitworks
#NONSTANDARD
#interview
#digest
#OS
#tools
#optimization
#performance
#fun
#compiler
#multitasking
#design
#exception
#guide
#задачки
#base
#quiz
#concurrency
Рады приветствовать всех на нашем канале!
Вы устали от скучного, монотонного, обезличенного контента по плюсам?
Тогда мы идем к вам!
Здесь не будет бесполезных 30 IQ постов, сгенеренных ChatGPT, накрученных подписчиков и активности.
Канал ведут два сеньора, Денис и Владимир, которые искренне хотят делится своими знаниями по С++ и создать самое уютное коммьюнити позитивных прогеров в телеге!
(ну вы поняли, да? с++, плюс плюс, плюс типа
позитивный?.. ай ладно)
Жмакай и попадешь в наш чат. Там обсуждения не привязаны к постам, можете общаться на любые темы.
Материалы для новичка
ГАЙДЫ:
Мини-гайд по собеседования
Гайд по категория выражения и мув-семантике
Гайд по inline
Дальше пойдет список хэштегов, которыми вы можете пользоваться для более удобной навигации по каналу и для быстрого поиска группы постов по интересующей теме:
#algorithms
#datastructures
#cppcore
#stl
#goodoldc
#cpp11
#cpp14
#cpp17
#cpp20
#commercial
#net
#database
#hardcore
#memory
#goodpractice
#howitworks
#NONSTANDARD
#interview
#digest
#OS
#tools
#optimization
#performance
#fun
#compiler
#multitasking
#design
#exception
#guide
#задачки
#base
#quiz
#concurrency
Telegram
Грокаем C++ Chat
You’ve been invited to join this group on Telegram.
CREATE TABLE IF NOT EXIST
Вроде бы SQL запрос с подобным началом выглядит довольно разумно: зачем создавать таблицу, когда она уже есть в базе. Однако же он таит в себе проблему. В многопоточном приложении этот запрос может приводить к состоянию гонки.
Короткая справка по race condition'у: это такое состояние программы, когда корректность выполнения куска кода зависит от таймингов или порядка выполнения операций в нем.
Давайте посмотрим, что происходит внутри базы данных, что может вызвать такие проблемы. Запрос «CREATE TABLE IF NOT EXISTS» проверяет, существует ли таблица в базе данных. Если это не так, таблица создается; в противном случае он пропускает этап создания. Однако при одновременном выполнении нескольких запросов может возникнуть состояние гонки из-за следующих шагов:
1️⃣ Проверка существования таблицы. Первый шаг — проверить, существует ли таблица в базе данных. Это включает в себя доступ к метаданным базы данных и поиск имени таблицы.
2️⃣ Создание таблицы: если таблица не существует, запрос переходит к ее созданию. Это включает в себя выделение ресурсов, определение схемы таблицы и обновление метаданных.
2️⃣ Атомарность. Основная проблема возникает, когда несколько запросов одновременно проверяют существование таблицы. Они могут увидеть, что таблицы не существует, и создать ее самостоятельно. Результатом является попытка создание нескольких одинаковых таблиц, что нарушает смысл условия «ЕСЛИ НЕ СУЩЕСТВУЕТ».
Последствия этой проблемы: ошибки там, где вы их не ожидаете. Нельзя в большинстве реляционных баз данных взять и просто создать 2 одинаковые таблицы. Вы получите ошибку. А самое приятное, что эта ошибка зависит от Бога Рандома, поэтому отловить ее, воспроизвести или пофиксить будет непросто.
В будущем расскажу, как предотвратить эти проблемы.
Stay cool.
#database #multitasking
Вроде бы SQL запрос с подобным началом выглядит довольно разумно: зачем создавать таблицу, когда она уже есть в базе. Однако же он таит в себе проблему. В многопоточном приложении этот запрос может приводить к состоянию гонки.
Короткая справка по race condition'у: это такое состояние программы, когда корректность выполнения куска кода зависит от таймингов или порядка выполнения операций в нем.
Давайте посмотрим, что происходит внутри базы данных, что может вызвать такие проблемы. Запрос «CREATE TABLE IF NOT EXISTS» проверяет, существует ли таблица в базе данных. Если это не так, таблица создается; в противном случае он пропускает этап создания. Однако при одновременном выполнении нескольких запросов может возникнуть состояние гонки из-за следующих шагов:
1️⃣ Проверка существования таблицы. Первый шаг — проверить, существует ли таблица в базе данных. Это включает в себя доступ к метаданным базы данных и поиск имени таблицы.
2️⃣ Создание таблицы: если таблица не существует, запрос переходит к ее созданию. Это включает в себя выделение ресурсов, определение схемы таблицы и обновление метаданных.
2️⃣ Атомарность. Основная проблема возникает, когда несколько запросов одновременно проверяют существование таблицы. Они могут увидеть, что таблицы не существует, и создать ее самостоятельно. Результатом является попытка создание нескольких одинаковых таблиц, что нарушает смысл условия «ЕСЛИ НЕ СУЩЕСТВУЕТ».
Последствия этой проблемы: ошибки там, где вы их не ожидаете. Нельзя в большинстве реляционных баз данных взять и просто создать 2 одинаковые таблицы. Вы получите ошибку. А самое приятное, что эта ошибка зависит от Бога Рандома, поэтому отловить ее, воспроизвести или пофиксить будет непросто.
В будущем расскажу, как предотвратить эти проблемы.
Stay cool.
