Полезная тула для визуализации нейронных сетей https://github.com/lutzroeder/netron С помощью её вы можете открыть сохранённую нейронную сеть (поддерживаются все основные форматы) и визуализировать в виде красивого графа. Я попробовал, результат выглядит не плохо, и дополнительно к изображению, можно посмотреть параметры каждого слоя и прочитать информацию, что это за слой (естественно для своих слоёв такое не получите)
#tool #nn
#tool #nn
GitHub
GitHub - lutzroeder/netron: Visualizer for neural network, deep learning and machine learning models
Visualizer for neural network, deep learning and machine learning models - lutzroeder/netron
Оказывается сегодня 4-х летний юбилей самой известного фреймворка для создания нейронных сетей. Нет, речь не о tensorflow, а про keras, всё же большинство людей, которые говорят, что используют tensorflow, пишут свои модельки на keras. https://twitter.com/fchollet/status/1110928802077523968
Стоит поздравить команду, keras - это пример хорошего и понятного API. Сейчас он честно интегрирован с tensorflow, но всё так же можно использовать другие фреймворки, theano и CNTK - хотя кого мы обманываем, обычно все используют связку keras + tf backend
#keras #tf
Стоит поздравить команду, keras - это пример хорошего и понятного API. Сейчас он честно интегрирован с tensorflow, но всё так же можно использовать другие фреймворки, theano и CNTK - хотя кого мы обманываем, обычно все используют связку keras + tf backend
#keras #tf
Twitter
François Chollet
Keras turns 4 years old today 🎂 Congrats to all contributors and the entire community! We're only just getting started 👍
Предпочитаю docker-подход к деплойменту приложений. Однажды натолкнулся на интересный баг-особенность на centos.
Описание ситуации:
У вас есть несколько контейнеров:
- backend с REST API
- frontend приложение, которое использует это API,
Оба приложения, естественно имеют свой контейнер. Frontend ходит к API через внешний адрес (естественно через прокси, но это не имеет значения здесь). С дефолтными настройками вы можете столкнуться с проблемой, что ваш контейнер не может получить доступ к API, хотя:
1. Они на одной машине
2. API доступно для всех публично, и с любой другой машины API работает.
Причина в особой конфигурации firewall на centos, что легко исправляется добавлением сети докера в исключения, но не забывайте, что если сеть докера не задана, то при каждом запуске контейнеров docker-сеть может отличаться, поэтому советую задать её явно.
Подробнее здесь https://forums.docker.com/t/no-route-to-host-network-request-from-container-to-host-ip-port-published-from-other-container/39063
Простой фикс для копипаста (не копируйте, если не понимаете, что происходит):
Описание ситуации:
У вас есть несколько контейнеров:
- backend с REST API
- frontend приложение, которое использует это API,
Оба приложения, естественно имеют свой контейнер. Frontend ходит к API через внешний адрес (естественно через прокси, но это не имеет значения здесь). С дефолтными настройками вы можете столкнуться с проблемой, что ваш контейнер не может получить доступ к API, хотя:
1. Они на одной машине
2. API доступно для всех публично, и с любой другой машины API работает.
Причина в особой конфигурации firewall на centos, что легко исправляется добавлением сети докера в исключения, но не забывайте, что если сеть докера не задана, то при каждом запуске контейнеров docker-сеть может отличаться, поэтому советую задать её явно.
Подробнее здесь https://forums.docker.com/t/no-route-to-host-network-request-from-container-to-host-ip-port-published-from-other-container/39063
Простой фикс для копипаста (не копируйте, если не понимаете, что происходит):
sudo firewall-cmd --permanent --zone=public --add-rich-rule='rule family=ipv4 source address=172.19.0.0/16 accept' && firewall-cmd --reloadи конфигурация сети в docker-compose
networks:#docker #web #rest #linux #issues
my-net:
driver: bridge
ipam:
driver: default
config:
- subnet: 172.19.0.0/16
Docker Community Forums
NO ROUTE TO HOST network request from container to host-ip:port published from other container
it’s really weir things to me. I have a container A run with “-p 8080:80”, and a container B ( on the same host ) directly visit host-ip:8080, then log says: NO ROUTE TO HOST. I test the following things: 1.from within container B, “telnet host-ip 8080”…
Следующая информация может быть полезна, если вы хотите запустить jupyter notebook на сервере, сделать сервис публично доступным и сделать это правильно, https и запрятать за каким-нибудь прокси.
