
Приветственный пост
Рады приветствовать всех на нашем канале!
Вы устали от скучного, монотонного, обезличенного контента по плюсам?
Тогда мы идем к вам!
Здесь не будет бесполезных 30 IQ постов, сгенеренных ChatGPT, накрученных подписчиков и активности.
Канал ведут два сеньора, Денис и Владимир, которые искренне хотят делится своими знаниями по С++ и создать самое уютное коммьюнити позитивных прогеров в телеге!
(ну вы поняли, да? с++, плюс плюс, плюс типа
позитивный?.. ай ладно)
Жмакай и попадешь в наш чат. Там обсуждения не привязаны к постам, можете общаться на любые темы.
Материалы для новичка
ГАЙДЫ:
Мини-гайд по собеседования
Гайд по категория выражения и мув-семантике
Гайд по inline
Дальше пойдет список хэштегов, которыми вы можете пользоваться для более удобной навигации по каналу и для быстрого поиска группы постов по интересующей теме:
#algorithms
#datastructures
#cppcore
#stl
#goodoldc
#cpp11
#cpp14
#cpp17
#cpp20
#commercial
#net
#database
#hardcore
#memory
#goodpractice
#howitworks
#NONSTANDARD
#interview
#digest
#OS
#tools
#optimization
#performance
#fun
#compiler
#multitasking
#design
#exception
#guide
#задачки
#base
#quiz
#concurrency
Рады приветствовать всех на нашем канале!
Вы устали от скучного, монотонного, обезличенного контента по плюсам?
Тогда мы идем к вам!
Здесь не будет бесполезных 30 IQ постов, сгенеренных ChatGPT, накрученных подписчиков и активности.
Канал ведут два сеньора, Денис и Владимир, которые искренне хотят делится своими знаниями по С++ и создать самое уютное коммьюнити позитивных прогеров в телеге!
(ну вы поняли, да? с++, плюс плюс, плюс типа
позитивный?.. ай ладно)
Жмакай и попадешь в наш чат. Там обсуждения не привязаны к постам, можете общаться на любые темы.
Материалы для новичка
ГАЙДЫ:
Мини-гайд по собеседования
Гайд по категория выражения и мув-семантике
Гайд по inline
Дальше пойдет список хэштегов, которыми вы можете пользоваться для более удобной навигации по каналу и для быстрого поиска группы постов по интересующей теме:
#algorithms
#datastructures
#cppcore
#stl
#goodoldc
#cpp11
#cpp14
#cpp17
#cpp20
#commercial
#net
#database
#hardcore
#memory
#goodpractice
#howitworks
#NONSTANDARD
#interview
#digest
#OS
#tools
#optimization
#performance
#fun
#compiler
#multitasking
#design
#exception
#guide
#задачки
#base
#quiz
#concurrency
Telegram
Грокаем C++ Chat
You’ve been invited to join this group on Telegram.
Small string optimization
Люди, которые разрабатывают компилляторы - гении. Никто не знает тех маленьких индусов, которые рвут свои маленькие попки, чтобы из твоего зачастую дурнопахнущего кода на С++ сделать конфетку. Эта фича не является геймченджером или сильным бустром перфоманса. Это просто крутая оптимизация, которая исходит из понимания работы с памятью на низком уровне и юз-кейсов класса строки.
Дело в том, что в основе плюсовой строки лежит обычный сишный массив. Точнее не обычный, а выделенный в куче. Так вот, когда вы пишите std::string var = "Like this post", по идее на куче должен выделяться блок памяти, равный размеру этой строки. Но. Зачастую пользователь класса std::string хочет присвоить переменной какую-нибудь короткую строку, которую он менять не собирается. Зачем тогда тратить драгоценные клоки проца и делать дорогостоящий вызов, когда можно поместить эту короткую строку в маленький внутренний буффер самого объекта строки и жить счастливо? Не дергать аллокатор, не фрагментировать память. Хорошо звучит? Вот и индусы так же подумали и запилили small string optimization.
