
Код ревью Ч4
Продолжаем тему код-ревью.
Конечно, найти все ошибки самостоятельно нельзя. Это следует из закона, который я упомянул в одном из предыдущих постов. Но можно поспособствовать себе в этом! В основном, большая часть ошибок допускается по невнимательности или неосознанности принятых решений. Мне помогают следующие рекомендации:
1. Отдыхать после работы.
Без комментариев.
2. Не публиковать код вечером.
Не думаю, что вашим коллегам будет принципиально важно увидеть код как можно скорее - вечером или утром следующего дня. А вот вам этот перерыв поможет перевести дух и взглянуть на решение свежим взглядом. Я так неоднократно находил у себя разные мелочи.
3. Спрашивайте себя почему и зачем?
Почаще спрашивайте себя, зачем вы приняли такой решение тут? Почему это работает так там? И не забывайте отвечать на эти вопросы :) Это просто влияет на вашу осознанность и погруженность в код.
3. Представить себя на месте коллег
Бывало ли у вас такое, что вы идете по очень знакомой улице, но вспоминаете свои ощущения и впечатления, как это было впервые? Попробуйте погрузиться в это ментальное состояние и попробовать посмотреть на свой код чужими глазами, абстрагировавшись от контекста. Это то, что увидят ваши коллеги. Поймут ли они то, что задумали вы?
4. Как бы сказал ваш авторитет?
Да, можно представить себя на месте вашего авторитета и подумать, что бы он сказал по поводу того или иного решения?
Надеюсь, что и для вас эти рекомендации будут полезны! 😉
#commercial #goodpractice
Продолжаем тему код-ревью.
Конечно, найти все ошибки самостоятельно нельзя. Это следует из закона, который я упомянул в одном из предыдущих постов. Но можно поспособствовать себе в этом! В основном, большая часть ошибок допускается по невнимательности или неосознанности принятых решений. Мне помогают следующие рекомендации:
1. Отдыхать после работы.
Без комментариев.
2. Не публиковать код вечером.
Не думаю, что вашим коллегам будет принципиально важно увидеть код как можно скорее - вечером или утром следующего дня. А вот вам этот перерыв поможет перевести дух и взглянуть на решение свежим взглядом. Я так неоднократно находил у себя разные мелочи.
3. Спрашивайте себя почему и зачем?
Почаще спрашивайте себя, зачем вы приняли такой решение тут? Почему это работает так там? И не забывайте отвечать на эти вопросы :) Это просто влияет на вашу осознанность и погруженность в код.
3. Представить себя на месте коллег
Бывало ли у вас такое, что вы идете по очень знакомой улице, но вспоминаете свои ощущения и впечатления, как это было впервые? Попробуйте погрузиться в это ментальное состояние и попробовать посмотреть на свой код чужими глазами, абстрагировавшись от контекста. Это то, что увидят ваши коллеги. Поймут ли они то, что задумали вы?
4. Как бы сказал ваш авторитет?
Да, можно представить себя на месте вашего авторитета и подумать, что бы он сказал по поводу того или иного решения?
Надеюсь, что и для вас эти рекомендации будут полезны! 😉
#commercial #goodpractice
{kind=link}
Как правильно запретить объекту копироваться
Бывают такие ситуации, когда объект владеет каким-то ресурсом единолично, то есть имеет над ним так называемый ownership. В этом случае время жизни и использования ресурса совпадает с временем жизни объекта, а использование этого же самого ресурса другим объектом будет приносить странные side effect’ы. Например у нас есть класс, который содержит файл в качестве поля и который открывает этот файл в конструкторе и закрывает в деструкторе. Что должно происходить при копировании объекта этого класса? Должен ли файл ещё раз открываться или в начале в копируемом объекте закрываться, а потом открываться в скопированном? Все варианты выглядят выстрелом в хлебало, поэтому логично запретить таким объектам копироваться.
Как это сделать? Самое широкоиспользуемое решение - объявить конструктор копирования и оператор присваивания приватными и жить счастливо. Никто снаружи класса не сможет получить доступ к этим специальным методам, а при попытке будет ошибка компиляции. Но это только снаружи класса. Внутри класса-то можно использовать приватные поля и методы. И тут уже огромный простор для ошибок, в зависимости от того, как вы определили специальные методы.
Такой код
class NonCopyable {
private:
NonCopyable( const NonCopyable& ) {}
void NonCopyable::operator=( const NonCopyable& ) {}
};
void NonCopyable::SomeOtherMehod() {
callSomething( *this );
}
Приведёт к вызову копирующего конструктора и копированию всех полей, что ведёт к неопределенному поведению.
Но С++11 подарил нам прекрасную фича - можно пометить любую функцию как = delete и компилятор просто не будет генерировать код для неё. Поэтому такие функции физически не могут быть вызваны. Пометив наши методы удаленными, мы уберём возможность любой сущности их вызывать и сильно обезопасим код.
К тому же, использование этой фичи повышает читаемость кода. А так как пометить удаленной можно любую функцию, то можно удалить ненужную перегрузку или запретить вызывать функцию с ошибочным приведением параметров.
Modern C++ - сила.
Stay cool.
#cppcore #cpp11 #goodpractice
Бывают такие ситуации, когда объект владеет каким-то ресурсом единолично, то есть имеет над ним так называемый ownership. В этом случае время жизни и использования ресурса совпадает с временем жизни объекта, а использование этого же самого ресурса другим объектом будет приносить странные side effect’ы. Например у нас есть класс, который содержит файл в качестве поля и который открывает этот файл в конструкторе и закрывает в деструкторе. Что должно происходить при копировании объекта этого класса? Должен ли файл ещё раз открываться или в начале в копируемом объекте закрываться, а потом открываться в скопированном? Все варианты выглядят выстрелом в хлебало, поэтому логично запретить таким объектам копироваться.
