
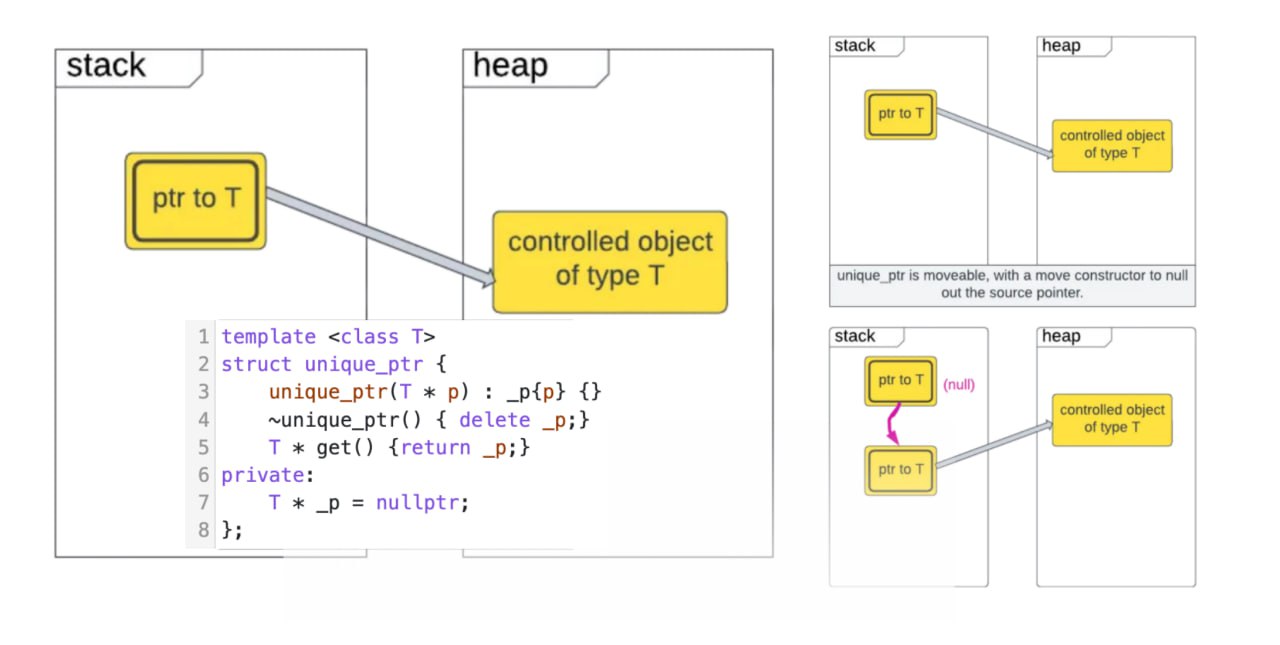
std::unique_ptr
Снова пост по запросам подписчиков. @load_balancer попросил пояснить за std::unique_ptr и в чем его преимущества по сравнению со связкой new/delete. Когда-то я сам не понимал, в чем прикол этих умных указателей. Но со временем осознал, насколько это маст-хэв в современной плюсовой разработке.
Как было раньше. Концепция умных указателей появилась довольно давно и даже до стандартных классов, все пользовались или кастомными вариантами, или бустовскими. Но без семантики перемещения все работало довольно костыльно(яркий пример std::auto_ptr). Потому не буду брать это в расчет. Представим, что давным-давно не было никаких умных указателей. В С++ есть 2(4 если учитывать варианты для массивов) оператора для работы с кучей. new и delete. Когда нам нужен объект, время жизни которого мы хотим полностью контролировать от и до, мы вызываем оператор new. В этот момент происходят 2 вещи: выделяется память на куче и на этой памяти создается объект с помощью конструктора. И нам возвращается типизированный указатель на объект. Далее мы этим объектом работаем, работаем. И когда он нам больше не нужен, мы его удаляем с помощью delete. Тут тоже происходят 2 вещи: вызывается деструктор объекта и память возвращается системе. Когда-то все так писали и ничего страшного. В языке С до сих пор оперируют сырыми указателями и память менеджится самостоятельно.
Но у такого подхода есть проблемы. Системы, которые мы строим, имеют намного большую сложность, чем средний программист может воспринять. Иногда мы вообще работаем только с одной частью этой системы и чхать хотели на остальные компоненты. Все еще сильно усложняется тем, что приложения обычно многопоточные и мыслить в парадигме многопоточности - дело нетривиальное даже для самых профиков. Всвязи с этим логичное следствие - мы не до конца понимает и не осознаем полный цикл жизни объектов. А из этого проистекают 2 проблемы: человек может просто не удалить объект и удалить этот объект повторно. Первая приводит к утечкам памяти и все увеличивающему потреблению памяти приложением, а вторая приводит просто к падению этого приложения. Обе вещи пренеприятнейшие и хотелось бы не сталкиваться с ними.
Что придумали взрослые толстые дяди. В начале появилась идиома RAII. У нас есть довольно подробный пост на эту тему тут. Благодаря пониманию, что мы можем перенести ответственность за удаление объекта на систему при вызове деструктора, и благодаря внедрению move-семантики, появились привычные нам умные указатели std::unique_ptr и std::shared_ptr.
Их общее преимущество, по сравнению со старым подходом new/delete - разработчик теперь не заботится об удалении объекта. Он определяет только момент создания объекта и знает условия, при которых тот или иной умный указатель освободит память.
Специфика конкретно unique_ptr - объект этого указателя реализует семантику владения ресурсом. То есть нет другого объекта, который может повлиять на время жизни объекта-хозяина. Объект-хозяин может только удалиться сам и освободить ресурс, и передать права на владение ресурсом другому объекту. Все! Удаление происходит в предсказуемом моменте времени - при выходе из скоупа. А передача прав происходит при создании другого объекта в его конструкторе перемещения с явным вызовом std::move, который делает программист руками, когда хочет передать владение.
Нет ни одной причины не использовать unique_ptr для управления объектами. Памяти он обычно занимает столько же, как и обычный указатель. Благодаря нему мы пишем код в объектно-ориентированном стиле. И не заботимся о менеджменте памяти. Недостатков не наблюдаю.
Надеюсь, я довольно подробно описал мотивацию использования smart pointers и их преимущества. Будут вопросы - в удовольствием поговорим в комментах.
Stay smart. Stay cool.
#cpp11 #memory #goodpractice
Снова пост по запросам подписчиков. @load_balancer попросил пояснить за std::unique_ptr и в чем его преимущества по сравнению со связкой new/delete. Когда-то я сам не понимал, в чем прикол этих умных указателей. Но со временем осознал, насколько это маст-хэв в современной плюсовой разработке.
Как было раньше. Концепция умных указателей появилась довольно давно и даже до стандартных классов, все пользовались или кастомными вариантами, или бустовскими. Но без семантики перемещения все работало довольно костыльно(яркий пример std::auto_ptr). Потому не буду брать это в расчет. Представим, что давным-давно не было никаких умных указателей. В С++ есть 2(4 если учитывать варианты для массивов) оператора для работы с кучей. new и delete. Когда нам нужен объект, время жизни которого мы хотим полностью контролировать от и до, мы вызываем оператор new. В этот момент происходят 2 вещи: выделяется память на куче и на этой памяти создается объект с помощью конструктора. И нам возвращается типизированный указатель на объект. Далее мы этим объектом работаем, работаем. И когда он нам больше не нужен, мы его удаляем с помощью delete. Тут тоже происходят 2 вещи: вызывается деструктор объекта и память возвращается системе. Когда-то все так писали и ничего страшного. В языке С до сих пор оперируют сырыми указателями и память менеджится самостоятельно.
Но у такого подхода есть проблемы. Системы, которые мы строим, имеют намного большую сложность, чем средний программист может воспринять. Иногда мы вообще работаем только с одной частью этой системы и чхать хотели на остальные компоненты. Все еще сильно усложняется тем, что приложения обычно многопоточные и мыслить в парадигме многопоточности - дело нетривиальное даже для самых профиков. Всвязи с этим логичное следствие - мы не до конца понимает и не осознаем полный цикл жизни объектов. А из этого проистекают 2 проблемы: человек может просто не удалить объект и удалить этот объект повторно. Первая приводит к утечкам памяти и все увеличивающему потреблению памяти приложением, а вторая приводит просто к падению этого приложения. Обе вещи пренеприятнейшие и хотелось бы не сталкиваться с ними.
Что придумали взрослые толстые дяди. В начале появилась идиома RAII. У нас есть довольно подробный пост на эту тему тут. Благодаря пониманию, что мы можем перенести ответственность за удаление объекта на систему при вызове деструктора, и благодаря внедрению move-семантики, появились привычные нам умные указатели std::unique_ptr и std::shared_ptr.