Замечу, что этой фичи нет в стандарте. Это просто хорошая практика реализации стандартной библиотеки. Длина буферизируемой строки может отличатся от одной реализации к другой, а также может варьирываться с помощью опций компиллятора. Для гцц по дефолту она равна 15 байт.
Давайте все быть такими же умными, как индусы.
Stay cool.
#optimization #datastructures
Люди, которые разрабатывают компилляторы - гении. Никто не знает тех маленьких индусов, которые рвут свои маленькие попки, чтобы из твоего зачастую дурнопахнущего кода на С++ сделать конфетку. Эта фича не является геймченджером или сильным бустром перфоманса. Это просто крутая оптимизация, которая исходит из понимания работы с памятью на низком уровне и юз-кейсов класса строки.
Дело в том, что в основе плюсовой строки лежит обычный сишный массив. Точнее не обычный, а выделенный в куче. Так вот, когда вы пишите std::string var = "Like this post", по идее на куче должен выделяться блок памяти, равный размеру этой строки. Но. Зачастую пользователь класса std::string хочет присвоить переменной какую-нибудь короткую строку, которую он менять не собирается. Зачем тогда тратить драгоценные клоки проца и делать дорогостоящий вызов, когда можно поместить эту короткую строку в маленький внутренний буффер самого объекта строки и жить счастливо? Не дергать аллокатор, не фрагментировать память. Хорошо звучит? Вот и индусы так же подумали и запилили small string optimization.
Замечу, что этой фичи нет в стандарте. Это просто хорошая практика реализации стандартной библиотеки. Длина буферизируемой строки может отличатся от одной реализации к другой, а также может варьирываться с помощью опций компиллятора. Для гцц по дефолту она равна 15 байт.
Давайте все быть такими же умными, как индусы.
Stay cool.
#optimization #datastructures
{kind=link}
std::lower_bound
Продолжение басни с алгоритмами в STL. Предыдущие части можете найти тут жмак и жмак
Сегодня речь пойдет про бинарный поиск. Точнее немного более прикладную его вариацию - std::lower_bound.
На самом деле не удивительно, почему в списке 3-х самых используемых алгоритмов есть этот, учитывая, что на первом месте стояла сортировка. Если что-то и искать, то искать надо в упорядоченных структурах данных. Ведь преимущества очевидны: О(n) против O(logn) (можно и за О(1), но это другая уже другая история). Поэтому следует избегать использования линейного поиска (типа std::find), а использовать подходящий контейнер и эффективный алгоритм поиска над ним.
Функция выполняет поиск в отсортированном диапазоне и возвращает итератор на первый элемент, не меньший, чем заданное значение. За счет того, что поиск происходит в упорядоченном контейнере, алгоритмическая сложность такой операции - О(logn). То есть это очень эффективный способ найти нужный элемент в контейнере. В основе алгоритма лежит бинарный поиск, где на каждой итерации цикла диапазон поиска уменьшается вдвое.
Алгоритм может использоваться, как для поиска конкретного элемента, так и для поиска диапазона значений самостоятельно (открытый диапазон) или в сочетании с upper_bound (закрытый диапазон).
Немного более вариабельным lower_bound становится в применении к деревьям. Тогда возвращаемый итератор можно использовать для эффективной вставки ноды в дерево (например методом map::emplace_hint).
И не зря довольно часто на собесах встречаются задачи на бинарный поиск. Потому что это реально маст-хэв. Поэтому его в принципе полезно знать и уметь запрогать руками.
Stay cool.
#STL #algorithms #datastructures
Продолжение басни с алгоритмами в STL. Предыдущие части можете найти тут жмак и жмак
Сегодня речь пойдет про бинарный поиск. Точнее немного более прикладную его вариацию - std::lower_bound.
На самом деле не удивительно, почему в списке 3-х самых используемых алгоритмов есть этот, учитывая, что на первом месте стояла сортировка. Если что-то и искать, то искать надо в упорядоченных структурах данных. Ведь преимущества очевидны: О(n) против O(logn) (можно и за О(1), но это другая уже другая история). Поэтому следует избегать использования линейного поиска (типа std::find), а использовать подходящий контейнер и эффективный алгоритм поиска над ним.