Как это сделать? Самое широкоиспользуемое решение - объявить конструктор копирования и оператор присваивания приватными и жить счастливо. Никто снаружи класса не сможет получить доступ к этим специальным методам, а при попытке будет ошибка компиляции. Но это только снаружи класса. Внутри класса-то можно использовать приватные поля и методы. И тут уже огромный простор для ошибок, в зависимости от того, как вы определили специальные методы.
Такой код
class NonCopyable {
private:
NonCopyable( const NonCopyable& ) {}
void NonCopyable::operator=( const NonCopyable& ) {}
};
void NonCopyable::SomeOtherMehod() {
callSomething( *this );
}
Приведёт к вызову копирующего конструктора и копированию всех полей, что ведёт к неопределенному поведению.
Но С++11 подарил нам прекрасную фича - можно пометить любую функцию как = delete и компилятор просто не будет генерировать код для неё. Поэтому такие функции физически не могут быть вызваны. Пометив наши методы удаленными, мы уберём возможность любой сущности их вызывать и сильно обезопасим код.
К тому же, использование этой фичи повышает читаемость кода. А так как пометить удаленной можно любую функцию, то можно удалить ненужную перегрузку или запретить вызывать функцию с ошибочным приведением параметров.
Modern C++ - сила.
Stay cool.
#cppcore #cpp11 #goodpractice
{kind=link}
Дублирование - зло. Ч1
Обычно, когда затрагивают тему злостности дублирования кода, вспоминают принцип DRY - акроним Don't Repeat Yourself, т.е. не повторяй себя. Это хорошо известный с давних времен и проверенный временем принцип, о котором вы обязательно должны знать.
Почему же дублирование кода вызывает проблемы? В основном, причина заключается в том, что это сильно увеличивает сложность и непредсказуемость ваших программ в будущем:
1. Распространение ошибок. Ошибки в исходном фрагменте кода будут копироваться и распространяться по проекту.
2. Поиск клонов. При внесении изменений в продублированную область приходится помнить где и что было скопировано ранее, чтобы туда тоже внести еще изменения.
3. Мелкие различия в клонах. Нередко так же приходится помнить, чем же дублированный код отличается друг от друга, чтобы вносить корректные изменения. Значит, придется перечитывать этот код везде, где он появился...
4. Проблема тестирования. Нередко теряется работоспособность скопированных участков кода в другом контексте. Например, переменные с одинаковым именем могут иметь разные типы данных там, куда вы скопировали код.
Если вы разрабатываете проект один, вы, допустим, сможете это все запомнить, но если приходит новый сотрудник - эти знания приходится передавать ему. Чем больше таких нюансов, тем сильнее растет этот снежный ком. А вот как дело пойдет дальше - неизвестно, вдруг коллега не все запомнит или что-то забудет? Вообще говоря, это неизбежно рано или поздно произойдет. Я предпочитаю думать сразу, что если что-то неизбежно, то можно считать, что это уже произошло. Значит действовать нужно уже сейчас!
Короче, вы создаете себе армию клонов, которая потом начинает атаковать вас. На самом деле, вам просто не хватает человеческих возможностей, чтобы обслуживать все клоны. Миритесь с этим 🙃
Давайте подумаем, что изменится, если отказаться от дублирования?
- Во первых, увеличится предсказуемость кода. Если я знаю, что дублирования нет, значит мне нужно найти единственный кусок кода / файл. Пока я его не найду, я буду уверен, что его нужно продолжать искать.
- Во вторых, увеличится реактивность при внесении изменений. Если я знаю, что дублирования нет, значит мне достаточно внести изменение в единственный кусок кода / файл. Этого достаточно, чтобы изменить все вышестоящие модели, которые от него зависят.
Конечно же, придерживаться 100% этого принципа, невозможно и даже не всегда нужно. Поговорим об этих нюансах в следующих статьях.
Кстати, зацените комментарии к постам! Жду вопросов 👇
#goodpractice #design
Обычно, когда затрагивают тему злостности дублирования кода, вспоминают принцип DRY - акроним Don't Repeat Yourself, т.е. не повторяй себя. Это хорошо известный с давних времен и проверенный временем принцип, о котором вы обязательно должны знать.
Почему же дублирование кода вызывает проблемы? В основном, причина заключается в том, что это сильно увеличивает сложность и непредсказуемость ваших программ в будущем:
1. Распространение ошибок. Ошибки в исходном фрагменте кода будут копироваться и распространяться по проекту.
2. Поиск клонов. При внесении изменений в продублированную область приходится помнить где и что было скопировано ранее, чтобы туда тоже внести еще изменения.
3. Мелкие различия в клонах. Нередко так же приходится помнить, чем же дублированный код отличается друг от друга, чтобы вносить корректные изменения. Значит, придется перечитывать этот код везде, где он появился...
4. Проблема тестирования. Нередко теряется работоспособность скопированных участков кода в другом контексте. Например, переменные с одинаковым именем могут иметь разные типы данных там, куда вы скопировали код.
Если вы разрабатываете проект один, вы, допустим, сможете это все запомнить, но если приходит новый сотрудник - эти знания приходится передавать ему. Чем больше таких нюансов, тем сильнее растет этот снежный ком. А вот как дело пойдет дальше - неизвестно, вдруг коллега не все запомнит или что-то забудет? Вообще говоря, это неизбежно рано или поздно произойдет. Я предпочитаю думать сразу, что если что-то неизбежно, то можно считать, что это уже произошло. Значит действовать нужно уже сейчас!
