
Приветственный пост
Рады приветствовать всех на нашем канале!
Вы устали от скучного, монотонного, обезличенного контента по плюсам?
Тогда мы идем к вам!
Здесь не будет бесполезных 30 IQ постов, сгенеренных ChatGPT, накрученных подписчиков и активности.
Канал ведут два сеньора, Денис и Владимир, которые искренне хотят делится своими знаниями по С++ и создать самое уютное коммьюнити позитивных прогеров в телеге!
(ну вы поняли, да? с++, плюс плюс, плюс типа
позитивный?.. ай ладно)
Жмакай и попадешь в наш чат. Там обсуждения не привязаны к постам, можете общаться на любые темы.
ГАЙДЫ:
Мини-гайд по собеседования
Гайд по категория выражения и мув-семантике
Гайд по inline
Дальше пойдет список хэштегов, которыми вы можете пользоваться для более удобной навигации по каналу и для быстрого поиска группы постов по интересующей теме:
#algorithms
#datastructures
#cppcore
#stl
#goodoldc
#cpp11
#cpp14
#cpp17
#cpp20
#commercial
#net
#database
#hardcore
#memory
#goodpractice
#howitworks
#NONSTANDARD
#interview
#digest
#OS
#tools
#optimization
#performance
#fun
#compiler
#multitasking
#design
#exception
#guide
#задачки
#base
#quiz
#concurrency
Рады приветствовать всех на нашем канале!
Вы устали от скучного, монотонного, обезличенного контента по плюсам?
Тогда мы идем к вам!
Здесь не будет бесполезных 30 IQ постов, сгенеренных ChatGPT, накрученных подписчиков и активности.
Канал ведут два сеньора, Денис и Владимир, которые искренне хотят делится своими знаниями по С++ и создать самое уютное коммьюнити позитивных прогеров в телеге!
(ну вы поняли, да? с++, плюс плюс, плюс типа
позитивный?.. ай ладно)
Жмакай и попадешь в наш чат. Там обсуждения не привязаны к постам, можете общаться на любые темы.
ГАЙДЫ:
Мини-гайд по собеседования
Гайд по категория выражения и мув-семантике
Гайд по inline
Дальше пойдет список хэштегов, которыми вы можете пользоваться для более удобной навигации по каналу и для быстрого поиска группы постов по интересующей теме:
#algorithms
#datastructures
#cppcore
#stl
#goodoldc
#cpp11
#cpp14
#cpp17
#cpp20
#commercial
#net
#database
#hardcore
#memory
#goodpractice
#howitworks
#NONSTANDARD
#interview
#digest
#OS
#tools
#optimization
#performance
#fun
#compiler
#multitasking
#design
#exception
#guide
#задачки
#base
#quiz
#concurrency
Telegram
Грокаем C++
Мини-гайд по собеседованиям
Доброго дня, дорогие подписчики. Сегодня у нас радостный день - на канале выходит первый гайд. Не так давно мы в комментах с ребятами осуждали этот вопрос, что нужно сделать чеклист по вопросам с собесов. Собственно, сделал. Скачивайте…
Доброго дня, дорогие подписчики. Сегодня у нас радостный день - на канале выходит первый гайд. Не так давно мы в комментах с ребятами осуждали этот вопрос, что нужно сделать чеклист по вопросам с собесов. Собственно, сделал. Скачивайте…
Дублирование - зло. Ч1
Обычно, когда затрагивают тему злостности дублирования кода, вспоминают принцип DRY - акроним Don't Repeat Yourself, т.е. не повторяй себя. Это хорошо известный с давних времен и проверенный временем принцип, о котором вы обязательно должны знать.
Почему же дублирование кода вызывает проблемы? В основном, причина заключается в том, что это сильно увеличивает сложность и непредсказуемость ваших программ в будущем:
1. Распространение ошибок. Ошибки в исходном фрагменте кода будут копироваться и распространяться по проекту.
2. Поиск клонов. При внесении изменений в продублированную область приходится помнить где и что было скопировано ранее, чтобы туда тоже внести еще изменения.
3. Мелкие различия в клонах. Нередко так же приходится помнить, чем же дублированный код отличается друг от друга, чтобы вносить корректные изменения. Значит, придется перечитывать этот код везде, где он появился...
4. Проблема тестирования. Нередко теряется работоспособность скопированных участков кода в другом контексте. Например, переменные с одинаковым именем могут иметь разные типы данных там, куда вы скопировали код.
Если вы разрабатываете проект один, вы, допустим, сможете это все запомнить, но если приходит новый сотрудник - эти знания приходится передавать ему. Чем больше таких нюансов, тем сильнее растет этот снежный ком. А вот как дело пойдет дальше - неизвестно, вдруг коллега не все запомнит или что-то забудет? Вообще говоря, это неизбежно рано или поздно произойдет. Я предпочитаю думать сразу, что если что-то неизбежно, то можно считать, что это уже произошло. Значит действовать нужно уже сейчас!
Короче, вы создаете себе армию клонов, которая потом начинает атаковать вас. На самом деле, вам просто не хватает человеческих возможностей, чтобы обслуживать все клоны. Миритесь с этим 🙃
Давайте подумаем, что изменится, если отказаться от дублирования?
- Во первых, увеличится предсказуемость кода. Если я знаю, что дублирования нет, значит мне нужно найти единственный кусок кода / файл. Пока я его не найду, я буду уверен, что его нужно продолжать искать.
- Во вторых, увеличится реактивность при внесении изменений. Если я знаю, что дублирования нет, значит мне достаточно внести изменение в единственный кусок кода / файл. Этого достаточно, чтобы изменить все вышестоящие модели, которые от него зависят.
Конечно же, придерживаться 100% этого принципа, невозможно и даже не всегда нужно. Поговорим об этих нюансах в следующих статьях.
Кстати, зацените комментарии к постам! Жду вопросов 👇
#goodpractice #design
Обычно, когда затрагивают тему злостности дублирования кода, вспоминают принцип DRY - акроним Don't Repeat Yourself, т.е. не повторяй себя. Это хорошо известный с давних времен и проверенный временем принцип, о котором вы обязательно должны знать.
Почему же дублирование кода вызывает проблемы? В основном, причина заключается в том, что это сильно увеличивает сложность и непредсказуемость ваших программ в будущем:
1. Распространение ошибок. Ошибки в исходном фрагменте кода будут копироваться и распространяться по проекту.
2. Поиск клонов. При внесении изменений в продублированную область приходится помнить где и что было скопировано ранее, чтобы туда тоже внести еще изменения.
3. Мелкие различия в клонах. Нередко так же приходится помнить, чем же дублированный код отличается друг от друга, чтобы вносить корректные изменения. Значит, придется перечитывать этот код везде, где он появился...
4. Проблема тестирования. Нередко теряется работоспособность скопированных участков кода в другом контексте. Например, переменные с одинаковым именем могут иметь разные типы данных там, куда вы скопировали код.
Если вы разрабатываете проект один, вы, допустим, сможете это все запомнить, но если приходит новый сотрудник - эти знания приходится передавать ему. Чем больше таких нюансов, тем сильнее растет этот снежный ком. А вот как дело пойдет дальше - неизвестно, вдруг коллега не все запомнит или что-то забудет? Вообще говоря, это неизбежно рано или поздно произойдет. Я предпочитаю думать сразу, что если что-то неизбежно, то можно считать, что это уже произошло. Значит действовать нужно уже сейчас!
Короче, вы создаете себе армию клонов, которая потом начинает атаковать вас. На самом деле, вам просто не хватает человеческих возможностей, чтобы обслуживать все клоны. Миритесь с этим 🙃
Давайте подумаем, что изменится, если отказаться от дублирования?
- Во первых, увеличится предсказуемость кода. Если я знаю, что дублирования нет, значит мне нужно найти единственный кусок кода / файл. Пока я его не найду, я буду уверен, что его нужно продолжать искать.
- Во вторых, увеличится реактивность при внесении изменений. Если я знаю, что дублирования нет, значит мне достаточно внести изменение в единственный кусок кода / файл. Этого достаточно, чтобы изменить все вышестоящие модели, которые от него зависят.