#database #multitasking
{kind=link}
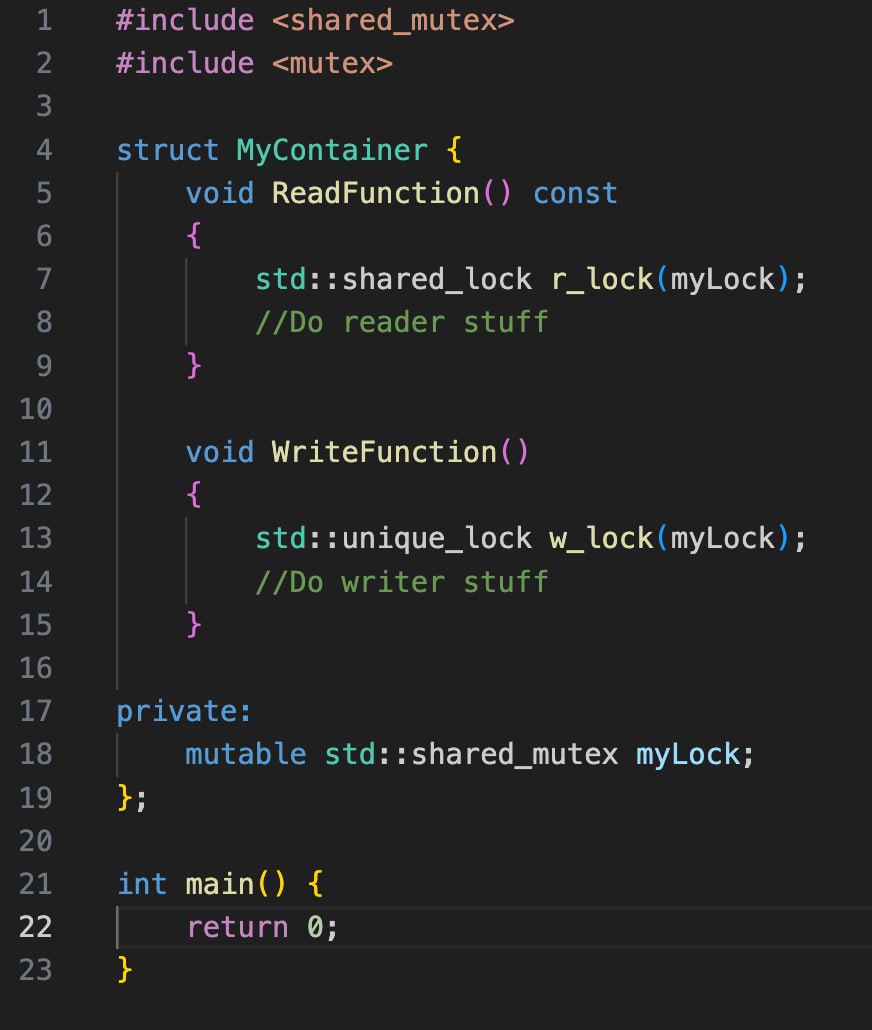
Потокобезопасные константные методы
Представьте, что у вас есть есть кастомный контейнер, который хранит ваши данные каким-то нетривиальным образом. Как и у любого контейнера, у него должны быть методы аля insert(…) для вставки значения в контейнер и методы для доступа к элементам get(…)(оператор [], at() и тд). Согласно правилам организации хорошего и понятного кода вы объявили get() как const. Оно и понятно, ведь любой пользователь вашего контейнера будет понимать, что доступ к элементам контейнера никак не будет отражаться на его внутреннем устройстве. Это делает код более понятным и безопасным для пользователя. Все хорошо и прекрасно.
Но тут вам приходит идея сделать этот контейнер потокобезопасным. Проблем нет, заводим shared_mutex как поле объекта и лочим операции вставки и доступа. Используем read-write lock, чтобы несколько потоков одновременно могли безопасно читать из контейнера значения, а как только придёт пишущий поток, блокировать операции чтения и записи для других потоков. Компилируем это дело и получаем ошибку. Причём гцц вам как всегда выдаст самое понятное сообщение об ошибке. Такое, что глаза вытекают и мозг плавится. Но рано или поздно осознание придёт. Вы не можете изменять поля класса в константных методах. Что делать?
На деле проблема серьёзная. С одной стороны, пользователь должен получать доступ к чтению элементов контейнера у константного объекта, иначе он по сути бесполезен. С другой стороны, существует ряд юз-кейсов, когда для оптимизации константной операции требуется изменять внутреннее состояние объекта. Классика - это использование кэш-значения и замков.
Поэтому в языке есть ключевое слово, про которое все, вплоть до мидлов, забывают и встречаются с ним только на собесах. Mutable. Этот keyword разрешает изменять какое-то поле класса в константных методах. Объявим наш shared_mutex как mutable и все заработает.
Решение элегантное, красивое и лаконичное. Только вот само использование этого приема попахивает нарушением инкапсуляции. Немножко совсем. Поэтому не стоит злоупотреблять этим приемом и скрывать им недостатки архитектуры класса. Если вам нужно поменять объект в константном методе и это не общепринятый кейс использования mutable - вам скорее всего нужно пересмотреть дизайн.
Stay safe. Stay cool.
#multitasking #cppcore #design
Представьте, что у вас есть есть кастомный контейнер, который хранит ваши данные каким-то нетривиальным образом. Как и у любого контейнера, у него должны быть методы аля insert(…) для вставки значения в контейнер и методы для доступа к элементам get(…)(оператор [], at() и тд). Согласно правилам организации хорошего и понятного кода вы объявили get() как const. Оно и понятно, ведь любой пользователь вашего контейнера будет понимать, что доступ к элементам контейнера никак не будет отражаться на его внутреннем устройстве. Это делает код более понятным и безопасным для пользователя. Все хорошо и прекрасно.
Но тут вам приходит идея сделать этот контейнер потокобезопасным. Проблем нет, заводим shared_mutex как поле объекта и лочим операции вставки и доступа. Используем read-write lock, чтобы несколько потоков одновременно могли безопасно читать из контейнера значения, а как только придёт пишущий поток, блокировать операции чтения и записи для других потоков. Компилируем это дело и получаем ошибку. Причём гцц вам как всегда выдаст самое понятное сообщение об ошибке. Такое, что глаза вытекают и мозг плавится. Но рано или поздно осознание придёт. Вы не можете изменять поля класса в константных методах. Что делать?
На деле проблема серьёзная. С одной стороны, пользователь должен получать доступ к чтению элементов контейнера у константного объекта, иначе он по сути бесполезен. С другой стороны, существует ряд юз-кейсов, когда для оптимизации константной операции требуется изменять внутреннее состояние объекта. Классика - это использование кэш-значения и замков.
Поэтому в языке есть ключевое слово, про которое все, вплоть до мидлов, забывают и встречаются с ним только на собесах. Mutable. Этот keyword разрешает изменять какое-то поле класса в константных методах. Объявим наш shared_mutex как mutable и все заработает.