Их общее преимущество, по сравнению со старым подходом new/delete - разработчик теперь не заботится об удалении объекта. Он определяет только момент создания объекта и знает условия, при которых тот или иной умный указатель освободит память.
Специфика конкретно unique_ptr - объект этого указателя реализует семантику владения ресурсом. То есть нет другого объекта, который может повлиять на время жизни объекта-хозяина. Объект-хозяин может только удалиться сам и освободить ресурс, и передать права на владение ресурсом другому объекту. Все! Удаление происходит в предсказуемом моменте времени - при выходе из скоупа. А передача прав происходит при создании другого объекта в его конструкторе перемещения с явным вызовом std::move, который делает программист руками, когда хочет передать владение.
Нет ни одной причины не использовать unique_ptr для управления объектами. Памяти он обычно занимает столько же, как и обычный указатель. Благодаря нему мы пишем код в объектно-ориентированном стиле. И не заботимся о менеджменте памяти. Недостатков не наблюдаю.
Надеюсь, я довольно подробно описал мотивацию использования smart pointers и их преимущества. Будут вопросы - в удовольствием поговорим в комментах.
Stay smart. Stay cool.
#cpp11 #memory #goodpractice
{kind=link}
Можно ли явно вызывать деструктор объекта?
Вопрос скорее из категории "А что если?" и скорее всего большинство разработчиков не столкнуться с надобностью это делать. Однако менее интересным этот вопрос не становится, если немного глубже копнуть. А копаться в плюсах всегда интересно)
В целом, любой публичный метод может быть вызван снаружи. Поэтому ответ на вопрос - да, можно. Но вот какие у этого будут последствия?
Возьмем простую структурку
struct SomeDefaultDestructedType
{
SomeDefaultDestructedType(int b): a{b} {}
~SomeDefaultDestructedType() = default;
int getNumber() {return a;}
int a;
};
Как видим, у нее дефолтовый деструктор, то есть отдает генерацию кода для него в руки компилятора. А компилятор в этих вопросах тупой и прямолинейный. Для нетривиальных полей он вызывает деструкторы, а для тривиальных типов - ничего не делает. И все. Поэтому для нашего класса вызывали мы деструктор для объекта, не вызывали, значения не имеет. Даже можно вызвать метод getNumber после явного вызова деструктора и он вернет валидное значение. Семантически объект уничтожен, а на самом деле живее всех живых. Память для него на стеке есть, данные в этой области лежат, поэтому мы и можем оперировать им как полноценным объектом. И хорошо, если у класса все его поля будут рекурсивно default deconstructed, тогда мы ничего не сломает. Проблемы начинаются, когда класс имеет нетривиальный деструктор. Посмотрим на следующую структурку:
struct SomeNonTrivialDestructedType
{
SomeNonTrivialDestructedType(int b): a{new int(b)} {}
~SomeNonTrivialDestructedType() { delete a;}
int getNumber() {return *a;}
int * a;
};
Простенькое выделение и освобождение памяти в куче. Что будет сейчас при явном вызове деструктора? Ресурс освободится, а объект останется лежать на стеке. А что происходит с объектами, которые выделяются в автоматической области, при выходе из области их создания? У них вызывается деструктор. Поэтому будет двойное освобождение памяти. А если этот объект еще использовать как-то, например вызвать у него метод getNumber, это еще и неопределенное поведение, так как обращаемся к освобожденной памяти.
Для объектов, созданных в куче через new, проблема остается такой же. Потому что хорошей практикой разработки является вызывать delete на каждый выделенный с помощью new объект. А delete вызывает деструктор.
Да и вообще для любого класса с нетривиальным деструктором, явный вызов этого самого деструктора будет сопровождаться приведением объекта в неконсистентное состояние, когда объект семантически мертв, а на деле им можно еще пользоваться и его придется умертвить еще раз(самостоятельно через delete или автоматически при выходе из скоупа). Это может приводить к ошибкам самого широкого спектра, в зависимости от логики работы объекта.
Есть случаи, когда явный вызов деструктора оправдан, но это всегда связано с работой с памятью на низком уровне. Об этом поговорим как-нибудь в другой раз. А пока, если вам всерьез не приходила в голову мысль явно вызывать деструктор - и не нужно этого делать)
Stay safe. Stay cool.
#cppcore #fun #memory
Вопрос скорее из категории "А что если?" и скорее всего большинство разработчиков не столкнуться с надобностью это делать. Однако менее интересным этот вопрос не становится, если немного глубже копнуть. А копаться в плюсах всегда интересно)
В целом, любой публичный метод может быть вызван снаружи. Поэтому ответ на вопрос - да, можно. Но вот какие у этого будут последствия?
Возьмем простую структурку
struct SomeDefaultDestructedType
{
SomeDefaultDestructedType(int b): a{b} {}
~SomeDefaultDestructedType() = default;
int getNumber() {return a;}
int a;
};
Как видим, у нее дефолтовый деструктор, то есть отдает генерацию кода для него в руки компилятора. А компилятор в этих вопросах тупой и прямолинейный. Для нетривиальных полей он вызывает деструкторы, а для тривиальных типов - ничего не делает. И все. Поэтому для нашего класса вызывали мы деструктор для объекта, не вызывали, значения не имеет. Даже можно вызвать метод getNumber после явного вызова деструктора и он вернет валидное значение. Семантически объект уничтожен, а на самом деле живее всех живых. Память для него на стеке есть, данные в этой области лежат, поэтому мы и можем оперировать им как полноценным объектом. И хорошо, если у класса все его поля будут рекурсивно default deconstructed, тогда мы ничего не сломает. Проблемы начинаются, когда класс имеет нетривиальный деструктор. Посмотрим на следующую структурку:
struct SomeNonTrivialDestructedType
{
SomeNonTrivialDestructedType(int b): a{new int(b)} {}
~SomeNonTrivialDestructedType() { delete a;}
int getNumber() {return *a;}
int * a;
};
Простенькое выделение и освобождение памяти в куче. Что будет сейчас при явном вызове деструктора? Ресурс освободится, а объект останется лежать на стеке. А что происходит с объектами, которые выделяются в автоматической области, при выходе из области их создания? У них вызывается деструктор. Поэтому будет двойное освобождение памяти. А если этот объект еще использовать как-то, например вызвать у него метод getNumber, это еще и неопределенное поведение, так как обращаемся к освобожденной памяти.
Для объектов, созданных в куче через new, проблема остается такой же. Потому что хорошей практикой разработки является вызывать delete на каждый выделенный с помощью new объект. А delete вызывает деструктор.
Да и вообще для любого класса с нетривиальным деструктором, явный вызов этого самого деструктора будет сопровождаться приведением объекта в неконсистентное состояние, когда объект семантически мертв, а на деле им можно еще пользоваться и его придется умертвить еще раз(самостоятельно через delete или автоматически при выходе из скоупа). Это может приводить к ошибкам самого широкого спектра, в зависимости от логики работы объекта.
Есть случаи, когда явный вызов деструктора оправдан, но это всегда связано с работой с памятью на низком уровне. Об этом поговорим как-нибудь в другой раз. А пока, если вам всерьез не приходила в голову мысль явно вызывать деструктор - и не нужно этого делать)
Stay safe. Stay cool.
#cppcore #fun #memory
{kind=link}
Порядок вычислений в С++
Рассмотрим простой вызов функции:
foo(std::unique_ptr{new A}, std::unique_ptr{new B});
Что может пойти здесь не так?
Есть 2 противоположных ответа на этот вопрос, но выбор каждого из них определяется версией плюсов.
Что было до С++17?
Был бардак, одним словом. Нормальный человек подумает, что в начале вычисляем new A, потом конструктор unique_ptr, потом new B и второй конструктор. Но это же С++. Компилятор на самом деле мог сгенерировать код, который вычисляет это выражение в любом рандомном порядке. Именно поэтому существует эта известная проблема, что компилятор так переупорядочит вызовы, что первым будет вызов new A, а вторым будет вызов new B и дальше конструкторы. Прикол в том, что если new B бросит std::bad_alloc, то мы получим утечку памяти. Успешно отработавший new выдаст указатель на память, которая никогда не будет возвращена обратно системе. Это мог бы сделать unique_ptr, но его конструктор так и не был вызван.
Да и вообще там много приколов неприятных было. Самые знаменитые примеры:
i = i++ + i++;
std::string s = "but I have heard it works even if you don't believe in it";
s.replace(0, 4, "").replace(s.find("even"), 4, "only").replace(s.find(" don't"), 6, "");
В обоих примерах компилятор мог так переставить операции, что в первом случае i будет равно нулю, а во втором случае будет совсем каша.
Порядок вычислений неспецифицирован. Конечно, там много правил под капотом и все-таки какие-то гарантии там есть, но объяснение их всех явно влезет в этот пост.
Именно поэтому std::make_unique и std::make_shared были незаменимы до 17-х плюсов. Потому что содержали внутри себя аллокацию памяти и давали базовую гарантию безопасности исключений.