Конечно же, придерживаться 100% этого принципа, невозможно и даже не всегда нужно. Поговорим об этих нюансах в следующих статьях.
Кстати, зацените комментарии к постам! Жду вопросов 👇
#goodpractice #design
{kind=link}
Дублирование - зло. Ч2
В предыдущей части я успел сказать, что проблема дублирования кода не настолько однозначна, как может показаться. Главная цель, которая преследуется при удалении клонов - это упростить разработку и сделать код понятнее.
Самый простой код - не всегда самый короткий. При написании и рефакторинге кода обобщению подлежат только осмысленные части кода. Это подразумевает выделение только значимых и повторяющихся элементов и изоляцию их в отдельные функции, классы или модули. Суть заключается в разделении обязанностей и зон ответственностей. Универсальные вещи, как правило, сложно устроены, и поэтому неповоротливы для изменений. Более того, с развитием проекта, где-то обязательно придется вносить корректировки. То есть еще больше наращивать сложность... Куда проще понять и поменять композицию простых действий.
По своей сути, клонирование, говорит о не очень качественном коде. Однако, я бы не хотел, чтобы у наших подписчиков появилась навязчивая мысль всюду искать клоны и избавляться от них. Напоминаю, цель в другом 😅 Истинная причина возникновения дублей может заключаться в плохом интерфейсе, в неудачной архитектуре или наборе библиотек. Соответственно, это может подтолкнуть к совершенно другим стратегическим действиям разработчиков.
Еще одной проблемой на пути к искоренению дублирования в существующем проекте может быть развесистая кодовая база. Вносить изменения в уже написанный код, потенциально, чревато не только затратами времени, но и появлением новых или возрождением старых багов. Воскресшие запросы, наверно, больше всего огорчают. Всегда стоит взвешивать количество принесенной пользы и потенциальные риски переделок.
Если уж все таки было принято решение избавляться от клонов, то следует в первую очередь попробовать использовать возможности среды разработки / задействовать сторонние инструменты. Например, посмотрите на SonarQube и плагин для IDEA, Eclipse, Visual Studio, Visual Studio Code и Atom — SonarLint. Дело даже не в том, что это рутинная работа, которая может быть автоматизирована. Программный поиск даст возможность быстро провести разведку и легко оценить ситуацию в вашем проекте. Это сильно ускорит анализ, сократит рутину и снизит риски найти на поздних этапах какой-то исключительный клон, меняющий правила обобщения кода.
Надеюсь, что мне удалось убедить вас в злостности и неоднозначности проблемы дублирования 😉 Эта статья мне пригодится для следующих постов, так что если остались вопросы - пишите комменты!
#design #goodpractice #tools
В предыдущей части я успел сказать, что проблема дублирования кода не настолько однозначна, как может показаться. Главная цель, которая преследуется при удалении клонов - это упростить разработку и сделать код понятнее.
Самый простой код - не всегда самый короткий. При написании и рефакторинге кода обобщению подлежат только осмысленные части кода. Это подразумевает выделение только значимых и повторяющихся элементов и изоляцию их в отдельные функции, классы или модули. Суть заключается в разделении обязанностей и зон ответственностей. Универсальные вещи, как правило, сложно устроены, и поэтому неповоротливы для изменений. Более того, с развитием проекта, где-то обязательно придется вносить корректировки. То есть еще больше наращивать сложность... Куда проще понять и поменять композицию простых действий.
По своей сути, клонирование, говорит о не очень качественном коде. Однако, я бы не хотел, чтобы у наших подписчиков появилась навязчивая мысль всюду искать клоны и избавляться от них. Напоминаю, цель в другом 😅 Истинная причина возникновения дублей может заключаться в плохом интерфейсе, в неудачной архитектуре или наборе библиотек. Соответственно, это может подтолкнуть к совершенно другим стратегическим действиям разработчиков.
Еще одной проблемой на пути к искоренению дублирования в существующем проекте может быть развесистая кодовая база. Вносить изменения в уже написанный код, потенциально, чревато не только затратами времени, но и появлением новых или возрождением старых багов. Воскресшие запросы, наверно, больше всего огорчают. Всегда стоит взвешивать количество принесенной пользы и потенциальные риски переделок.
Если уж все таки было принято решение избавляться от клонов, то следует в первую очередь попробовать использовать возможности среды разработки / задействовать сторонние инструменты. Например, посмотрите на SonarQube и плагин для IDEA, Eclipse, Visual Studio, Visual Studio Code и Atom — SonarLint. Дело даже не в том, что это рутинная работа, которая может быть автоматизирована. Программный поиск даст возможность быстро провести разведку и легко оценить ситуацию в вашем проекте. Это сильно ускорит анализ, сократит рутину и снизит риски найти на поздних этапах какой-то исключительный клон, меняющий правила обобщения кода.
Надеюсь, что мне удалось убедить вас в злостности и неоднозначности проблемы дублирования 😉 Эта статья мне пригодится для следующих постов, так что если остались вопросы - пишите комменты!
#design #goodpractice #tools
{kind=link}
Экспресс совет
Когда реализуете сущность типа фабричного метода, скорее всего вы выделяете объект в куче и возвращаете его в каком-то виде. В сишном стиле это raw pointer. Для плюсовиков это уже считается зашкваром, поэтому все возвращают умный указатель. Но какой умный указатель возвратить?
Если вы не используете кэширование для возвращаемых объектов, то лучший выбор - std::unique_ptr. Причина проста, как мир - у шареного указателя есть конструктор от уникального, а у уникального нет от шареного. Права и ограничения вполне понятны, а значит в случае, если вам нужен будет шареный указатель - просто скастуете уникальный к нему. В остальных случая используйте как есть.
При кэшировании в любом случае придётся использовать std::shared_ptr, ибо вторую ссылку где-то надо хранить, так что выбора особо нет.
The end. Stay cool.
#goodpractice #STL #design
Когда реализуете сущность типа фабричного метода, скорее всего вы выделяете объект в куче и возвращаете его в каком-то виде. В сишном стиле это raw pointer. Для плюсовиков это уже считается зашкваром, поэтому все возвращают умный указатель. Но какой умный указатель возвратить?
Если вы не используете кэширование для возвращаемых объектов, то лучший выбор - std::unique_ptr. Причина проста, как мир - у шареного указателя есть конструктор от уникального, а у уникального нет от шареного. Права и ограничения вполне понятны, а значит в случае, если вам нужен будет шареный указатель - просто скастуете уникальный к нему. В остальных случая используйте как есть.
При кэшировании в любом случае придётся использовать std::shared_ptr, ибо вторую ссылку где-то надо хранить, так что выбора особо нет.
The end. Stay cool.
#goodpractice #STL #design
Когда использовать Nodiscard?
Вот тут мы обсудили мотив защиты своих сущностей от опасного использования, в том числе и защиту от неиспользования возвращаемого значения функции с помощью атрибута nodiscard. Тот разговор был довольно общим и не затрагивал особой конкретики. Теперь же поговорим о том, в каких ситуациях стоит использовать этот атрибут, чтобы вынести из этого реальную пользу.
💥 Функция возвращает код ошибки. Стандартная тема в принципе. Очень много кода написано в стиле: функция использует in/out параметры и возвращает статус(ошибка или нет). Не важно, в каком виде статус: булавок значение, числовое или enum. В этом случае возникает потенциальная проблема, когда программист не обработает статус выполнения операции и программа может продолжить выполняться совсем не так, как предполагалось изначально.
💥 Ваша функция - фабрика. Кажется, что таких ситуаций случалось примерно никогда, НО! Чисто семантически, предполагается, что возвращаемое значение будет использоваться. Поэтому в целом, не лишним будет усилить эту семантику. Ну знаете. На всякий случай. Вдруг какой-то кодер скопипастил название фабрики с аргументами, захотел кекать, вернулся облегчённым и на радостях забыл использовать созданный объект. Во время компиляции это выясниться и этот кодер уйдёт в глубокий тильт от своей тупости. Давайте заботиться о невнимательных коллегах и не подвергать их ментальное здоровье риску.