Решение элегантное, красивое и лаконичное. Только вот само использование этого приема попахивает нарушением инкапсуляции. Немножко совсем. Поэтому не стоит злоупотреблять этим приемом и скрывать им недостатки архитектуры класса. Если вам нужно поменять объект в константном методе и это не общепринятый кейс использования mutable - вам скорее всего нужно пересмотреть дизайн.
Stay safe. Stay cool.
#multitasking #cppcore #design
{kind=link}
Как создать поток с помощью метода?
Пост коротенький, но возможно вы не знали о такой фишке.
Если вдруг так случилось, что вам нужно запустить поток не с помощью свободной функции, а с помощью нестатического метода класса, то возникает вопрос. Метод ведь может быть вызван только из существующего объекта и не очевидно, как это можно сделать с вот таким набором конструкторов для класса потока:
thread() noexcept;
thread( thread&& other ) noexcept;
template< class Function, class... Args >
explicit thread( Function&& f, Args&&... args );
Поэтому рассказываю. Нужно первым аргументом передать в конструктор указатель на метод и вторым аргументом - сам объект. Тогда компилятор все поймёт и сгенерирует такой код, чтобы поток начал выполняться с методом класса. Прикрепил пример кода, как это выглядит.
Если метод принимает несколько аргументов, все они должны идти после указателя на объект третьим, четвёртым и тд аргументом.
Пост бы написан давно и в спешке. Теперь понимаю, что здесь можно несколько подробностей еще осветить, поэтому ждите продолжения)
Stay versatile. Stay cool.
#multitasking #cppcore
Пост коротенький, но возможно вы не знали о такой фишке.
Если вдруг так случилось, что вам нужно запустить поток не с помощью свободной функции, а с помощью нестатического метода класса, то возникает вопрос. Метод ведь может быть вызван только из существующего объекта и не очевидно, как это можно сделать с вот таким набором конструкторов для класса потока:
thread() noexcept;
thread( thread&& other ) noexcept;
template< class Function, class... Args >
explicit thread( Function&& f, Args&&... args );
Поэтому рассказываю. Нужно первым аргументом передать в конструктор указатель на метод и вторым аргументом - сам объект. Тогда компилятор все поймёт и сгенерирует такой код, чтобы поток начал выполняться с методом класса. Прикрепил пример кода, как это выглядит.
Если метод принимает несколько аргументов, все они должны идти после указателя на объект третьим, четвёртым и тд аргументом.
Пост бы написан давно и в спешке. Теперь понимаю, что здесь можно несколько подробностей еще осветить, поэтому ждите продолжения)
Stay versatile. Stay cool.
#multitasking #cppcore
{kind=link}
shared_ptr и потокобезопасность
Использование шареного указателя для менеджмента ресурсов в многопоточных приложениях де-факто - стандарт. Ничего другого адекватного нет для совместного использования ресурсов несколькими потоками одновременно. Есть конечно глобальные объекты, но это практически всегда зло и не очень хочется с этим связываться. И возникает вопрос - а безопасно ли использоваться std::shared_ptr в многопоточном контексте?
Тут есть на самом деле, о чем порассуждать. Потому что размножение вашего объекта и чтение его данных - thread-safe. С чтением все понятно, никто ничего не меняет, поэтому и гонок быть не может. Но вот размножение почему? Дело в атомарном счетчике ссылок. Каждый вызов конструктора и деструктора инкрементирует или декрементирует общий для всех объектов указателя счетчик ссылок. Однако эти операции выполняются атомарно. То есть ни один поток не может увидеть промежуточный результат таких операций. Поэтому размножение и смерть объектов умного указателя - потокобезопасны..
Но вряд ли часто появляются кейсы, когда везде с собой нужно таскать объект, который никто не будет изменять. Потоки для того и работают с общими данными, чтобы и читать их, и изменять.
Ну и конечно, шаренный указатель не предоставляет из коробки потокобезопасное использование объектов, на которые он указывает. Тут работает один из базовых принципов С++ - не плати за то, чем не пользуешься. Потокобезопасность - это всегда дополнительные расходы памяти и производительности. И внедрение этой фичи замедлило бы приложения, которые этой фичей не пользовались.
Так что вызов изменяющих методов объектов, для которых не позаботились о их безопасности, в разных тредах - гарантированные трудноотловмые многопоточные проблемы. Какие? Да вообще любые. Пусть вы храните какую-нибудь мапу и передаете ее везде в виде шаред поинтера. Как только к эту мапу захочет записать какой-нибудь поток, начнет это делать и через писечную долю секунды придет читающий поток, то он увидит данные в неконсистентном состоянии. Только что на ваших глазах произошла так называемая гонка данных. И это самая тривиальная проблема. Баги могут быть намного более изощренными.
Поэтому критически важно синхронизировать доступ потоков для объектов, которые будут использоваться множеством потоков.
Stay safe. Stay cool.
#multitasking #cpp11
Использование шареного указателя для менеджмента ресурсов в многопоточных приложениях де-факто - стандарт. Ничего другого адекватного нет для совместного использования ресурсов несколькими потоками одновременно. Есть конечно глобальные объекты, но это практически всегда зло и не очень хочется с этим связываться. И возникает вопрос - а безопасно ли использоваться std::shared_ptr в многопоточном контексте?
Тут есть на самом деле, о чем порассуждать. Потому что размножение вашего объекта и чтение его данных - thread-safe. С чтением все понятно, никто ничего не меняет, поэтому и гонок быть не может. Но вот размножение почему? Дело в атомарном счетчике ссылок. Каждый вызов конструктора и деструктора инкрементирует или декрементирует общий для всех объектов указателя счетчик ссылок. Однако эти операции выполняются атомарно. То есть ни один поток не может увидеть промежуточный результат таких операций. Поэтому размножение и смерть объектов умного указателя - потокобезопасны..
Но вряд ли часто появляются кейсы, когда везде с собой нужно таскать объект, который никто не будет изменять. Потоки для того и работают с общими данными, чтобы и читать их, и изменять.
Ну и конечно, шаренный указатель не предоставляет из коробки потокобезопасное использование объектов, на которые он указывает. Тут работает один из базовых принципов С++ - не плати за то, чем не пользуешься. Потокобезопасность - это всегда дополнительные расходы памяти и производительности. И внедрение этой фичи замедлило бы приложения, которые этой фичей не пользовались.