Функция выполняет поиск в отсортированном диапазоне и возвращает итератор на первый элемент, не меньший, чем заданное значение. За счет того, что поиск происходит в упорядоченном контейнере, алгоритмическая сложность такой операции - О(logn). То есть это очень эффективный способ найти нужный элемент в контейнере. В основе алгоритма лежит бинарный поиск, где на каждой итерации цикла диапазон поиска уменьшается вдвое.
Алгоритм может использоваться, как для поиска конкретного элемента, так и для поиска диапазона значений самостоятельно (открытый диапазон) или в сочетании с upper_bound (закрытый диапазон).
Немного более вариабельным lower_bound становится в применении к деревьям. Тогда возвращаемый итератор можно использовать для эффективной вставки ноды в дерево (например методом map::emplace_hint).
И не зря довольно часто на собесах встречаются задачи на бинарный поиск. Потому что это реально маст-хэв. Поэтому его в принципе полезно знать и уметь запрогать руками.
Stay cool.
#STL #algorithms #datastructures
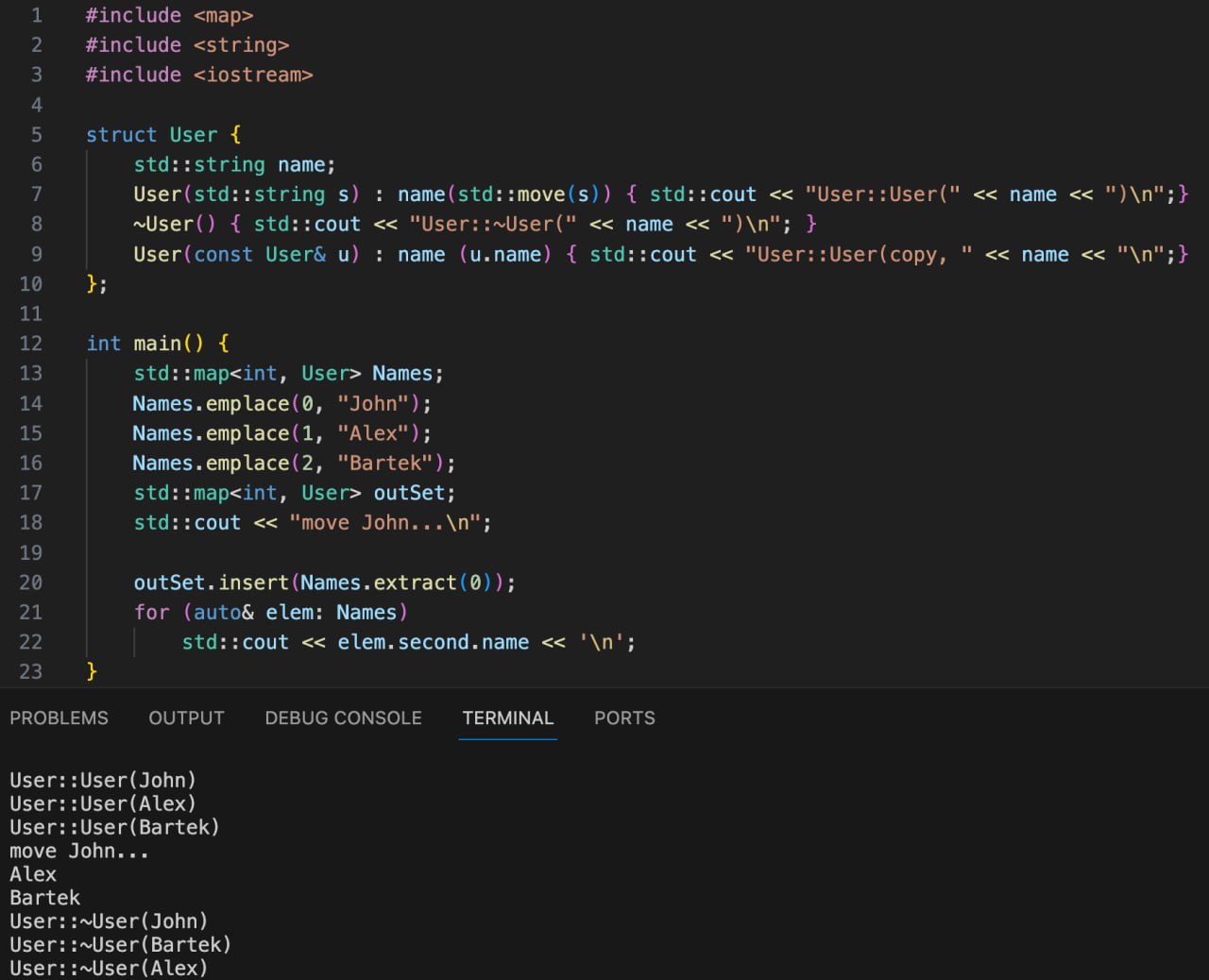
Перенос элементов между ассоциативными контейнерами
Пост для тех, кто много работает с древовидными структурами данных. Таких среди нас, думаю, немного. Но мне кажется фишка интересная. Слышали когда-нибудь об одной изящной функции, представленной в C++17, которая значительно облегчила нам жизнь при работе с ассоциативными контейнерами? Я говорю о методе extract, который как бы вырезает ноду из внутренней структуры контейнера и помещает его наружу, в специальный хэндлер node_type, не дергая конструкторы класса.
Что было до С++17
В эпоху до C++17 перемещение или перенос узлов между ассоциативными контейнерами было обременительной задачей. Представьте, что у вас есть узел в одном std::map или std::set, и вы хотите переместить его в другой контейнер. Вам приходилось вручную выполнять операцию копирования/перемещения объекта во временный объект, удаления этой ноды из одной мапы и вставки в другую копированием/перемещением . Это было не очень красиво эстетически, нельзя было трансферрить объекты, у которых не было конструкторов копирования и перемещения. Ну и конечно были совершенно лишние вызовы конструкторов.