Всё кажется предельно просто, запускаем jupyter (лучше в контейнере конечно), настраиваем https на вашем любимом сервере, например apache и настраиваете прокси на ваш jupyter. И всё действительно просто, но не совсем. Jupyter использует прекрасную технологию WebSocket для того, чтобы всё было максимально интерактивно и без WebSocket никак, если вы не пропишите правильно инструкции для прокси, вебсокеты у вас отвалятся, jupyter не будет работать и вообще всё плохо, вы резко перестаёте любить новые технологии.
Но всё не так печально, есть большой стрим обсуждений на github, и там у вас есть всё что надо.
https://github.com/jupyterhub/jupyterhub/issues/219
Всё кажется предельно просто, запускаем jupyter (лучше в контейнере конечно), настраиваем https на вашем любимом сервере, например apache и настраиваете прокси на ваш jupyter. И всё действительно просто, но не совсем. Jupyter использует прекрасную технологию WebSocket для того, чтобы всё было максимально интерактивно и без WebSocket никак, если вы не пропишите правильно инструкции для прокси, вебсокеты у вас отвалятся, jupyter не будет работать и вообще всё плохо, вы резко перестаёте любить новые технологии.
Но всё не так печально, есть большой стрим обсуждений на github, и там у вас есть всё что надо.
https://github.com/jupyterhub/jupyterhub/issues/219
ProxyPreserveHost OnВозможно, нужно понадобится добавить ещё эти строчки, перед <Location ... :
ProxyRequests off
ProxyPass / http://localhost:8000/
ProxyPassReverse / http://localhost:8000/
ProxyPass /api/kernels/ ws://127.0.0.1:8888/api/kernels/
ProxyPassReverse /api/kernels/ https://127.0.0.1:8888/api/kernels/
<Location ~ "/(user/[^/]*)/(api/kernels/[^/]+/channels|terminals/websocket)/?">
ProxyPass ws://localhost:8000
ProxyPassReverse ws://localhost:8000
</Location>
Header edit Origin {external address} localhost:8000
RequestHeader edit Origin {external address} localhost:8000
Header edit Referer {external address} localhost:8000
RequestHeader edit Referer {external address} localhost:8000
Ещё нужно сконфигурировать сам jupyter, см. настройки в документации. В файле jupyter_notebook_config.json можно добавить следующее.{
"NotebookApp": {
"ip": "*",
"allow_origin": "*",
"open_browser": false,
"password": "sha1:yourpass hash",
"trust_xheaders": true
}
}
#jupyter #deployment #web #issuesGitHub
Deploying behind a reverse proxy · Issue #219 · jupyterhub/jupyterhub
Has anyone worked on deploying jupyterhub behind a Reverse Proxy? I am trying to deploy it on a system that communicates with the open network through an Apache reverse proxy. Authentication works ...
Теперь немного про нейронные сети. Обычно сложно интерпретировать как и почему нейронная сеть решила именно так. Я не сторонник полностью интерпретируемого машинного обучения в ущерб их эффективности, но иногда заглянуть в чёрный ящик полезно для разработки.
Например, когда сравнивают разные модели, обычно смотрится общая эффективность на каком-нибудь датасете, но общая оценка не показывает значимые отличая сетей.
В статье проводится обзор на примере задачи автодополнения поисковых запросов (или текста, когда вы набираете что-то на клавиатуре). В статье приходят к выводу, что GRU более ёмкая для запоминания long-term зависимостей, в сравнении с LSTM и Nested LSTM. Что лучше на практике, зависит от задачи, но понимание таких особенностей сетей очень помогает. Было очень бы интересно посмотреть, как запоминают современные модели и сравнить GRU с ELMO, BERT.
https://distill.pub/2019/memorization-in-rnns/
Интересный подход к визуализации "запоминания" в рекуррентных сетях. Как обычно, на distill очень красивые и интерактивные визуализации, хотя бы для этого стоит перейти по ссылке:)
#rnn #nn #sequences #paper
Например, когда сравнивают разные модели, обычно смотрится общая эффективность на каком-нибудь датасете, но общая оценка не показывает значимые отличая сетей.
В статье проводится обзор на примере задачи автодополнения поисковых запросов (или текста, когда вы набираете что-то на клавиатуре). В статье приходят к выводу, что GRU более ёмкая для запоминания long-term зависимостей, в сравнении с LSTM и Nested LSTM. Что лучше на практике, зависит от задачи, но понимание таких особенностей сетей очень помогает. Было очень бы интересно посмотреть, как запоминают современные модели и сравнить GRU с ELMO, BERT.
https://distill.pub/2019/memorization-in-rnns/
Интересный подход к визуализации "запоминания" в рекуррентных сетях. Как обычно, на distill очень красивые и интерактивные визуализации, хотя бы для этого стоит перейти по ссылке:)
#rnn #nn #sequences #paper
Distill
Visualizing memorization in RNNs
Inspecting gradient magnitudes in context can be a powerful tool to see when recurrent units use short-term or long-term contextual understanding.