Так что вызов изменяющих методов объектов, для которых не позаботились о их безопасности, в разных тредах - гарантированные трудноотловмые многопоточные проблемы. Какие? Да вообще любые. Пусть вы храните какую-нибудь мапу и передаете ее везде в виде шаред поинтера. Как только к эту мапу захочет записать какой-нибудь поток, начнет это делать и через писечную долю секунды придет читающий поток, то он увидит данные в неконсистентном состоянии. Только что на ваших глазах произошла так называемая гонка данных. И это самая тривиальная проблема. Баги могут быть намного более изощренными.
Поэтому критически важно синхронизировать доступ потоков для объектов, которые будут использоваться множеством потоков.
Stay safe. Stay cool.
#multitasking #cpp11
{kind=link}
std::thread::id
Когда в процессе может существовать несколько потоков(а сейчас обычно это условие выполняется), то очевидно, что эти потоки надо как-то идентифицировать. Они будут конкурировать друг с другом за ресурсы и планировщику нужно знать, кому именно нужно выдавать заветное процессорное время. И действительно, у каждого потока в системе есть свой уникальный номер(лучше сказать идентификатор). И мы, как прикладные разработчики, можем даже его получить. С появлением С++11 у нас есть стандартное средство для этого - std::thread::id. Это тип, который и представляет собой идентификатор потока.
Его можно получить двумя способами - снаружи потока и внутри него.
Снаружи мы должны иметь объект std::thread, у которого хотим узнать id, и вызвать у него метод get_id(). Если с объектом не связан никакой поток исполнения, то вернется дефолтно-сконструированный объект, обозначающий "я девушка свободная, не обременненная никаким исполнением".
Внутри id можно достать с помощью свободной функции std::this_thread::get_id().
Объекты типа std::thread::id могут свободно копироваться и сравниваться. Иначе их нельзя было бы использовать, как идентификаторы. Если два объекта типа std::thread::id равны, то они репрезентуют один и тот же тред. Или оба являются свободными девушками. Если объекты не равны, то они представляют разные треды или один из них создан конструктором по умолчанию.
Стандартная библиотека никак не ограничивает вас в проверке одинаковые ли идентификаторы или нет: для объектов std::thread::id предусмотрен полный набор операторов сравнения, которые предоставляют возможность упорядочить все отличные друг от друга значения. Эта возможность позволяет использовать id в качестве ключей в ассоциативных контейнерах, они могут быть отсортированы и тд. Все вытекающие плюшки. Операторы сравнения обеспечивают свойство транзитивности для объектов. То есть, если a < b и b < c, то a < c.
Также у нас из коробки есть возможность получить хэш id с помощью std::hash<std::thread::id>, что позволяет использовать идентификаторы потоков в хэш-таблицах, аля unordered контейнерах.
На самом деле, не очень тривиально понять, где и как эти айдишники могут быть использованы, поэтому в следующем посте проясню этот момент подробно.
Identify yourself. Stay cool.
#multitasking #cpp11
Когда в процессе может существовать несколько потоков(а сейчас обычно это условие выполняется), то очевидно, что эти потоки надо как-то идентифицировать. Они будут конкурировать друг с другом за ресурсы и планировщику нужно знать, кому именно нужно выдавать заветное процессорное время. И действительно, у каждого потока в системе есть свой уникальный номер(лучше сказать идентификатор). И мы, как прикладные разработчики, можем даже его получить. С появлением С++11 у нас есть стандартное средство для этого - std::thread::id. Это тип, который и представляет собой идентификатор потока.
Его можно получить двумя способами - снаружи потока и внутри него.
Снаружи мы должны иметь объект std::thread, у которого хотим узнать id, и вызвать у него метод get_id(). Если с объектом не связан никакой поток исполнения, то вернется дефолтно-сконструированный объект, обозначающий "я девушка свободная, не обременненная никаким исполнением".
Внутри id можно достать с помощью свободной функции std::this_thread::get_id().
Объекты типа std::thread::id могут свободно копироваться и сравниваться. Иначе их нельзя было бы использовать, как идентификаторы. Если два объекта типа std::thread::id равны, то они репрезентуют один и тот же тред. Или оба являются свободными девушками. Если объекты не равны, то они представляют разные треды или один из них создан конструктором по умолчанию.
Стандартная библиотека никак не ограничивает вас в проверке одинаковые ли идентификаторы или нет: для объектов std::thread::id предусмотрен полный набор операторов сравнения, которые предоставляют возможность упорядочить все отличные друг от друга значения. Эта возможность позволяет использовать id в качестве ключей в ассоциативных контейнерах, они могут быть отсортированы и тд. Все вытекающие плюшки. Операторы сравнения обеспечивают свойство транзитивности для объектов. То есть, если a < b и b < c, то a < c.
Также у нас из коробки есть возможность получить хэш id с помощью std::hash<std::thread::id>, что позволяет использовать идентификаторы потоков в хэш-таблицах, аля unordered контейнерах.
На самом деле, не очень тривиально понять, где и как эти айдишники могут быть использованы, поэтому в следующем посте проясню этот момент подробно.
Identify yourself. Stay cool.
#multitasking #cpp11
{kind=link}
Зачем нужен std::thread::id?
Не так-то и просто придумать практические кейсы использования std::thread::id. Поэтому тут скорее будут какие-то общие вещи. Если вы можете рассказать о своем опыте, то поделитесь им в комментариях.
Но давайте отталкиваться от операций, которые мы можем выполнять с айдишниками.
Мы их можем сравнивать, что дает нам возможность хранить их в упорядоченных ассоциативных контейнерах и, в целом, сравнивать 2 значения идентификаторов. Также мы можем взять хэш от thread::id, поэтому можем хранить их в неупорядоченных ассоциативных контейнерах. Также мы можем сериализовать эти айдишники в наследников std::basic_ostream ака писать в какие-то потоки (например stdout или файл).
Последнее явно нам намекает на логирование событий разных тредов. И это наверное самый популярный вариант их использования. Например, можно логировать скорости обработки запросов, какие-то thread-specific инкременты, cpu usage, возникающие ошибки и тд. Эти данные помогут при аналитике сервиса или при отладке.
