
Приветственный пост
Рады приветствовать всех на нашем канале!
Вы устали от скучного, монотонного, обезличенного контента по плюсам?
Тогда мы идем к вам!
Здесь не будет бесполезных 30 IQ постов, сгенеренных ChatGPT, накрученных подписчиков и активности.
Канал ведут два сеньора, Денис и Владимир, которые искренне хотят делится своими знаниями по С++ и создать самое уютное коммьюнити позитивных прогеров в телеге!
(ну вы поняли, да? с++, плюс плюс, плюс типа
позитивный?.. ай ладно)
Жмакай и попадешь в наш чат. Там обсуждения не привязаны к постам, можете общаться на любые темы.
Материалы для новичка
ГАЙДЫ:
Мини-гайд по собеседования
Гайд по категория выражения и мув-семантике
Гайд по inline
Дальше пойдет список хэштегов, которыми вы можете пользоваться для более удобной навигации по каналу и для быстрого поиска группы постов по интересующей теме:
#algorithms
#datastructures
#cppcore
#stl
#goodoldc
#cpp11
#cpp14
#cpp17
#cpp20
#commercial
#net
#database
#hardcore
#memory
#goodpractice
#howitworks
#NONSTANDARD
#interview
#digest
#OS
#tools
#optimization
#performance
#fun
#compiler
#multitasking
#design
#exception
#guide
#задачки
#base
#quiz
#concurrency
Рады приветствовать всех на нашем канале!
Вы устали от скучного, монотонного, обезличенного контента по плюсам?
Тогда мы идем к вам!
Здесь не будет бесполезных 30 IQ постов, сгенеренных ChatGPT, накрученных подписчиков и активности.
Канал ведут два сеньора, Денис и Владимир, которые искренне хотят делится своими знаниями по С++ и создать самое уютное коммьюнити позитивных прогеров в телеге!
(ну вы поняли, да? с++, плюс плюс, плюс типа
позитивный?.. ай ладно)
Жмакай и попадешь в наш чат. Там обсуждения не привязаны к постам, можете общаться на любые темы.
Материалы для новичка
ГАЙДЫ:
Мини-гайд по собеседования
Гайд по категория выражения и мув-семантике
Гайд по inline
Дальше пойдет список хэштегов, которыми вы можете пользоваться для более удобной навигации по каналу и для быстрого поиска группы постов по интересующей теме:
#algorithms
#datastructures
#cppcore
#stl
#goodoldc
#cpp11
#cpp14
#cpp17
#cpp20
#commercial
#net
#database
#hardcore
#memory
#goodpractice
#howitworks
#NONSTANDARD
#interview
#digest
#OS
#tools
#optimization
#performance
#fun
#compiler
#multitasking
#design
#exception
#guide
#задачки
#base
#quiz
#concurrency
Telegram
Грокаем C++ Chat
You’ve been invited to join this group on Telegram.
__builtin Ч2
Предыдущий пост получил неожиданное продолжение благодаря нашим подписчикам - Сергею Нефедову и @Roman657. Взаимопомощь и отзывчивость всегда помогает добиваться бо́льшего 😃
Как было подмечено, строго говоря, использование __builtin функции сопряжено с потенциальными рисками. Например, список аргументов поменяется в будущих версиях компилятора или код нельзя будет скомпилировать на другой платформе...
На практике нам неизвестны такие печальные истории, но если вы сомневаетесь — для вас есть другое решение 😉
Начиная с C++20 появляется стандартизированная поддержка некоторых нетривиальных битовых операций. Библиотека bit предоставляет набор реализаций. Рассмотрим некоторые из них:
std::has_single_bit - проверяет целое число на степень двойки.
std::popcount - подсчитывает количество установленных битов в целом числе.
std::countl_zero - подсчитывает количество нулей "слева" у целого числа.
std::countr_zero - подсчитывает количество нулей "справа" у целого числа.
std::rotr - выполняет циклический сдвиг битов вправо для целого числа.
std::rotl - выполняет циклический сдвиг битов влево для целого числа.
Живой пример: ссылка.
Могу еще отметить, что это еще и шаблонные
#cpp20 #STL
Предыдущий пост получил неожиданное продолжение благодаря нашим подписчикам - Сергею Нефедову и @Roman657. Взаимопомощь и отзывчивость всегда помогает добиваться бо́льшего 😃
Как было подмечено, строго говоря, использование __builtin функции сопряжено с потенциальными рисками. Например, список аргументов поменяется в будущих версиях компилятора или код нельзя будет скомпилировать на другой платформе...
На практике нам неизвестны такие печальные истории, но если вы сомневаетесь — для вас есть другое решение 😉
Начиная с C++20 появляется стандартизированная поддержка некоторых нетривиальных битовых операций. Библиотека bit предоставляет набор реализаций. Рассмотрим некоторые из них:
std::has_single_bit - проверяет целое число на степень двойки.
std::popcount - подсчитывает количество установленных битов в целом числе.
std::countl_zero - подсчитывает количество нулей "слева" у целого числа.
std::countr_zero - подсчитывает количество нулей "справа" у целого числа.
std::rotr - выполняет циклический сдвиг битов вправо для целого числа.
std::rotl - выполняет циклический сдвиг битов влево для целого числа.
Живой пример: ссылка.
Могу еще отметить, что это еще и шаблонные
constexpr функции 😋#cpp20 #STL
{kind=link}
std::span
Все мы любим С++ за способность работать как на высоком уровне, так и на низком уровне абстракции. Ну ладно, за это не любим. За это ценим. Довольно много проблем зашито в самом языке из-за этой особенности, однако плюсы перевешивают(какой каламбур получился неожиданный). Одна из таких проблем - поддержка высокоуровневых контейнеров и низкоуровневых сишных массивов. Проектируя обобщенный код, нам нужно учитывать, что пользователь хотел бы оперировать и контейнерами, и массивами, при работе с этим кодом. Однако это не всегда удается сделать красиво, да и комон, какие сишные массивы? 2к23 наконец. Хочется писать в терминах С++, объектно-ориентированной модели и все такое. Однако с недавних пор у нас появился инструмент, который может нам помочь.
Я говорю в std::span.
template<class T, std::size_t Extent = std::dynamic_extent>
class span;
Этот шаблонный класс, который введен в С++20. Он описывает объекты, являющиеся ссылкой на непрерывную последовательность объектов. В чем фишка этой фичи?
1️⃣ Первое. Она позволяет единообразно работать с динамическими контейнерами и со статическими массивами. Для статических последовательностей в конструктор передается указатель на первый элемент и количество элементов в массиве. Тогда типичная реализация будет содержать только указатель на первый элемент последовательности, и количество элементов будет содержаться в самом типе. А если передать в конструктор контейнер, то объект будет содержать 2 поля - указатель и размер последовательности.