Что стало после С++17?
Порядок вычислений стал более понятен. Там ввели кучу ужесточающих правил, не буду их всех приводить, потому что они скучные и скорее всего вы с ними не пересечетесь в своей работе. Главное, что в самом первом примере с функций foo и умными указателями теперь не сможет случиться утечка памяти. Новый закон таков, что не указано, в каком порядке должны быть вычислены аргументы функций, но каждый из них должен быть полностью вычислен до того, как начнет вычисляться следующий. Если второй new бросит bad_alloc, то первый указатель уже будет обернут в unique_ptr и при разворачивании стека будет вызван его деструктор и память освободится.
Тема на самом деле не простая. Если кто хочет поподробнее ее разобрать, то можете почитать тут и тут.
Stay safe. Stay cool.
#cpp17 #memory
Рассмотрим простой вызов функции:
foo(std::unique_ptr{new A}, std::unique_ptr{new B});
Что может пойти здесь не так?
Есть 2 противоположных ответа на этот вопрос, но выбор каждого из них определяется версией плюсов.
Что было до С++17?
Был бардак, одним словом. Нормальный человек подумает, что в начале вычисляем new A, потом конструктор unique_ptr, потом new B и второй конструктор. Но это же С++. Компилятор на самом деле мог сгенерировать код, который вычисляет это выражение в любом рандомном порядке. Именно поэтому существует эта известная проблема, что компилятор так переупорядочит вызовы, что первым будет вызов new A, а вторым будет вызов new B и дальше конструкторы. Прикол в том, что если new B бросит std::bad_alloc, то мы получим утечку памяти. Успешно отработавший new выдаст указатель на память, которая никогда не будет возвращена обратно системе. Это мог бы сделать unique_ptr, но его конструктор так и не был вызван.
Да и вообще там много приколов неприятных было. Самые знаменитые примеры:
i = i++ + i++;
std::string s = "but I have heard it works even if you don't believe in it";
s.replace(0, 4, "").replace(s.find("even"), 4, "only").replace(s.find(" don't"), 6, "");
В обоих примерах компилятор мог так переставить операции, что в первом случае i будет равно нулю, а во втором случае будет совсем каша.
Порядок вычислений неспецифицирован. Конечно, там много правил под капотом и все-таки какие-то гарантии там есть, но объяснение их всех явно влезет в этот пост.
Именно поэтому std::make_unique и std::make_shared были незаменимы до 17-х плюсов. Потому что содержали внутри себя аллокацию памяти и давали базовую гарантию безопасности исключений.
Что стало после С++17?
Порядок вычислений стал более понятен. Там ввели кучу ужесточающих правил, не буду их всех приводить, потому что они скучные и скорее всего вы с ними не пересечетесь в своей работе. Главное, что в самом первом примере с функций foo и умными указателями теперь не сможет случиться утечка памяти. Новый закон таков, что не указано, в каком порядке должны быть вычислены аргументы функций, но каждый из них должен быть полностью вычислен до того, как начнет вычисляться следующий. Если второй new бросит bad_alloc, то первый указатель уже будет обернут в unique_ptr и при разворачивании стека будет вызван его деструктор и память освободится.
Тема на самом деле не простая. Если кто хочет поподробнее ее разобрать, то можете почитать тут и тут.
Stay safe. Stay cool.
#cpp17 #memory
{kind=link}
std::make_unique
В комментах под этим постом, @Zolderix предложил рассказать про плюсы-минусы использования std::make_unique и std::make_shared. Темы клевые, да и умные указатели, судя по всему, вам заходят. Но будем делать все по порядку и поэтому сегодня говорим про std::make_unique.
Нет ни одной ситуации, где я бы предпочел создать объект через new вместо того, чтобы воспользоваться какой-нибудь RAII оберткой, будь то smart pointer или, например, std::array. Бывает апи говно и по-другому просто нельзя. Но чтобы намеренно делать это - неа. Но и даже при работе с умными указателями, их можно создать с помощью сырого поинтера, возвращенного new. Нужно ли так делать или лучше воспользоваться специальными функциями?
Мне кажется, что в целом идея умных указателей - снять с разработчиков ответственность за работу с памятью(потому что они ее не вывозят) и семантически разграничить разные по предназначению виды указателей. И, как мне кажется, функции std:make_... делают большой вклад именно в полной снятии ответственности. Я большой фанат отказа от явного вызова new и delete. Со вторым умные указатели и сами хорошо справляются, а вот с первым сильно помогают их функции-фабрики. Программист в идеале должен один раз сказать: "создать объект", объект создастся и программист просто забудет о том, что за этим объектом надо следить. Уверен, что большую часть компонентов систем можно и нужно строить без упоминания операторов new и delete вообще. И если с delete все и так ясно, то ограничение использования new может привести к улучшению безопасности и читаемости кода.
Это было особенно актуально до С++17, когда гарантии для порядка вычисления выражений были довольно слабые. Использование new, даже в комбинации с умным указателем, в качестве аргумента функции могло привести к утечкам памяти. Об этом более подробно я рассказывал в этом посте. А введение std::make_unique в С++14 полностью решило это проблему! Эта функция дает базовую гарантию безопасности исключений и, даже в случае их появлений, никакие ресурсы не утекут. Уверен, что какие-то проекты до сих не апнулись до 17 версии по разным причинам, поэтому для них это будет особенно актуально. Но гарантии исключений std::make_unique остаются прежними для всех существующих версий плюсов. Поэтому, кажется, что сердцу будет все равно спокойнее при ее использовании. У меня каждый раз повышается алертность, когда я вижу new. А какой цикл жизни у объекта? А что с исключениями? Оно того не стоит.
Также std::make_unique улучшает читаемость кода. И на этом есть 2 причины.
Первая - она лучше выражает намерение. На канале мы много об этом говорим. Эта функция доносит в понятной человеку языковой форме, что сейчас идет создание объекта. Я считаю использование фабрик - хорошей идеей именно поэтому. Хотя ничего и не меняется, и в конструктор и фабрику мы передаем одни и те же аргументы. Но вот это человеческое сообщение "make" "create" воспринимается в несколько раз лучше, чем просто имя класса.
Вторая - вы избегаете повторения кода. Чтобы создать unique_ptr через new нужно написать что-то такое:
std::unique_ptr<VeryLongAndClearNameLikeItShouldBeType> ptr{ new VeryLongAndClearNameLikeItShouldBeType(...) };
И сравните во с этим:
auto ptr = std::make_unique<VeryLongAndClearNameLikeItShouldBeType>(...);
В полтора раза короче и намного приятнее на вид.
Еще std::make_unique разделят типы Т и Т[]. Здесь вы обязаны явно специфицировать шаблон с подходящим типом, иначе вы просто создадите не массив, а объект. Функция сделает так, чтобы при выходе из скоупа обязательно вызовется подходящий оператор delete или delete[]. А вот если работать с непосредственно с конструктором std::unique_ptr, то вот такая строчка
std::unique_ptr<int> ptr(new int[5]);
хоть и компилируется, но приводит к UB.
Надеюсь, я убедил вас, что это действительно крутая фича. Пост уже получился довольно длинный, а я еще хотел впихнуть сюда недостатки. Но видимо придется разбить на 2 части. Поэтому
Stay in touch. Stay cool.
#cpp14 #cpp17 #STL #memory #goodpractice
В комментах под этим постом, @Zolderix предложил рассказать про плюсы-минусы использования std::make_unique и std::make_shared. Темы клевые, да и умные указатели, судя по всему, вам заходят. Но будем делать все по порядку и поэтому сегодня говорим про std::make_unique.
Нет ни одной ситуации, где я бы предпочел создать объект через new вместо того, чтобы воспользоваться какой-нибудь RAII оберткой, будь то smart pointer или, например, std::array. Бывает апи говно и по-другому просто нельзя. Но чтобы намеренно делать это - неа. Но и даже при работе с умными указателями, их можно создать с помощью сырого поинтера, возвращенного new. Нужно ли так делать или лучше воспользоваться специальными функциями?
Мне кажется, что в целом идея умных указателей - снять с разработчиков ответственность за работу с памятью(потому что они ее не вывозят) и семантически разграничить разные по предназначению виды указателей. И, как мне кажется, функции std:make_... делают большой вклад именно в полной снятии ответственности. Я большой фанат отказа от явного вызова new и delete. Со вторым умные указатели и сами хорошо справляются, а вот с первым сильно помогают их функции-фабрики. Программист в идеале должен один раз сказать: "создать объект", объект создастся и программист просто забудет о том, что за этим объектом надо следить. Уверен, что большую часть компонентов систем можно и нужно строить без упоминания операторов new и delete вообще. И если с delete все и так ясно, то ограничение использования new может привести к улучшению безопасности и читаемости кода.