Теперь про сравнения. Два различных потока должны иметь разные айдишники. Это поможет нам проверить, выполняется ли какая-то функция в нужном потоке. Например, мы создали какой-то класс и в его конструкторе сохраняем айди потока, в котором он был создан. Опять же, если у нас есть класс, который накапливает статистику по потоку, он не то чтобы должен быть thread-safe, его просто нельзя использовать в потоках, отличных от того, в котором объект был создан. Это будет некорректным поведением. Поэтому перед каждый сохранением статов можно проверять равенство std::this_thread::get_id() и сохраненного значения идентификатора.
Какие-нибудь асинхронные штуки, типа асинхронных клиентов, тоже могут быть сильно завязаны на конкретном потоке и для них тоже нужно постоянно проверять валидность текущего потока.
Ну и возможность хранения в ассоциативных контейнерах. Для этого нужны какие-то данные, которые будут ассоциированы с конкретным потоком. Например, там могут находится контексты исполнения потоков, thread specific очереди задач или событий или, опять же, какая-то статистика по потокам. В такие структуры данных можно писать без замков и, при необходимости, аггрегировать собранные результаты.
Хоть это и очень узкоспециализированные use case'ы, лучше знать, какие инструментны нужно использовать для решения таких задач.
Know the right tool. Stay cool.
#multitasking
Не так-то и просто придумать практические кейсы использования std::thread::id. Поэтому тут скорее будут какие-то общие вещи. Если вы можете рассказать о своем опыте, то поделитесь им в комментариях.
Но давайте отталкиваться от операций, которые мы можем выполнять с айдишниками.
Мы их можем сравнивать, что дает нам возможность хранить их в упорядоченных ассоциативных контейнерах и, в целом, сравнивать 2 значения идентификаторов. Также мы можем взять хэш от thread::id, поэтому можем хранить их в неупорядоченных ассоциативных контейнерах. Также мы можем сериализовать эти айдишники в наследников std::basic_ostream ака писать в какие-то потоки (например stdout или файл).
Последнее явно нам намекает на логирование событий разных тредов. И это наверное самый популярный вариант их использования. Например, можно логировать скорости обработки запросов, какие-то thread-specific инкременты, cpu usage, возникающие ошибки и тд. Эти данные помогут при аналитике сервиса или при отладке.
Теперь про сравнения. Два различных потока должны иметь разные айдишники. Это поможет нам проверить, выполняется ли какая-то функция в нужном потоке. Например, мы создали какой-то класс и в его конструкторе сохраняем айди потока, в котором он был создан. Опять же, если у нас есть класс, который накапливает статистику по потоку, он не то чтобы должен быть thread-safe, его просто нельзя использовать в потоках, отличных от того, в котором объект был создан. Это будет некорректным поведением. Поэтому перед каждый сохранением статов можно проверять равенство std::this_thread::get_id() и сохраненного значения идентификатора.
Какие-нибудь асинхронные штуки, типа асинхронных клиентов, тоже могут быть сильно завязаны на конкретном потоке и для них тоже нужно постоянно проверять валидность текущего потока.
Ну и возможность хранения в ассоциативных контейнерах. Для этого нужны какие-то данные, которые будут ассоциированы с конкретным потоком. Например, там могут находится контексты исполнения потоков, thread specific очереди задач или событий или, опять же, какая-то статистика по потокам. В такие структуры данных можно писать без замков и, при необходимости, аггрегировать собранные результаты.
Хоть это и очень узкоспециализированные use case'ы, лучше знать, какие инструментны нужно использовать для решения таких задач.
Know the right tool. Stay cool.
#multitasking
{kind=link}
Уникален ли std::thread::id среди всех процессов?
std::thread::id используется как уникальный идентификатор потока внутри вашего приложения. Но тут возникает интересный вопрос. А вот допустим я запустил 2 инстанса моего многопоточного приложения. Могу ли я гаранировать, что айди потоков будут уникальны между двумя инстансами? Например, я хочу какую-то общую для всех инстансов логику сделать, основанную на идентификаторах потоков. Могу ли я положиться на их уникальность? Или даже более общий вопрос: уникален ли std::thread::id среди всех процессов в системе?
Начнем с того, что стандарт С++ ничего не знает про процессы. Точно так же, как и до С++11, стандарт ничего не знал про потоки. У нас нет никаких стандартных инструментов(syscall - это не плюсовый инструмент) для работы с процессами, их запуском или для общения между процессами. И раз это не специфицировано стандратном, мы не можем ничего гарантировать. Потому что никаких гарантий и нет. Единственная гарантия стандарта относительно std::thread::id - идентификаторы - уникальны для каждого потока выполнения и могут переиспользоваться из уничтоженных потоков. Но давайте посмотрим немного глубже, на основу std::thread. Возможно там мы найдем ответ.
И тут есть 2 основных варианта. Для unix-подобных систем std::thread реализован на основе pthreads. Для виндовса это будет Windows Thread API.
В доках pthreads написано: "Thread IDs are guaranteed to be unique only within a process". Так что на юникс системах идентификатор потока уникален только в пределах одного процесса и может повторяться в разных процессах.
А вот доках Win32 API написано следующее: "Until the thread terminates, the thread identifier uniquely identifies the thread throughout the system". Оказывается, что на винде айди потока уникален среди всех процессов. Эти айдишники выдаются из одного пула, поэтому их значения синхронизированы сквозь все процессы.
Как всегда, вы вольны выбирать между кроссплатформеностью и возможностью использовать нужные особенности конкретной системы. Но интересно, что у двух систем такие разные подходы к этому вопросу.
Stay unique all over the world. Stay cool.
#cpp11 #cppcore #OS #multitasking
std::thread::id используется как уникальный идентификатор потока внутри вашего приложения. Но тут возникает интересный вопрос. А вот допустим я запустил 2 инстанса моего многопоточного приложения. Могу ли я гаранировать, что айди потоков будут уникальны между двумя инстансами? Например, я хочу какую-то общую для всех инстансов логику сделать, основанную на идентификаторах потоков. Могу ли я положиться на их уникальность? Или даже более общий вопрос: уникален ли std::thread::id среди всех процессов в системе?