Короче, вы создаете себе армию клонов, которая потом начинает атаковать вас. На самом деле, вам просто не хватает человеческих возможностей, чтобы обслуживать все клоны. Миритесь с этим 🙃
Давайте подумаем, что изменится, если отказаться от дублирования?
- Во первых, увеличится предсказуемость кода. Если я знаю, что дублирования нет, значит мне нужно найти единственный кусок кода / файл. Пока я его не найду, я буду уверен, что его нужно продолжать искать.
- Во вторых, увеличится реактивность при внесении изменений. Если я знаю, что дублирования нет, значит мне достаточно внести изменение в единственный кусок кода / файл. Этого достаточно, чтобы изменить все вышестоящие модели, которые от него зависят.
Конечно же, придерживаться 100% этого принципа, невозможно и даже не всегда нужно. Поговорим об этих нюансах в следующих статьях.
Кстати, зацените комментарии к постам! Жду вопросов 👇
#goodpractice #design
{kind=link}
Дублирование - зло. Ч2
В предыдущей части я успел сказать, что проблема дублирования кода не настолько однозначна, как может показаться. Главная цель, которая преследуется при удалении клонов - это упростить разработку и сделать код понятнее.
Самый простой код - не всегда самый короткий. При написании и рефакторинге кода обобщению подлежат только осмысленные части кода. Это подразумевает выделение только значимых и повторяющихся элементов и изоляцию их в отдельные функции, классы или модули. Суть заключается в разделении обязанностей и зон ответственностей. Универсальные вещи, как правило, сложно устроены, и поэтому неповоротливы для изменений. Более того, с развитием проекта, где-то обязательно придется вносить корректировки. То есть еще больше наращивать сложность... Куда проще понять и поменять композицию простых действий.
По своей сути, клонирование, говорит о не очень качественном коде. Однако, я бы не хотел, чтобы у наших подписчиков появилась навязчивая мысль всюду искать клоны и избавляться от них. Напоминаю, цель в другом 😅 Истинная причина возникновения дублей может заключаться в плохом интерфейсе, в неудачной архитектуре или наборе библиотек. Соответственно, это может подтолкнуть к совершенно другим стратегическим действиям разработчиков.
Еще одной проблемой на пути к искоренению дублирования в существующем проекте может быть развесистая кодовая база. Вносить изменения в уже написанный код, потенциально, чревато не только затратами времени, но и появлением новых или возрождением старых багов. Воскресшие запросы, наверно, больше всего огорчают. Всегда стоит взвешивать количество принесенной пользы и потенциальные риски переделок.
Если уж все таки было принято решение избавляться от клонов, то следует в первую очередь попробовать использовать возможности среды разработки / задействовать сторонние инструменты. Например, посмотрите на SonarQube и плагин для IDEA, Eclipse, Visual Studio, Visual Studio Code и Atom — SonarLint. Дело даже не в том, что это рутинная работа, которая может быть автоматизирована. Программный поиск даст возможность быстро провести разведку и легко оценить ситуацию в вашем проекте. Это сильно ускорит анализ, сократит рутину и снизит риски найти на поздних этапах какой-то исключительный клон, меняющий правила обобщения кода.
Надеюсь, что мне удалось убедить вас в злостности и неоднозначности проблемы дублирования 😉 Эта статья мне пригодится для следующих постов, так что если остались вопросы - пишите комменты!
#design #goodpractice #tools
В предыдущей части я успел сказать, что проблема дублирования кода не настолько однозначна, как может показаться. Главная цель, которая преследуется при удалении клонов - это упростить разработку и сделать код понятнее.
Самый простой код - не всегда самый короткий. При написании и рефакторинге кода обобщению подлежат только осмысленные части кода. Это подразумевает выделение только значимых и повторяющихся элементов и изоляцию их в отдельные функции, классы или модули. Суть заключается в разделении обязанностей и зон ответственностей. Универсальные вещи, как правило, сложно устроены, и поэтому неповоротливы для изменений. Более того, с развитием проекта, где-то обязательно придется вносить корректировки. То есть еще больше наращивать сложность... Куда проще понять и поменять композицию простых действий.
По своей сути, клонирование, говорит о не очень качественном коде. Однако, я бы не хотел, чтобы у наших подписчиков появилась навязчивая мысль всюду искать клоны и избавляться от них. Напоминаю, цель в другом 😅 Истинная причина возникновения дублей может заключаться в плохом интерфейсе, в неудачной архитектуре или наборе библиотек. Соответственно, это может подтолкнуть к совершенно другим стратегическим действиям разработчиков.
Еще одной проблемой на пути к искоренению дублирования в существующем проекте может быть развесистая кодовая база. Вносить изменения в уже написанный код, потенциально, чревато не только затратами времени, но и появлением новых или возрождением старых багов. Воскресшие запросы, наверно, больше всего огорчают. Всегда стоит взвешивать количество принесенной пользы и потенциальные риски переделок.
Если уж все таки было принято решение избавляться от клонов, то следует в первую очередь попробовать использовать возможности среды разработки / задействовать сторонние инструменты. Например, посмотрите на SonarQube и плагин для IDEA, Eclipse, Visual Studio, Visual Studio Code и Atom — SonarLint. Дело даже не в том, что это рутинная работа, которая может быть автоматизирована. Программный поиск даст возможность быстро провести разведку и легко оценить ситуацию в вашем проекте. Это сильно ускорит анализ, сократит рутину и снизит риски найти на поздних этапах какой-то исключительный клон, меняющий правила обобщения кода.