2️⃣ Второе. Это по сути вьюха на существующий контейнер или массив, которая позволяет работать с ними целиком и даже с подпоследовательностями без передачи владения и главное без копирования. Мы можем проектировать свои апи так, чтобы пользователь был уверен, что ничего плохого не случится с его массивом в функции. Это повышает безопасность кода. А отсутствие копирования открывает нам двери к адекватным легковесным слайсам в с++. Метод subspan предоставляет интерфейс слайсинга. Теперь для задания отрезка массива необходимы просто 2 числа. Как во всех нормальных языках.
Фича на самом деле рабочая. Даже в кор гайдлайнах код написан с использованием std::span. Там не советуют его использовать. А просто используют его в листингах. Как бы предполагая, что все про это знают и это стандартный способ написания кода. А это уже о многом говорит.
Stay updated. Stay cool.
#cpp20 #STL
Все мы любим С++ за способность работать как на высоком уровне, так и на низком уровне абстракции. Ну ладно, за это не любим. За это ценим. Довольно много проблем зашито в самом языке из-за этой особенности, однако плюсы перевешивают(какой каламбур получился неожиданный). Одна из таких проблем - поддержка высокоуровневых контейнеров и низкоуровневых сишных массивов. Проектируя обобщенный код, нам нужно учитывать, что пользователь хотел бы оперировать и контейнерами, и массивами, при работе с этим кодом. Однако это не всегда удается сделать красиво, да и комон, какие сишные массивы? 2к23 наконец. Хочется писать в терминах С++, объектно-ориентированной модели и все такое. Однако с недавних пор у нас появился инструмент, который может нам помочь.
Я говорю в std::span.
template<class T, std::size_t Extent = std::dynamic_extent>
class span;
Этот шаблонный класс, который введен в С++20. Он описывает объекты, являющиеся ссылкой на непрерывную последовательность объектов. В чем фишка этой фичи?
1️⃣ Первое. Она позволяет единообразно работать с динамическими контейнерами и со статическими массивами. Для статических последовательностей в конструктор передается указатель на первый элемент и количество элементов в массиве. Тогда типичная реализация будет содержать только указатель на первый элемент последовательности, и количество элементов будет содержаться в самом типе. А если передать в конструктор контейнер, то объект будет содержать 2 поля - указатель и размер последовательности.
2️⃣ Второе. Это по сути вьюха на существующий контейнер или массив, которая позволяет работать с ними целиком и даже с подпоследовательностями без передачи владения и главное без копирования. Мы можем проектировать свои апи так, чтобы пользователь был уверен, что ничего плохого не случится с его массивом в функции. Это повышает безопасность кода. А отсутствие копирования открывает нам двери к адекватным легковесным слайсам в с++. Метод subspan предоставляет интерфейс слайсинга. Теперь для задания отрезка массива необходимы просто 2 числа. Как во всех нормальных языках.
Фича на самом деле рабочая. Даже в кор гайдлайнах код написан с использованием std::span. Там не советуют его использовать. А просто используют его в листингах. Как бы предполагая, что все про это знают и это стандартный способ написания кода. А это уже о многом говорит.
Stay updated. Stay cool.
#cpp20 #STL
{kind=link}
Идиома Remove-Erase устарела?
Снова вспомним про эту идиому. В прошлых частях тык и тык(кто не видел эту серию постов, то после первого нужно еще вот этот посмотреть) говорили о том, зачем что это такое, какую проблему решает, и как работает. А в этой части я расскажу, что это все не нужно)
Точнее будет не нужно, после того, как ваши проекты полностью перейдут на С++20.
Дело в том, что этот релиз подарил нам 2 прекрасные шаблонные функции: std::erase и std::erase_if. Чем они занимаются в контексте идиомы? А занимаются они ровно тем же, только намного красивее. Если раньше нам приходилось использовать 2 алгоритма, чтобы удалить нужные элементы из вектора, то здесь нужна всего одна функция.
std::vector<int> myVec = {1, 2, 3, 4, 5};
std::erase(myVec, 2);
И все. Больше ничего не нужно городить. И даже убрали этот некрасивый интерфейс с итераторами (по сути интерфейс крутой и функциональный, но слишком много букав писать надо). Да, для ренджей придется использовать идиому по старинке, но случаи, когда это реально необходимо, очень редки.
Вся прелесть этих функции в том, что они шаблонные. То есть могут принимать на вход любые контейнеры стандартной библиотеки. Примечательно, что для большинства контейнеров эти функции частично специализированы под этот конкретный контейнер. Писать обобщенный код теперь стало еще проще.
Stay updated. Stay cool.
#cpp20 #STL #algorithms
Снова вспомним про эту идиому. В прошлых частях тык и тык(кто не видел эту серию постов, то после первого нужно еще вот этот посмотреть) говорили о том, зачем что это такое, какую проблему решает, и как работает. А в этой части я расскажу, что это все не нужно)
Точнее будет не нужно, после того, как ваши проекты полностью перейдут на С++20.
Дело в том, что этот релиз подарил нам 2 прекрасные шаблонные функции: std::erase и std::erase_if. Чем они занимаются в контексте идиомы? А занимаются они ровно тем же, только намного красивее. Если раньше нам приходилось использовать 2 алгоритма, чтобы удалить нужные элементы из вектора, то здесь нужна всего одна функция.
std::vector<int> myVec = {1, 2, 3, 4, 5};
std::erase(myVec, 2);
И все. Больше ничего не нужно городить. И даже убрали этот некрасивый интерфейс с итераторами (по сути интерфейс крутой и функциональный, но слишком много букав писать надо). Да, для ренджей придется использовать идиому по старинке, но случаи, когда это реально необходимо, очень редки.
Вся прелесть этих функции в том, что они шаблонные. То есть могут принимать на вход любые контейнеры стандартной библиотеки. Примечательно, что для большинства контейнеров эти функции частично специализированы под этот конкретный контейнер. Писать обобщенный код теперь стало еще проще.
Stay updated. Stay cool.
#cpp20 #STL #algorithms
{kind=link}
std::make_shared в С++20
Начиная со стандарта С++11 в С++ появилась поддержка создания std::shared_ptr при помощи фабричной функции std::make_shared. У нас даже есть пост про особенности этой функции вот здесь. Но у нее были такие же недостатки, как и у std::shared_ptr до С++17. Нельзя было ее использовать для массивов. Но, как отметил уже в комментах Константин, начиная с С++20 эта фабричная функция синхронизировалась со своим вдохновителем и теперь тоже поддерживает создание массивов из std::shared_ptr. Например:
⚡️ std::shared_ptr<double[]> shar = std::make_shared<double[]>(1024): создает std::shared_ptr c 1024 значениями типа double, проинициализированными по умолчанию;
⚡️ std::shared_ptr<double[]> shar = std::make_shared<double[]>(1024, 1.0): создает std::shared_ptr c 1024 значениями типа double, проинициализированными значениями, равными 1,0.