Начнем с того, что стандарт С++ ничего не знает про процессы. Точно так же, как и до С++11, стандарт ничего не знал про потоки. У нас нет никаких стандартных инструментов(syscall - это не плюсовый инструмент) для работы с процессами, их запуском или для общения между процессами. И раз это не специфицировано стандратном, мы не можем ничего гарантировать. Потому что никаких гарантий и нет. Единственная гарантия стандарта относительно std::thread::id - идентификаторы - уникальны для каждого потока выполнения и могут переиспользоваться из уничтоженных потоков. Но давайте посмотрим немного глубже, на основу std::thread. Возможно там мы найдем ответ.
И тут есть 2 основных варианта. Для unix-подобных систем std::thread реализован на основе pthreads. Для виндовса это будет Windows Thread API.
В доках pthreads написано: "Thread IDs are guaranteed to be unique only within a process". Так что на юникс системах идентификатор потока уникален только в пределах одного процесса и может повторяться в разных процессах.
А вот доках Win32 API написано следующее: "Until the thread terminates, the thread identifier uniquely identifies the thread throughout the system". Оказывается, что на винде айди потока уникален среди всех процессов. Эти айдишники выдаются из одного пула, поэтому их значения синхронизированы сквозь все процессы.
Как всегда, вы вольны выбирать между кроссплатформеностью и возможностью использовать нужные особенности конкретной системы. Но интересно, что у двух систем такие разные подходы к этому вопросу.
Stay unique all over the world. Stay cool.
#cpp11 #cppcore #OS #multitasking
{kind=link}
Варианты запуска потоков
В прошлом я рассказал, что можно запускать поток не только свободной функцией, но и методом какого-то объекта. Во время публикации этого поста у меня появилось ощущение, что со стороны не совсем понятно, как компилятор различает аргументы функции, саму функцию и объект, из метода которого потенциально поток может быть запущен. Поэтому сегодняшний пост по это.
В С++ есть такое понятие - callable objects. Это просто сущности, которые можно вызвать. Это функции, лямбды, функторы, методы и так далее. Как можно единообразно вызывать все эти сущности? Сходу в голову ничего не приходит, но в стандартной библиотеке начиная с С++17 есть такая функция std::invoke. Вот ее сигнатура:
template< class F, class... Args>
std::invokeresultt<F, Args...> invoke(F&& f, Args&&... args) noexcept
И существуют правила, по которым эта функция парсит свои аргументы. Но не только она, а все сущности, которые как бы "вовлекают" в работу callable объект. Открывайте окна, потому что щас немного духоты будет.
Пусть INVOKE(f, t1, t2, ..., tN) - выражение, обозначающее вовлечение в работу функционального объекта f. Тогда:
Если f - указатель на метод класса T:
t1 - объект типа Т, или ссылка на объект типа Т,
или ссылка на наследника типа Т, то этот INVOKE превращается в (t1.*f)(t2, ..., tN).
t1 - ни что из перечисленного выше(то есть указатель на объект), то INVOKE превращается в ((*t1).*f)(t2, ..., tN).
Если N=1 и f - указатель на член класса:
t1 - объект типа Т, или ссылка на объект типа Т,
или ссылка на наследника типа Т, то этот INVOKE превращается в t1.*f.
t1 - ни что из перечисленного выше(то есть указатель на объект), то INVOKE превращается в (*t1).*f.
Во всех других случая INVOKE разворачивается в обычный вызов функции f(t1, t2, ..., tN).
То есть конструктор std::thread, который внутри себя дергает std::invoke, на основе вот этих простых правил и решает, что ему на самом деле передали и как себя дальше вести.
Пройдитесь глазами по схеме выбора еще раз, чтобы лучше уложить ее себе в голову, потому что она не прям простая. Тут кстати есть отсылочка к моему давнему посту про вызов метода объекта через указатель. Там их целая серия, поэтому, если не смотрели, посмотрите. Получилось очень прикольно, на мой взгляд)
Так что создавайте потоки осознанно и так, как больше подходит именно в вашей ситуации. Потому что способов - тьма.
Stay versatile. Stay cool.
#multitasking
В прошлом я рассказал, что можно запускать поток не только свободной функцией, но и методом какого-то объекта. Во время публикации этого поста у меня появилось ощущение, что со стороны не совсем понятно, как компилятор различает аргументы функции, саму функцию и объект, из метода которого потенциально поток может быть запущен. Поэтому сегодняшний пост по это.
В С++ есть такое понятие - callable objects. Это просто сущности, которые можно вызвать. Это функции, лямбды, функторы, методы и так далее. Как можно единообразно вызывать все эти сущности? Сходу в голову ничего не приходит, но в стандартной библиотеке начиная с С++17 есть такая функция std::invoke. Вот ее сигнатура:
template< class F, class... Args>
std::invokeresultt<F, Args...> invoke(F&& f, Args&&... args) noexcept
И существуют правила, по которым эта функция парсит свои аргументы. Но не только она, а все сущности, которые как бы "вовлекают" в работу callable объект. Открывайте окна, потому что щас немного духоты будет.
Пусть INVOKE(f, t1, t2, ..., tN) - выражение, обозначающее вовлечение в работу функционального объекта f. Тогда:
Если f - указатель на метод класса T:
t1 - объект типа Т, или ссылка на объект типа Т,
или ссылка на наследника типа Т, то этот INVOKE превращается в (t1.*f)(t2, ..., tN).
t1 - ни что из перечисленного выше(то есть указатель на объект), то INVOKE превращается в ((*t1).*f)(t2, ..., tN).
Если N=1 и f - указатель на член класса:
t1 - объект типа Т, или ссылка на объект типа Т,
или ссылка на наследника типа Т, то этот INVOKE превращается в t1.*f.
t1 - ни что из перечисленного выше(то есть указатель на объект), то INVOKE превращается в (*t1).*f.
Во всех других случая INVOKE разворачивается в обычный вызов функции f(t1, t2, ..., tN).
То есть конструктор std::thread, который внутри себя дергает std::invoke, на основе вот этих простых правил и решает, что ему на самом деле передали и как себя дальше вести.