Надеюсь, что мне удалось убедить вас в злостности и неоднозначности проблемы дублирования 😉 Эта статья мне пригодится для следующих постов, так что если остались вопросы - пишите комменты!
#design #goodpractice #tools
{kind=link}
Экспресс совет
Когда реализуете сущность типа фабричного метода, скорее всего вы выделяете объект в куче и возвращаете его в каком-то виде. В сишном стиле это raw pointer. Для плюсовиков это уже считается зашкваром, поэтому все возвращают умный указатель. Но какой умный указатель возвратить?
Если вы не используете кэширование для возвращаемых объектов, то лучший выбор - std::unique_ptr. Причина проста, как мир - у шареного указателя есть конструктор от уникального, а у уникального нет от шареного. Права и ограничения вполне понятны, а значит в случае, если вам нужен будет шареный указатель - просто скастуете уникальный к нему. В остальных случая используйте как есть.
При кэшировании в любом случае придётся использовать std::shared_ptr, ибо вторую ссылку где-то надо хранить, так что выбора особо нет.
The end. Stay cool.
#goodpractice #STL #design
Когда реализуете сущность типа фабричного метода, скорее всего вы выделяете объект в куче и возвращаете его в каком-то виде. В сишном стиле это raw pointer. Для плюсовиков это уже считается зашкваром, поэтому все возвращают умный указатель. Но какой умный указатель возвратить?
Если вы не используете кэширование для возвращаемых объектов, то лучший выбор - std::unique_ptr. Причина проста, как мир - у шареного указателя есть конструктор от уникального, а у уникального нет от шареного. Права и ограничения вполне понятны, а значит в случае, если вам нужен будет шареный указатель - просто скастуете уникальный к нему. В остальных случая используйте как есть.
При кэшировании в любом случае придётся использовать std::shared_ptr, ибо вторую ссылку где-то надо хранить, так что выбора особо нет.
The end. Stay cool.
#goodpractice #STL #design
Когда использовать Nodiscard?
Вот тут мы обсудили мотив защиты своих сущностей от опасного использования, в том числе и защиту от неиспользования возвращаемого значения функции с помощью атрибута nodiscard. Тот разговор был довольно общим и не затрагивал особой конкретики. Теперь же поговорим о том, в каких ситуациях стоит использовать этот атрибут, чтобы вынести из этого реальную пользу.
💥 Функция возвращает код ошибки. Стандартная тема в принципе. Очень много кода написано в стиле: функция использует in/out параметры и возвращает статус(ошибка или нет). Не важно, в каком виде статус: булавок значение, числовое или enum. В этом случае возникает потенциальная проблема, когда программист не обработает статус выполнения операции и программа может продолжить выполняться совсем не так, как предполагалось изначально.
💥 Ваша функция - фабрика. Кажется, что таких ситуаций случалось примерно никогда, НО! Чисто семантически, предполагается, что возвращаемое значение будет использоваться. Поэтому в целом, не лишним будет усилить эту семантику. Ну знаете. На всякий случай. Вдруг какой-то кодер скопипастил название фабрики с аргументами, захотел кекать, вернулся облегчённым и на радостях забыл использовать созданный объект. Во время компиляции это выясниться и этот кодер уйдёт в глубокий тильт от своей тупости. Давайте заботиться о невнимательных коллегах и не подвергать их ментальное здоровье риску.
💥 Когда функция возвращает тяжеловесный тип. Не за тем я конструировал сложный, тяжелый тип или контейнер объектов, которые потом не будут использованы. Обычно это делается все-таки, чтобы потом как-то использовать эту сущность. Поэтому опять же, на всякий случай, можно эту функцию пометить атрибутом.
💥 Везде? Был какой-то пропоузал в стандарт, чтобы весь новый код стандартной библиотеки помечался этим атрибутом. Это аргументировалось тем, что не зря функция что-то возвращает, и если это можно не использовать, зачем тогда проектировать такой интерфейс. А также тем, что пропуск возвращаемого значения в подавляющем большинстве случаев приводит к проблемам.
Думаю, что везде его пихать не надо, как это делать евреи со своими носами, но определенно использование nodiscard усилит безопасность вашего кода и первые три кейса - достаточно хорошая база, чтобы начать его внедрять.
Stay safe. Stay cool.
#compiler #goodpractice #design
Вот тут мы обсудили мотив защиты своих сущностей от опасного использования, в том числе и защиту от неиспользования возвращаемого значения функции с помощью атрибута nodiscard. Тот разговор был довольно общим и не затрагивал особой конкретики. Теперь же поговорим о том, в каких ситуациях стоит использовать этот атрибут, чтобы вынести из этого реальную пользу.
💥 Функция возвращает код ошибки. Стандартная тема в принципе. Очень много кода написано в стиле: функция использует in/out параметры и возвращает статус(ошибка или нет). Не важно, в каком виде статус: булавок значение, числовое или enum. В этом случае возникает потенциальная проблема, когда программист не обработает статус выполнения операции и программа может продолжить выполняться совсем не так, как предполагалось изначально.
💥 Ваша функция - фабрика. Кажется, что таких ситуаций случалось примерно никогда, НО! Чисто семантически, предполагается, что возвращаемое значение будет использоваться. Поэтому в целом, не лишним будет усилить эту семантику. Ну знаете. На всякий случай. Вдруг какой-то кодер скопипастил название фабрики с аргументами, захотел кекать, вернулся облегчённым и на радостях забыл использовать созданный объект. Во время компиляции это выясниться и этот кодер уйдёт в глубокий тильт от своей тупости. Давайте заботиться о невнимательных коллегах и не подвергать их ментальное здоровье риску.