Как обычно make функции немного тормозят относительно типов, для которых они созданы. Типа std::make_unique появился только в с++14, хотя сам уникальный указатель был представлен в предыдущем релизе. Но главное, что эти особенности все-таки доезжают, что не может не радовать.
Enjoy small things. Stay cool.
#cpp20 #memory
Начиная со стандарта С++11 в С++ появилась поддержка создания std::shared_ptr при помощи фабричной функции std::make_shared. У нас даже есть пост про особенности этой функции вот здесь. Но у нее были такие же недостатки, как и у std::shared_ptr до С++17. Нельзя было ее использовать для массивов. Но, как отметил уже в комментах Константин, начиная с С++20 эта фабричная функция синхронизировалась со своим вдохновителем и теперь тоже поддерживает создание массивов из std::shared_ptr. Например:
⚡️ std::shared_ptr<double[]> shar = std::make_shared<double[]>(1024): создает std::shared_ptr c 1024 значениями типа double, проинициализированными по умолчанию;
⚡️ std::shared_ptr<double[]> shar = std::make_shared<double[]>(1024, 1.0): создает std::shared_ptr c 1024 значениями типа double, проинициализированными значениями, равными 1,0.
Как обычно make функции немного тормозят относительно типов, для которых они созданы. Типа std::make_unique появился только в с++14, хотя сам уникальный указатель был представлен в предыдущем релизе. Но главное, что эти особенности все-таки доезжают, что не может не радовать.
Enjoy small things. Stay cool.
#cpp20 #memory
{kind=link}
Ответ на вопрос выше не так уж и прост на самом деле. Начнем с того, что когда вы запустите этот код на своей машине, то получите ответ: -1.
Эм. Неожиданно! "Как так получается?" - спросите вы меня. "Ведь я же знаю, как работает бинарный сдвиг: берем да и сдвигаем биты вправо и позади оставляем нули. В итоге получатся все нолики и самый младший бит 1. А это 1, а не -1!".
Логика железная и с ней не поспоришь. Однако в этой цепочке есть одно неверное утверждение. На самом деле вы не знаете, как работает правый бинарный сдвиг!(ну те, кто так рассуждают)
Заинтригованы?
Тогда мы идем к вам!
Что было до С++20.
Рассуждения верные только для беззнаковых чисел. Для знаковых все определяется конкретной реализацией. А у нас как раз такой вариант. Так еще все от стандарта зависит. Так что правильный ответ: "Мне-то откуда знать???". В общем случае вы вряд ли знаете, как во всех компиляторах это реализовано, а спрашивал я без привязки к конкретной реализации и стандарту. Да, вот так завуалировал ответ. Имею право.
Почему я тогда утверждаю, что вы на своих машинах получите -1?
Потому что в большинстве реализаций правый битовый сдвиг для знаковых чисел работает с помощью так называемого "арифметического сдвига".
Что это за акула такая.
Когда вы делаете правый сдвиг для беззнаковых чисел, то просто старшие разряды заполняете нулями. Арифметический же сдвиг заполняет старшие разряды не нулями, а знаковым битом. Таким образом, правый сдвиг любого 4-х байтного знакового числа оставит после себя либо 32 бита нулей (в случае положительного числа), либо 32 бита единичек(в случае отрицательного числа). А все единички в битах - это -1 для знаковых чисел.
С++20 начинает нам гарантировать, что правый сдвиг для знаковых чисел выполняется с помощью арифметического сдвига. Спасибо Дмитрию за это уточнение)
Вот такой прикол. Надеюсь, что я многих удивил тем, как это работает)
Арифметический сдвиг - хоть теперь и стандартное поведение, но
Во-первых, не все разрабы имеют достаточного опыта на 20-х плюсах, чтобы понять, что это стандартное поведение
Во-вторых, в каких-то проектах(которых на самом деле огромное количество) до сих пор не используется этот стандарт
В-третьих, слишком мало времени прошло с момента стандартизации. Если раньше это было грязным нестандартным приемом, то в умах людей он таковым еще долго останется. И это не изменится взмахом палочки комитета.
Поэтому не стоит использовать такие приколы без острой необходимости и правильного, подробного комментирования в случае этой необходимости.
Stay surprised. Stay cool.
#cpp20 #compiler
Эм. Неожиданно! "Как так получается?" - спросите вы меня. "Ведь я же знаю, как работает бинарный сдвиг: берем да и сдвигаем биты вправо и позади оставляем нули. В итоге получатся все нолики и самый младший бит 1. А это 1, а не -1!".
Логика железная и с ней не поспоришь. Однако в этой цепочке есть одно неверное утверждение. На самом деле вы не знаете, как работает правый бинарный сдвиг!(ну те, кто так рассуждают)
Заинтригованы?
Тогда мы идем к вам!
Что было до С++20.
Рассуждения верные только для беззнаковых чисел. Для знаковых все определяется конкретной реализацией. А у нас как раз такой вариант. Так еще все от стандарта зависит. Так что правильный ответ: "Мне-то откуда знать???". В общем случае вы вряд ли знаете, как во всех компиляторах это реализовано, а спрашивал я без привязки к конкретной реализации и стандарту. Да, вот так завуалировал ответ. Имею право.
Почему я тогда утверждаю, что вы на своих машинах получите -1?
Потому что в большинстве реализаций правый битовый сдвиг для знаковых чисел работает с помощью так называемого "арифметического сдвига".
Что это за акула такая.
Когда вы делаете правый сдвиг для беззнаковых чисел, то просто старшие разряды заполняете нулями. Арифметический же сдвиг заполняет старшие разряды не нулями, а знаковым битом. Таким образом, правый сдвиг любого 4-х байтного знакового числа оставит после себя либо 32 бита нулей (в случае положительного числа), либо 32 бита единичек(в случае отрицательного числа). А все единички в битах - это -1 для знаковых чисел.
С++20 начинает нам гарантировать, что правый сдвиг для знаковых чисел выполняется с помощью арифметического сдвига. Спасибо Дмитрию за это уточнение)
Вот такой прикол. Надеюсь, что я многих удивил тем, как это работает)
Арифметический сдвиг - хоть теперь и стандартное поведение, но
Во-первых, не все разрабы имеют достаточного опыта на 20-х плюсах, чтобы понять, что это стандартное поведение
Во-вторых, в каких-то проектах(которых на самом деле огромное количество) до сих пор не используется этот стандарт
В-третьих, слишком мало времени прошло с момента стандартизации. Если раньше это было грязным нестандартным приемом, то в умах людей он таковым еще долго останется. И это не изменится взмахом палочки комитета.