Без лишних слов, нагляднейшее объяснение таких не простых идей NLP, как word2vec, attention, BERT, ELMo. Если вы хотели разобраться, но читать слишком математические статьи вам не нравится, посмотрите ссылки ниже. Авторские качественные визуализации делают материал доступным.
The Illustrated Word2vec - https://jalammar.github.io/illustrated-word2vec/
The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning) - https://jalammar.github.io/illustrated-bert/
The Illustrated Transformer - https://jalammar.github.io/illustrated-transformer/
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention) - https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/
#learn #nlp #text #word2vec #bert #attention #text
The Illustrated Word2vec - https://jalammar.github.io/illustrated-word2vec/
The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning) - https://jalammar.github.io/illustrated-bert/
The Illustrated Transformer - https://jalammar.github.io/illustrated-transformer/
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention) - https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/
#learn #nlp #text #word2vec #bert #attention #text
jalammar.github.io
The Illustrated Word2vec
Discussions:
Hacker News (347 points, 37 comments), Reddit r/MachineLearning (151 points, 19 comments)
Translations: Chinese (Simplified), French, Korean, Portuguese, Russian
“There is in all things a pattern that is part of our universe.…
Hacker News (347 points, 37 comments), Reddit r/MachineLearning (151 points, 19 comments)
Translations: Chinese (Simplified), French, Korean, Portuguese, Russian
“There is in all things a pattern that is part of our universe.…
Поймал себя на мысли, что когда думаю о прошлом, кажется, что тогда многих технологий ещё не было, а они появились только в нашем детстве. Вот вы задумывались, когда появились первые магнитные банковские карты?
Немного информации из википедии:
в 1951 - нью-йоркским банком выпущена первая карта в мире
в 1951 - первая карта в европе
1964 - Япония не отстаёт
Конец 1960-х — Master Charge является ведущей банковской кредитной картой в США. - в 1979 становится известным нам MasterCard
1970 - появляется National BankAmericard Inc - в последствии VISA
2002 - MasterCard - первый PayPass. И более того в 2005 VISA и MasterCard договорились о едином стандарте
Что по поводу России? Так вот, 21 сентября 1991 первая транзакция, по карте произведённой в россии. Комментарий придумайте сами)
Вот не первый раз задумываюсь что в современных учебниках истории есть большой пробел, мы совершенно упускаем историю технологий, историю, как инженеры и учёные меняли мир вокруг. Потом вырастает поколение, которое считает, что калькулятор, это изобретение рептилоидов (привет рентв).
Многие современные технологии старше чем кажутся, иногда так не кажется, когда люди всё также стоят перед банкоматом в очереди в день получения ЗП, чтобы снять всё.
И если вы ещё никогда не посещали музеи науки, посетите обязательно (жаль в РБ/РФ нет ни одного хорошего).
#future #history
Немного информации из википедии:
в 1951 - нью-йоркским банком выпущена первая карта в мире
в 1951 - первая карта в европе
1964 - Япония не отстаёт
Конец 1960-х — Master Charge является ведущей банковской кредитной картой в США. - в 1979 становится известным нам MasterCard
1970 - появляется National BankAmericard Inc - в последствии VISA
2002 - MasterCard - первый PayPass. И более того в 2005 VISA и MasterCard договорились о едином стандарте
Что по поводу России? Так вот, 21 сентября 1991 первая транзакция, по карте произведённой в россии. Комментарий придумайте сами)
Вот не первый раз задумываюсь что в современных учебниках истории есть большой пробел, мы совершенно упускаем историю технологий, историю, как инженеры и учёные меняли мир вокруг. Потом вырастает поколение, которое считает, что калькулятор, это изобретение рептилоидов (привет рентв).
Многие современные технологии старше чем кажутся, иногда так не кажется, когда люди всё также стоят перед банкоматом в очереди в день получения ЗП, чтобы снять всё.
И если вы ещё никогда не посещали музеи науки, посетите обязательно (жаль в РБ/РФ нет ни одного хорошего).
#future #history
Ранее я уже говорил про очень полезный ресурс, где вы можете найти ссылку на исследование и реализация https://paperswithcode.com/ и ещё один про компьютерное зрение, набор открытых датасетов https://www.visualdata.io/.