💥 Когда функция возвращает тяжеловесный тип. Не за тем я конструировал сложный, тяжелый тип или контейнер объектов, которые потом не будут использованы. Обычно это делается все-таки, чтобы потом как-то использовать эту сущность. Поэтому опять же, на всякий случай, можно эту функцию пометить атрибутом.
💥 Везде? Был какой-то пропоузал в стандарт, чтобы весь новый код стандартной библиотеки помечался этим атрибутом. Это аргументировалось тем, что не зря функция что-то возвращает, и если это можно не использовать, зачем тогда проектировать такой интерфейс. А также тем, что пропуск возвращаемого значения в подавляющем большинстве случаев приводит к проблемам.
Думаю, что везде его пихать не надо, как это делать евреи со своими носами, но определенно использование nodiscard усилит безопасность вашего кода и первые три кейса - достаточно хорошая база, чтобы начать его внедрять.
Stay safe. Stay cool.
#compiler #goodpractice #design
{kind=link}
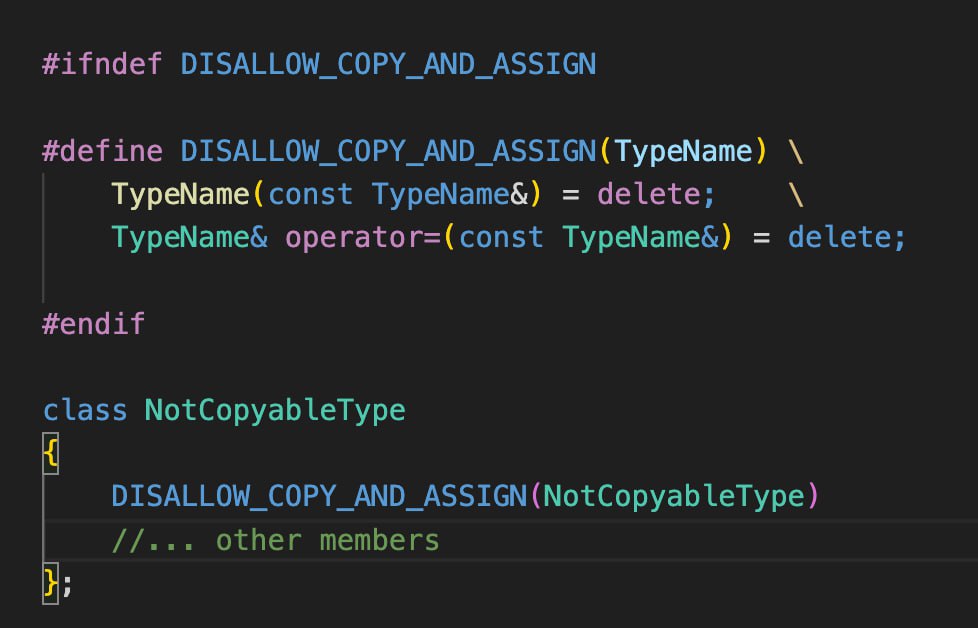
Экспресс совет для объявления некопируемых классов
Коротенький совет, как сделать ваш код более читаемым и понятным. Здесь мы говорили, что хорошей практикой запрещения копирования является определение копирующего конструктора и копирующего оператора присваивания как =delete. Это просто-напросто удалит этот метод, компилятор не будет для него генерировать код. Но иногда эти методы растворяются где-то в середине класса и они в глаза не бросаются. Хотя читающему код должно быть сразу понятно, что объект не предназначен для копирования.
Поэтому предлагаю один прием. Объявить макрос, в который передается имя класса и он подменяется на строку, которая содержит удаленные копирующий конструктор и копирующий оператор присваивания. И назвать этот макрос как-нибудь наподобие MAKE_ONLY_MOVABLE или DISALLOW_COPY. И поместить его первой же строчкой в теле класса.
Это предотвратит повторение кода, увеличит его читаемость и сделает его более понятным.
Простой трюк, но рабочий и полезный.
Stay useful. Stay cool.
#goodpractice #cppcore #cpp11
Коротенький совет, как сделать ваш код более читаемым и понятным. Здесь мы говорили, что хорошей практикой запрещения копирования является определение копирующего конструктора и копирующего оператора присваивания как =delete. Это просто-напросто удалит этот метод, компилятор не будет для него генерировать код. Но иногда эти методы растворяются где-то в середине класса и они в глаза не бросаются. Хотя читающему код должно быть сразу понятно, что объект не предназначен для копирования.
Поэтому предлагаю один прием. Объявить макрос, в который передается имя класса и он подменяется на строку, которая содержит удаленные копирующий конструктор и копирующий оператор присваивания. И назвать этот макрос как-нибудь наподобие MAKE_ONLY_MOVABLE или DISALLOW_COPY. И поместить его первой же строчкой в теле класса.
Это предотвратит повторение кода, увеличит его читаемость и сделает его более понятным.
Простой трюк, но рабочий и полезный.
Stay useful. Stay cool.
#goodpractice #cppcore #cpp11
{kind=link}
Выражайте свои намерения в коде явно
Всегда, когда мы пишем код, мы должны помнить одну вещь. То, что мы написали, потом будут читать. Много много раз. Фактически, вы пишите книгу о том, что делается у вас проекте. Безусловно, эта книга не будет понятна 99.9% жителей планеты. Однако иногда такой код пишется, что 99.9% программистов он непонятен)
Есть много разных способов сделать свой код понятнее для коллег. Расскажу про один из таких способов.