Поэтому не стоит использовать такие приколы без острой необходимости и правильного, подробного комментирования в случае этой необходимости.
Stay surprised. Stay cool.
#cpp20 #compiler
std::for_each
Все мы знаем эту знаменитую шаблонную функцию из стандартной библиотеки. Она позволяет применить унарную операцию для каждого элемента последовательности.
Чем она хороша? В подходящих условиях она дает больше семантики по сравнению с "конкурентами".
Например, есть range-based-for цикл. Он записывается примерно так:
В этом подходе к обработке набора данных нет ничего плохого. Но нам позволено слишком много свободы. Мы можем выйти из цикла, перейти к следующей итерации в середине текущей и так далее. И уже сама эта возможность заставляет читающего код больше напрягаться и искать сложную логику.
Но если такой логики нет и мы просто делаем определенную операцию над каждым элементом, то создается совершенно лишнее напряжение, которого можно было бы избежать. И этому побегу поможет std::for_each.
Функция имеет явную семантику: для каждого элемента последовательности выполняется вот эта функция. И все. Думать много не нужно. Нужно просто понять, как преобразуется или обрабатывается элемент и дело в шляпе.
Но не каждый знает, что эта функция возвращает не void, а тот же тип унарной операции, что мы передали в нее. Значит мы можем использовать stateful операции, то есть функциональные объекты, и сохранять результат вычислений в этом объекте не используя никакие глобальные переменные, ссылки и прочее. Стандарт гарантирует, что возвращаемое значение for_each содержит финальное состояния функтора после завершения операций над всеми элементами.
Эта особенность может пригодиться, когда помимо обработки элемента необходимо собрать по ним статистику. Допустим, я хочу убрать из массива строк все пробелы и сосчитать, сколько в среднем на каждую строку приходится пробелов. И тут как бы вроде скорее всего наверное вероятно лучше std::transform подходит(по семантике основной операции), но все портит сбор статистики. Можно засунуть в трансформ лямбду со ссылкой на внешний счетчик, но по смыслу это уже не будет чистая трансформация строк. Поэтому можно подобрать менее точечный по предназначению алгоритм, но он лучше подходит этой ситуации. Единственное, что лямбду нельзя будет использовать.
Пример:
Здесь мы используем функтор SpaceHandler, для которого перегружен оператор круглые скобки. За счет чего мы в этом операторе может сохранять вычисления в поля класса SpaceHandler. Чем мы и воспользовались для подсчета статистики.
Большое неудобство с этими лямбдами, но нам пока не позволено доставать из них поля класса, так что выживаем, как можем.
Кстати, с С++20 std::for_each стал constexpr, что позволяет удобнее обрабатывать наборы данных во время компиляции .
Use proper tools. Stay cool.
#cppcore #cpp20 #algorithms
Все мы знаем эту знаменитую шаблонную функцию из стандартной библиотеки. Она позволяет применить унарную операцию для каждого элемента последовательности.
Чем она хороша? В подходящих условиях она дает больше семантики по сравнению с "конкурентами".
Например, есть range-based-for цикл. Он записывается примерно так:
for(auto & traitor: traitors) {
// exquisitely torture the traitor
}
В этом подходе к обработке набора данных нет ничего плохого. Но нам позволено слишком много свободы. Мы можем выйти из цикла, перейти к следующей итерации в середине текущей и так далее. И уже сама эта возможность заставляет читающего код больше напрягаться и искать сложную логику.
Но если такой логики нет и мы просто делаем определенную операцию над каждым элементом, то создается совершенно лишнее напряжение, которого можно было бы избежать. И этому побегу поможет std::for_each.
Функция имеет явную семантику: для каждого элемента последовательности выполняется вот эта функция. И все. Думать много не нужно. Нужно просто понять, как преобразуется или обрабатывается элемент и дело в шляпе.
Но не каждый знает, что эта функция возвращает не void, а тот же тип унарной операции, что мы передали в нее. Значит мы можем использовать stateful операции, то есть функциональные объекты, и сохранять результат вычислений в этом объекте не используя никакие глобальные переменные, ссылки и прочее. Стандарт гарантирует, что возвращаемое значение for_each содержит финальное состояния функтора после завершения операций над всеми элементами.
Эта особенность может пригодиться, когда помимо обработки элемента необходимо собрать по ним статистику. Допустим, я хочу убрать из массива строк все пробелы и сосчитать, сколько в среднем на каждую строку приходится пробелов. И тут как бы вроде скорее всего наверное вероятно лучше std::transform подходит(по семантике основной операции), но все портит сбор статистики. Можно засунуть в трансформ лямбду со ссылкой на внешний счетчик, но по смыслу это уже не будет чистая трансформация строк. Поэтому можно подобрать менее точечный по предназначению алгоритм, но он лучше подходит этой ситуации. Единственное, что лямбду нельзя будет использовать.
Пример:
struct SpaceHandler {
void operator()(std::string& str) {
auto new_end_it = std::remove_if(str.begin(), str.end(), [](const auto & ch){ return ch == ' ';});
space_count += str.size() - std::distance(str.begin(), new_end_it);
str.erase(new_end_it, str.end());
}
int space_count {0};
};
int main() {
std::vector<std::string> container = {"Ole-ole-ole ole", "C++ is great!",
"Just a random string just to make third elem"};
int i = std::for_each(container.begin(), container.end(), SpaceHandler()).space_count;
std::for_each(container.begin(), container.end(), [](const auto& str) { std::cout << str << std::endl;});
std::cout << "Average number of spaces is " << static_cast<double>(i) / container.size() << std::endl;
}
//Output
Ole-ole-oleole
C++isgreat!
Justarandomstringjusttomakethirdelem
Average number of spaces is 3.66667
Здесь мы используем функтор SpaceHandler, для которого перегружен оператор круглые скобки. За счет чего мы в этом операторе может сохранять вычисления в поля класса SpaceHandler. Чем мы и воспользовались для подсчета статистики.
Большое неудобство с этими лямбдами, но нам пока не позволено доставать из них поля класса, так что выживаем, как можем.
Кстати, с С++20 std::for_each стал constexpr, что позволяет удобнее обрабатывать наборы данных во время компиляции .
Use proper tools. Stay cool.
#cppcore #cpp20 #algorithms
{kind=link}
Как узнать, что constexpr функция вычисляется в compile time
C constexpr функциями есть один прикол - они могут вычисляться и в рантайме, и компайлтайме. Но вот какой момент: мы же не зря пометили их constexpr. Нам важно, чтобы в тот момент, когда мы хотели разгрузить рантайм, он действительно разгружался. Не всегда просто бывает сходу понять, что все аргументы функции тоже являются вычислимыми во время компиляции. А это, собственно, одно из основных условий того, что и сама функция вычислится в это время.