Splicing в C++17
С появлением C++17 нам была предоставлена возможность для так называемого «сращивания». Вот как это работает:
👉🏿std::map::extract() и std::set::extract()
Эти новые функции-члены позволяют вам извлекать узел из std::map или std::set и возвращать его как «извлеченный» узел типа node_type. Эта операция эффективно отвязывает узел от исходного контейнера и внутри этого узла объект остаётся нетронутым. Никаких вызовов конструкторов объекта!
👉🏿std::map::insert() и std::set::insert()
Имея извлеченный узел на руках, вы теперь можете легко вставить его в другой std::map или std::set, используя метод insert(). Перенесенный узел будет легко интегрирован в новый контейнер без необходимости вовлечения конструкторов.
И все! Такой приём можно провернуть с любыми видами упорядоченных и неупорядоченных ассоциативных контейнеров. И да, это все ещё может вызывать перебалансировку дерева. Куда же без этого.
На картинке можете увидеть, как теперь за одну строчку перенести элемент из одной мапы в другую и при этом конструкторы и деструкторы вызываются только по одному разу. Я считаю это сильно.
Короче говоря, C++17 в целом значительно облегчил нам жизнь. Эта фича не геймченджер, но очень приятное нововведение, которое позитивно сказалось на качестве кода и его производительности.
Stay updated. Stay cool.
#cpp17 #datastructures #STL
Пост для тех, кто много работает с древовидными структурами данных. Таких среди нас, думаю, немного. Но мне кажется фишка интересная. Слышали когда-нибудь об одной изящной функции, представленной в C++17, которая значительно облегчила нам жизнь при работе с ассоциативными контейнерами? Я говорю о методе extract, который как бы вырезает ноду из внутренней структуры контейнера и помещает его наружу, в специальный хэндлер node_type, не дергая конструкторы класса.