Ещё один похожий проект по сбору известных моделей сетей и, очень часто, есть уже обученные модели. https://modelzoo.co/
Идея простая, вы хотите решить какую-то новую для себя задачу, открываете и ищите похожие модели, запускаете, смотрите, разбираетесь в постановке задачи, ищете новые статьи в этом направлении и шаг за шагом понимаете что уже сделали до вас и куда двигаться дальше к решению задачи.
#dataset #model #data
Ещё один похожий проект по сбору известных моделей сетей и, очень часто, есть уже обученные модели. https://modelzoo.co/
Идея простая, вы хотите решить какую-то новую для себя задачу, открываете и ищите похожие модели, запускаете, смотрите, разбираетесь в постановке задачи, ищете новые статьи в этом направлении и шаг за шагом понимаете что уже сделали до вас и куда двигаться дальше к решению задачи.
#dataset #model #data
huggingface.co
Trending Papers - Hugging Face
Your daily dose of AI research from AK
Знаете ли вы, что такое топологическая оптимизация? Основная идея в создании конструкций заданных прочностных характеристик, но с минимальным расходом материала (https://postnauka.ru/faq/84374). Естественно возникает сложность в изготовлении таких "оптимальных" конструкций, поэтому оптимизация проводилась очень давно, но нужно было учитывать, что цена производства может значительно вырасти https://caeai.com/blog/what-topology-optimization-and-why-use-it.
С развитием 3d печати, многие идеи могут получить реальное воплощение, поэтому интерес к этим исследованиям вернулся.
Каково же было моё удивление, когда я узнал, что в современных пакетах для проектирования: ANSYS и SolidWorks (с которыми я сталкивался во время учёбы в университете) есть возможность проводить такого рода оптимизацию.
Ещё одно новое направление, использование машинного обучения для оптимизации таких конструкций. Результат выглядит футуристично и самое важное, что это на самом деле можно использовать. #future #mechanics #optimization
С развитием 3d печати, многие идеи могут получить реальное воплощение, поэтому интерес к этим исследованиям вернулся.
Каково же было моё удивление, когда я узнал, что в современных пакетах для проектирования: ANSYS и SolidWorks (с которыми я сталкивался во время учёбы в университете) есть возможность проводить такого рода оптимизацию.
Ещё одно новое направление, использование машинного обучения для оптимизации таких конструкций. Результат выглядит футуристично и самое важное, что это на самом деле можно использовать. #future #mechanics #optimization
Неоднократно ссылался на гайды от гугл про машинное обучение, уж очевидно, что им есть что рассказать о ML и больших данных. Нашёл время и прочёл очередную серию статей https://developers.google.com/machine-learning/problem-framing - про постановку задач машинного обучения.
Серия статей подходит для чтения совсем новичкам в ML, но с опытом разработки. Люди с опытом найдут тоже много полезного. Особенно если у вас есть опыт исследователя и вы хотите применять знания в продакшене. Материал будет полезен тем, кто хочет делать продукты с ML, там рассматриваются важные вопросы, как нужно подходить к постановке задачи и о том, как оценить, проанализировать то, что нужно для вашего продукта. Меня особенно порадовало сходство правил по выставлению метрик, с рекомендациями, наподобие SMART, для постановки персональных целей.
Дальше лонгрид резюме, набор полезных сниппетов заметок важных идей для себя. Получилось реально много букв, поэтому вынев в telegraph
https://telegra.ph/Postanovka-zadachi-ML-04-07
#ml #problem #framing #production #engineering
Серия статей подходит для чтения совсем новичкам в ML, но с опытом разработки. Люди с опытом найдут тоже много полезного. Особенно если у вас есть опыт исследователя и вы хотите применять знания в продакшене. Материал будет полезен тем, кто хочет делать продукты с ML, там рассматриваются важные вопросы, как нужно подходить к постановке задачи и о том, как оценить, проанализировать то, что нужно для вашего продукта. Меня особенно порадовало сходство правил по выставлению метрик, с рекомендациями, наподобие SMART, для постановки персональных целей.
Дальше лонгрид резюме, набор полезных сниппетов заметок важных идей для себя. Получилось реально много букв, поэтому вынев в telegraph
https://telegra.ph/Postanovka-zadachi-ML-04-07
#ml #problem #framing #production #engineering
Google for Developers
Introduction to Machine Learning Problem Framing | Google for Developers
Вот такую новость подкинул сегодня google assistant. Как же плохо работает техническая журналистика, https://rb.ru/story/ibm-ai-personal/ Вот пример, как не надо подавать новости. Раздражает спекуляция термином Искусственный Интеллект, ну нет там никакого ИИ, ну совсем нет.