Если назначение какого-либо кода не указано (например, в именах переменных или комментариях), трудно сказать, делает ли код то, что должен делать(да и в принципе что этот код делает). Например:
int i = 0;
while (i < v.size()) {
// ... a lot of operations with v[i]...
}
...
Что в этом куске кода не так? Он непонятный. Ну то есть тут все читаемо и мы понимаем механику, как какие-то операции делаются. Но мы не понимаем главного. Намерений. Смысла.
Довольно часто нам приходится разбираться в новом чужом коде. И выражение намерений с помощью языковых конструкций дает огромный буст в понимании происходящего.
Вот возьмем код сверху. Мы понимаем, что есть какой-то цикл и есть переменная i, которая вроде как индекс и вот мы чет-то делаем до тех пор, пока не этот индекс не достигнет размера какого-то объекта. Непонятно, почему индекс объявлен вне цикла. Непонятно, будет ли он использоваться дальше и зачем. А человек всего лишь хотел обойти элементы массива и сделать с ними что-то. Почему бы не написать сразу вот так:
for (const auto& point : points_for_drawing) { DrawPoint(point);}
Это даже читать можно. Для каждой точки из набора точек для рисования нужно отрисовать точку. Причем сразу понятно, что DrawPoint не может изменить точку. Или так:
for (auto& point : points_for_drawing) { ReflectOx(point);}
Для каждой точки из набора точек для рисования нужно отразить ее относительно оси абсцисс. Это потребует изменения точек, поэтому ссылка неконстантная.
Здесь нет акцента на итерировании и способе прохождения по массиву. Я здесь выражаю намерение, а не способ достижения результата. ЧТО я хочу сделать, а не КАК.
Иногда можно использовать именованные алгоритмы для большей ясности повествования.
std::for_each (points_for_drawing.begin(), points_for_drawing.end(), ReflectOx(point));
Вариант не универсальный, но всегда нужно оценивать возможность этого подхода.
Выражайте свои намерения в коде. Это и вам помогает подняться на уровень выше и научиться понятно доносить свои мысли до людей. Ведь мы их доносим для того, чтобы нас поняли. И очень круто, если процесс понимания будет занимать минимум времени.
Stay clear. Stay cool.
#goodpractice
Всегда, когда мы пишем код, мы должны помнить одну вещь. То, что мы написали, потом будут читать. Много много раз. Фактически, вы пишите книгу о том, что делается у вас проекте. Безусловно, эта книга не будет понятна 99.9% жителей планеты. Однако иногда такой код пишется, что 99.9% программистов он непонятен)
Есть много разных способов сделать свой код понятнее для коллег. Расскажу про один из таких способов.
Если назначение какого-либо кода не указано (например, в именах переменных или комментариях), трудно сказать, делает ли код то, что должен делать(да и в принципе что этот код делает). Например:
int i = 0;
while (i < v.size()) {
// ... a lot of operations with v[i]...
}
...
Что в этом куске кода не так? Он непонятный. Ну то есть тут все читаемо и мы понимаем механику, как какие-то операции делаются. Но мы не понимаем главного. Намерений. Смысла.
Довольно часто нам приходится разбираться в новом чужом коде. И выражение намерений с помощью языковых конструкций дает огромный буст в понимании происходящего.
Вот возьмем код сверху. Мы понимаем, что есть какой-то цикл и есть переменная i, которая вроде как индекс и вот мы чет-то делаем до тех пор, пока не этот индекс не достигнет размера какого-то объекта. Непонятно, почему индекс объявлен вне цикла. Непонятно, будет ли он использоваться дальше и зачем. А человек всего лишь хотел обойти элементы массива и сделать с ними что-то. Почему бы не написать сразу вот так:
for (const auto& point : points_for_drawing) { DrawPoint(point);}
Это даже читать можно. Для каждой точки из набора точек для рисования нужно отрисовать точку. Причем сразу понятно, что DrawPoint не может изменить точку. Или так:
for (auto& point : points_for_drawing) { ReflectOx(point);}
Для каждой точки из набора точек для рисования нужно отразить ее относительно оси абсцисс. Это потребует изменения точек, поэтому ссылка неконстантная.
Здесь нет акцента на итерировании и способе прохождения по массиву. Я здесь выражаю намерение, а не способ достижения результата. ЧТО я хочу сделать, а не КАК.
Иногда можно использовать именованные алгоритмы для большей ясности повествования.
std::for_each (points_for_drawing.begin(), points_for_drawing.end(), ReflectOx(point));
Вариант не универсальный, но всегда нужно оценивать возможность этого подхода.
Выражайте свои намерения в коде. Это и вам помогает подняться на уровень выше и научиться понятно доносить свои мысли до людей. Ведь мы их доносим для того, чтобы нас поняли. И очень круто, если процесс понимания будет занимать минимум времени.
Stay clear. Stay cool.
#goodpractice
{kind=link}
Удобное представление чисел
Всем привет! Хочу рассказать про небольшую подсказку, которая сделает ваш код понятнее как для себя, так и для других.
Часто замечаю, что когда пишется длинная численная константа, она выглядит как куча-мала и требует внимательного прочтения:
При беглом чтении кода преимущественно хочется хотя бы быстро определить порядок этого числа.
При программировании, например, FPGA приходится использовать задокументированные численные константы к конкретной железке. Очень часто их пишут в двоичной или шестнадцатеричной СИ:
Начиная с C++14 появилась поддержка бинарных литералов, которые позволяют делать вот так:
На мой взгляд, группировка на порядки или байты позволяет быстро и легко воспринимать код. Как говорится, разделяй и властвуй 😉
#cpp14 #goodpractice #fun
Всем привет! Хочу рассказать про небольшую подсказку, которая сделает ваш код понятнее как для себя, так и для других.