💥 Когда функция возвращает тяжеловесный тип. Не за тем я конструировал сложный, тяжелый тип или контейнер объектов, которые потом не будут использованы. Обычно это делается все-таки, чтобы потом как-то использовать эту сущность. Поэтому опять же, на всякий случай, можно эту функцию пометить атрибутом.
💥 Везде? Был какой-то пропоузал в стандарт, чтобы весь новый код стандартной библиотеки помечался этим атрибутом. Это аргументировалось тем, что не зря функция что-то возвращает, и если это можно не использовать, зачем тогда проектировать такой интерфейс. А также тем, что пропуск возвращаемого значения в подавляющем большинстве случаев приводит к проблемам.
Думаю, что везде его пихать не надо, как это делать евреи со своими носами, но определенно использование nodiscard усилит безопасность вашего кода и первые три кейса - достаточно хорошая база, чтобы начать его внедрять.
Stay safe. Stay cool.
#compiler #goodpractice #design
Вот тут мы обсудили мотив защиты своих сущностей от опасного использования, в том числе и защиту от неиспользования возвращаемого значения функции с помощью атрибута nodiscard. Тот разговор был довольно общим и не затрагивал особой конкретики. Теперь же поговорим о том, в каких ситуациях стоит использовать этот атрибут, чтобы вынести из этого реальную пользу.
💥 Функция возвращает код ошибки. Стандартная тема в принципе. Очень много кода написано в стиле: функция использует in/out параметры и возвращает статус(ошибка или нет). Не важно, в каком виде статус: булавок значение, числовое или enum. В этом случае возникает потенциальная проблема, когда программист не обработает статус выполнения операции и программа может продолжить выполняться совсем не так, как предполагалось изначально.
💥 Ваша функция - фабрика. Кажется, что таких ситуаций случалось примерно никогда, НО! Чисто семантически, предполагается, что возвращаемое значение будет использоваться. Поэтому в целом, не лишним будет усилить эту семантику. Ну знаете. На всякий случай. Вдруг какой-то кодер скопипастил название фабрики с аргументами, захотел кекать, вернулся облегчённым и на радостях забыл использовать созданный объект. Во время компиляции это выясниться и этот кодер уйдёт в глубокий тильт от своей тупости. Давайте заботиться о невнимательных коллегах и не подвергать их ментальное здоровье риску.
💥 Когда функция возвращает тяжеловесный тип. Не за тем я конструировал сложный, тяжелый тип или контейнер объектов, которые потом не будут использованы. Обычно это делается все-таки, чтобы потом как-то использовать эту сущность. Поэтому опять же, на всякий случай, можно эту функцию пометить атрибутом.
💥 Везде? Был какой-то пропоузал в стандарт, чтобы весь новый код стандартной библиотеки помечался этим атрибутом. Это аргументировалось тем, что не зря функция что-то возвращает, и если это можно не использовать, зачем тогда проектировать такой интерфейс. А также тем, что пропуск возвращаемого значения в подавляющем большинстве случаев приводит к проблемам.
Думаю, что везде его пихать не надо, как это делать евреи со своими носами, но определенно использование nodiscard усилит безопасность вашего кода и первые три кейса - достаточно хорошая база, чтобы начать его внедрять.
Stay safe. Stay cool.
#compiler #goodpractice #design
{kind=link}
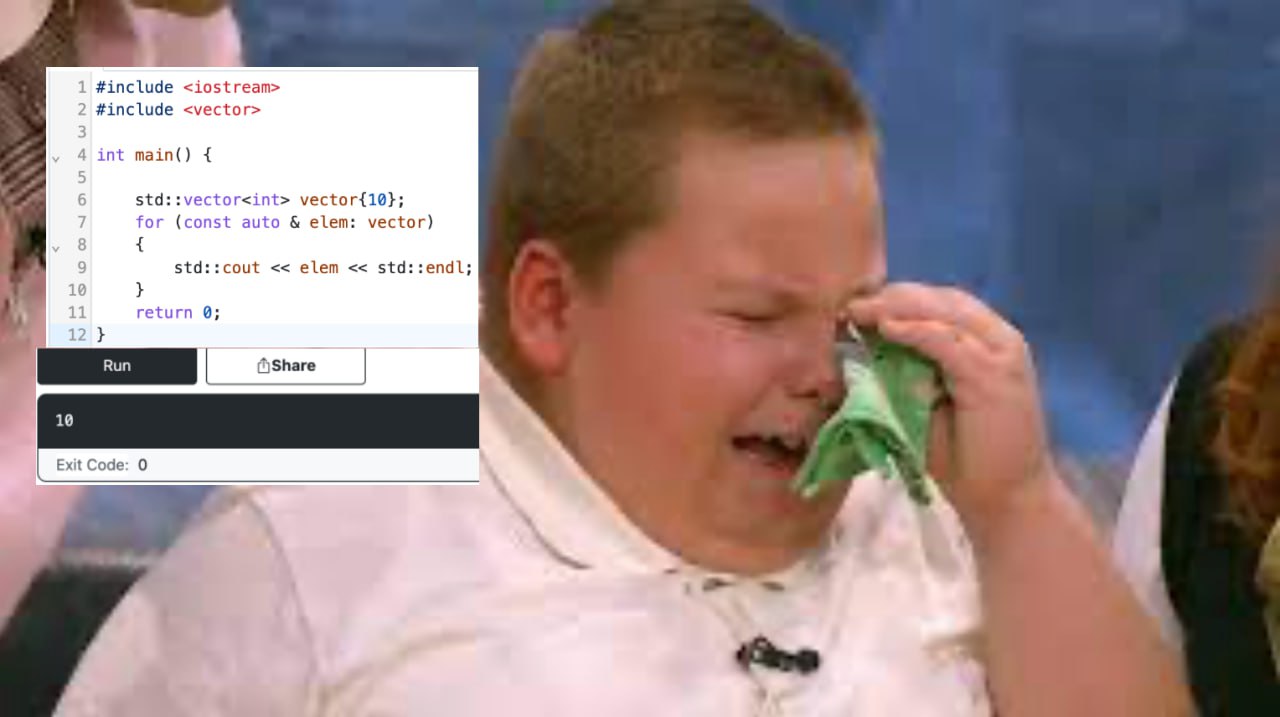
Универсальная инициализация и непростые пути инициализации векторов
Живете вы себе такой спокойно, хотите по фану создать массив на 10 элементов. И пишите:
std::vector<int> vector{10};
Запустив свой код, вы нихера не понимаете, че происходит. Поведение совершенно не такое, какое ожидалось при запуске. Проверяете все части программы, все в порядке. И доходите до того, что у вас в векторе не 10 элементов, а всего 1. WTF?! Щас разберемся.
Универсальная инициализация, представленная в C++11, позволяет нам инициализировать объекты, используя один набор фигурных скобок {}. Это безопасный и удобный способ инициализации различных типов. Не буду перечислять причин удобства, можете поверить на слово. Однако, когда дело доходит до инициализации векторов, возникает несколько препятствий.
На самом деле, не только векторов. А всех классов с конструкторами от std::initializer_list. Дело в том, что эта перегрузка затемняет все другие конструкторы класса. То есть, если вы определили такой конструктор и вы используете универсальную инициализацию, то компилятор всегда будет предполагать, что вы хотите вызвать именно конструктор от std::initializer_list. Даже если другие перегрузки будут иметь намного больший смысл. В основном эта проблема касается именно числовых типов. Но после С++17, когда мы можем опускать шаблонный параметр вектора, проблема заиграла новыми красками.
Что же с этим делать?
Универсального способа, конечно, нет. В разных командах существуют разные гайдлайны, как решать проблему. Приведу несколько общих правил, которые помогут не попадаться в ловушку:
Если вы намеренно используете список инициализации в качестве параметра конструктора, то можно явно его создавать, используя explicit конструктор. Типа того:
std::vector<int> myVector{std::initializer_list<int>{1, 2, 3}};. Это никогда не создаст семантическую путаницу.