Дальше, когда вам говорят, что модель работает с точностью 95%, то вы ничего из этого сообщения не узнали о точности модели. "Точность" - понятие размытое. В данном случае это просто число, ну да, можете статью прочесть и порадоваться https://ru.wikipedia.org/wiki/95_(%D1%87%D0%B8%D1%81%D0%BB%D0%BE)
Чтобы заявление не выглядело пустым, всегда нужно разобраться как это число изменяется, с чем сравнивается и как проверялось. В общем просто сказать, что алгоритм работает 95% точностью мало, нужно уточнить условия при которых это число получено, и что имеется ввиду под "точностью" - это не такой простой вопрос.
Ну и полезность таких моделей слегка преувеличена. Точнее выражаясь, такие модели безусловно полезны, но совсем не несут никакой информации о том, как это можно использовать. Для практического использования будет, например, гораздо полезнее модель предсказывающая сотрудников, которые собираются уходить, но их ещё можно удержать. В идеальном случае, нужна модель, которая сможет предсказать, что не устраивает сотрудника.
#news
Дальше, когда вам говорят, что модель работает с точностью 95%, то вы ничего из этого сообщения не узнали о точности модели. "Точность" - понятие размытое. В данном случае это просто число, ну да, можете статью прочесть и порадоваться https://ru.wikipedia.org/wiki/95_(%D1%87%D0%B8%D1%81%D0%BB%D0%BE)
Чтобы заявление не выглядело пустым, всегда нужно разобраться как это число изменяется, с чем сравнивается и как проверялось. В общем просто сказать, что алгоритм работает 95% точностью мало, нужно уточнить условия при которых это число получено, и что имеется ввиду под "точностью" - это не такой простой вопрос.
Ну и полезность таких моделей слегка преувеличена. Точнее выражаясь, такие модели безусловно полезны, но совсем не несут никакой информации о том, как это можно использовать. Для практического использования будет, например, гораздо полезнее модель предсказывающая сотрудников, которые собираются уходить, но их ещё можно удержать. В идеальном случае, нужна модель, которая сможет предсказать, что не устраивает сотрудника.
#news
Rusbase
Искусственный интеллект IBM научился прогнозировать уход сотрудников с точностью до 95%
IBM получает более 8 тысяч резюме в день.
Немножко мотивации: Progress Bar года https://twitter.com/year_progress или если вам больше нравится https://www.yearprogressbar.com/ и https://hugovk.github.io/year-progress-bar/ показывают какую часть года мы про ̶е̶...жили. ну правда же идеальные проекты?) Не знаю как вы, а я себе добавлю в закладку браузера, или в виде виджета на телефон
#fun
#fun
X (formerly Twitter)
Year Progress (@year_progress) on X
The only progress bar you'd rather see go slower (or faster?)
Пожалуй лучшее объяснение, что такое Agile https://habr.com/ru/company/edison/blog/313410/ (Как объяснить бабушке, что такое Agile за 15 минут)
#agile #management
#agile #management
Хабр
Как объяснить бабушке, что такое Agile за 15 минут с картинками
«Любое дело всегда длится дольше, чем ожидается, даже если учесть закон Хофштадтера.» — закон Хофштадтера Самый просматриваемый ролик на YouTube по теме agile. 744 625 просмотров на момент публикации...