Что было до С++17
В эпоху до C++17 перемещение или перенос узлов между ассоциативными контейнерами было обременительной задачей. Представьте, что у вас есть узел в одном std::map или std::set, и вы хотите переместить его в другой контейнер. Вам приходилось вручную выполнять операцию копирования/перемещения объекта во временный объект, удаления этой ноды из одной мапы и вставки в другую копированием/перемещением . Это было не очень красиво эстетически, нельзя было трансферрить объекты, у которых не было конструкторов копирования и перемещения. Ну и конечно были совершенно лишние вызовы конструкторов.
Splicing в C++17
С появлением C++17 нам была предоставлена возможность для так называемого «сращивания». Вот как это работает:
👉🏿std::map::extract() и std::set::extract()
Эти новые функции-члены позволяют вам извлекать узел из std::map или std::set и возвращать его как «извлеченный» узел типа node_type. Эта операция эффективно отвязывает узел от исходного контейнера и внутри этого узла объект остаётся нетронутым. Никаких вызовов конструкторов объекта!
👉🏿std::map::insert() и std::set::insert()
Имея извлеченный узел на руках, вы теперь можете легко вставить его в другой std::map или std::set, используя метод insert(). Перенесенный узел будет легко интегрирован в новый контейнер без необходимости вовлечения конструкторов.
И все! Такой приём можно провернуть с любыми видами упорядоченных и неупорядоченных ассоциативных контейнеров. И да, это все ещё может вызывать перебалансировку дерева. Куда же без этого.
На картинке можете увидеть, как теперь за одну строчку перенести элемент из одной мапы в другую и при этом конструкторы и деструкторы вызываются только по одному разу. Я считаю это сильно.
Короче говоря, C++17 в целом значительно облегчил нам жизнь. Эта фича не геймченджер, но очень приятное нововведение, которое позитивно сказалось на качестве кода и его производительности.
Stay updated. Stay cool.
#cpp17 #datastructures #STL
{kind=link}
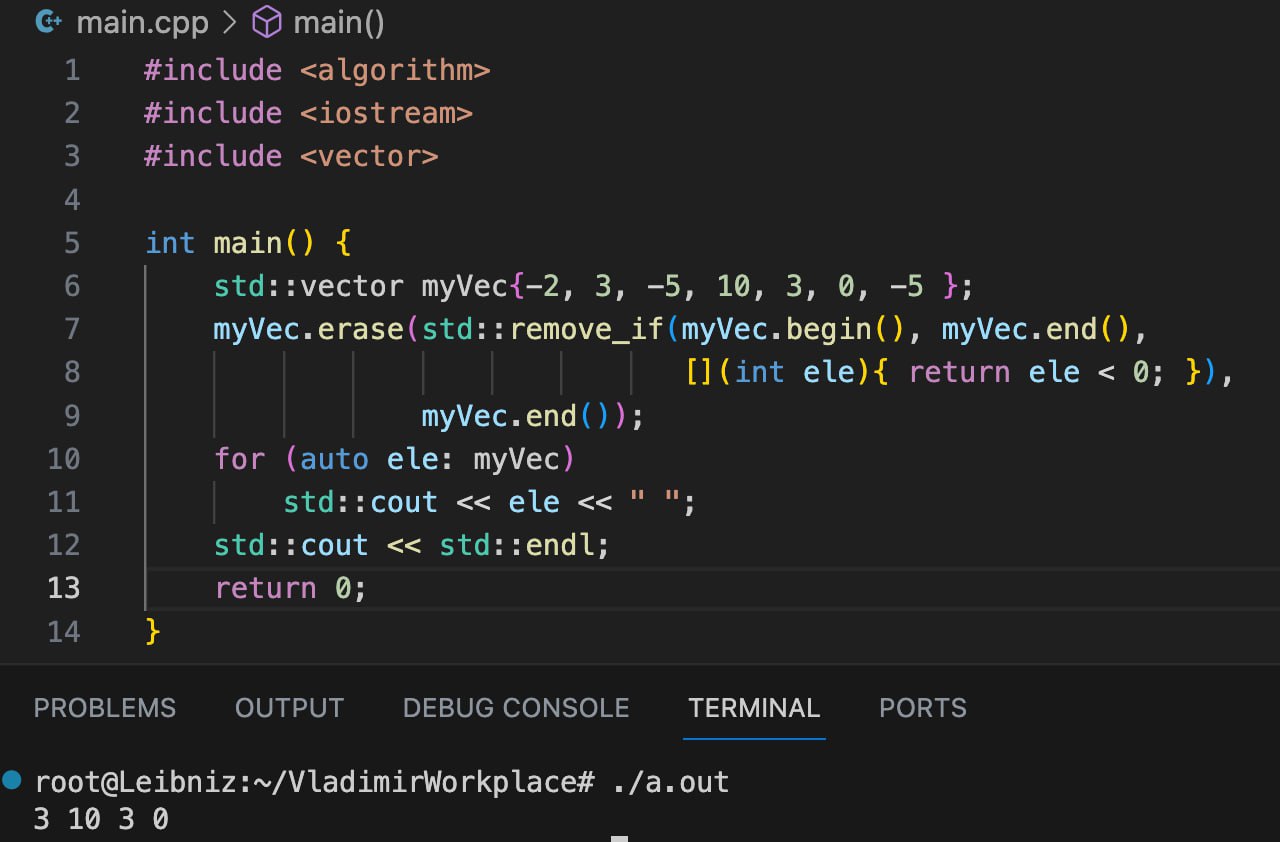
Remove-erase идиома