Часто замечаю, что когда пишется длинная численная константа, она выглядит как куча-мала и требует внимательного прочтения:
uint64_t speed = 299792458;
double size = 0.4315973;
При беглом чтении кода преимущественно хочется хотя бы быстро определить порядок этого числа.
При программировании, например, FPGA приходится использовать задокументированные численные константы к конкретной железке. Очень часто их пишут в двоичной или шестнадцатеричной СИ:
uint32_t SPI_hex_code = 0x374F0FB4;
uint16_t SPI_bin_code = 0b1000111110110100;
Начиная с C++14 появилась поддержка бинарных литералов, которые позволяют делать вот так:
// Binary literals since C++14
// Разделение на порядки
uint64_t speed = 299'792'458;
double size = 0.431'597'3;
// Разделение на октеты (байты)
uint32_t SPI_hex_code = 0x37'4F'0F'B4;
uint16_t SPI_bin_code = 0b10001111'10110100;
На мой взгляд, группировка на порядки или байты позволяет быстро и легко воспринимать код. Как говорится, разделяй и властвуй 😉
#cpp14 #goodpractice #fun
{kind=link}
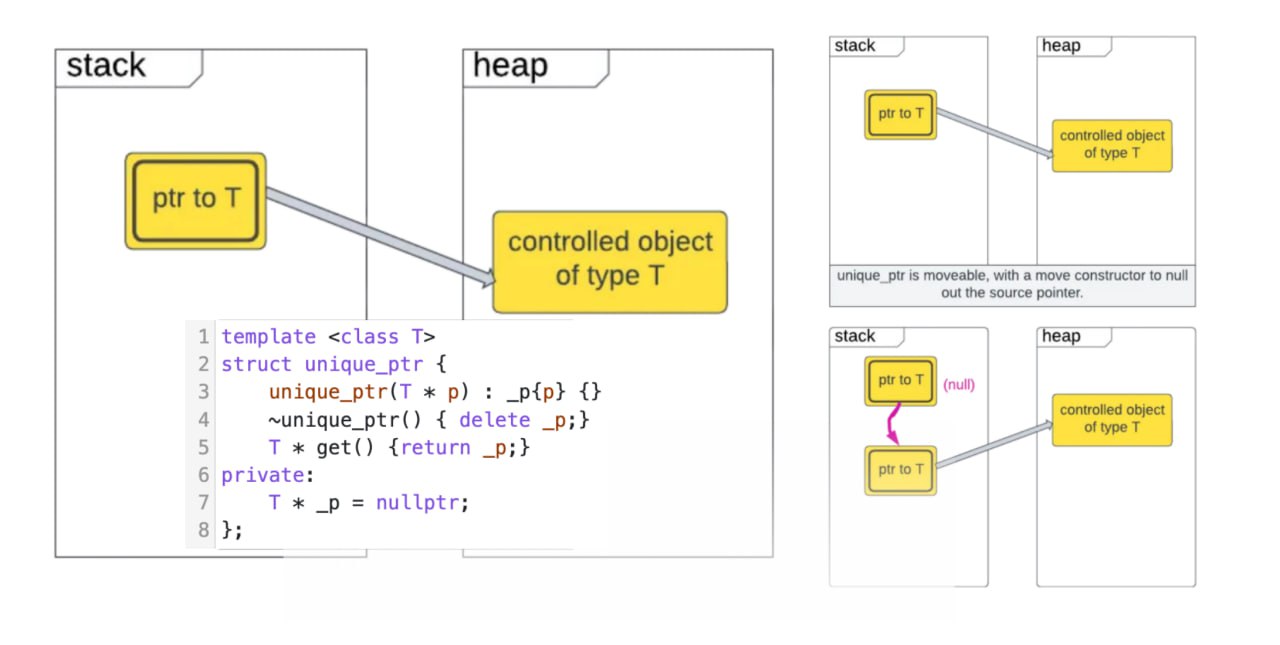
std::unique_ptr
Снова пост по запросам подписчиков. @load_balancer попросил пояснить за std::unique_ptr и в чем его преимущества по сравнению со связкой new/delete. Когда-то я сам не понимал, в чем прикол этих умных указателей. Но со временем осознал, насколько это маст-хэв в современной плюсовой разработке.
Как было раньше. Концепция умных указателей появилась довольно давно и даже до стандартных классов, все пользовались или кастомными вариантами, или бустовскими. Но без семантики перемещения все работало довольно костыльно(яркий пример std::auto_ptr). Потому не буду брать это в расчет. Представим, что давным-давно не было никаких умных указателей. В С++ есть 2(4 если учитывать варианты для массивов) оператора для работы с кучей. new и delete. Когда нам нужен объект, время жизни которого мы хотим полностью контролировать от и до, мы вызываем оператор new. В этот момент происходят 2 вещи: выделяется память на куче и на этой памяти создается объект с помощью конструктора. И нам возвращается типизированный указатель на объект. Далее мы этим объектом работаем, работаем. И когда он нам больше не нужен, мы его удаляем с помощью delete. Тут тоже происходят 2 вещи: вызывается деструктор объекта и память возвращается системе. Когда-то все так писали и ничего страшного. В языке С до сих пор оперируют сырыми указателями и память менеджится самостоятельно.