В эту субботу в 19:00 участвую в митапе, расскажу про нейронки и немного о том, как запускать их на JavaScript, вместе попытаемся ответить зачем это кому-то надо. Узнать как устроены нейронные сети и при чем здесь баклажан вы сможете узнать, если придёте на митап. Регистрация и детали здесь: https://communities.by/events/storm-the-front-meetup-5
Сегодня хочу поделиться несколькими ссылками на обучающие статьи, первая из них о нейронных сетях на PyTorch, очень хороший туториал для того, чтобы начать, достаточно подробно и небольшими шагами объясняются всё более сложные идеи фреймворка https://pytorch.org/tutorials/beginner/nn_tutorial.html
Вторая о TensorFlow 2.0, он вот-вот выйдет, интересного там много и важные новшества отображены в виде серии твитов https://twitter.com/fchollet/status/1105139360226140160 ( есть документ, где можно сразу и запустить https://colab.research.google.com/drive/17u-pRZJnKN0gO5XZmq8n5A2bKGrfKEUg)
Дальше про математику, не сложная серия статей про важные концепции, которые нужны Data Science https://towardsdatascience.com/statistics-is-the-grammar-of-data-science-part-1-c306cd02e4db объяснение поверхностное, но не плохое в качестве отправной точки. Последняя статья из серии о важной теореме Байеса, о которой рекомендую почитать серию статей https://arbital.com/p/bayes_rule_guide/ подробно, на примерах с картинками, всё как мы любим
#nn #math #pytorch #tf #stats #tuturial
Вторая о TensorFlow 2.0, он вот-вот выйдет, интересного там много и важные новшества отображены в виде серии твитов https://twitter.com/fchollet/status/1105139360226140160 ( есть документ, где можно сразу и запустить https://colab.research.google.com/drive/17u-pRZJnKN0gO5XZmq8n5A2bKGrfKEUg)
Дальше про математику, не сложная серия статей про важные концепции, которые нужны Data Science https://towardsdatascience.com/statistics-is-the-grammar-of-data-science-part-1-c306cd02e4db объяснение поверхностное, но не плохое в качестве отправной точки. Последняя статья из серии о важной теореме Байеса, о которой рекомендую почитать серию статей https://arbital.com/p/bayes_rule_guide/ подробно, на примерах с картинками, всё как мы любим
#nn #math #pytorch #tf #stats #tuturial
Twitter
François Chollet
Are you a deep learning researcher? Wondering if all this TensorFlow 2.0 stuff you heard about is relevant to you? This thread is a crash course on everything you need to know to use TensorFlow 2.0 + Keras for deep learning research. Read on!
Задумывались ли вы когда-нибудь, почему на монетах зубчатые грани?
Когда-то монеты были очень разные, и количество ценного метала было сложно проверить, поэтому были распространены махинации: почему бы не взять 10 монет, отпилить с каждой по немного и получить ещё одну монету. Поэтому нужно было придумать какой-то способ защиты, зубчатые грани значительно усложняют подделку монеты. Изготовлением монет без ценных металлов, это следующий важный экономический шаг.
Интересный факт, что в Англии замена монет проходила во времена Исака Ньютона, который был выбран для работы в Монетном дворе, ходят легенды, что именно Ньютон предложил добавить грани, но в биографии такого факта нет, да и зубчатые монеты были намного раньше, но на долю Ньютона выпало проведение многих улучшений в производстве монет.
https://en.wikipedia.org/wiki/Methods_of_coin_debasement
#just #facts
Когда-то монеты были очень разные, и количество ценного метала было сложно проверить, поэтому были распространены махинации: почему бы не взять 10 монет, отпилить с каждой по немного и получить ещё одну монету. Поэтому нужно было придумать какой-то способ защиты, зубчатые грани значительно усложняют подделку монеты. Изготовлением монет без ценных металлов, это следующий важный экономический шаг.
Интересный факт, что в Англии замена монет проходила во времена Исака Ньютона, который был выбран для работы в Монетном дворе, ходят легенды, что именно Ньютон предложил добавить грани, но в биографии такого факта нет, да и зубчатые монеты были намного раньше, но на долю Ньютона выпало проведение многих улучшений в производстве монет.
https://en.wikipedia.org/wiki/Methods_of_coin_debasement
#just #facts
Wikipedia
Debasement
practice of lowering the value of currency; financial gain for the sovereign at the expense of citizens
Около недели назад посетил https://datafest.by в Минске, некоторые заметки по этому поводу.
Доклады мне понравились, было 2 трека, один более практический, то, что нужно в продакшене, а другой больше про разные новые идеи.
В основном слушал доклады со второго трека (видео со второго трека пока не опубликованы, с первого уже доступны).
Чтобы организовать работу команды data science, нужно подумать о том, как контролировать версии моделей, данных и пайплайнов и иметь возможность повторять эксперименты. Про это первых 2 доклада.
1. Создание Data Science архитектуры на базе Apache Airflow - узнал про https://azkaban.github.io/ и https://airflow.apache.org/, так же был упомянут шаблон data science проекта, с которого мы тоже когда-то начинали https://drivendata.github.io/cookiecutter-data-science/ - в целом доклад суховат, и больше про пайплайны, а не про управление экспериментами.
2. Начните с контроля версий и управления экспериментами в ML проектах. Доклад про DVC и он как раз более интересный и полезный для начинающей ML команды. В нём разбирается переход от простого, к более сложному проекту, показывая какие подходы и инструменты позволяют улучшить проект. Про https://dvc.org/ знал давно, похоже пока это лучший инструмент, хоть и не лишён недостатков. Из доклада узнал про https://mlflow.org/, мне этот инструмент кажется довольно интересным.