Удаление элементов из вектора - вещь не совсем тривиальная. Безусловно, в STL есть интерфейс для этого, бери да вызывай. Проблема в том, что удаление вызывает копирование всех элементов вектора, которые находятся правее от удаляемого элемента. То есть, в среднем, сложность удаления одного элемента контейнера будет линейной. А сложность очистки всего контейнера - квадратичная. Это все очень печальные результаты. И хоть для последовательности упорядоченных элементов нет стандартного алгоритма удаления из середины, для вектора, в котором порядок неважен, такой алгоритм есть.
Нам нужно лишь свопнуть удаляемый элемент с последним элементом в векторе и очистить последнюю с конца ячейку. Таким образом, удаление будет занимать всего 2 действия, а значит сложность этой операции - константная. Звучит намного лучше.
А что, если нужно отфильтровать массив по какому-то критерию? Ну удалить все ячейки, которые обладают какими-то характеристиками. Например, из массива удалить все числа, кратные 5. Надо тогда в цикле проделать действия из предыдущего абзаца и все будет пучком.
Однако, есть ощущение, что это задача слишком общая и хотелось бы иметь для нее какое-то более элегантное решение, чем каждый раз писать цикл. Можно конечно объявить функцию, но все-таки хочется чего-то стандартного.
И такое есть. В плюсах это называется remove-erase idiom. Идиома удаления-очистки. Какой у меня прекрасный английский)
Решение хоть и стандартное, но не прям очень элегантное. Ну а что вы хотели? Это плюсы все-таки.
Судя по названию, надо просто скомбинировать стандартный алгоритм std::remove (или std::remove_if) и метод вектора std::vector::erase.
На картинке снизу можете увидеть, как конкретно эта комбинация решает задачу удаления элементов.
Stay cool.
#algorithms #STL #datastructures
Удаление элементов из вектора - вещь не совсем тривиальная. Безусловно, в STL есть интерфейс для этого, бери да вызывай. Проблема в том, что удаление вызывает копирование всех элементов вектора, которые находятся правее от удаляемого элемента. То есть, в среднем, сложность удаления одного элемента контейнера будет линейной. А сложность очистки всего контейнера - квадратичная. Это все очень печальные результаты. И хоть для последовательности упорядоченных элементов нет стандартного алгоритма удаления из середины, для вектора, в котором порядок неважен, такой алгоритм есть.