Это было особенно актуально до С++17, когда гарантии для порядка вычисления выражений были довольно слабые. Использование new, даже в комбинации с умным указателем, в качестве аргумента функции могло привести к утечкам памяти. Об этом более подробно я рассказывал в этом посте. А введение std::make_unique в С++14 полностью решило это проблему! Эта функция дает базовую гарантию безопасности исключений и, даже в случае их появлений, никакие ресурсы не утекут. Уверен, что какие-то проекты до сих не апнулись до 17 версии по разным причинам, поэтому для них это будет особенно актуально. Но гарантии исключений std::make_unique остаются прежними для всех существующих версий плюсов. Поэтому, кажется, что сердцу будет все равно спокойнее при ее использовании. У меня каждый раз повышается алертность, когда я вижу new. А какой цикл жизни у объекта? А что с исключениями? Оно того не стоит.
Также std::make_unique улучшает читаемость кода. И на этом есть 2 причины.
Первая - она лучше выражает намерение. На канале мы много об этом говорим. Эта функция доносит в понятной человеку языковой форме, что сейчас идет создание объекта. Я считаю использование фабрик - хорошей идеей именно поэтому. Хотя ничего и не меняется, и в конструктор и фабрику мы передаем одни и те же аргументы. Но вот это человеческое сообщение "make" "create" воспринимается в несколько раз лучше, чем просто имя класса.
Вторая - вы избегаете повторения кода. Чтобы создать unique_ptr через new нужно написать что-то такое:
std::unique_ptr<VeryLongAndClearNameLikeItShouldBeType> ptr{ new VeryLongAndClearNameLikeItShouldBeType(...) };
И сравните во с этим:
auto ptr = std::make_unique<VeryLongAndClearNameLikeItShouldBeType>(...);
В полтора раза короче и намного приятнее на вид.
Еще std::make_unique разделят типы Т и Т[]. Здесь вы обязаны явно специфицировать шаблон с подходящим типом, иначе вы просто создадите не массив, а объект. Функция сделает так, чтобы при выходе из скоупа обязательно вызовется подходящий оператор delete или delete[]. А вот если работать с непосредственно с конструктором std::unique_ptr, то вот такая строчка
std::unique_ptr<int> ptr(new int[5]);
хоть и компилируется, но приводит к UB.
Надеюсь, я убедил вас, что это действительно крутая фича. Пост уже получился довольно длинный, а я еще хотел впихнуть сюда недостатки. Но видимо придется разбить на 2 части. Поэтому
Stay in touch. Stay cool.
#cpp14 #cpp17 #STL #memory #goodpractice
{kind=link}
std::make_unique. Part 2
Вчера мы поговорили о том, почему вам стоит всегда использовать std::make_unique вместо std::unique_ptr(new ...). Однако может вы и убедились, что фича крутая и ей надо пользоваться всегда, но, как бы я этого не хотел, это не всегда возможно. То, что фича крутая - это беспортно! Просто в некоторых ситуациях вы не сможете ее применить. Поэтому сегодня рассмотрим эти ограничения. Ситуации значит такие:
1️⃣ Вам нужен кастомный делитер. Например, для логирования. Или для закрытия файла, если в умный указатель вы положили файл. Делитер нужно передавать, как параметр шаблона класса, а std::make_unique не умеет принимать второй параметр шаблона. Поэтому вы просто не сможете с ее помощью создать объект с кастомным удалителем. Скорее всего такой дизайн функции был продиктован простотой ее использования и следованием более понятной модели владения и инкапсуляции ресурсов. Когда ответственность за владение и удаление ресурсов ложится целиком на класс указателя.
2️⃣ Если у вас уже есть сырой указатель и вы хотите сделать из него смарт поинтер. Дело в том, что std::make_unique делает perfect-forwarding своих аргументов в аргументы конструктора целевого объекта. И получается, что передавая в функцию Type *, вы говорите - создай новый объект на основе Type *. И в большинстве ситуаций это не то, что вы хотите. У вас уже есть существующий объект и вам хочется именно его обезопасить. С make_unique такого не получится.
3️⃣ Если у вашего класса конструктор объявлен как private или protected. По идее, make_unique - внешний код для вашего класса. И если вы не хотите разрешать внешнему коду создавать объекты какого-то класса, то нужно быть готовым, что объекты такого класса нельзя будет создать через std::make_unique. В этом случае придется пользоваться конструкцией std::unique_ptr(new Type(...)). Этот пункт довольно болезненный в проектах, где у многих классов есть фабричные методы.
4️⃣ std::make_unique плохо работает с initializer_list. Например, вы не сможете скомпилировать такой код:
make_unique<TypeWithMapInitialization>({})
мы бы хотели создать объект с пустой мапой, но не можем этого сделать вот таким элегантным образом. Придется делать вот так:
make_unique<TypeWithMapInitialization>(std::map<std::string, std::map<std::string, std::string>>({}))
или придется использовать new для простоты:
unique_ptr<TypeWithDeepMap>(new TypeWithDeepMap({}))
5️⃣ И наконец, не ограничение, а скорее отличие make_unique<Type>() от unique_ptr<Type>(new Type()). Первое выражение выполняет так называемую default initialization, а второе - value initialization. Это довольно сложнопонимаемые явления, может как-нибудь отдельный пост на это запипю. Но просто для базового понимания, например, int x; - default initialization, в х будет лежать мусор. А int x{}; - value initialization и в х будет лежать 0. Повторюсь, не все так просто. Но такое отличие есть и его надо иметь ввиду при выборе нужного выражения, чтобы получить ожидаемое поведение.
Закончить я хочу так. Как часто вам нужны кастомные делитеры, приватные конструкторы? Как часто нужно передавать список инициализации в конструктор или создавать пустые объекты? Думаю, что таких кейсов явно немного. А, если и много, то поспрашивайте у коллег, мне кажется, что у них не так)
Поэтому всем рекомендую пользоваться std::make_unique, несмотря на все эти редкие и мелкие ограничения.
Stay unique. Stay cool.
#cpp14 #cpp17 #STL #memory #goodpractice
Вчера мы поговорили о том, почему вам стоит всегда использовать std::make_unique вместо std::unique_ptr(new ...). Однако может вы и убедились, что фича крутая и ей надо пользоваться всегда, но, как бы я этого не хотел, это не всегда возможно. То, что фича крутая - это беспортно! Просто в некоторых ситуациях вы не сможете ее применить. Поэтому сегодня рассмотрим эти ограничения. Ситуации значит такие:
1️⃣ Вам нужен кастомный делитер. Например, для логирования. Или для закрытия файла, если в умный указатель вы положили файл. Делитер нужно передавать, как параметр шаблона класса, а std::make_unique не умеет принимать второй параметр шаблона. Поэтому вы просто не сможете с ее помощью создать объект с кастомным удалителем. Скорее всего такой дизайн функции был продиктован простотой ее использования и следованием более понятной модели владения и инкапсуляции ресурсов. Когда ответственность за владение и удаление ресурсов ложится целиком на класс указателя.
2️⃣ Если у вас уже есть сырой указатель и вы хотите сделать из него смарт поинтер. Дело в том, что std::make_unique делает perfect-forwarding своих аргументов в аргументы конструктора целевого объекта. И получается, что передавая в функцию Type *, вы говорите - создай новый объект на основе Type *. И в большинстве ситуаций это не то, что вы хотите. У вас уже есть существующий объект и вам хочется именно его обезопасить. С make_unique такого не получится.
3️⃣ Если у вашего класса конструктор объявлен как private или protected. По идее, make_unique - внешний код для вашего класса. И если вы не хотите разрешать внешнему коду создавать объекты какого-то класса, то нужно быть готовым, что объекты такого класса нельзя будет создать через std::make_unique. В этом случае придется пользоваться конструкцией std::unique_ptr(new Type(...)). Этот пункт довольно болезненный в проектах, где у многих классов есть фабричные методы.
4️⃣ std::make_unique плохо работает с initializer_list. Например, вы не сможете скомпилировать такой код:
make_unique<TypeWithMapInitialization>({})
мы бы хотели создать объект с пустой мапой, но не можем этого сделать вот таким элегантным образом. Придется делать вот так:
make_unique<TypeWithMapInitialization>(std::map<std::string, std::map<std::string, std::string>>({}))
или придется использовать new для простоты:
unique_ptr<TypeWithDeepMap>(new TypeWithDeepMap({}))
5️⃣ И наконец, не ограничение, а скорее отличие make_unique<Type>() от unique_ptr<Type>(new Type()). Первое выражение выполняет так называемую default initialization, а второе - value initialization. Это довольно сложнопонимаемые явления, может как-нибудь отдельный пост на это запипю. Но просто для базового понимания, например, int x; - default initialization, в х будет лежать мусор. А int x{}; - value initialization и в х будет лежать 0. Повторюсь, не все так просто. Но такое отличие есть и его надо иметь ввиду при выборе нужного выражения, чтобы получить ожидаемое поведение.