Для инициализации объектов классов с помощью обычных аргументов используйте круглые скобки. Это предотвратит интерпретацию компилятором параметров как списка инициализации и поспособствует вызову нужных конструкторов.
Проектируйте свои классы, чтобы этой путаницы не происходило. Мы не можем повлиять на код стандартной библиотеки. Но можем в своих проектах придерживаться порядка и однозначности.
Stay well-designed. Stay cool.
#cpp11 #design #STL
Живете вы себе такой спокойно, хотите по фану создать массив на 10 элементов. И пишите:
std::vector<int> vector{10};
Запустив свой код, вы нихера не понимаете, че происходит. Поведение совершенно не такое, какое ожидалось при запуске. Проверяете все части программы, все в порядке. И доходите до того, что у вас в векторе не 10 элементов, а всего 1. WTF?! Щас разберемся.
Универсальная инициализация, представленная в C++11, позволяет нам инициализировать объекты, используя один набор фигурных скобок {}. Это безопасный и удобный способ инициализации различных типов. Не буду перечислять причин удобства, можете поверить на слово. Однако, когда дело доходит до инициализации векторов, возникает несколько препятствий.
На самом деле, не только векторов. А всех классов с конструкторами от std::initializer_list. Дело в том, что эта перегрузка затемняет все другие конструкторы класса. То есть, если вы определили такой конструктор и вы используете универсальную инициализацию, то компилятор всегда будет предполагать, что вы хотите вызвать именно конструктор от std::initializer_list. Даже если другие перегрузки будут иметь намного больший смысл. В основном эта проблема касается именно числовых типов. Но после С++17, когда мы можем опускать шаблонный параметр вектора, проблема заиграла новыми красками.
Что же с этим делать?
Универсального способа, конечно, нет. В разных командах существуют разные гайдлайны, как решать проблему. Приведу несколько общих правил, которые помогут не попадаться в ловушку:
Если вы намеренно используете список инициализации в качестве параметра конструктора, то можно явно его создавать, используя explicit конструктор. Типа того:
std::vector<int> myVector{std::initializer_list<int>{1, 2, 3}};. Это никогда не создаст семантическую путаницу.
Для инициализации объектов классов с помощью обычных аргументов используйте круглые скобки. Это предотвратит интерпретацию компилятором параметров как списка инициализации и поспособствует вызову нужных конструкторов.
Проектируйте свои классы, чтобы этой путаницы не происходило. Мы не можем повлиять на код стандартной библиотеки. Но можем в своих проектах придерживаться порядка и однозначности.
Stay well-designed. Stay cool.
#cpp11 #design #STL
{kind=link}
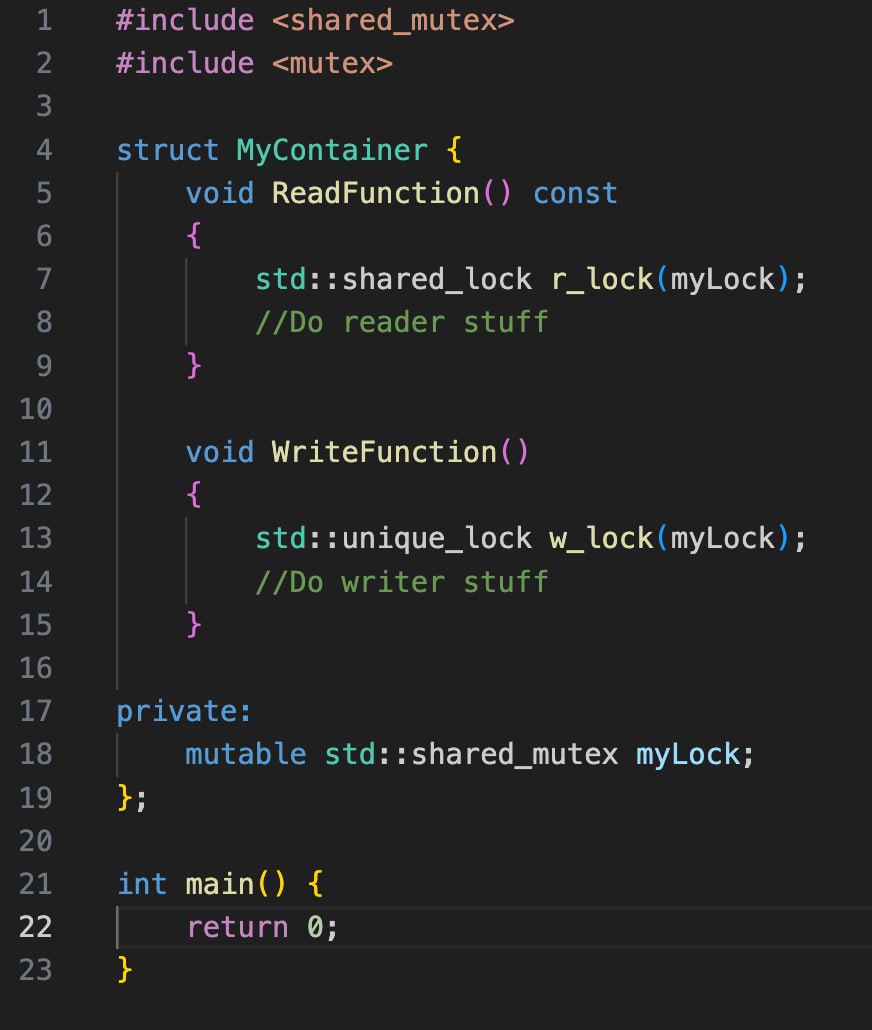
Потокобезопасные константные методы
Представьте, что у вас есть есть кастомный контейнер, который хранит ваши данные каким-то нетривиальным образом. Как и у любого контейнера, у него должны быть методы аля insert(…) для вставки значения в контейнер и методы для доступа к элементам get(…)(оператор [], at() и тд). Согласно правилам организации хорошего и понятного кода вы объявили get() как const. Оно и понятно, ведь любой пользователь вашего контейнера будет понимать, что доступ к элементам контейнера никак не будет отражаться на его внутреннем устройстве. Это делает код более понятным и безопасным для пользователя. Все хорошо и прекрасно.
Но тут вам приходит идея сделать этот контейнер потокобезопасным. Проблем нет, заводим shared_mutex как поле объекта и лочим операции вставки и доступа. Используем read-write lock, чтобы несколько потоков одновременно могли безопасно читать из контейнера значения, а как только придёт пишущий поток, блокировать операции чтения и записи для других потоков. Компилируем это дело и получаем ошибку. Причём гцц вам как всегда выдаст самое понятное сообщение об ошибке. Такое, что глаза вытекают и мозг плавится. Но рано или поздно осознание придёт. Вы не можете изменять поля класса в константных методах. Что делать?
На деле проблема серьёзная. С одной стороны, пользователь должен получать доступ к чтению элементов контейнера у константного объекта, иначе он по сути бесполезен. С другой стороны, существует ряд юз-кейсов, когда для оптимизации константной операции требуется изменять внутреннее состояние объекта. Классика - это использование кэш-значения и замков.
Поэтому в языке есть ключевое слово, про которое все, вплоть до мидлов, забывают и встречаются с ним только на собесах. Mutable. Этот keyword разрешает изменять какое-то поле класса в константных методах. Объявим наш shared_mutex как mutable и все заработает.
Решение элегантное, красивое и лаконичное. Только вот само использование этого приема попахивает нарушением инкапсуляции. Немножко совсем. Поэтому не стоит злоупотреблять этим приемом и скрывать им недостатки архитектуры класса. Если вам нужно поменять объект в константном методе и это не общепринятый кейс использования mutable - вам скорее всего нужно пересмотреть дизайн.
Stay safe. Stay cool.
#multitasking #cppcore #design
Представьте, что у вас есть есть кастомный контейнер, который хранит ваши данные каким-то нетривиальным образом. Как и у любого контейнера, у него должны быть методы аля insert(…) для вставки значения в контейнер и методы для доступа к элементам get(…)(оператор [], at() и тд). Согласно правилам организации хорошего и понятного кода вы объявили get() как const. Оно и понятно, ведь любой пользователь вашего контейнера будет понимать, что доступ к элементам контейнера никак не будет отражаться на его внутреннем устройстве. Это делает код более понятным и безопасным для пользователя. Все хорошо и прекрасно.