Нам нужно лишь свопнуть удаляемый элемент с последним элементом в векторе и очистить последнюю с конца ячейку. Таким образом, удаление будет занимать всего 2 действия, а значит сложность этой операции - константная. Звучит намного лучше.
А что, если нужно отфильтровать массив по какому-то критерию? Ну удалить все ячейки, которые обладают какими-то характеристиками. Например, из массива удалить все числа, кратные 5. Надо тогда в цикле проделать действия из предыдущего абзаца и все будет пучком.
Однако, есть ощущение, что это задача слишком общая и хотелось бы иметь для нее какое-то более элегантное решение, чем каждый раз писать цикл. Можно конечно объявить функцию, но все-таки хочется чего-то стандартного.
И такое есть. В плюсах это называется remove-erase idiom. Идиома удаления-очистки. Какой у меня прекрасный английский)
Решение хоть и стандартное, но не прям очень элегантное. Ну а что вы хотели? Это плюсы все-таки.
Судя по названию, надо просто скомбинировать стандартный алгоритм std::remove (или std::remove_if) и метод вектора std::vector::erase.
На картинке снизу можете увидеть, как конкретно эта комбинация решает задачу удаления элементов.
Stay cool.
#algorithms #STL #datastructures
{kind=link}
Зачем для Remove-Erase идиомы нужны 2 алгоритма?
Удалить из вектора элементы по значению или подходящие под какой-то шаблон не получится напрямую через API вектора. Ну точнее получится, просто вы не хотите, чтобы получалось именно так)
Дело в том, что метод erase у вектора действительно удаляет элемент или рэндж элементов. Но как он это делает?
Вектор - массив смежных ячеек памяти, в которых находятся объекты. То есть один элемент заканчивается и начинается новый. Представим, что мы хотим удалить объект где-нибудь в середине массива. Если мы просто вызовем деструктор этого объекта(отдельную ячейку памяти вернуть системе мы не можем), то тогда у нас нарушится этот инвариант вектора, что все элементы идут друг за другом. И это чисто идейная проблема. А на практике это место в памяти еще и можно было бы также итерпретировать, как живой объект, и работать с ним. Потому что в векторе нет механизма запоминания данных об удаленных ячейках. А если удалять рэндж, то будет целая область пустующая.
Решается эта проблема метода erase сдвигом влево всех элементов, которые остались справа после удаленных. То есть либо копированием, либо перемещением объектов. Тогда все дырки заполнены, инвариантов не нарушено. Но это линейная сложность удаления. То есть на удаление каждого одиноко стоящего элемента нужно тратить линейное время. И для фильтрации всего массива понадобится уже квадратичное время, что не может не огорчать.
Хорошо. Лезем в cpp-reference и находим там алгоритмы std::remove и std:remove_if. Они принимают рендж начало-конец, ищут там конкретное значение или проверяют предикат на верность и удаляют найденные элементы. Вот что там написано про сложность:
Given
1,2) exactly
3,4) exactly
Сложность удаления найденных элементов - линейная. Ну отлично. Х*як и в рабочий код. Тесты валятся, код работает не так как ожидалось. После применения алгоритма на самом деле ничего не удалилось. Элементов столько же, только они в каком-то странном порядке. Почему?
Это я объясняю в видосе из вчерашнего поста. Довольно сложно описать работу std::remove на пальцах в тексте, поэтому и видео появилось. Но для тех, кто не смотрел кратко зарезюмирую. С помощью двух указателей нужные элементы остаются в массиве и перемещаются на свои новые места и делается это так, что в конце массива скапливаются ненужные ячейки. А возвращается из алгоритма итератор на новый конец последовательности, то есть на начало вот этого скопления. Получается std::remove ничего не удаляет, он только переупорядочивает элементы.