Закончить я хочу так. Как часто вам нужны кастомные делитеры, приватные конструкторы? Как часто нужно передавать список инициализации в конструктор или создавать пустые объекты? Думаю, что таких кейсов явно немного. А, если и много, то поспрашивайте у коллег, мне кажется, что у них не так)
Поэтому всем рекомендую пользоваться std::make_unique, несмотря на все эти редкие и мелкие ограничения.
Stay unique. Stay cool.
#cpp14 #cpp17 #STL #memory #goodpractice
{kind=link}
std::make_shared
Недавно тут и тут мы поговорили про плюсы и минусы использования std::make_unique. Настала очередь его братишки std::make_shared.
Базового все pros and cons с предыдущих постов справедливы и для сегодняшнего разбора. Поэтому не будем на этом долго останавливаться.
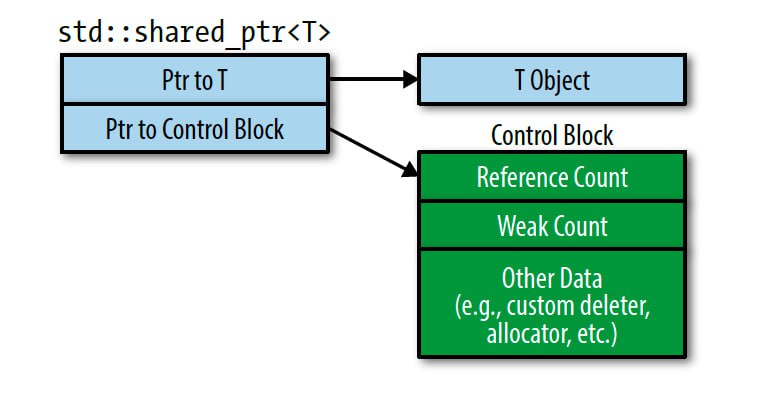
Но шаренный указатель немного сложнее внутри устроен, чем уникальный. От этого идут и уникальные преимущества и недостатки. А связаны они вот с чем. Посмотрите на эту строчку:
std::shared_ptr<T>(new T(...));
Сколько раз память аллоцируется в результате выполнения этой строчки?
Многие скажут 1. А люди, знающие внутреннее устройство шареного уккзателя, скажут 2. И будут правы.
Первая аллокация, очевидно, происходит в new. А вот где вторая?
На выделении памяти для, так называемого, control block'а. Это внутренняя структура, которая хранит счетчики ссылок и еще пару приколюх. Она нужна для того, чтобы вести учет существующих объектов указателя, указывающих на данный объект. Естественно, эта структура должна быть общей для всех таких объектов. Поэтому в каждом объекте указателя хранится сырой указатель на этот самый контрол блок. То есть базово в классе std::shared_ptr 2 поля: указатель на объект и указатель на контрол блок. Ну и приняв указатель на объект, конструктор указателя дополнитель выделяет память для этого блока.
Чем в этом контексте отличается поведение std::make_shared?
Она вызывает всего одну аллокацию. Как? выделяет просто один блок памяти, который может содержать сразу и создаваемый объект, и control block, и кладет эти данные вместе. Это уменьшает статический размер программы, потому что код содержит всего 1 вызов аллокатора. И увеличивает скорость выполнения кода, потому что аллокация - довольно дорогостоящий вызов.
Перформанс - это уже серьезный аргумент отдать свое предпочтение в пользу make функции.
Однако эта фича ведет к одной проблеме. Для кого-то она совсем не проблемная, но об этом надо знать.
Дело в том, что может создаться такая ситуация, когда ни одного shared_pointer уже не существует, а память, выделенная для объекта и блока, все еще не отдана системе. Как такое может быть? Слабые ссылки.
Контрол блок помимо счетчика сильных ссылок(собственно сами shared_ptr'ы) хранит еще и счетчик слабых ссылок - для weak_ptr'ов. А деструктор control block'а и деаллокация памяти происходят только после того, как оба счетчика зануляться. Поэтому, если у вас есть хоть один висящий std::weak_ptr, то у вашего объекта хоть и будет вызван деструктор, но память так и не будет возвращена системе.
При создании больших объектов и при обильном использовании слабых ссылок это действительно может создавать проблему.
А если у вас не этот случай - смело используйте std::make_shared()
Stay efficient. Stay cool.
#cpp17 #cpp17 #STL #optimization #memory
Недавно тут и тут мы поговорили про плюсы и минусы использования std::make_unique. Настала очередь его братишки std::make_shared.
Базового все pros and cons с предыдущих постов справедливы и для сегодняшнего разбора. Поэтому не будем на этом долго останавливаться.
Но шаренный указатель немного сложнее внутри устроен, чем уникальный. От этого идут и уникальные преимущества и недостатки. А связаны они вот с чем. Посмотрите на эту строчку:
std::shared_ptr<T>(new T(...));
Сколько раз память аллоцируется в результате выполнения этой строчки?
Многие скажут 1. А люди, знающие внутреннее устройство шареного уккзателя, скажут 2. И будут правы.
Первая аллокация, очевидно, происходит в new. А вот где вторая?
На выделении памяти для, так называемого, control block'а. Это внутренняя структура, которая хранит счетчики ссылок и еще пару приколюх. Она нужна для того, чтобы вести учет существующих объектов указателя, указывающих на данный объект. Естественно, эта структура должна быть общей для всех таких объектов. Поэтому в каждом объекте указателя хранится сырой указатель на этот самый контрол блок. То есть базово в классе std::shared_ptr 2 поля: указатель на объект и указатель на контрол блок. Ну и приняв указатель на объект, конструктор указателя дополнитель выделяет память для этого блока.
Чем в этом контексте отличается поведение std::make_shared?
Она вызывает всего одну аллокацию. Как? выделяет просто один блок памяти, который может содержать сразу и создаваемый объект, и control block, и кладет эти данные вместе. Это уменьшает статический размер программы, потому что код содержит всего 1 вызов аллокатора. И увеличивает скорость выполнения кода, потому что аллокация - довольно дорогостоящий вызов.
Перформанс - это уже серьезный аргумент отдать свое предпочтение в пользу make функции.
Однако эта фича ведет к одной проблеме. Для кого-то она совсем не проблемная, но об этом надо знать.
Дело в том, что может создаться такая ситуация, когда ни одного shared_pointer уже не существует, а память, выделенная для объекта и блока, все еще не отдана системе. Как такое может быть? Слабые ссылки.
Контрол блок помимо счетчика сильных ссылок(собственно сами shared_ptr'ы) хранит еще и счетчик слабых ссылок - для weak_ptr'ов. А деструктор control block'а и деаллокация памяти происходят только после того, как оба счетчика зануляться. Поэтому, если у вас есть хоть один висящий std::weak_ptr, то у вашего объекта хоть и будет вызван деструктор, но память так и не будет возвращена системе.
При создании больших объектов и при обильном использовании слабых ссылок это действительно может создавать проблему.
А если у вас не этот случай - смело используйте std::make_shared()
Stay efficient. Stay cool.
#cpp17 #cpp17 #STL #optimization #memory
{kind=link}
Когда нужно явно вызывать деструктор?
В прошлом мы поговорили о том, можно ли явно вызывать деструкторы у объектов и какие последствия это за собой несет. Обещал рассказать, когда это делать разумно, собственно выполняю обещание.