Но тут вам приходит идея сделать этот контейнер потокобезопасным. Проблем нет, заводим shared_mutex как поле объекта и лочим операции вставки и доступа. Используем read-write lock, чтобы несколько потоков одновременно могли безопасно читать из контейнера значения, а как только придёт пишущий поток, блокировать операции чтения и записи для других потоков. Компилируем это дело и получаем ошибку. Причём гцц вам как всегда выдаст самое понятное сообщение об ошибке. Такое, что глаза вытекают и мозг плавится. Но рано или поздно осознание придёт. Вы не можете изменять поля класса в константных методах. Что делать?
На деле проблема серьёзная. С одной стороны, пользователь должен получать доступ к чтению элементов контейнера у константного объекта, иначе он по сути бесполезен. С другой стороны, существует ряд юз-кейсов, когда для оптимизации константной операции требуется изменять внутреннее состояние объекта. Классика - это использование кэш-значения и замков.
Поэтому в языке есть ключевое слово, про которое все, вплоть до мидлов, забывают и встречаются с ним только на собесах. Mutable. Этот keyword разрешает изменять какое-то поле класса в константных методах. Объявим наш shared_mutex как mutable и все заработает.
Решение элегантное, красивое и лаконичное. Только вот само использование этого приема попахивает нарушением инкапсуляции. Немножко совсем. Поэтому не стоит злоупотреблять этим приемом и скрывать им недостатки архитектуры класса. Если вам нужно поменять объект в константном методе и это не общепринятый кейс использования mutable - вам скорее всего нужно пересмотреть дизайн.
Stay safe. Stay cool.
#multitasking #cppcore #design
{kind=link}
Как использовать RAII с сишным API
Все мы с вами используем сишный API. Базы данных, работа с сетью, криптография. Перечислять области можно долго. И все мы с вами немного недолюбливаем такой способ взаимодействия с сущностями. Оно и понятно. Не зря умные дяди придумывали объектно-ориентированное программирование и не зря мы, не такие умные дяди, стараемся этой методологии следовать. А тут нужны какие-то сырые указатели, байтовые буфферы и прочие вульгарности. Это не только неудобно, но может приводить к трудноотловимым ошибкам, недостаточной гарантии безопасности. Старшие ребята, естественно, знают, как правильно использовать плюсовые объекты в таких случаях, а вот молодняк может не знать этого или не осознавать подходов, которые они использовали. Поэтому поделюсь своей интерпретацией адекватного подхода, который поможет грамотно использовать RAII с сишным апи.
На помощь нам неожиданно приходят std::array и std::vector. Это простые RAII обертки над статическими и динамическими массивами, которые предлагают следующие фичи:
1️⃣ Автоматическое управление памятью. std::array в конструкторе аллоцирует память на стеке, std::vector - на куче. Их деструктор вызывается при выходе из скоупа.
2️⃣ Детерминированная инициализация. Инициализация этих контейнеров происходи в конструкторе, что предотвращает обращение к неинициализированной памяти.
3️⃣ Безопасный и удобный доступ к элементам с помощью методов .at(), .back(), .front() и итераторов.
4️⃣ Легкий доступ к буферу через метод .data().
Как их использовать для взаимодействия с С API? Гениально и просто.
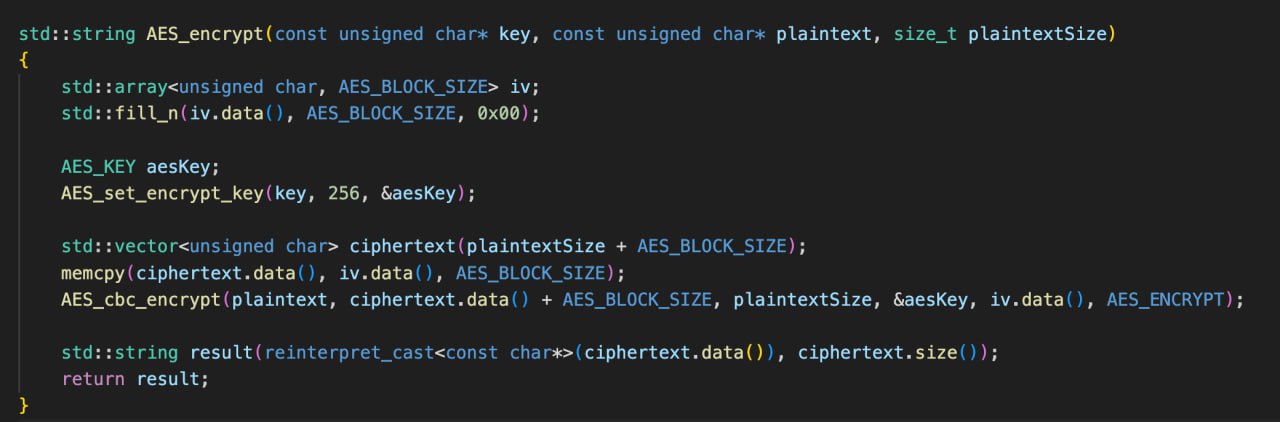
👉🏿 Объявить нужный массив. Если размер структуры известен на момент компиляции - std::array, если нет - std::vector. Инициализировать его в конструкторе нужными значениями: дефолтовыми - в конструкторе, кастомными - через memcpy(array_ptr, struct_ptr, struct_size).
👉🏿 Передать в Сишный апи. Например так:
AES_cbc_encrypt(plaintext_array.data, ciphertext_array.size(), plaintext_array.size() ...);
👉🏿 Наслаждаться жизнью, ибо больше вам не нужно ни о чем беспокоиться.
Если уж вы передаете в С API более сложные структуры, чем массивы, то вам могут понадобиться методы сериализации и десериализации.
Используя возможности RAII массивов вы можете упростить и оптимизировать свой код, гарантировать правильное управление памятью и безопасную передачу данных в С API.
Делитесь своим опытом взаимодействия с API C и используйте modern C++ для более надежного и эффективного кода.
Stay cool.
#goodoldc #design #cppcore #STL
Все мы с вами используем сишный API. Базы данных, работа с сетью, криптография. Перечислять области можно долго. И все мы с вами немного недолюбливаем такой способ взаимодействия с сущностями. Оно и понятно. Не зря умные дяди придумывали объектно-ориентированное программирование и не зря мы, не такие умные дяди, стараемся этой методологии следовать. А тут нужны какие-то сырые указатели, байтовые буфферы и прочие вульгарности. Это не только неудобно, но может приводить к трудноотловимым ошибкам, недостаточной гарантии безопасности. Старшие ребята, естественно, знают, как правильно использовать плюсовые объекты в таких случаях, а вот молодняк может не знать этого или не осознавать подходов, которые они использовали. Поэтому поделюсь своей интерпретацией адекватного подхода, который поможет грамотно использовать RAII с сишным апи.
На помощь нам неожиданно приходят std::array и std::vector. Это простые RAII обертки над статическими и динамическими массивами, которые предлагают следующие фичи:
1️⃣ Автоматическое управление памятью. std::array в конструкторе аллоцирует память на стеке, std::vector - на куче. Их деструктор вызывается при выходе из скоупа.
2️⃣ Детерминированная инициализация. Инициализация этих контейнеров происходи в конструкторе, что предотвращает обращение к неинициализированной памяти.
3️⃣ Безопасный и удобный доступ к элементам с помощью методов .at(), .back(), .front() и итераторов.
4️⃣ Легкий доступ к буферу через метод .data().
Как их использовать для взаимодействия с С API? Гениально и просто.
👉🏿 Объявить нужный массив. Если размер структуры известен на момент компиляции - std::array, если нет - std::vector. Инициализировать его в конструкторе нужными значениями: дефолтовыми - в конструкторе, кастомными - через memcpy(array_ptr, struct_ptr, struct_size).