Так вот интересно: а можно ли как-то убедиться в том, что выражение вычислено в compile-time?
На самом деле можно, для этого даже есть несколько вариантов. Не то, чтобы эти проверки нужны в продовом коде, но они могут быть полезны при отладке.
⚡️ Присвоить значение выражения constexpr переменной. Они могут инициализироваться только значениями, доступными на этапе компиляции, поэтому вам сразу же компилятор выдаст ошибку "constexpr variable must be initialized by a constant expression", если вы попытаетесь передать в функцию не constexpr значение.
Правда, здесь есть ограничение, что void выражения таким макаром не проверить.
⚡️ Поместить вызов функции в static_assert. Эта штука может проверять только вычислимые на этапе компиляции условия, поэтому компилятор опять же вам подскажет, облажались вы или нет.
Ограничение здесь даже еще жестче, чем в предыдущем пункте. Вы должны каким-то образом из возвращаемого значения функции получить булевое значение. Для тривиальных типов это довольно тривиальное преобразование, как бы тривиально это не звучало. Но для более сложных конструкций нужно будет чуть больше подумать.
⚡️ Использовать фичу С++20 - std::is_constant_evaluated(). Если коротко, то она позволяет внутри функции определить в каком контексте она вычисляется: constant evaluation context или runtime context. Здесь есть и практическая польза: в зависимости от контекста мы можем использовать constexpr-френдли операции(их набор довольно сильно ограничен и придется попотеть, чтобы что-то сложное реализовать) или обычные. Но для наших целей мы можем вот как использовать: мы можем заветвиться по контексту и вернуть из функции какое-то уникальное значение, которое соответствует только compile-time ветке. И уже по итоговому результату понять, когда произошли вычисления. А дальше уже набрасывать реальный код в ветки. Например:
Обратите внимание, что здесь используется обычный if, потому что в if constexpr is_constant_evaluated будет всегда возвращать true(в нем условие всегда в compile-time поверяется).
Наверняка, есть еще способы. Если знаете, напишите их в комментарии)
Check context of your life. Stay cool.
#cpp20 #cpp11 #compiler
C constexpr функциями есть один прикол - они могут вычисляться и в рантайме, и компайлтайме. Но вот какой момент: мы же не зря пометили их constexpr. Нам важно, чтобы в тот момент, когда мы хотели разгрузить рантайм, он действительно разгружался. Не всегда просто бывает сходу понять, что все аргументы функции тоже являются вычислимыми во время компиляции. А это, собственно, одно из основных условий того, что и сама функция вычислится в это время.
Так вот интересно: а можно ли как-то убедиться в том, что выражение вычислено в compile-time?
На самом деле можно, для этого даже есть несколько вариантов. Не то, чтобы эти проверки нужны в продовом коде, но они могут быть полезны при отладке.
⚡️ Присвоить значение выражения constexpr переменной. Они могут инициализироваться только значениями, доступными на этапе компиляции, поэтому вам сразу же компилятор выдаст ошибку "constexpr variable must be initialized by a constant expression", если вы попытаетесь передать в функцию не constexpr значение.
constexpr int JustRandomUselessFunction(int num) {
return num + 1;
}
int main() {
int usual_runtime_var = 0;
constexpr int error = JustRandomUselessFunction(usual_runtime_var);
//👆🏿Error: constexpr variable must be initialized by a constant expression
constexpr int constexpr_var = 5;
constexpr int ok = JustRandomUselessFunction(constexpr_var);
//👆🏿 OK since constexpr_var is constexpr
}
Правда, здесь есть ограничение, что void выражения таким макаром не проверить.
⚡️ Поместить вызов функции в static_assert. Эта штука может проверять только вычислимые на этапе компиляции условия, поэтому компилятор опять же вам подскажет, облажались вы или нет.
constexpr int JustRandomUselessFunction(int num) {
return num + 1;
}
int main() {
int usual_runtime_var = 0;
constexpr int constexpr_var = 5;
static_assert(JustRandomUselessFunction(usual_runtime_var));
//👆🏿 Error: static assertion expression is not an integral constant expression
static_assert(JustRandomUselessFunction(constexpr_var)); // OK
}
Ограничение здесь даже еще жестче, чем в предыдущем пункте. Вы должны каким-то образом из возвращаемого значения функции получить булевое значение. Для тривиальных типов это довольно тривиальное преобразование, как бы тривиально это не звучало. Но для более сложных конструкций нужно будет чуть больше подумать.
⚡️ Использовать фичу С++20 - std::is_constant_evaluated(). Если коротко, то она позволяет внутри функции определить в каком контексте она вычисляется: constant evaluation context или runtime context. Здесь есть и практическая польза: в зависимости от контекста мы можем использовать constexpr-френдли операции(их набор довольно сильно ограничен и придется попотеть, чтобы что-то сложное реализовать) или обычные. Но для наших целей мы можем вот как использовать: мы можем заветвиться по контексту и вернуть из функции какое-то уникальное значение, которое соответствует только compile-time ветке. И уже по итоговому результату понять, когда произошли вычисления. А дальше уже набрасывать реальный код в ветки. Например:
constexpr int CalculatePeaceNumber(double base)
{
if (std::is_constant_evaluated())
{
return 666; // That's how we can be sure about compile time evaluation
}
else
{
// some peaceful code
return 0; // true balance and peace
}
}
constexpr double pi = 3.14;
int main() {
const int result = CalculatePeaceNumber(pi);
std::cout << result << " " << CalculatePeaceNumber(pi) << std::endl;
}
//Output
666 0
Обратите внимание, что здесь используется обычный if, потому что в if constexpr is_constant_evaluated будет всегда возвращать true(в нем условие всегда в compile-time поверяется).
Наверняка, есть еще способы. Если знаете, напишите их в комментарии)
Check context of your life. Stay cool.