Но у такого подхода есть проблемы. Системы, которые мы строим, имеют намного большую сложность, чем средний программист может воспринять. Иногда мы вообще работаем только с одной частью этой системы и чхать хотели на остальные компоненты. Все еще сильно усложняется тем, что приложения обычно многопоточные и мыслить в парадигме многопоточности - дело нетривиальное даже для самых профиков. Всвязи с этим логичное следствие - мы не до конца понимает и не осознаем полный цикл жизни объектов. А из этого проистекают 2 проблемы: человек может просто не удалить объект и удалить этот объект повторно. Первая приводит к утечкам памяти и все увеличивающему потреблению памяти приложением, а вторая приводит просто к падению этого приложения. Обе вещи пренеприятнейшие и хотелось бы не сталкиваться с ними.
Что придумали взрослые толстые дяди. В начале появилась идиома RAII. У нас есть довольно подробный пост на эту тему тут. Благодаря пониманию, что мы можем перенести ответственность за удаление объекта на систему при вызове деструктора, и благодаря внедрению move-семантики, появились привычные нам умные указатели std::unique_ptr и std::shared_ptr.
Их общее преимущество, по сравнению со старым подходом new/delete - разработчик теперь не заботится об удалении объекта. Он определяет только момент создания объекта и знает условия, при которых тот или иной умный указатель освободит память.
Специфика конкретно unique_ptr - объект этого указателя реализует семантику владения ресурсом. То есть нет другого объекта, который может повлиять на время жизни объекта-хозяина. Объект-хозяин может только удалиться сам и освободить ресурс, и передать права на владение ресурсом другому объекту. Все! Удаление происходит в предсказуемом моменте времени - при выходе из скоупа. А передача прав происходит при создании другого объекта в его конструкторе перемещения с явным вызовом std::move, который делает программист руками, когда хочет передать владение.
Нет ни одной причины не использовать unique_ptr для управления объектами. Памяти он обычно занимает столько же, как и обычный указатель. Благодаря нему мы пишем код в объектно-ориентированном стиле. И не заботимся о менеджменте памяти. Недостатков не наблюдаю.
Надеюсь, я довольно подробно описал мотивацию использования smart pointers и их преимущества. Будут вопросы - в удовольствием поговорим в комментах.
Stay smart. Stay cool.
#cpp11 #memory #goodpractice
Снова пост по запросам подписчиков. @load_balancer попросил пояснить за std::unique_ptr и в чем его преимущества по сравнению со связкой new/delete. Когда-то я сам не понимал, в чем прикол этих умных указателей. Но со временем осознал, насколько это маст-хэв в современной плюсовой разработке.
Как было раньше. Концепция умных указателей появилась довольно давно и даже до стандартных классов, все пользовались или кастомными вариантами, или бустовскими. Но без семантики перемещения все работало довольно костыльно(яркий пример std::auto_ptr). Потому не буду брать это в расчет. Представим, что давным-давно не было никаких умных указателей. В С++ есть 2(4 если учитывать варианты для массивов) оператора для работы с кучей. new и delete. Когда нам нужен объект, время жизни которого мы хотим полностью контролировать от и до, мы вызываем оператор new. В этот момент происходят 2 вещи: выделяется память на куче и на этой памяти создается объект с помощью конструктора. И нам возвращается типизированный указатель на объект. Далее мы этим объектом работаем, работаем. И когда он нам больше не нужен, мы его удаляем с помощью delete. Тут тоже происходят 2 вещи: вызывается деструктор объекта и память возвращается системе. Когда-то все так писали и ничего страшного. В языке С до сих пор оперируют сырыми указателями и память менеджится самостоятельно.
Но у такого подхода есть проблемы. Системы, которые мы строим, имеют намного большую сложность, чем средний программист может воспринять. Иногда мы вообще работаем только с одной частью этой системы и чхать хотели на остальные компоненты. Все еще сильно усложняется тем, что приложения обычно многопоточные и мыслить в парадигме многопоточности - дело нетривиальное даже для самых профиков. Всвязи с этим логичное следствие - мы не до конца понимает и не осознаем полный цикл жизни объектов. А из этого проистекают 2 проблемы: человек может просто не удалить объект и удалить этот объект повторно. Первая приводит к утечкам памяти и все увеличивающему потреблению памяти приложением, а вторая приводит просто к падению этого приложения. Обе вещи пренеприятнейшие и хотелось бы не сталкиваться с ними.
Что придумали взрослые толстые дяди. В начале появилась идиома RAII. У нас есть довольно подробный пост на эту тему тут. Благодаря пониманию, что мы можем перенести ответственность за удаление объекта на систему при вызове деструктора, и благодаря внедрению move-семантики, появились привычные нам умные указатели std::unique_ptr и std::shared_ptr.
Их общее преимущество, по сравнению со старым подходом new/delete - разработчик теперь не заботится об удалении объекта. Он определяет только момент создания объекта и знает условия, при которых тот или иной умный указатель освободит память.
Специфика конкретно unique_ptr - объект этого указателя реализует семантику владения ресурсом. То есть нет другого объекта, который может повлиять на время жизни объекта-хозяина. Объект-хозяин может только удалиться сам и освободить ресурс, и передать права на владение ресурсом другому объекту. Все! Удаление происходит в предсказуемом моменте времени - при выходе из скоупа. А передача прав происходит при создании другого объекта в его конструкторе перемещения с явным вызовом std::move, который делает программист руками, когда хочет передать владение.
Нет ни одной причины не использовать unique_ptr для управления объектами. Памяти он обычно занимает столько же, как и обычный указатель. Благодаря нему мы пишем код в объектно-ориентированном стиле. И не заботимся о менеджменте памяти. Недостатков не наблюдаю.
Надеюсь, я довольно подробно описал мотивацию использования smart pointers и их преимущества. Будут вопросы - в удовольствием поговорим в комментах.
Stay smart. Stay cool.
#cpp11 #memory #goodpractice
{kind=link}