Пройдитесь глазами по схеме выбора еще раз, чтобы лучше уложить ее себе в голову, потому что она не прям простая. Тут кстати есть отсылочка к моему давнему посту про вызов метода объекта через указатель. Там их целая серия, поэтому, если не смотрели, посмотрите. Получилось очень прикольно, на мой взгляд)
Так что создавайте потоки осознанно и так, как больше подходит именно в вашей ситуации. Потому что способов - тьма.
Stay versatile. Stay cool.
#multitasking
{kind=link}
static local variables
В этом давнишнем посте кратко резюмировали все стороны "употребления" ключевого слова static. Сегодня поговорим про статические локальные переменные.
Это довольно интересная сущность, которая сочетает в себе поведение локального объекта функции и глобальной переменной.
От локального объекта она берет область видимости. То есть к этой переменной по имени никак нельзя обратиться вне ее функции. Можно, например, вернуть из функции ссылку на эту переменную и иметь возможность ее читать и модифицировать. Но по имени к ней можно обратиться только внутри функции. Соответственно, у static local variable нет никакого собственного типа линковки, это бессмысленно.
От глобальной переменной она берет статическое время жизни. То есть, начиная с момента своей инициализации, она продолжает существовать, пока не вызовется std::exit aka завершение программы.
Разберем немного цикл жизни такой переменной.
1) Она инициализируется при первом достижении исполнения ее объявления. Стандарт нам говорит:
То есть нам дается очень важная гарантия: локальные статические переменные инициализируются потокобезопасно. Это значит, что даже если несколько потоков одновременно зайдут в функцию и попытаются проинициализировать переменную, то победителем в этой истории будет только один поток, который и проведет инициализацию, все остальные будут ждать. Эта гарантия появляется вместе с появлением новой модели памяти и исполнения в С++11. И обычно реализуется с помощью паттерна блокировки с двойной проверкой.
Однако, если переменная числового типа или инициализируется с помощью константного выражения, то инициализация может произойти раньше(какой смысл ждать, если все понятно как делать и делать это просто).
2) При выходе из скоупа функции для статической локальной переменной не вызывается деструктор. Она продолжает жить не тужить и сохраняет свое значение до следующего вызова функции.
3) При повторном заходе в функцию объявление переменной просто игнорируется и выполняется весь код, помимо инициализации. Здесь мы можем повторно использовать переменную, изменить ее значение и вообще много чего с ней делать.
4) После завершения функции main переменная разрушается. Press F умершим.
Пример:
Функция BytesToHex переводит любое количество байт от заданного указателя в их hex представление. Раз мы знаем, что hex представление содержит только 16 символов и больше нигде эти символы не нужны, то очень удобно поместить массив этих символов в саму функцию в качестве локальной статической переменной. Так мы инкапсулируем данные и сохраним возможность 1 раз создать переменную и пользоваться именно этим инстансом во всех вызовах функции.
Один интересный момент, что kHexDigits инициализируется не при первом вызове функции. Потому что в первый раз исполнение не прошло через ее декларацию. И только начиная со второго вызова она начинает существовать и разрушается только после выхода из main().
Combine your best sides. Stay cool.
#cpp11 #multitasking #cppcore
В этом давнишнем посте кратко резюмировали все стороны "употребления" ключевого слова static. Сегодня поговорим про статические локальные переменные.
Это довольно интересная сущность, которая сочетает в себе поведение локального объекта функции и глобальной переменной.
От локального объекта она берет область видимости. То есть к этой переменной по имени никак нельзя обратиться вне ее функции. Можно, например, вернуть из функции ссылку на эту переменную и иметь возможность ее читать и модифицировать. Но по имени к ней можно обратиться только внутри функции. Соответственно, у static local variable нет никакого собственного типа линковки, это бессмысленно.
От глобальной переменной она берет статическое время жизни. То есть, начиная с момента своей инициализации, она продолжает существовать, пока не вызовется std::exit aka завершение программы.
Разберем немного цикл жизни такой переменной.
1) Она инициализируется при первом достижении исполнения ее объявления. Стандарт нам говорит:
such a variable is initialized the first
time control passes through its declaration; [...]
If control enters the declaration concurrently
while the variable is being initialized,
the concurrent execution shall wait for
completion of the initialization.
То есть нам дается очень важная гарантия: локальные статические переменные инициализируются потокобезопасно. Это значит, что даже если несколько потоков одновременно зайдут в функцию и попытаются проинициализировать переменную, то победителем в этой истории будет только один поток, который и проведет инициализацию, все остальные будут ждать. Эта гарантия появляется вместе с появлением новой модели памяти и исполнения в С++11. И обычно реализуется с помощью паттерна блокировки с двойной проверкой.
Однако, если переменная числового типа или инициализируется с помощью константного выражения, то инициализация может произойти раньше(какой смысл ждать, если все понятно как делать и делать это просто).
2) При выходе из скоупа функции для статической локальной переменной не вызывается деструктор. Она продолжает жить не тужить и сохраняет свое значение до следующего вызова функции.
3) При повторном заходе в функцию объявление переменной просто игнорируется и выполняется весь код, помимо инициализации. Здесь мы можем повторно использовать переменную, изменить ее значение и вообще много чего с ней делать.
4) После завершения функции main переменная разрушается. Press F умершим.
Пример:
std::string BytesToHex(const void* bytes, size_t size)
{
if (size) {
static const char kHexDigits[] = {'0', '1', '2', '3', '4', '5', '6', '7',
'8', '9', 'A', 'B', 'C', 'D', 'E', 'F'};
std::string output;
output.reserve(size * 2);
auto c = static_cast<const uint8_t*>(bytes);
for (size_t i = 0; i < size; ++i) {
uint8_t value = *(c + i);
output.push_back(kHexDigits[value >> 4]);
output.push_back(kHexDigits[value & 0xf]);
}
return output;
}
else {
return "";
}
}
int main()
{
std::cout << BytesToHex("", 0) << std::endl;
std::cout << BytesToHex("123", 3) << std::endl;
std::cout << BytesToHex("abc", 3) << std::endl;
}
Функция BytesToHex переводит любое количество байт от заданного указателя в их hex представление. Раз мы знаем, что hex представление содержит только 16 символов и больше нигде эти символы не нужны, то очень удобно поместить массив этих символов в саму функцию в качестве локальной статической переменной. Так мы инкапсулируем данные и сохраним возможность 1 раз создать переменную и пользоваться именно этим инстансом во всех вызовах функции.