#cpp20 #cpp11 #compiler
{kind=link}
bit_cast
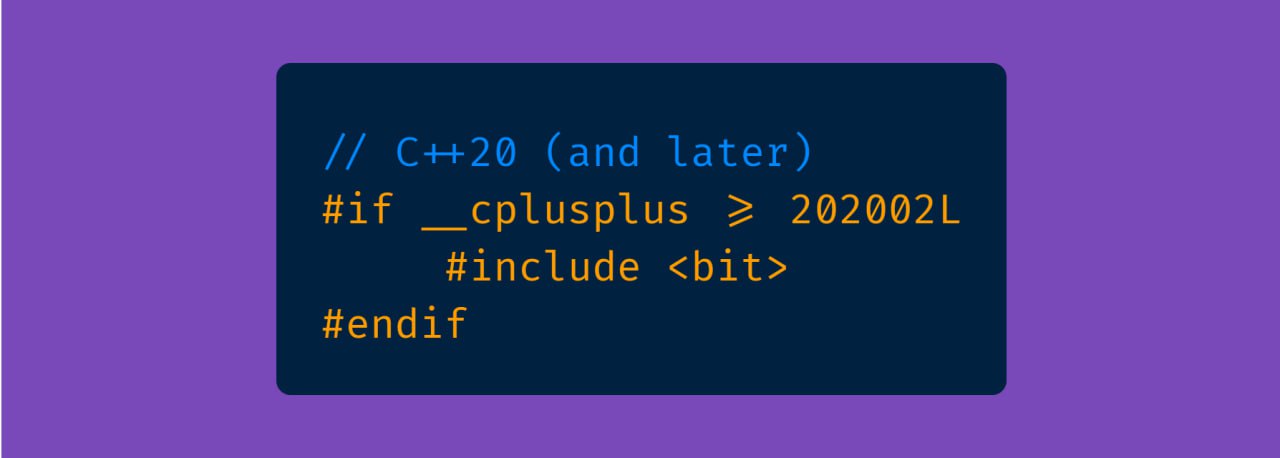
Начиная с C++20 появилась шаблонная функция
В конкретном примере переменные
Аналогичного результата можно добиться и с помощью
В отличие от альтернативных способов, шаблонная функция
Продемонстрирую проблему на примере с
Бывает и так, что изначально некоторые типы были реализованы тривиальными, но затем (в ходе доработок) потеряли такое свойство. Встроенные проверки
Нельзя назвать
Оставляйте реакции, считаете ли вы этот пост полезным для других! А мы, как и всегда, будем рады прочитать ваши комментарии и ответить вопросы 😉
#cppcore #cpp20
Начиная с C++20 появилась шаблонная функция
std::bit_cast в заголовочном файле <bit>. Она предоставляет возможность создавать побитовые копии объектов с другим типом:#include <bit>
double src = 42.0;
uint64_t dst = std::bit_cast<uint64_t>(src);
В конкретном примере переменные
dst и src имеют одинаковый размер 8 байт, поэтому их содержимое может быть интерпретировано по-разному, в зависимости от типа представления: беззнаковое целое или число с плавающей запятой.Аналогичного результата можно добиться и с помощью
union или reinterpret_cast. Однако, это нельзя было сделать в compile time! Функция std::bit_cast поддерживает constexpr выражения. Бонусом мы получаем достаточно лаконичное приведение и не нарушаем strict aliasing.В отличие от альтернативных способов, шаблонная функция
std::bit_cast дополнительно проверяет, что исходный и целевой типы имеют одинаковый размер и могут быть тривиально скопированы. Последнее означает, что память объекта может быть просто скопирована без дополнительных действий и это будет рабочей копией. Если это не так, то такие операции могут нарушать жизненный цикл нового объекта.Продемонстрирую проблему на примере с
std::string. Объекты данного типа, в общем случае, хранят строку где-то в другом месте, а сами выступают в роли умной оболочки (RAII). Клонирование такого объекта «в лоб» создает потенциально опасную ситуацию: два объекта будут ссылаться на один и тот же уникальный ресурс и пытаться управлять им. Например, они оба попытаются освободить ресурс. У первого объекта это получится, а у второго приведет к ошибке double free: живой пример. Отсюда и вытекает ограничение, что нельзя создавать побитовых клонов нетривиально копируемых объектов. Им необходимо обязательно вызвать конструктор копирования, который выделит собственный ресурс. Бывает и так, что изначально некоторые типы были реализованы тривиальными, но затем (в ходе доработок) потеряли такое свойство. Встроенные проверки
std::bit_cast тут же сообщат о некорректности работы с таким типом.Нельзя назвать
std::bit_cast оператором приведения, т.к. эта штука все таки не включена в семантику языка (в отличие от static_cast, reinterpret_cast и т.д.) и вынесена в пространство имен библиотеки STL. Однако её стоит упомянуть в текущем цикле статей.Оставляйте реакции, считаете ли вы этот пост полезным для других! А мы, как и всегда, будем рады прочитать ваши комментарии и ответить вопросы 😉
#cppcore #cpp20
{kind=link}
Невероятные вероятности
Зачастую, когда мы пишем какие-то условия, то предполагаем, что какая-то ветка будет выполняться чаще другой. Самый простой пример - проверка чего-то на корректность. И если это что-то некорректно, то мы делаем какие-то действия, сигнализирующие о проблеме. И логично предположить, что наша программа хорошо написана (по крайней мере мы в это охотно верим). Поэтому ошибка - некая экстренная ситуация, которая не должна появляться часто. В принципе, любой не happy path может рассматриваться, как пример такой ситуации.
Может ли нам это знание как-то помочь? Вполне. В процессорах есть такой модуль - предсказатель переходов. На основе кода он по определенным эвристикам пытается понять, какая из веток выполниться с большей вероятностью. Он заранее подгружает данные и код для этой ветки, чтобы в случае удачного предсказания сократить время простоя вычислительного конвейера. И на самом деле, современные процессоры - настоящие Ванги! Их модуль предсказания переходов принимает правильные решения примерно в 90% случаев! Что не мало. Но все равно не идеально.
И вот тут-то мы и вступаем в дело. Мы можем немножко помочь предсказателю сделать более правильный выбор в конкретной ситуации. Путем указания ветки, которая по нашему мнению, будет выполняться с большей вероятностью.
У компиляторов есть свои расширения, которые могут помочь нам в этой задаче. Но они нам больше не нужны!
Потому что в С++20 появились стандартные аттрибуты [[likely]] и [[unlikely]]!
Допустим, мы пишем свой вектор интов. Причины покататься на байсикле мы отбросим в сторону и сконцентрируемся на сути. И мы дошли до метода MyVector::at, который по индексу выдает элемент. Но фишка в том, что этот метод проверяет индекс на нахождение в границах дозволенного и кидает исключение, если нештатная ситуация все-таки произошла.
Это довольно базовый класс, которым будет пользоваться множество программистов во множестве модулей. И разумно предположить, что большинство использований этого метода будут вполне корректны и все будет стабильно работать. Поэтому вполне логично сказать компилятору встроить в код подсказку, которая поможет процессору предсказывать правильно с большей вероятностью.
Ставьте лайки, если хотите немного бэнчмарков на эту тему. Если хотите что-то определенное померять(в пределах разумного времени написания поста), то пишите в комментах свои идеи.
Predict people's actions. Stay cool.