👉🏿 Передать в Сишный апи. Например так:
AES_cbc_encrypt(plaintext_array.data, ciphertext_array.size(), plaintext_array.size() ...);
👉🏿 Наслаждаться жизнью, ибо больше вам не нужно ни о чем беспокоиться.
Если уж вы передаете в С API более сложные структуры, чем массивы, то вам могут понадобиться методы сериализации и десериализации.
Используя возможности RAII массивов вы можете упростить и оптимизировать свой код, гарантировать правильное управление памятью и безопасную передачу данных в С API.
Делитесь своим опытом взаимодействия с API C и используйте modern C++ для более надежного и эффективного кода.
Stay cool.
#goodoldc #design #cppcore #STL
{kind=link}
Идиома NVI
В публикации под названием "C++ Coding Standards: 101 Rules, Guidelines, and Best Practices" есть такая строчка: Consider making virtual functions nonpublic, and public functions nonvirtual. По-русски - рассмотрите возможности сделать виртуальные функции непубличными, а публичные функции - невиртуальными. Для кого-то сейчас это предложение звучит, как минимум, странно. "Я ж всегда определял полиморфный интерфейс классов публичным. И зачем вообще делать виртуальные методы непубличными? " Уверяю вас, что эту строчку написали вполне уважаемые в международном коммьюнити люди - Андрей Александреску и Герб Саттер. Фигню они вряд ли скажут, поэтому сейчас постараюсь объяснить, какие идеи лежат за этими словами.
Иногда хорошие практики организации кода оформляют в виде идиом. И для выражения выше появилась такая идиома(хотя не знаю, что появилось раньше:курица или яйцоидиома или эта цитата). Называется она non-virtual interface idiom. Говорящее название)
Мотивация
Представьте себе какую-нибудь обычную иерархию классов. Очень часто полиморфные методы классов в ней выполняют какую-то общую работу. Это может быть обработка ошибок, логирование, сбор мониторингов, вызов какого-то общего метода, захват общего мьютекса, вы работаете с данными на низком уровне, а потом запаковываете в одинаковый формат и выдаете наружу и тд. Перечислять можно реально долго. Я бы даже так сказал: полифорфные методы с развитием проекта практически обречены обретать общую функциональность. То есть даже если ее не было, она с большой вероятностью появится. К чему это будет приводить? Желание изменить один аспект поведения объектов приводит к изменению кода по всей иерархии классов. Это увеличивает сложность внедрения новой или обслуживающей функциональности. А там еще и копипаст ошибки могут подьехать. Можно забыть в каком-то наследнике добавить то, что нужно. В общем беда.
А если нужно подкорректировать API без особого изменения кор-функциональности? Тогда опять придется править по всей иерархии.
А если надо подкорректировать кор-функциональнальность, без изменения апи и общей функциональности? Тоже самое.
Виртуальные функции же могут быть еще и перегружены. Тогда очень легко сделать ошибку и скрыть некоторые из перегрузок во время переопределения. Тогда будут вызываться методы базового класса, хотя вы ожидаете другого поведения.
Все это следствия одной проблемы: наследование - пожалуй самая сильная форма связывания классов между собой. Когда метрика связывания высокая, то в приложение очень сложно вносить изменения. В этом корень.
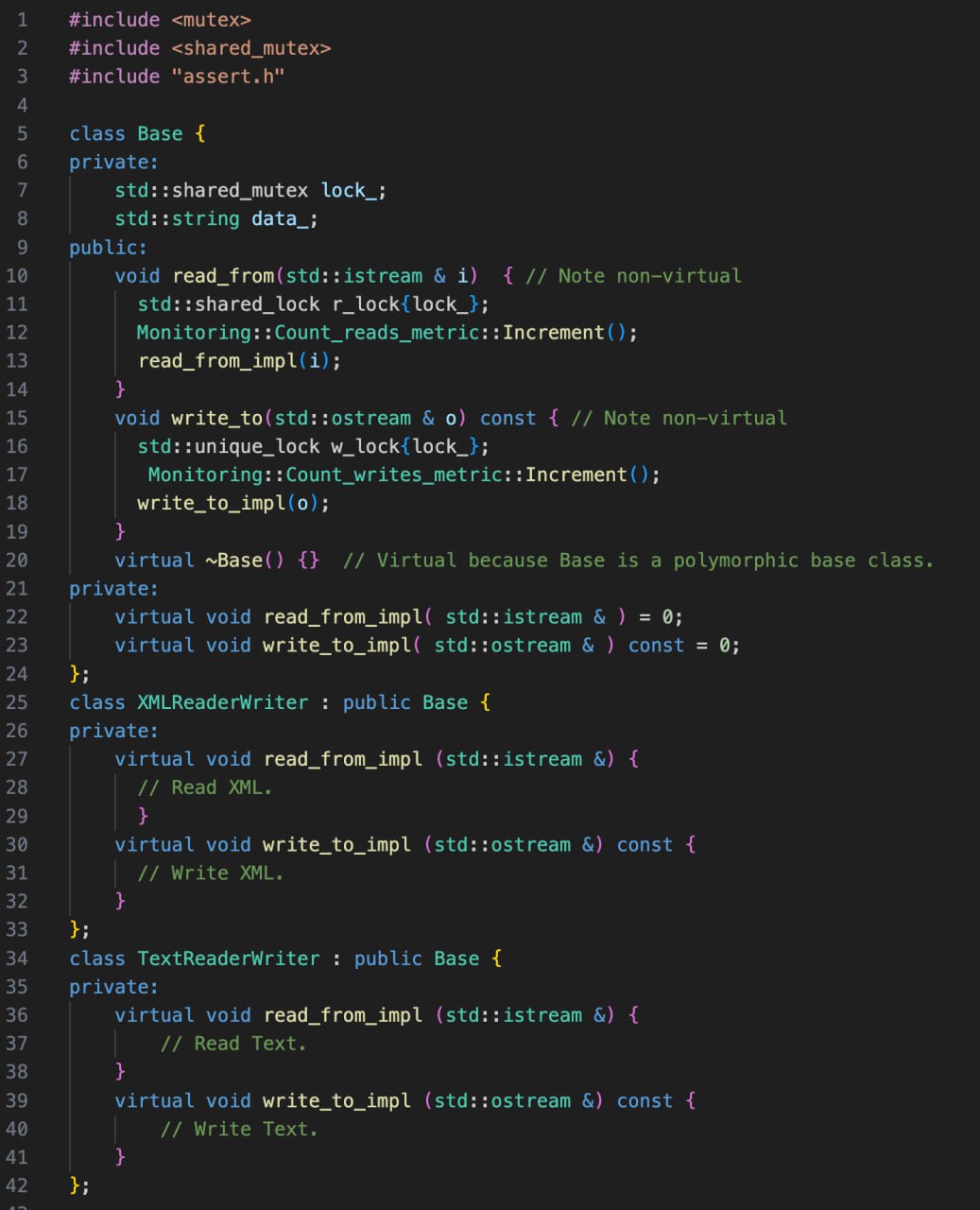
Но есть один способ, который поможет несколько смягчить проблему - введение еще одного уровня индирекции. А точнее - перенаправление кор-функциональности из публичных невиртуальных методов базового класса в непубличные виртуальные. Тем самым вы четко разделяете пользовательский интерфейс и реализацию. Это и увеличивает инкапсуляцию, потому что кор-интерфейс может даже иметь сигнатуру, отличную от того, что выдается наружу. Вы скрываете от пользователя информацию, которую ему потенциально не нужно знать. Ну мы здесь все понимаем, какие преимущества дает инкапсуляция, что уж я буду распинаться.
Можно вынести всю общую функциональность в метод базового класса, а наследнико-специфичиные задачи решать с помощью внутреннего виртуального интерфейса. Можно вносить изменения и в общую, и в кор функциональности, не затрагивая при этом друг друга. Одно изменение дизайна, а сколько радостей оно приносит!
Следование идиоме действительно дает гибкость в проектировании классов и интерфейсов. Однако эта гибкость идет вместе с ответственностью за возросшую сложность системы. Теперь вам нужно поддерживать 2 интерфейса: внутренний и внешний. Если не очень аккуратно проектировать базовый класс, то не так уж и сложно нарваться на проблемы.