Один интересный момент, что kHexDigits инициализируется не при первом вызове функции. Потому что в первый раз исполнение не прошло через ее декларацию. И только начиная со второго вызова она начинает существовать и разрушается только после выхода из main().
Combine your best sides. Stay cool.
#cpp11 #multitasking #cppcore
{kind=link}
Double-Checked Locking Pattern. Мотивация
#новичкам
Михаил на ретро предложил идею посмотреть в прошлое на определенную проблему и понять, как изменялись подходы к решению проблемы. Тут не прям сильно далеко пойдем и сильно много итераций будем рассматривать, но все же. Также были запросы на многопоточку и паттерны плюсовые. Собсна, все это комбинируя с большой темой статиков, начинаем изучать паттерн Блокировки с двойной проверкой.
Начнем с того, что в стародавние времена до С++11 у нас была довольно примитивная модель памяти, которая вообще не знала о существовании потоков. И не было вот этой гарантии для статических локальных переменных:
Поэтому раньше люди не могли писать такой простой код:
и надеяться на то, что объект будет создаваться потокобезопасно.
Самое простое, что можно здесь придумать - влепить замок и не париться.
У нас есть какая-то своя RAII обертка Lock над каким-то мьютексом(до С++11 ни std::mutex, ни std::lock_guard не существовало, приходилось велосипедить(ну или бустовать, кому как удобнее)).
Обратите внимание, как это работает. Статические указатели автоматически zero-инициализируются нулем, поэтому в начале inst_ptr равен NULL. Дальше нужно проверить, если указатель еще нулевой, то значит мы ничего не проинициализировали и нужно создать объект. И делать это должен один тред. Но куда поставить лок? На весь скоуп или только внутри условия на создание объекта?
Дело в том, что может получиться так, что несколько потоков одновременно войдут в условие. Но только один из них успешно возьмет лок. Создаст объект и отпустит мьютекс. Но другие потоки-то уже вошли в условие. И когда настанет их черед выполняться, то они просто будут пересоздавать объекты и мы получим бог знает какие сайдэффекты. Плюс утечку памяти, так как изначально созданные объект потеряется навсегда. Плюс получается, что наш синглтон не такой уж и сингл...
Именно поэтому замок должен стоять с самого начала, чтобы только один поток вошел в условие. И создал объект. А все остальные потоки будут просто пользоваться этим объектом, обходя условие.
Однако теперь возникает проблема. Нам, вообще говоря, этот замок нахрен не сдался после того, как мы создали объект. Захват и освобождение мьютекса - довольно затратные операции и не хотелось бы их каждый раз выполнять, когда мы просто хотим получить доступ к нашему объекту-одиночке. И было бы очень удобно перенести этот лок в условие. Но в текущей реализации это невозможно...
Здесь-то и приходит на помощь шаблон блокировки с двойной проверкой, о котором подробнее поговорим в следующих статьях.
Solve your problems. Stay cool.
#multitasking #cppcore #cpp11
#новичкам
Михаил на ретро предложил идею посмотреть в прошлое на определенную проблему и понять, как изменялись подходы к решению проблемы. Тут не прям сильно далеко пойдем и сильно много итераций будем рассматривать, но все же. Также были запросы на многопоточку и паттерны плюсовые. Собсна, все это комбинируя с большой темой статиков, начинаем изучать паттерн Блокировки с двойной проверкой.
Начнем с того, что в стародавние времена до С++11 у нас была довольно примитивная модель памяти, которая вообще не знала о существовании потоков. И не было вот этой гарантии для статических локальных переменных:
...
If control enters the declaration concurrently
while the variable is being initialized,
the concurrent execution shall wait for
completion of the initialization.
Поэтому раньше люди не могли писать такой простой код:
Singleton& GetInstance() {
static Singleton inst{};
return inst;
}
и надеяться на то, что объект будет создаваться потокобезопасно.
Самое простое, что можно здесь придумать - влепить замок и не париться.
class Singleton {
public:
static Singleton* instance() {
Lock lock;
if (inst_ptr == NULL) {
inst_ptr = new Singleton;
}
return inst_ptr;
}
private:
Singleton() = default;
static Singleton* inst_ptr;
};
У нас есть какая-то своя RAII обертка Lock над каким-то мьютексом(до С++11 ни std::mutex, ни std::lock_guard не существовало, приходилось велосипедить(ну или бустовать, кому как удобнее)).
Обратите внимание, как это работает. Статические указатели автоматически zero-инициализируются нулем, поэтому в начале inst_ptr равен NULL. Дальше нужно проверить, если указатель еще нулевой, то значит мы ничего не проинициализировали и нужно создать объект. И делать это должен один тред. Но куда поставить лок? На весь скоуп или только внутри условия на создание объекта?
Дело в том, что может получиться так, что несколько потоков одновременно войдут в условие. Но только один из них успешно возьмет лок. Создаст объект и отпустит мьютекс. Но другие потоки-то уже вошли в условие. И когда настанет их черед выполняться, то они просто будут пересоздавать объекты и мы получим бог знает какие сайдэффекты. Плюс утечку памяти, так как изначально созданные объект потеряется навсегда. Плюс получается, что наш синглтон не такой уж и сингл...
Именно поэтому замок должен стоять с самого начала, чтобы только один поток вошел в условие. И создал объект. А все остальные потоки будут просто пользоваться этим объектом, обходя условие.
Однако теперь возникает проблема. Нам, вообще говоря, этот замок нахрен не сдался после того, как мы создали объект. Захват и освобождение мьютекса - довольно затратные операции и не хотелось бы их каждый раз выполнять, когда мы просто хотим получить доступ к нашему объекту-одиночке. И было бы очень удобно перенести этот лок в условие. Но в текущей реализации это невозможно...
Здесь-то и приходит на помощь шаблон блокировки с двойной проверкой, о котором подробнее поговорим в следующих статьях.
Solve your problems. Stay cool.
#multitasking #cppcore #cpp11
{kind=link}