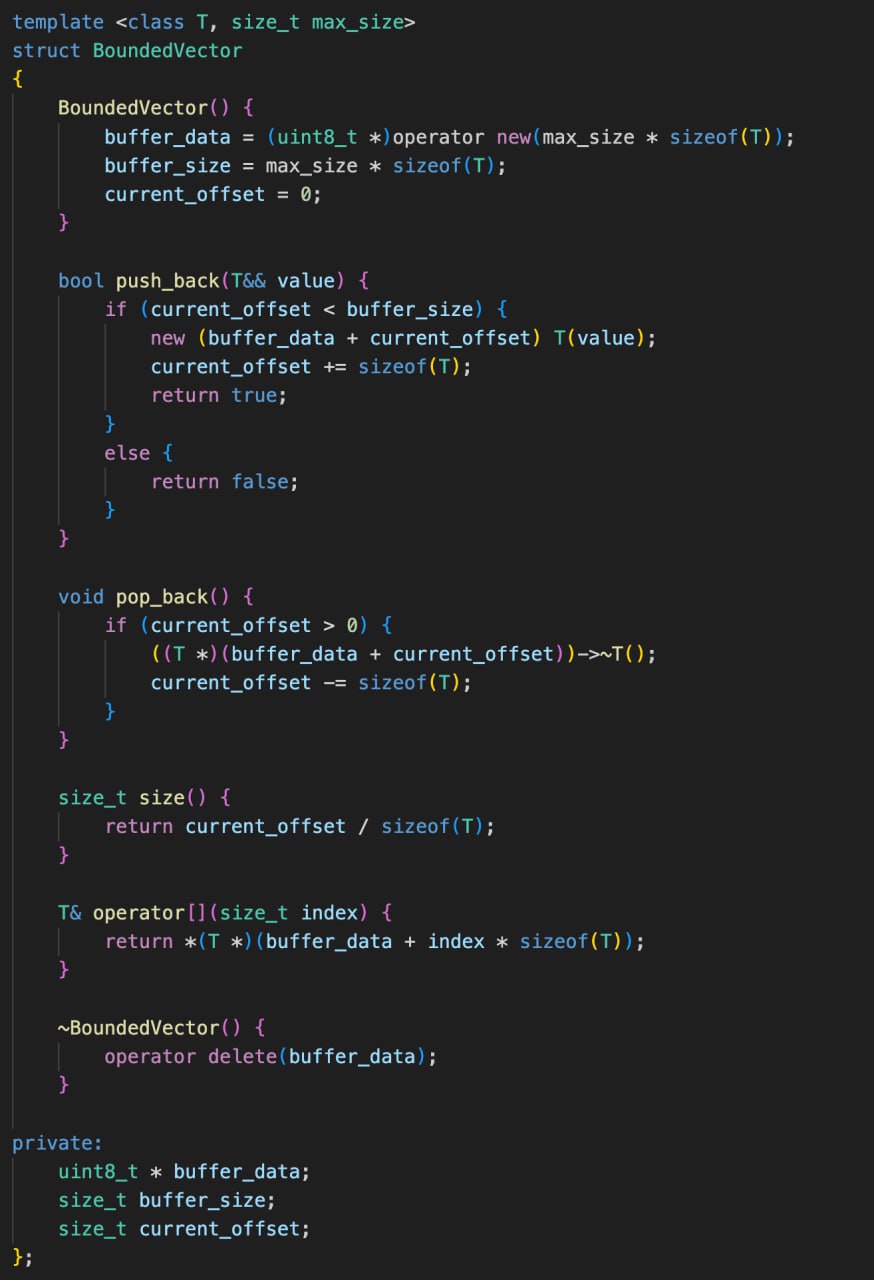
Проблема в том, что при выходе из скоупа автоматически вызывается деструктор для локальных объектов, а при выделении объектов на куче мы обязаны вручную это делать через delete, в том числе и чтобы освободить память. Прежде чем говорить о каких-то реальных приложениях, нам нужно найти способ, при котором аллокация памяти и создание/удаление объекта полностью и раздельно управляется программистом. И такой способ есть.
Мы знает, как выделить и удалить просто сырой кусок памяти. Статический массив чаров, комбинация malloc+free, и комбинация operator new + operator delete помогут это сделать. Последние операторы имеют ту же семантику, что и malloc+free.
Теперь нужен механизм, позволяющий конструировать объект на уже заранее известной области памяти. Этот механизм называется placement new. Тут п****ц какой-то с названиями на русском языке, на английском new expression - это то, что наиболее часто используют для аллокации+конструирования, operator new - функция, которая выполняет только аллокацию памяти, а placement new - конструирует объект на заданной памяти. И, наконец, явный вызов деструктора позволяет освободить ресурсы из объекта.
Применяя эти связки, мы добиваемся полного контроля над всеми этапами создания и удаления объекта. И в этом случае, проблем с double free или повторном освобождении ресурса происходить не будет. Но это все равно на какое-то время порождает зомби-объекты, для которых есть имя и мы знаем как к ним обратиться, но по факту они уже удалены.
Для чего нужно идти на риск неправильно использовать объекты ради возможности самостоятельно вызывать декструкторы? High risk - high reward. Смысл в оптимизации работы с памятью. Выделение объектов в куче - дело дорогостоящее в плане производительности и использования дополнительных ячеек памяти. Если мы очень сильно ограничены в ресурсах железки, то приходится идти на риск, чтобы добиться желаемого. Обычно выделяется какой-то чанк памяти и на этом чанке создаются и, что самое главное, пересоздаются объекты, потенциально разных типов. Это сильно сокращает используемое пространство памяти, уменьшает ее фрагментацию и снижает издержки на выделение новых ячеек. Сейчас сложно представить себе, что есть такие жесткие рамки, при которых нужно максимумально ужиматься в использовании ресурсов. Однако в прошлом, когда у компьютеров было несколько сот килобайт оперативы, ужимались все и во всем. Даже при работе со стеком нужно было использовать такие ухищрения.
Еще один пример использования явного деструктора - стандартный класс std::vector. Тут на самом деле ситуация очень похожая. У вектора есть некий внутренний буфер, который всегда выделяется с некоторым запасом, чтобы не аллоцировать память на каждое добавление элемента. Поэтому при этом самом добавлении элемента происходит конструирование объекта на нужном блоке памяти. И у вектора есть метод erase, который удаляет элемент из контейнера. Хотя удаляет - слишком общий термин. Он его уничтожает. При этом память, занимаемая этим объектом не освобождается. Поэтому в этом случае просто необходимо использовать явный вызов деструктора.
В принципе, в любом случае, когда необходимо раздельно аллоцировать память и конструировать объекты, будет использоваться явный вызов деструктора. Вряд ли обычные бэкэнд девелоперы когда-нибудь с этим столкнуться. Но знать, что такое есть, надо.
Расскажите о своих кейсах, когда вы знаете, что нужно использовать явный вызов деструктора. Будет интересно почитать другие варианты)
Stay optimized. Stay cool.
#cppcore #optimization #memory
В прошлом мы поговорили о том, можно ли явно вызывать деструкторы у объектов и какие последствия это за собой несет. Обещал рассказать, когда это делать разумно, собственно выполняю обещание.
Проблема в том, что при выходе из скоупа автоматически вызывается деструктор для локальных объектов, а при выделении объектов на куче мы обязаны вручную это делать через delete, в том числе и чтобы освободить память. Прежде чем говорить о каких-то реальных приложениях, нам нужно найти способ, при котором аллокация памяти и создание/удаление объекта полностью и раздельно управляется программистом. И такой способ есть.
Мы знает, как выделить и удалить просто сырой кусок памяти. Статический массив чаров, комбинация malloc+free, и комбинация operator new + operator delete помогут это сделать. Последние операторы имеют ту же семантику, что и malloc+free.
Теперь нужен механизм, позволяющий конструировать объект на уже заранее известной области памяти. Этот механизм называется placement new. Тут п****ц какой-то с названиями на русском языке, на английском new expression - это то, что наиболее часто используют для аллокации+конструирования, operator new - функция, которая выполняет только аллокацию памяти, а placement new - конструирует объект на заданной памяти. И, наконец, явный вызов деструктора позволяет освободить ресурсы из объекта.
Применяя эти связки, мы добиваемся полного контроля над всеми этапами создания и удаления объекта. И в этом случае, проблем с double free или повторном освобождении ресурса происходить не будет. Но это все равно на какое-то время порождает зомби-объекты, для которых есть имя и мы знаем как к ним обратиться, но по факту они уже удалены.
Для чего нужно идти на риск неправильно использовать объекты ради возможности самостоятельно вызывать декструкторы? High risk - high reward. Смысл в оптимизации работы с памятью. Выделение объектов в куче - дело дорогостоящее в плане производительности и использования дополнительных ячеек памяти. Если мы очень сильно ограничены в ресурсах железки, то приходится идти на риск, чтобы добиться желаемого. Обычно выделяется какой-то чанк памяти и на этом чанке создаются и, что самое главное, пересоздаются объекты, потенциально разных типов. Это сильно сокращает используемое пространство памяти, уменьшает ее фрагментацию и снижает издержки на выделение новых ячеек. Сейчас сложно представить себе, что есть такие жесткие рамки, при которых нужно максимумально ужиматься в использовании ресурсов. Однако в прошлом, когда у компьютеров было несколько сот килобайт оперативы, ужимались все и во всем. Даже при работе со стеком нужно было использовать такие ухищрения.
Еще один пример использования явного деструктора - стандартный класс std::vector. Тут на самом деле ситуация очень похожая. У вектора есть некий внутренний буфер, который всегда выделяется с некоторым запасом, чтобы не аллоцировать память на каждое добавление элемента. Поэтому при этом самом добавлении элемента происходит конструирование объекта на нужном блоке памяти. И у вектора есть метод erase, который удаляет элемент из контейнера. Хотя удаляет - слишком общий термин. Он его уничтожает. При этом память, занимаемая этим объектом не освобождается. Поэтому в этом случае просто необходимо использовать явный вызов деструктора.
В принципе, в любом случае, когда необходимо раздельно аллоцировать память и конструировать объекты, будет использоваться явный вызов деструктора. Вряд ли обычные бэкэнд девелоперы когда-нибудь с этим столкнуться. Но знать, что такое есть, надо.