#cpp20 #compiler #performance
Зачастую, когда мы пишем какие-то условия, то предполагаем, что какая-то ветка будет выполняться чаще другой. Самый простой пример - проверка чего-то на корректность. И если это что-то некорректно, то мы делаем какие-то действия, сигнализирующие о проблеме. И логично предположить, что наша программа хорошо написана (по крайней мере мы в это охотно верим). Поэтому ошибка - некая экстренная ситуация, которая не должна появляться часто. В принципе, любой не happy path может рассматриваться, как пример такой ситуации.
Может ли нам это знание как-то помочь? Вполне. В процессорах есть такой модуль - предсказатель переходов. На основе кода он по определенным эвристикам пытается понять, какая из веток выполниться с большей вероятностью. Он заранее подгружает данные и код для этой ветки, чтобы в случае удачного предсказания сократить время простоя вычислительного конвейера. И на самом деле, современные процессоры - настоящие Ванги! Их модуль предсказания переходов принимает правильные решения примерно в 90% случаев! Что не мало. Но все равно не идеально.
И вот тут-то мы и вступаем в дело. Мы можем немножко помочь предсказателю сделать более правильный выбор в конкретной ситуации. Путем указания ветки, которая по нашему мнению, будет выполняться с большей вероятностью.
У компиляторов есть свои расширения, которые могут помочь нам в этой задаче. Но они нам больше не нужны!
Потому что в С++20 появились стандартные аттрибуты [[likely]] и [[unlikely]]!
Допустим, мы пишем свой вектор интов. Причины покататься на байсикле мы отбросим в сторону и сконцентрируемся на сути. И мы дошли до метода MyVector::at, который по индексу выдает элемент. Но фишка в том, что этот метод проверяет индекс на нахождение в границах дозволенного и кидает исключение, если нештатная ситуация все-таки произошла.
int MyVector::at(size_t index) {
if (index >= this->size) [[unlikely]] {
throw std::out_of_range ("MyVector index is out of range");
}
return this->data[index];
}
Это довольно базовый класс, которым будет пользоваться множество программистов во множестве модулей. И разумно предположить, что большинство использований этого метода будут вполне корректны и все будет стабильно работать. Поэтому вполне логично сказать компилятору встроить в код подсказку, которая поможет процессору предсказывать правильно с большей вероятностью.
Ставьте лайки, если хотите немного бэнчмарков на эту тему. Если хотите что-то определенное померять(в пределах разумного времени написания поста), то пишите в комментах свои идеи.
Predict people's actions. Stay cool.
#cpp20 #compiler #performance
{kind=link}
Результаты ревью
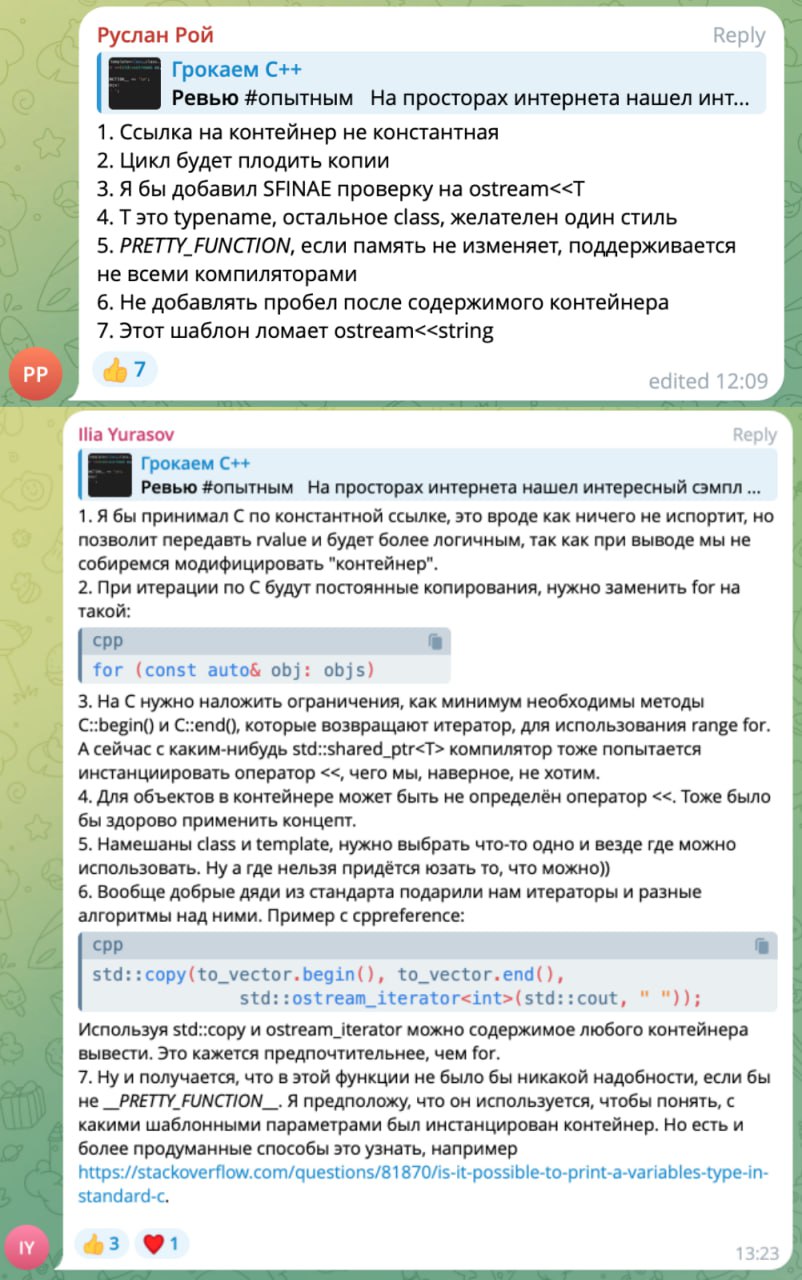
Круто вчера постарались, столько проблем нашли в этом маленьком кусочке кода. Больше всего проблем нашли два подписчика со скрина: я не смог выбрать из них одного, так как их пункты хоть и пересекаются, но все же дополняют друг друга различными мыслями. Давайте похлопаем нашим героям!👏👏👏👏👏👏
А теперь скомпануем все воедино. Напомню, что код был такой:
Сначала очевидное и то, что бросается в глаза. Все правильно поняли, что смысл кода - вывести элементы любого контейнера на выходной поток. Всвязи с этим следующие рассуждения:
❗️ Второй аргумент оператора принимается по значению, что ведет с излишним копированиям. Лучше использовать константную ссылку, так как мы не собираемся изменять значения контейнера.