Так что
Stay well-designed. Stay cool.
#design #goodpractice
В публикации под названием "C++ Coding Standards: 101 Rules, Guidelines, and Best Practices" есть такая строчка: Consider making virtual functions nonpublic, and public functions nonvirtual. По-русски - рассмотрите возможности сделать виртуальные функции непубличными, а публичные функции - невиртуальными. Для кого-то сейчас это предложение звучит, как минимум, странно. "Я ж всегда определял полиморфный интерфейс классов публичным. И зачем вообще делать виртуальные методы непубличными? " Уверяю вас, что эту строчку написали вполне уважаемые в международном коммьюнити люди - Андрей Александреску и Герб Саттер. Фигню они вряд ли скажут, поэтому сейчас постараюсь объяснить, какие идеи лежат за этими словами.
Иногда хорошие практики организации кода оформляют в виде идиом. И для выражения выше появилась такая идиома(хотя не знаю, что появилось раньше:
Мотивация
Представьте себе какую-нибудь обычную иерархию классов. Очень часто полиморфные методы классов в ней выполняют какую-то общую работу. Это может быть обработка ошибок, логирование, сбор мониторингов, вызов какого-то общего метода, захват общего мьютекса, вы работаете с данными на низком уровне, а потом запаковываете в одинаковый формат и выдаете наружу и тд. Перечислять можно реально долго. Я бы даже так сказал: полифорфные методы с развитием проекта практически обречены обретать общую функциональность. То есть даже если ее не было, она с большой вероятностью появится. К чему это будет приводить? Желание изменить один аспект поведения объектов приводит к изменению кода по всей иерархии классов. Это увеличивает сложность внедрения новой или обслуживающей функциональности. А там еще и копипаст ошибки могут подьехать. Можно забыть в каком-то наследнике добавить то, что нужно. В общем беда.
А если нужно подкорректировать API без особого изменения кор-функциональности? Тогда опять придется править по всей иерархии.
А если надо подкорректировать кор-функциональнальность, без изменения апи и общей функциональности? Тоже самое.
Виртуальные функции же могут быть еще и перегружены. Тогда очень легко сделать ошибку и скрыть некоторые из перегрузок во время переопределения. Тогда будут вызываться методы базового класса, хотя вы ожидаете другого поведения.
Все это следствия одной проблемы: наследование - пожалуй самая сильная форма связывания классов между собой. Когда метрика связывания высокая, то в приложение очень сложно вносить изменения. В этом корень.
Но есть один способ, который поможет несколько смягчить проблему - введение еще одного уровня индирекции. А точнее - перенаправление кор-функциональности из публичных невиртуальных методов базового класса в непубличные виртуальные. Тем самым вы четко разделяете пользовательский интерфейс и реализацию. Это и увеличивает инкапсуляцию, потому что кор-интерфейс может даже иметь сигнатуру, отличную от того, что выдается наружу. Вы скрываете от пользователя информацию, которую ему потенциально не нужно знать. Ну мы здесь все понимаем, какие преимущества дает инкапсуляция, что уж я буду распинаться.
Можно вынести всю общую функциональность в метод базового класса, а наследнико-специфичиные задачи решать с помощью внутреннего виртуального интерфейса. Можно вносить изменения и в общую, и в кор функциональности, не затрагивая при этом друг друга. Одно изменение дизайна, а сколько радостей оно приносит!
Следование идиоме действительно дает гибкость в проектировании классов и интерфейсов. Однако эта гибкость идет вместе с ответственностью за возросшую сложность системы. Теперь вам нужно поддерживать 2 интерфейса: внутренний и внешний. Если не очень аккуратно проектировать базовый класс, то не так уж и сложно нарваться на проблемы.
Так что
Stay well-designed. Stay cool.
#design #goodpractice
{kind=link}
Application Binary Interface
Вчера разобрали, что обратная совместимость ABI играет значительную роль при разработке shared библиотек. Но это только применение этого понятие, сам термин мы еще не разбирали. Сегодня исправим этот момент.
ABI - набор правил, которые определяют соглашения о вызовах и расположение структур(стека, ваших кастомных и тд) в памяти. Соглашение о вызовах, наверное, здесь центровую роль играет. В общих словах, это какие операции нужно делать, чтобы выполнить функцию. Компьютер на самом деле не знает, что такое "выполнить функцию". Он знает лишь небольшой набор команд. Типа сложить, переместить, прыгнуть. То, как передаются аргументы для функции - через стек или через регистры, в каком порядке передаются аргументы, как очищать регистры, куда сохранять возвращаемое значение, и определяет calling convention. Но это что-то низкоуровневое, нам бы поближе к коду.
Сравним с API. Если API говорит, что вот есть такой-то набор функций и вы можете их использовать. То ABI говорит, как вы должны этими функциями пользоваться. Ну не вы, а скомпилированный код. Можно представить себе, что все детали того, что нужно сделать процессору, чтобы выполнить ваш код - это и есть ABI. То есть, как API, только на уровень ниже.
Что может изменить ABI? Очень много вещей. Именно поэтому имплементацию выносят в отдельный класс. Всего одна перестановка полей класса местами ломает низкоуровневое представление о том, как работать с вашим кодом. Потому что для доступа к определенному полю нужен определенный сдвиг от начала данных объекта. При перестановке эти сдвиги меняются и использование вашего кода без перекомпиляции будет вести к неправильной работе приложения.
Приведу некоторые изменения в коде, которые могут аффектить ABI.
👉🏿 Добавление, удаление и изменение порядка полей класса.
👉🏿 Изменение иерархии классов. Данные всех базовых классов лежат в определенном порядке, изменение иерархии влечет изменения в том, как данные объекта располагаются в памяти.
👉🏿 Изменение шаблонных аргументов в шаблонных классах. Это влияет на то, какое mangled имя будет у класса, и соответсвенно, то как к нему обращаться.
👉🏿 Объявление функции как inline. Компилятор может встроить такую функцию и ее имени просто больше не будет в списке доступных функций.
👉🏿 Изменение сигнатуры функций, включая cv-квалификаторы. Тоже по причине манглинга.
👉🏿 Добавление первого виртуального метода. Обычно внутри объекта появляется vptr, это ведет к изменению расположения объекта в памяти.
👉🏿 Изменение порядка объявления виртуальных методов. В таблице виртуальных функций они располагаются по порядку и вызываются по порядку. Изменив порядок можно вызвать не тот метод.
👉🏿 Изменение набора приватных методов. Ну а здесь-то што?! Клиент же их даже вызвать не может? Дело в том, что приватные методы участвуют в разрешении перегрузок, поэтому клиентский код в каком-то смысле имеет к ним доступ и знает об этом наборе методов. Его изменение в коде не перезаписывает знание клиента о нем, поэтому низя так делать.
👉🏿 И еще куча приколюх с наследованием.
Деталей очень много и списочек там реально очень большой. Я привел только самую верхушку, которую все понимают.
И вот при стандартном подходе с header/implementation любое изменение из этого списка влечет за собой перекомпиляцию всего кода, использующего ваш класс. А это как бы пипец. Почти любая реальная промышленная плюсовая задача требует таких изменений.
При использовании pimpl мы избегаем такого исхода. Указатель - он и в Африке указатель. На заданной платформе имеет один и тот же размер. И пока вы не делаете этих "опасных" изменений в публичном классе, его структура никак не изменяется. А обычно таких изменений не делают, потому что там оставляют только базовый API, который очень стабилен.
Вот такие пироги. Надеюсь, этот пост прояснил некоторые вопросы, которые могли вчера у вас возникнуть.
Stay compatible. Stay cool.
#design #hardcore #cppcore
Вчера разобрали, что обратная совместимость ABI играет значительную роль при разработке shared библиотек. Но это только применение этого понятие, сам термин мы еще не разбирали. Сегодня исправим этот момент.