Расскажите о своих кейсах, когда вы знаете, что нужно использовать явный вызов деструктора. Будет интересно почитать другие варианты)
Stay optimized. Stay cool.
#cppcore #optimization #memory
{kind=link}
Сколько памяти вы можете аллоцировать?
Пару месяцев назад мы обсуждали, что будет, если маллокнуть 100 Гб памяти. Идея эксперимента мне понравилась, поэтому решил сделать что-то похожее. На этот раз я попробую в цикле на каждой итерации выделять по одному гигабайту памяти.
На этом месте я предлагаю вам задуматься, на какой итерации остановится цикл? Ну то есть, сколько всего памяти с смогу выделить таким образом?
Для конкретики определимся, что у меня на машине 64-битная Ubuntu c 21111872 кбайт оперативной памяти или ~21 Гб. И выделяю я, просто вызывая маллок, ничего больше. Память я также не освобождаю (ждал бы завершения эксперимента уже в гробу😵).
Тут есть несколько вариантов:
1️⃣ Система нам выделить 21 Гб и скажет гуляй хлопец дальше без меня.
2️⃣ У операционной системы есть какой-то внутренний лимит, больше или меньше реального количества доступной памяти, который зависит от количества доступной RAM, и при достижении вот этого лимита ОС откажется выдавать больше памяти.
3️⃣ Мы каким-то образом сможем использовать тот факт, что процессы оперируют с виртуальной памятью, которая по размерам намного больше доступной, и сможем выделить больше памяти, чем есть на самом деле.
В целом, все варианты имеют место быть. Но давайте перейдем уже к результатам. Они на картинке под постом.
Система смогла выделить 131 террабайт памяти для нас. 131 ТЕРРАБАЙТ, КАРЛ. Вы в шоке? Я в шоке. Все в шоке.
Это примерно в 2^12 раза больше, чем доступно на машине. Кто офигел - ставим лайкосик.
What the fuck is going on и откуда такие цифры взялись, разберем в следующих постах.
Stay in touch. Stay cool.
#fun #memory #hardcore
Пару месяцев назад мы обсуждали, что будет, если маллокнуть 100 Гб памяти. Идея эксперимента мне понравилась, поэтому решил сделать что-то похожее. На этот раз я попробую в цикле на каждой итерации выделять по одному гигабайту памяти.
На этом месте я предлагаю вам задуматься, на какой итерации остановится цикл? Ну то есть, сколько всего памяти с смогу выделить таким образом?
Для конкретики определимся, что у меня на машине 64-битная Ubuntu c 21111872 кбайт оперативной памяти или ~21 Гб. И выделяю я, просто вызывая маллок, ничего больше. Память я также не освобождаю (ждал бы завершения эксперимента уже в гробу😵).
Тут есть несколько вариантов:
1️⃣ Система нам выделить 21 Гб и скажет гуляй хлопец дальше без меня.
2️⃣ У операционной системы есть какой-то внутренний лимит, больше или меньше реального количества доступной памяти, который зависит от количества доступной RAM, и при достижении вот этого лимита ОС откажется выдавать больше памяти.
3️⃣ Мы каким-то образом сможем использовать тот факт, что процессы оперируют с виртуальной памятью, которая по размерам намного больше доступной, и сможем выделить больше памяти, чем есть на самом деле.
В целом, все варианты имеют место быть. Но давайте перейдем уже к результатам. Они на картинке под постом.
Система смогла выделить 131 террабайт памяти для нас. 131 ТЕРРАБАЙТ, КАРЛ. Вы в шоке? Я в шоке. Все в шоке.
Это примерно в 2^12 раза больше, чем доступно на машине. Кто офигел - ставим лайкосик.
What the fuck is going on и откуда такие цифры взялись, разберем в следующих постах.
Stay in touch. Stay cool.
#fun #memory #hardcore
{kind=link}
Как система может выделить 131 Терабайт оперативы?
Здесь мы выясняли, сколько же памяти может нам выдать система. И ответ для многих оказался неожиданным. 131 тарабайт - в дохренальен раз больше, чем реальный объем RAM на тестовой машине. Понятное дело, что это фейковые терабайты, потому что их просто негде расположить. И если бы было хотя бы RAMx2, можно было бы еще поговорить про такие штуки, как файлы подкачки. Но здесь прям совсем ничего не сходится, поэтому погнали разбираться, что к чему. Повторю ремарку, что здесь я говорю про 64-битные системы.
Первая подсказка к ответу для вас - практически в точности такой же результат я получил на других своих машинах. Да и под тем постом @dtbeaver оставил скрин, что у него такие же цифры +- 2 Гб от того, что получил я. Значит этот предел - общий для, по крайней мере, большой группы линуксоидов с 64-битными системами. Это наводит на вопрос: а сколько вообще можно адресовать памяти? Может 131 Тб и есть это количество?
Вторая подсказка - выделилось на самом деле не 131(ох уж это эти десятичные приставки в двоичном мире...), а 128. До боли знакомое число...
Однажды на собесе меня спросили: сколько байт я могу адресовать в программе? И я ответил: 2^64 байт. Ну вот у нас есть указатель. Он занимает 8 байт или 64-бит памяти. Минимально адресуемый размер памяти - 1 байт. И получается, что 8 байт памяти могут хранить 2^64 уникальных чисел и, соответственно, именно столько байт и могут быть адресованы. У меня этот ответ приняли, типа я ответил правильно. Но я ошибался....
Для начала вспомним, как вообще данные программы маппятся на физическую память. Напрямую использовать физические адреса мы не можем, потому что тогда каждый процесс должен был знать о том, какие ячейки уже используются, чтобы не нарваться на конфликт. Поэтому придумали такую абстракцию - виртуальная память. Теперь каждый процесс думает, что он пуп вселенной и ему одному принадлежит вся память компьютера. Теперь процессу ничего не нужно знать, он просто кайфует и оперирует всем адресным пространством единолично. А грязной работой занимается ОС. А раз процессу "принадлежит" вся память компьютера, то в теории ему и доступны все те 2^64 байта для размещения своих данных.
Но на самом деле в современных системах для адресации используются только 48 бит адреса. Почему не все 64? 48-бит - это 256 Тб оперативной памяти. Нет таких промышленных систем, которые бы обладали таким объемом оперативной+swap памяти. Сейчас уже конечно стали появляться, поэтому появляются системы с 52/57 адресными битами, но сегодня не об этом. Представим, что их нет. Тогда введение возможности адресовать все 2^64 байта виртуальной памяти будет увеличивать сложность и нагрузку на преобразование виртуального адреса в физический. Зачем платить за то, чем не пользуешься? Да и 64-битная адресация потребовала бы больший размер страниц, больший размер таблиц страниц или большую глубину страничной структуры. Это все увеличивает стоимость кеш промаха в буфере ассоциативной трансляции (TLB). В общем, накладные расходы были бы больше. А никому этого не надо, пока у нас нет столько памяти.
Но вы спросите у меня: 128 терабайт - это 2^47, а ты нам говоришь, что 48 бит адресуются. Куда делся еще один бит, ааа?
Операционная система, как главный дерижер всех процессов в системе, может вмешиваться в их работу по самым разным причинам. Ну например, через системные вызовы. Поэтому в ОС нужно иметь возможность в адресном пространстве конкретного процесса адресовать свой код и свои данные. Поэтому операционка делает свою виртуальную память видимой в адресном пространстве каждого процесса. Это значит, что 2^48 байт делятся между адресным пространством пользователя (user space) и ядра (kernel space). История встречала разные отношения в этом разделении. Но сейчас более-менее все остановились на соотношении 1:1. То есть 256 терабайт делятся поровну между пользовательским процессом и системой. Положительную часть берет себе система, а отрицательную - процесс. Так и получаются те самые 128 Тб.
Продолжение в комментариях
#memory #OS #fun #hardcore
Здесь мы выясняли, сколько же памяти может нам выдать система. И ответ для многих оказался неожиданным. 131 тарабайт - в дохренальен раз больше, чем реальный объем RAM на тестовой машине. Понятное дело, что это фейковые терабайты, потому что их просто негде расположить. И если бы было хотя бы RAMx2, можно было бы еще поговорить про такие штуки, как файлы подкачки. Но здесь прям совсем ничего не сходится, поэтому погнали разбираться, что к чему. Повторю ремарку, что здесь я говорю про 64-битные системы.
Первая подсказка к ответу для вас - практически в точности такой же результат я получил на других своих машинах. Да и под тем постом @dtbeaver оставил скрин, что у него такие же цифры +- 2 Гб от того, что получил я. Значит этот предел - общий для, по крайней мере, большой группы линуксоидов с 64-битными системами. Это наводит на вопрос: а сколько вообще можно адресовать памяти? Может 131 Тб и есть это количество?
Вторая подсказка - выделилось на самом деле не 131(ох уж это эти десятичные приставки в двоичном мире...), а 128. До боли знакомое число...