3. Эксплуатация ML в Почте Mail.ru - думал доклад не очень интересный, но вынес для себя много полезных трюков для дообучения моделей. Как использовать эмбеддинги сети и решающие деревья вместе. Конечно всё это не новые техники, но именно это уже давно используется в продакшене.
4. Откуда, куда и как быстро бежит NLP. - последовательное изложение достижений NLP от более простого к SOTA на данный момент решениям - если вы только начали работать с NLP будет очень полезно, но если вы знаете о Transformer и BERT, думаю вы и так всё знаете.
5. Экспертная оценка текстовой информации ML и NLP методами.Не всем этот доклад понравился, мало крутого машинного обучения, много разных трюков, и слабая валидация результатов. Всё же для себя я отметил большой набор идей и алгоритмов, которые мне нужны для решения задач.
В докладе показывали такую карту сентимента новостей https://krimmkr.carto.com/builder/e211c628-c0b7-4877-8cae-b4832d93c75c/embed
Также были затронуты некоторые рюки с эмбедингами и LDA для выделения похожих категорий текста, knn для того, чтобы удалить мусорные топики. Извлечение паттернов с помощью обычных морфологических шаблонов.
Дальше я переместился в трек 1
6. Полностью генеративные ответы на вопросы в Поддержку ВКонтакте - доклад не зашёл, мои ожидания были выше, того, что я узнал.
7. Анализ реплеев компьютерных игр. Кажется что доклад про игры,как предсказывать победителя по поведению в игре. Но он глубже чем кажется, подумайте о том, как можно использовать эту информацию, просто замените слово "Dota" на любой домен где есть некая динамика - поведение человека, история использования гаджетом и т.д.
8. Как понять пешеходов - действительно, как? Доклад традиционно рассказывает о проблемах, и почему простые методы не работают, слушать увлекательно, решения интересные - в очередной раз хочу сказать, что Deep Learning + творческое мышление = интересный результат.
9. От простого к сложному в аналитике рука об руку с бизнесом. Критически важный доклад, для использования ML в продакшене. Нужно помнить, что информацию нужно правильно преподносить бизнес-стейкхолдерам, и нужно переводить их требования в аналитические задачи, и тогда у вас будут интересные задачи, полезные бизнесу.
#ml #datafest #summary
Доклады мне понравились, было 2 трека, один более практический, то, что нужно в продакшене, а другой больше про разные новые идеи.
В основном слушал доклады со второго трека (видео со второго трека пока не опубликованы, с первого уже доступны).
Чтобы организовать работу команды data science, нужно подумать о том, как контролировать версии моделей, данных и пайплайнов и иметь возможность повторять эксперименты. Про это первых 2 доклада.
1. Создание Data Science архитектуры на базе Apache Airflow - узнал про https://azkaban.github.io/ и https://airflow.apache.org/, так же был упомянут шаблон data science проекта, с которого мы тоже когда-то начинали https://drivendata.github.io/cookiecutter-data-science/ - в целом доклад суховат, и больше про пайплайны, а не про управление экспериментами.
2. Начните с контроля версий и управления экспериментами в ML проектах. Доклад про DVC и он как раз более интересный и полезный для начинающей ML команды. В нём разбирается переход от простого, к более сложному проекту, показывая какие подходы и инструменты позволяют улучшить проект. Про https://dvc.org/ знал давно, похоже пока это лучший инструмент, хоть и не лишён недостатков. Из доклада узнал про https://mlflow.org/, мне этот инструмент кажется довольно интересным.
3. Эксплуатация ML в Почте Mail.ru - думал доклад не очень интересный, но вынес для себя много полезных трюков для дообучения моделей. Как использовать эмбеддинги сети и решающие деревья вместе. Конечно всё это не новые техники, но именно это уже давно используется в продакшене.
4. Откуда, куда и как быстро бежит NLP. - последовательное изложение достижений NLP от более простого к SOTA на данный момент решениям - если вы только начали работать с NLP будет очень полезно, но если вы знаете о Transformer и BERT, думаю вы и так всё знаете.
5. Экспертная оценка текстовой информации ML и NLP методами.Не всем этот доклад понравился, мало крутого машинного обучения, много разных трюков, и слабая валидация результатов. Всё же для себя я отметил большой набор идей и алгоритмов, которые мне нужны для решения задач.
В докладе показывали такую карту сентимента новостей https://krimmkr.carto.com/builder/e211c628-c0b7-4877-8cae-b4832d93c75c/embed
Также были затронуты некоторые рюки с эмбедингами и LDA для выделения похожих категорий текста, knn для того, чтобы удалить мусорные топики. Извлечение паттернов с помощью обычных морфологических шаблонов.