ABI - набор правил, которые определяют соглашения о вызовах и расположение структур(стека, ваших кастомных и тд) в памяти. Соглашение о вызовах, наверное, здесь центровую роль играет. В общих словах, это какие операции нужно делать, чтобы выполнить функцию. Компьютер на самом деле не знает, что такое "выполнить функцию". Он знает лишь небольшой набор команд. Типа сложить, переместить, прыгнуть. То, как передаются аргументы для функции - через стек или через регистры, в каком порядке передаются аргументы, как очищать регистры, куда сохранять возвращаемое значение, и определяет calling convention. Но это что-то низкоуровневое, нам бы поближе к коду.
Сравним с API. Если API говорит, что вот есть такой-то набор функций и вы можете их использовать. То ABI говорит, как вы должны этими функциями пользоваться. Ну не вы, а скомпилированный код. Можно представить себе, что все детали того, что нужно сделать процессору, чтобы выполнить ваш код - это и есть ABI. То есть, как API, только на уровень ниже.
Что может изменить ABI? Очень много вещей. Именно поэтому имплементацию выносят в отдельный класс. Всего одна перестановка полей класса местами ломает низкоуровневое представление о том, как работать с вашим кодом. Потому что для доступа к определенному полю нужен определенный сдвиг от начала данных объекта. При перестановке эти сдвиги меняются и использование вашего кода без перекомпиляции будет вести к неправильной работе приложения.
Приведу некоторые изменения в коде, которые могут аффектить ABI.
👉🏿 Добавление, удаление и изменение порядка полей класса.
👉🏿 Изменение иерархии классов. Данные всех базовых классов лежат в определенном порядке, изменение иерархии влечет изменения в том, как данные объекта располагаются в памяти.
👉🏿 Изменение шаблонных аргументов в шаблонных классах. Это влияет на то, какое mangled имя будет у класса, и соответсвенно, то как к нему обращаться.
👉🏿 Объявление функции как inline. Компилятор может встроить такую функцию и ее имени просто больше не будет в списке доступных функций.
👉🏿 Изменение сигнатуры функций, включая cv-квалификаторы. Тоже по причине манглинга.
👉🏿 Добавление первого виртуального метода. Обычно внутри объекта появляется vptr, это ведет к изменению расположения объекта в памяти.
👉🏿 Изменение порядка объявления виртуальных методов. В таблице виртуальных функций они располагаются по порядку и вызываются по порядку. Изменив порядок можно вызвать не тот метод.
👉🏿 Изменение набора приватных методов. Ну а здесь-то што?! Клиент же их даже вызвать не может? Дело в том, что приватные методы участвуют в разрешении перегрузок, поэтому клиентский код в каком-то смысле имеет к ним доступ и знает об этом наборе методов. Его изменение в коде не перезаписывает знание клиента о нем, поэтому низя так делать.
👉🏿 И еще куча приколюх с наследованием.
Деталей очень много и списочек там реально очень большой. Я привел только самую верхушку, которую все понимают.
И вот при стандартном подходе с header/implementation любое изменение из этого списка влечет за собой перекомпиляцию всего кода, использующего ваш класс. А это как бы пипец. Почти любая реальная промышленная плюсовая задача требует таких изменений.
При использовании pimpl мы избегаем такого исхода. Указатель - он и в Африке указатель. На заданной платформе имеет один и тот же размер. И пока вы не делаете этих "опасных" изменений в публичном классе, его структура никак не изменяется. А обычно таких изменений не делают, потому что там оставляют только базовый API, который очень стабилен.
Вот такие пироги. Надеюсь, этот пост прояснил некоторые вопросы, которые могли вчера у вас возникнуть.
Stay compatible. Stay cool.
#design #hardcore #cppcore
{kind=link}
Что не нарушает ABI класса?
В комментах к предыдущему посту @MayerArtur удачно ванганул тему поста, который я писал в момент публикации его коммента. Поэтому этот пост обязан был выйти сегодня 😁. Вчера мы поговорили о том, что делать нельзя, если мы хотим сохранить стабильный ABI. Сегодня коротко пройдемся по тому, что делать можно. Завершим, так сказать, тему с ABI, чтобы картинка полная у вас была. Тут будет все в перемешку: и для хедеров, и для файлов реализации. Поехали:
✅ Изменять реализацию метода. Довольно очевидно. Если не трогать сигнатуру, то внутри можно хоть хороводы водить с гусями, ничего для внешнего наблюдателя не изменится.
✅ Добавлять новые публичные невиртуальные методы. Это новая функциональность, которая никак не мешает находить и пользоваться старой.
✅ Добавлять новые конструкторы. Same thing. Ничто не помешает создать объект старым способом.
✅ Добавлять новые енамы в класс.
✅ Добавлять новые поля в существующие енамы. Сишные енамы - это всего лишь красивенькие цифры, памяти они не занимают и компилятор их встраивает в код в виде обычных чисел.
✅ Добавление новых статических полей и изменение их порядка. Дело в том, что статические поля аллоцируются в области глобальных данных и никак не влияют на репрезентацию объекта в памяти.
✅ Добавлять новые классы и функции в файл. Obviously.
✅ Изменять параметр по умолчанию. Это тоже ничего не меняет, можно пользоваться как и прежде, но перекомпиляция нужна, чтобы новый параметр встал на место старого.
🥴 Чет есть какая-то инфа по поводу того, что удаление приватных невиртуальных методов может не сломать ABI, если они не вызываются и никогда не вызывались никакими инлайн мембер-функциями. Но учитывая, что в стандарте написано, что любые изменения в приватных полях и методах ведут к перекомпиляции, а также, что компилятор может встраивать методы без вашего на то разрешения, я бы это не брал в расчет.
Как-то так. Не густо. Но и не пусто.
На этом, думаю, тему завершаем на какое-то время разговор про бинарный интерфейс. Верхнеуровнево затронули самые важные моменты. Возможно в будущем будем возвращаться к отдельным деталям и прорабатывать их.
Stay compatible. Stay cool.
#design #hardcore #cppcore
В комментах к предыдущему посту @MayerArtur удачно ванганул тему поста, который я писал в момент публикации его коммента. Поэтому этот пост обязан был выйти сегодня 😁. Вчера мы поговорили о том, что делать нельзя, если мы хотим сохранить стабильный ABI. Сегодня коротко пройдемся по тому, что делать можно. Завершим, так сказать, тему с ABI, чтобы картинка полная у вас была. Тут будет все в перемешку: и для хедеров, и для файлов реализации. Поехали:
✅ Изменять реализацию метода. Довольно очевидно. Если не трогать сигнатуру, то внутри можно хоть хороводы водить с гусями, ничего для внешнего наблюдателя не изменится.
✅ Добавлять новые публичные невиртуальные методы. Это новая функциональность, которая никак не мешает находить и пользоваться старой.
✅ Добавлять новые конструкторы. Same thing. Ничто не помешает создать объект старым способом.
✅ Добавлять новые енамы в класс.
✅ Добавлять новые поля в существующие енамы. Сишные енамы - это всего лишь красивенькие цифры, памяти они не занимают и компилятор их встраивает в код в виде обычных чисел.
✅ Добавление новых статических полей и изменение их порядка. Дело в том, что статические поля аллоцируются в области глобальных данных и никак не влияют на репрезентацию объекта в памяти.
✅ Добавлять новые классы и функции в файл. Obviously.
✅ Изменять параметр по умолчанию. Это тоже ничего не меняет, можно пользоваться как и прежде, но перекомпиляция нужна, чтобы новый параметр встал на место старого.
🥴 Чет есть какая-то инфа по поводу того, что удаление приватных невиртуальных методов может не сломать ABI, если они не вызываются и никогда не вызывались никакими инлайн мембер-функциями. Но учитывая, что в стандарте написано, что любые изменения в приватных полях и методах ведут к перекомпиляции, а также, что компилятор может встраивать методы без вашего на то разрешения, я бы это не брал в расчет.
Как-то так. Не густо. Но и не пусто.
На этом, думаю, тему завершаем на какое-то время разговор про бинарный интерфейс. Верхнеуровнево затронули самые важные моменты. Возможно в будущем будем возвращаться к отдельным деталям и прорабатывать их.
Stay compatible. Stay cool.
#design #hardcore #cppcore
{kind=link}