И это хорошо, потому что теперь мы можем действительно удалить эти элементы. Причем все разом. Делается это через уже знакомый нам метод вектора erase. Если erase очищает рэндж и этот рендж заканчивается последним элементом, то никаких копирований не происходит. Вызываются деструкторы объектов и изменяется поле, хранящее размер массива. Поэтому получается такая каша:
myVec.erase(std::remove(myVec.begin(), myVec.end(), value), myVec.end());
Собственно, когда эти 2 алгоритма применяются в одной строчке, можно наглядно увидеть причину названия идиомы.
Теперь сложность удаления будет линейной, а это уже не может не радовать.
Да, это выглядит не очень солидно, но имеем, что имеем. Хотя в 20-х плюсах эта ситуация изменилась, как-нибудь расскажу про это.
Stay based. Stay cool.
#cppcore #STL #algorithms #datastructures
Удалить из вектора элементы по значению или подходящие под какой-то шаблон не получится напрямую через API вектора. Ну точнее получится, просто вы не хотите, чтобы получалось именно так)
Дело в том, что метод erase у вектора действительно удаляет элемент или рэндж элементов. Но как он это делает?
Вектор - массив смежных ячеек памяти, в которых находятся объекты. То есть один элемент заканчивается и начинается новый. Представим, что мы хотим удалить объект где-нибудь в середине массива. Если мы просто вызовем деструктор этого объекта(отдельную ячейку памяти вернуть системе мы не можем), то тогда у нас нарушится этот инвариант вектора, что все элементы идут друг за другом. И это чисто идейная проблема. А на практике это место в памяти еще и можно было бы также итерпретировать, как живой объект, и работать с ним. Потому что в векторе нет механизма запоминания данных об удаленных ячейках. А если удалять рэндж, то будет целая область пустующая.
Решается эта проблема метода erase сдвигом влево всех элементов, которые остались справа после удаленных. То есть либо копированием, либо перемещением объектов. Тогда все дырки заполнены, инвариантов не нарушено. Но это линейная сложность удаления. То есть на удаление каждого одиноко стоящего элемента нужно тратить линейное время. И для фильтрации всего массива понадобится уже квадратичное время, что не может не огорчать.
Хорошо. Лезем в cpp-reference и находим там алгоритмы std::remove и std:remove_if. Они принимают рендж начало-конец, ищут там конкретное значение или проверяют предикат на верность и удаляют найденные элементы. Вот что там написано про сложность:
Given
N as std::distance(first, last)1,2) exactly
N comparisons with value using operator==.3,4) exactly
N applications of the predicate p.Сложность удаления найденных элементов - линейная. Ну отлично. Х*як и в рабочий код. Тесты валятся, код работает не так как ожидалось. После применения алгоритма на самом деле ничего не удалилось. Элементов столько же, только они в каком-то странном порядке. Почему?
Это я объясняю в видосе из вчерашнего поста. Довольно сложно описать работу std::remove на пальцах в тексте, поэтому и видео появилось. Но для тех, кто не смотрел кратко зарезюмирую. С помощью двух указателей нужные элементы остаются в массиве и перемещаются на свои новые места и делается это так, что в конце массива скапливаются ненужные ячейки. А возвращается из алгоритма итератор на новый конец последовательности, то есть на начало вот этого скопления. Получается std::remove ничего не удаляет, он только переупорядочивает элементы.
И это хорошо, потому что теперь мы можем действительно удалить эти элементы. Причем все разом. Делается это через уже знакомый нам метод вектора erase. Если erase очищает рэндж и этот рендж заканчивается последним элементом, то никаких копирований не происходит. Вызываются деструкторы объектов и изменяется поле, хранящее размер массива. Поэтому получается такая каша:
myVec.erase(std::remove(myVec.begin(), myVec.end(), value), myVec.end());
Собственно, когда эти 2 алгоритма применяются в одной строчке, можно наглядно увидеть причину названия идиомы.
Теперь сложность удаления будет линейной, а это уже не может не радовать.
Да, это выглядит не очень солидно, но имеем, что имеем. Хотя в 20-х плюсах эта ситуация изменилась, как-нибудь расскажу про это.
Stay based. Stay cool.
#cppcore #STL #algorithms #datastructures
{kind=link}