❗️ В цикле тоже будут копирования, так как obj - объект, а не ссылка. Лучше использовать const auto &.
❗️ В первой строчке смешиваются class и typename. Это путает читателя, заставляя задумываться о тайном замысле использования разных ключевых слов. Лучше везде использовать class, так как Артем отметил , что до С++17 в шаблон-шаблонных параметрах нельзя было использовать typename.
❗️ Не очень выразительное название для аргумента, которым предполагается быть контейнеру. Хотя бы полностью написать Container.
❗️ Вывод элементов очень странный и кривой. Как минимум после последнего элемента будет ставиться пробел. Решить проблему можно с помощью стандартного алгоритма std::copy и интересного экспериментального итератора std::experimental::make_ostream_joiner, который может выводить элементы последовательности через разделитель, не записывая разделитель в конце! Выглядит это так:
На этом очевидные недостатки, которые мог выделить даже не очень разбирающийся в шаблонах читатель, заканчиваются.
Посмотрим чуть поглужбе. Функция используется для отладочных и учебных целей. Это понятно по использованию макроса PRETTY_FUNCTION. Он позволяет посмотреть полную сигнатуру функции с расшифровкой всех шаблонных параметров. Он довольно сильно помогает при обучении. Но к сожалению, этот макрос определен только под gcc/clang. Давайте уж не будем сильно внимание заострять на кроссплатформенности и целесообразности использования этой конструкции. В прод функция явно не пойдет. Д. А более интересные и кроссплатформенные варианты вывода сигнатуры функции можно посмотреть тут.
Однако автором этот кусок кода преподносился, как универсальный принт контейнеров STL. А вот тут уже залет! Потому что он не только не универсальный, но еще и не безопасный и корявый!.
🔞 Для класса std::string уже определен оператор вывода на поток, поэтому при наличии этого куска в общем коде мы просто не сможем выводить строку, так как компилятор найдет 2 подходящие перегрузки и не сможет из них выбрать лучшую. Можно ограничить тип контейнера с помощью sfinae/концептов.
🔞 Перегрузка не будет работать для мап. У них элементы - пары, которые не имеют собственной реализации вывода на поток. Да и вообще: если элементы "контейнера" не умеют выводиться на поток, то будет ошибка. Выход - поставить sfinae/концепт на существовании перегрузки на поток вывода для типа Т.
🔞 В предыдущем пункте я взял слово контейнер в кавычки. Все потому что сигнатура функции способна принимать любую шаблонную тварь, даже какой-нибудь std::shared_ptr. А для него уже перегружен оператор вывода. Опять компилятор не сможет выбрать из двух одинаковых перегрузок. Поэтому было бы неплохо поставить ограничение на существование методов begin() и end().
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
Fix your flaws. Stay cool.
#template #STL #cppcore #cpp17 #cpp20
Круто вчера постарались, столько проблем нашли в этом маленьком кусочке кода. Больше всего проблем нашли два подписчика со скрина: я не смог выбрать из них одного, так как их пункты хоть и пересекаются, но все же дополняют друг друга различными мыслями. Давайте похлопаем нашим героям!👏👏👏👏👏👏
А теперь скомпануем все воедино. Напомню, что код был такой:
template<typename T, template<class,class...> class C, class... Args>
std::ostream& operator <<(std::ostream& os, C<T,Args...> objs)
{
os << PRETTY_FUNCTION << '\n';
for (auto obj : objs)
os << obj << ' ';
return os;
}
Сначала очевидное и то, что бросается в глаза. Все правильно поняли, что смысл кода - вывести элементы любого контейнера на выходной поток. Всвязи с этим следующие рассуждения:
❗️ Второй аргумент оператора принимается по значению, что ведет с излишним копированиям. Лучше использовать константную ссылку, так как мы не собираемся изменять значения контейнера.
❗️ В цикле тоже будут копирования, так как obj - объект, а не ссылка. Лучше использовать const auto &.
❗️ В первой строчке смешиваются class и typename. Это путает читателя, заставляя задумываться о тайном замысле использования разных ключевых слов. Лучше везде использовать class, так как Артем отметил , что до С++17 в шаблон-шаблонных параметрах нельзя было использовать typename.
❗️ Не очень выразительное название для аргумента, которым предполагается быть контейнеру. Хотя бы полностью написать Container.
❗️ Вывод элементов очень странный и кривой. Как минимум после последнего элемента будет ставиться пробел. Решить проблему можно с помощью стандартного алгоритма std::copy и интересного экспериментального итератора std::experimental::make_ostream_joiner, который может выводить элементы последовательности через разделитель, не записывая разделитель в конце! Выглядит это так:
std::copy(vec.begin(), vec.end(),
std::experimental::make_ostream_joiner(std::cout, ", "));
На этом очевидные недостатки, которые мог выделить даже не очень разбирающийся в шаблонах читатель, заканчиваются.
Посмотрим чуть поглужбе. Функция используется для отладочных и учебных целей. Это понятно по использованию макроса PRETTY_FUNCTION. Он позволяет посмотреть полную сигнатуру функции с расшифровкой всех шаблонных параметров. Он довольно сильно помогает при обучении. Но к сожалению, этот макрос определен только под gcc/clang. Давайте уж не будем сильно внимание заострять на кроссплатформенности и целесообразности использования этой конструкции. В прод функция явно не пойдет. Д. А более интересные и кроссплатформенные варианты вывода сигнатуры функции можно посмотреть тут.
Однако автором этот кусок кода преподносился, как универсальный принт контейнеров STL. А вот тут уже залет! Потому что он не только не универсальный, но еще и не безопасный и корявый!.
🔞 Для класса std::string уже определен оператор вывода на поток, поэтому при наличии этого куска в общем коде мы просто не сможем выводить строку, так как компилятор найдет 2 подходящие перегрузки и не сможет из них выбрать лучшую. Можно ограничить тип контейнера с помощью sfinae/концептов.
🔞 Перегрузка не будет работать для мап. У них элементы - пары, которые не имеют собственной реализации вывода на поток. Да и вообще: если элементы "контейнера" не умеют выводиться на поток, то будет ошибка. Выход - поставить sfinae/концепт на существовании перегрузки на поток вывода для типа Т.
🔞 В предыдущем пункте я взял слово контейнер в кавычки. Все потому что сигнатура функции способна принимать любую шаблонную тварь, даже какой-нибудь std::shared_ptr. А для него уже перегружен оператор вывода. Опять компилятор не сможет выбрать из двух одинаковых перегрузок. Поэтому было бы неплохо поставить ограничение на существование методов begin() и end().
ПРОДОЛЖЕНИЕ В КОММЕНТАРИЯХ
Fix your flaws. Stay cool.
#template #STL #cppcore #cpp17 #cpp20
{kind=link}