Дальше я переместился в трек 1
6. Полностью генеративные ответы на вопросы в Поддержку ВКонтакте - доклад не зашёл, мои ожидания были выше, того, что я узнал.
7. Анализ реплеев компьютерных игр. Кажется что доклад про игры,как предсказывать победителя по поведению в игре. Но он глубже чем кажется, подумайте о том, как можно использовать эту информацию, просто замените слово "Dota" на любой домен где есть некая динамика - поведение человека, история использования гаджетом и т.д.
8. Как понять пешеходов - действительно, как? Доклад традиционно рассказывает о проблемах, и почему простые методы не работают, слушать увлекательно, решения интересные - в очередной раз хочу сказать, что Deep Learning + творческое мышление = интересный результат.
9. От простого к сложному в аналитике рука об руку с бизнесом. Критически важный доклад, для использования ML в продакшене. Нужно помнить, что информацию нужно правильно преподносить бизнес-стейкхолдерам, и нужно переводить их требования в аналитические задачи, и тогда у вас будут интересные задачи, полезные бизнесу.
#ml #datafest #summary
datafest.by
Data Fest
Крупнейшие Data Science конференции в Беларуси
Andrej Karpathy недавно опубликовал у себя подборку советов, как тренировать нейронные сети. Со стороны может показаться что тренировка сетей сводится к подбору параметров, берём некоторую модель и начинаем случайным образом выбирать параметры и учить модели и сравнивать результаты, но всё куда сложнее и если работать таким образом, то вероятно у вас ничего хорошего не получится.
По большей части советы расписанные в статье будут вам знакомы, если вы уже имеете реальный опыт решения задач с помочью нейронных сетей, но думаю вы найдете полезным иметь такую список советов.
https://karpathy.github.io/2019/04/25/recipe/
#nn #guide #tutorial
По большей части советы расписанные в статье будут вам знакомы, если вы уже имеете реальный опыт решения задач с помочью нейронных сетей, но думаю вы найдете полезным иметь такую список советов.
https://karpathy.github.io/2019/04/25/recipe/
#nn #guide #tutorial
karpathy.github.io
A Recipe for Training Neural Networks
Musings of a Computer Scientist.
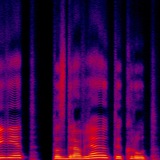
Вы конечно же слышали о впечатляющей MuseNet от OpenAI https://openai.com/blog/musenet/, а вот работа от facebook тоже связанная с музыкой, хоть и не получила большого анонса https://github.com/facebookresearch/music-translation
Одна из возможностей разделить музыкальную композицию на составляющие её музыкальные ряды, очень напомнило один проект связанный с разделением сигналов мозга https://neurosteer.com
Больше примеров доступно на этой странице.
https://musictranslation.github.io/
#fun #musenet #facebook #openai
Одна из возможностей разделить музыкальную композицию на составляющие её музыкальные ряды, очень напомнило один проект связанный с разделением сигналов мозга https://neurosteer.com
Больше примеров доступно на этой странице.
https://musictranslation.github.io/
#fun #musenet #facebook #openai
Openai
MuseNet
We’ve created MuseNet, a deep neural network that can generate 4-minute musical compositions with 10 different instruments, and can combine styles from country to Mozart to the Beatles. MuseNet was not explicitly programmed with our understanding of music…
Как ваши сервисы хранят бинарные артифакты/файлы? В базу сохранять большие объекты не лучший выбор. Напрямую хранить на диске? Проблем тоже не мало вызывает такой подход (с масштабированием, с доступом, нет абстракции над файловой системой и т.д.). Решает эти проблемы уже давно решает s3 у Amazon (у гугла есть сбой object storage, а у azure - свой)
Если вы хотите получить бонусы s3, но ещё не в amazon, то не плохая альтернатива https://min.io/. Всё очень просто: деплоим, и получаем s3 совместимый API, простую UI. Решение масштабируемое, есть возможность поднять в docker контейнере или даже запустить на кластере с использованием docker swarm или kubernetes
#aws #minio #s3
Если вы хотите получить бонусы s3, но ещё не в amazon, то не плохая альтернатива https://min.io/. Всё очень просто: деплоим, и получаем s3 совместимый API, простую UI. Решение масштабируемое, есть возможность поднять в docker контейнере или даже запустить на кластере с использованием docker swarm или kubernetes
#aws #minio #s3
www.min.io
Exascale object store for AI | MinIO
MinIO's High Performance Object Storage is Open Source, Amazon S3 compatible, Kubernetes Native, and is designed for cloud native workloads like AI.