Однажды на собесе меня спросили: сколько байт я могу адресовать в программе? И я ответил: 2^64 байт. Ну вот у нас есть указатель. Он занимает 8 байт или 64-бит памяти. Минимально адресуемый размер памяти - 1 байт. И получается, что 8 байт памяти могут хранить 2^64 уникальных чисел и, соответственно, именно столько байт и могут быть адресованы. У меня этот ответ приняли, типа я ответил правильно. Но я ошибался....
Для начала вспомним, как вообще данные программы маппятся на физическую память. Напрямую использовать физические адреса мы не можем, потому что тогда каждый процесс должен был знать о том, какие ячейки уже используются, чтобы не нарваться на конфликт. Поэтому придумали такую абстракцию - виртуальная память. Теперь каждый процесс думает, что он пуп вселенной и ему одному принадлежит вся память компьютера. Теперь процессу ничего не нужно знать, он просто кайфует и оперирует всем адресным пространством единолично. А грязной работой занимается ОС. А раз процессу "принадлежит" вся память компьютера, то в теории ему и доступны все те 2^64 байта для размещения своих данных.
Но на самом деле в современных системах для адресации используются только 48 бит адреса. Почему не все 64? 48-бит - это 256 Тб оперативной памяти. Нет таких промышленных систем, которые бы обладали таким объемом оперативной+swap памяти. Сейчас уже конечно стали появляться, поэтому появляются системы с 52/57 адресными битами, но сегодня не об этом. Представим, что их нет. Тогда введение возможности адресовать все 2^64 байта виртуальной памяти будет увеличивать сложность и нагрузку на преобразование виртуального адреса в физический. Зачем платить за то, чем не пользуешься? Да и 64-битная адресация потребовала бы больший размер страниц, больший размер таблиц страниц или большую глубину страничной структуры. Это все увеличивает стоимость кеш промаха в буфере ассоциативной трансляции (TLB). В общем, накладные расходы были бы больше. А никому этого не надо, пока у нас нет столько памяти.
Но вы спросите у меня: 128 терабайт - это 2^47, а ты нам говоришь, что 48 бит адресуются. Куда делся еще один бит, ааа?
Операционная система, как главный дерижер всех процессов в системе, может вмешиваться в их работу по самым разным причинам. Ну например, через системные вызовы. Поэтому в ОС нужно иметь возможность в адресном пространстве конкретного процесса адресовать свой код и свои данные. Поэтому операционка делает свою виртуальную память видимой в адресном пространстве каждого процесса. Это значит, что 2^48 байт делятся между адресным пространством пользователя (user space) и ядра (kernel space). История встречала разные отношения в этом разделении. Но сейчас более-менее все остановились на соотношении 1:1. То есть 256 терабайт делятся поровну между пользовательским процессом и системой. Положительную часть берет себе система, а отрицательную - процесс. Так и получаются те самые 128 Тб.
Продолжение в комментариях
#memory #OS #fun #hardcore
{kind=link}
std::byte
Если вы приличное время работаете с байтами на низком уровне, вы понимаете, что стандартные сишные возможности репрезентации сырых байтов данных не очень удобные. В основном сложности, конечно, в семантике. Вот возьмём какой-нибудь указатель на чар char *. Что это? Символ, число или просто сырой байт? Да, со временем это уже откладывается на подкорке, все всё понимают, ничего лучше же нет. Или есть?
Что такое std::byte?
std::byte — это фундаментальный тип данных, предназначенный для представления необработанных байтов памяти. Это неотъемлемая часть стандарта C++17, призванная обеспечить стандартизированный способ работы с необработанными двоичными данными. В отличие от базовых числовых типов, таких как char, int или float, std::byte — это отдельный тип, оптимизированный для операций на уровне байтов, что делает его более подходящим для задач, связанных с манипулированием памятью и низкоуровневым программированием.
Откуда оно взялось?
На самом деле все просто. В cтандарте этот тип определяется как enum class byte : unsigned char {} ;
Выглядит просто, но такая сущность давно напрашивалась. В плюсах есть большая необходимость в стандартизированном, независимом от платформы способа манипулирования необработанными двоичными данными, особенно в таких сценариях, как сериализация данных, работа с сетевыми протоколами и взаимодействие с оборудованием. Появление отдельного типа для байтов в C++17 частично решило эти проблемы, так как std::byte:
1️⃣ Обеспечивает строгое разделение манипуляций с сырой памятью от числовых типов. Вы сразу видите, что оперируете с байтами, что снижает риск путаницы с типами данных.
2️⃣ Обеспечивает безопасность при проверке типов. Операции над std::byte выполняются без непреднамеренного преобразования типов, так как нет переопределенных операторов преобразования в базовые типы. Это помогает выявить потенциальные проблемы, связанные с типами, и повышает безопасность кода при работе с данными низкого уровня.
3️⃣ Явно поддерживает только байтовую и битовую арифметику за счёт переопределенных операторов сравнения и битовых манипуляций. Это с одной стороны, ограничивает функционал класса, а, с другой стороны, че вы ещё хотите делать с байтами?
4️⃣ В качестве стандартной фичи C++ использование std::byte обеспечивает безопасность вашего кода на уровне языка.
Есть один единственный минус у этой фичи. Очень мало народу ей пользуется. Большинству существующих проектов на плюсах больше 5 лет и там есть уже свои привычные методы работы с сырой памятью и сишным интерфейсом, которые естественно все завязано на типе char. И только потому, что в стандарте появилась новая фича, никто эти методы изменять не будет. Да и новые проекты могут по инерции использовать старый подход. Он всем знаком и проверен временем.
Так что и, хоть вам не часто доведётся работать с этим типом, знать о его существовании и функционале есть смысл. Вы всегда можете написать новый микросервис или модуль в вашем проекте с использование этой фичи и сделаете код лучше и безопаснее.
Stay hardcore. Stay cool.
#cpp17 #memory #hardcore
Если вы приличное время работаете с байтами на низком уровне, вы понимаете, что стандартные сишные возможности репрезентации сырых байтов данных не очень удобные. В основном сложности, конечно, в семантике. Вот возьмём какой-нибудь указатель на чар char *. Что это? Символ, число или просто сырой байт? Да, со временем это уже откладывается на подкорке, все всё понимают, ничего лучше же нет. Или есть?
Что такое std::byte?
std::byte — это фундаментальный тип данных, предназначенный для представления необработанных байтов памяти. Это неотъемлемая часть стандарта C++17, призванная обеспечить стандартизированный способ работы с необработанными двоичными данными. В отличие от базовых числовых типов, таких как char, int или float, std::byte — это отдельный тип, оптимизированный для операций на уровне байтов, что делает его более подходящим для задач, связанных с манипулированием памятью и низкоуровневым программированием.
Откуда оно взялось?
На самом деле все просто. В cтандарте этот тип определяется как enum class byte : unsigned char {} ;
Выглядит просто, но такая сущность давно напрашивалась. В плюсах есть большая необходимость в стандартизированном, независимом от платформы способа манипулирования необработанными двоичными данными, особенно в таких сценариях, как сериализация данных, работа с сетевыми протоколами и взаимодействие с оборудованием. Появление отдельного типа для байтов в C++17 частично решило эти проблемы, так как std::byte:
1️⃣ Обеспечивает строгое разделение манипуляций с сырой памятью от числовых типов. Вы сразу видите, что оперируете с байтами, что снижает риск путаницы с типами данных.
2️⃣ Обеспечивает безопасность при проверке типов. Операции над std::byte выполняются без непреднамеренного преобразования типов, так как нет переопределенных операторов преобразования в базовые типы. Это помогает выявить потенциальные проблемы, связанные с типами, и повышает безопасность кода при работе с данными низкого уровня.
3️⃣ Явно поддерживает только байтовую и битовую арифметику за счёт переопределенных операторов сравнения и битовых манипуляций. Это с одной стороны, ограничивает функционал класса, а, с другой стороны, че вы ещё хотите делать с байтами?
4️⃣ В качестве стандартной фичи C++ использование std::byte обеспечивает безопасность вашего кода на уровне языка.
Есть один единственный минус у этой фичи. Очень мало народу ей пользуется. Большинству существующих проектов на плюсах больше 5 лет и там есть уже свои привычные методы работы с сырой памятью и сишным интерфейсом, которые естественно все завязано на типе char. И только потому, что в стандарте появилась новая фича, никто эти методы изменять не будет. Да и новые проекты могут по инерции использовать старый подход. Он всем знаком и проверен временем.
Так что и, хоть вам не часто доведётся работать с этим типом, знать о его существовании и функционале есть смысл. Вы всегда можете написать новый микросервис или модуль в вашем проекте с использование этой фичи и сделаете код лучше и безопаснее.
Stay hardcore. Stay cool.
#cpp17 #memory #hardcore
{kind=link}